TL;DR#
Current multimodal language models lack visual reasoning capabilities, limiting their performance on tasks requiring visual-spatial understanding. Existing chain-of-thought methods rely solely on text, neglecting the human tendency to sketch for better reasoning. This paper addresses these shortcomings by introducing SKETCHPAD, a framework designed to improve multimodal language model performance.
SKETCHPAD enhances multimodal LLMs by providing them with the tools to create and utilize intermediate sketches during the reasoning process. By generating visual artifacts such as lines, boxes, and masks, the models can better understand and solve problems. Experiments across diverse mathematical and visual reasoning tasks reveal substantial performance gains over strong baseline models, demonstrating SKETCHPAD’s effectiveness and setting a new state-of-the-art on multiple benchmarks.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on multimodal learning and large language models. It introduces a novel framework, SKETCHPAD, that significantly boosts the performance of LLMs on complex reasoning tasks by integrating visual sketching capabilities. This opens up new avenues for improving LLM interpretability and creating more capable AI agents that can effectively handle both visual and textual information. The findings on various benchmarks also demonstrate the effectiveness of integrating vision into language models which is a key current research trend.
Visual Insights#
🔼 This figure showcases four examples of how SKETCHPAD, a framework that allows multimodal language models to generate intermediate sketches for reasoning, improves the performance of GPT-4 on various tasks. Each example demonstrates a different task: geometry (proving angles in a triangle sum to 180 degrees), math function (determining convexity/concavity), visual search (identifying the type of a shop from an image), and spatial reasoning (determining if cookies are stacked). In each example, the model utilizes sketching as an intermediary step in the reasoning process. Without SKETCHPAD, GPT-4 fails to solve these problems correctly, whereas SKETCHPAD + GPT-4 solves them accurately.
read the caption
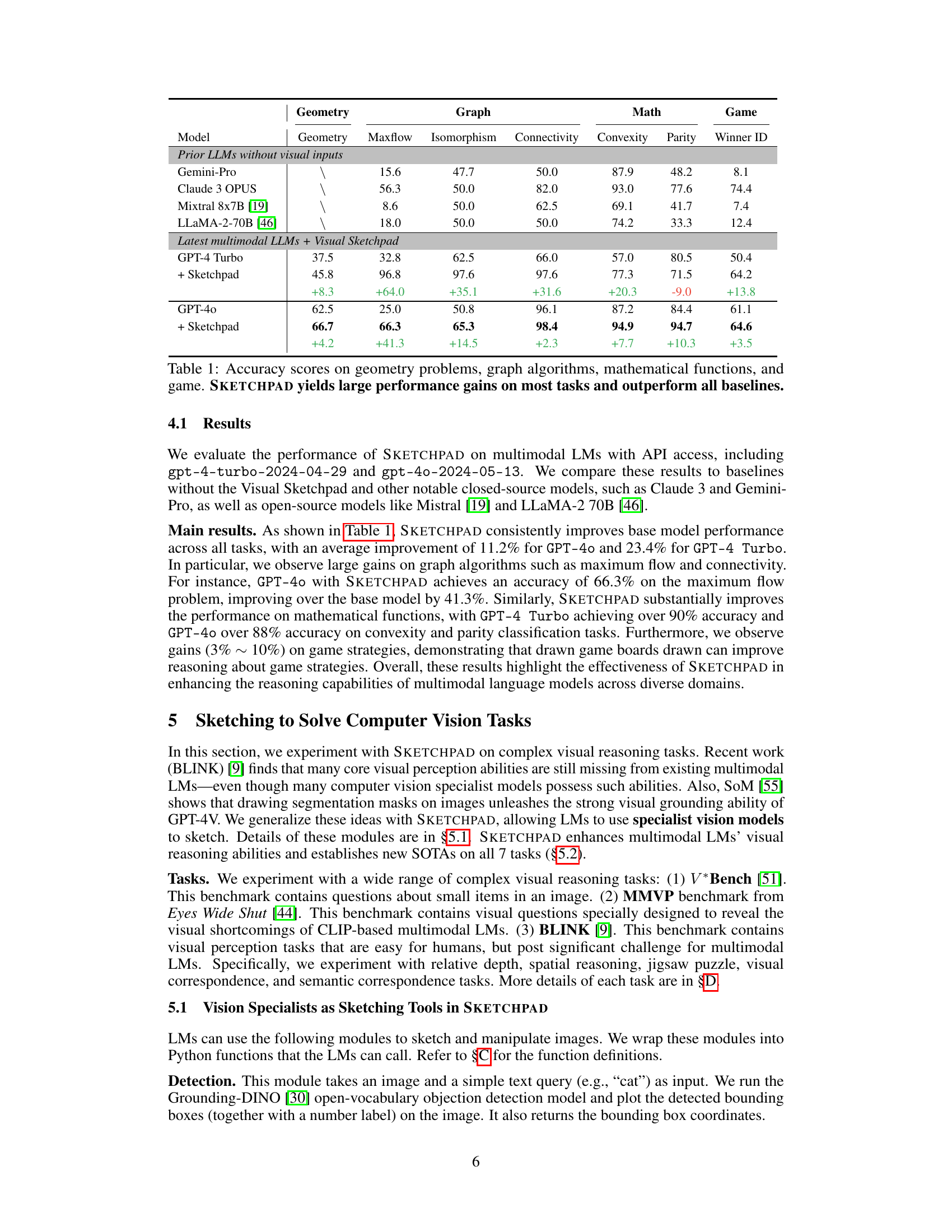
Figure 1: SKETCHPAD equips GPT-4 with the ability to generate intermediate sketches to reason over tasks. Given a visual input and query, such as proving the angles of a triangle equal 180°, SKETCHPAD enables the model to draw auxiliary lines which help solve the geometry problem. The examples are from [8, 51, 44]. For all these examples, without SKETCHPAD, GPT-40 fails to get the correct answer, while SKETCHPAD + GPT-4o achieves the correct solution.

