↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating high-quality dynamic 3D content (4D) is challenging due to slow optimization speeds and inconsistencies in existing methods. Most approaches rely on multiple images or video diffusion models, leading to suboptimal results. Additionally, achieving spatial-temporal consistency in 4D geometry has been a significant hurdle. Existing methods often struggle to maintain consistent 3D geometry across different timestamps while simultaneously generating smooth and realistic motions.
This paper introduces Diffusion4D, which tackles these challenges head-on. It leverages a novel 4D-aware video diffusion model trained on a meticulously curated dynamic 3D dataset to synthesize orbital views of dynamic 3D assets. This model incorporates a novel 3D-to-4D motion magnitude metric and a motion magnitude reconstruction loss to refine motion dynamics. Furthermore, a 3D-aware classifier-free guidance is introduced to further improve the dynamic fidelity of the generated assets. Finally, explicit 4D construction is performed via Gaussian splatting for better efficiency and consistency, demonstrating state-of-the-art results.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient framework for 4D content generation, addressing the challenges of slow optimization and inconsistencies in existing methods. Its approach of integrating spatial and temporal consistency into a single video diffusion model opens new avenues for research in efficient and high-quality 4D asset creation. This has significant implications for various applications, from film production and animation to augmented reality.
Visual Insights#
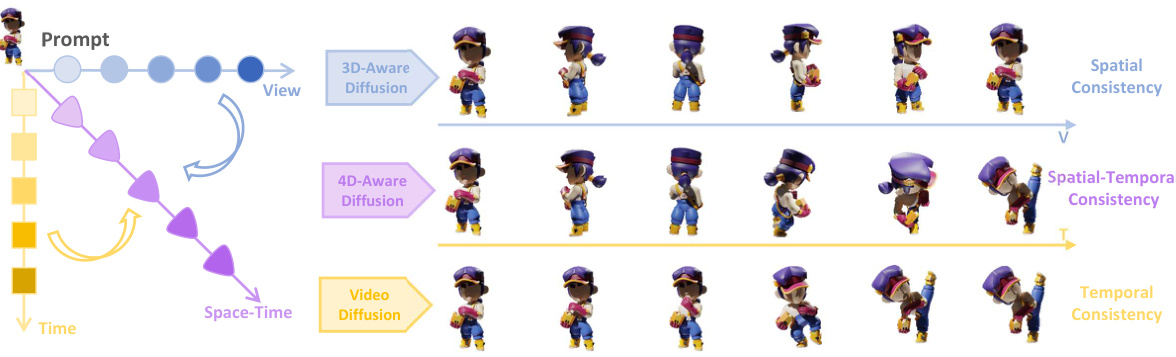
This figure illustrates the concept of spatial-temporal consistency in 4D generation. It decomposes the challenge into three aspects: spatial consistency (consistent 3D geometry at each timestamp), temporal consistency (smooth and coherent appearance and movement across timestamps), and spatial-temporal consistency (combining both). The figure then shows how the proposed Diffusion4D method integrates all three aspects into a unified network for efficient and consistent 4D content generation.
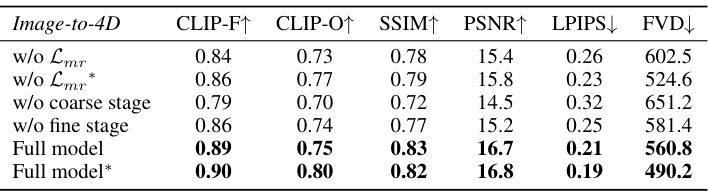
This table presents the results of an ablation study assessing the impact of different components within the proposed Diffusion4D framework on 4D construction. The study removes components one at a time to measure their individual contribution to the overall performance. Metrics used to evaluate performance include CLIP-F (CLIP score based on front views), CLIP-O (CLIP score based on all views), SSIM, PSNR, LPIPS (Learned Perceptual Image Patch Similarity), and FVD (Fréchet Video Distance). The rows labeled ‘Full model’ and ‘Full model*’ represent the complete model and the model’s output before the final 4D construction stage respectively.
