TL;DR#
Training accurate visual models often requires massive, annotated datasets, which can be expensive and time-consuming to create. Using multiple datasets is one solution; however, datasets may have conflicting labels, hurting model performance. This significantly reduces the effectiveness of multi-dataset training.
This paper introduces AutoUniSeg, a novel approach that uses Graph Neural Networks (GNNs) to automatically create a unified label space across multiple datasets. AutoUniSeg solves the label conflict problem by learning relationships between labels from different datasets using text embeddings and GNNs. This allows simultaneous training on multiple datasets, significantly improving training efficiency and performance. Experiments show AutoUniSeg outperforms existing methods, achieving state-of-the-art results.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient solution to a major challenge in multi-dataset semantic segmentation: handling conflicting label spaces. It offers a significant advancement in model training efficiency and performance, opening new avenues for research in multi-dataset learning and improving the robustness of models trained on diverse data. The proposed GNN-based approach is particularly relevant to researchers working on large-scale semantic segmentation tasks and applications with varied annotation standards.
Visual Insights#
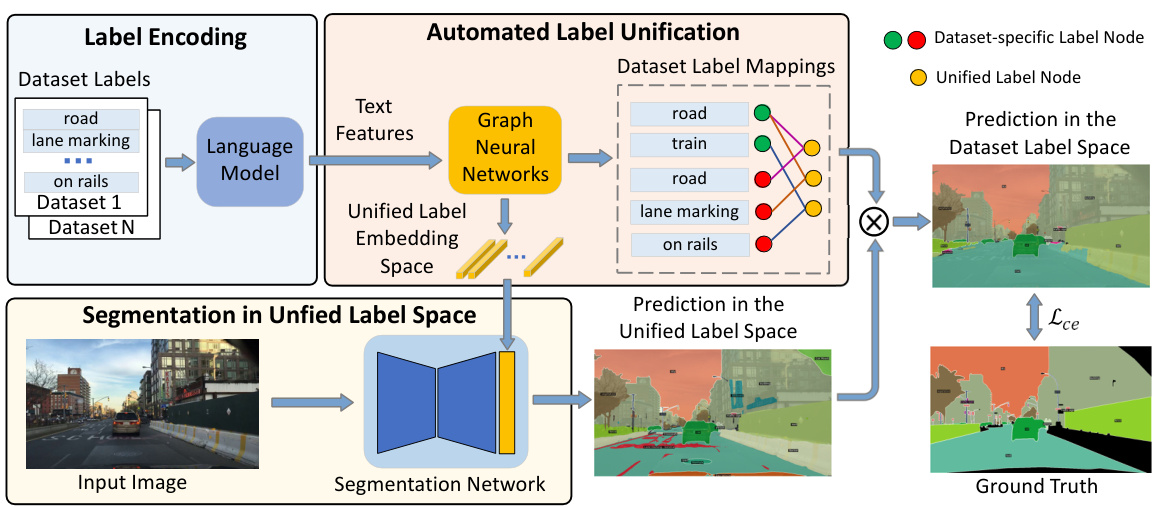
🔼 This figure illustrates the pipeline of the proposed method. It shows three main modules: 1) Label Encoding: uses a language model to convert dataset labels into textual features. 2) Automated Label Unification: uses Graph Neural Networks (GNNs) to learn a unified label embedding space and dataset label mappings based on the textual features and input images. 3) Segmentation in Unified Label Space: uses a segmentation network to produce segmentation results in the unified label space which are then mapped back to the original dataset label spaces. The figure also visually depicts the relationships between the different components and the flow of information.
read the caption
Figure 1: Our method consists of three modules. The label encoding provides the semantic text features of the dataset labels. The GNNs learn the unified label embedding space and dataset label mappings based on the textual features and input images. The segmentation network leverages the unified label embedding space to produce segmentation results in the unified label space.

🔼 This table presents the datasets used in the experiments described in the paper. It shows a breakdown of the datasets used for training and validation, separated by domain (driving scene, indoor scene, everyday objects). For each domain, the table lists the specific datasets used and their corresponding reference numbers. It also lists the unseen test datasets used for evaluating the generalization performance of the proposed model.
read the caption
Table 1: Training and test datasets in our experiments.
In-depth insights#
Multi-Dataset Seg.#
Multi-dataset semantic segmentation tackles the challenge of training accurate models using data from multiple sources with varying label spaces. The core issue lies in unifying these disparate label sets to enable effective model training. Naive approaches like concatenation often fail due to redundancy and semantic conflicts. Advanced methods propose constructing universal taxonomies or re-annotating datasets, but these are laborious and time-consuming. This research explores a novel, automated approach using Graph Neural Networks (GNNs) to unify label spaces, significantly improving efficiency. The GNNs learn relationships between labels from various datasets, building a unified embedding space and enabling seamless model training. This approach outperforms other multi-dataset training techniques by avoiding manual intervention, ultimately leading to more efficient and effective model development for semantic segmentation tasks.
