TL;DR#
Federated multi-view clustering (FedMVC) faces challenges when data is distributed across clients with varied numbers and qualities of views. Existing methods often assume uniformity which is unrealistic in practical settings, where some clients may have complete data from all views while others only have partial views. This heterogeneity leads to problems of model misalignment and biased clustering results.
To tackle these issues, the authors present FMCSC. This new framework uses a combination of cross-client consensus pre-training, local-synergistic contrastive learning, and global-specific weighting aggregation. Cross-client pre-training aligns local models, addressing initial misalignment. Local-synergistic contrastive learning bridges the gap between single and multi-view clients by encouraging consistent feature learning. Finally, global-specific weighting aggregation handles the view gap by ensuring the global model appropriately weights information from different views. Experimental results on various datasets show FMCSC outperforms current state-of-the-art FedMVC methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning and multi-view clustering due to its novel approach to handling heterogeneous hybrid views. It addresses the critical challenges of data heterogeneity and model misalignment in real-world scenarios, offering significant improvements in clustering performance while preserving data privacy. The proposed framework and theoretical analysis provide valuable insights and guidance for future research in this rapidly evolving field, opening avenues for addressing privacy and data quality issues.
Visual Insights#
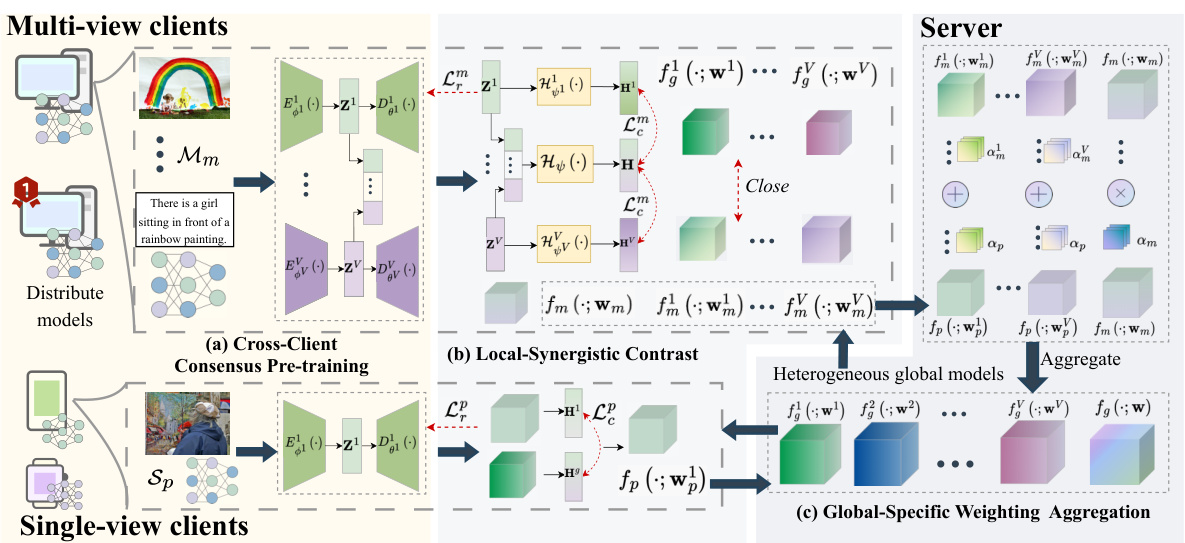
🔼 This figure illustrates the FMCSC framework, which involves three main stages: 1) Cross-Client Consensus Pre-training to align local models, 2) Local-Synergistic Contrast for single-view and multi-view clients to learn consistent features, and 3) Global-Specific Weighting Aggregation to combine local models into heterogeneous global models. The final stage involves using these global models to discover cluster structures.
read the caption
Figure 1: The framework of FMCSC. Initially, each client conducts cross-client consensus pre-training to alleviate model misalignment (Section 3.2). Then, all clients begin training using the designed local-synergistic contrast (Section 3.3) and upload their local models to the server. The server performs global-specific weighting aggregation and distributes multiple heterogeneous global models to all clients (Section 3.4). Finally, leveraging global models received from the server, clients discover complementary cluster structures across all clients.
