TL;DR#
Large language model (LLM) instruction fine-tuning requires substantial high-quality data, but current methods often lack efficiency and data transferability across models. Acquiring such data is expensive and requires significant computational resources, limiting broader applications. This creates a critical need for efficient data selection methods.
The paper proposes SHED, a Shapley value-based automated dataset refinement framework. SHED uses model-agnostic clustering and a proxy-based Shapley calculator to efficiently evaluate data subsets. SHED’s optimization-aware sampling selects subsets maximizing the performance-diversity tradeoff. Experimental results demonstrate SHED’s superiority over existing methods across various LLMs. Notably, SHED-selected datasets comprising only 10% of the original data achieve comparable or superior performance, highlighting its significant contribution to efficient and effective LLM instruction fine-tuning.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel solution to the data efficiency problem in instruction fine-tuning of LLMs. It introduces a computationally efficient method to select high-quality data, improving model performance and reducing costs. This is crucial given the current limitations in access to high-end computational resources for LLM training. The transferability of the selected datasets across different LLMs further enhances its practical significance.
Visual Insights#

🔼 This figure illustrates the workflow of the SHED (Shapley-based automated dataset refinement) framework. It starts with an original dataset, which is then processed through three main stages: 1) Model-agnostic clustering groups similar data points together. 2) A proxy-based Shapley calculator efficiently estimates the contribution of each cluster to the overall model performance. 3) Optimization-aware sampling selects a subset of data points from the clusters to create a curated dataset that is smaller but of higher quality. The final output is a curated dataset that can be used for instruction fine-tuning.
read the caption
Figure 1: Overview of SHED.

🔼 This table presents the performance of the LLaMA-7B model fine-tuned on three different datasets created from the MMLU dataset: a high-quality dataset selected using DSIR, a random dataset, and a mixed dataset combining samples from the high-quality and random datasets. The performance is measured using the MMLU test set, showing the accuracy achieved by each dataset.
read the caption
Table 1: We apply DSIR [50] to compile a high-quality dataset (10k instances), a random dataset (10k instances) from MMLU, and a mixed dataset samples 5k instances from each of the high-quality and random datasets. We fine-tune the LLaMA-7B model [3] on the curated dataset and evaluate them using the MMLU test set.
In-depth insights#
Shapley Value in LLMs#
The application of Shapley values to Large Language Models (LLMs) presents a novel approach to understanding and improving model performance and data efficiency. Shapley values offer a unique way to quantify the contribution of individual data points within a training dataset, moving beyond simpler metrics that consider only isolated instances. This allows for the identification of data points that are highly impactful and those that are redundant or harmful. By assigning a Shapley value to each data point, we can better understand which data contributes the most to overall performance, leading to more effective data selection and refinement methods. This is particularly valuable for instruction fine-tuning, where high-quality data is crucial but often scarce. The use of Shapley values in this context allows for the creation of smaller, higher-quality datasets, thus reducing the computational cost and time associated with training LLMs. However, calculating Shapley values for large datasets can be computationally expensive, making approximate methods or clever data sampling techniques essential for practical application. Future research in this area could explore different approximation methods, ways to handle the inherent computational complexity, and the potential impact on bias and fairness in LLMs.
SHED Framework#
The SHED framework, a novel automated dataset refinement approach, addresses the challenge of efficiently curating high-quality datasets for instruction fine-tuning of large language models (LLMs). Its core innovation lies in leveraging Shapley values to assess the contribution of individual data points, but instead of directly computing values for each data point, which is computationally expensive, it employs a three-stage process: model-agnostic clustering, proxy-based Shapley calculation, and optimization-aware sampling. This strategy significantly reduces computational cost while maintaining effectiveness. The framework’s model-agnostic nature enables adaptability across various LLMs, and its flexibility allows for customization of the optimization objectives. Furthermore, the datasets produced by SHED demonstrate high transferability, showcasing robust performance even when used with different LLMs or for various downstream tasks, ultimately leading to more efficient and effective LLM fine-tuning.
