↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
In-context learning (ICL) is a powerful capability of large language models (LLMs) but its working mechanisms and optimization are not well understood. This paper addresses this gap by analyzing compressed vectors derived from transformers, which represent functions learned by ICL. Current methods struggle with the efficiency and robustness of these vectors, especially when dealing with numerous examples.
The researchers propose inner and momentum optimization methods to progressively refine the ‘state vector’ (a representation of the ICL function) at test time. They also introduce a divide-and-conquer aggregation technique to efficiently manage many examples. Experiments show that these methods effectively enhance state vectors, achieving state-of-the-art performance on diverse tasks. The contributions advance understanding of ICL’s workings and enable more effective use of LLMs in various applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on in-context learning and large language models. It offers novel optimization methods to improve the efficiency and robustness of ICL, addressing a key limitation in current LLMs. The findings pave the way for more efficient and scalable ICL applications, impacting various downstream NLP tasks and potentially influencing future LLM development.
Visual Insights#

This figure illustrates the proposed framework for processing state vectors in the context of in-context learning. It shows how state vectors are extracted from attention head outputs, progressively optimized using inner and momentum methods or aggregated via a divide-and-conquer strategy, and finally used to intervene in the inference forward pass.
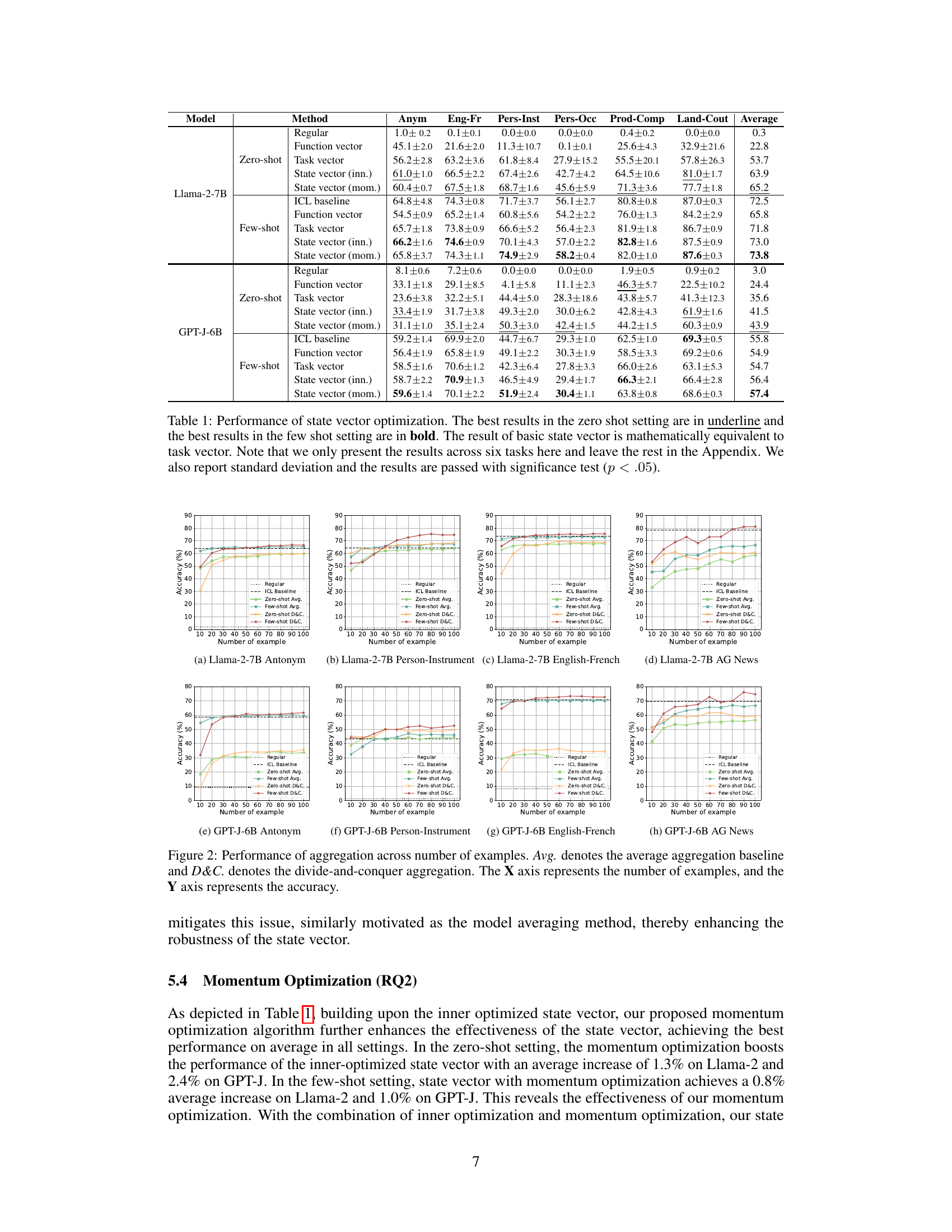
This table presents the performance comparison of different methods for in-context learning (ICL) on several tasks, using Llama-2-7B and GPT-J-6B language models. The methods compared include regular baselines (zero-shot and few-shot ICL), using the task vector, function vector, and the proposed state vector method with inner and momentum optimization. The table displays the average performance across different tasks and models, highlighting the improvements achieved by the proposed state vector optimization methods. Statistical significance (p<.05) is indicated.
In-depth insights#
ICL State Vector#
The concept of “ICL State Vector” offers a novel perspective on In-Context Learning (ICL) by representing the learned function as a compressed vector derived from the transformer’s internal state. This contrasts with previous approaches that focus on identifying specific parameters or attention heads. The state vector’s strength lies in its direct connection to the dynamic processing of ICL, capturing the evolution of information flow within the transformer layers. This allows for progressive refinement using optimization techniques like inner and momentum methods, mirroring traditional gradient descent optimization on model parameters. The innovative divide-and-conquer aggregation method cleverly addresses the limitation of long demonstration sequences by efficiently compressing multiple examples into a single state vector. This allows ICL to scale to more complex tasks and larger datasets. The state vector framework facilitates a deeper mechanistic understanding of ICL, bridging the gap between the observed behavior and the underlying processes within the model. Its effectiveness is validated through empirical results demonstrating state-of-the-art performance on diverse tasks, highlighting its potential as a crucial component for future ICL research and applications.
Inner Optimization#
