↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Cross-domain image denoising is challenging due to the high cost and time required to obtain large datasets for various sensors. Existing methods like noise synthesis have limitations. This paper proposes an efficient approach to address this issue.
The proposed method, Adaptive Domain Learning (ADL), uses a small amount of data from the target domain sensor alongside existing data from different sensors (source domains). ADL intelligently filters out source data harmful to target-domain performance, improving efficiency and reducing resource requirements. A modulation module leverages sensor-specific information, enhancing cross-domain generalization. Extensive experimental results demonstrate that ADL significantly outperforms existing methods in cross-domain image denoising.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenge of cross-domain image denoising, a crucial problem in computer vision. The proposed adaptive domain learning (ADL) method offers a solution that is both effective and efficient, requiring only small amounts of target-domain data. This is highly relevant to current research trends in few-shot learning and domain adaptation. The work also opens avenues for improving existing noise calibration methods and enhances the robustness of various image restoration tasks.
Visual Insights#

This figure illustrates the three steps in the adaptive domain learning (ADL) pipeline proposed in the paper: 1) Target domain pretraining: a model is pre-trained using a small amount of data from the target domain; 2) Source domain adaptive learning: data from source domains are iteratively used to fine-tune the model, with a dynamic validation set determining whether each data batch improves performance on the target domain; and 3) Target domain fine-tuning: the model is fine-tuned using the remaining data from the target domain.
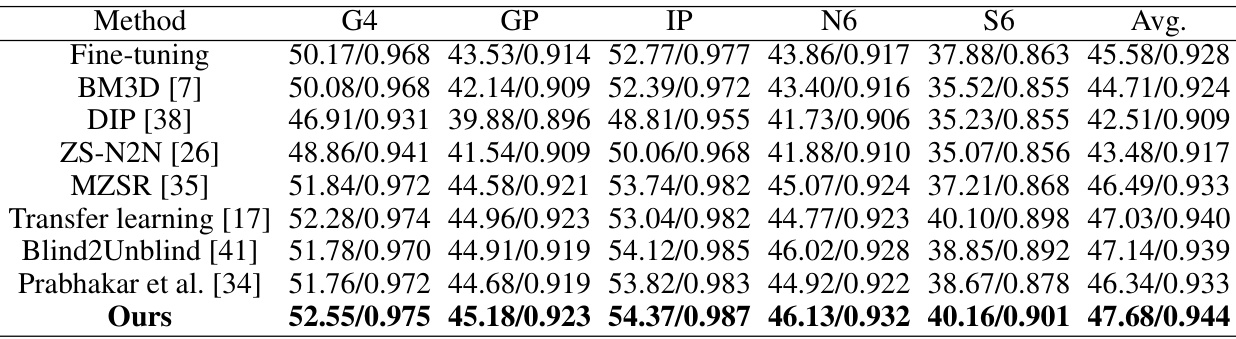
This table presents a quantitative comparison of the proposed ADL method against various baselines for RAW image denoising. The performance is measured using Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) metrics. The results are shown for different cameras (sensors) from three datasets: SIDD, ELD, and SID. The ‘Fine-tuning’ baseline represents training on source domain data (data from other sensors) followed by fine-tuning on the target domain data (data from a specific sensor). The average performance across all sensors is also provided.
In-depth insights#
Cross-Domain Challenge#
The cross-domain challenge in image denoising arises from variations in noise patterns across different camera sensors. Training a model on one sensor’s data often leads to poor performance on others, necessitating separate datasets for each sensor. This is a significant hurdle because acquiring large, high-quality datasets is expensive and time-consuming. Existing solutions like noise synthesis and self-supervised learning have limitations in accuracy and generalizability. Therefore, the core challenge lies in developing effective methods that can transfer knowledge learned from source domain datasets (data from various sensors) to target domains (new sensors) with minimal additional data, thereby addressing both the data scarcity and domain discrepancy problems. This requires robust techniques for domain adaptation and potentially incorporating sensor-specific information into the model architecture to enhance adaptability.
