TL;DR#
Current multi-view indoor 3D object detection methods often rely on Neural Radiance Fields (NeRFs) for geometry reasoning. However, NeRFs are computationally expensive and produce inaccurate geometry, leading to suboptimal detection performance. This paper introduces MVSDet, which uses plane sweeps for geometry-aware 3D object detection. Unlike NeRF-based methods, MVSDet does not require a large number of depth planes for depth prediction; instead, it uses a probabilistic sampling and soft weighting mechanism to select multiple depth proposals for each pixel. This greatly reduces computational costs and improves efficiency.
To further enhance depth prediction accuracy and detection performance, MVSDet integrates pixel-aligned Gaussian splatting. This technique regularizes depth prediction and improves the quality of depth estimations. Extensive experiments on ScanNet and ARKitScenes datasets demonstrate MVSDet’s superiority, showcasing significant improvements in detection accuracy and efficiency compared to state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MVSDet, a novel approach for 3D object detection that significantly improves accuracy and efficiency. It addresses the limitations of existing methods, offering a more robust and computationally efficient solution. The introduction of probabilistic sampling and soft weighting alongside pixel-aligned Gaussian splatting opens new avenues for research in geometry-aware 3D object detection and multi-view stereo, impacting areas like robotics, AR/VR, and scene understanding.
Visual Insights#

🔼 This figure compares the proposed MVSDet method with the NeRF-Det method in terms of 3D voxel center backprojections. It visualizes the accuracy of projecting 2D image features into 3D space. The grey dots represent the voxel centers, while the red dots highlight erroneous projections into free space. MVSDet demonstrates significantly fewer incorrect projections compared to NeRF-Det, indicating improved accuracy in geometry estimation.
read the caption
Figure 1: Comparison with NeRF-Det [22]. The 3D voxel centers (grey dots) are overlaid with the reference scene. The red dots denotes the erroneous backprojection pixel features to the points in the free space. Compared to NeRF-Det, we show much less inaccurate backprojections.
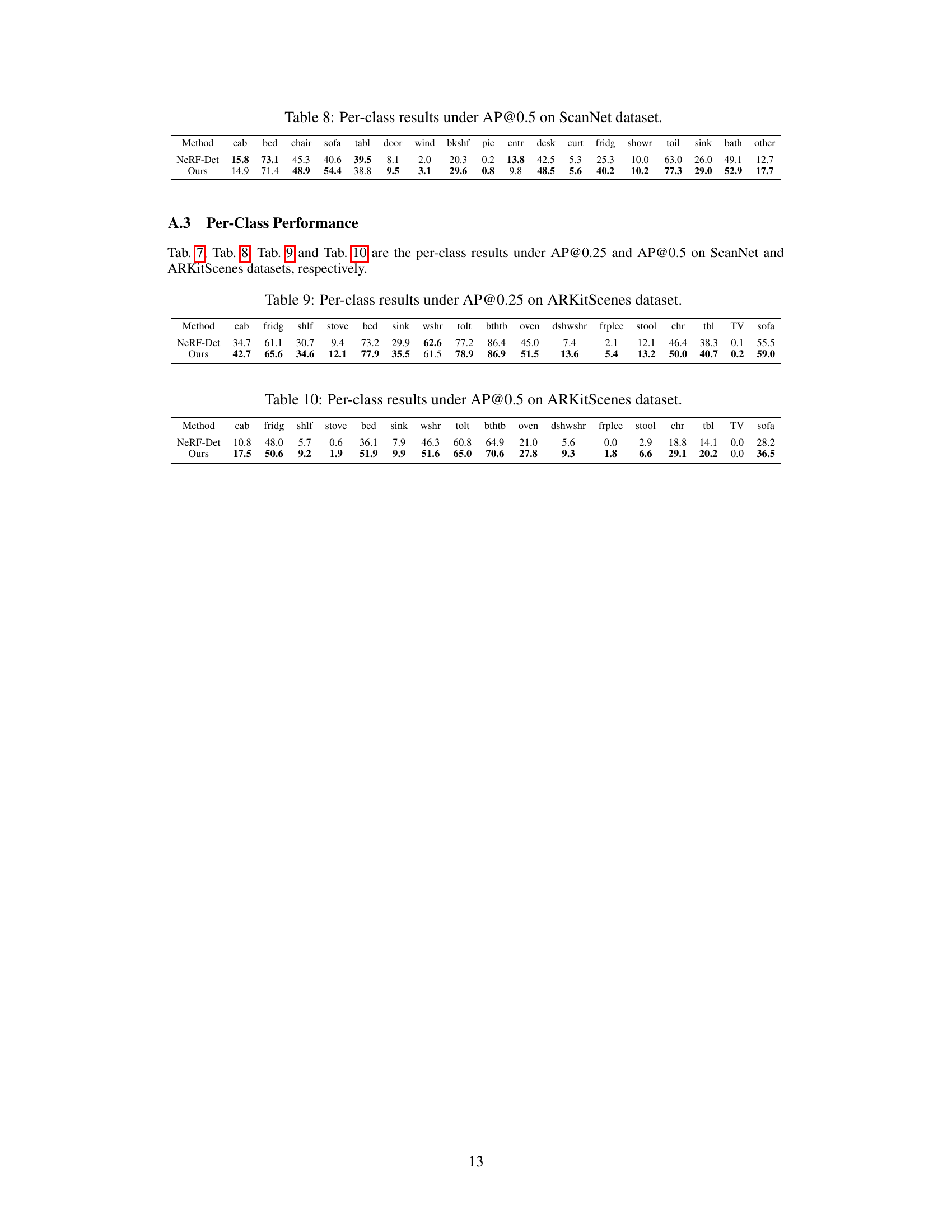
🔼 This table presents the results of different methods on the ScanNet dataset for indoor 3D object detection. The performance is measured using mean Average Precision (mAP) at IoU thresholds of 0.25 and 0.5. The ‘GT Geo’ column indicates whether ground truth geometry was used for supervision during the training process. The methods compared include ImGeoNet, CN-RMA, ImVoxelNet, NeRF-Det, and the proposed method, MVSDet. The table shows the mAP values for each method under different supervision conditions.
read the caption
Table 1: Results on ScanNet. 'GT Geo' denotes whether ground truth geometry is used as supervision during training.