Dataset Transferability#
Dataset transferability, in the context of large language model (LLM) fine-tuning, refers to the ability of a dataset curated for one LLM to effectively improve the performance of other, potentially different, LLMs. This is a crucial concept because creating high-quality datasets is resource-intensive, and the ability to reuse them across various models significantly reduces the cost and effort associated with LLM adaptation. A high degree of transferability implies that the selected data captures fundamental aspects of the task, rather than being overly specialized for a specific model architecture or training dynamics. Factors influencing transferability could include the diversity and quality of the data, how well it represents the task’s underlying characteristics, and the choice of data selection methodology. Demonstrating dataset transferability often involves fine-tuning multiple LLMs on the same curated dataset and comparing the results against those obtained with other datasets or methods. Successful transferability validates the generalizability of a data selection process, thereby promoting efficiency and reducing research costs across the LLM community. However, it is vital to acknowledge that the extent of transferability might vary depending on the models involved and the specific nature of the downstream tasks. Future research should explore ways to further understand and improve dataset transferability, maximizing the value of curated datasets and minimizing the computational resources dedicated to LLM training.
Computational Efficiency#
The paper’s core innovation lies in enhancing computational efficiency during dataset refinement for instruction fine-tuning. This is achieved primarily through a proxy-based Shapley value calculation, which dramatically reduces computational complexity by operating on cluster representatives rather than individual data points. Model-agnostic clustering further optimizes this by grouping similar data instances, allowing for efficient evaluation of representative samples. The choice of using smaller LLMs for data selection further reduces computational costs while maintaining strong transferability of the selected datasets to larger models, suggesting a cost-effective approach. This strategy is particularly valuable because fine-tuning LLMs is computationally expensive, and this approach significantly reduces resource requirements while maintaining high performance. However, the approximation inherent in the proxy-based Shapley calculation introduces a trade-off between computational efficiency and accuracy; the optimal balance requires careful hyperparameter tuning as demonstrated in the experiment’s varying cluster counts and iteration numbers.
Future Work#
Future research directions stemming from this Shapley-based dataset refinement method (SHED) could explore several key areas. Extending SHED’s capabilities to handle diverse data modalities beyond text, such as images or audio, would significantly broaden its applicability and impact. Investigating more sophisticated clustering techniques than K-means, potentially incorporating domain knowledge or task-specific features into the clustering process, could improve the quality and efficiency of data subset selection. A particularly valuable area would involve developing a more robust and efficient Shapley value approximation algorithm, as this remains a computational bottleneck for very large datasets. A thorough investigation into the generalizability of SHED across different LLMs and downstream tasks is necessary to confirm its widespread utility and potential limitations. Finally, exploring alternative optimization objectives, beyond simple accuracy, to guide data selection (e.g., fairness, robustness, explainability) would make SHED a more versatile and ethically responsible tool.
More visual insights#
More on figures
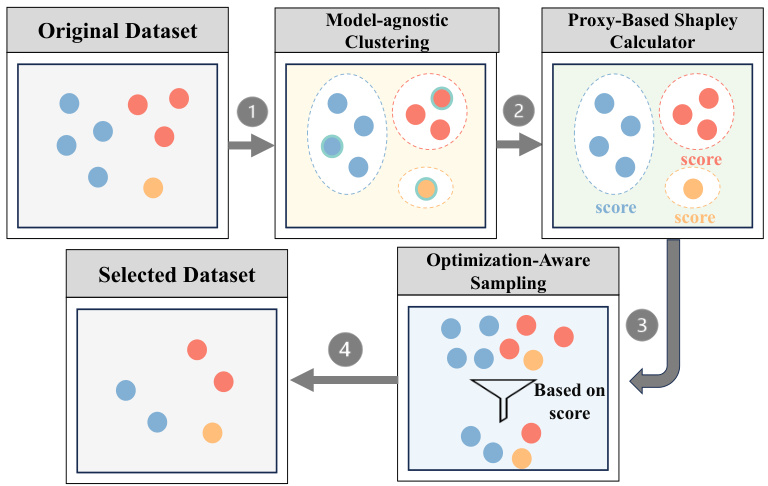
🔼 This figure illustrates the workflow of the SHED (Shapley-based automated dataset refinement) framework. It consists of four main stages: 1. Model-agnostic clustering groups similar data points together using embeddings from sentence transformers. 2. A proxy-based Shapley calculator then efficiently approximates the Shapley values (importance scores) for the representative data points within each cluster, focusing on task-specific objectives. 3. Optimization-aware sampling is then used to select data from the clusters based on their calculated Shapley values, considering both quality and diversity. 4. Finally, the selected dataset, a smaller subset of the original dataset, is formed, which is expected to achieve comparable performance to the original, larger dataset when used to fine-tune LLMs.
read the caption
Figure 2: Workflow of SHED: ① Clustering and determining proxy data; ② Calculating Shapley values as scores; ③ Sampling based on scores; and ④ Forming the selected dataset.