In-depth insights#
4D Diffusion Model#
A hypothetical ‘4D Diffusion Model’ would extend the successful framework of diffusion models into the fourth dimension, time, for generating dynamic 3D content. This would move beyond simple image or video generation, enabling the creation of complex 4D assets such as animated characters or evolving landscapes. The core challenge lies in the increased computational complexity and data requirements. Constructing a 4D diffusion model would require massive datasets of spatio-temporal data representing 4D objects or scenes from various viewpoints, which are currently scarce. The model would likely need novel architectural designs to effectively capture and model the intricate interplay between spatial and temporal features. Furthermore, efficient sampling and denoising strategies specific to 4D data would need to be developed. One potential approach could involve modeling temporal dynamics as a latent variable within a 3D diffusion model, using techniques such as recurrent neural networks or transformers to incorporate temporal dependencies. Ultimately, the success of such a model hinges on its ability to achieve both spatial and temporal consistency, producing smooth and realistic dynamic content. The research would need to carefully consider and manage the tradeoffs between model complexity and computational efficiency.
Motion Magnitude#
The concept of “Motion Magnitude” in the context of 4D video generation is crucial for controlling the dynamic intensity of 3D assets. It’s not merely about detecting motion; it’s about quantifying the strength and scale of movement in a way that can be used as a control signal for a diffusion model. This involves separating actual object motion from changes in camera perspective during the capture of orbital videos. A key challenge is the development of a robust metric that accurately reflects this motion strength, distinguishing it from visual artifacts or inconsistencies in the data. The effective implementation of motion magnitude involves incorporating this metric as guidance during both the training and generation phases of a 4D-aware diffusion model. This might involve using it as an explicit condition for the diffusion process, or incorporating a reconstruction loss to ensure accurate learning of motion dynamics. The resulting control allows for a fine-grained management of animation quality. Ultimately, a well-defined and precisely used ‘Motion Magnitude’ metric is essential for achieving high-quality, temporally consistent 4D content generation.
4D Geometry#
The concept of “4D Geometry” in the context of a research paper likely refers to the representation and manipulation of three-dimensional objects that change over time. This extends the typical understanding of 3D space by incorporating a temporal dimension, allowing for the modeling of dynamic scenes and objects. Key challenges in 4D geometry include efficiently representing the continuous change of 3D shapes, ensuring temporal consistency, and handling complex interactions between multiple moving objects. Effective techniques often involve combining spatial and temporal information, such as using sequences of 3D scans or dynamic mesh models. Data representation is crucial, with common choices including volumetric representations, point clouds evolving over time, or implicit surfaces. The paper might explore novel methods for 4D data acquisition, processing, or rendering, possibly focusing on the optimization of efficient algorithms and effective compression strategies given the high dimensionality of the data. Finally, applications of 4D geometry are vast, ranging from animation and VFX to robotics and scientific simulations, making this a very active area of research.
Future of 4D#
The “Future of 4D” in visual content generation hinges on several key advancements. High-fidelity and efficient 4D asset creation will require more sophisticated models that can learn intricate details of dynamic 3D objects from limited data. Improved control over dynamic properties remains critical; models need better methods to manage motion, deformation, and overall realism. Data scarcity continues to be a major bottleneck; research must focus on generating high-quality synthetic datasets or exploiting alternative training paradigms. Finally, seamless integration with existing 3D and AR/VR pipelines is crucial for broader adoption. The future likely involves a shift towards more integrated and comprehensive frameworks that unify the generation process with downstream applications.
Limitations#
The section on limitations should critically examine the shortcomings of the proposed Diffusion4D framework. Data limitations are a crucial aspect to address; the curated dataset, while large, might still lack diversity in terms of object types, actions, and motion styles, impacting the model’s generalizability. The reliance on existing 4D construction pipelines is another limitation; these pipelines might introduce artifacts or limitations that propagate to the final 4D asset. The computational cost and efficiency of the framework warrant examination; although the approach is designed to be efficient, quantifying its performance and scalability compared to alternative methods is necessary. Finally, a thorough discussion of the model’s robustness and limitations in handling complex or ambiguous prompts, especially across different input modalities (text, image, static 3D), is essential for a complete evaluation. Addressing these issues would significantly strengthen the paper’s analysis and contribute to a more complete and balanced understanding of Diffusion4D’s capabilities.
