TL;DR#
Current road network representation learning methods primarily focus on proximity (First Law of Geography), neglecting geographic configuration similarity. This limitation hinders accuracy in applications like traffic prediction and route planning. Existing methods struggle to capture complex urban environments and long-range relationships between road segments, limiting their effectiveness.
To address this, Garner introduces a novel graph contrastive learning framework. It leverages street view images to understand geographic configurations, employs configuration-aware graph augmentation and spectral negative sampling, and integrates both the First and Third Laws of Geography using a dual contrastive learning objective. This approach significantly improves downstream task performance compared to baselines, showcasing the importance of considering geographic configurations for accurate road network representation.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses limitations in existing road network representation learning methods by integrating the Third Law of Geography. This novel approach significantly improves the accuracy of downstream tasks like road function prediction and traffic inference, paving the way for more efficient and effective smart city applications. The use of street view images and a dual contrastive learning objective are also valuable contributions, potentially impacting various related fields.
Visual Insights#
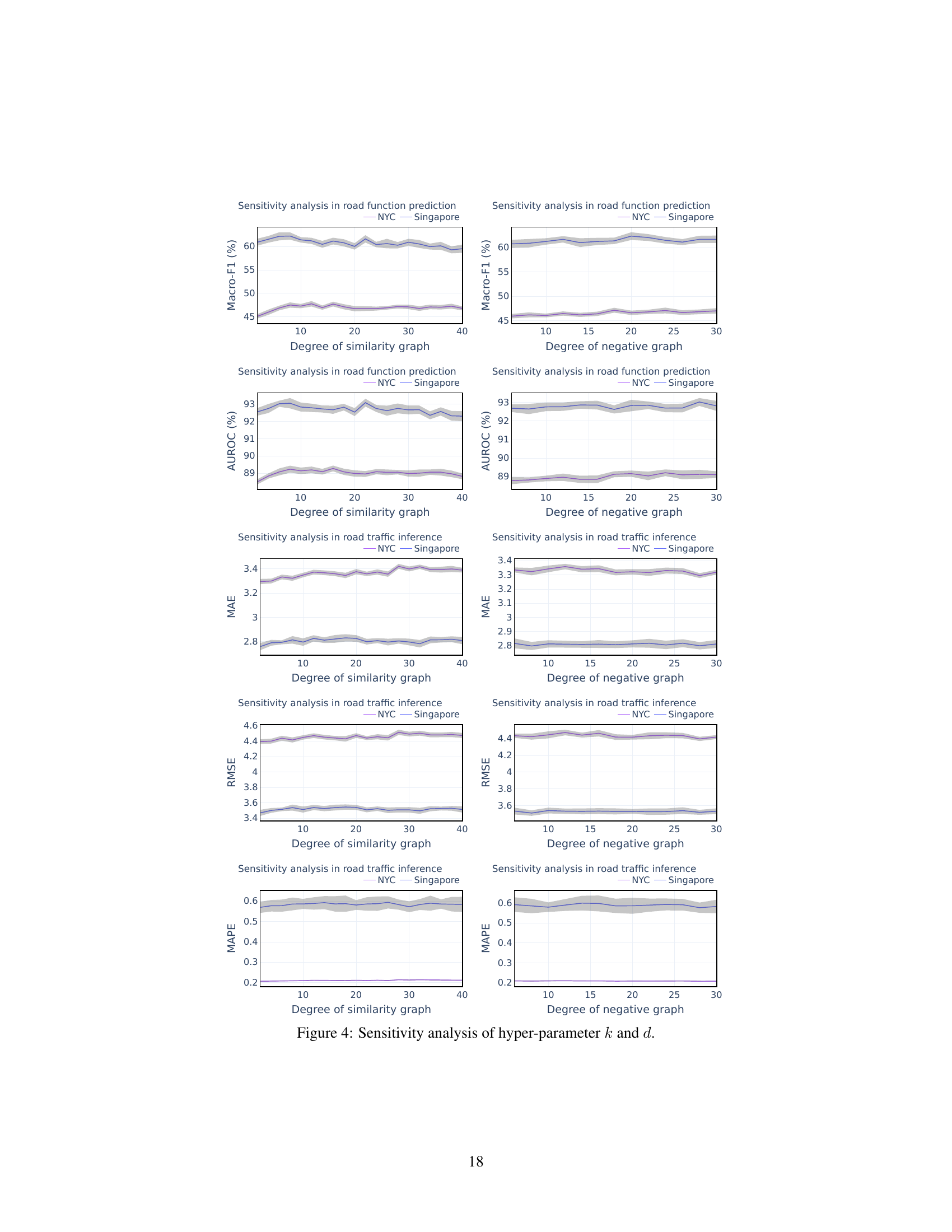
🔼 This figure shows the architecture of the proposed Garner framework. It consists of three main components: Data preprocessing, Graph augmentation, and Graph contrastive loss. The Data preprocessing component takes street view images and road network data as input and produces initial road features. The Graph augmentation component generates augmented graphs