↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many search and rescue operations rely on locating individuals using indirect information like textual descriptions or images. However, accurately pinpointing these locations can be challenging and time-sensitive. This paper tackles the problem of active geo-localization (AGL) where an agent uses aerial images to efficiently find a target specified via various modalities. Existing approaches typically struggle with different goal modalities and limited time for localization.
The proposed solution, GOMAA-Geo, uses cross-modality contrastive learning to align representations across different modalities (text, images). It then uses supervised pretraining and reinforcement learning to train an efficient navigation and localization agent. Experiments showed that GOMAA-Geo outperforms previous methods and generalizes well to unseen datasets and goal modalities, highlighting the value of its modality-agnostic design. The created novel dataset enables benchmarking this challenging task across different modalities.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework for active geo-localization that is goal modality agnostic, meaning it can handle various goal descriptions (text, images). This is highly relevant to real-world applications like search and rescue and opens new avenues for zero-shot generalization in AI, allowing for more robust and versatile AI agents.
Visual Insights#
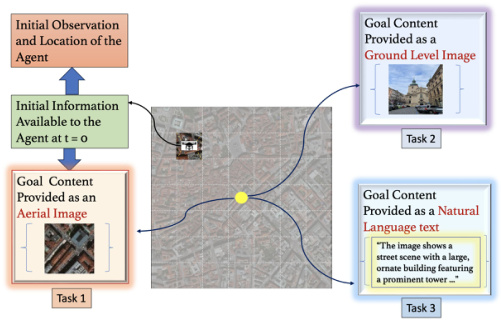
This figure illustrates the active geo-localization task across different goal modalities. The agent (e.g., a UAV) uses a sequence of aerial images to locate a target. The target’s location is specified in one of three modalities: aerial image, ground-level image, or natural language text. The agent’s field of view is limited, so it must navigate efficiently to find the target.

