TL;DR#
Current large language model (LLM) benchmarks primarily focus on final answer accuracy, neglecting the intricacies of the reasoning process. This limitation hinders effective evaluation of LLMs’ true reasoning capabilities and progress tracking. This paper addresses this issue by introducing MR-Ben, a novel benchmark demanding meta-reasoning skills. MR-Ben requires LLMs to not only solve problems but also to identify and analyze potential errors in automatically generated reasoning steps, mimicking human ‘System-2’ thinking.
MR-Ben consists of 5,975 questions across various subjects. Evaluation using MR-Ben reveals interesting limitations and weaknesses in current LLMs, both open-source and closed-source. While some models excel at scrutinizing solutions, many others lag significantly, pointing to potential shortcomings in training and inference strategies. The findings highlight the need for improved training methodologies and a shift towards more process-oriented evaluation of LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for advancing LLM evaluation beyond simple accuracy metrics. It introduces a novel meta-reasoning benchmark, MR-Ben, enabling a more nuanced understanding of LLM reasoning capabilities and identifying crucial weaknesses in current models. This work paves the way for improved training strategies and more robust AI systems.
Visual Insights#

🔼 This figure illustrates the MR-Ben evaluation paradigm. Each data point includes a question, a Chain-of-Thought (CoT) answer generated by LLMs, and a human-annotated error analysis. The error analysis details the erroneous step, reason for the error, and the correction. Three example questions are shown representing arithmetic, logical, and algorithmic reasoning tasks. This visualization demonstrates the process-based nature of the MR-Ben benchmark, focusing on evaluating the quality of the reasoning process rather than just the final answer.
read the caption
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.

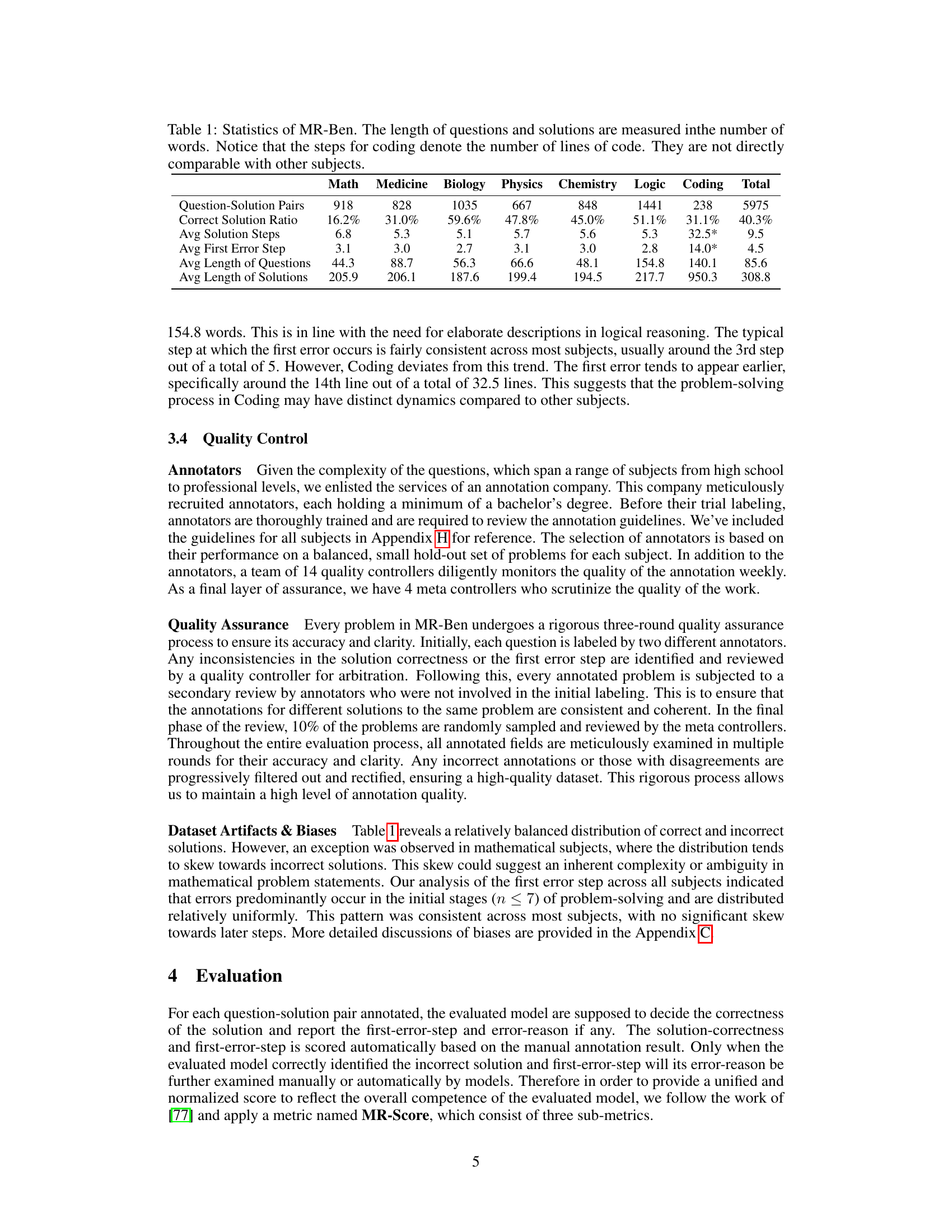
🔼 This table presents the statistics of the MR-Ben benchmark dataset. It shows the number of question-solution pairs, the percentage of correctly solved questions, the average number of steps in the solutions, the average step number where the first error occurs, and the average length (in words) of the questions and solutions for each subject (Math, Medicine, Biology, Physics, Chemistry, Logic, and Coding). The table highlights the relative difficulty of different subjects, noting that coding problems have significantly more steps and a different average length compared to other subjects.
read the caption
Table 1: Statistics of MR-Ben. The length of questions and solutions are measured in the number of words. Notice that the steps for coding denote the number of lines of code. They are not directly comparable with other subjects.
In-depth insights#
Meta-Reasoning#