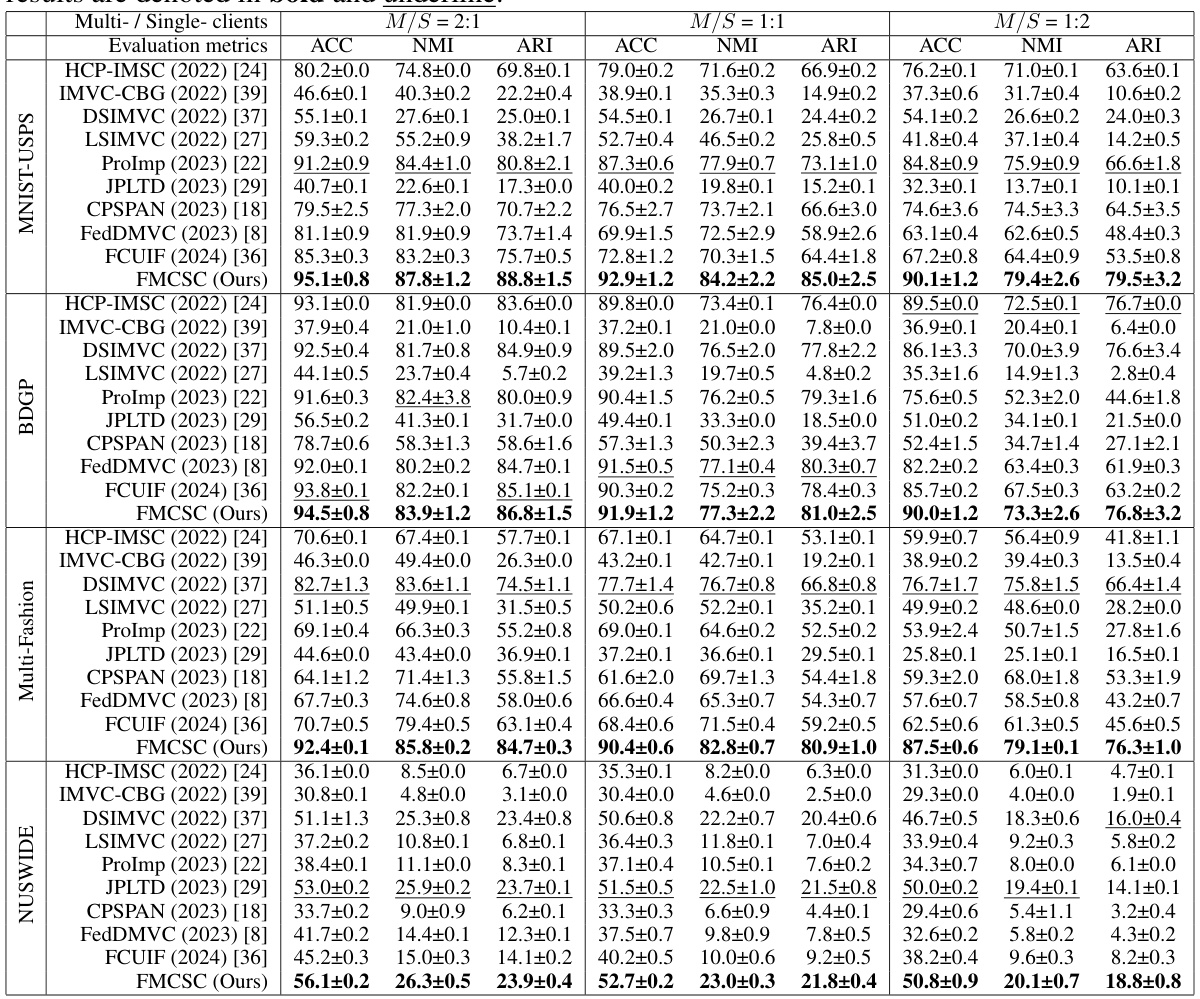
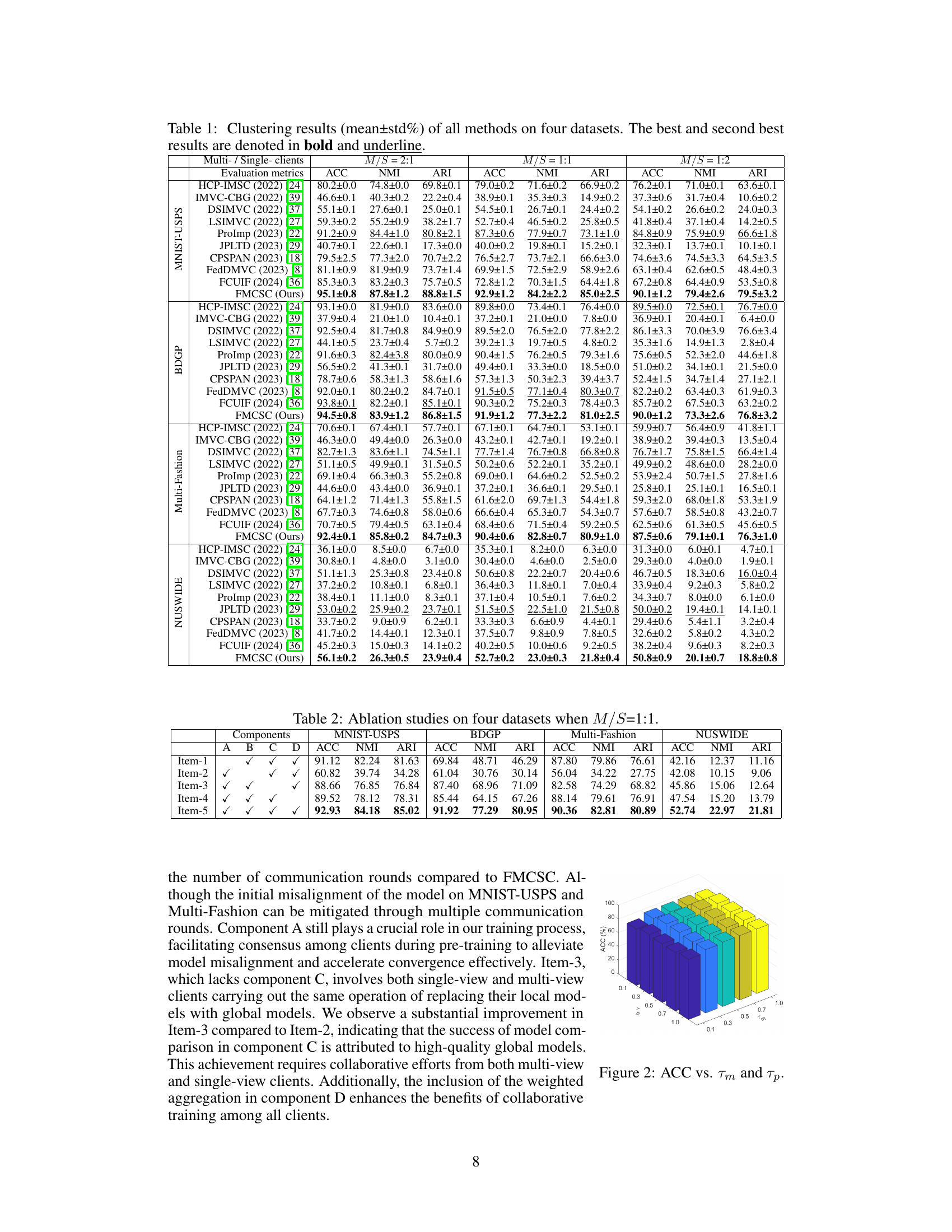
🔼 This table presents a quantitative comparison of the proposed FMCSC method against nine state-of-the-art multi-view clustering methods across four different datasets (MNIST-USPS, BDGP, Multi-Fashion, NUSWIDE). The results are shown for three different ratios of multi-view to single-view clients (2:1, 1:1, 1:2), evaluating performance using three metrics: Accuracy (ACC), Normalized Mutual Information (NMI), and Adjusted Rand Index (ARI). The best and second-best results for each scenario are highlighted in bold and underlined, respectively, providing a clear view of FMCSC’s comparative performance.
read the caption
Table 1: Clustering results (mean±std%) of all methods on four datasets. The best and second best results are denoted in bold and underline.