Adaptive Domain Learning#
Adaptive domain learning (ADL) tackles the challenge of training machine learning models that generalize well across different data domains. Its core innovation lies in selectively leveraging data from multiple source domains while mitigating the negative impact of domain discrepancies. Unlike traditional domain adaptation methods, ADL doesn’t aim for complete domain harmonization. Instead, it dynamically evaluates the utility of each data point from source domains, identifying and excluding samples that hinder target domain performance. This adaptive approach is particularly valuable when target domain data is scarce, a common limitation in many real-world scenarios. By focusing on what’s beneficial, ADL reduces reliance on large, meticulously curated datasets, significantly improving efficiency. The method often incorporates techniques to bridge the remaining domain gap. For example, a modulation module might be used to incorporate sensor-specific information, ensuring the model appropriately adjusts its internal representations to the characteristics of the new sensor or data modality. The strength of ADL resides in its flexibility and adaptability, making it particularly suited for cross-domain tasks with limited target data.
Channel-wise Modulation#
The proposed ‘Channel-wise Modulation’ network ingeniously addresses the challenge of cross-domain RAW image denoising by incorporating sensor-specific information. This is achieved by embedding sensor type and ISO values, which are easily accessible metadata, directly into the network architecture. This allows the model to adapt to the varying noise characteristics of different sensors, effectively aligning features from diverse data sources. The modulation module dynamically adjusts the feature space, enabling the network to learn common knowledge while mitigating the negative impact of domain discrepancies. This is a key component of the Adaptive Domain Learning (ADL) strategy, enhancing the model’s ability to generalize across different sensors with minimal target domain data, improving robustness and reducing resource needs.
Real-World Evaluation#
A robust ‘Real-World Evaluation’ section for a research paper would delve into the practical applicability of the presented method. It should go beyond synthetic datasets and address challenges encountered in real-world scenarios. Key aspects include specifying the hardware used for data acquisition (cameras, sensors, etc.), diverse real-world conditions tested (lighting, motion blur, varying noise levels), and detailed comparisons against state-of-the-art methods, using metrics relevant to practical applications. A thorough discussion of limitations and failure cases is crucial, showcasing the method’s robustness and its potential limitations. Visual results demonstrating the performance in complex scenarios with varied data would strengthen the evaluation. Qualitative analysis of results, including user feedback or expert assessment, could further provide insights into the usability and practical value of the proposed method.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the adaptive domain learning (ADL) framework to other low-level vision tasks such as image deblurring and super-resolution is a natural next step, leveraging the power of ADL’s ability to learn from limited target domain data. Investigating more sophisticated noise models that incorporate sensor-specific parameters beyond ISO and sensor type could further enhance denoising accuracy. The current modulation module could be made more flexible, perhaps by incorporating a learnable attention mechanism that dynamically weighs the importance of different sensor parameters, allowing the model to better adapt to unseen sensor characteristics. Additionally, exploring alternative methods for dynamically evaluating data usefulness could lead to improved efficiency and robustness of the ADL training process. Finally, a comprehensive investigation into the generalizability of ADL across a wider range of sensors and imaging conditions would be essential to solidify its impact on practical applications and ensure that benefits extend beyond the datasets used in this study.
More visual insights#
More on figures

This figure showcases a comparison of error maps between the proposed method and two other state-of-the-art approaches (Blind2Unblind and Transfer Learning) on two different datasets (SIDD and SID). The error maps visually represent the difference between the ground truth images and the denoised images produced by each method. The results show that the proposed method produces images with significantly fewer errors and less noise compared to the other two methods, indicating its superior performance in cross-domain image denoising.