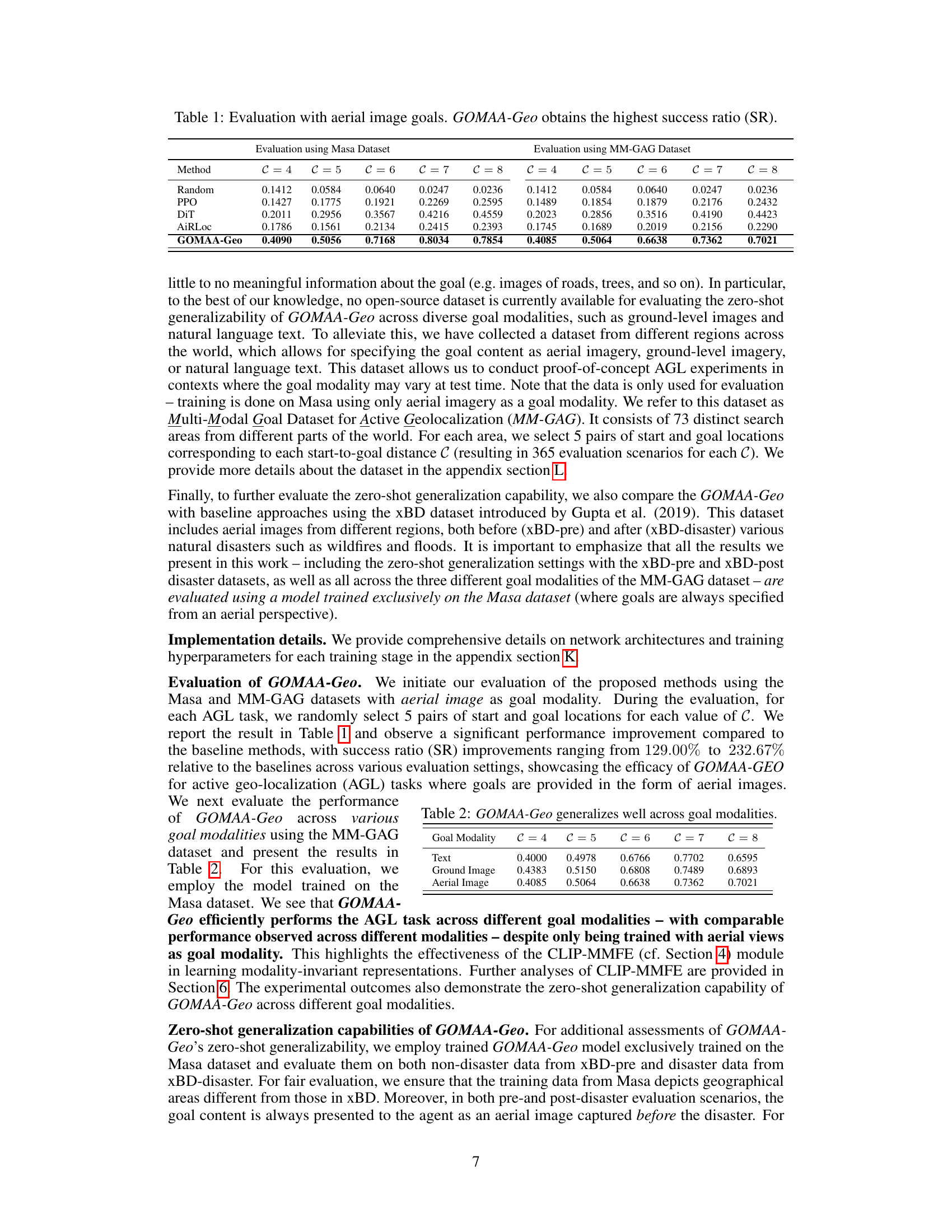
This table presents the success ratio (SR) achieved by different methods on the task of active geo-localization using aerial images as goals. The methods compared include a random policy, PPO, Decision Transformer (DiT), AiRLoc, and the proposed GOMAA-Geo. The evaluation is conducted across various distances (C) from the starting point to the goal location. The results show that GOMAA-Geo significantly outperforms all baseline methods across all distances, demonstrating its superior performance in the task.
In-depth insights#
Multimodal AGL#
Multimodal active geo-localization (AGL) presents a significant advancement in search and rescue operations and environmental monitoring. It tackles the challenge of locating targets specified using diverse modalities—text descriptions, aerial imagery, ground-level images—by leveraging the strengths of each. This approach surpasses unimodal methods by enabling more robust and flexible goal representations, leading to improved zero-shot generalization capabilities. The ability to handle varied input types enhances reliability in scenarios where information is fragmented or incomplete. However, successful implementation requires careful consideration of computational cost and the potential for misalignment between modalities. Data scarcity remains a key challenge, as well as ensuring that the cross-modal alignment techniques accurately capture the relevant semantic information. Future research should focus on addressing these limitations and exploring the applications of multimodal AGL in even more challenging, real-world environments.
Cross-modal Contrastive Learning#
Cross-modal contrastive learning is a powerful technique for aligning representations from different modalities, such as images and text. It leverages the idea that semantically similar data points, even if expressed in different modalities, should have similar representations in a shared embedding space. The approach typically involves designing a contrastive loss function that encourages similar data points across modalities to be closer together, while pushing dissimilar points further apart. This is achieved by contrasting positive pairs (semantically similar data from different modalities) with negative pairs (semantically dissimilar data). Effective implementation requires careful design of data augmentation strategies and the choice of appropriate network architectures. The key benefit is enabling cross-modal retrieval and generation tasks, where information from one modality can be used to retrieve or generate data in another. This is particularly useful when one modality is scarce or expensive to obtain, allowing for leveraging abundant data in another modality. However, challenges remain in handling complex relationships between modalities and ensuring generalization across diverse datasets. Further research is crucial to address these issues and unlock the full potential of this technique in various applications.
GASP Pretraining#
The Goal-Aware Supervised Pretraining (GASP) strategy is a novel approach for training LLMs to effectively handle the complexities of active geo-localization. GASP leverages a two-step process: First, it generates random sequences of agent actions within a search environment. Second, it trains the LLM to predict optimal actions at each time step based on the observed history and goal specifications. This supervised pre-training aligns the LLM’s representations with the task’s demands, effectively leveraging the LLM’s strengths in long-range sequence modeling and autoregressive prediction. A key advantage of GASP is its ability to generate a history-aware, goal-conditioned latent representation. This representation guides subsequent policy learning, enabling the agent to make informed decisions based on past experience and the specified goal. The effectiveness of GASP is demonstrated through comparisons with alternative pre-training methods, highlighting its crucial role in achieving high performance in active geo-localization.
Zero-shot Generalization#
Zero-shot generalization, a crucial aspect of robust AI, is thoroughly investigated in this research. The capacity of the model to successfully perform active geo-localization tasks across diverse goal modalities despite being trained exclusively on aerial images is a significant finding. This showcases the model’s ability to extrapolate learned knowledge to unseen scenarios and data types. The paper highlights the importance of cross-modality contrastive learning and the effectiveness of foundation model pretraining in achieving this zero-shot capability. However, the study also acknowledges limitations in the zero-shot generalization performance, particularly when faced with extremely similar goal patches. Further analysis and the introduction of dense reward functions are implemented to improve performance, but these are areas worthy of further research. The achieved level of zero-shot generalization remains impressive and suggests the potential for broader applicability in various domains beyond the scope of this paper. Overall, the research contributes valuable insights into building robust, generalized AI systems that can effectively handle previously unseen data modalities. The use of publicly available datasets makes the results reproducible, and limitations are explicitly acknowledged, further strengthening the research’s credibility.
AGL Framework#
An AGL (Active Geo-localization) framework centers around efficiently locating a target using an agent’s sequential observations, typically images acquired during navigation. A key challenge is handling diverse goal specifications, such as natural language descriptions or ground-level images, while using only aerial imagery as navigation cues. Therefore, a robust framework necessitates cross-modality alignment to bridge these representation gaps. Contrastive learning techniques are crucial for aligning representations from different modalities, enabling the agent to effectively relate a textual description to its visual counterpart in the aerial imagery. A strong AGL framework often incorporates a sophisticated planning mechanism, potentially based on reinforcement learning, to optimally guide the agent’s navigation decisions. Supervised pre-training, often using LLMs, can further enhance the agent’s ability to incorporate history and contextual information into its decisions. The overall success of an AGL framework is measured by its efficiency in reaching the target and its ability to generalize across diverse goal modalities and environmental contexts.
More visual insights#
More on figures
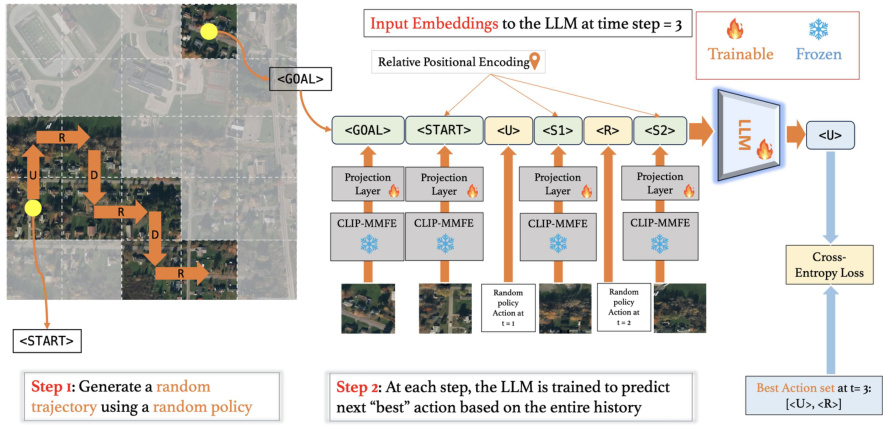
This figure illustrates the Goal-Aware Supervised Pretraining (GASP) strategy used to pretrain Large Language Models (LLMs) for the Goal-Conditioned Partially Observable Markov Decision Process (GC-POMDP) problem of active geo-localization. The GASP strategy involves two steps: 1) generating a random trajectory using a random policy, and 2) training the LLM to predict the next best action at each step based on the entire history. The LLM uses a CLIP-based Multi-Modal Feature Extractor (CLIP-MMFE) to process aerial image observations. The training objective is to minimize the cross-entropy loss between the LLM’s predicted actions and a set of optimal actions. The figure shows the input embeddings to the LLM, the LLM architecture, and the cross-entropy loss function.