according to the Third Law of Geography and the First Law of Geography. The Graph contrastive loss component then takes the augmented graphs and original graph as input and learns road representations by maximizing the mutual information between the different views. The framework also includes a dual contrastive learning objective to harmonize the effects of the First and Third Laws of Geography. The output is a road segment representation that aligns with both laws.
read the caption
Figure 1: Architecture of Geographic law aware road network representation learning (Garner).
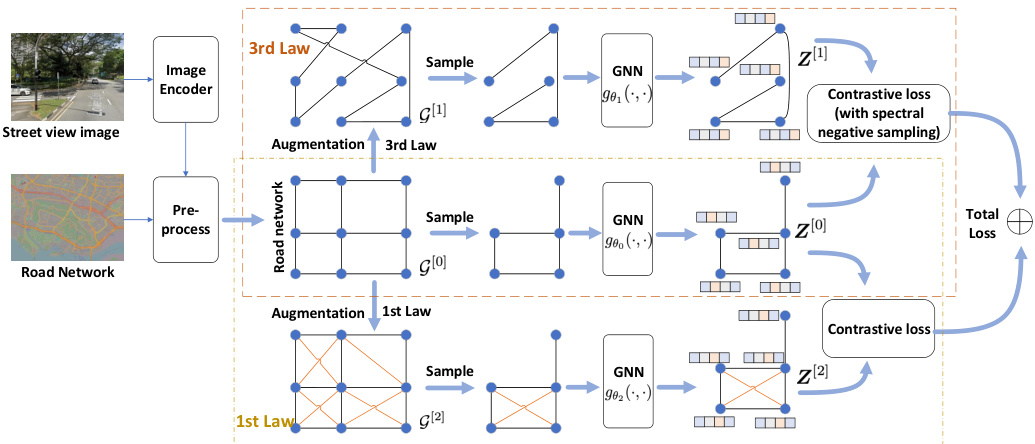
🔼 This table presents the statistics of the datasets used in the paper. It shows the number of roads, edges, and street view images (SVIs) available for each city included in the study: Singapore and New York City (NYC).
read the caption
Table 1: Dataset Statistics
In-depth insights#
Third Law Impact#
Analyzing the impact of the Third Law of Geography on road network representation learning reveals significant improvements in downstream tasks. The integration of this law, which emphasizes the importance of similar geographic configurations yielding similar representations, addresses limitations of existing methods that primarily focus on distance. This is particularly evident in tasks such as road function prediction and traffic inference, where nuanced geographic contexts significantly influence the target variable. While the study demonstrates a clear advantage, further investigation is needed to explore its limitations, especially regarding data scarcity and the generalizability to diverse urban settings. The synergistic combination of the First and Third Laws within the proposed model represents a novel and promising approach, showcasing the potential of integrating multiple geographic principles for enhanced representation learning.