Meta-reasoning, the ability to reason about reasoning, is a crucial aspect of higher-order cognition. In the context of large language models (LLMs), meta-reasoning signifies the capacity to not only produce an answer but also to analyze the reasoning process that led to it. This involves identifying potential errors, evaluating the validity of assumptions, and correcting flawed steps. The significance of meta-reasoning in LLMs lies in its potential to address the limitations of existing outcome-based evaluation metrics. These metrics primarily assess the correctness of the final answer, often overlooking the intricacies of the reasoning process. Meta-reasoning benchmarks, therefore, offer a more nuanced and comprehensive evaluation of LLMs’ reasoning abilities by focusing on the quality of the reasoning process itself. They aim to foster the development of models that not only generate correct answers but also provide robust and reliable explanations. Current meta-reasoning benchmarks, however, face challenges in terms of scope, size, and diversity of reasoning tasks, underscoring the need for continuous improvement and expansion in the field.
Benchmark Design#
A robust benchmark design is crucial for evaluating complex reasoning abilities in LLMs. It should carefully consider the types of reasoning being assessed (e.g., arithmetic, logical, common sense), ensuring a diverse and representative range of problems across different difficulty levels. The benchmark’s design should prioritize process-based evaluation rather than solely focusing on the final outcome to gain insights into the model’s reasoning process. This requires detailed annotations that provide insights into not only the answer but also the steps and justifications leading to it. Meta-reasoning tasks, where LLMs are asked to analyze and correct their own reasoning, offer a particularly powerful way to assess higher-order cognitive skills. The benchmark’s structure should also ensure scalability to accommodate the continual evolution of LLMs and the emergence of more sophisticated reasoning capabilities. A well-designed benchmark facilitates the identification of specific weaknesses in LLMs, paving the way for targeted improvements in model training and inference methodologies.
LLM Evaluation#
LLM evaluation is a rapidly evolving field, crucial for understanding and improving large language models. Current methods often focus on outcome-based metrics, such as accuracy on specific tasks, which can be limiting. A more holistic approach is needed, encompassing process-based evaluations that examine the reasoning steps leading to the final answer. This allows for the identification of errors and biases that may not be apparent from the outcome alone. Meta-reasoning benchmarks which involve assessing the models’ capacity to identify and correct errors in automatically-generated reasoning, are increasingly important tools. They reveal limitations in current LLMs’ abilities to critically examine assumptions, calculations, and logical steps. Creating datasets that assess reasoning across a wide range of subjects and difficulty levels is also critical for developing more robust and versatile LLMs. Future evaluation methods should incorporate intrinsic measures of reasoning quality, in addition to outcome-based metrics, to provide a more comprehensive assessment of LLM capabilities.