The concept of ‘Inner Optimization’ in the context of in-context learning (ICL) state vectors presents a novel approach to enhance ICL’s performance. It leverages the idea of a model soup, averaging multiple state vectors extracted from different demonstrations to create a robust, generalized representation. This averaging process implicitly refines the state vector, improving its effectiveness and robustness. The method is inspired by the success of model soup techniques in ensemble learning, but instead of averaging model parameters, it averages ICL state vectors, showcasing a unique application of ensemble methods within the ICL framework. This approach is significant because it directly addresses the challenge of optimizing compressed ICL representations, a topic previously underexplored. By viewing state vectors as trainable parameters akin to model weights, inner optimization allows for test-time adaptation and improved generalization, making it a promising technique for enhancing the performance of LLMs in few-shot settings. The effectiveness is demonstrated by experiments, showcasing the improvement of inner optimized state vectors over standard methods, particularly in the robustness of predictions. However, future work should explore the optimal averaging strategy (weighted vs. unweighted) and the impact of the number of examples averaged on performance.
Momentum Boost#
The concept of a ‘Momentum Boost’ in the context of a research paper likely refers to an enhancement or acceleration of a process or effect. This could manifest in several ways depending on the specific research area. For example, in machine learning, it might describe a technique that significantly speeds up the training of a model or improves its convergence speed. This could involve incorporating a momentum-based optimizer, which leverages past gradients to guide the current update direction. The effectiveness of the momentum boost would be evaluated based on metrics relevant to the context, such as training time, accuracy, or generalization performance. In other fields, ‘momentum boost’ could allude to a strategy that amplifies a particular phenomenon or catalyzes a desired outcome. The key would be a clear demonstration of enhanced progress or improvement relative to a baseline or alternative approach. Understanding the specific mechanism underlying the momentum boost is crucial; was it due to algorithmic improvements, a novel data processing method, or a change in experimental design? A robust evaluation requires a comprehensive comparison showing statistical significance and considering potential confounding factors. The discussion of such a boost should always acknowledge limitations and potential caveats, providing a well-rounded and credible analysis.
Divide & Conquer#
The “Divide & Conquer” strategy, applied to in-context learning (ICL), cleverly tackles the limitation of long demonstration sequences in large language models (LLMs). By splitting extensive demonstrations into smaller, manageable groups, it allows LLMs to process information more efficiently. This approach not only bypasses context length constraints of LLMs but also enables parallel processing and, potentially, reduced memory usage. The “conquer” phase cleverly aggregates the learned information from each group into a single, comprehensive state vector, which is then used to guide predictions. This strategy demonstrates an intelligent approach to scaling ICL to a wider range of complex tasks that involve a large number of demonstrations. The key to its success lies in the LLM’s capacity to compress information efficiently via the state vector, thereby enabling effective handling of much larger datasets than previously possible.
Future of ICL#
The future of In-Context Learning (ICL) is bright, but challenging. Understanding the underlying mechanisms of ICL, moving beyond the current empirical observations, is crucial. This involves delving deeper into the interaction between the model’s internal representations and the provided examples, potentially using techniques like causal analysis or probing classifiers to unravel the
More visual insights#
More on figures

The figure shows the performance of two aggregation methods (average and divide-and-conquer) compared to baselines (regular and ICL) across different numbers of examples. The x-axis shows the number of examples used for aggregation, while the y-axis represents the accuracy achieved. It demonstrates how the performance of the aggregation methods improves as the number of examples increases, eventually surpassing the baselines in many cases. This highlights the effectiveness of the divide-and-conquer approach in handling a large number of examples in in-context learning.

