TL;DR#
Current song generation models struggle to produce high-quality songs with both vocals and instrumental accompaniment, given only lyrics. This limits real-world applications. Existing approaches often treat the song as a single entity, overlooking the complex interplay between vocals and accompaniment, leading to unnatural-sounding results and limited control over individual elements.
SongCreator addresses these limitations using a novel dual-sequence language model (DSLM) that separately models vocals and accompaniment, capturing their interactions. Attention mask strategies allow SongCreator to handle various song-related tasks (lyrics-to-song, lyrics-to-vocals, song editing). Extensive experiments demonstrate superior performance on multiple tasks, highlighting the system’s versatility and high-quality song generation abilities. The ability to independently control vocal and accompaniment acoustics showcases its potential for wider applications.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SongCreator, a novel system for universal song generation that significantly advances the state-of-the-art. Its dual-sequence language model and attention mask strategies enable high-quality song generation from various inputs (lyrics, vocals, accompaniment), opening up exciting avenues for research in music generation and AI-driven creativity. The demonstrated ability to independently control the acoustic conditions of vocals and accompaniment shows significant potential in music production.
Visual Insights#
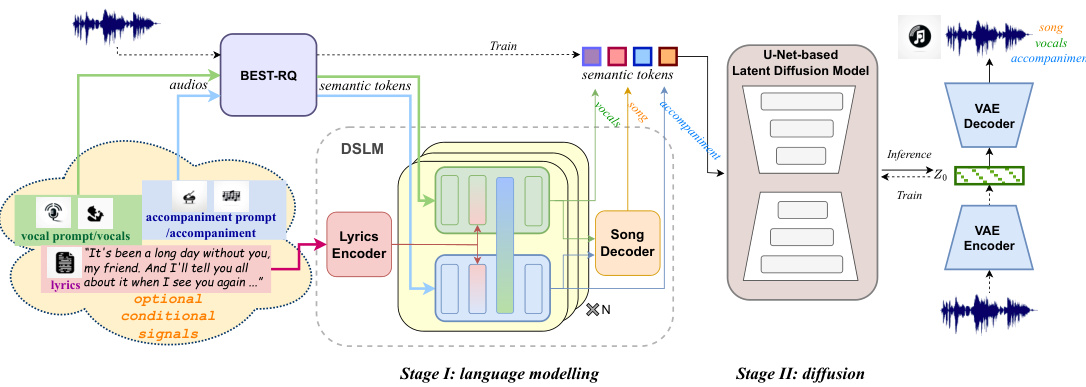
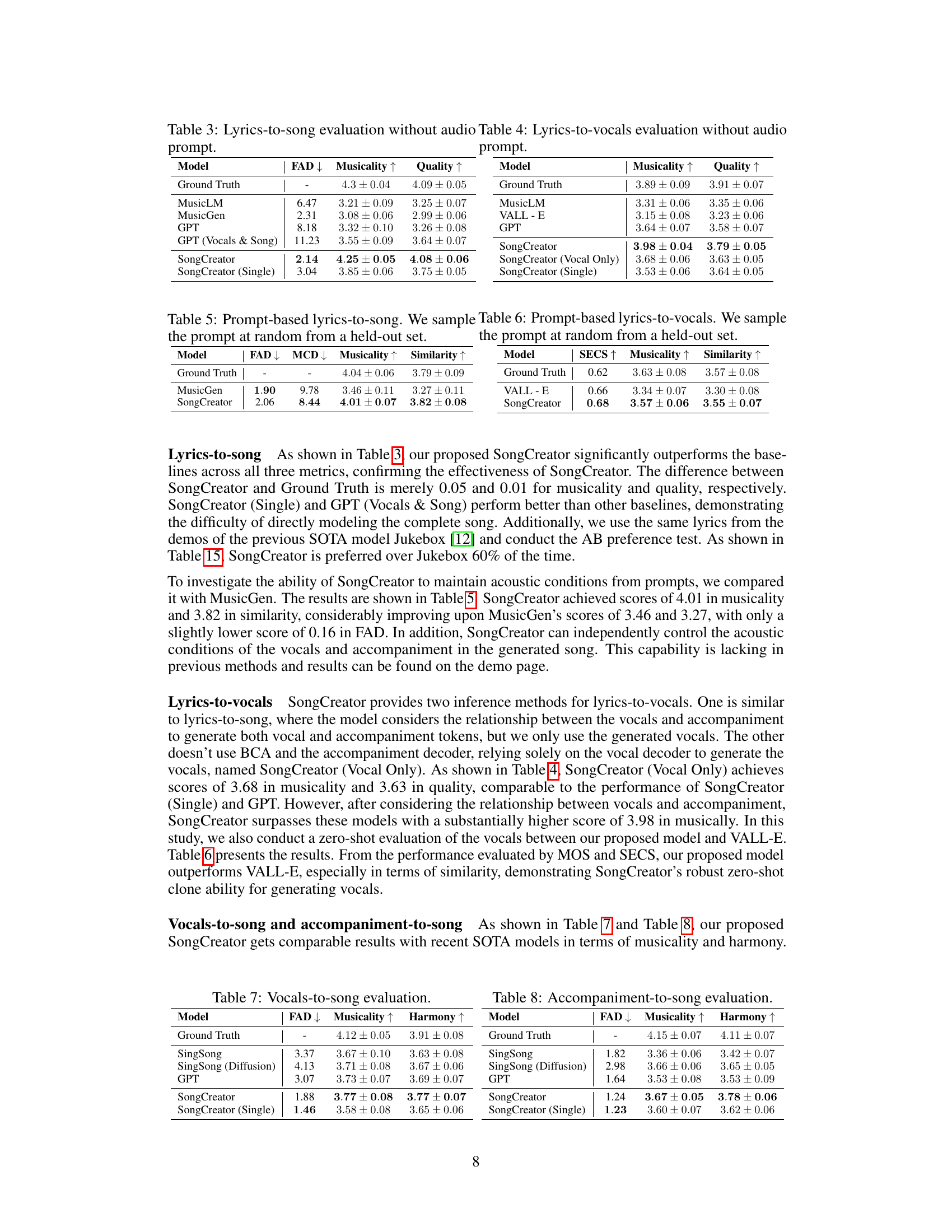
🔼 This figure illustrates the overall architecture of the SongCreator system. It shows the two main stages: a language modeling stage (Stage I) and a diffusion stage (Stage II). Stage I utilizes a dual-sequence language model (DSLM) to process lyrics and optional conditional signals (vocal prompt, accompaniment prompt, pre-determined vocal/accompaniment track) to generate semantic tokens for vocals and accompaniment. These tokens represent high-level musical information. Stage II employs a U-Net-based latent diffusion model to convert the semantic tokens into actual audio signals (song, vocals, and accompaniment). The BEST-RQ module acts as a bridge between these two stages, translating raw audio into semantic tokens and vice versa.
read the caption
Figure 1: The overview of SongCreator. The BEST-RQ tokens is a proxy that bridges the DSLM and the latent diffusion model.

