TL;DR#
Current video editing methods struggle to realistically edit videos involving hand-object interactions (HOI). Existing generative models often fail to produce natural-looking edits when object shapes or functionalities change, resulting in unnatural hand poses or object placements. This is due to challenges in HOI awareness, precise spatial alignment, and controllable motion alignment.
HOI-Swap, a novel two-stage framework, is proposed to address these issues. The first stage focuses on object swapping in a single frame with HOI awareness, while the second stage extends this edit across the video sequence, using optical flow to achieve controllable motion alignment. Comprehensive evaluations demonstrate that HOI-Swap significantly improves the quality of video edits, generating realistic HOIs and outperforming existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a challenging problem in video editing, achieving realistic hand-object interaction results that were previously unattainable. It introduces a novel two-stage framework and opens new avenues for research in HOI-aware video generation and manipulation. This will impact the fields of entertainment, advertising, and robotics.
Visual Insights#

🔼 This figure demonstrates the results of HOI-Swap, a novel video editing framework that swaps objects in videos while maintaining hand-object interaction awareness. Three examples are shown, each replacing a kettle with a different object (A water bottle, a bowl, and a different kettle). The figure highlights the model’s ability to seamlessly integrate the new objects into the videos, naturally adjusting hand poses to match the new objects’ shapes and positions. This illustrates the key capabilities of the HOI-Swap model: precise object swapping and realistic HOI.
read the caption
Figure 1: We present HOI-Swap that seamlessly swaps the in-contact object in videos using a reference object image, producing precise video edits with natural hand-object interactions (HOI). Notice how the generated hand needs to adjust to the shapes of the swapped-in objects (A,B,C) and how the reference object may require automatic re-posing to fit the video context (A).