GNN Label Unification#
The core idea of “GNN Label Unification” revolves around using Graph Neural Networks (GNNs) to address the challenge of inconsistent label spaces across multiple datasets in semantic segmentation. GNNs excel at modeling relationships between nodes, making them ideal for learning a unified label space from the diverse label sets of individual datasets. The method leverages text embeddings of label descriptions (generated using a language model) as node features, allowing the GNN to learn the relationships and dependencies between labels, thus automatically creating a unified embedding space. This automated approach eliminates the need for manual annotation or complex taxonomy design, significantly improving efficiency. By learning mappings between the unified space and the original dataset-specific spaces, the model allows for training across datasets simultaneously. This is a significant improvement over previous approaches that rely on manual label harmonization or iterative two-dataset unification. The key contribution lies in the seamless integration of GNNs for label space unification directly within the training pipeline of a semantic segmentation model, resulting in a unified prediction space that is robust and generalizable across multiple, diverse datasets. The effectiveness of this approach is demonstrated through improved performance on a variety of standard benchmarks.
Unified Label Space#
The concept of a ‘Unified Label Space’ is crucial for effectively training semantic segmentation models on multiple datasets. The core challenge addressed is the inherent inconsistency in label spaces across different datasets; a ‘road’ in one dataset might be further subdivided into ‘road’, ’lane marking’, and ‘crosswalk’ in another. The proposed method leverages Graph Neural Networks (GNNs) to learn a unified embedding space, effectively mapping the disparate label spaces into a common representation. This approach bypasses the time-consuming and error-prone methods of manual re-annotation or taxonomy creation, thus significantly improving efficiency. The GNNs learn relationships between labels from different datasets using textual features extracted through a language model, and this results in a unified space that is more generalized and robust. This unified space allows for seamless training of a single segmentation model across all datasets, reducing redundancy and improving overall performance. The success of this method relies heavily on the capability of the GNN to successfully capture inter-dataset label relationships, and the quality of textual feature extraction also plays a critical role. Ultimately, the unified label space enables a model to generalize well across diverse datasets and scenarios, leading to more robust and efficient semantic segmentation.
Benchmark Results#
Benchmark results are crucial for evaluating the effectiveness of a new method in a research paper. A strong benchmark section should present results comparing the proposed approach against existing state-of-the-art methods on established datasets, demonstrating the method’s superiority or, at minimum, its competitiveness. Quantitative metrics, such as mean Intersection over Union (mIoU) for semantic segmentation, are essential. Beyond simple metrics, qualitative comparisons (visualizations) help to understand model performance in challenging scenarios. The choice of benchmarks is important; they should be relevant, widely accepted, and representative of the problem domain. Comprehensive analysis of benchmark results includes a discussion of limitations, and potential reasons for unexpected outcomes, leading to valuable insights and future research directions. A well-written benchmark section is more than just a table of numbers; it is a demonstration of a method’s capabilities within the context of existing work.
Future Directions#
Future research could explore several promising avenues. Extending the approach to handle weakly-supervised or unsupervised data would significantly broaden the applicability and reduce reliance on extensive, fully annotated datasets. Investigating more sophisticated graph neural network architectures or alternative graph-based methods may improve the accuracy and efficiency of label space unification. Addressing the challenges posed by noisy or inconsistent annotations in real-world datasets is also critical. Additionally, exploring different strategies for combining information from multiple datasets, beyond simple label space unification, could yield further performance improvements. Finally, thorough evaluation on a wider range of datasets and benchmark tasks is necessary to fully assess the robustness and generalizability of this method. The potential for integrating this approach with other multi-modal techniques such as language models for richer semantic understanding warrants further study.
More visual insights#
More on figures

🔼 This figure illustrates the proposed method’s architecture, showing how dataset-specific annotations are used to train a unified segmentation model. It highlights the use of a graph neural network (GNN) to learn label mappings and a unified label embedding space, enabling the model to be trained simultaneously on multiple datasets. The process involves encoding input images into pixel embeddings, projecting them into the unified label space, and finally mapping the unified predictions to dataset-specific label spaces for training with dataset-specific annotations.
read the caption
Figure 2: Illustration of our method that training with dataset-specific annotations through label mappings constructed by GNNs. We leverage a unified segmentation head (UniSegHead) to enable simultaneous training on multiple datasets. In the UniSegHead, we compute the matrix product between pixel embedding and augmented unified node features output by the GNNs, resulting in predictions for the unified label space. We finally utilize the label mappings constructed by GNNs to map the unified predictions to dataset-specific prediction for training.