In-depth insights#
FedMVC Challenges#
Federated multi-view clustering (FedMVC) presents unique challenges stemming from the distributed nature of data and the inherent heterogeneity of multi-view data. Data heterogeneity across clients, including variations in data volume, view types, and data quality, poses a significant hurdle. Communication efficiency is crucial given the decentralized setting; minimizing data transfer between clients and the central server is paramount. Privacy preservation is another critical aspect, as FedMVC needs to protect sensitive information residing on individual clients. Model heterogeneity may arise from diverse local models trained on varied data distributions. Furthermore, view alignment becomes critical when clients possess different views of the same data or when views exhibit differing levels of information richness. Effectively addressing these challenges through innovative methods is crucial to unlock the full potential of FedMVC.
FMCSC Framework#
The FMCSC framework, designed for federated multi-view clustering, stands out by directly addressing the challenges posed by heterogeneous hybrid views. It employs a two-pronged approach, tackling both the client gap (inconsistencies between single and multi-view clients) and the view gap (varied data quality across views). The framework begins with cross-client consensus pre-training to harmonize local models and mitigate model misalignment before proceeding to its core stages. Local-synergistic contrastive learning is employed to bridge the client gap, aligning single-view client features and model outputs with those from multi-view clients, encouraging a more consistent representation. Finally, global-specific weighting aggregation is used to integrate local models effectively, addressing the view gap by extracting complementary features across all client views and creating robust, generalizable global models. This iterative process of pre-training, contrastive learning, and weighted aggregation is what makes FMCSC particularly effective at handling complex datasets with varying degrees of data availability and heterogeneity across clients.
Synergistic Learning#
Synergistic learning, in the context of multi-view learning, aims to combine information from multiple views in a way that is more effective than simply concatenating them. The core idea is that different views provide complementary information, and that by learning from them jointly, we can achieve a better understanding of the underlying data than by treating each view separately. Effective synergistic learning methods carefully consider how to fuse the heterogeneous data, often using techniques that explicitly model the relationships between different views. This might involve building a joint representation, using weighted averaging schemes that take view quality into account, or employing techniques such as co-training, where models trained on one view are used to improve the performance of models trained on another. Successful synergistic methods must address challenges such as view heterogeneity, where views have different data types and qualities, and missing data across views. The ultimate goal is to build a more robust and accurate model that leverages all the available information, leading to improved performance on downstream tasks such as clustering or classification.
Theoretical Analysis#
A theoretical analysis section in a research paper would delve into the mathematical underpinnings of the proposed method. It would likely present theorems and lemmas, providing rigorous proof to support claims made about the algorithm’s performance and properties. Key aspects might include establishing bounds on generalization error, analyzing convergence rates, or quantifying the information gain or mutual information achieved. For a Federated Multi-View Clustering method, the analysis would likely address how heterogeneity among clients and views impacts the algorithm’s performance, perhaps demonstrating convergence under different data distributions. It might also explore the trade-offs between communication costs and clustering accuracy in a federated setting. A strong theoretical analysis section not only validates the proposed approach but also enhances its credibility and provides deeper insights into its behavior.
Future of FedMVC#
The future of federated multi-view clustering (FedMVC) looks promising, driven by the need for privacy-preserving collaborative learning on decentralized data. Addressing heterogeneity in data distributions across clients, including variations in the number and types of views, remains a key challenge. Future research should focus on developing more robust and efficient algorithms that can handle diverse data characteristics and network conditions. Advanced techniques, such as graph neural networks, contrastive learning, and efficient aggregation strategies, offer potential solutions. Furthermore, exploring the integration of domain adaptation and transfer learning methods could enhance the ability of FedMVC to handle data from different domains and improve model generalization. Privacy-enhancing techniques, like differential privacy and homomorphic encryption, will be essential for securing sensitive data in FedMVC applications. Finally, developing methods for automatic view selection and adaptive weighting of views based on their relevance and quality will be critical for improving the accuracy and efficiency of multi-view clustering in a federated setting. The ultimate goal is to create truly scalable and robust FedMVC systems capable of handling a wide array of real-world applications while upholding strict privacy standards.