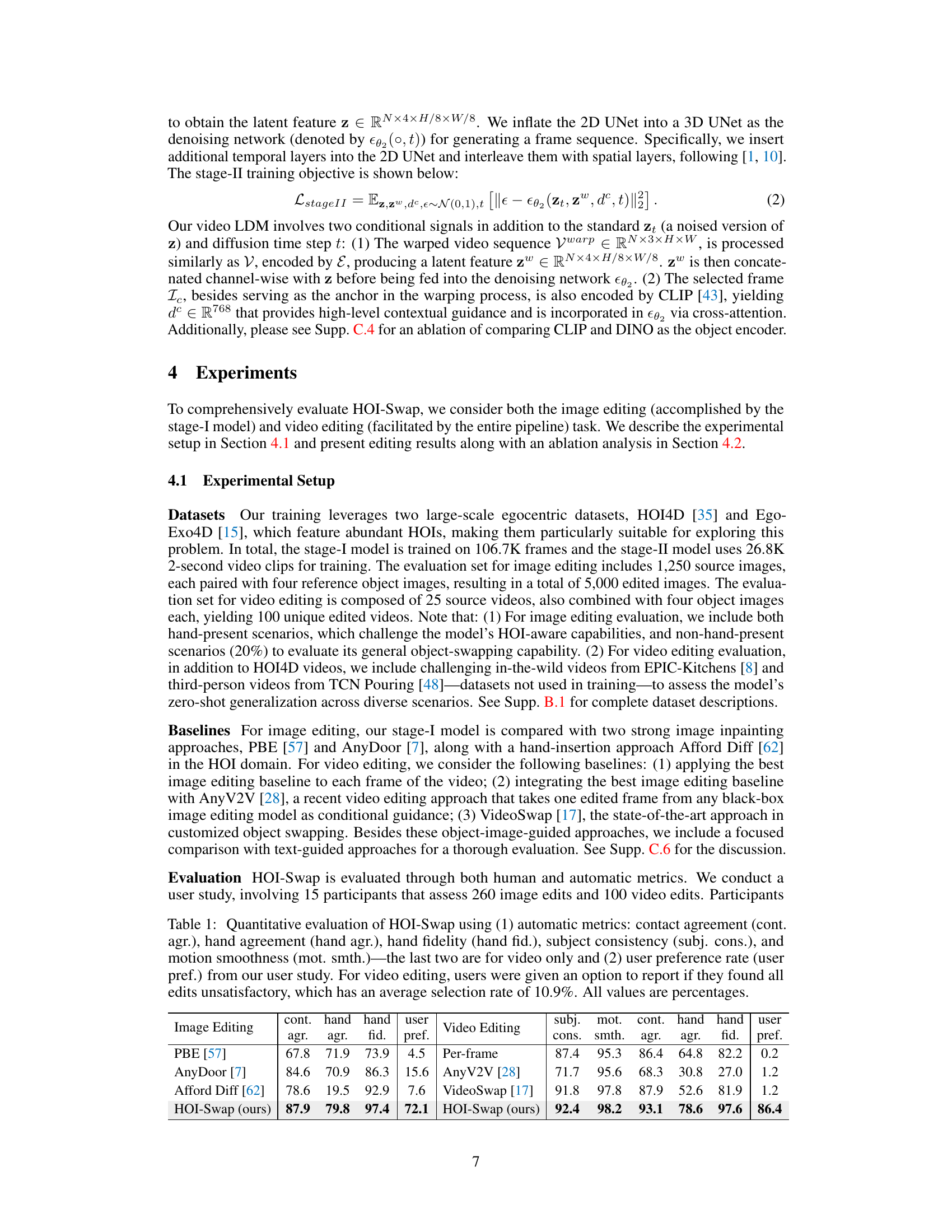
🔼 This table presents a quantitative comparison of HOI-Swap against several baselines for both image and video editing tasks. It uses both automatic metrics (measuring things like hand realism and motion smoothness) and human preference rates from a user study. The results show that HOI-Swap significantly outperforms the baselines in terms of overall quality and user preference.
read the caption
Table 1: Quantitative evaluation of HOI-Swap using (1) automatic metrics: contact agreement (cont. agr.), hand agreement (hand agr.), hand fidelity (hand fid.), subject consistency (subj. cons.), and motion smoothness (mot. smth.)—the last two are for video only and (2) user preference rate (user pref.) from our user study. For video editing, users were given an option to report if they found all edits unsatisfactory, which has an average selection rate of 10.9%. All values are percentages.
In-depth insights#
HOI-Swap Overview#
HOI-Swap is a novel video editing framework designed to seamlessly swap objects in videos while maintaining hand-object interaction (HOI) awareness. Its two-stage architecture addresses the challenges of realistic HOI replacement. Stage one focuses on single-frame object swapping, learning to adjust hand grasp patterns based on object property changes. Stage two extends this edit across the entire video sequence using optical flow to align motion, creating a controllable level of temporal correspondence between the edited video and the original. The framework is trained in a self-supervised manner, avoiding the need for paired video data. HOI-Swap’s key innovation lies in its capacity for controllable motion alignment, allowing adjustments based on the degree of object change. The approach significantly outperforms existing methods, producing high-quality edits with natural HOIs and demonstrating its superior performance through comprehensive quantitative and qualitative evaluations.
Two-Stage Approach#
A two-stage approach to video object swapping offers a structured way to tackle the complexities of hand-object interaction (HOI). The first stage, focused on single-frame editing, is crucial for establishing spatial alignment and HOI awareness. By inpainting the object region within a single frame, this stage allows the model to learn the nuances of how hands interact with objects of varying shapes and properties. This addresses the challenge of realistic hand poses and grasps. The second stage extends this single-frame edit across the entire video sequence. This stage is particularly important for achieving temporal coherence. By using optical flow and strategically sampled motion points, the model can maintain realistic motion while adapting to changes in object shape and functionality. This two-stage design allows for a more manageable and effective training process compared to a single-stage approach, resulting in higher-quality video edits and a greater level of control over the final result. Importantly, the decoupling of spatial and temporal aspects in separate stages addresses the distinct challenges inherent in HOI-aware video manipulation.
Motion Control#
The concept of “Motion Control” in video editing, particularly within the context of object manipulation, is crucial for realism. HOI-Swap’s approach tackles this by introducing a two-stage framework. The first stage focuses on single-frame edits, ensuring spatial alignment and HOI awareness. The second stage cleverly uses optical flow to warp a sequence, based on randomly sampled points, to generate a new video consistent with the original motion. Controllability is a key feature; varying the number of sampled points allows for flexibility in the degree of motion alignment, adapting to the degree of object change. This is a significant departure from the fixed-alignment approaches of many current methods, representing a key advancement for realistic HOI-aware video editing. The effectiveness of this approach is supported by experimental results, highlighting its ability to produce realistic video edits that surpass the quality of existing techniques.
Limitations#
The limitations section of a research paper is crucial for demonstrating a thorough understanding of the work’s scope and boundaries. It allows the authors to honestly acknowledge the shortcomings of their approach, enhancing the paper’s credibility and paving the way for future improvements. A thoughtful limitations section identifies specific areas where the model falls short, such as its reliance on certain assumptions that might not hold in real-world scenarios, or the datasets used for training and evaluation. It also acknowledges constraints such as computational resources, leading to limitations on the model’s scalability or the types of videos it can effectively handle. It might discuss aspects of generalization, pointing out where the model’s performance degrades when faced with new object types or changes in visual context. Crucially, the limitations section should be more than a mere list; it should provide nuanced insights into the nature and severity of these limitations, offering valuable context and potential solutions for future research. A well-written limitations section is not meant to diminish the value of the work but rather to strengthen it, demonstrating the authors’ self-awareness and providing a roadmap for future improvements. By explicitly mentioning these limitations, researchers can make the paper more complete and robust, opening up opportunities for constructive criticism and future advancements. The authors’ honest assessment and forward-looking perspective will greatly benefit the scientific community.
Future Work#
The paper’s “Future Work” section implicitly acknowledges the limitations of the current approach and proposes avenues for improvement. Generalization to new objects and longer, more complex video sequences are key areas identified. The model’s current ability to handle variations in object shape and function is limited, especially in longer sequences where hand-object interactions may evolve dynamically. The authors suggest the need for incorporating world knowledge so the model can predict HOIs (Hand-Object Interactions) even with unfamiliar objects. The challenge of improving motion control is also addressed; finer control over the degree of motion alignment between the generated and original videos is desired, potentially through spatial-temporal control. Addressing these challenges would significantly enhance HOI-Swap’s applicability and robustness, marking valuable steps toward realistic and versatile video editing technology. Expanding the model’s capabilities to handle diverse and complex HOIs while maintaining its efficiency is the ultimate goal.
More visual insights#
More on figures