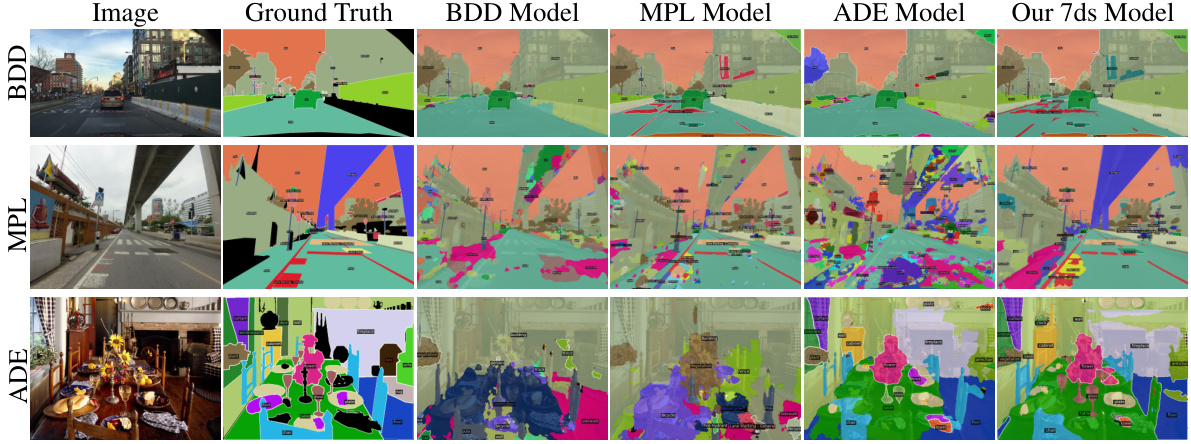
🔼 This figure displays a visual comparison of segmentation results on three different datasets (BDD, Mapillary, and ADE) using both a single-dataset model and the proposed multi-dataset model (‘Our 7ds Model’). It shows that the multi-dataset model produces more consistent and accurate results across various datasets and different scene types by integrating knowledge learned from multiple datasets compared to the single dataset approach.
read the caption
Figure 3: Visual comparisons with Single dataset model on different training datasets.
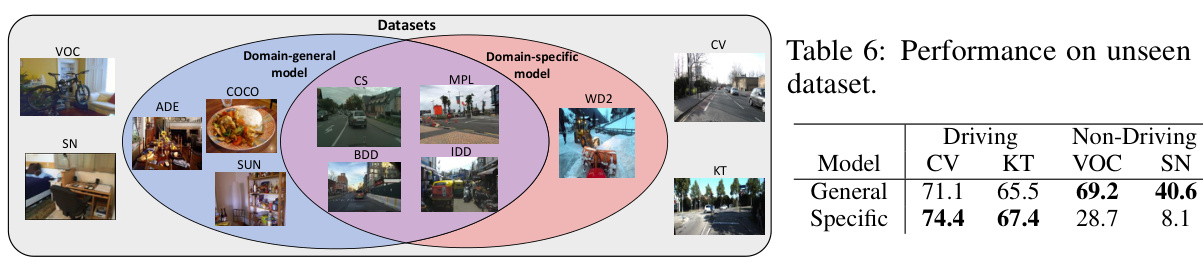
🔼 This figure shows a Venn diagram illustrating the overlap between the datasets used to train the domain-general and domain-specific models. The domain-general model is trained on a larger set of datasets (Cityscapes, Mapillary, BDD, IDD, SUN RGBD, ADE20K, COCO) representing a broader range of visual scenes and object categories. The domain-specific model, in contrast, focuses solely on a subset of these datasets, predominantly those featuring driving scenes (Cityscapes, Mapillary, BDD, and IDD). The Venn diagram visually depicts the unique and shared datasets between the two training approaches, showcasing the differences in data coverage and potential implications for model generalization.
read the caption
Figure 4: The composition of the training datasets.

🔼 This figure compares the unified label space learned by the proposed Graph Neural Network (GNN) method with a label space constructed solely from text features. The top row shows images from the IDD and Mapillary datasets, highlighting the ‘curb’ and ‘barrier’ classes. The ground truth and the model’s predictions are displayed. The bottom row presents a similar comparison, this time involving the IDD, Mapillary, and ADE datasets, focusing on the ’tunnel or bridge’, ‘bridge’, ’tunnel’, and ‘fireplace’ classes. The accompanying diagrams illustrate how the GNN method effectively learns and merges labels with similar visual appearances, even when their textual descriptions differ, leading to a more accurate and concise unified label space.
read the caption
Figure 5: Comparison of unified label space learned by GNNs with constructed by text features.

🔼 This figure provides a visual comparison of the segmentation results obtained using different training strategies on various datasets. The top row shows the input images, while the subsequent rows show the ground truth segmentation masks, results from the domain-general model, and results from the domain-specific model. The figure visually demonstrates the differences in performance between the models trained on a broader set of datasets (general model) and models focused on a specific domain (specific model), highlighting the impact of data diversity on segmentation accuracy.
read the caption
Figure 6: Visual comparisons of different training dataset models.