🔼 This table presents the accuracy results achieved by several large language models (LLMs) on four categories of mathematical tasks: geometry problems, graph algorithms, mathematical functions, and game strategies. It compares the performance of baseline LLMs without visual sketching capabilities to the performance of the same models enhanced with the SKETCHPAD framework. The table shows that SKETCHPAD consistently improves the accuracy of the base models across all four task categories, demonstrating significant performance gains. The improvements are substantial, particularly in certain tasks. Note that the last row indicates the incremental gains due to SKETCHPAD compared to its corresponding baseline model.
read the caption
Table 1: Accuracy scores on geometry problems, graph algorithms, mathematical functions, and game. SKETCHPAD yields large performance gains on most tasks and outperform all baselines.
In-depth insights#
Visual Reasoning#
Visual reasoning, a crucial aspect of human intelligence, involves understanding and inferring information from visual data. It’s a complex process encompassing several stages such as visual perception, object recognition, spatial reasoning, and causal inference. Research in visual reasoning often focuses on developing computational models capable of mimicking these abilities, particularly within the context of artificial intelligence. These models, often utilizing deep learning techniques, aim to achieve robust performance on diverse benchmarks that require understanding visual relationships and solving visual puzzles. Key challenges include handling ambiguous or noisy visual input, dealing with varying levels of abstraction, and integrating visual information with other modalities like language. The development of effective visual reasoning systems holds significant implications for applications such as autonomous driving, medical image analysis, and robotics, where the ability to accurately interpret and reason from visual data is paramount. Furthermore, research explores the interplay between visual and linguistic information, investigating how language can guide and improve visual reasoning processes and vice-versa. The field is continuously evolving with the goal of building more sophisticated, flexible, and explainable AI systems that can truly reason with the visual world.
Sketchpad Framework#
A hypothetical ‘Sketchpad Framework’ in a research paper would likely detail a novel approach for integrating visual reasoning capabilities into multimodal language models. It would likely emphasize interactive sketching, allowing the model to generate visual elements (lines, shapes, annotations) during the reasoning process, mimicking human behavior. The core idea would be to treat the sketchpad as a dynamic workspace that evolves along with the reasoning steps, facilitating a chain of visual thought analogous to chain-of-thought prompting. The framework would likely involve a combination of techniques such as programmatic code generation to instruct the model’s drawing tools and integration of specialist computer vision models for advanced visual perception and interpretation. Evaluation would focus on benchmarks demonstrating improved performance in tasks demanding visual reasoning such as geometry and spatial problems. Key to success would be the ability to demonstrate that the visual sketches are integral to the model’s problem-solving process and not just decorative additions.
Math & Vision Tasks#
A hypothetical research paper section titled ‘Math & Vision Tasks’ would likely explore the intersection of mathematical reasoning and visual perception. The core challenge would be how to leverage visual information to improve mathematical problem-solving in AI models. This might involve tasks such as solving geometry problems using diagrams, analyzing graphs represented visually, or understanding mathematical functions through their plotted graphs. The section would likely benchmark different multimodal AI architectures’ performance across a range of carefully designed tasks, comparing their accuracy and efficiency against baselines and potentially other state-of-the-art models. A key focus would be on the types of visual reasoning mechanisms used by the models to arrive at their solutions, such as the ability to identify relevant features in images, draw intermediate sketches, or apply specialist computer vision techniques. The authors would likely discuss the implications of their findings for the design of future multimodal AI systems and the potential for such systems to tackle more complex problems requiring both visual understanding and mathematical reasoning. Analysis of model performance might reveal valuable insights into the relationship between visual and mathematical cognition in AI. The research would also need to address limitations, perhaps focusing on the difficulty of creating robust evaluation datasets and the challenges of interpreting model behaviour within complex, real-world scenarios.
Multimodal Reasoning#
Multimodal reasoning, at its core, seeks to enable artificial intelligence systems to understand and interact with information presented across various modalities, such as text, images, audio, and video. A key challenge lies in effectively fusing information from these diverse sources, each carrying unique representational characteristics. Current approaches often involve complex architectures that integrate modality-specific encoders and decoders, aiming for seamless information exchange and joint reasoning. However, many existing methods struggle to effectively capture the intricate relationships and contextual dependencies between different modalities. Furthermore, evaluating the success of multimodal reasoning remains a significant hurdle, as benchmark datasets and evaluation metrics continue to evolve and improve, reflecting the diverse applications and problem settings. The development of more robust and explainable multimodal reasoning models is crucial, enabling more nuanced understanding and interactions with the increasingly multimodal world around us. This includes developing methods capable of handling incomplete or noisy data from multiple modalities. Additionally, research into interpretability and transparency will help us understand decision-making processes in these complex systems.
Future of SKETCHPAD#
The future of SKETCHPAD lies in expanding its capabilities beyond the current mathematical and visual reasoning tasks. Integrating more sophisticated vision models, particularly those handling nuanced visual cues like depth perception and object relationships, will broaden SKETCHPAD’s application in complex real-world scenarios. Developing a more versatile sketching interface is crucial, enabling the model to handle various drawing styles and input modalities, including touch and gesture-based interactions. Furthermore, improving the interpretability of SKETCHPAD’s reasoning process is important. Analyzing its intermediate sketches and thought processes could unlock insights into its decision-making mechanism, facilitating more trustworthy and reliable results. Lastly, exploring collaborative sketching will enhance the system’s ability to handle more intricate and knowledge-intensive tasks, allowing multiple agents to contribute visual elements and ideas to reach a solution. This opens up possibilities of collaboration between human and AI.
More visual insights#
More on figures