🔼 This figure highlights three key challenges in swapping in-contact objects in videos: HOI (Hand-Object Interaction) awareness (adapting hand grasp to object shape changes), spatial alignment (correctly positioning the swapped object relative to the hand and scene), and temporal alignment (controlling the motion of the swapped object to match the video’s context). It compares HOI-Swap’s results to three other methods (PBE, AnyDoor, Afford Diff), showcasing its superior performance in addressing these challenges.
read the caption
Figure 2: We highlight three challenges for the in-contact object swapping problem: (a) HOI awareness, where the model needs to adapt to interactions, such as changing the grasp to realistically accommodate the different shapes of the kettle vs. the bowl; (b) spatial alignment with source, requiring the model to automatically reorient objects, such as aligning the blue kettle from the reference image to match the hand position in the source; (c) temporal alignment with source, necessitating controllable motion guidance capability, essential when swapping objects like a trash can with a differently shaped and functioning reference, where not all original motions are transferable or desirable. In (a) and (b), we compare HOI-Swap's edited images with Paint by Example (PBE) [57], AnyDoor [7], and Affordance Diffusion (Afford Diff) [62].
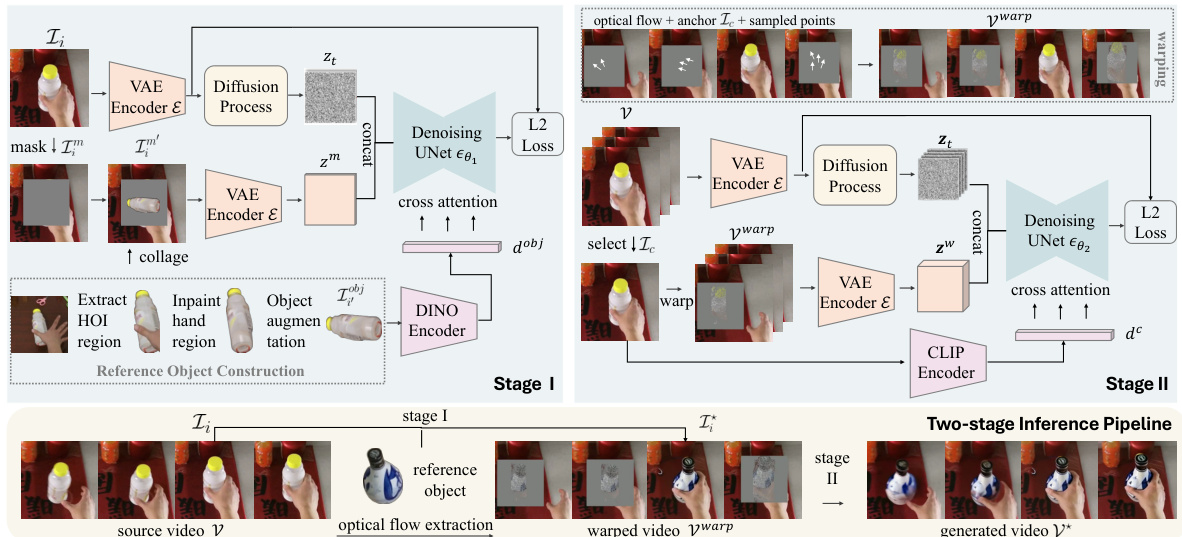
🔼 This figure illustrates the two-stage framework of HOI-Swap. Stage I focuses on single-frame object swapping with HOI awareness, while stage II extends this edit across the whole video sequence, achieving controllable motion alignment. The self-supervised training process is also visualized.
read the caption
Figure 3: HOI-Swap involves two stages, each trained separately in a self-supervised manner. In stage I, an image diffusion model θ₁ is trained to inpaint the masked object region with a strongly augmented version of the original object image. In stage II, one frame is selected from the video to serve as the anchor. The remaining video is then warped using this anchor frame, several points sampled within it, and optical flow extracted from the video. A video diffusion model θ₂ is trained to reconstruct the full video sequence from the warped sequence. During inference, the stage-I model swaps the object in one frame. This edited frame then serves as the anchor for warping a new video sequence, which is subsequently taken as input for the stage-II model to generate the complete video. reference object is realistically interacting with human hands and accurately positioned within the scene context of the source frame.