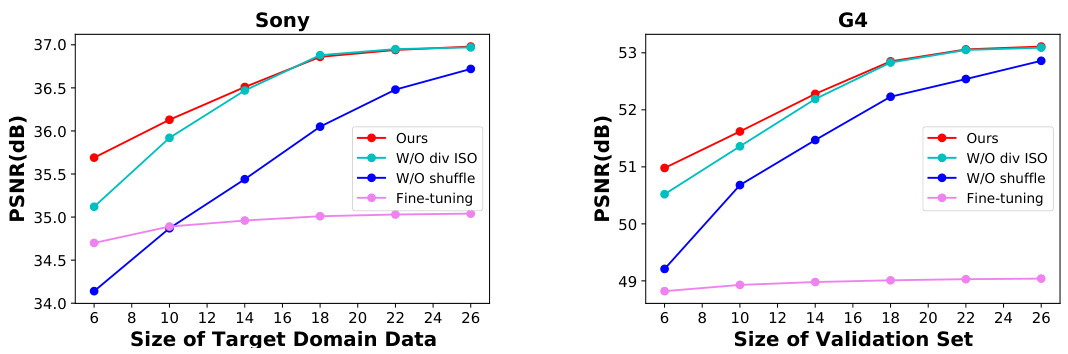
The figure shows the ablation study of the size of the validation set. It compares the performance of the proposed adaptive domain learning (ADL) method against a baseline (fine-tuning) and variations of ADL. Specifically, it shows the impact of removing different components of ADL (division of ISO, data shuffling, and dynamic validation set) on the PSNR across different sizes of the target domain dataset. The results demonstrate that the dynamic validation set is crucial for preventing overfitting, especially when only a small amount of target domain data is available. The graphs shows PSNR (dB) against the size of the target domain data for Sony and G4 sensors.
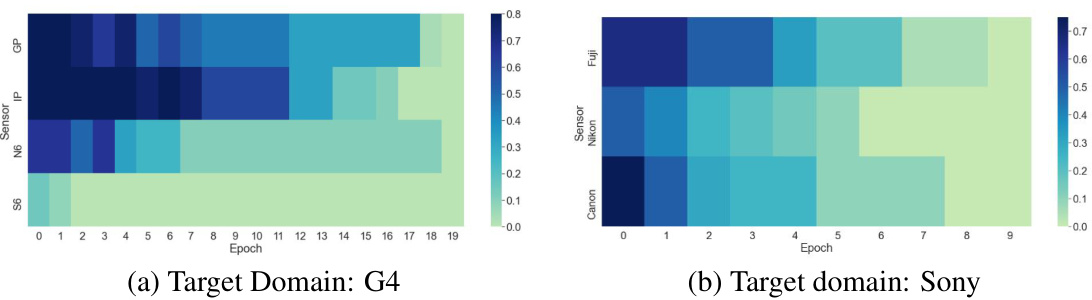
This figure shows heatmaps visualizing the contribution of data from different source domains (sensors) to the training of the target domain model over epochs. Each cell’s color intensity represents the percentage contribution of a specific sensor’s data to the target domain’s model at a particular epoch. The heatmaps illustrate how the ADL algorithm selectively uses data from different sensors to effectively train the target domain’s model, adapting to each sensor’s unique characteristics and data distribution. (a) shows this for sensor G4 in the SIDD dataset, and (b) for sensor Sony in the SID dataset.