🔼 This figure showcases examples of how SKETCHPAD, a framework that allows multimodal language models to generate sketches for reasoning, improves performance on various tasks. The four panels display examples from different task domains (Geometry, Math Function, Visual Search, Spatial Reasoning). Each panel shows the task prompt, the model’s response with and without SKETCHPAD, and the generated sketches (if any). The key takeaway is that SKETCHPAD’s ability to create visual intermediate steps aids the model in solving problems that it would otherwise fail to solve.
read the caption
Figure 1: SKETCHPAD equips GPT-4 with the ability to generate intermediate sketches to reason over tasks. Given a visual input and query, such as proving the angles of a triangle equal 180°, SKETCHPAD enables the model to draw auxiliary lines which help solve the geometry problem. The examples are from [8, 51, 44]. For all these examples, without SKETCHPAD, GPT-40 fails to get the correct answer, while SKETCHPAD + GPT-4o achieves the correct solution.

🔼 This figure demonstrates the core functionality of SKETCHPAD. It shows four examples of how adding SKETCHPAD to GPT-4 allows the model to generate intermediate sketches to solve problems that it could not solve without the sketches. The examples illustrate the effectiveness of SKETCHPAD across different tasks, including geometry, visual search, and spatial reasoning.
read the caption
Figure 1: SKETCHPAD equips GPT-4 with the ability to generate intermediate sketches to reason over tasks. Given a visual input and query, such as proving the angles of a triangle equal 180°, SKETCHPAD enables the model to draw auxiliary lines which help solve the geometry problem. The examples are from [8, 51, 44]. For all these examples, without SKETCHPAD, GPT-40 fails to get the correct answer, while SKETCHPAD + GPT-4o achieves the correct solution.

🔼 This figure showcases how SKETCHPAD enhances the reasoning capabilities of GPT-4 by allowing it to generate intermediate sketches. Four examples illustrate how adding sketching improves the model’s ability to solve geometry, visual search, and spatial reasoning problems. Without SKETCHPAD, GPT-4 fails on these examples, while with SKETCHPAD and the auxiliary images it generates, it successfully solves the problems.
read the caption
Figure 1: SKETCHPAD equips GPT-4 with the ability to generate intermediate sketches to reason over tasks. Given a visual input and query, such as proving the angles of a triangle equal 180°, SKETCHPAD enables the model to draw auxiliary lines which help solve the geometry problem. The examples are from [8, 51, 44]. For all these examples, without SKETCHPAD, GPT-40 fails to get the correct answer, while SKETCHPAD + GPT-4o achieves the correct solution.

🔼 This figure shows examples of how SKETCHPAD, a framework that allows multimodal language models to generate sketches for reasoning, helps solve various tasks. In each example, a visual input and a question are given. SKETCHPAD allows the model to generate intermediate sketches (like auxiliary lines in geometry or segmentation masks in visual reasoning) which aid in solving the problem. The figure highlights that GPT-40 alone fails these tasks, but with SKETCHPAD, it successfully arrives at the correct answers.
read the caption
Figure 1: SKETCHPAD equips GPT-4 with the ability to generate intermediate sketches to reason over tasks. Given a visual input and query, such as proving the angles of a triangle equal 180°, SKETCHPAD enables the model to draw auxiliary lines which help solve the geometry problem. The examples are from [8, 51, 44]. For all these examples, without SKETCHPAD, GPT-40 fails to get the correct answer, while SKETCHPAD + GPT-4o achieves the correct solution.

🔼 This figure shows four examples of how SKETCHPAD helps GPT-4 solve different reasoning tasks by generating intermediate sketches. The top row demonstrates mathematical reasoning tasks, where SKETCHPAD allows the model to draw auxiliary lines (geometry) or plots (math functions) to aid problem-solving. The bottom row showcases visual reasoning tasks, where SKETCHPAD uses tools like sliding windows and segmentation to help the model identify shops or analyze cookie stacking. In all cases, GPT-4 alone fails, but succeeds with SKETCHPAD’s sketch-based reasoning.
read the caption
Figure 1: SKETCHPAD equips GPT-4 with the ability to generate intermediate sketches to reason over tasks. Given a visual input and query, such as proving the angles of a triangle equal 180°, SKETCHPAD enables the model to draw auxiliary lines which help solve the geometry problem. The examples are from [8, 51, 44]. For all these examples, without SKETCHPAD, GPT-40 fails to get the correct answer, while SKETCHPAD + GPT-4o achieves the correct solution.