🔼 This figure shows qualitative comparisons of HOI-Swap’s image and video editing results against several baselines. It highlights HOI-Swap’s ability to seamlessly replace objects in contact with hands while maintaining realistic hand interactions and motion consistency in videos. The results showcase HOI-Swap’s superior performance in both image and video editing tasks compared to other state-of-the-art methods.
read the caption
Figure 4: Qualitative results of HOI-Swap. We compare HOI-Swap with image (left) and video editing approaches (right). The reference object image is shown in the upper left corner of the source image. For image editing, HOI-Swap demonstrates the ability to seamlessly swap in-contact objects with HOI awareness, even in cluttered scenes. For video editing, HOI-Swap effectively propagates the one-frame edit across the entire video sequence while accurately following the source video's motion, achieving the highest overall quality among all methods. We highly encourage readers to check Supp. C.1 and the project page video for more comparisons.

🔼 This figure shows an ablation study on the impact of using different numbers of sampled motion points as input to the second stage of the HOI-Swap model. The left side visualizes the warped video sequences (Vwarp) that serve as input to the second stage’s video diffusion model. The right side shows the final generated videos resulting from using no sampled points, all sampled points, or an intermediate number of points. It demonstrates the model’s ability to control the degree of motion alignment with the source video by adjusting the number of sampled points, which is particularly useful when swapping objects with significantly different shapes or functionalities. When no points are sampled, the generated video diverges from the original video’s motion. As the number of sampled points increases, the generated motion more closely follows the motion of the source video.
read the caption
Figure 5: Ablation study on sampled motion points, comparing no to full motion points sampling. Left: we visualize Vwarp, used as conditional guidance for the stage-II model. Note that row 1 displays warp based on the source frame and is for illustration only, not provided to the model. Right: HOI-Swap exhibits controllable motion alignment: with no sampled points, the generated video diverges from the source video's motion; with full motion points, it closely mimics the source.