🔼 This table compares song generation with related tasks like singing voice synthesis, accompaniment generation, and text-to-music generation. It shows the inputs and outputs for each task and indicates whether each model exhibits vocal composition, instrumental arrangement, and harmonious combination of vocals and accompaniment.
read the caption
Table 1: A comparison of song generation with related tasks in the literature. We use Composition to denote whether the model can complete vocal composition, Arrangement to denote whether the model can arrange the instrumental accompaniment, and Harmony to denote whether vocals and accompaniment sound harmonious and pleasant together.
In-depth insights#
Dual-Seq LM Design#
A dual-sequence language model (Dual-Seq LM) architecture presents a novel approach to music generation by processing vocal and accompaniment information in separate yet interconnected sequences. This design is crucial as it tackles the limitation of previous methods that treat vocals and accompaniment as a single entity, often resulting in unnatural or musically inconsistent output. By modeling these two sequences independently, the Dual-Seq LM enables finer-grained control and better understanding of the intricate interplay between them. This improved control allows for higher-quality and more harmonious song generation. The model’s effectiveness likely stems from its ability to capture and learn the mutual influences between vocals and accompaniment, a characteristic often neglected in simpler, monolithic models. Furthermore, the flexibility afforded by this architecture allows for diverse song generation tasks such as lyrics-to-song, lyrics-to-vocals, and accompaniment-to-song, showcasing its adaptability and versatility.
Attention Mask#
The concept of “Attention Mask” in the context of a sequence-to-sequence model for music generation is crucial for controlling information flow and task performance. Masks selectively prevent the model from attending to certain parts of the input or output sequences during training and inference. This allows for a flexible approach to various song generation tasks, such as lyrics-to-song, lyrics-to-vocals, and accompaniment generation. Different mask strategies, such as causal, non-causal, and bidirectional masks, enable the model to handle autoregressive and non-autoregressive prediction tasks. By carefully designing attention masks, the model can learn to coordinate vocals and accompaniment harmoniously, enhancing the overall quality of the generated music. The ability to selectively mask information allows for better control of the generative process, enabling functionalities like song editing and understanding. This flexibility showcases the power of attention mechanisms and masks as tools to manage complex sequential data.