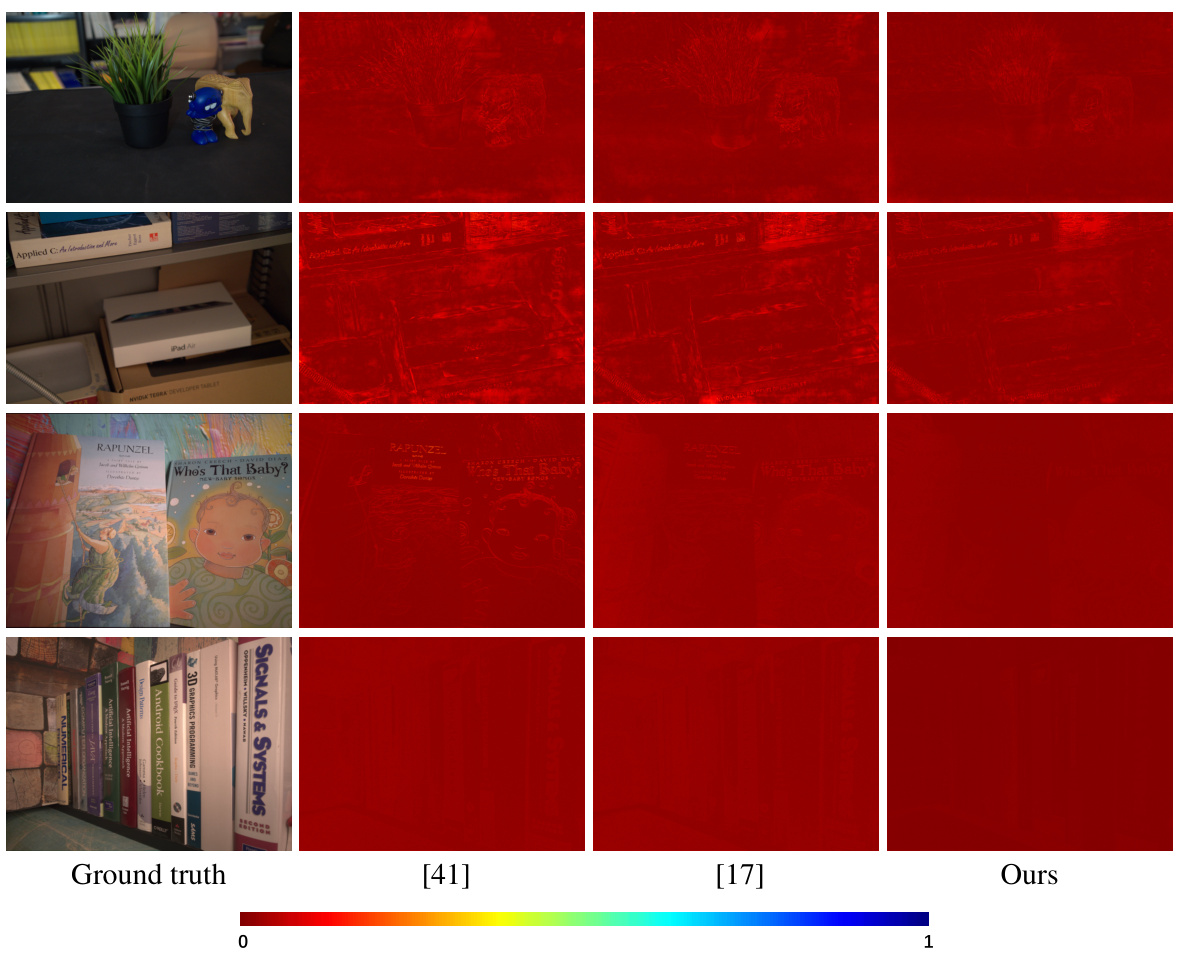
This figure compares the error maps of the proposed method against two state-of-the-art methods (Blind2Unblind [41] and Transfer learning [17]) on two datasets (SIDD and SID). Each row shows results from a different dataset. The error maps visually represent the difference between the denoised images produced by each method and the ground truth images. The brighter the color in an error map, the greater the error. This visualization shows that the proposed method produces denoised images with significantly lower errors (less bright colors) compared to the other two methods.
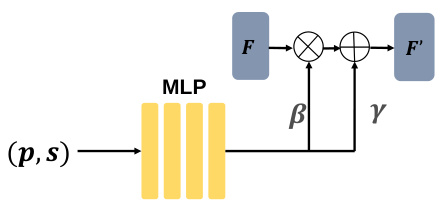
This figure illustrates the channel-wise modulation network architecture. Sensor-specific metadata (sensor type and ISO) is input into a Multi-Layer Perceptron (MLP). The MLP outputs channel-wise scaling (γ) and shifting (β) parameters. These parameters modulate the convolutional feature maps (F) to produce adjusted feature maps (F’) that are better adapted to sensor-specific noise characteristics.

This figure shows a qualitative comparison of the proposed method against a baseline fine-tuning approach on image deblurring and dehazing tasks. The results suggest that the proposed method produces clearer and more detailed images compared to the fine-tuning method. Two example images are shown for each task (deblurring and dehazing) showing input, fine-tuned, and proposed method results, respectively. The enhanced clarity in the output of the proposed method is visually evident.