🔼 This figure compares a one-stage and a two-stage approach for swapping objects in videos. The results show that the two-stage approach (HOI-Swap) outperforms the one-stage baseline in terms of both qualitative and quantitative metrics. The one-stage model struggles to maintain the identity of the swapped object and doesn’t accurately model the hand-object interactions, while the two-stage model produces better results.
read the caption
Figure 6: Qualitative and quantitative comparisons between a one-stage baseline [1] and our two-stage HOI-Swap. The one-stage model struggles with preserving the new object's identify and fails to generate accurate interaction patterns, yielding inferior quantitative performance.

🔼 This figure shows the user interface for the human evaluation of image editing results. Participants are presented with a source image and a reference object image. They are then shown four edited images: three from baseline methods and one from HOI-Swap (randomly ordered). Participants are asked to rate the images based on several criteria including how well the reference object’s identity is preserved, the realism of the hand-object interaction, and the overall quality of the edit. These criteria help to assess the HOI-awareness, spatial alignment, and overall effectiveness of the different methods.
read the caption
Figure 7: Human evaluation interface for image editing part. We provide a source frame for editing alongside an image of the reference object. Users are asked to evaluate and select their favorite edited results based on various image editing criteria.

🔼 This figure illustrates the two-stage framework of the HOI-Swap model. Stage I focuses on single-frame object swapping with hand-object interaction (HOI) awareness, using an image diffusion model. Stage II extends this single-frame edit across the video sequence using warping based on optical flow and sampled points, then a video diffusion model reconstructs the video. The self-supervised training process for each stage is also shown.
read the caption
Figure 3: HOI-Swap involves two stages, each trained separately in a self-supervised manner. In stage I, an image diffusion model θ1 is trained to inpaint the masked object region with a strongly augmented version of the original object image. In stage II, one frame is selected from the video to serve as the anchor. The remaining video is then warped using this anchor frame, several points sampled within it, and optical flow extracted from the video. A video diffusion model θ2 is trained to reconstruct the full video sequence from the warped sequence. During inference, the stage-I model swaps the object in one frame. This edited frame then serves as the anchor for warping a new video sequence, which is subsequently taken as input for the stage-II model to generate the complete video.

🔼 This figure showcases a qualitative comparison of HOI-Swap with other image and video editing methods. It highlights HOI-Swap’s ability to seamlessly replace objects in images and videos while maintaining realistic hand-object interactions, even in complex scenes. The results demonstrate its superior performance compared to other methods in terms of natural interactions and motion alignment.
read the caption
Figure 4: Qualitative results of HOI-Swap. We compare HOI-Swap with image (left) and video editing approaches (right). The reference object image is shown in the upper left corner of the source image. For image editing, HOI-Swap demonstrates the ability to seamlessly swap in-contact objects with HOI awareness, even in cluttered scenes. For video editing, HOI-Swap effectively propagates the one-frame edit across the entire video sequence while accurately following the source video's motion, achieving the highest overall quality among all methods. We highly encourage readers to check Supp. C.1 and the project page video for more comparisons.