In-depth insights#
Plane Sweep 3D#
Plane sweep 3D is a crucial technique in 3D computer vision, particularly for tasks like object detection and scene reconstruction from multiple 2D images. It leverages the concept of slicing the 3D space into parallel planes and processing each plane individually. This approach simplifies the complex 3D problem into a series of 2D problems which are often more manageable. The efficiency of plane sweep is tightly coupled with the sampling strategy of these planes. Over-sampling can lead to increased computational cost, while under-sampling may result in inaccuracies. Therefore, effective probabilistic sampling and soft weighting mechanisms, as demonstrated in the paper, become essential for balancing accuracy and computational efficiency. This technique is especially beneficial in multi-view scenarios where depth estimation is crucial but challenging due to the ambiguity inherent in 2D projections. The integration of plane sweep with other methods, such as pixel-aligned Gaussian splatting, significantly improves the overall robustness and accuracy of 3D scene representation. By enhancing depth prediction and reducing noise, the combined approach offers a significant advantage over traditional methods that rely solely on depth sensors or less robust geometric reasoning techniques. The probabilistic nature of the plane sweep makes it particularly well-suited for applications where noisy or incomplete data are common.
Multi-View Geometry#
Multi-view geometry in 3D object detection leverages information from multiple camera viewpoints to reconstruct a comprehensive 3D scene understanding. The core idea is that combining observations from different perspectives enhances depth perception and reduces ambiguities present in single-view images. This is particularly crucial in indoor environments where occlusions and complex object arrangements are common. Effective multi-view methods often involve techniques like stereo vision, structure from motion (SfM), and multi-view stereo (MVS) to estimate depth maps, point clouds, or voxel grids. Challenges include dealing with varying camera parameters, noisy data, and computational complexity, especially when processing high-resolution images. Sophisticated approaches utilize deep learning to address these issues, often integrating geometric reasoning within neural network architectures. A critical aspect is the efficient and accurate fusion of information from multiple views, which might involve techniques like cost volume aggregation or feature matching. The ultimate goal is to improve the accuracy and robustness of 3D object detection by exploiting the rich geometric constraints provided by multiple camera viewpoints. Successful methods require a balance between computational efficiency and geometric accuracy, offering a robust and detailed understanding of the 3D scene.