Universal SongGen#
A hypothetical “Universal SongGen” system, as implied by the provided text, would represent a significant advancement in AI music generation. Its ambition is to transcend the limitations of current models, which often excel at specific tasks (like vocal synthesis or accompaniment generation) but struggle to seamlessly integrate these components into a complete and high-quality song. The key innovation seems to lie in the unified approach, moving beyond treating vocals and accompaniment as separate entities towards a model that comprehends their interplay and mutual influence. This might involve sophisticated attention mechanisms or novel neural architectures designed to capture the intricate relationships between these elements. Successful realization of such a system would have enormous implications, potentially democratizing music creation by providing a powerful tool accessible to both novice and expert musicians. A robust Universal SongGen would also need to manage complex musical elements such as rhythm, melody, harmony, and timbre, all within a cohesive and artistic whole. The successful implementation will likely involve large-scale training on diverse and high-quality datasets and probably advanced techniques for audio manipulation and generation.
Multi-task Training#
Multi-task learning, in the context of this research paper, is a crucial technique used to enhance the model’s ability to generate high-quality songs from various inputs. By training the model on multiple related tasks simultaneously, such as lyrics-to-song, lyrics-to-vocals, and accompaniment-to-song, the model learns shared representations and relationships between different aspects of music creation. This approach leads to significant improvements in overall performance, particularly in the lyrics-to-song and lyrics-to-vocals tasks. The shared representations allow the model to transfer knowledge gained from one task to improve the performance of other tasks. The results demonstrate that the multi-task training strategy surpasses single-task training methods significantly. This improvement suggests that the model has gained a more holistic and comprehensive understanding of music generation, enabling it to handle more complex and nuanced aspects of the process. The effectiveness of this strategy highlights the importance of considering the interdependencies between different musical elements, such as vocals and accompaniment, and leverages the shared structure for better overall song generation.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a song generation model, this might involve removing or disabling different modules (e.g., the lyrics encoder, vocal decoder, accompaniment decoder, bidirectional cross-attention layer, or specific attention mechanisms). Analyzing the performance drop after each ablation reveals the importance of each component. For instance, removing the bidirectional cross-attention layer might significantly degrade the harmony between vocals and accompaniment, indicating its crucial role in coordinating these elements. Similarly, ablating different attention mechanisms reveals which strategies are most effective for different tasks. The results of ablation studies demonstrate not only the contributions of individual components but also their interdependencies, offering critical insights into the model’s architecture and how the different parts work together to generate high-quality songs. These insights are invaluable for improving future models and understanding the limitations of the current design. They help identify bottlenecks and areas that require further attention or improvement, thereby guiding further research and development.
More visual insights#
More on figures
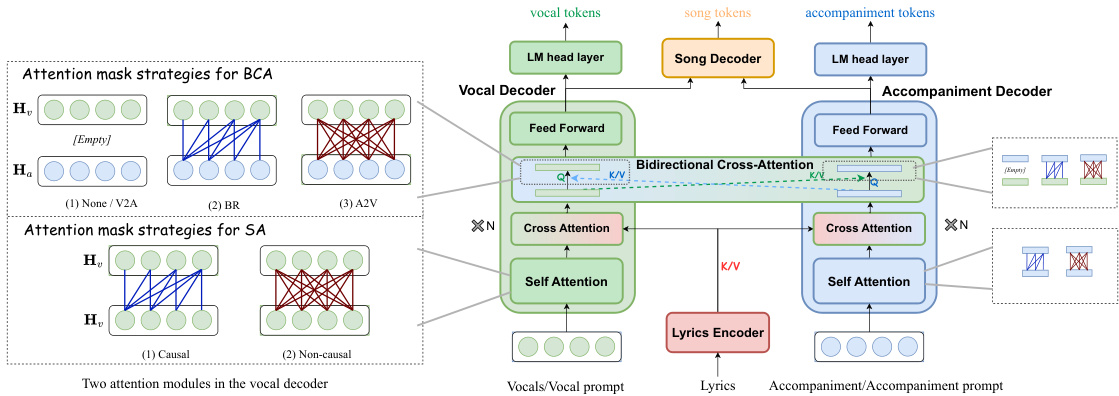
🔼 This figure illustrates the architecture of the Dual-Sequence Language Model (DSLM) which is a core component of SongCreator. The DSLM consists of three decoders: one for vocals, one for accompaniment, and one for the complete song. Each decoder utilizes self-attention and cross-attention mechanisms. Notably, a bidirectional cross-attention (BCA) layer allows interaction between the vocal and accompaniment decoders, enabling a more harmoniously coordinated output. The figure highlights various attention mask strategies used for different song generation tasks (lyrics-to-song, vocals-to-song, accompaniment-to-song, song editing, etc.). These attention masks control information flow within and between the decoders, adapting DSLM for various song-related tasks.