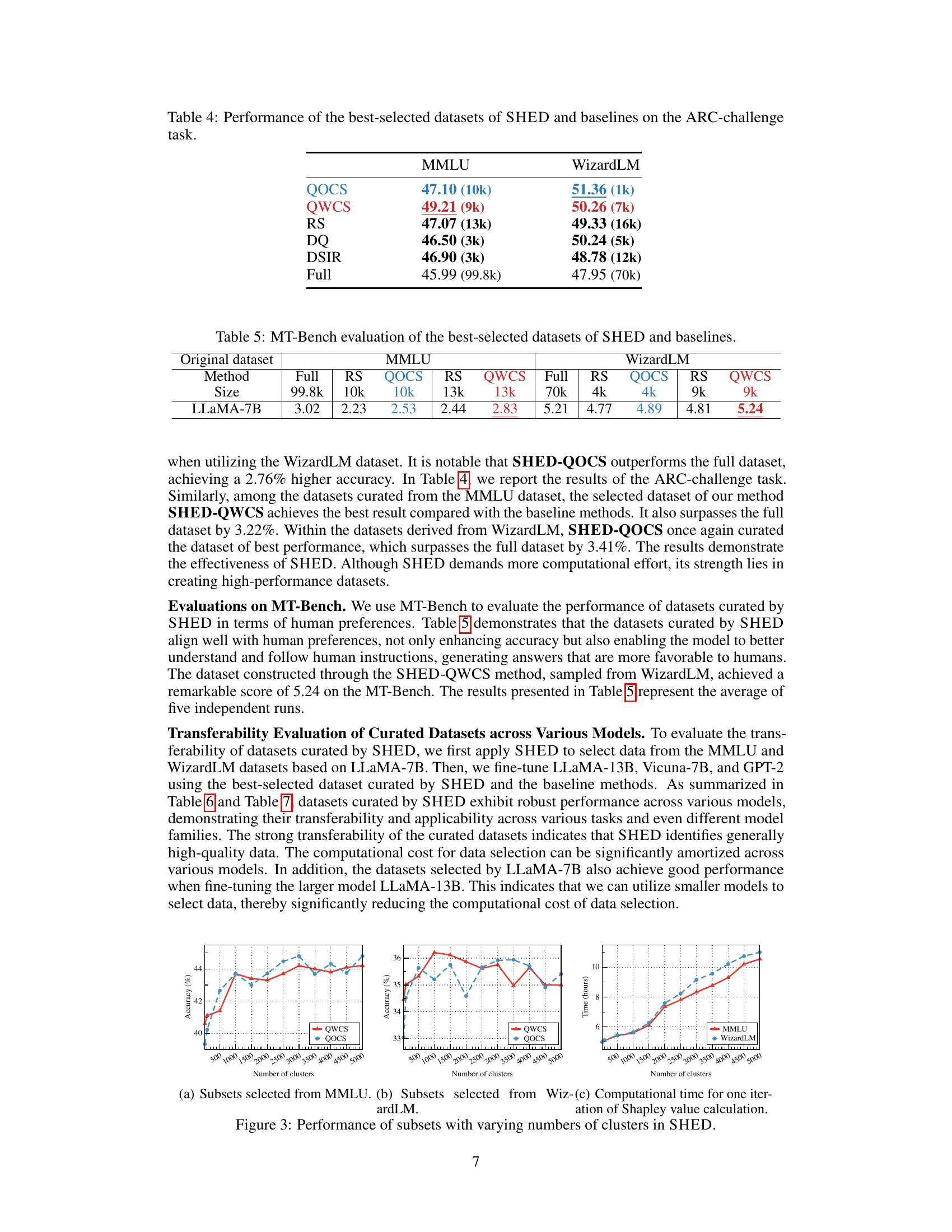
🔼 This figure shows the performance of datasets curated by SHED using different numbers of clusters. The left panel displays the accuracy on the MMLU test set, with the middle panel showing accuracy on the ARC-challenge test set. Both panels compare the Quality-Ordered Cluster Sampling (QOCS) and Quality-Weighted Cluster Sampling (QWCS) methods across a range of cluster counts. The right panel illustrates the computational time (in hours) required for the Shapley value calculation for datasets curated from MMLU and WizardLM, again demonstrating the trade-off between accuracy and computational cost as the number of clusters increases. The plots reveal the effect of increasing the number of clusters on the performance of different sampling strategies used in SHED. The results show that increasing the number of clusters beyond a certain point does not significantly increase the accuracy and increases the computation time.