Future Directions#
Future research directions stemming from this work could involve expanding the MR-Ben benchmark to encompass a wider array of reasoning types and subjects. Incorporating more diverse question formats and reasoning paradigms beyond the current scope would enhance its robustness and generalizability. Further investigation into the specific training and inference methodologies that contribute to strong meta-reasoning performance is warranted. Analyzing the influence of dataset composition and characteristics—such as the inclusion of synthetic data—on model meta-reasoning abilities should be explored. Furthermore, research into novel evaluation metrics that are more sensitive to nuances in the reasoning process, potentially complementing or replacing MR-Score, is necessary. Exploring the potential of interactive evaluation where LLMs can clarify their reasoning or ask clarifying questions, could offer new insights into LLM reasoning capabilities. Finally, a cross-lingual extension of the MR-Ben benchmark to facilitate a more comprehensive understanding of meta-reasoning across diverse linguistic contexts is a valuable future direction.
Limitations#
A critical analysis of the limitations section in a research paper is crucial for a comprehensive understanding. Identifying limitations demonstrates the researcher’s self-awareness and commitment to scientific rigor. It enhances the paper’s credibility by acknowledging potential weaknesses and uncertainties, rather than presenting a purely positive view of the findings. The discussion should explicitly address methodological limitations, such as sample size, data collection methods, or the chosen analytical techniques. It must also discuss limitations in scope, generalizability, or the potential for bias. The exploration should also consider the practical implications of the limitations, and explain how these limitations affect the interpretation of the results. Finally, a robust limitations section often proposes avenues for future research, suggesting how subsequent studies might address the identified shortcomings and build upon the current findings. This proactive approach not only strengthens the immediate contribution but also guides the direction of future inquiry within the field.