Garner Framework#
The Garner framework, as described in the research paper, is a novel approach to road network representation learning that leverages the principles of both the First and Third Laws of Geography. Its core innovation lies in integrating the Third Law, which emphasizes the importance of similar geographic configurations leading to similar representations, with the widely used First Law, which focuses on proximity. The framework achieves this using geographic configuration-aware graph augmentation, incorporating street view imagery to capture contextual information, and spectral negative sampling for contrastive learning. This dual contrastive learning objective ensures a balanced representation that reflects both spatial proximity and geographic context. The use of Simple Graph Convolution (SGC) as an encoder facilitates the harmonization of these two laws, resulting in improved performance across downstream tasks such as road function prediction, traffic inference, and visual retrieval. The framework’s design addresses limitations of existing methods by moving beyond a sole reliance on distance-based similarity. The results demonstrate the significance of integrating the Third Law for a more comprehensive and effective road network representation.
Geo-Aware Augmentation#
The concept of “Geo-Aware Augmentation” in the context of road network representation learning involves enhancing graph data with geographical information to improve model accuracy. This approach moves beyond simply using proximity as a feature, as it integrates richer contextual information about the spatial relationships between road segments. It acknowledges the limitations of methods that rely solely on the First Law of Geography (proximity-based relationships) by incorporating principles from the Third Law (geographic configuration similarity). Geo-aware augmentation strategies could involve constructing augmented graphs where edges connect road segments with similar geographic contexts, regardless of their physical distance. This might involve using street view imagery to analyze surroundings and creating connections between similar contexts. The augmentation aims to generate more informative graph representations that capture both local and global relationships within the network, potentially leading to improved performance in various downstream tasks such as traffic prediction or route planning. The success of this approach relies heavily on the quality and type of geographical data used for augmentation as well as the design of the graph augmentation strategy.
Dual Contrastive Loss#
The concept of “Dual Contrastive Loss” in the context of road network representation learning presents a compelling approach to reconcile seemingly disparate principles. By incorporating both the First Law (proximity matters) and the Third Law (similar geographic configurations yield similar representations) of Geography, this dual loss function aims to create more robust and comprehensive road segment embeddings. The dual nature likely involves contrasting two distinct views of the road network: one reflecting topological proximity (First Law), and another reflecting geographic context derived from street view imagery or similar data (Third Law). The framework would simultaneously learn to maximize agreement between these views where appropriate, promoting spatial consistency, while also enforcing divergence where necessary, capturing the nuanced variations dictated by geographic context. Effective implementation hinges on carefully balancing the contributions of each loss component to prevent one law from dominating the representation, leading to potentially skewed or incomplete information. The use of a dual loss would likely result in representations that capture both local and global contextual information, improving performance on downstream tasks such as traffic forecasting and route planning.
Future Directions#
Future research could explore several promising avenues. Expanding the framework to encompass additional geographic laws beyond the First and Third could lead to even richer and more nuanced road network representations. Investigating the impact of different data sources, such as incorporating real-time traffic data or sensor readings, would offer opportunities to improve accuracy and real-world applicability. Further research could focus on developing more sophisticated graph augmentation techniques, exploring alternative methods to capture complex relationships between road segments. Finally, extensive comparative studies are needed against a wider range of baselines and across diverse downstream applications to rigorously validate the proposed framework’s generalizability and effectiveness.
More visual insights#
More on figures

🔼 The figure presents a detailed architecture of the Geographic Law-aware Road Network Representation Learning (Garner) framework. It illustrates the data preprocessing steps, involving the use of street view images to capture geographic configurations. The graph augmentation process, which generates graphs adhering to the Third Law of Geography, is also depicted. The core of the framework is a Graph Neural Network (GNN) encoder that derives road representations from both original and augmented graphs. The figure highlights the dual contrastive learning objective which harmonizes the implications of the First and Third Laws of Geography, resulting in a comprehensive road network representation.
read the caption
Figure 1: Architecture of Geographic law aware road network representation learning (Garner).