🔼 This figure shows four examples of how SKETCHPAD helps GPT-4 solve problems by generating intermediate sketches. The top row demonstrates SKETCHPAD solving geometry and math function problems, while the bottom row shows its application to visual search and spatial reasoning tasks. In each example, the left image shows the problem as presented to the model, the middle image demonstrates the model’s intermediate sketch generated by SKETCHPAD, and the right shows the final solution. The caption highlights that without SKETCHPAD, GPT-40 is unable to correctly solve these problems, showcasing the system’s effectiveness.
read the caption
Figure 1: SKETCHPAD equips GPT-4 with the ability to generate intermediate sketches to reason over tasks. Given a visual input and query, such as proving the angles of a triangle equal 180°, SKETCHPAD enables the model to draw auxiliary lines which help solve the geometry problem. The examples are from [8, 51, 44]. For all these examples, without SKETCHPAD, GPT-40 fails to get the correct answer, while SKETCHPAD + GPT-4o achieves the correct solution.

🔼 This figure shows four examples of how SKETCHPAD helps GPT-4 solve different reasoning tasks by generating intermediate sketches. The tasks include proving the angles of a triangle sum to 180 degrees (geometry), determining if a function is convex (mathematical functions), identifying a shop type based on an image (visual search), and determining if cookies are stacked (spatial reasoning). In each case, standard GPT-4 fails, but with the addition of SKETCHPAD and its ability to generate sketches, the model successfully completes the tasks.
read the caption
Figure 1: SKETCHPAD equips GPT-4 with the ability to generate intermediate sketches to reason over tasks. Given a visual input and query, such as proving the angles of a triangle equal 180°, SKETCHPAD enables the model to draw auxiliary lines which help solve the geometry problem. The examples are from [8, 51, 44]. For all these examples, without SKETCHPAD, GPT-40 fails to get the correct answer, while SKETCHPAD + GPT-4o achieves the correct solution.

🔼 This figure shows four examples of how SKETCHPAD helps GPT-4 solve different reasoning tasks by generating intermediate sketches. Each example includes the task prompt (e.g., proving angles of triangle sum to 180), the model’s solution with SKETCHPAD (showing the intermediate sketches drawn and the final answer), and the model’s solution without SKETCHPAD (which often results in a wrong or incomplete answer). The examples illustrate how sketching facilitates reasoning in geometry, math functions, visual search, and spatial reasoning problems.
read the caption
Figure 1: SKETCHPAD equips GPT-4 with the ability to generate intermediate sketches to reason over tasks. Given a visual input and query, such as proving the angles of a triangle equal 180°, SKETCHPAD enables the model to draw auxiliary lines which help solve the geometry problem. The examples are from [8, 51, 44]. For all these examples, without SKETCHPAD, GPT-40 fails to get the correct answer, while SKETCHPAD + GPT-4o achieves the correct solution.
More on tables

🔼 This table presents the accuracy scores achieved by various multimodal language models on seven complex visual reasoning tasks. The results are broken down by model (prior multimodal LLMs, previous state-of-the-art models, and latest multimodal LLMs with and without the Visual SKETCHPAD framework). The improvement provided by SKETCHPAD is also shown, highlighting its significant impact on the performance of these models across all tasks.
read the caption
Table 2: Accuracy on complex visual reasoning tasks. SKETCHPAD enhances both GPT-4 Turbo and GPT-40 performance, establishing new SOTA performance levels on all the tasks.