More visual insights#
More on figures

🔼 This radar chart visualizes the performance of several LLMs across different reasoning subjects, including math, medicine, biology, chemistry, logic, and coding. Each axis represents a subject, and the distance from the center indicates the model’s performance (MR-Score) on that subject. The chart allows for a comparison of the strengths and weaknesses of different models across various reasoning domains. The overlapping areas show where models have comparable performances, while distinct separation indicates performance differences.
read the caption
Figure 2: Model performance across subjects
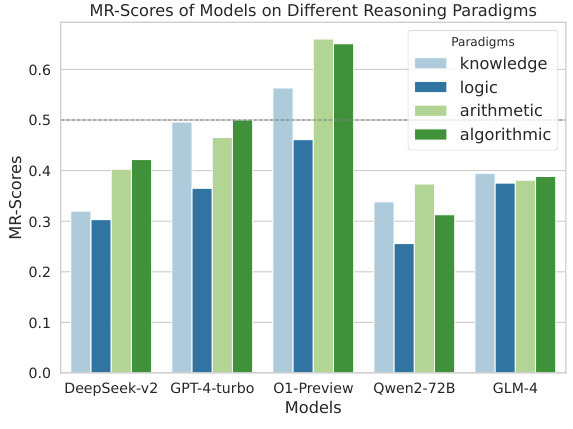
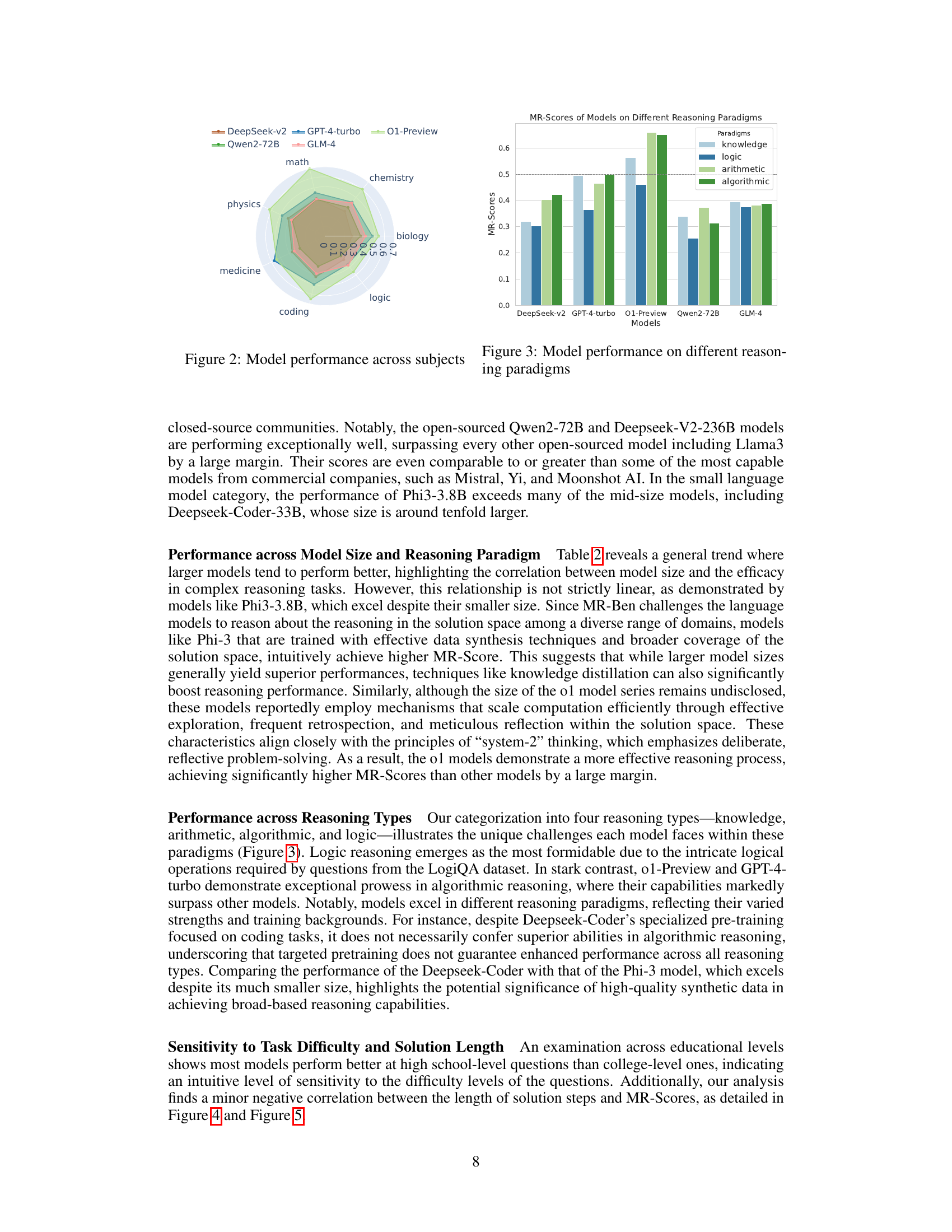
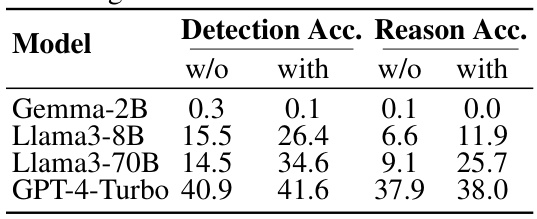
🔼 This figure presents a bar chart that compares the performance of several large language models (LLMs) across four different reasoning paradigms: knowledge, logic, arithmetic, and algorithmic. Each bar represents the MR-Score achieved by a specific LLM in each reasoning paradigm. The height of the bar indicates the performance level, allowing for a direct comparison of model capabilities in various reasoning tasks. The MR-Score, explained in section 4 of the paper, is a composite metric integrating accuracy in identifying correct solutions, pinpointing the first incorrect reasoning step, and providing accurate error explanations.
read the caption
Figure 3: Model performance on different reasoning paradigms
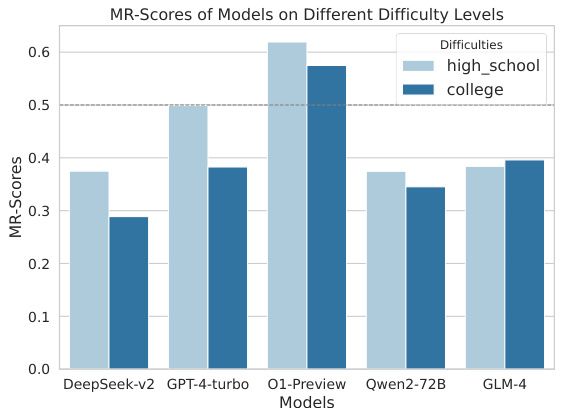
🔼 This figure displays the MR-Scores achieved by various LLMs on questions of different difficulty levels (high school vs. college). It visually represents the performance difference of the models on questions with varying complexities. The horizontal dashed line indicates a benchmark score of 0.5, providing a visual reference point to compare model performance against.