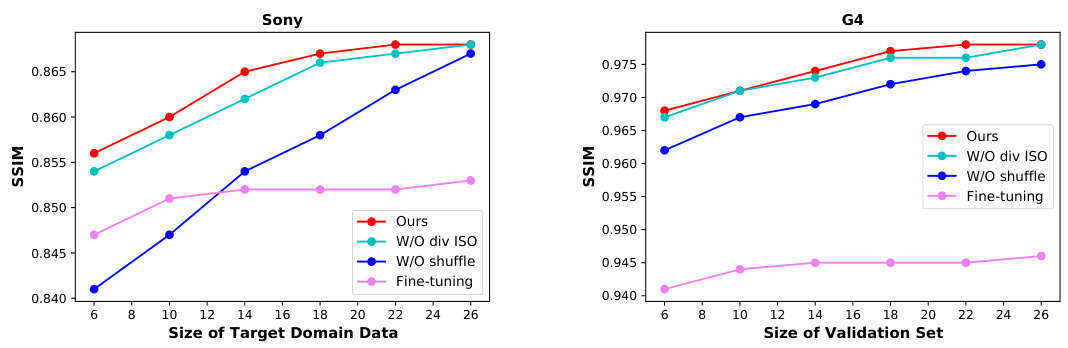
This figure shows the ablation study on the impact of the validation set size on the model performance. It compares the SSIM (structural similarity index metric) scores achieved by four different model training approaches with varying sizes of the target domain dataset and validation set: the proposed approach (‘Ours’), the approach without diversity in ISO (‘W/O div ISO’), the approach without shuffling data (‘W/O shuffle’), and a simple fine-tuning approach. The results clearly indicate that using a dynamic validation set, as proposed by the authors, is crucial in mitigating overfitting when limited target domain data is available.
More on tables
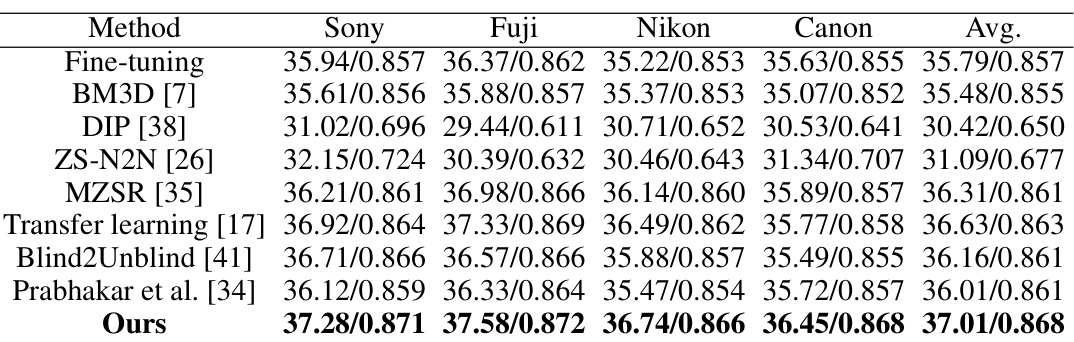
This table presents a quantitative comparison of the proposed ADL method against several baseline methods for RAW image denoising. The comparison is done using Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) metrics. The results are shown for five different smartphone cameras (SIDD dataset), two DSLR cameras (ELD dataset), and two other DSLR cameras (SID dataset), highlighting the performance across various sensors and lighting conditions. The ‘Fine-tuning’ row indicates the results when training on the source domain and then fine-tuning on the target domain data, providing a baseline for comparison against ADL. The camera names in the first column represent which camera’s data is used as the target domain during training.

This table presents a quantitative comparison of the proposed ADL method against several baseline methods for RAW image denoising. The comparison is performed on three datasets: SIDD, ELD, and SID, each captured by different types of cameras (smartphones and DSLRs). The table shows the PSNR and SSIM values achieved by each method on different sensors. The ‘Fine-tuning’ row indicates the performance when a model is first trained on source domain data (data from other sensors) and then fine-tuned on the target domain data. The camera name in the first column indicates which sensor’s data was used as the target domain in that particular experiment.