read the caption
Figure 2: The overview of DSLM with the attention mask strategies. The DSLM can utilize specific attention mask strategy to achieve different song generation tasks. We illustrate multiple attention mask strategies of what each vocal token's representation attend to in both self-attention and bidirectional cross-attention. Attention mask strategies in the accompaniment decoder are similar.
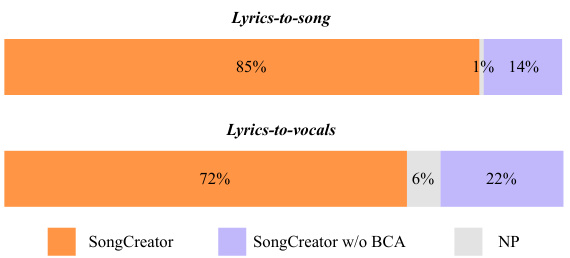
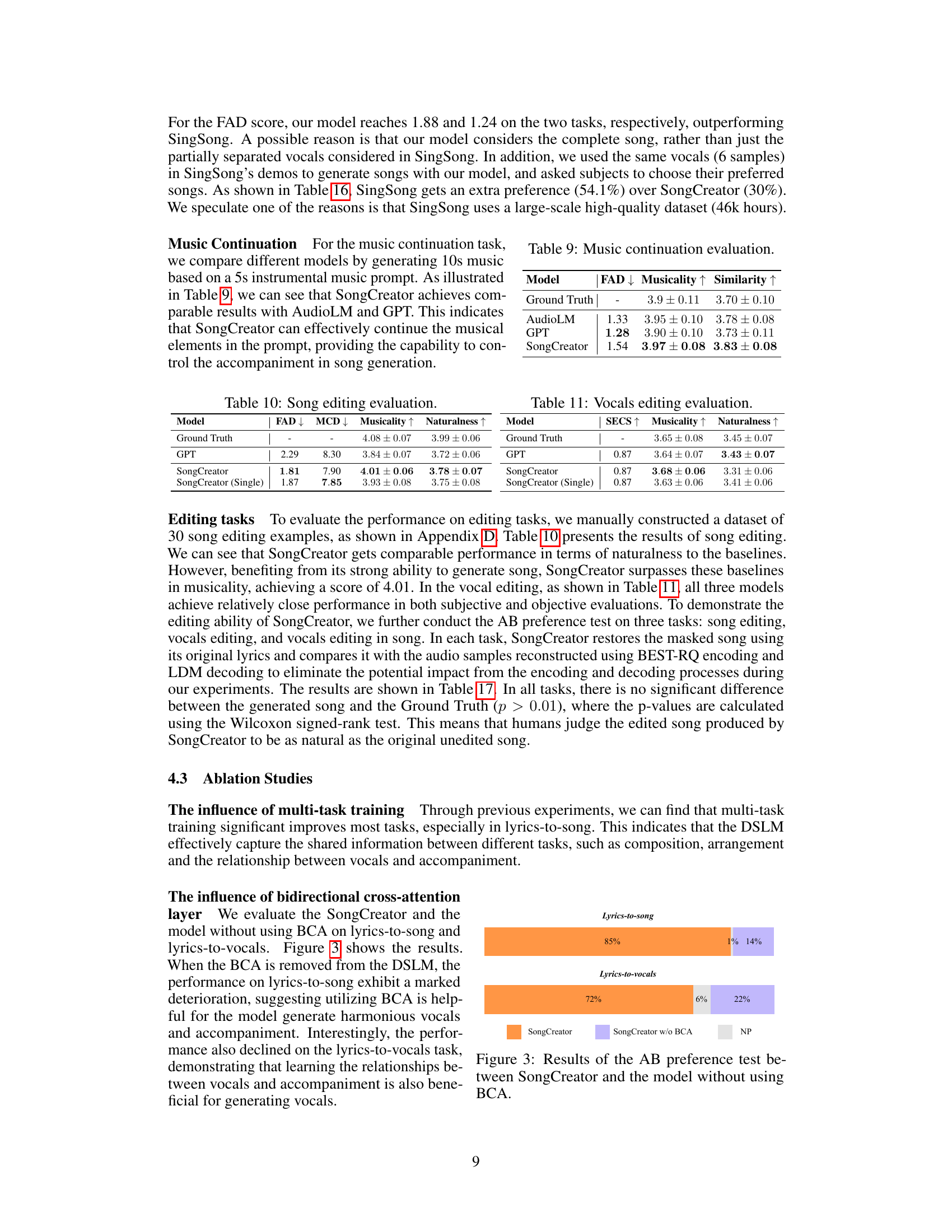
🔼 The figure shows the results of an A/B preference test comparing SongCreator’s performance to a version of the model without the Bidirectional Cross-Attention (BCA) layer. The test was performed on two tasks: lyrics-to-song and lyrics-to-vocals. The results indicate that the BCA layer significantly improves the performance of the model, especially on the lyrics-to-vocals task. SongCreator with BCA is overwhelmingly preferred in both scenarios.