More visual insights#
More on figures
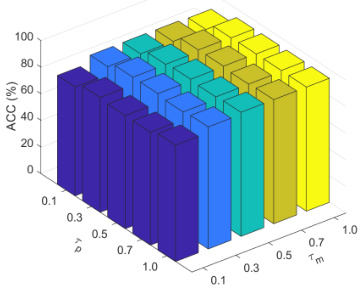
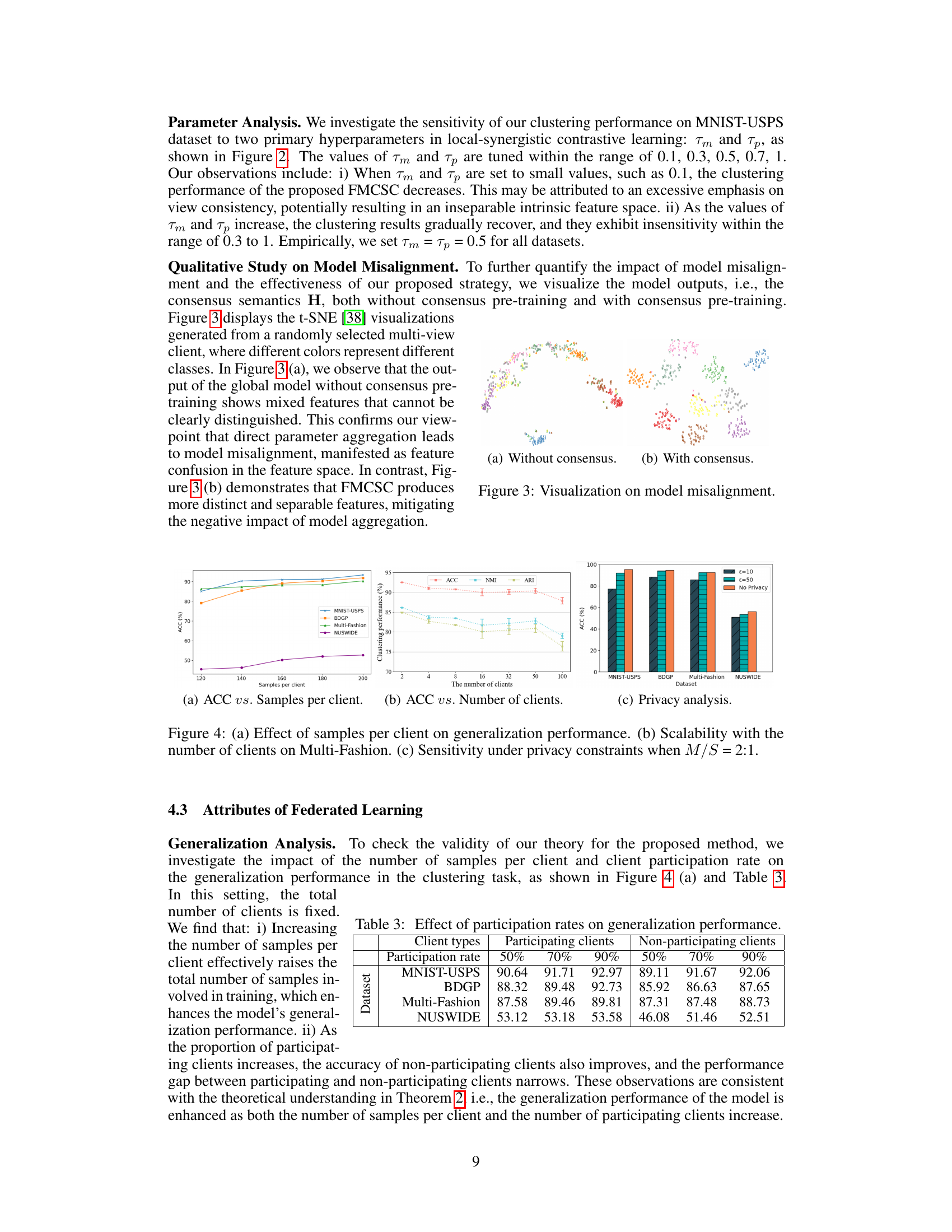
🔼 This figure shows the impact of temperature parameters Tm and Tp on the clustering accuracy (ACC) of the FMCSC method. The x and y axes represent Tm and Tp respectively, ranging from 0.1 to 1.0. Each bar represents the ACC for a given combination of Tm and Tp values. The figure demonstrates the sensitivity of the clustering performance to these hyperparameters and helps determine optimal settings for Tm and Tp. Different colors might represent different datasets or experimental conditions.
read the caption
Figure 2: ACC vs. Tm and Tp.