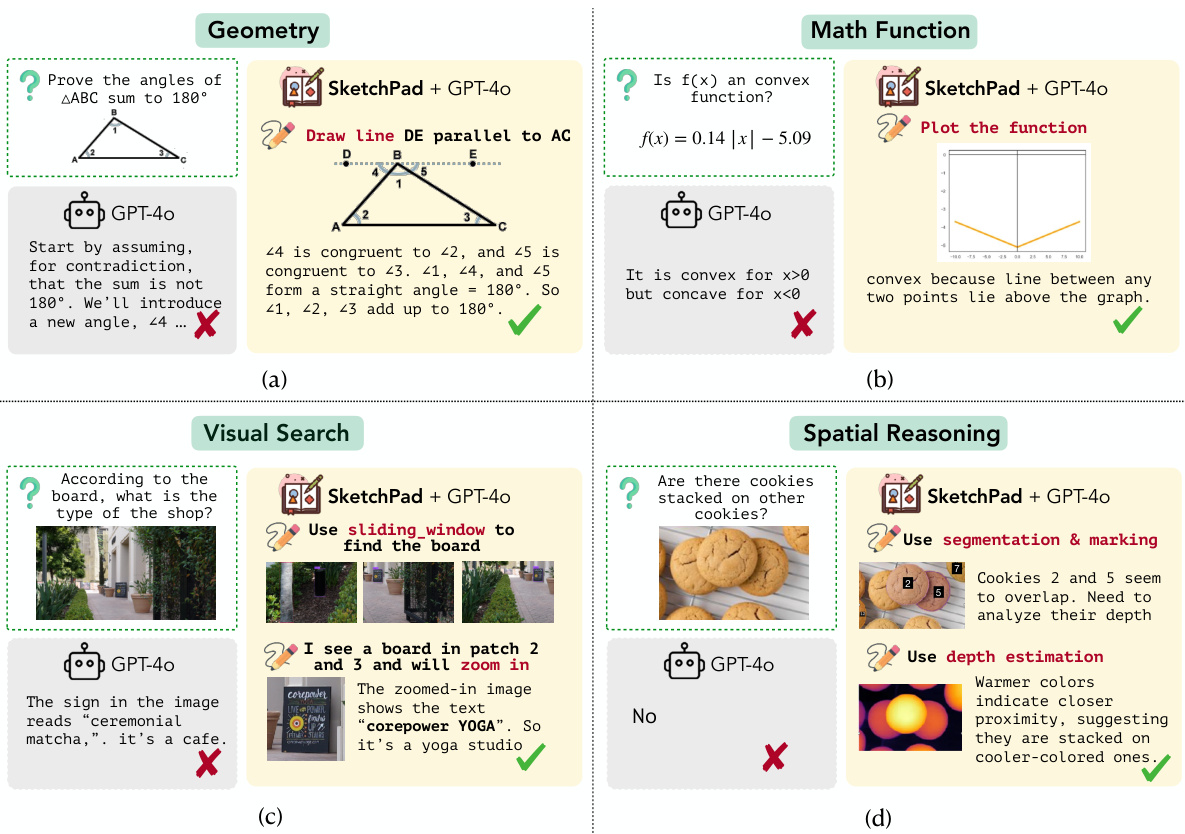
🔼 This table compares the performance of SKETCHPAD with other augmentation methods (SoM and Visprog) on single-image computer vision tasks. To ensure a fair comparison, the authors modified Visprog by using GPT-4 as the language model. The table shows that SKETCHPAD consistently outperforms other methods across all tasks.
read the caption
Table 3: Comparison with other augmentation frameworks for multimodal LMs on single-image tasks. For fair comparison, we modify the original Visprog [14] framework by replacing the LM and VQA components with the corresponding GPT-4 model.
🔼 This table presents the accuracy results achieved by different language models (LLMs) on four categories of mathematical tasks: geometry problems, graph algorithms, mathematical functions, and game strategies. It compares the performance of several base LLMs (without visual sketching) to the same LLMs enhanced by the SKETCHPAD framework. The results show that SKETCHPAD consistently improves the accuracy of the models across all four task categories, significantly outperforming the baselines in most cases.
read the caption
Table 1: Accuracy scores on geometry problems, graph algorithms, mathematical functions, and game. SKETCHPAD yields large performance gains on most tasks and outperform all baselines.