read the caption
Figure 4: MR-Scores of different models on different levels of difficulty
🔼 This figure visualizes the performance of different LLMs across various subjects in the MR-Ben benchmark. Each bar represents a model’s MR-Score (a metric combining solution correctness, first error step accuracy, and error reason accuracy) for a specific subject. The subjects included are likely math, medicine, biology, physics, chemistry, logic, and coding, as mentioned in the paper. The figure helps to illustrate the relative strengths and weaknesses of each model across different reasoning domains and shows the variation in performance of LLMs depending on the subject matter.
read the caption
Figure 2: Model performance across subjects

🔼 This figure illustrates the three key components of the MR-Ben dataset: question, chain-of-thought (CoT) answer, and error analysis. The CoT answers are generated automatically by various LLMs and then human experts annotate each example, providing an error analysis that includes the step where the error occurs, the reason for the error, and the correction. The figure uses three example questions to showcase how this works for arithmetic, logical, and algorithmic reasoning.
read the caption
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.
🔼 This figure illustrates the meta-reasoning paradigm used in the MR-Ben benchmark. It shows how each data point in the benchmark consists of three parts: a question, a Chain-of-Thought (CoT) answer generated by an LLM, and a human-expert-provided error analysis. The error analysis details the step where the error occurred, the reason for the error, and the correction. Three examples are given to showcase how the paradigm applies to different reasoning types: arithmetic, logical, and algorithmic.
read the caption
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.
🔼 This figure illustrates the meta-reasoning paradigm used in the MR-Ben benchmark. It shows three examples of questions, each with a chain-of-thought (CoT) answer generated by an LLM and a corresponding error analysis provided by human experts. The error analyses identify the specific erroneous steps, explain the reasons behind the errors, and provide corrections. The three examples showcase the diversity of reasoning types covered by MR-Ben: arithmetic, logical, and algorithmic reasoning.
read the caption
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.

🔼 This figure illustrates the meta-reasoning paradigm used in the MR-Ben benchmark. Each data point consists of a question, a Chain-of-Thought (CoT) answer generated by an LLM, and a human-annotated error analysis. The error analysis details the erroneous steps in the CoT answer, explains the reasons for the errors, and provides corrections. The figure presents three examples showcasing the application of this paradigm to arithmetic, logical, and algorithmic reasoning problems, demonstrating the benchmark’s comprehensive evaluation of reasoning capabilities across diverse domains.
read the caption
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.

🔼 This figure illustrates the meta-reasoning paradigm used in the MR-Ben benchmark. It shows how each data point contains a question, a Chain-of-Thought (CoT) answer generated by LLMs, and a human-annotated error analysis. The error analysis details the erroneous steps, reasons for the errors, and the necessary corrections. Three example questions are provided to showcase arithmetic, logical, and algorithmic reasoning.
read the caption
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.

🔼 This figure illustrates the meta-reasoning paradigm used in the MR-Ben benchmark. It shows that each data point includes a question, a Chain-of-Thought (CoT) solution generated by an LLM, and a human-annotated error analysis. The error analysis details the incorrect steps in the reasoning, the reasons for the errors, and the corrections. The three examples highlight the diversity of reasoning types covered by the benchmark: arithmetic, logical, and algorithmic reasoning.
read the caption
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.
🔼 This figure illustrates the meta-reasoning paradigm used in the MR-Ben benchmark. Each data point contains a question, a Chain-of-Thought (CoT) answer generated by an LLM, and a human-annotated error analysis. The error analysis details the erroneous step, reason for the error, and correction. Three examples are shown representing arithmetic, logical, and algorithmic reasoning question types. This visually represents how the benchmark goes beyond simply evaluating the correctness of the answer, instead focusing on the reasoning process itself.
read the caption
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.

🔼 This figure illustrates the meta-reasoning paradigm used in the MR-Ben benchmark. Each data point shows a question, a Chain-of-Thought (CoT) answer generated by an LLM, and a human-provided error analysis. The error analysis identifies the incorrect step(s) in the CoT answer, explains the reason for the error(s), and provides corrections. The three examples showcase arithmetic, logical, and algorithmic reasoning types, demonstrating the diverse range of reasoning skills assessed by the benchmark.
read the caption
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.