This figure shows the GOMAA-Geo framework’s architecture, illustrating how it handles different goal modalities (aerial, ground-level images, and text) to achieve active geo-localization. The process begins with the CLIP-MMFE which handles the different modalities by aligning their representations. The aligned representations are then fed into an LLM, which predicts an action based on the history of observed states and actions. Finally, an actor-critic network refines the action selection, considering the current state and the goal.

This figure illustrates the active geo-localization task across different modalities. The agent, using only sequential observations of aerial images, needs to find the goal which can be specified using various modalities such as aerial images, ground level images, or natural language descriptions. The agent can only observe a small part of the search area at each time step.
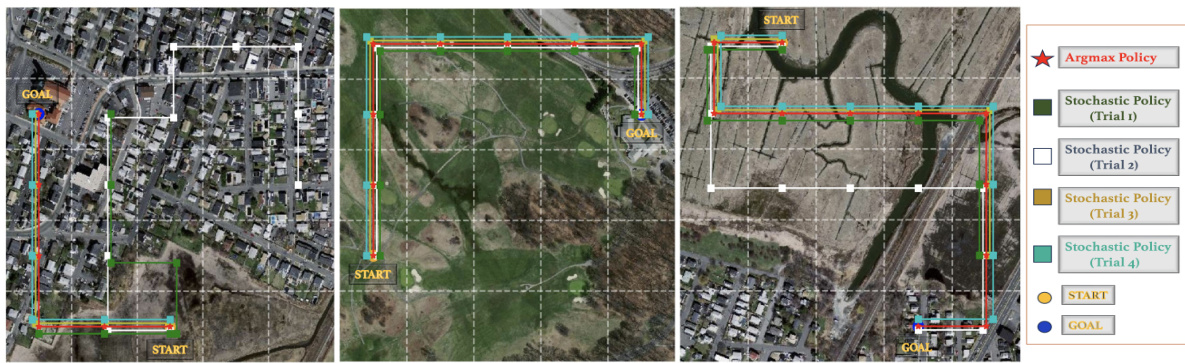
The figure showcases four different exploration strategies used by GOMAA-Geo to reach a goal, categorized by different goal modalities. The first column demonstrates an argmax policy, which always selects the action with the highest probability of success, thus resulting in a deterministic path. The remaining columns illustrate stochastic policies, introducing randomness in action selection, leading to four distinct but successful trajectories.
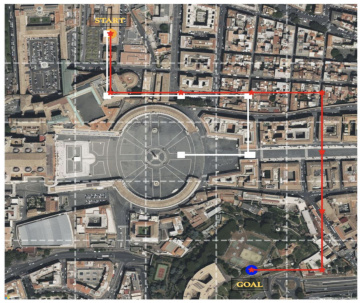
This figure illustrates the task of active geo-localization. An agent (like a UAV) needs to find a target within a search area using only a sequence of partial aerial views (limited field of view). The goal can be described in multiple ways: as an aerial image, a ground-level image, or natural language. The agent must efficiently use the sequence of observations to find the goal as quickly as possible.