Gaussian Splatting#
The integration of Gaussian splatting within the 3D object detection framework presents a novel approach to enhancing depth estimation. Pixel-aligned Gaussian splatting (PAGS), in particular, offers a compelling alternative to traditional volumetric rendering methods employed in NeRF-based techniques. By modeling the scene using 3D Gaussian primitives, PAGS significantly reduces computational complexity while maintaining accuracy. The use of PAGS as an additional supervision signal, guiding the refinement of depth predictions from a probability volume, is a key contribution. This allows for improved accuracy with minimal computational overhead, making the system more efficient. The alignment of Gaussians with depth predictions from a probability volume allows for a synergistic improvement. The rendering loss associated with PAGS serves as a powerful regularizer, further enhancing depth accuracy and indirectly benefiting the overall object detection performance. This method shows promise in overcoming limitations of NeRF-based approaches while offering significant improvements in both efficiency and accuracy.
Depth Prediction#
Accurate depth prediction is crucial for geometry-aware 3D object detection, especially when dealing with multi-view indoor scenes. The paper explores this challenge, highlighting the limitations of traditional methods. NeRF-based approaches, while elegant, often suffer from inaccuracies in geometry extraction, leading to suboptimal detection performance. The authors cleverly address this by proposing an efficient plane-sweeping technique. This approach avoids the computational burden of using numerous depth planes by employing a probabilistic sampling and soft weighting mechanism. This clever strategy focuses on the most likely depth locations, improving computational efficiency while retaining accuracy. Further enhancing depth prediction, the authors integrate pixel-aligned Gaussian Splatting (PAGS). This regularization technique leverages the power of novel view synthesis to further refine depth estimation with minimal overhead. The integration of PAGS with the plane-sweeping method creates a robust and computationally efficient framework, resulting in significant performance improvements compared to existing state-of-the-art methods.
MVSDet Limits#
MVSDet, while demonstrating promising results in multi-view indoor 3D object detection, has inherent limitations. Its reliance on a probabilistic sampling and soft weighting mechanism, while efficient, introduces uncertainty in depth estimation, potentially impacting the accuracy of 3D bounding box predictions. The method’s performance is sensitive to the quality of input images, particularly in scenarios with textureless surfaces or significant occlusions. The selection of nearby views also introduces a degree of subjectivity, affecting the resulting geometry. The use of Pixel-Aligned Gaussian Splatting (PAGS) as a regularization technique, though improving accuracy and efficiency, is not a substitute for robust depth estimation. While the probabilistic approach reduces computational burden, it cannot entirely avoid the limitations of traditional plane-sweeping methods. Finally, the generalizability of MVSDet to outdoor scenes or other drastically different environments remains untested, limiting its broad applicability. Therefore, future research should focus on refining depth estimation techniques, developing more robust feature matching methods, and further validating the performance on diverse datasets.
More visual insights#
More on figures

🔼 This figure illustrates the MVSDet architecture. The upper branch details the detection pipeline using probabilistic sampling and soft weighting to efficiently place pixel features on the 3D volume based on depth probability. The lower branch demonstrates the use of Pixel-aligned Gaussian Splatting (PAGS) for novel view synthesis, improving depth prediction, but only used during training. The figure highlights the selection of depth proposals and shows how pixel features are assigned to valid and invalid 3D locations, comparing to the ground truth.
read the caption
Figure 2: Overview of our MVSDet. The upper branch shows the detection pipeline with our proposed probabilistic sampling and soft weighting. The backprojected ray intersects at 3 points (shown as dots), but only the green point receives the pixel feature based on the selected depth proposals. The red points are denoted as invalid backprojection location and thus the pixel feature is not assigned to them. 'GT Location' is the ground truth 3D location of the pixel. The lower branch shows the pixel-aligned Gaussian Splatting (PAGS). We select nearby views for the novel image from the images input to the detection branch and predict Gaussian maps on them. Note that PAGS is removed during testing.