More on tables
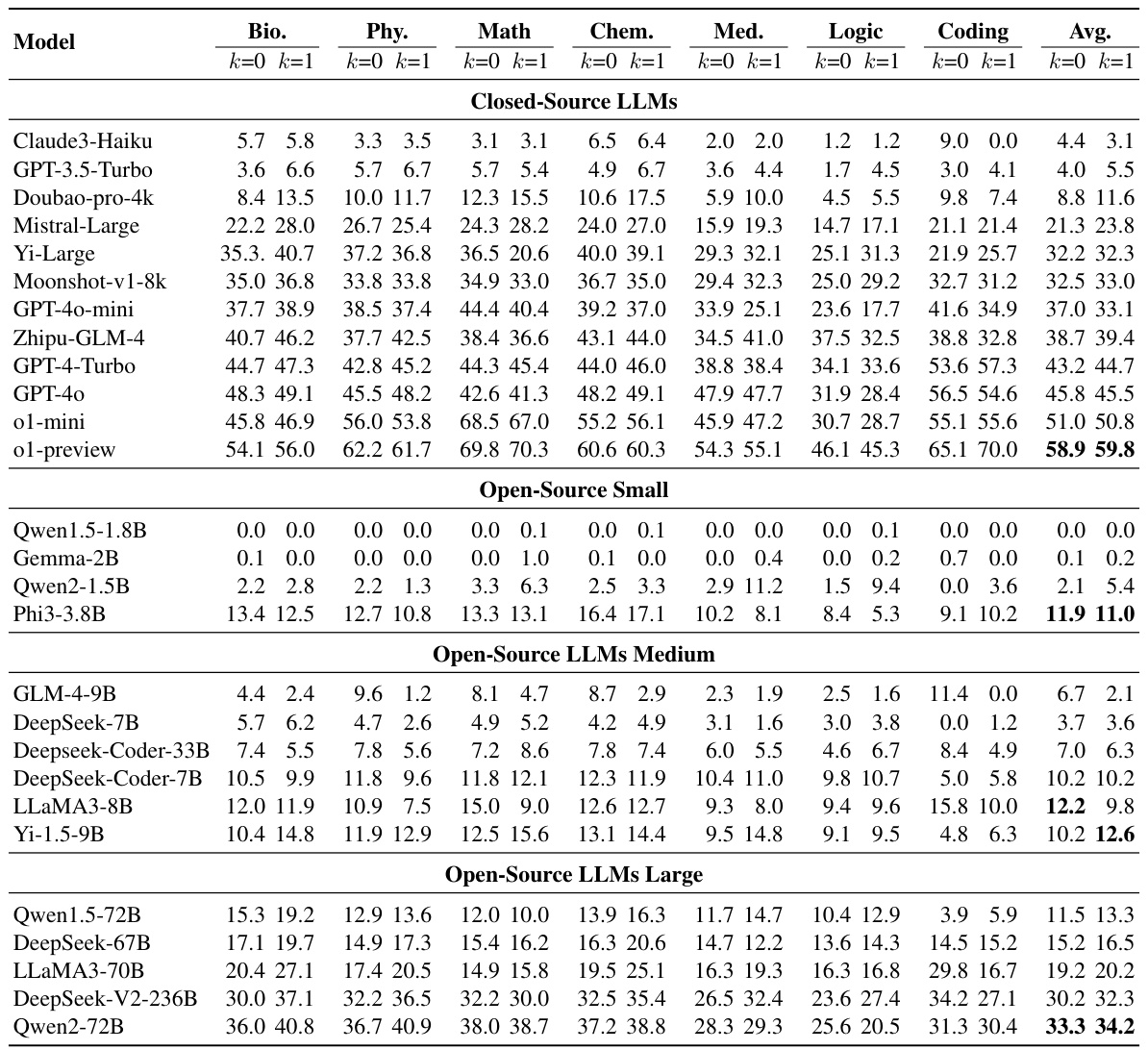
🔼 This table shows the performance of various large language models (LLMs) on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which takes into account the correctness of the solution, the accuracy of identifying the first error step, and the accuracy of explaining the error reason. The table breaks down the results by subject area (Math, Medicine, Biology, Physics, Chemistry, Logic, Coding) and also shows results with different numbers of demonstration examples (k=0 and k=1). The table compares both closed-source and open-source LLMs.