This figure shows four example scenarios of GOMAA-Geo’s exploration behavior using both stochastic and argmax policies across different goal modalities. In each scenario, the agent starts at the same location and attempts to reach the goal. The stochastic policy is shown in different colors for multiple trials (different colored lines) to show the variability introduced by its probabilistic action selection. The argmax policy, in contrast, always chooses the most probable action at each step, resulting in a more direct path to the goal. The figure aims to illustrate how different policy choices lead to different exploration patterns, even when the underlying model and goal are the same.

This figure illustrates the active geo-localization task across different modalities. An agent (e.g., a UAV) must locate a goal within a search area using only sequential observations of aerial sub-images. The goal is specified in one of several modalities (natural language, ground-level image, or aerial image), but its exact location (pg) within the search area is unknown. The agent can move to different positions (pt) within the area. The challenge is to efficiently find the goal (pt = pg) with limited localization time. The figure visually represents the task with three examples: a ground-level image, an aerial image, and natural language text, all indicating a distinct goal.

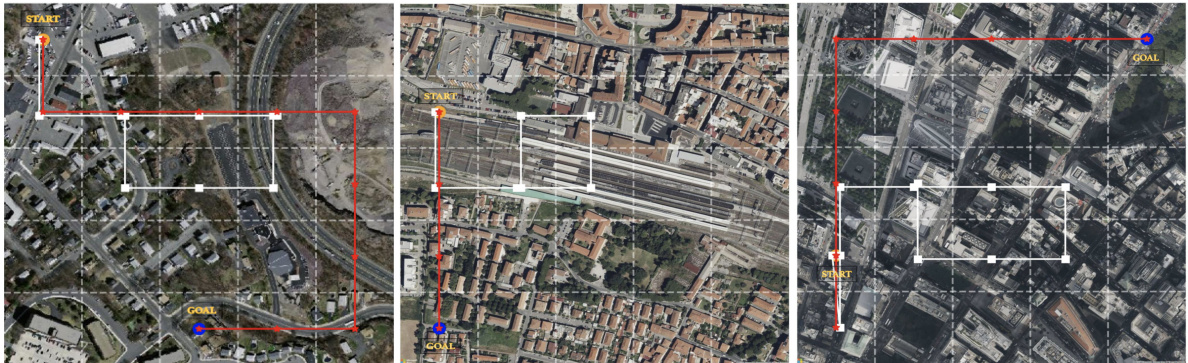
This figure shows four different trials of the GOMAA-Geo model exploring a search area to find a goal. The goal is specified in three different modalities: an image, a textual description, and an aerial image. The red line shows the optimal path taken by the argmax policy. The other lines depict alternative paths taken by the stochastic policy in four different runs. The figure demonstrates the agent’s ability to successfully locate the goal in all three modalities using the minimum number of steps.

This figure visualizes how the GOMAA-Geo agent explores the environment to reach a goal specified in different modalities (text, ground-level image, aerial image). The figure shows four different stochastic policy trials and one argmax policy trial. The stochastic policy demonstrates the agent’s ability to explore probabilistically, while the argmax policy represents the most likely path based on the learned model’s predictions. The visualization helps understand the agent’s decision-making process across various goal modalities.

This figure showcases four different exploration trajectories generated by the GOMAA-Geo agent using a stochastic policy (trials 1-4) and a deterministic argmax policy. Each trajectory shows the path taken by the agent (indicated by different colored lines) to reach the goal, starting from the same initial point. All four stochastic policy runs and the argmax policy run successfully reach the goal. The figure demonstrates the agent’s ability to find a successful route to the goal, even when using a stochastic policy that introduces randomness into the action selection process. This highlights the robustness of the GOMAA-Geo method.