🔼 This figure shows a visual comparison of the ground truth segmentation masks and the predictions made by the proposed method and several single-dataset trained models. The figure demonstrates that the method achieves a strong performance across all training datasets by integrating label spaces from different datasets. For example, it can predict lane marking and crosswalk for ADE and BDD datasets, and books for the SUN dataset.
read the caption
Figure 7: Visual comparisons on training datasets.

🔼 This figure shows a visual comparison of segmentation results on different datasets using both a single-dataset model and the proposed multi-dataset model. Each column represents a different dataset (BDD, Mapillary, ADE, and the proposed model). The rows represent (top to bottom) the input image, the ground truth segmentation masks, the output from a model trained only on the BDD dataset, the output from a model trained only on the Mapillary dataset, the output from a model trained only on the ADE dataset, and finally the output from the proposed model trained on multiple datasets. The comparison visually demonstrates the effectiveness of the proposed method in generating consistent and accurate segmentation results across different datasets.
read the caption
Figure 3: Visual comparisons with Single dataset model on different training datasets.

🔼 This figure shows a qualitative comparison of the semantic segmentation results on the WildDash 2 benchmark dataset. It compares the ground truth (GT) segmentations with the predictions from several different models, including the authors’ trained model, their unseen model, and other state-of-the-art models like Uni NLL+, FAN, and MIX6D. The comparison highlights the robustness and generalization capabilities of the authors’ approach, particularly in challenging real-world scenarios presented in the WildDash 2 dataset.
read the caption
Figure 9: Visual comparisons on WildDash 2 benchmark.
More on tables

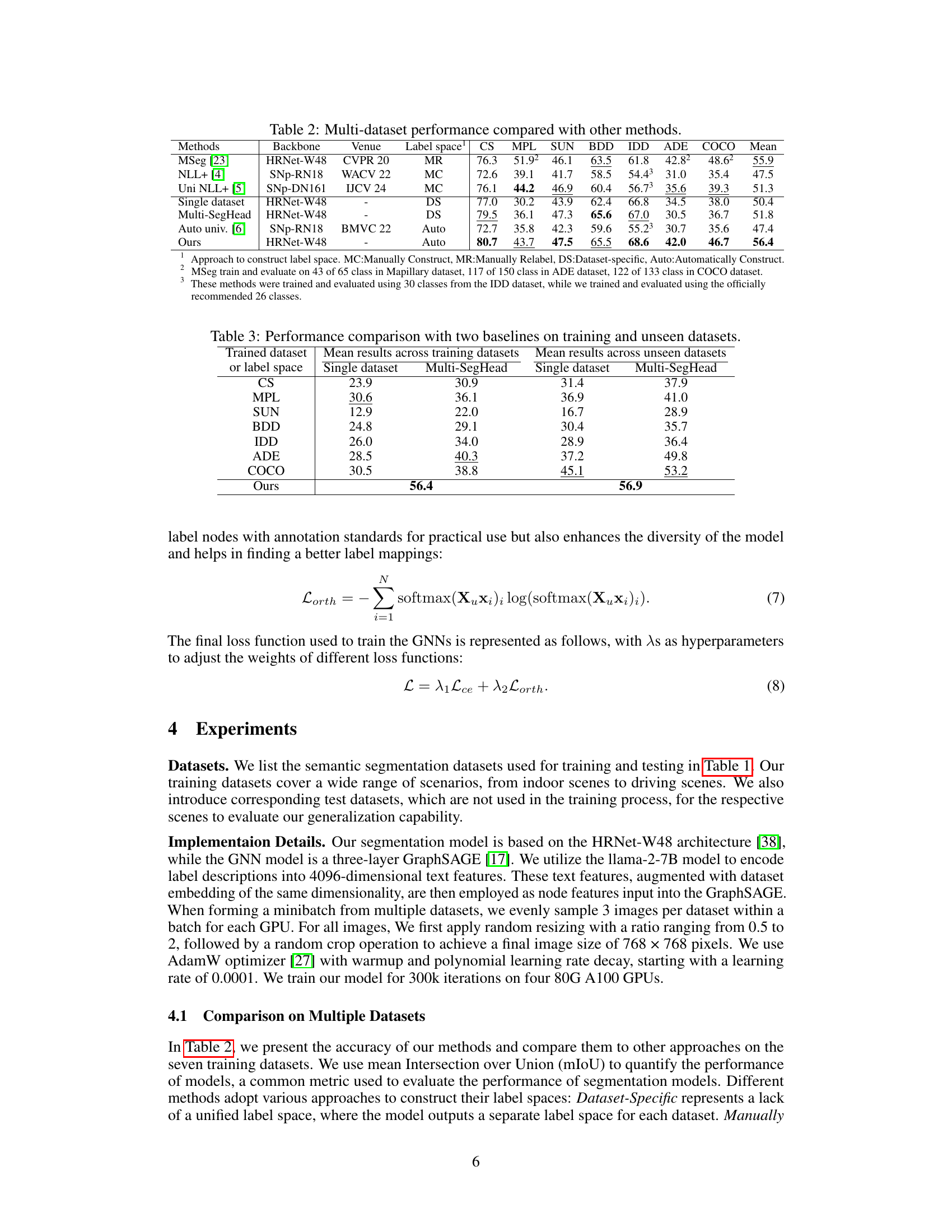
🔼 This table compares the performance of the proposed method against other state-of-the-art multi-dataset semantic segmentation methods. It shows the mean Intersection over Union (mIoU) achieved on seven datasets (Cityscapes, Mapillary, BDD, IDD, ADE20K, COCO) using different backbones and label space construction approaches. The methods are categorized by how they construct the unified label space: Manually Construct, Manually Relabel, Dataset-specific, Automatically Construct. The table highlights the superior performance of the proposed method, particularly in its ability to automatically construct a unified label space.