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model's performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.
🔼 This table shows the performance of various large language models (LLMs) on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which incorporates multiple aspects of reasoning ability. The table breaks down the results by subject area (Biology, Physics, Math, Chemistry, Medicine, Logic, Coding) and by the number of demonstration examples (k=0 and k=1, representing zero-shot and one-shot settings, respectively). This allows for a comparison of model performance both across subjects and across prompting strategies.
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model's performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.

🔼 This table shows the performance of various large language models (LLMs) on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which considers solution correctness, accuracy in identifying the first error step, and accuracy in explaining the error reason. The table breaks down the results by subject area (Biology, Physics, Math, Chemistry, Medicine, Logic, Coding) and indicates the model’s performance with zero and one demonstration examples (k=0 and k=1, respectively). This allows for a comparison of model performance across different reasoning types and levels of difficulty, highlighting strengths and weaknesses in different LLMs.
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model's performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.

🔼 This table shows the performance of various large language models (LLMs) on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which considers solution correctness, accuracy in identifying the first error step, and the accuracy of the explanation of that error. The table breaks down the results across different subjects (Biology, Physics, Mathematics, Chemistry, Medicine, Logic, and Coding). The ‘k’ values in the column headers indicate the number of demonstration examples used for few-shot prompting. The results highlight the performance differences across models and subjects, revealing strengths and weaknesses of each model in various reasoning tasks.
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model's performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.

🔼 This table shows the performance of various LLMs on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which considers solution correctness, accuracy in identifying the first error step, and accuracy of the error reason explanation. The table breaks down the results by subject area (Biology, Physics, Math, Chemistry, Medicine, Logic, Coding), showing the MR-Score for each model in each subject with and without demonstration examples (k=0 and k=1). The models are categorized into closed-source and open-source LLMs and further sub-categorized by size (small, medium, large).
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model's performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.
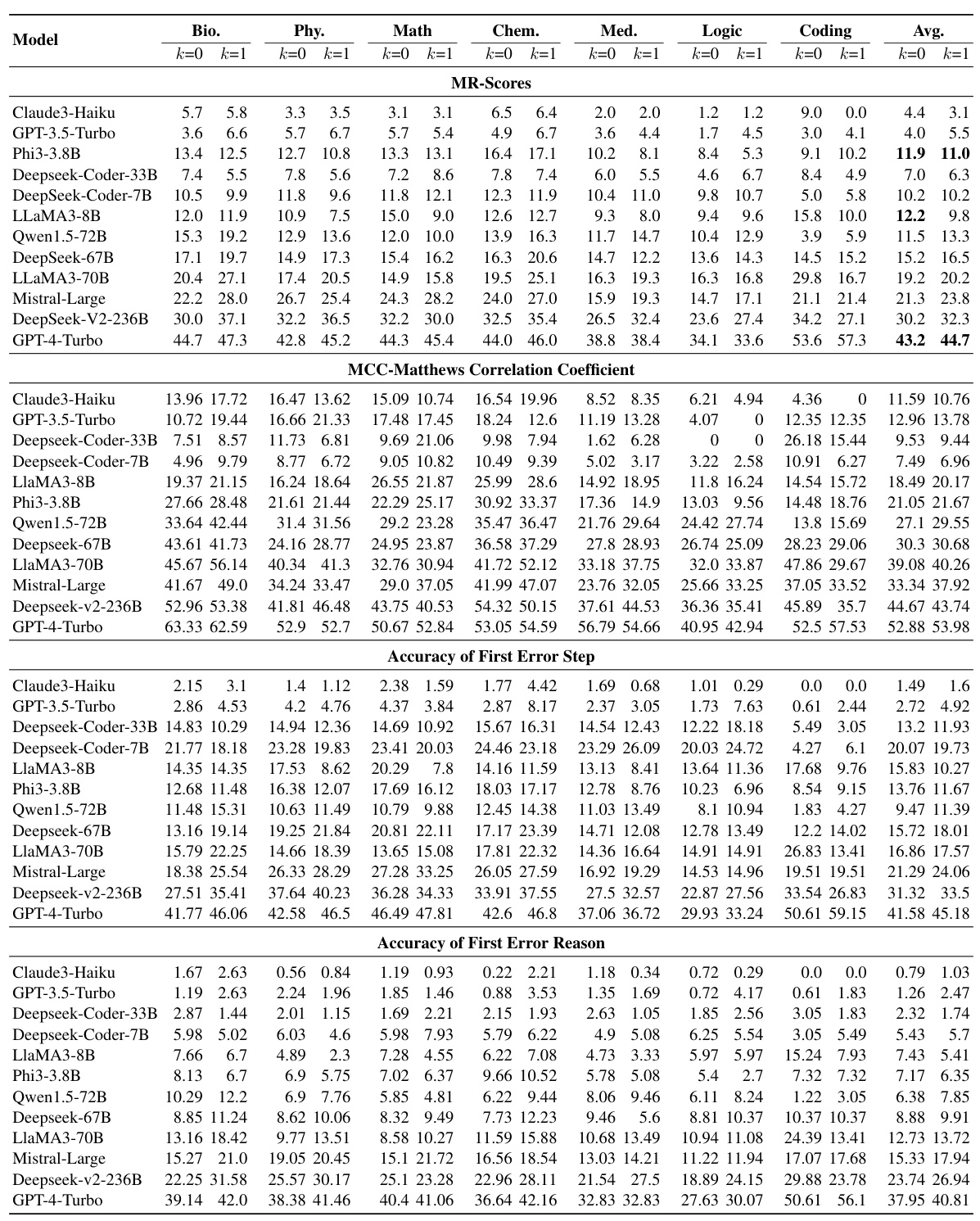