🔼 This table presents the accuracy scores achieved by various language models on four different types of mathematical problems: geometry, graph algorithms, mathematical functions, and games. The results are shown for baseline language models without visual sketching capabilities and for the same language models enhanced with the SKETCHPAD framework. The table highlights the significant improvement in accuracy that SKETCHPAD provides across all four mathematical task categories. The improvements are expressed as both absolute gains and percentage increases, clearly demonstrating the effectiveness of the SKETCHPAD method in boosting the performance of language models on mathematical reasoning tasks.
read the caption
Table 1: Accuracy scores on geometry problems, graph algorithms, mathematical functions, and game. SKETCHPAD yields large performance gains on most tasks and outperform all baselines.

🔼 This table presents the accuracy scores achieved by different language models on four categories of mathematical tasks: geometry problems, graph algorithms, mathematical functions, and game strategies. The results are shown for several language models, including some prior LLMs without visual inputs and the latest multimodal LLMs both with and without the addition of the SKETCHPAD framework. The table highlights the significant performance gains achieved by adding SKETCHPAD to the multimodal LLMs on all four task categories. The average improvement using SKETCHPAD with GPT-40 is 11.2%, and 23.4% for GPT-4 Turbo.
read the caption
Table 1: Accuracy scores on geometry problems, graph algorithms, mathematical functions, and game. SKETCHPAD yields large performance gains on most tasks and outperform all baselines.

🔼 This table presents the accuracy results achieved by several language models on four categories of mathematical tasks: geometry problems, graph algorithms, mathematical functions, and game strategies. The performance is shown both with and without using the proposed SKETCHPAD framework. The results demonstrate that SKETCHPAD significantly improves the accuracy of the language models across all four tasks, outperforming previous state-of-the-art models.
read the caption
Table 1: Accuracy scores on geometry problems, graph algorithms, mathematical functions, and game. SKETCHPAD yields large performance gains on most tasks and outperform all baselines.

🔼 This table presents the accuracy scores achieved by different language models (LLMs) on four categories of mathematical tasks: geometry problems, graph algorithms, mathematical functions, and game strategies. The performance is compared between base LLMs without visual inputs and those augmented with the SKETCHPAD framework. The table highlights the significant performance improvements achieved by SKETCHPAD across all four categories, demonstrating its effectiveness in enhancing the reasoning capabilities of LLMs.
read the caption
Table 1: Accuracy scores on geometry problems, graph algorithms, mathematical functions, and game. SKETCHPAD yields large performance gains on most tasks and outperform all baselines.
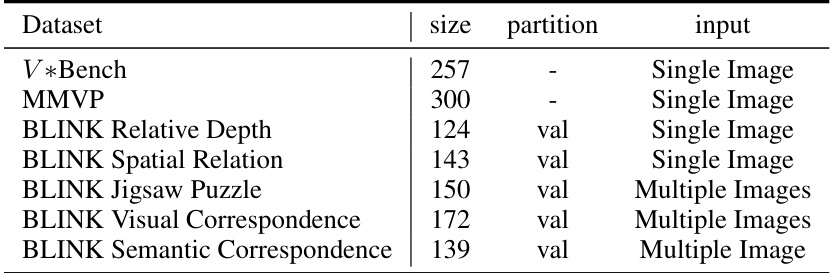
🔼 This table presents the statistics for seven computer vision datasets used in the paper’s experiments. It shows the dataset name, the number of samples in each dataset, whether it uses a validation partition, and the type of input (single image or multiple images). These datasets are used to evaluate the performance of the proposed SKETCHPAD framework on various visual reasoning tasks.
read the caption
Table 6: Vision tasks data statistics.

🔼 This table presents the accuracy results achieved by various language models (LLMs) on four categories of mathematical tasks: geometry problems, graph algorithms, mathematical functions, and game strategies. The performance of these LLMs is compared with and without the use of SKETCHPAD, a framework that enhances reasoning by allowing LLMs to generate intermediate sketches. The results highlight the consistent improvement in accuracy across all four tasks when SKETCHPAD is used, demonstrating its effectiveness in boosting the performance of LLMs on complex mathematical problems.
read the caption
Table 1: Accuracy scores on geometry problems, graph algorithms, mathematical functions, and game. SKETCHPAD yields large performance gains on most tasks and outperform all baselines.
Full paper#