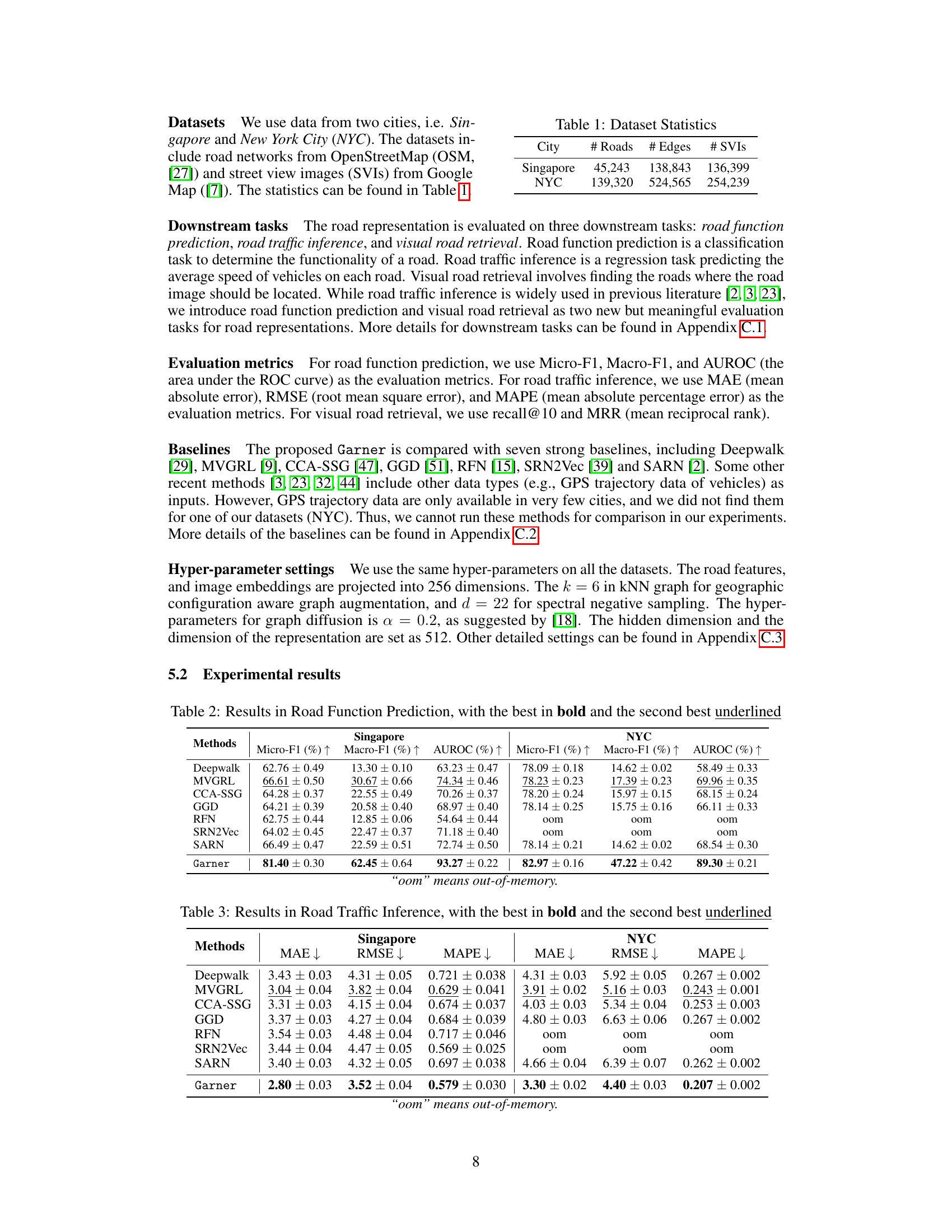
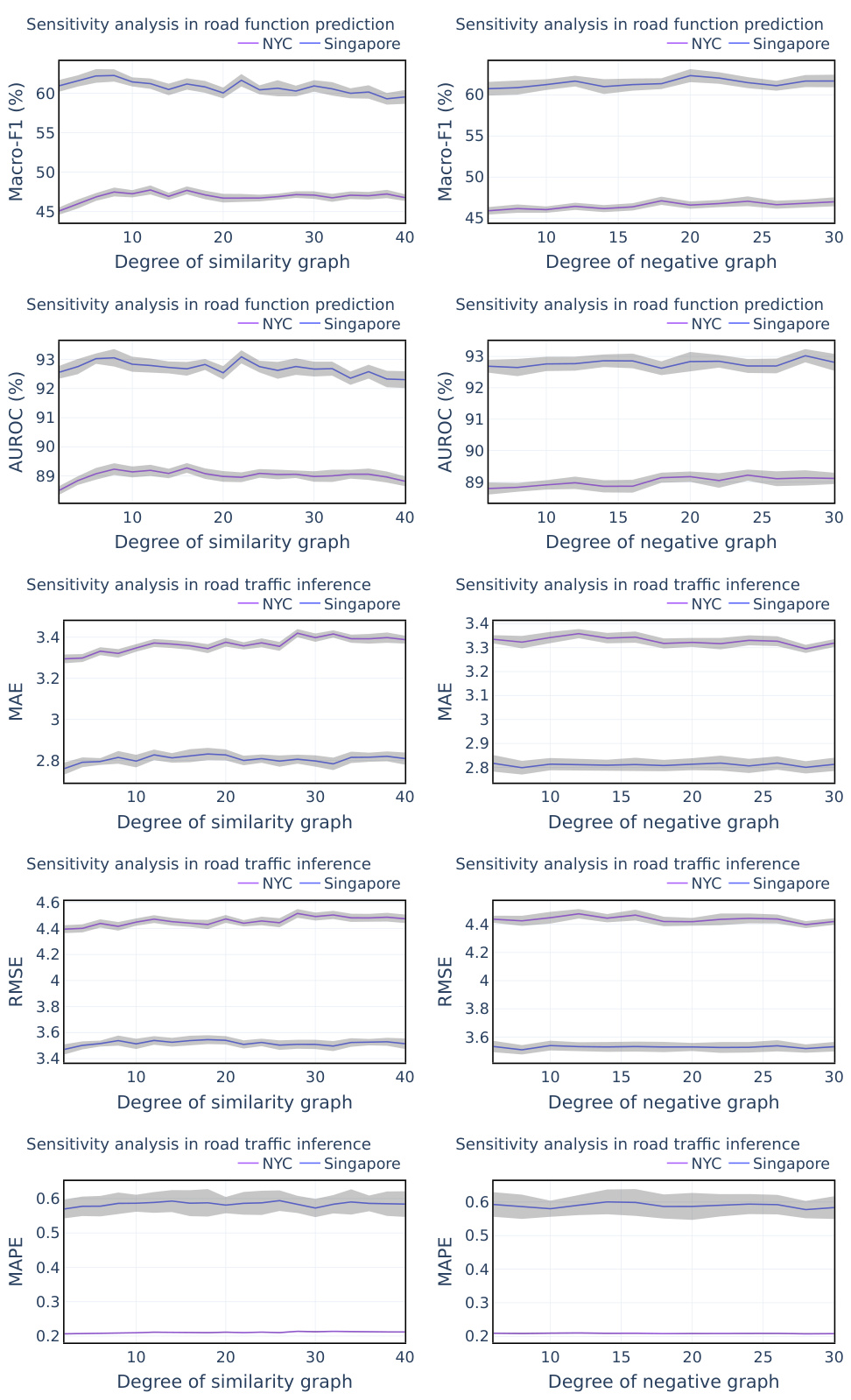
🔼 This figure shows the sensitivity analysis of two hyperparameters: the degree (k) of the augmented KNN similarity graph and the degree (d) of the negative graph. The results are shown as Micro-F1 scores for road function prediction on two datasets, Singapore and NYC, with error bars representing the standard deviation. The x-axis represents the values of k and d, respectively, and the y-axis shows the Micro-F1 score. The plots demonstrate the robustness of the model to changes in these hyperparameters, indicating that performance is relatively stable across a range of values.
read the caption
Figure 3: Sensitivity analysis of hyper-parameter k and d.