🔼 This table shows the performance of various LLMs on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which considers solution correctness, first error step accuracy, and error reason accuracy. The table breaks down the results by subject area (Biology, Physics, Math, Chemistry, Medicine, Logic, Coding) and indicates the MR-Score for each model under different numbers of demonstration examples (k). It provides a comparison of both open-source and closed-source LLMs.
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model’s performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.
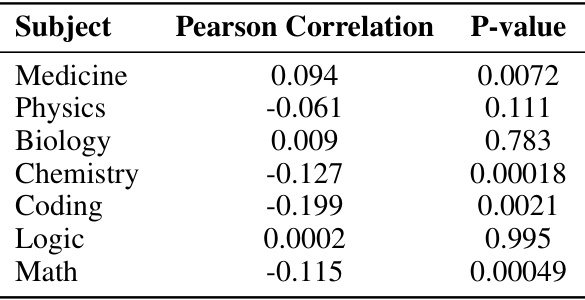
🔼 This table presents the performance of various LLMs on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which incorporates three sub-metrics (Matthews Correlation Coefficient for solution correctness, accuracy of locating the first error step, and accuracy of the error reason). The table shows a detailed breakdown of each model’s performance across different subjects (Math, Medicine, Biology, Physics, Chemistry, Logic, Coding). The ‘k’ values represent the number of demonstration examples used in few-shot settings.
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model's performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.

🔼 This table shows the performance of various large language models (LLMs) on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which combines several sub-metrics to evaluate different aspects of reasoning ability. The table breaks down the results across different subjects (Biology, Physics, Math, Chemistry, Medicine, Logic, Coding) and for different numbers of demonstration examples (k=0, k=1). The models are categorized into closed-source and open-source LLMs, and further sub-categorized by size (small, medium, large). This provides a comprehensive comparison of the strengths and weaknesses of various models across different reasoning tasks and scales.
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model's performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.

🔼 This table shows the performance of various LLMs on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which is a composite score that incorporates three sub-metrics related to solution correctness, identification of the first error step, and correctness of the explanation for the error. The table breaks down the performance across various subjects including Math, Medicine, Biology, Physics, Chemistry, Logic, and Coding. This allows for a more granular analysis of the strengths and weaknesses of each model across different reasoning types and domains. The ‘k’ value indicates the number of demonstration examples used during evaluation.
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model's performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.

🔼 This table shows the performance of various large language models (LLMs) on the MR-Ben benchmark. The performance is measured using the MR-Score metric, which considers solution correctness, the accuracy of identifying the first error step, and the accuracy of explaining the error reason. The table breaks down the results by subject area (Math, Medicine, Biology, Physics, Chemistry, Logic, Coding) and shows the performance with zero and one-shot prompting. ‘K’ indicates the number of demonstration examples used.
read the caption
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model's performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.
Full paper#