read the caption
Figure 3: Performance of subsets with varying numbers of clusters in SHED.
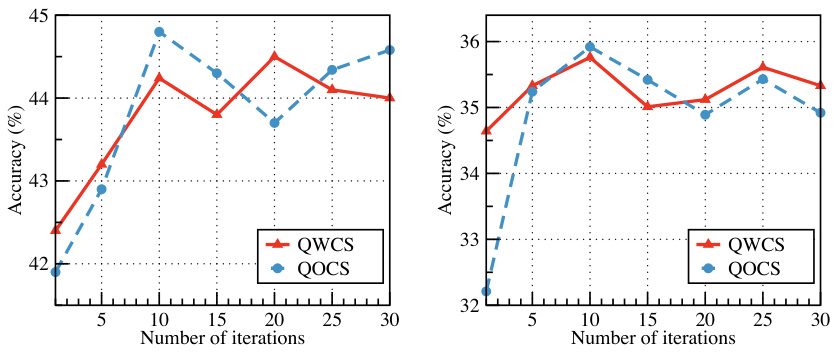
🔼 This figure shows the performance of SHED’s curated datasets with varying numbers of clusters used in the model-agnostic clustering step. The left panel displays results using the MMLU dataset, while the right shows results using the WizardLM dataset. Both panels show accuracy on the MMLU (left) and ARC-Challenge (right) test sets for both QOCS (Quality-Ordered Cluster Sampling) and QWCS (Quality-Weighted Cluster Sampling) methods. The x-axis represents the number of clusters, and the y-axis represents accuracy. The plot demonstrates how performance changes as the number of clusters increases, helping to determine the optimal number of clusters for SHED. The results show that there’s an optimal range for the number of clusters where both QOCS and QWCS achieve high accuracy, before performance plateaus or decreases.
read the caption
Figure 3: Performance of subsets with varying numbers of clusters in SHED.

🔼 This figure illustrates the workflow of the SHED algorithm. It starts with the original dataset and performs model-agnostic clustering to group similar data points. Then, it calculates Shapley values for representative samples (proxy data) within each cluster. These Shapley values serve as quality scores. Finally, the algorithm employs optimization-aware sampling (QOCS or QWCS) based on these scores to select a subset of data points forming the curated dataset.
read the caption
Figure 2: Workflow of SHED: ① Clustering and determining proxy data; ② Calculating Shapley values as scores; ③ Sampling based on scores; and ④ Forming the selected dataset.
More on tables

🔼 This table presents a comparison of the performance of datasets curated using different methods, including SHED (with Quality-Ordered Cluster Sampling (QOCS) and Quality-Weighted Cluster Sampling (QWCS)), Random Sampling (RS), Dataset Quantization (DQ), and Data Selection with Importance Resampling (DSIR). The performance is evaluated on two tasks: MMLU and ARC-challenge, using two original datasets: MMLU and WizardLM. The goal is to demonstrate SHED’s superiority in creating high-quality, smaller datasets compared to existing methods. The table shows the performance achieved when using the same number of samples from the various curated datasets for fine-tuning.
read the caption
Table 2: Performance comparison of curated datasets of the same size by SHED and baseline methods.