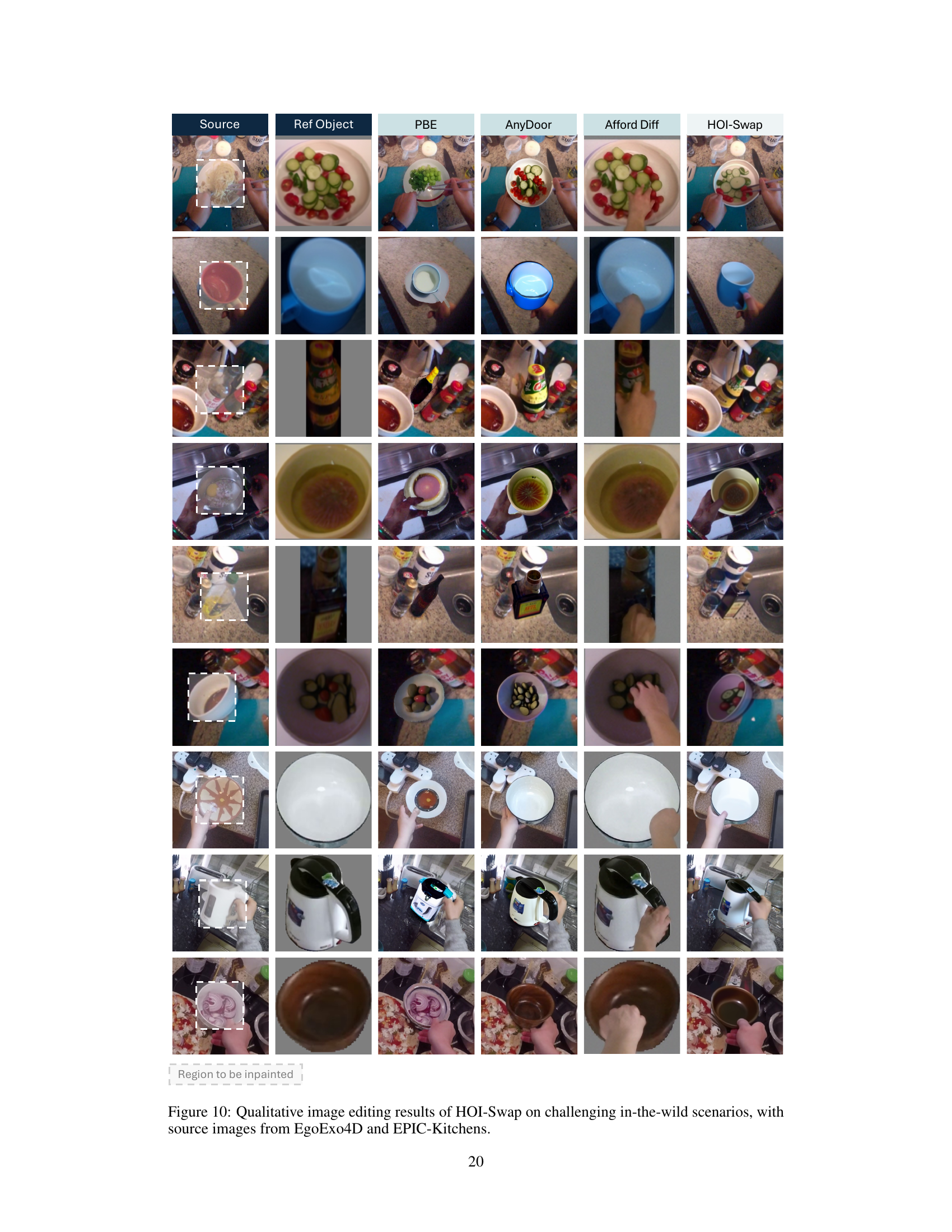
🔼 This figure shows a comparison of HOI-Swap with other image editing baselines on challenging in-the-wild scenarios. The first column shows the source image with the region to be inpainted indicated by a dotted box. The second column displays the reference object. The subsequent columns show the results from using PBE, AnyDoor, Afford Diff, and HOI-Swap. The images demonstrate HOI-Swap’s ability to seamlessly swap objects in complex scenes even when the background is cluttered, resulting in more natural and realistic-looking hand-object interactions compared to the baselines.
read the caption
Figure 10: Qualitative image editing results of HOI-Swap on challenging in-the-wild scenarios, with source images from EgoExo4D and EPIC-Kitchens.