This figure visualizes the exploration trajectories generated by GOMAA-Geo’s stochastic and argmax policies for a specific start and goal pair. The stochastic policy selects actions probabilistically, while the argmax policy chooses the action with the highest probability. The figure demonstrates the different exploration paths taken by the agent in multiple trials using the stochastic policy and contrasts them with the more direct, deterministic path of the argmax policy. This illustrates the exploration-exploitation trade-off inherent in reinforcement learning agents and how a stochastic policy can lead to discovering alternative, potentially more efficient, paths to the goal.
This figure illustrates the task of active geo-localization with goals specified in different modalities (aerial image, ground-level image, natural language description). An agent (e.g., a UAV) uses a sequence of aerial images to locate a goal. The agent’s field of view is limited (as shown by the grid overlay), and it must navigate efficiently to the goal. The goal is only partially observed through the agent’s limited view.
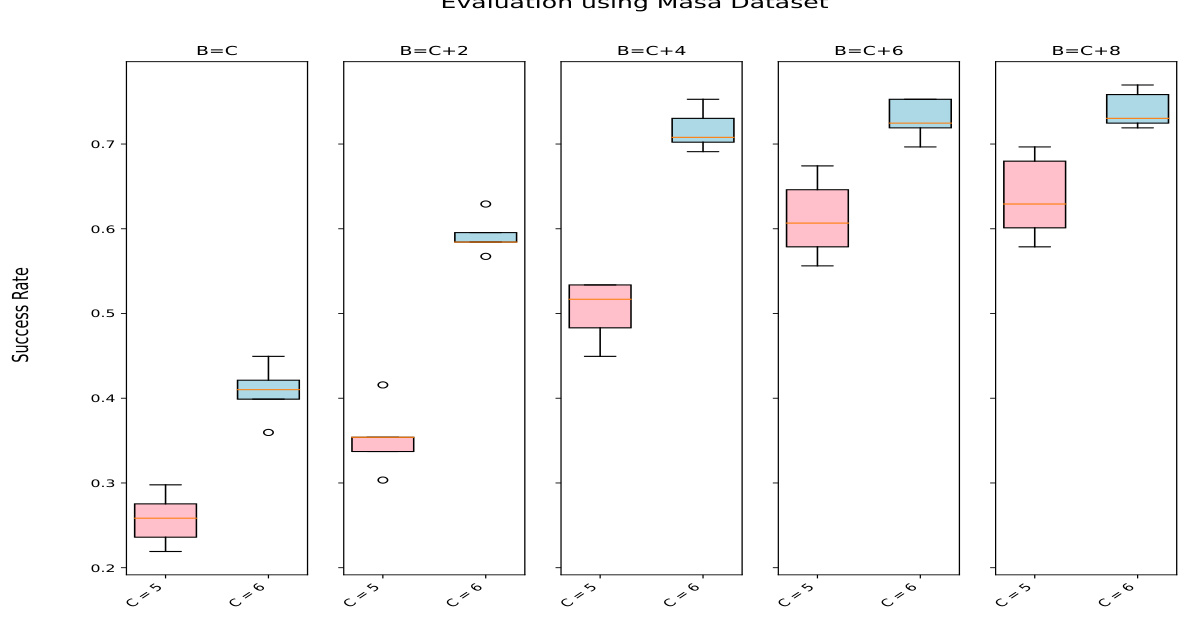
This figure shows the performance of the GOMAA-Geo model across different search budget sizes (B). The x-axis represents different values of C (distance from start to goal) and B (search budget), and the y-axis represents the success rate. The box plot shows the distribution of success rates across multiple independent trials for each configuration. For both C=5 and C=6, the success rate generally increases as the search budget B increases.

The figure shows the GOMAA-Geo framework, illustrating its components: CLIP-MMFE for multi-modal feature extraction, GASP (Goal-Aware Supervised Pretraining) for LLM pre-training, and the actor-critic network for planning. The framework enables the agent to learn a goal-conditioned latent representation using historical data and goal specifications. The trained model can generalize to different goal modalities (text, ground-level, aerial images).

This figure shows the geographical distribution of the 73 ground-level images collected for the MM-GAG dataset. The images are sourced from various locations across the globe, indicating a diverse range of geographical contexts represented in the dataset. This diversity is important for evaluating the generalizability of the GOMAA-Geo model to unseen environments and real-world scenarios.
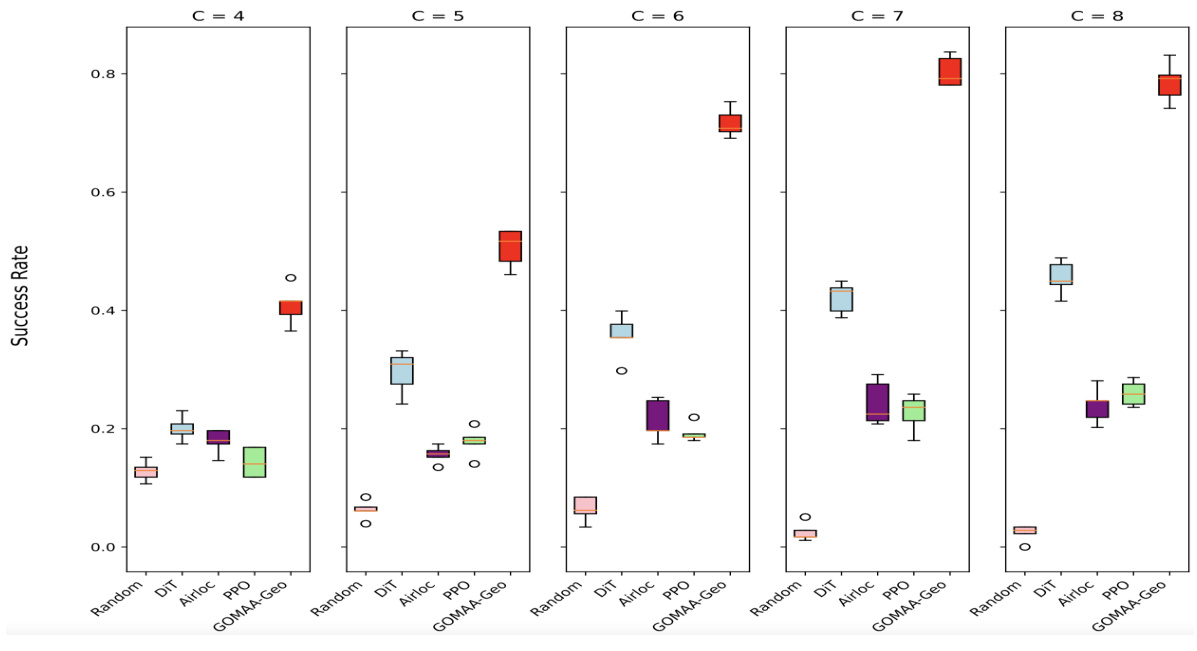
This boxplot visualizes the performance of different active geo-localization methods (Random, DiT, AirLoc, PPO, and GOMAA-Geo) across various start-to-goal distances (C = 4, 5, 6, 7, 8) using the Masa dataset. Each box represents the distribution of success ratios obtained across multiple trials for each method and distance. The boxplot clearly shows that GOMAA-Geo consistently outperforms all other baselines in terms of success rate.