read the caption
Table 2: Multi-dataset performance compared with other methods.
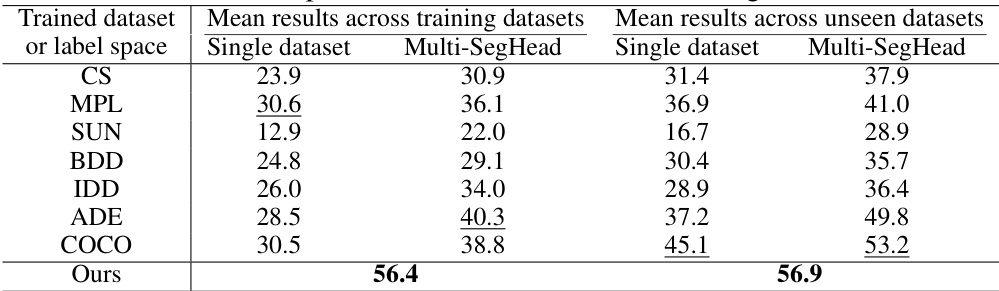
🔼 This table compares the performance of the proposed method with two baselines: a single dataset model and a multi-SegHead model, across both training and unseen datasets. The table shows the mean results (mIoU) for each dataset (CS, MPL, SUN, BDD, IDD, ADE, COCO) for both training and unseen datasets. It highlights that the proposed method significantly outperforms the baselines, especially in the unseen datasets, demonstrating better generalization ability.
read the caption
Table 3: Performance comparison with two baselines on training and unseen datasets.
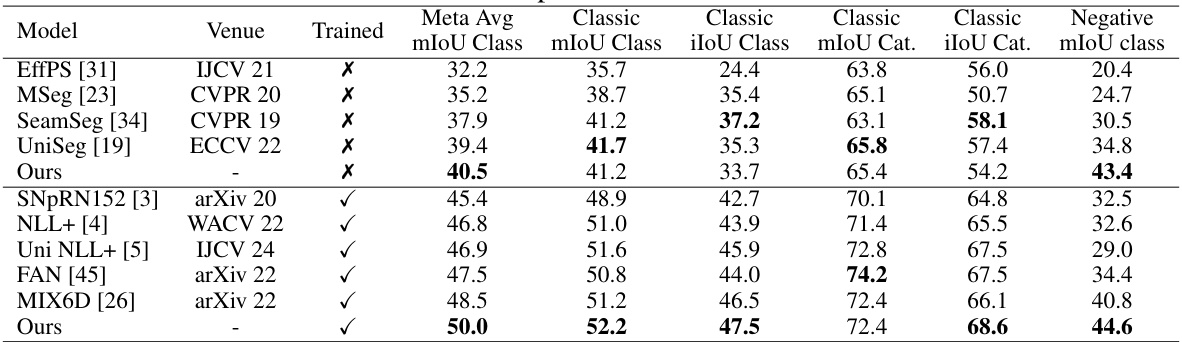
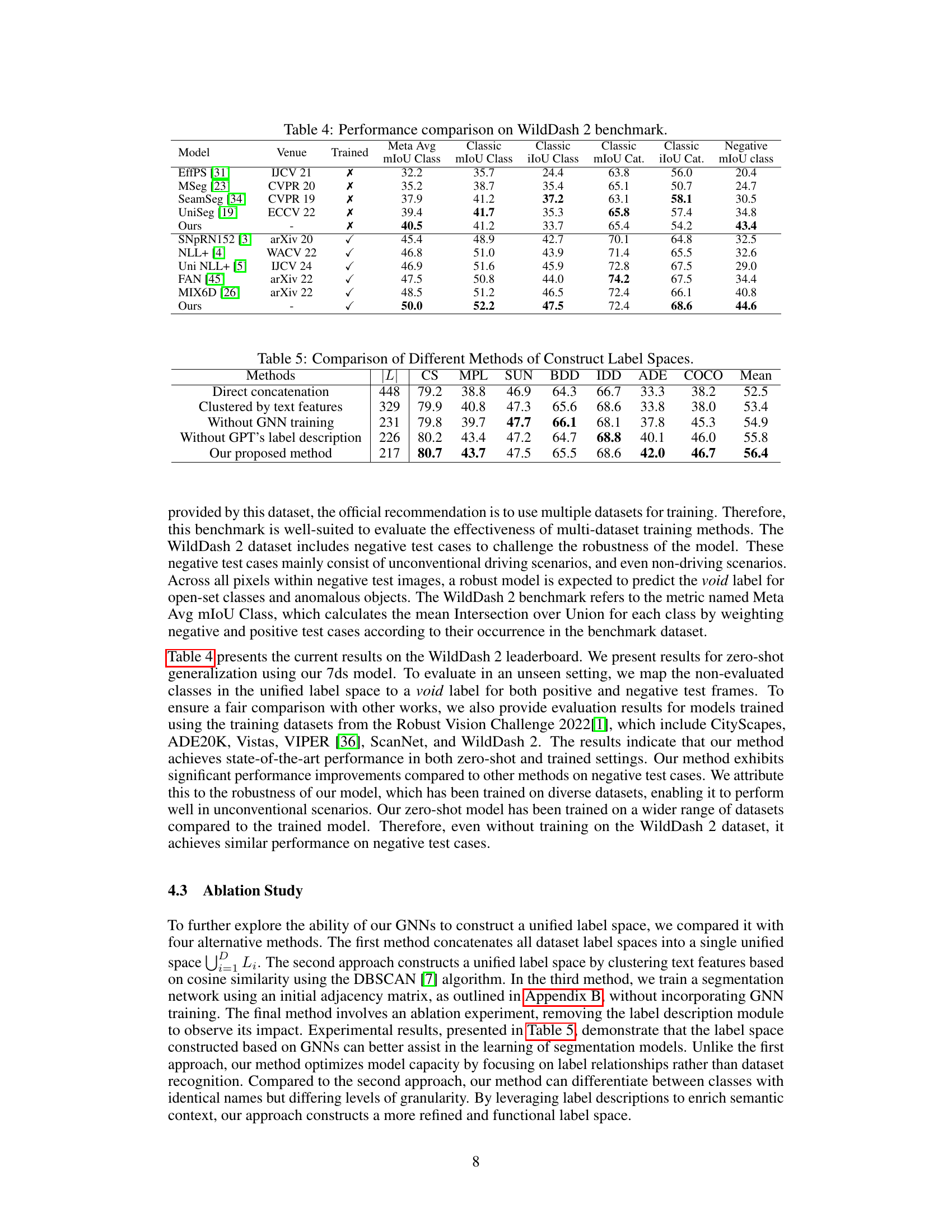
🔼 This table presents a comparison of the proposed method’s performance on the WildDash 2 benchmark against other state-of-the-art methods. It shows the mean Intersection over Union (mIoU) for different categories (classic and negative) and splits the results based on whether the model was trained on the WildDash 2 dataset or not. The ‘Meta Avg’ column indicates the overall performance across all classes, weighted by their frequency in the benchmark dataset.
read the caption
Table 4: Performance comparison on WildDash 2 benchmark.

🔼 This table compares various methods for constructing unified label spaces across multiple datasets in semantic segmentation. It shows the mean Intersection over Union (mIoU) achieved by different methods on eight datasets (Cityscapes, Mapillary, SUN RGB-D, Berkeley Deep Drive, IDD, ADE20K, COCO, and Pascal VOC). The methods include: direct concatenation of label spaces, clustering labels based on text features, a method without graph neural network (GNN) training, a method without GPT label descriptions, and the proposed method. The table demonstrates the superiority of the proposed method in building a unified label space that improves the performance of semantic segmentation across multiple datasets. The ‘‘‘L’’’ column represents the number of unified labels generated by each method.
read the caption
Table 5: Comparison of Different Methods of Construct Label Spaces.