This figure shows the average zero-shot performance across six datasets for different choices of the intermediate layer L, a hyperparameter in the proposed model. The x-axis represents the number of layers (L), and the y-axis shows the accuracy. The solid line represents the average accuracy across the six datasets, and the shaded region indicates the standard deviation, illustrating the variability of the performance across different datasets at each layer. This visualization helps determine the optimal number of layers for extracting the state vector for optimal model performance in a zero-shot setting.

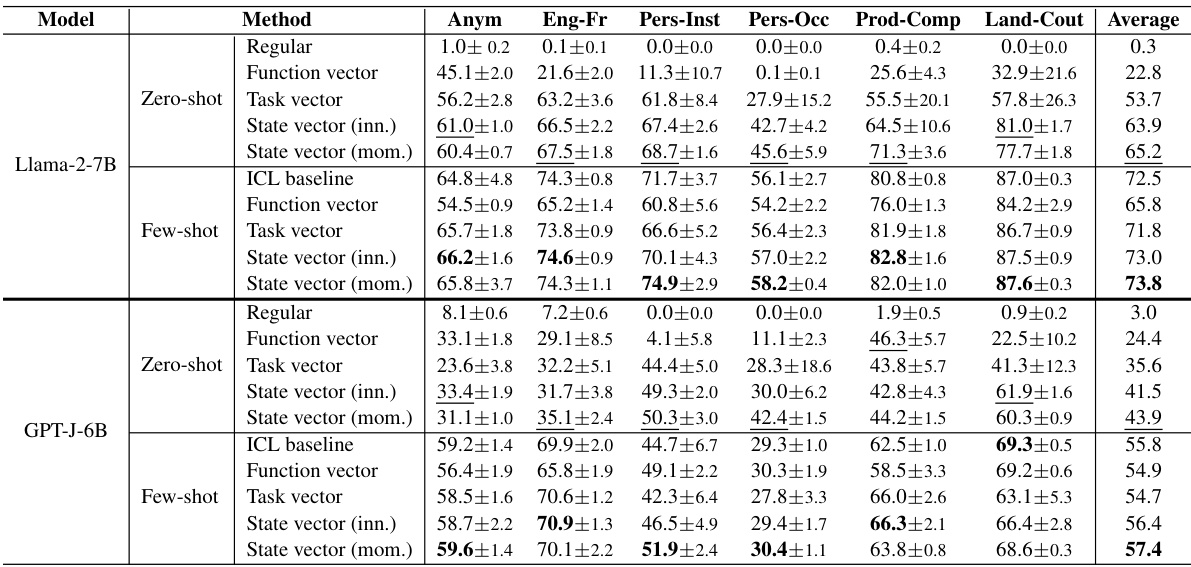
This figure shows the results of applying Principal Component Analysis (PCA) to reduce the dimensionality of the state vectors from three different tasks: Antonym, English-French translation, and Product-Company. Each point in the plots represents a state vector extracted from the transformer model’s attention mechanism, specifically focusing on the final separate token, the last layer. The color of each point corresponds to the example position in the demonstration sequence. The plot helps to visualize the clustering of state vectors based on their position within the demonstration, revealing how the model encodes information from the examples into the compressed vectors.

This figure shows the speedup achieved by the proposed inner and momentum optimization methods compared to regular ICL. The speedup is calculated as the ratio of the inference time of regular ICL to the inference time of the optimized methods. The results are shown separately for Llama-2-7B and GPT-J-6B, and for both zero-shot and few-shot settings. The figure demonstrates that the proposed optimization methods significantly speed up the inference process while maintaining a high level of accuracy, as reported in Table 1.

This figure displays the performance of two different aggregation methods (average and divide-and-conquer) on the accuracy of in-context learning (ICL) tasks as the number of examples increases. It showcases how the performance of both methods improves with more examples, with divide-and-conquer eventually surpassing the average aggregation method. The results are presented separately for zero-shot and few-shot learning settings and for different datasets (AG News, Antonym, English-French, and Product-Company). The figure helps to visually understand and compare the effectiveness of different aggregation strategies in ICL.