The figure shows the performance comparison of GOMAA-Geo with different baseline methods across different evaluation settings using the Masa dataset. The boxplots represent the distribution of the success ratios obtained from five independent experimental trials for each method across various start-to-goal distances (C). The results show that GOMAA-Geo significantly outperforms all the baseline methods across all evaluation settings.
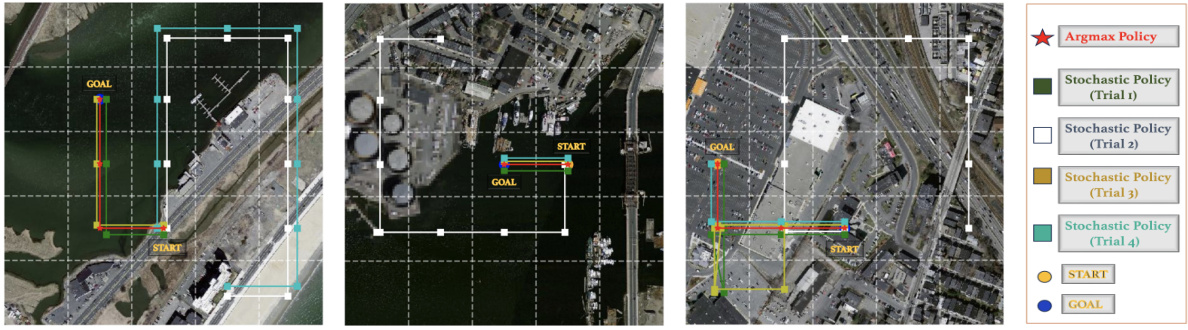
This figure visualizes the exploration behavior of the GOMAA-Geo model across four different goal modalities: aerial image, ground-level image, and natural language text. Each column represents a different goal modality, and each row illustrates the agent’s path (trajectory) during a single trial. The stochastic policy (represented by different colored lines) allows the agent to explore multiple paths probabilistically by selecting actions based on their probabilities. In contrast, the argmax policy uses a deterministic approach, selecting the action with the highest probability at each step. The figure aims to showcase how GOMAA-Geo can handle different goal specifications while learning effective exploration strategies.

The figure shows four examples of how the GOMAA-Geo model explores the environment in order to reach the goal. The goal is represented as a yellow dot in each case. The top row shows the argmax policy, where the agent deterministically chooses the action with the highest predicted probability. The bottom row shows four trials of the stochastic policy, where the agent randomly selects an action, with the probability of each action determined by the policy. The different colors of the trajectories represent the different trials of the stochastic policy. This figure illustrates the stochastic nature of the exploration process and how the agent learns to find the goal effectively.
More on tables
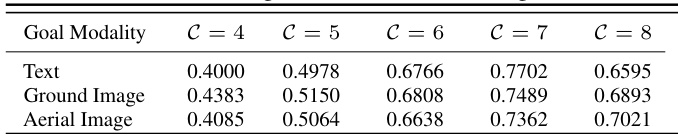
This table presents the success ratio (SR) achieved by GOMAA-Geo across three different goal modalities (text, ground image, and aerial image) for various distances (C) from the start to the goal location. The results highlight GOMAA-Geo’s zero-shot generalization capabilities, demonstrating comparable performance across modalities despite only being trained with aerial image goals.