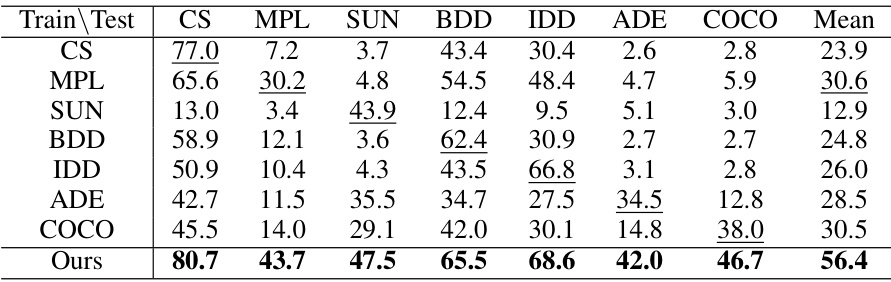
🔼 This table presents the mean Intersection over Union (mIoU) achieved by training a semantic segmentation model on each of seven datasets individually (single dataset) and simultaneously using the proposed method. The diagonal elements represent the mIoU when the training and test sets are the same dataset. The off-diagonal values show the model’s performance when trained on one dataset and tested on a different one. This helps quantify the impact of dataset-specific characteristics and label conflicts on model performance, highlighting the effectiveness of the proposed multi-dataset training approach.
read the caption
Table 7: Semantic segmentation accuracy (mIoU) on training datasets compared with Single dataset model.
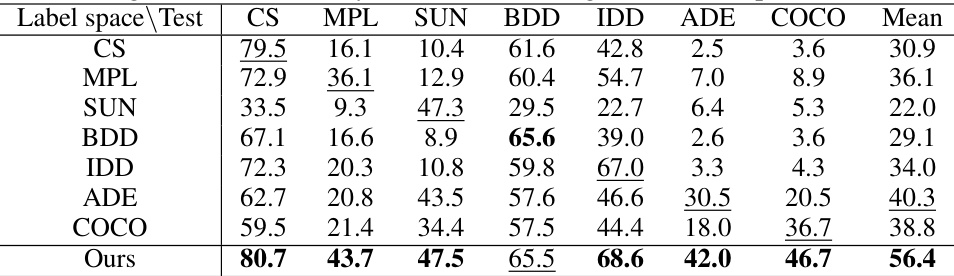
🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by different methods on seven training datasets (Cityscapes, Mapillary, SUN RGBD, BDD100K, IDD, ADE20K, and COCO). The methods compared are: Multi-SegHead (using dataset-specific segmentation heads), and the proposed method (using a unified label space). The table shows the mIoU for each dataset and the mean mIoU across all datasets, highlighting the superior performance of the proposed method.
read the caption
Table 8: Semantic segmentation accuracy (mIoU) on training datasets compared with Multi-SegHead.

🔼 This table presents a comparison of semantic segmentation accuracy (measured by mean Intersection over Union, or mIoU) on five unseen datasets (KITTI, ScanNet, CamVid, Pascal VOC, and Pascal Context) between a model trained on a single dataset and the proposed model (Ours). It highlights the generalization capability of the proposed approach by demonstrating its performance on datasets not included in its training.
read the caption
Table 9: Semantic segmentation accuracy (mIoU) on unseen datasets compared with Single dataset.
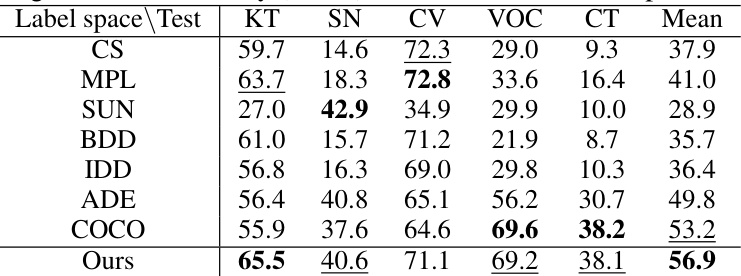
🔼 This table compares the performance of semantic segmentation models trained on different datasets against models trained only on a single dataset. It provides a measure (mIoU) of how accurately the models segment images into different classes on unseen datasets. This comparison helps in understanding the generalization capabilities of models trained on multiple datasets. The results show improved performance when training on multiple datasets.
read the caption
Table 9: Semantic segmentation accuracy (mIoU) on unseen datasets compared with Single dataset.