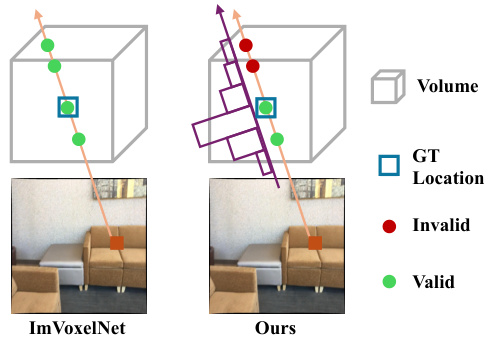
🔼 This figure compares different feature backprojection methods in 3D volume-based object detection. The left shows the method used in ImVoxelNet, which projects pixel features to all voxels intersected by the ray. The right demonstrates the proposed method (MVSDet). MVSDet uses depth probability distribution to guide feature placement, assigning features only to voxels with high probability, thus reducing errors. The blue box represents the ground truth 3D location, green dots represent valid feature placements, and red dots represent invalid feature placements.
read the caption
Figure 3: Comparison of different feature backprojection methods. The pixel ray intersects at 4 voxel centers with the blue box denoting the ground truth 3D location of the pixel. Our method computes the placement of the pixel features based on the depth probability distribution (purple) and thus able to suppress incorrect intersections.
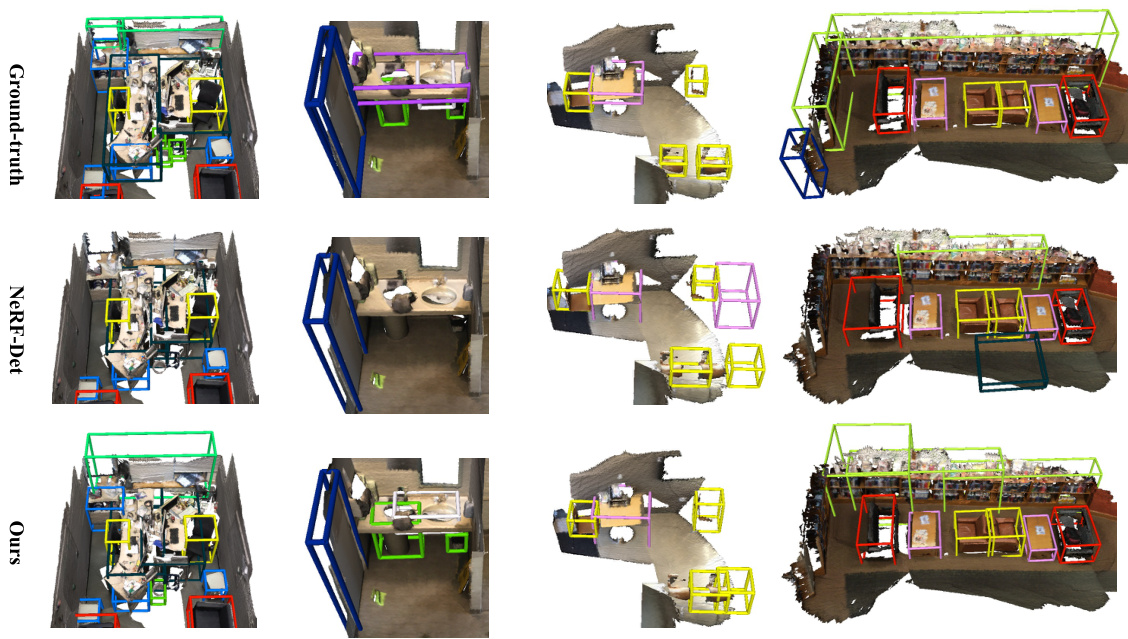
🔼 This figure compares the qualitative results of three different methods on the ScanNet dataset for indoor 3D object detection. The first row shows the ground truth bounding boxes, illustrating the actual locations and sizes of the objects. The second row displays the results of the NeRF-Det method which uses NeRF for geometric reasoning. The third row shows the results obtained using the proposed method (Ours), MVSDet, which leverages a more efficient plane sweep technique. A visual comparison highlights the differences in accuracy and precision between the different approaches, demonstrating the improved performance of the proposed method over NeRF-Det.
read the caption
Figure 4: Qualitative comparison on ScanNet dataset. Note that the mesh is not the input to the model and is only for visualization purpose.