🔼 This figure presents a detailed architecture of the Geographic Law-aware road network representation learning (Garner) framework. It illustrates the data preprocessing steps, graph augmentation techniques that incorporate both the First and Third Laws of Geography, the GNN encoder that processes the augmented and original graphs, and the dual contrastive learning objective that harmonizes both laws. The figure shows the flow of data from street view images (SVIs) to the final road segment representations, highlighting the key components and their interactions within the framework.
read the caption
Figure 1: Architecture of Geographic law aware road network representation learning (Garner).
More on tables
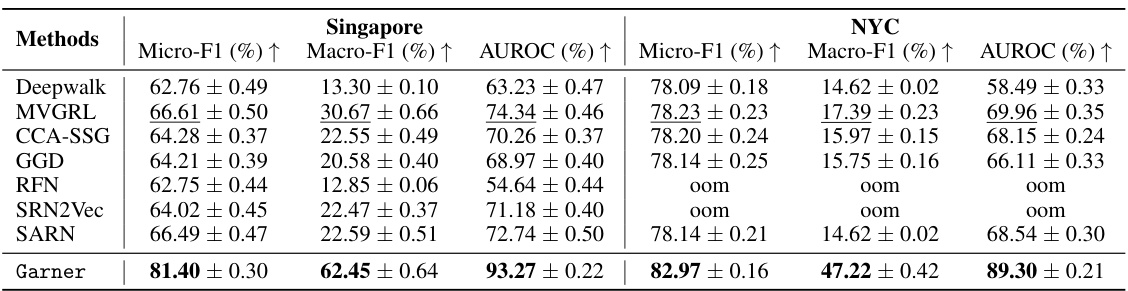
🔼 This table presents the results of the road function prediction task on two datasets (Singapore and NYC). It compares the performance of the proposed Garner model against several baseline methods (Deepwalk, MVGRL, CCA-SSG, GGD, RFN, SRN2Vec, SARN). The evaluation metrics are Micro-F1, Macro-F1, and AUROC, which measure the model’s ability to classify the function of road segments accurately. The best performing model in each category is highlighted in bold, with the second best underlined. The results show that Garner significantly outperforms all the baselines.
read the caption
Table 2: Results in Road Function Prediction, with the best in bold and the second best underlined
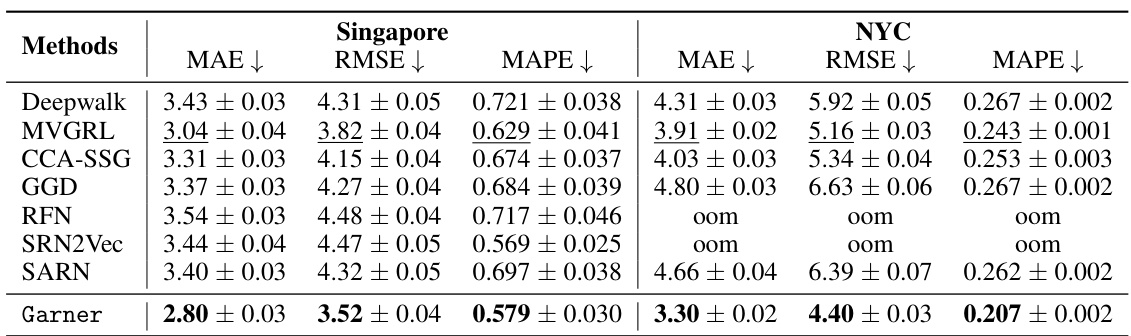
🔼 This table presents the results of three different metrics (MAE, RMSE, MAPE) used to evaluate the performance of various methods in predicting road traffic inference. The results are shown for two different cities, Singapore and NYC. The table helps to compare the accuracy and effectiveness of different approaches in this specific task, highlighting the best-performing method (Garner) in bold.