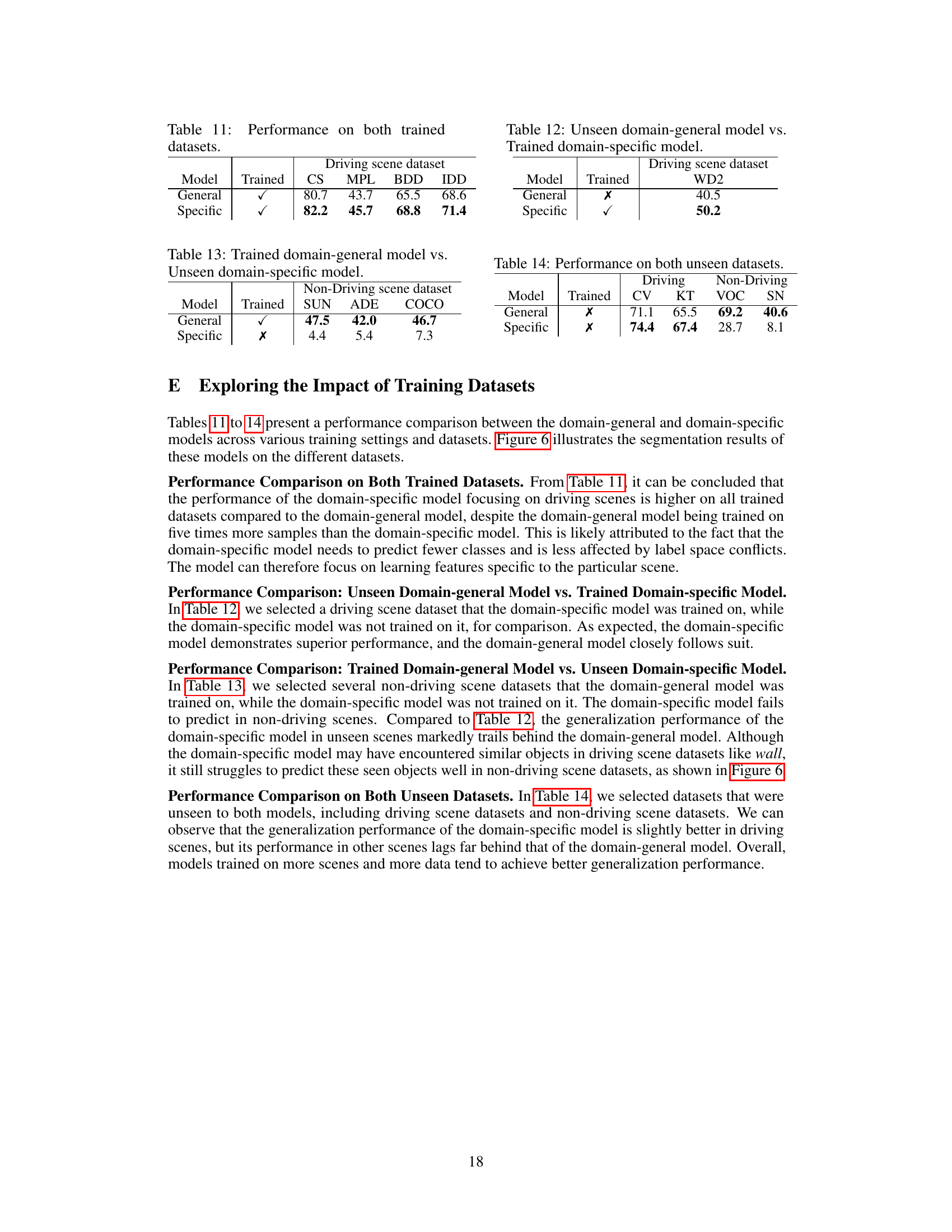
🔼 This table presents the performance comparison between the domain-general and domain-specific models on the four driving scene datasets (Cityscapes, Mapillary, Berkeley Deep Drive, and Intelligent Driving Dataset) that both models were trained on. The domain-specific model shows superior performance, suggesting that focusing on a particular domain leads to better performance on trained datasets within that domain. The domain-general model, while not lagging significantly, demonstrates a lower performance compared to the domain-specific model.
read the caption
Table 11: Performance on both trained datasets.

🔼 This table presents the performance comparison between the unseen domain-general model and the trained domain-specific model. The domain-specific model is trained on driving scene datasets while the domain-general model is trained on a broader range of datasets. The results show that the domain-specific model significantly outperforms the domain-general model on the driving scene dataset (WildDash2). This highlights that the domain-specific model excels at learning features specific to the target scene while the domain-general model shows better generalization capability to the unseen dataset.
read the caption
Table 12: Unseen domain-general model vs. Trained domain-specific model.

🔼 This table compares the performance of a domain-general model (trained on multiple datasets) against a domain-specific model (trained only on driving scene datasets) when tested on non-driving scene datasets (SUN, ADE, COCO). The results show a significant performance gap, highlighting the generalization capability of the domain-general model.
read the caption
Table 13: Trained domain-general model vs. Unseen domain-specific model.
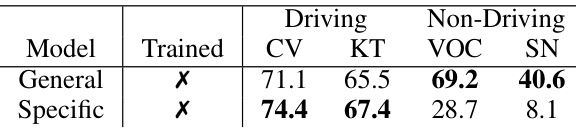
🔼 This table presents the performance comparison between the domain-general and domain-specific models on unseen datasets. The domain-general model shows better generalization performance on non-driving datasets, while the domain-specific model performs slightly better on driving scene datasets. It highlights the trade-off between specializing for one type of scene and generalizing across many.
read the caption
Table 6: Performance on unseen dataset.
Full paper#