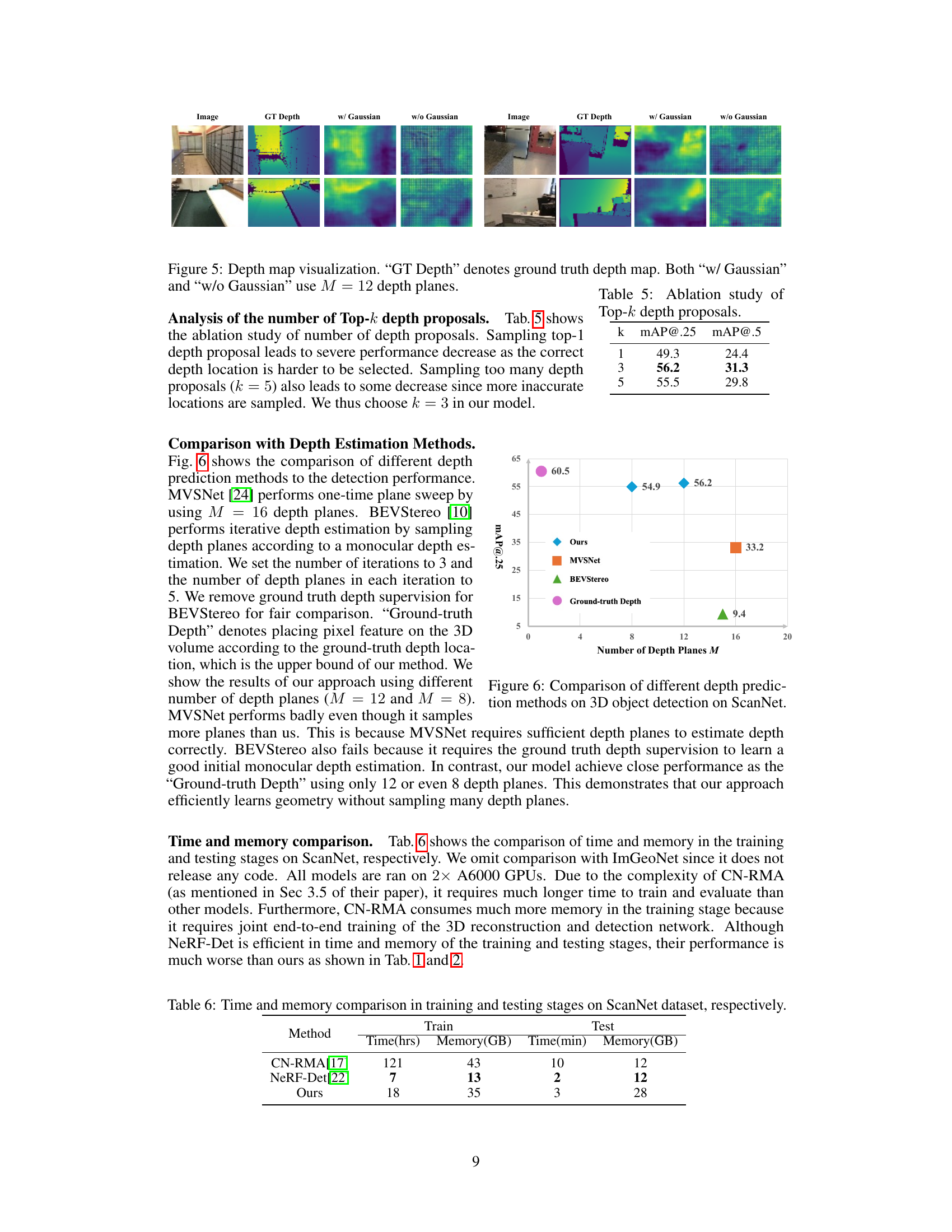
🔼 This figure visualizes the depth maps predicted by the probability volume. It compares the ground truth depth map with the depth maps predicted with and without using Gaussian Splatting. Both versions use 12 depth planes. The visualization helps to show the impact of incorporating Gaussian Splatting on depth map quality.
read the caption
Figure 5: Depth map visualization. “GT Depth” denotes ground truth depth map. Both “w/ Gaussian” and “w/o Gaussian” use M = 12 depth planes.