🔼 This figure visualizes the impact of consensus pre-training on model alignment using t-SNE. (a) shows the feature space without consensus pre-training, demonstrating feature mixing and poor separability. (b) shows the feature space with consensus pre-training, revealing distinct and separable features indicating effective alignment.
read the caption
Figure 3: Visualization on model misalignment.
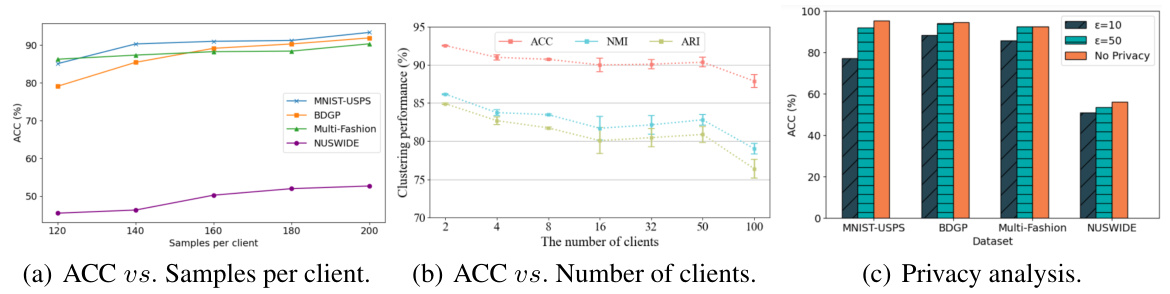
🔼 This figure demonstrates the impact of the number of clients on the clustering performance of FMCSC across different datasets (MNIST-USPS, BDGP, and NUSWIDE). Each sub-figure displays the accuracy (ACC), normalized mutual information (NMI), and adjusted rand index (ARI) against the number of clients. It shows that FMCSC maintains relatively stable performance even as the number of clients increases, indicating robustness and scalability. However, a slight decline in performance is observed for MNIST-USPS when the client number reaches 50, which is attributed to insufficient samples per client.
read the caption
Figure 7: Scalability with the number of clients.
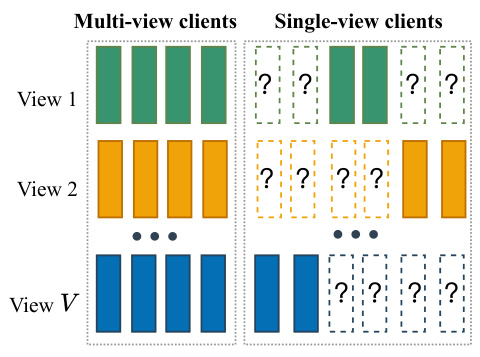
🔼 This figure illustrates the data distribution strategies in the heterogeneous hybrid view scenario of federated multi-view clustering. The left side represents the multi-view clients, who have complete data across all views (View 1 to View V). The right side represents the single-view clients, who only have partial data. In this scenario, multi-view clients have complete data for all views, while single-view clients only have data for some views. This data distribution creates challenges in federated multi-view clustering because the clients have varying amounts of data, and the data is not uniformly distributed among the clients.
read the caption
Figure 5: Comparison strategies.