read the caption
Figure 3: Results of the AB preference test between SongCreator and the model without using BCA.

🔼 This figure shows the results of an A/B preference test comparing SongCreator’s performance against a version of the model where the non-causal attention mask in the self-attention layer was disabled. The test was conducted across three tasks: lyrics-to-song, vocals-to-song, and accompaniment-to-song. The results demonstrate a significant performance decrease in all three tasks when the non-causal mask was removed, especially for the vocals-to-song task. This highlights the importance of the non-causal attention mask for capturing contextual relationships and improving generation quality.
read the caption
Figure 4: Results of the AB preference test between SongCreator and the model without using non-causal mask in SA.
🔼 This figure shows a high-level overview of the SongCreator architecture. It illustrates the data flow, starting with lyrics as input. The lyrics are then processed by a dual-sequence language model (DSLM), which generates semantic tokens for both vocals and accompaniment. These tokens are further processed by a latent diffusion model which ultimately outputs the song audio. BEST-RQ tokens act as an intermediary representation between the DSLM and the diffusion model.
read the caption
Figure 1: The overview of SongCreator. The BEST-RQ tokens is a proxy that bridges the DSLM and the latent diffusion model.

🔼 This figure shows the overall architecture of the SongCreator system. It illustrates the flow of information, starting with lyrics as input, which are then encoded using a Lyrics Encoder. This information is then passed to a Dual-Sequence Language Model (DSLM), which independently processes the vocal and accompaniment components. The DSLM outputs are converted into semantic tokens using a BEST-RQ module, which serves as a bridge to a Latent Diffusion Model (LDM). The LDM finally generates the song audio, integrating both vocals and accompaniment.
read the caption
Figure 1: The overview of SongCreator. The BEST-RQ tokens is a proxy that bridges the DSLM and the latent diffusion model.
🔼 This figure shows the overall architecture of the SongCreator model. It consists of three main stages: 1) a lyrics encoder that processes the input lyrics; 2) a dual-sequence language model (DSLM) that generates semantic tokens for both vocals and accompaniment; and 3) a latent diffusion model that converts these tokens into high-quality audio. The BEST-RQ tokens act as an intermediary representation between the DSLM and the latent diffusion model. The figure also illustrates the process of generating a song from lyrics and optionally including vocal or accompaniment prompts.
read the caption
Figure 1: The overview of SongCreator. The BEST-RQ tokens is a proxy that bridges the DSLM and the latent diffusion model.

🔼 This figure shows a high-level overview of the SongCreator architecture, illustrating the flow of information from lyrics input to the final generated song audio. The lyrics are first processed by a lyrics encoder, then fed into a dual-sequence language model (DSLM) which generates semantic tokens representing vocals and accompaniment separately. These tokens are then converted to audio using a latent diffusion model (LDM) with the help of BEST-RQ which acts as a bridge between the DSLM and LDM. The figure also shows the optional addition of vocal and accompaniment prompts to control the characteristics of the generated audio.
read the caption
Figure 1: The overview of SongCreator. The BEST-RQ tokens is a proxy that bridges the DSLM and the latent diffusion model.