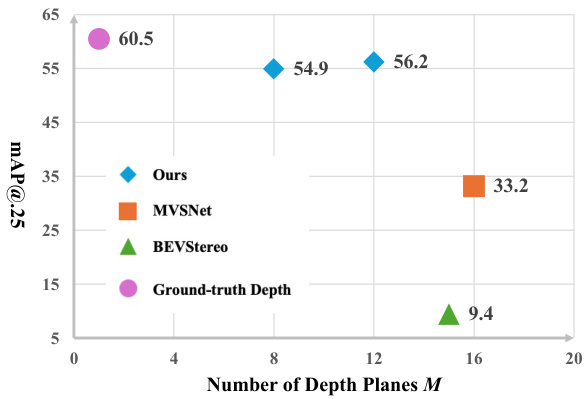
🔼 This figure compares the performance of different depth prediction methods on 3D object detection using the ScanNet dataset. The x-axis represents the number of depth planes used in the methods, while the y-axis shows the mAP@0.25 (mean Average Precision at IoU threshold of 0.25). The results show that the proposed method (Ours) achieves comparable performance to using ground truth depth with significantly fewer depth planes than other methods like MVSNet and BEVStereo. MVSNet performs poorly despite using many depth planes, while BEVStereo’s performance is limited even with ground truth depth information.
read the caption
Figure 6: Comparison of different depth prediction methods on 3D object detection on ScanNet.

🔼 This figure shows a qualitative comparison of the proposed MVSDet method against the NeRF-Det method on the ScanNet dataset. It visually demonstrates the improved accuracy of object detection using MVSDet. The images display the ground truth bounding boxes in the scene, followed by the bounding boxes produced by the NeRF-Det method, and lastly the bounding boxes predicted by the MVSDet method. The improved accuracy in locating the object bounding boxes in the MVSDet results is clearly apparent from the visual comparison. Note that the mesh is added for visualization purposes and is not an input to the model.
read the caption
Figure 4: Qualitative comparison on ScanNet dataset. Note that the mesh is not the input to the model and is only for visualization purpose.

🔼 This figure shows the results of novel view synthesis on the ScanNet dataset. It compares the rendered images and depth maps produced by the model’s Gaussian Splatting module against the ground truth images and depth maps for several novel viewpoints. The comparison demonstrates the model’s ability to generate realistic and accurate novel views.
read the caption
Figure 8: Novel view synthesis results on ScanNet dataset. 'Rendering' denotes the rendered image / depth from our Gaussian Splatting module. 'GT' denotes the ground-truth image /depth of the novel view.
More on tables
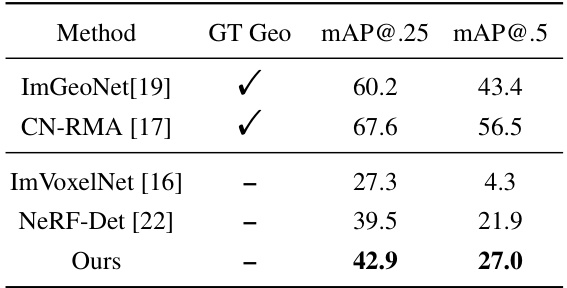
🔼 This table presents the results of the proposed MVSDet method and several baseline methods on the ARKitScenes dataset. The mAP@.25 and mAP@.5 metrics are used to evaluate the performance of each method. The ‘GT Geo’ column indicates whether ground truth geometry was used for supervision during training. The table shows that MVSDet outperforms the other methods that don’t use ground truth geometry, highlighting its effectiveness.
read the caption
Table 2: Results on ARKitScenes. 'GT Geo' denotes whether ground truth geometry is used as supervision during training.

🔼 This table presents the results of an ablation study conducted to evaluate the impact of probabilistic sampling and soft weighting on the model’s performance. The study was performed without using the rendering loss, allowing for an isolated assessment of the effects of these two techniques. Three different model configurations were compared: one with only probabilistic sampling, one with only soft weighting, and one with both techniques enabled. The results, measured in terms of mean Average Precision (mAP) at thresholds of 0.25 and 0.5, demonstrate the importance of both probabilistic sampling and soft weighting for achieving optimal performance.
read the caption
Table 3: Ablation study of probabilistic sampling and soft weighting. All methods are conducted without using rendering loss.