More visual insights#
More on figures
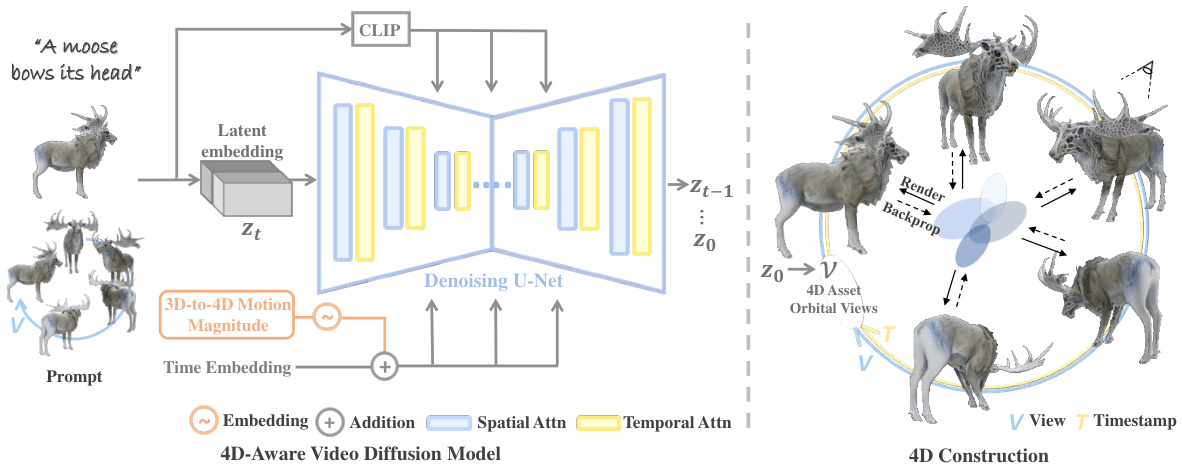
This figure illustrates the architecture of the proposed Diffusion4D framework. It shows how a 4D-aware video diffusion model generates orbital videos of dynamic 3D assets from various input prompts (text, image, or static 3D model). The model incorporates a 3D-to-4D motion magnitude metric to control the dynamic strength of the assets. The generated orbital views are then used for explicit 4D construction via Gaussian splatting, resulting in a final 4D asset.

This figure showcases a qualitative comparison of 4D object generation results between the proposed Diffusion4D method and several existing baselines (4DFY, Animate124, 4DGen, and STAG4D). The comparison is done for both text-to-4D and image-to-4D generation tasks. For Diffusion4D, five different views of the generated 4D object at consecutive timestamps are displayed to highlight the temporal consistency achieved by the model. The baselines primarily show only two viewpoints (start and end), thereby lacking the dynamic view demonstration that is a major feature of Diffusion4D.

This figure visualizes the results of using Diffusion4D with static 3D assets as input. The top row shows the input static 3D models used as conditioning. The subsequent rows show the generated 4D assets from different conditioning methods: Image-conditioned (using a single image), Static-3D conditioned (using a static 3D model), and Static-3D conditioned (*), which uses results from the 4D-aware video diffusion model. The circled areas highlight how well the model captures the input characteristics.

This figure presents a qualitative comparison of 4D generation results between the proposed Diffusion4D method and several other state-of-the-art baselines. The comparison is shown for both text-to-4D and image-to-4D generation tasks. For each method and task, several consecutive frames of the generated 4D asset are displayed from multiple viewpoints. The asterisk (*) denotes results obtained directly from the 4D-aware video diffusion model (before the explicit 4D construction step). This allows a visual assessment of the quality, realism, and dynamic consistency of each approach.
Full paper#



