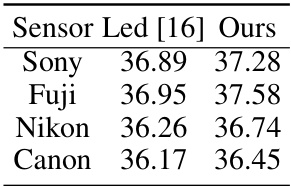
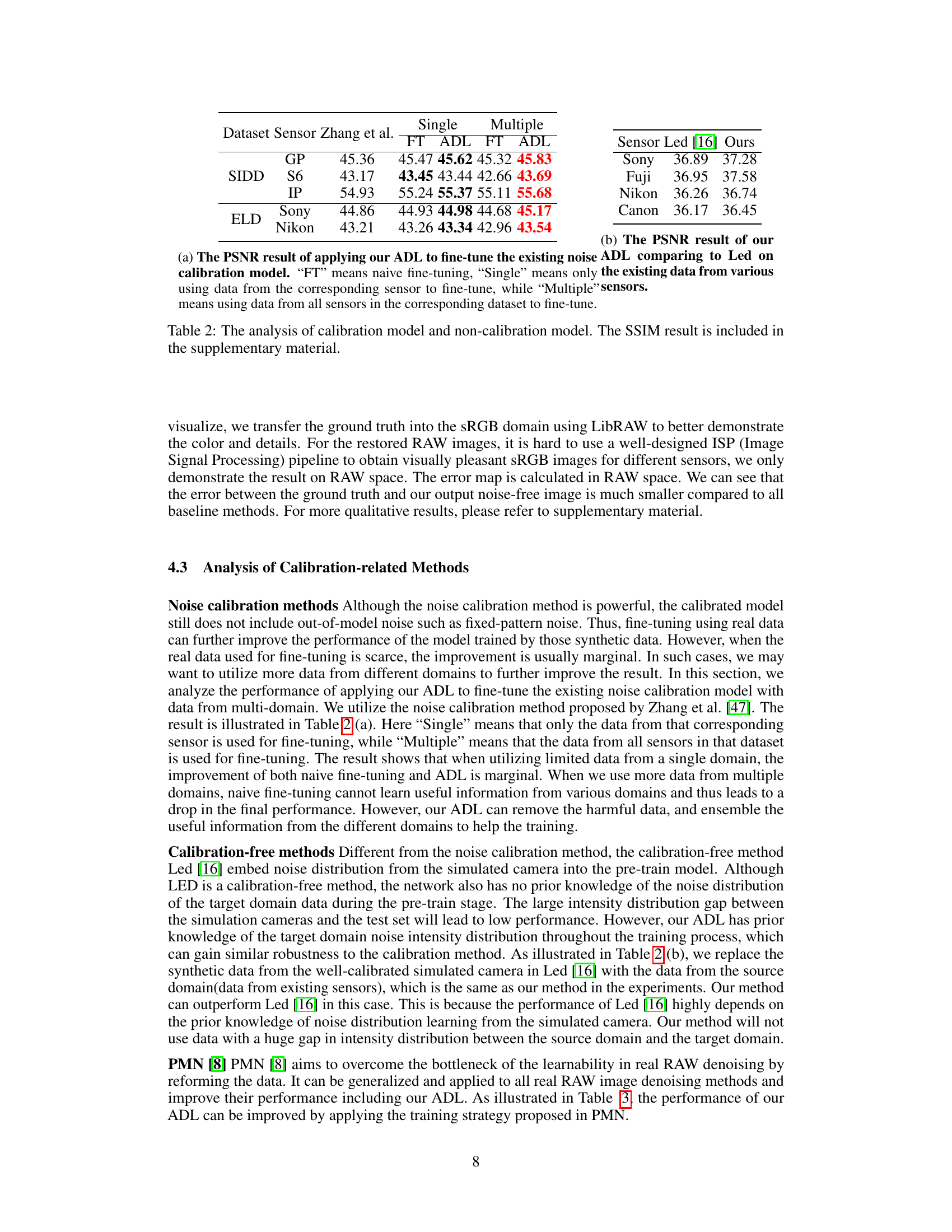
This table compares the performance of the proposed ADL method to a calibration-based method (Led [16]) and a non-calibration method. The comparison is done using both single-sensor fine-tuning (using only data from the corresponding sensor) and multi-sensor fine-tuning (using data from all sensors in the dataset). PSNR values are shown, while SSIM values are included in the supplementary materials.