read the caption
Table 3: Results in Road Traffic Inference, with the best in bold and the second best underlined
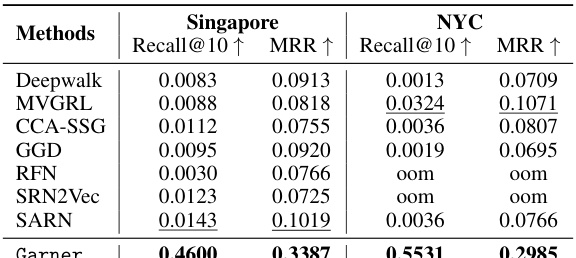
🔼 This table presents the results of visual road retrieval experiments using different methods. The best performing method is highlighted in bold, and the second-best method is underlined. The evaluation metrics used are Recall@10 and MRR (Mean Reciprocal Rank). Results are shown separately for Singapore and New York City datasets.
read the caption
Table 4: Results on Visual Road Retrieval, with the best in bold and the second best underlined

🔼 This table presents the results of ablation studies conducted on the road function prediction task. It shows the impact of removing various components of the proposed Garner model, such as the street view images (SVIs), the geographic configuration-aware graph augmentation, and the spectral negative sampling. The results are reported in terms of Micro-F1, Macro-F1, and AUROC scores for both the Singapore and NYC datasets, demonstrating the contribution of each component to the overall performance.
read the caption
Table 5: Ablation studies on Road Function Prediction

🔼 This table presents the ablation study results on road function prediction using different similarity measures for building the augmented graph. The results are shown for both the Singapore and NYC datasets, evaluating the performance across Micro-F1, Macro-F1, and AUROC metrics. This analysis aims to understand the impact of the chosen similarity measure on the model’s performance in road function prediction.
read the caption
Table 6: Ablation studies of similarity measures on Road Function Prediction

🔼 This table presents the results of ablation studies conducted on the road traffic inference task. It shows the MAE, RMSE, and MAPE metrics for different versions of the Garner model, each with a component removed (street view images, graph augmentation, spectral negative sampling). This allows for an assessment of the contribution of each component to the overall performance on this task. The results are presented for both the Singapore and NYC datasets.
read the caption
Table 7: Ablation studies on Road Traffic Inference
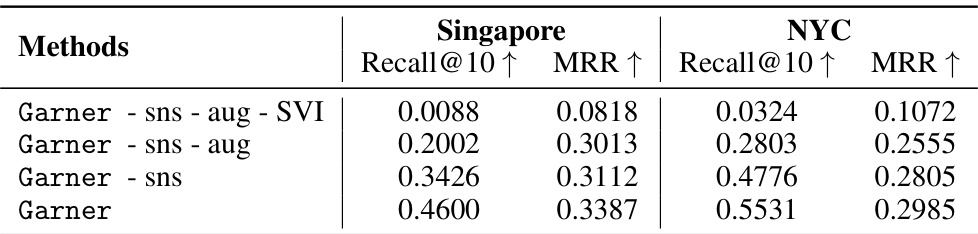
🔼 This table presents the results of visual road retrieval experiments on two datasets, Singapore and NYC. The results are broken down by method, showing the Recall@10 and Mean Reciprocal Rank (MRR) metrics. The best performing method for each metric on each dataset is shown in bold, while the second-best is underlined. This demonstrates the performance of different road network representation learning methods in a visual retrieval task, where the goal is to identify the road segments corresponding to a given image.
read the caption
Table 4: Results on Visual Road Retrieval, with the best in bold and the second best underlined
Full paper#