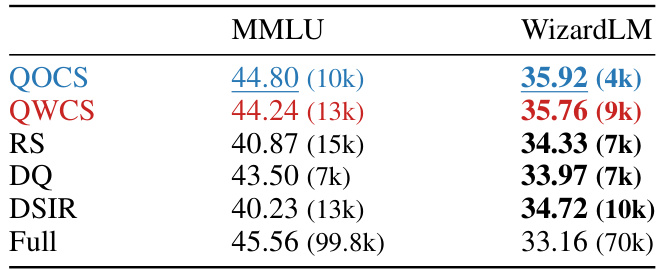
🔼 This table compares the performance of the best-performing dataset selected by SHED and several baseline methods (RS, DQ, DSIR, and using the full dataset) on the MMLU benchmark. The best-selected dataset for each method is the one that achieved the highest performance across various sample sizes tested for that particular method. The table shows the accuracy achieved by each method’s best-performing dataset on the MMLU task, along with the size of that dataset in parentheses.
read the caption
Table 3: Performance of the best-selected datasets of SHED and baseline methods on the MMLU task.
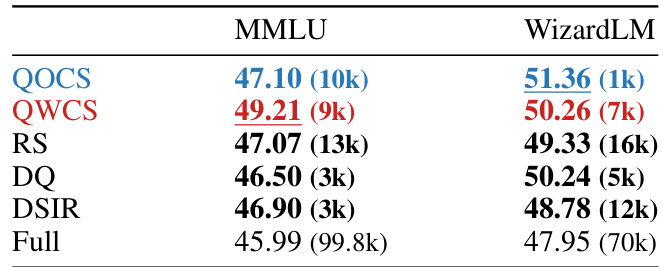
🔼 This table presents a comparison of the performance achieved by SHED (with QOCS and QWCS sampling methods), and three baseline methods (RS, DQ, DSIR) on the ARC-challenge task. The performance metric is not explicitly defined but is presumed to be accuracy, given the context. The results are shown for both the MMLU and WizardLM datasets. For each method, the size of the best-performing curated dataset (in number of instances) is indicated in parentheses. The ‘Full’ row shows the performance achieved when training on the full original dataset, providing a baseline for comparison.
read the caption
Table 4: Performance of the best-selected datasets of SHED and baselines on the ARC-challenge task.

🔼 This table presents the results of evaluating the best-performing datasets selected by SHED and baseline methods using MT-Bench. MT-Bench assesses the human preference for the model’s generated responses, evaluating aspects such as quality and alignment with human expectations. The table shows the scores achieved by different models (LLaMA-7B) and datasets (full dataset, randomly sampled datasets, and datasets curated by SHED’s QOCS and QWCS methods) on both MMLU and WizardLM tasks. Lower scores indicate better alignment with human preference.
read the caption
Table 5: MT-Bench evaluation of the best-selected datasets of SHED and baselines.

🔼 This table presents the performance of the best-performing datasets selected by SHED and baseline methods (RS, QOCS, QWCS) across three different LLMs (LLaMA-13B, VICUNA-7B, and GPT-2) on the MMLU task. It demonstrates the transferability of the datasets curated by SHED, showing consistent performance improvements across various model sizes and families. The numbers represent the accuracy achieved by each method on the MMLU task, and the dataset size is indicated in parentheses.
read the caption
Table 6: Transferability evaluation using the best-selected datasets across different models on MMLU task.

🔼 This table presents the performance of the best-selected datasets (curated by SHED and baseline methods) when fine-tuned on different LLMs (LLaMA-13B, VICUNA-7B, and GPT-2) for the MMLU task. It demonstrates the transferability of the datasets curated by SHED, showing consistent performance across various LLMs. The table shows the performance of the full dataset and datasets with various sizes selected by different methods. The best performance is indicated in bold.
read the caption
Table 6: Transferability evaluation using the best-selected datasets across different models on MMLU task.