This table presents the results of a zero-shot generalization experiment. The GOMAA-Geo model, trained only on the Masa dataset with aerial image goals, is evaluated on the xBD-pre and xBD-disaster datasets. The success rate (SR) is reported for various distances (C) between the start and goal locations. The results demonstrate that GOMAA-Geo significantly outperforms several baseline methods in this zero-shot generalization scenario, showing its ability to adapt to unseen environments and goal modalities.

This table compares the performance of the GOMAA-Geo model against a modified version (Mask-GOMAA) where goal information is masked out. It demonstrates the importance of goal information for effective active geo-localization by showing a substantial drop in performance when goal information is removed.

This table compares the performance of GOMAA-Geo and LLM-Geo across various evaluation settings using the Masa dataset. The only distinction between LLM-Geo and GOMAA-Geo is the presence of the planner module in the latter. The results show that the performance of LLM-Geo is significantly inferior to GOMAA-Geo, highlighting the importance of combining an LLM with a planning module.

This table compares the performance of GOMAA-Geo and RPG-GOMAA on the Masa dataset. RPG-GOMAA uses a different LLM pre-training strategy than GOMAA-Geo, using an autoregressive token masking approach instead of GASP. The results show that GOMAA-Geo outperforms RPG-GOMAA across all evaluation settings (different distances from start to goal), demonstrating the effectiveness of the GASP pre-training strategy.

This table compares the performance of GOMAA-Geo against several baseline methods in a zero-shot generalization setting. The evaluation is performed using two datasets, xBD-pre (pre-disaster) and xBD-disaster (post-disaster) with the goal always specified as a pre-disaster aerial image. The results demonstrate GOMAA-Geo’s superior performance across different start-to-goal distances (C) compared to baseline methods like Random, PPO, DiT, and AiRLoc.

This table presents the results of a zero-shot evaluation experiment on a 10x10 grid. The models being evaluated were trained only on the smaller 5x5 grid using the Masa dataset. The goal in this zero-shot experiment is to use the models trained on the smaller grid size and dataset, to successfully perform on a new, larger 10x10 grid with disaster data (xBD-disaster). The table shows success rate (SR) for different distances (C) between start and goal locations. GOMAA-Geo consistently outperforms other methods across all distances.
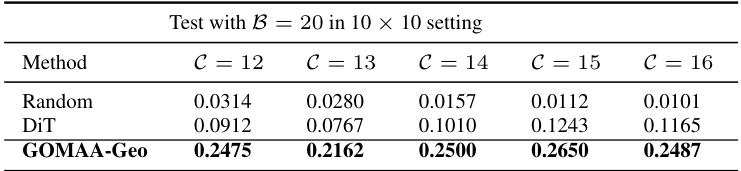
This table presents the results of a zero-shot evaluation on a 10x10 grid using the xBD-disaster dataset. The models used were trained only on the smaller 5x5 grid using the Masa dataset. The table shows that GOMAA-Geo significantly outperforms the other methods (Random, DiT) across different distances (C) from start to goal location.

This table presents the success ratio (SR) achieved by different methods on the geo-localization task using the Massachusetts Buildings dataset, where goals are specified as aerial images. The methods compared are Random policy, PPO, DiT, AiRLoc, and GOMAA-Geo. The SR is shown for varying distances (C) from the starting point to the goal location, representing the difficulty of the task. The results demonstrate that GOMAA-Geo outperforms all other methods across all evaluated distances.

This table compares the performance of GOMAA-Geo and RPG-GOMAA on the xBD-disaster dataset in a zero-shot generalization setting. Both models were trained on the Masa dataset, but evaluated on the xBD-disaster dataset where the goal is presented as pre-disaster top-view imagery. The results demonstrate the importance of the GASP strategy for achieving robust performance in zero-shot generalization scenarios.

This table shows the results of an experiment comparing the performance of two policies trained with different sampling strategies (random vs. uniform). The evaluation includes both pre-disaster (Masa) and post-disaster (xBD) datasets, providing an assessment of the policies’ zero-shot generalization capability. The results indicate that the uniform sampling strategy leads to superior performance.