🔼 This figure showcases the results of HOI-Swap, a novel video editing framework. It demonstrates the ability to seamlessly swap objects within videos while maintaining realistic hand-object interactions. The results show several examples of objects being swapped, highlighting the model’s ability to adapt the hand’s grasp and pose to match the new object, even requiring re-posing to fit the video context. The reference image is shown for comparison.
read the caption
Figure 1: We present HOI-Swap that seamlessly swaps the in-contact object in videos using a reference object image, producing precise video edits with natural hand-object interactions (HOI). Notice how the generated hand needs to adjust to the shapes of the swapped-in objects (A,B,C) and how the reference object may require automatic re-posing to fit the video context (A).

🔼 This figure showcases the main results of HOI-Swap, highlighting its ability to seamlessly replace objects in videos while maintaining realistic hand-object interactions. It demonstrates the model’s adaptability to different object shapes and its capacity to adjust hand poses accordingly. The example shows three variations (A, B, and C) of the same video with different objects substituted for the original object. This illustrates the nuanced changes in hand-object interaction the system accounts for.
read the caption
Figure 1: We present HOI-Swap that seamlessly swaps the in-contact object in videos using a reference object image, producing precise video edits with natural hand-object interactions (HOI). Notice how the generated hand needs to adjust to the shapes of the swapped-in objects (A,B,C) and how the reference object may require automatic re-posing to fit the video context (A).

🔼 This figure shows an ablation study on the impact of sampled motion points sparsity on the video generation results. The left column shows a scenario where the original and new objects differ significantly in shape and function, so only partial motion transfer is desired; the right column shows a scenario where the original and new objects are quite similar, so full motion transfer is preferred. In each column, the top row shows the source video frames, and the subsequent rows show the generated video frames using different numbers of sampled motion points (0%, 50%, 100%). The results demonstrate that HOI-Swap can generate videos with different degrees of motion alignment with the original video, demonstrating its flexibility and adaptability.
read the caption
Figure 13: Ablation study of sampled motion points sparsity. The left figure illustrates a scenario where only partial motion transfer is desired, due to differences between the original and new object. The right figure showcases a scenario where full motion transfer is beneficial, owing to the similarities between the objects. We invite readers to view these examples in our project page.

🔼 This figure shows an ablation study on the impact of the number of sampled motion points used in the second stage of the HOI-Swap model. The left side visualizes the warped video sequence (Vwarp) which is used as conditional guidance for the video generation process. The right side shows the generated videos with different numbers of sampled points. It demonstrates that HOI-Swap exhibits controllable motion alignment, allowing the model to generate videos that either closely mimic or diverge from the source video’s motion depending on the number of points sampled.
read the caption
Figure 5: Ablation study on sampled motion points, comparing no to full motion points sampling. Left: we visualize Vwarp, used as conditional guidance for the stage-II model. Note that row 1 displays warp based on the source frame and is for illustration only, not provided to the model. Right: HOI-Swap exhibits controllable motion alignment: with no sampled points, the generated video diverges from the source video's motion; with full motion points, it closely mimics the source.

🔼 This figure compares HOI-Swap’s performance against three other text-guided diffusion models (Pika, Runway, and Rerender) in a video object-swapping task. The results show that HOI-Swap significantly outperforms the others by successfully swapping the object while maintaining natural hand-object interactions, unlike the other models which fail to accurately replace or reshape the object.
read the caption
Figure 15: Comparison of HOI-Swap with text-guided diffusion models: Pika [30], Runway [10], and Rerender-a-video (Rerender) [59]. To evaluate these latest models on the object swapping task, we describe the reference object in text and prompt the models to replace the original object in the video. These approaches are unable to alter the shape of the bowl and fail to swap the original bowl with a kettle as required.

🔼 This figure shows an ablation study on the impact of the number of sampled motion points on the generated video’s motion. The left side demonstrates a scenario where the objects differ significantly, and only a partial transfer of motion from the source video to the generated video is desirable; using all points leads to incorrect motion. The right side shows a scenario where the objects are similar, and full motion transfer is desired. This figure highlights HOI-Swap’s flexibility in controlling the degree of motion alignment.
read the caption
Figure 13: Ablation study of sampled motion points sparsity. The left figure illustrates a scenario where only partial motion transfer is desired, due to differences between the original and new object. The right figure showcases a scenario where full motion transfer is beneficial, owing to the similarities between the objects. We invite readers to view these examples in our project page.
More on tables