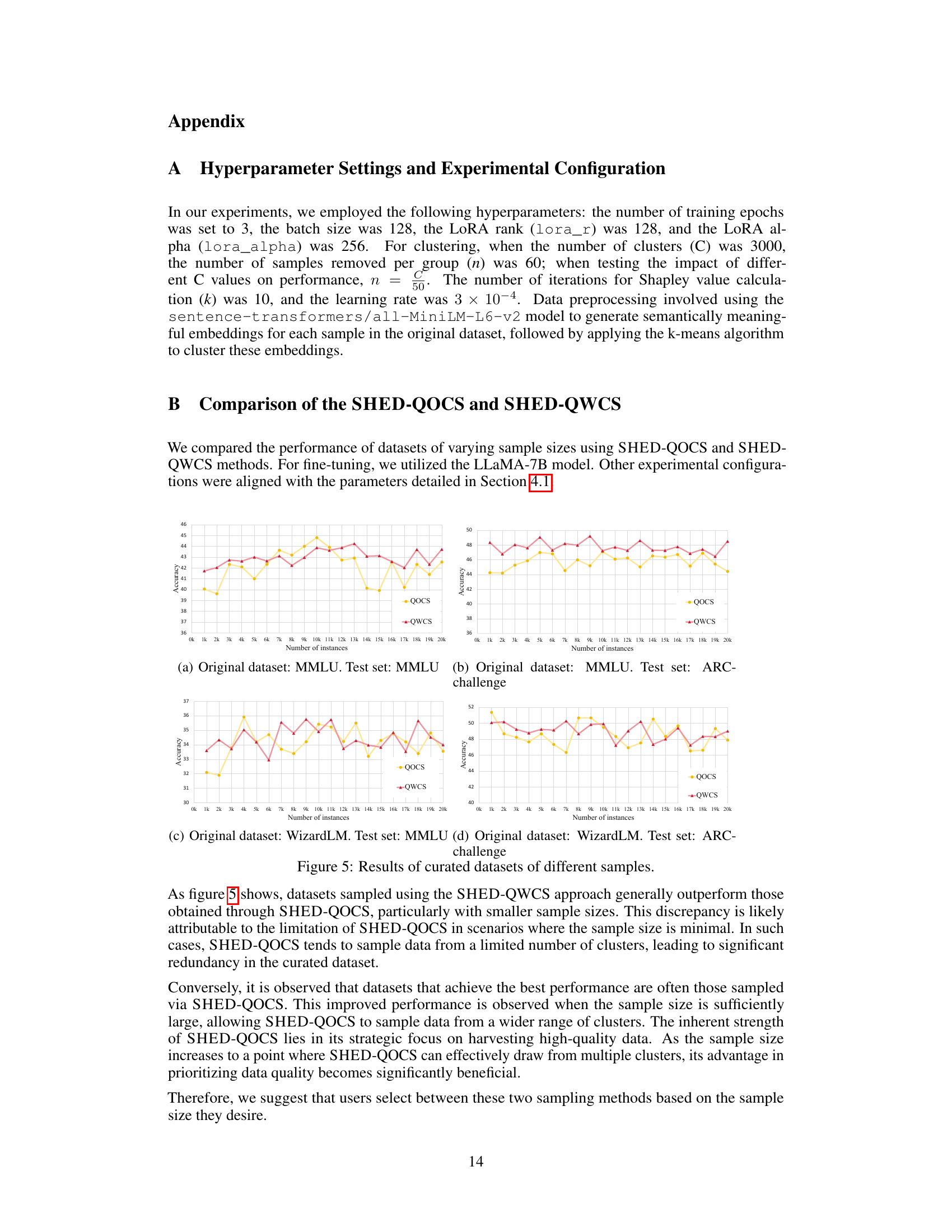
🔼 This table compares the performance of SHED’s selected dataset (with 1k samples) against LIMA’s selected dataset (also with 1k samples) on the MMLU and ARC-challenge tasks using LLaMA-7B as the base model. It highlights that SHED, despite being fully automated, achieves comparable or better performance than the manually curated LIMA dataset.
read the caption
Table 8: Performance comparison between SHED and LIMA.

🔼 This table presents a comparison of the performance of the best-performing datasets selected by SHED and baseline methods on the ARC-challenge task. It shows the performance (likely accuracy scores) achieved by SHED-QOCS, SHED-QWCS, RS (Random Sampling), DQ (Dataset Quantization), DSIR (Data Selection with Importance Resampling), and the original full dataset, across different dataset sizes for both the MMLU and WizardLM datasets.
read the caption
Table 4: Performance of the best-selected datasets of SHED and baselines on the ARC-challenge task.
Full paper#