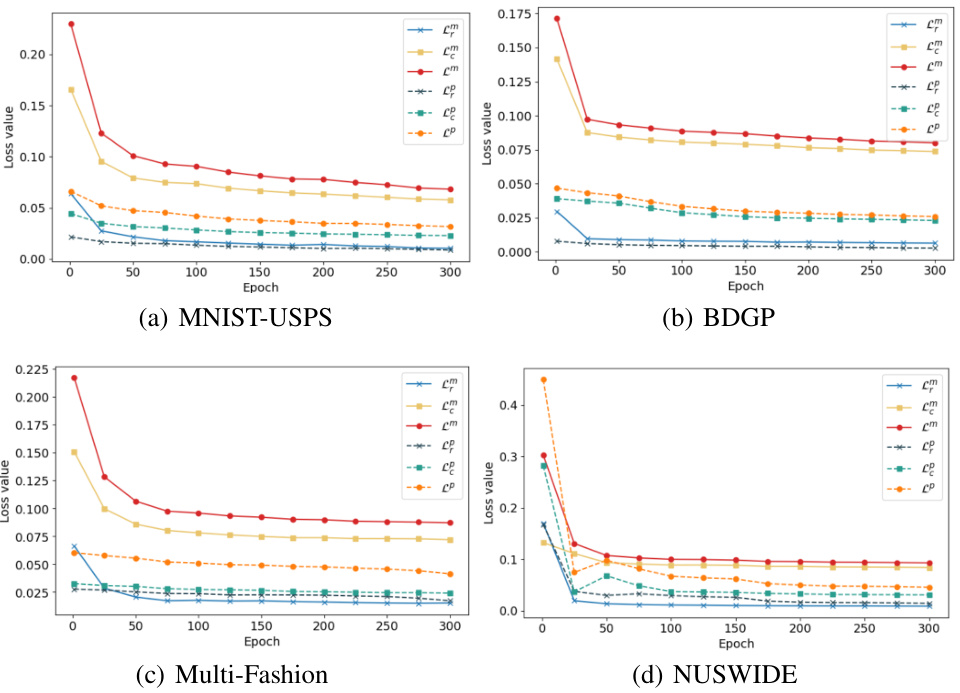
🔼 This figure presents the convergence analysis of the reconstruction loss, consistency loss, and total loss for multi-view and single-view clients on four datasets: MNIST-USPS, BDGP, Multi-Fashion, and NUSWIDE. Each subfigure shows the loss values over the number of epochs for different loss types (Cm, CP, Lm, Lp). The plots visually demonstrate the training process, showing how the losses decrease and eventually reach a stable state. This visual representation supports the stability and effectiveness of the proposed FMCSC method.
read the caption
Figure 6: Convergence analysis on four datasets.
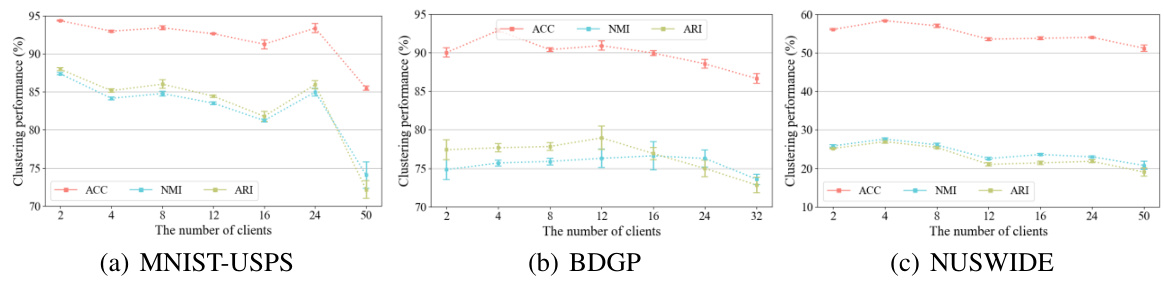
🔼 This figure shows the impact of the number of clients on the clustering performance for three datasets: MNIST-USPS, BDGP, and NUSWIDE. Each subfigure displays the accuracy (ACC), normalized mutual information (NMI), and adjusted rand index (ARI) as the number of clients increases from 2 to 50. Error bars represent the standard deviation across multiple runs. The results demonstrate that the performance of FMCSC remains generally stable even when the number of clients increases, though a slight decrease in performance is observed for MNIST-USPS when the number of clients reaches 50, which is likely due to insufficient samples per client in that scenario.
read the caption
Figure 7: Scalability with the number of clients.