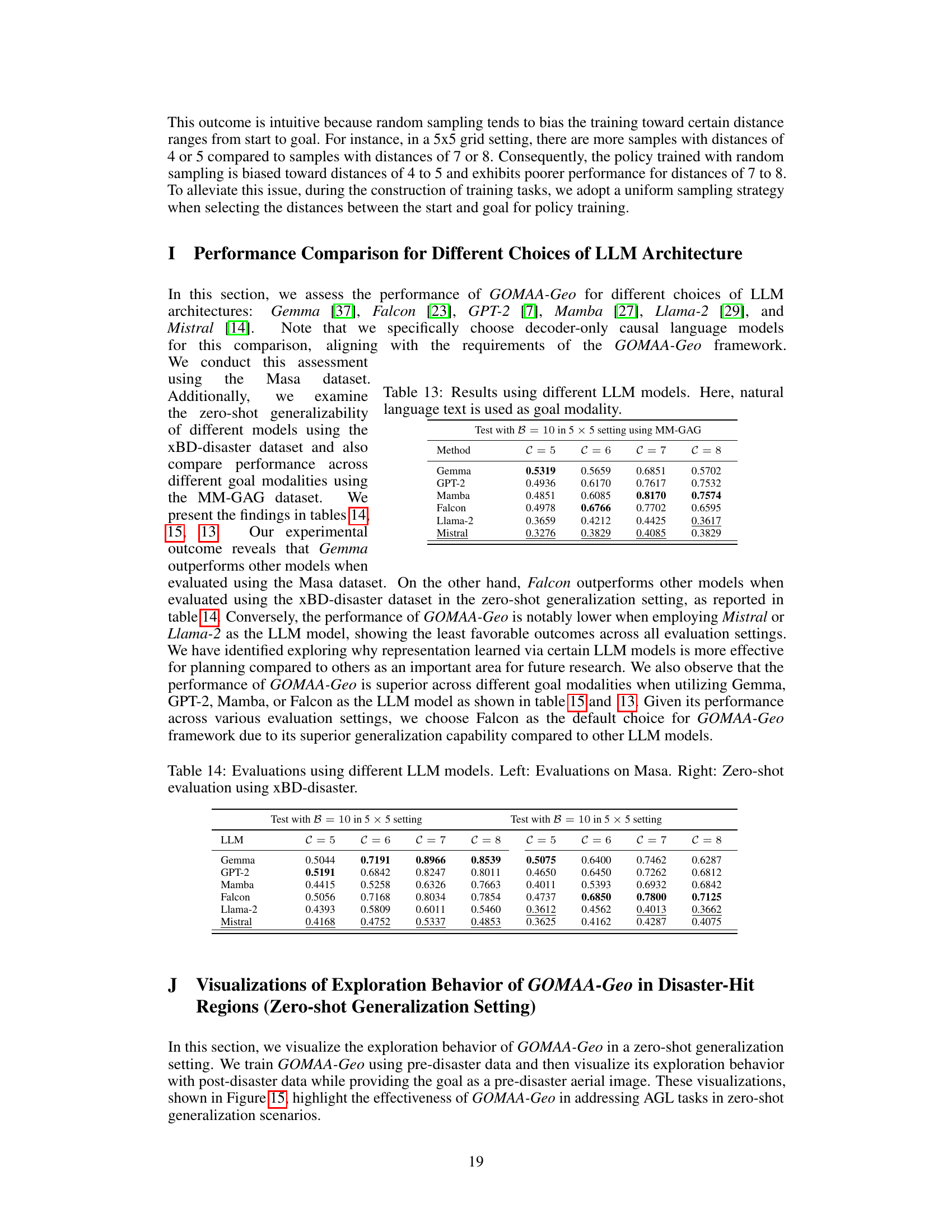
This table presents the results of experiments evaluating the performance of GOMAA-Geo using different Large Language Models (LLMs) with natural language text as the goal modality. The results are broken down by different distances (C) between the starting point and the goal location. The table allows for a comparison of the efficacy of various LLMs within the GOMAA-Geo framework.
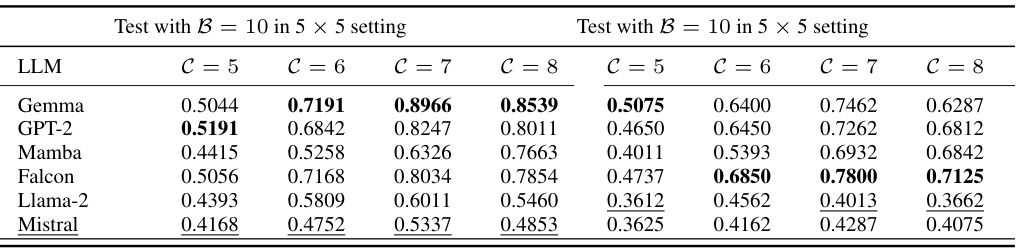
This table presents the results of experiments evaluating the performance of GOMAA-Geo using different Large Language Models (LLMs) on the MM-GAG dataset. The MM-GAG dataset allows for the specification of goals using different modalities (ground-level images and aerial images). The table is split into two sections: the left section shows results when goals are specified as ground-level images, and the right section shows results when goals are specified as aerial images. The results are presented for different distances (C) from the starting point to the goal location. This allows for an assessment of the model’s performance across various conditions.

This table presents the results of evaluating GOMAA-Geo’s performance using different Large Language Models (LLMs) on the MM-GAG dataset. It is split into two sections: one for ground-level image goals and one for aerial image goals. The table shows the success ratio (SR) achieved by GOMAA-Geo with different LLMs across various evaluation settings, demonstrating the model’s performance across different goal modalities.

This table presents the success rates (SR) achieved by different methods on the active geo-localization task, specifically when the goals are specified as aerial images. It compares the performance of GOMAA-Geo against baseline methods such as Random Policy, PPO, DiT, and AiRLoc across various distances (C) between the start and goal locations. The results demonstrate the superior performance of GOMAA-Geo in achieving higher success rates compared to other methods.
Full paper#