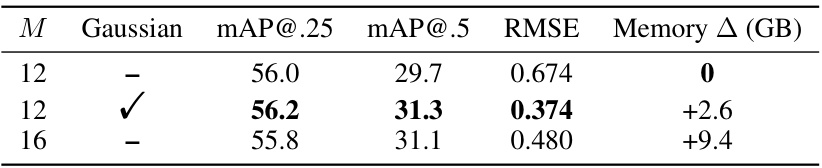
🔼 This table presents an ablation study on the impact of using pixel-aligned Gaussian splatting (PAGS) on the model’s performance. It shows the results with different numbers of depth planes (M) and with/without PAGS, evaluating the mean Average Precision (mAP) at thresholds of 0.25 and 0.5, and the Root Mean Squared Error (RMSE) of depth prediction. The increase in memory consumption due to adding PAGS is also indicated.
read the caption
Table 4: Ablation study of Gaussian Splatting. M denotes the number of depth planes in the plane sweep. “Gaussian” denotes using pixel-aligned Gaussian splatting. “RMSE” is the depth evaluation metric. “Memory ∆” denotes the increased memory consumption during training.

🔼 This table presents the results of an ablation study conducted to determine the optimal number of top-k depth proposals to use in the probabilistic sampling method. The study varied the number of proposals (k) and measured the impact on mean Average Precision (mAP) at two different thresholds (0.25 and 0.5). The results show that using 3 depth proposals achieves the best performance.
read the caption
Table 5: Ablation study of Top-k depth proposals.
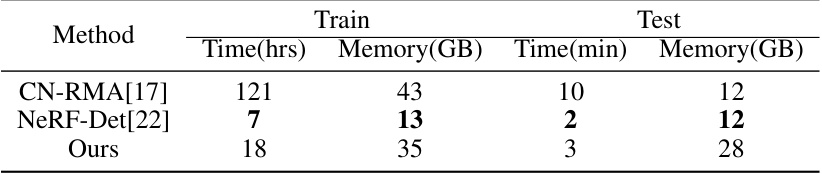
🔼 This table compares the training and testing time and memory usage of three different methods: CN-RMA, NeRF-Det, and the authors’ proposed method. The comparison highlights the computational efficiency of each approach on the ScanNet dataset.
read the caption
Table 6: Time and memory comparison in training and testing stages on ScanNet dataset, respectively.

🔼 This table presents a breakdown of the model’s performance on the ScanNet dataset, specifically focusing on the average precision (AP) at an Intersection over Union (IoU) threshold of 0.5. It shows the AP for each of the 18 object classes individually, offering a detailed view of the model’s strengths and weaknesses in recognizing specific object types within the indoor scenes.
read the caption
Table 8: Per-class results under AP@0.5 on ScanNet dataset.

🔼 This table presents a breakdown of the model’s performance (average precision at 0.5 IoU threshold) on the ScanNet dataset. Each row represents a different object category from the dataset, and the columns show the average precision for that category. The table allows for a detailed analysis of the model’s accuracy across different object types.
read the caption
Table 8: Per-class results under AP@0.5 on ScanNet dataset.

🔼 This table presents a breakdown of the Average Precision (AP) at IoU threshold of 0.25 for each object class in the ARKitScenes dataset. The results are categorized by object class (e.g., ‘cab’, ‘fridg’, ‘shlf’, etc.), allowing for a granular analysis of the model’s performance on various object types. The table compares the performance of the proposed method (Ours) with the baseline method (NeRF-Det). Each cell in the table represents the AP score achieved for a specific object class. It highlights the strengths and weaknesses of each method in detecting specific object categories.
read the caption
Table 9: Per-class results under AP@0.25 on ARKitScenes dataset.

🔼 This table presents a breakdown of the model’s performance on the ARKitScenes dataset, specifically focusing on the average precision (AP) at a 0.5 intersection over union (IoU) threshold. Each row represents a different object category (cab, fridge, shelf, etc.), and the columns show the AP for each category. This allows for detailed analysis of the model’s strengths and weaknesses in recognizing various object types within indoor scenes. Comparing these results to other methods in the paper provides insights into the model’s relative performance across different object classes.
read the caption
Table 10: Per-class results under AP@0.5 on ARKitScenes dataset.
Full paper#