🔼 This figure shows the overall architecture of SongCreator, a lyrics-based universal song generation system. It details the two main stages: language modeling and diffusion. The language modeling stage uses a dual-sequence language model (DSLM) to process lyrics and generate semantic tokens for both vocals and accompaniment. These tokens are then fed into a latent diffusion model (LDM), which uses a variational autoencoder (VAE) and a U-Net to generate the final audio. BEST-RQ tokens act as an intermediary representation between the DSLM and the LDM.
read the caption
Figure 1: The overview of SongCreator. The BEST-RQ tokens is a proxy that bridges the DSLM and the latent diffusion model.
🔼 This figure illustrates the architecture of SongCreator, a lyrics-based universal song generation system. It shows the main components: a lyrics encoder, a dual-sequence language model (DSLM) with separate decoders for vocals and accompaniment, and a latent diffusion model (LDM) for audio generation. The BEST-RQ tokens act as an intermediary representation between the DSLM’s textual outputs and the LDM’s audio generation process. The diagram also shows the flow of information, from lyrics input to final song audio output, including optional conditional signals such as vocal and accompaniment prompts.
read the caption
Figure 1: The overview of SongCreator. The BEST-RQ tokens is a proxy that bridges the DSLM and the latent diffusion model.
🔼 This figure shows the overall architecture of the SongCreator model. It illustrates the process of song generation, starting with lyrics as input. The lyrics are encoded, and then a dual-sequence language model (DSLM) processes the information to generate semantic tokens for both vocals and accompaniment. These tokens are then fed into a latent diffusion model that outputs the final song audio. BEST-RQ tokens act as an intermediary representation between the DSLM and the diffusion model.
read the caption
Figure 1: The overview of SongCreator. The BEST-RQ tokens is a proxy that bridges the DSLM and the latent diffusion model.
More on tables
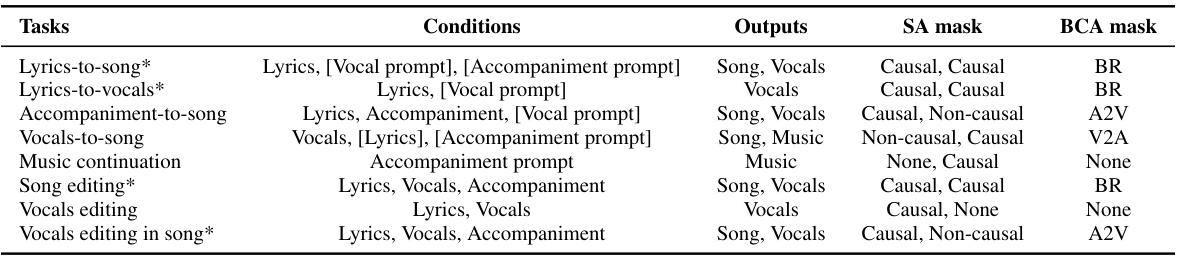
🔼 This table lists the eight tasks supported by the SongCreator model, showing the input conditions, output types, and the attention mask strategies (self-attention and bidirectional cross-attention) used for each task. The * indicates tasks where SongCreator shows significant improvement over previous state-of-the-art methods. Square brackets around conditions indicate optional inputs.
read the caption
Table 2: Specific attention mask strategy of all tasks supported by SongCreator. [·] indicates that the condition is optional. * indicates that our proposed model achieves significant improvements in this task.

🔼 This table presents the results of the lyrics-to-song task without using any audio prompts. It compares the performance of SongCreator with several baseline models across three metrics: FAD (Fréchet Audio Distance), Musicality (MOS score), and Quality (MOS score). Lower FAD indicates better generation fidelity, while higher Musicality and Quality scores represent better subjective evaluations. The results show that SongCreator outperforms the baseline models in both musicality and quality.
read the caption
Table 3: Lyrics-to-song evaluation without audio prompt.
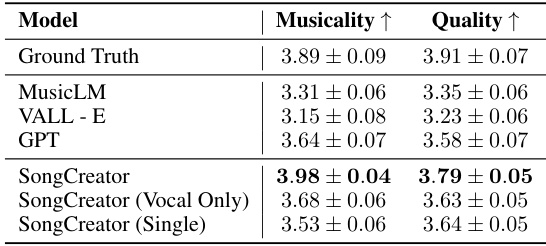
🔼 This table presents the results of the lyrics-to-vocals task without using any audio prompts. It compares the performance of SongCreator and several baselines, including MusicLM and VALL-E, across three evaluation metrics: Musicality, Quality, and Similarity. SongCreator demonstrates superior performance across all three metrics compared to the baselines.
read the caption
Table 4: Lyrics-to-vocals evaluation without audio prompt.