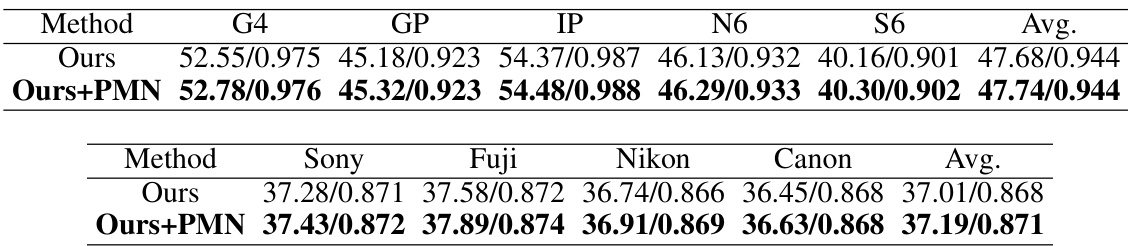
This table presents a quantitative comparison of the proposed ADL method against various baselines on three datasets: SIDD, ELD, and SID. The datasets contain RAW image data captured under different conditions (normal light, extremely low light) by different types of cameras (smartphones, DSLRs). The results are reported in terms of Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM), two common image quality metrics. The table shows that ADL consistently outperforms the baselines, demonstrating its effectiveness in cross-domain RAW image denoising.
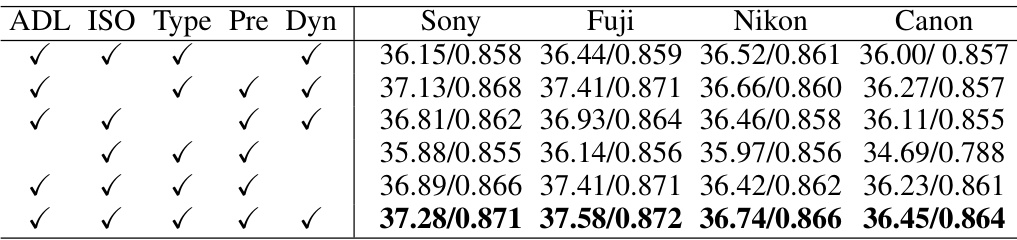
This table presents the ablation study results on ELD and SID datasets, evaluating the impact of different components of the proposed adaptive domain learning (ADL) method. Each row shows PSNR/SSIM values obtained by removing one or more components (ADL, ISO modulation, sensor type modulation, target domain pretraining, dynamic validation set) from the full method. This allows assessing the individual contribution of each component to the overall performance.

This table shows a comparison of Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) values obtained using different methods. It compares the performance of Adaptive Domain Learning (ADL) against a naive fine-tuning approach on various datasets. The datasets include a base set and two synthetic ‘harmful’ datasets: one with different light conditions (Harmfull) and one with misaligned input/ground truth data (Harmful2). The results demonstrate how ADL handles the presence of harmful data during training.