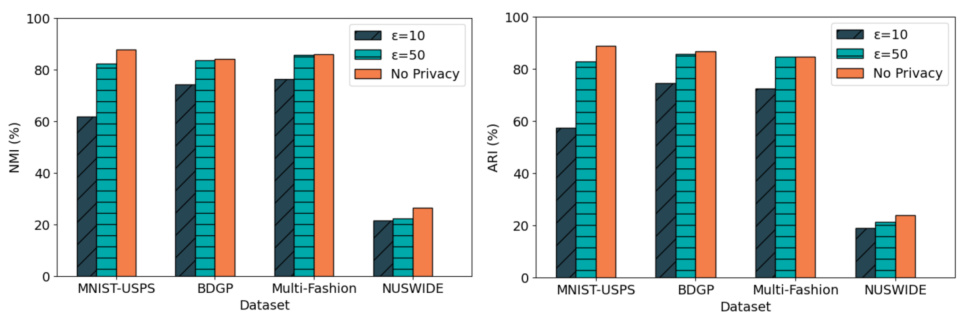
🔼 This figure visualizes the impact of differential privacy on the clustering performance of FMCSC across four datasets (MNIST-USPS, BDGP, Multi-Fashion, NUSWIDE). The results show the NMI (Normalized Mutual Information) and ARI (Adjusted Rand Index) for three different privacy levels (ε=10, ε=50, No Privacy) when the ratio of multi-view clients to single-view clients is 2:1 (M/S = 2:1). It demonstrates how the addition of differential privacy (with varying levels of noise) affects the clustering accuracy, highlighting the trade-off between privacy and performance.
read the caption
Figure 8: Sensitivity under privacy constraints when M/S = 2:1.
More on tables

🔼 This table presents a quantitative comparison of FMCSC against nine state-of-the-art methods (including both centralized and federated multi-view clustering approaches) across four benchmark datasets (MNIST-USPS, BDGP, Multi-Fashion, NUSWIDE) with varying ratios of multi-view to single-view clients. The results are presented as mean ± standard deviation of accuracy (ACC), normalized mutual information (NMI), and adjusted rand index (ARI) across five independent runs. The best and second-best performing methods for each dataset and client ratio are highlighted in bold and underlined, respectively, demonstrating FMCSC’s superior clustering performance, even under diverse heterogeneous hybrid view scenarios.
read the caption
Table 1: Clustering results (mean±std%) of all methods on four datasets. The best and second best results are denoted in bold and underline.
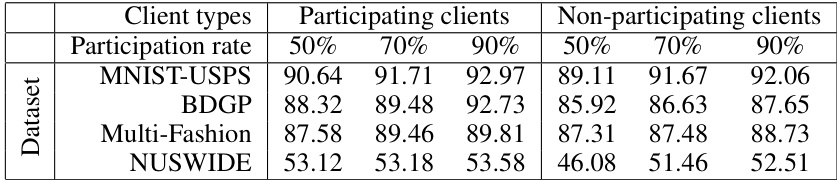
🔼 This table shows the clustering performance (ACC) of the FMCSC method under different participation rates (50%, 70%, 90%) of clients. The performance is evaluated for both participating and non-participating clients, demonstrating the impact of the number of participating clients on generalization performance. The results are presented for four datasets: MNIST-USPS, BDGP, Multi-Fashion, and NUSWIDE.
read the caption
Table 3: Effect of participation rates on generalization performance.

🔼 This table presents a quantitative comparison of the proposed FMCSC method against nine state-of-the-art multi-view clustering methods across four datasets (MNIST-USPS, BDGP, Multi-Fashion, NUSWIDE) under different scenarios. The scenarios vary the ratio of multi-view to single-view clients to simulate heterogeneity. The table shows the results of three clustering evaluation metrics: ACC (Accuracy), NMI (Normalized Mutual Information), and ARI (Adjusted Rand Index). The best and second-best performing methods for each dataset and scenario are highlighted in bold and underlined, respectively, to show the relative performance of FMCSC.
read the caption
Table 1: Clustering results (mean±std%) of all methods on four datasets. The best and second best results are denoted in bold and underline.

🔼 This table presents a quantitative comparison of FMCSC against nine state-of-the-art multi-view clustering methods across four different datasets (MNIST-USPS, BDGP, Multi-Fashion, and NUSWIDE). The results are shown for three different ratios of multi-view to single-view clients (2:1, 1:1, 1:2) and use Accuracy (ACC), Normalized Mutual Information (NMI), and Adjusted Rand Index (ARI) as evaluation metrics. The best and second-best results for each dataset and metric are highlighted in bold and underlined, respectively.
read the caption
Table 1: Clustering results (mean±std%) of all methods on four datasets. The best and second best results are denoted in bold and underline.
Full paper#