🔼 This table presents the results of a prompt-based lyrics-to-vocals experiment. The model generated vocals using prompts randomly selected from a held-out set. The results are evaluated using SECS (Speaker Embedding Cosine Similarity), Musicality (MOS score), and Similarity (MOS score). The metrics assess the quality of the generated vocals in terms of speaker similarity, musicality, and overall similarity to reference vocals.
read the caption
Table 6: Prompt-based lyrics-to-vocals. We sample the prompt at random from a held-out set.

🔼 This table presents the results of a prompt-based lyrics-to-song generation task. The model was evaluated using FAD (Fréchet Audio Distance), MCD (Mel-Cepstral Distortion), Musicality (MOS), and Similarity (MOS) metrics. The prompt was randomly selected from a held-out set to assess the model’s ability to generate songs with varied acoustic conditions based on the provided prompt.
read the caption
Table 5: Prompt-based lyrics-to-song. We sample the prompt at random from a held-out set.

🔼 This table presents the results of the Vocals-to-song task, comparing SongCreator against several baselines. Metrics include FAD (Fréchet Audio Distance), Musicality (MOS score), and Harmony (MOS score). The table helps demonstrate SongCreator’s performance compared to existing methods when generating a song from an input vocal track.
read the caption
Table 7: Vocals-to-song evaluation.
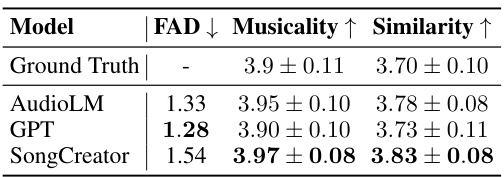
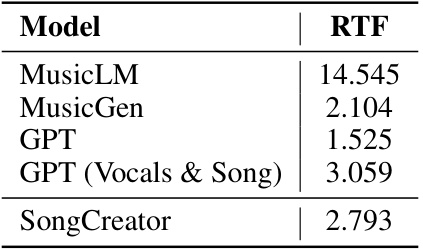
🔼 This table presents the results of the music continuation evaluation. Three models, AudioLM, GPT, and SongCreator, are evaluated using three metrics: FAD (Fréchet Audio Distance), Musicality (MOS score), and Similarity (MOS score). Lower FAD indicates better fidelity, while higher Musicality and Similarity scores indicate better performance. The results show that SongCreator achieves competitive performance with state-of-the-art models in music continuation.
read the caption
Table 9: Music continuation evaluation.

🔼 This table compares different music generation tasks based on their inputs and outputs, focusing on whether each task involves vocal composition, instrumental arrangement, and the harmonious integration of vocals and accompaniment. It helps to illustrate the unique contribution of the SongCreator model, which aims to achieve all three aspects simultaneously.
read the caption
Table 1: A comparison of song generation with related tasks in the literature. We use Composition to denote whether the model can complete vocal composition, Arrangement to denote whether the model can arrange the instrumental accompaniment, and Harmony to denote whether vocals and accompaniment sound harmonious and pleasant together.
🔼 This table compares the capabilities of different song generation approaches and related tasks, focusing on whether they can perform vocal composition, instrumental arrangement, and harmonious vocal and accompaniment generation. It highlights the unique challenge of generating songs with both vocals and accompaniment given only lyrics as input.
read the caption
Table 1: A comparison of song generation with related tasks in the literature. We use Composition to denote whether the model can complete vocal composition, Arrangement to denote whether the model can arrange the instrumental accompaniment, and Harmony to denote whether vocals and accompaniment sound harmonious and pleasant together.

🔼 This table presents a comparison of the performance of various semantic tokenizers in reconstructing music. The models used were HuBERT, MERT, MusicFM, and BEST-RQ. The evaluation metric used was ViSQOL, which measures the quality of the reconstructed audio. BEST-RQ shows the best performance, suggesting it is a better choice for music reconstruction.
read the caption
Table 13: Reconstructed music performance results for different semantic tokenizers.