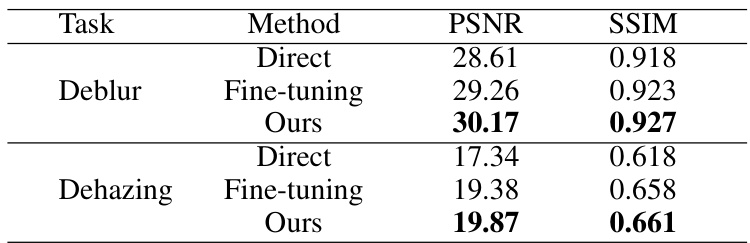
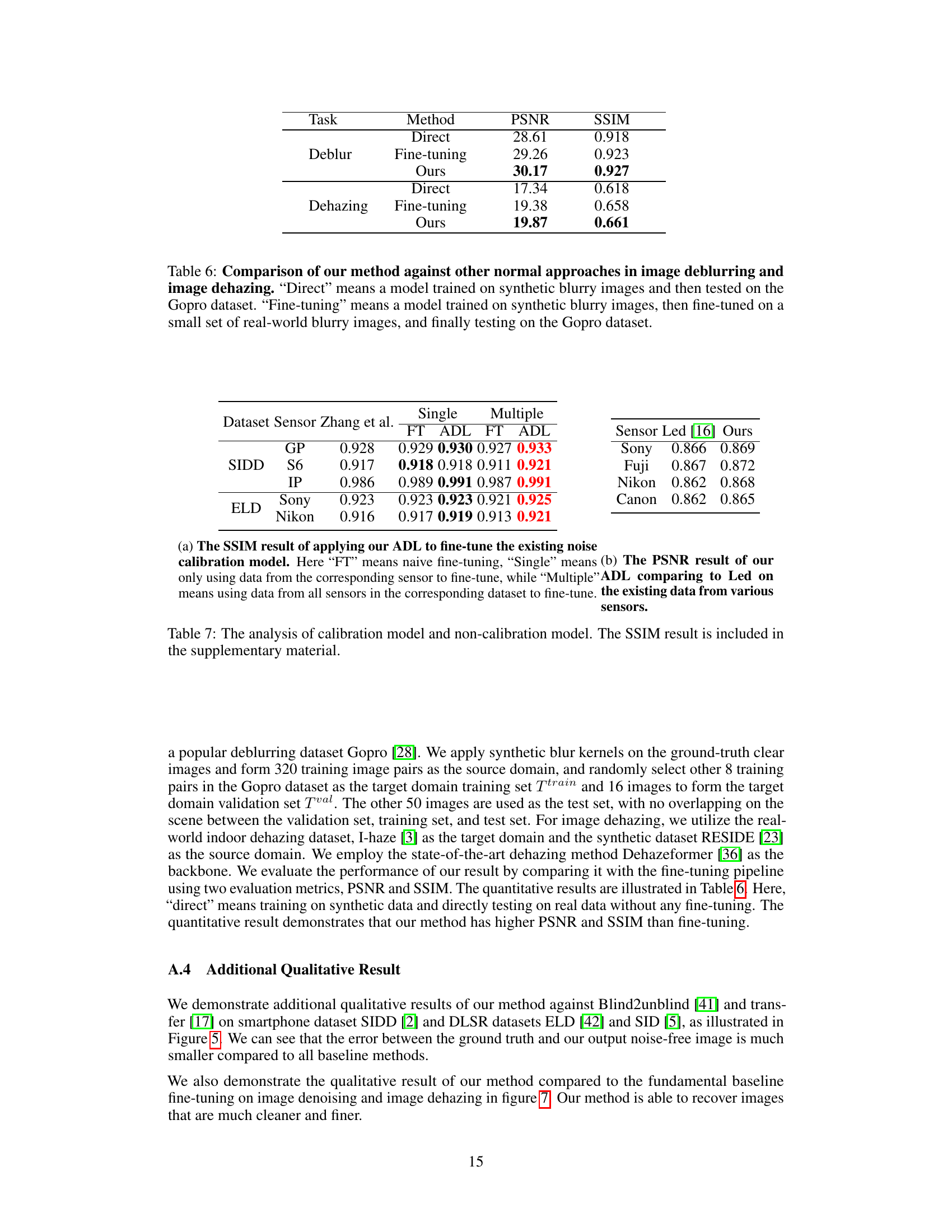
This table compares the performance of the proposed method against other methods (direct and fine-tuning) for image deblurring and dehazing tasks using the GoPro dataset. It shows that the proposed adaptive domain learning method outperforms the other methods, especially for dehazing.

This table presents the quantitative results of the proposed ADL method compared against several baselines using PSNR and SSIM metrics on three datasets: SIDD, ELD, and SID. The results are broken down by camera sensor (target domain) and include results for fine-tuning and the ADL method. Higher PSNR and SSIM scores indicate better performance.
Full paper#