🔼 This table presents the quantitative results of video editing experiments, broken down by two different splitting methods: one by subject and the other by action. It shows the performance of several methods (Per-frame, AnyV2V, VideoSwap, and HOI-Swap) across various metrics including subject consistency, motion smoothness, contact agreement, hand agreement, and hand fidelity. The results highlight the relative strengths of each method in handling different aspects of video editing, particularly regarding temporal and spatial consistency in the context of hand-object interactions.
read the caption
Table 2: Video editing results with splitting by subject and action (Table 1 in the main paper reports results with splitting by object instances).
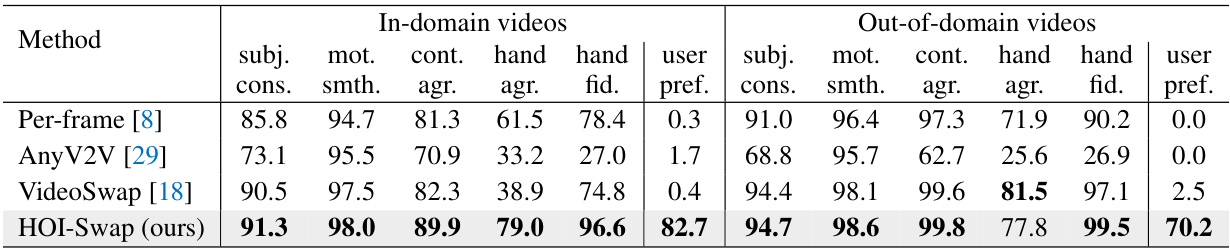
🔼 This table presents a detailed quantitative evaluation of the HOI-Swap model’s video editing performance. It breaks down the results based on whether the videos used for evaluation are from datasets that were part of the model’s training (in-domain) or not (out-of-domain). The metrics used to evaluate the performance include subject consistency, motion smoothness, contact agreement, hand agreement, hand fidelity, and user preference. The table allows for a comparison of HOI-Swap against several baseline methods, illustrating the model’s generalization capabilities across different video datasets.
read the caption
Table 3: Video editing results breakdown: in-domain videos (left) and out-of-domain videos (right).

🔼 This table presents a quantitative comparison of HOI-Swap against various baselines for both image and video editing tasks. It uses both automatic metrics (measuring aspects like hand realism, object consistency, and motion smoothness) and user preference rates from a user study. The user study involved participants choosing their preferred edits across different methods for both image and video editing scenarios.
read the caption
Table 1: Quantitative evaluation of HOI-Swap using (1) automatic metrics: contact agreement (cont. agr.), hand agreement (hand agr.), hand fidelity (hand fid.), subject consistency (subj. cons.), and motion smoothness (mot. smth.)—the last two are for video only and (2) user preference rate (user pref.) from our user study. For video editing, users were given an option to report if they found all edits unsatisfactory, which has an average selection rate of 10.9%. All values are percentages.

🔼 This table presents a comparison of the performance of the HOI-Swap model when using either DINO or CLIP encoders in stage II of the two-stage pipeline. The results show that both encoders achieve very similar performance across various video editing metrics, including subject consistency, motion smoothness, contact agreement, hand agreement, and hand fidelity. This suggests that the choice of encoder in stage II has minimal impact on the overall performance of the method.
read the caption
Table 5: Video editing results: comparison of DINO and CLIP encoders for stage II. The two object encoders yield similar performance.

🔼 This table presents a comparison of video editing results obtained using two different methods for providing object bounding box information to the model: ground truth bounding boxes and bounding boxes estimated using the Segment Anything Model (SAM-2). The table shows the performance of HOI-Swap on several video editing metrics (subject consistency, motion smoothness, contact agreement, hand agreement, and hand fidelity) using each type of input bounding box. The comparison highlights the effectiveness of using SAM-2 generated bounding boxes as a more user-friendly alternative to manually generating ground truth boxes.
read the caption
Table 6: Video editing results: comparison of using ground truth object bounding boxes vs. SAM-2 estimated ones as model input.
Full paper#