🔼 This table compares different music generation tasks, including singing voice synthesis, song composition, text-to-music, accompaniment generation, and the complete song generation task. For each task, it lists the input, output, and whether the model can complete vocal composition, instrumental arrangement, and achieve harmonious vocals and accompaniment. The table highlights that while previous work has tackled aspects of song generation, the complete generation of songs with both vocals and accompaniment from lyrics remained a significant challenge before SongCreator.
read the caption
Table 1: A comparison of song generation with related tasks in the literature. We use Composition to denote whether the model can complete vocal composition, Arrangement to denote whether the model can arrange the instrumental accompaniment, and Harmony to denote whether vocals and accompaniment sound harmonious and pleasant together.

🔼 This table presents the results of an A/B preference test comparing the song generation quality of SongCreator and Jukebox. Participants were asked to choose their preferred song based on overall quality. The results show that SongCreator was preferred in 60% of comparisons, while Jukebox was preferred in 38.5%, and 1.5% showed no preference.
read the caption
Table 15: Results of the AB preference test between SongCreator and Jukebox in lyrics-to-song. N/P denotes “no preference”.
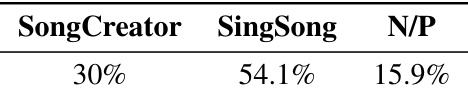
🔼 This table presents the results of an A/B preference test comparing the quality of vocal generation between SongCreator and Singsong. Participants were asked to choose their preferred song based on overall quality. The results show that Singsong was preferred by a significant margin (54.1%) compared to SongCreator (30%), with only a small percentage (15.9%) indicating no preference.
read the caption
Table 16: Results of the AB preference test between SongCreator and Singsong in vocals-to-song. N/P denotes 'no preference'.

🔼 This table shows the specific attention mask strategies used for each of the eight tasks supported by SongCreator. It details the attention masking approach used for both self-attention (SA) and bidirectional cross-attention (BCA) layers within the model for vocals and accompaniment generation. The table clarifies which masking strategy (causal, non-causal, bidirectional, accompaniment-to-vocal (A2V), or vocal-to-accompaniment (V2A)) is employed for each layer in each task, highlighting tasks where SongCreator shows significant improvement over previous works.
read the caption
Table 2: Specific attention mask strategy of all tasks supported by SongCreator. [·] indicates that the condition is optional. * indicates that our proposed model achieves significant improvements in this task.
🔼 This table shows the different attention mask strategies used by SongCreator for eight different song generation tasks. For each task, it specifies the input conditions (lyrics, vocal prompt, accompaniment prompt, etc.), the output (song, vocals, etc.), and the attention mask strategies used in the self-attention (SA) and bidirectional cross-attention (BCA) layers of the model. The SA mask can be either causal (only attending to previous tokens) or non-causal (attending to all tokens). The BCA mask options include Bidirectional (BR), Accompaniment-to-Vocals (A2V), Vocals-to-Accompaniment (V2A), and None (no cross-attention). The table highlights the tasks where SongCreator achieved state-of-the-art or significantly improved results.
read the caption
Table 2: Specific attention mask strategy of all tasks supported by SongCreator. [·] indicates that the condition is optional. * indicates that our proposed model achieves significant improvements in this task.

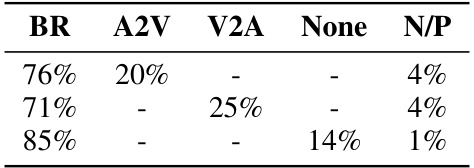
🔼 This table presents the results of an A/B preference test comparing different attention mask strategies used in the bidirectional cross-attention (BCA) layer of the SongCreator model for the accompaniment-to-song generation task. The test shows the percentage of participants who preferred each strategy (BR, A2V) or had no preference (N/P). The A2V strategy, allowing the vocal decoder to attend to the entire accompaniment sequence, was significantly preferred.
read the caption
Table 19: Results of the AB preference test for using different attention mask strategies in BAC on the Accompaniment-to-song task.
🔼 This table shows the attention mask strategies used by SongCreator for various song generation tasks, including lyrics-to-song, lyrics-to-vocals, accompaniment-to-song, vocals-to-song, music continuation, song editing, vocals editing, and vocals editing in song. It details the specific mask strategies (SA mask and BCA mask) employed for each task, indicating whether a causal, non-causal, bidirectional, or no mask is used for self-attention (SA) and bidirectional cross-attention (BCA) layers. The optional conditions for each task are also listed, along with an indication of significant performance improvements achieved by the model (*).
read the caption
Table 2: Specific attention mask strategy of all tasks supported by SongCreator. [·] indicates that the condition is optional. * indicates that our proposed model achieves significant improvements in this task.
Full paper#