The figure shows the performance of two aggregation methods (average and divide-and-conquer) compared to baselines (regular and ICL) across different numbers of examples for four tasks using two different LLMs. The X-axis represents the number of examples used, and the Y-axis represents the accuracy achieved. The results illustrate how the performance of both methods initially trails behind ICL, but they improve as the number of examples increases, showcasing the efficiency of aggregation, especially the divide-and-conquer approach.
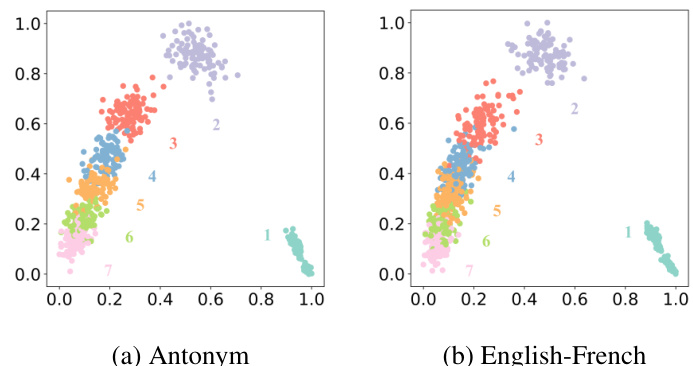
This figure shows the result of applying Principal Component Analysis (PCA) to reduce the dimensionality of the state vectors for the Antonym and English-French tasks using GPT-J. Each color represents a different example’s position within the demonstration sequence. The clustering suggests that state vectors from the same demonstration position are similar, and there is a clear separation between the first example and subsequent examples, potentially indicating how ICL develops incrementally. The outlier is indicated as a first-order outlier.

This figure displays the standard deviation of performance results for the task vector and the inner optimized state vector on three datasets (Antonym, Person-Instrument, English-French) in both zero-shot and few-shot settings. It illustrates the robustness of the methods against variations in demonstrations (a) and dummy queries (b) during the experiment. Lower standard deviations indicate more consistent performance.
More on tables
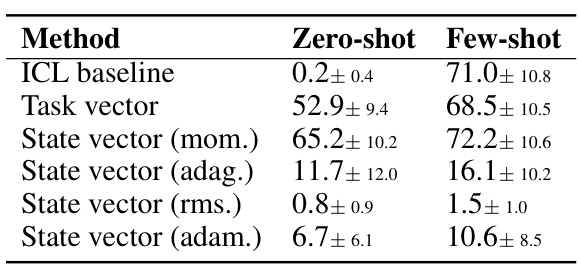
This table compares the performance of different gradient optimization algorithms applied to the state vector optimization method proposed in the paper. It shows the zero-shot and few-shot performance for several methods. The best performing method is highlighted, demonstrating the effectiveness of the chosen optimization strategy in improving ICL performance. The results illustrate that the momentum-based optimization method yields the best performance, exceeding other first-order methods.

This table presents the results of an experiment evaluating the effectiveness of the momentum-optimized state vector in generating natural text completions. Three different prompts were used, each containing a variable ‘X’ representing a query word. The table compares the performance of Llama-2-7B with and without the addition of the momentum-optimized state vector (+SV). The results show a significant improvement in accuracy when the optimized state vector is included.

This table presents the performance comparison of different methods for in-context learning (ICL), including baselines like regular and ICL, task vector, and function vector, and the proposed state vector with inner and momentum optimization. The results are shown for both zero-shot and few-shot settings across six tasks, indicating improvements achieved by the proposed methods in terms of accuracy. Statistical significance (p<0.05) is reported.

This table shows the performance comparison of different methods for in-context learning (ICL) on six tasks, including zero-shot and few-shot settings. It compares the regular approach, function vector, task vector, and the proposed state vector methods (with inner and momentum optimization). The best results for each setting are highlighted. Standard deviations are reported, and statistical significance (p<0.05) is indicated.

This table presents the performance comparison of different methods for in-context learning (ICL) on six tasks using Llama-2-7B and GPT-J-6B language models. The methods compared are regular ICL, function vector, task vector, state vector with inner optimization, state vector with momentum optimization, and the ICL baseline. Results are shown for both zero-shot and few-shot settings, with statistically significant improvements demonstrated by the proposed state vector optimization methods.

This table presents the performance comparison of different methods for in-context learning (ICL). The methods compared are the Regular baseline, Function Vector, Task Vector, State Vector with inner optimization, State Vector with momentum optimization, and the ICL baseline. The performance is evaluated on six different tasks across two different large language models (LLMs). The results show the effectiveness of the proposed state vector optimization methods.
Full paper#