↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current Image Copy Detection (ICD) methods struggle to identify replicated content in AI-generated images, particularly those produced by diffusion models. This is because existing ICDs focus on detecting hand-crafted replicas, overlooking the unique patterns in diffusion-generated images. This poses a significant challenge in ensuring content originality in digital artwork and visual marketing, raising intellectual property concerns.
To address this, the authors introduce ICDiff, the first ICD specialized for diffusion models. They create a new dataset, D-Rep, with 40,000 image-replica pairs manually annotated with replication levels. A novel deep embedding method called PDF-Embedding is proposed, which transforms replication levels into probability density functions, improving performance. The results reveal that well-known diffusion models have replication ratios between 10% and 20%, highlighting the need for robust detection techniques. This work provides valuable tools and datasets for future research on content originality in AI-generated content.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on image copy detection and generative models. It addresses the critical issue of content originality in AI-generated images, a significant concern in the digital art and marketing worlds. The introduction of ICDiff and the D-Rep dataset provides a valuable benchmark and opens new avenues for developing robust methods to detect replication in diffusion model outputs. Furthermore, the findings on replication ratios of popular models offer valuable insights for the development of more responsible AI systems.
Visual Insights#

🔼 This figure shows a comparison of images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) with their corresponding source images from the LAION-Aesthetics dataset. The top row displays the generated images, while the bottom row shows the original images from which they appear to be copied. The figure highlights the issue of diffusion models potentially replicating existing content, which is a key challenge addressed in the paper.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

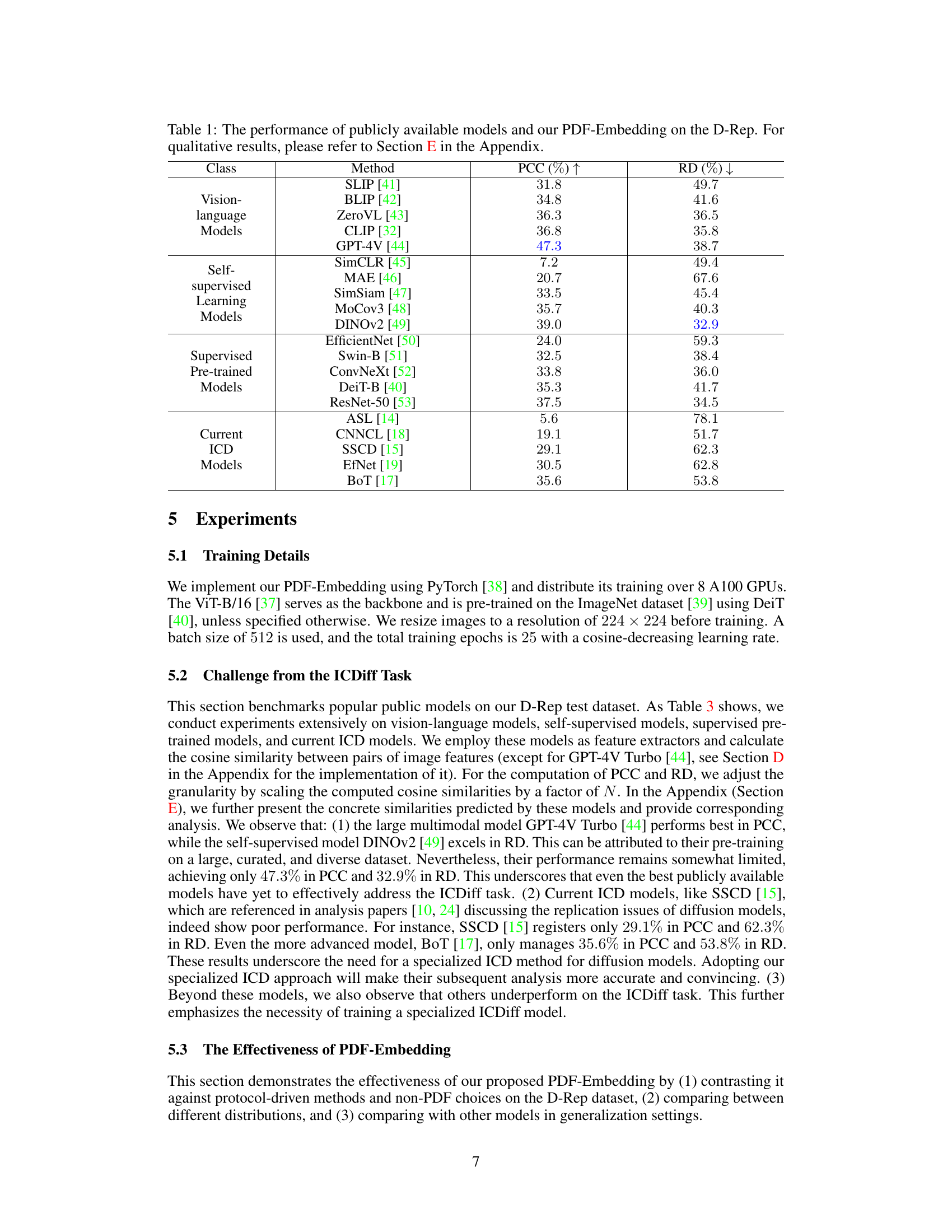
🔼 This table presents a comparison of different methods for image copy detection on the D-Rep dataset, including vision-language models, self-supervised learning models, supervised pre-trained models, and current ICD models. The table shows the performance of each method in terms of PCC (Pearson Correlation Coefficient) and RD (Relative Deviation), which are two metrics used to evaluate the accuracy of image copy detection. Higher PCC indicates better performance and lower RD also indicates better performance. The PDF-Embedding method proposed in the paper is also included in the comparison.
read the caption
Table 1: The performance of publicly available models and our PDF-Embedding on the D-Rep. For qualitative results, please refer to Section E in the Appendix.
In-depth insights#
Diffusion-Based ICD#
A hypothetical ‘Diffusion-Based ICD’ research heading likely explores image copy detection (ICD) methods specifically tailored for images generated by diffusion models. This is crucial because standard ICD techniques, designed for traditional image manipulations, often fail to detect subtle replications inherent in diffusion-generated content. The research would likely involve developing new datasets of diffusion-model generated images and their corresponding originals, focusing on various levels of replication. Novel deep learning architectures or modifications to existing ones would be investigated to effectively capture the unique characteristics of diffusion-based copying. Evaluation metrics would need to be carefully chosen to address the challenges in assessing similarity across varied image styles and resolutions produced by diffusion models. A key aspect would be determining the robustness and generalizability of the proposed methods across different diffusion models and image domains. The overall aim would be to advance the state-of-the-art in detecting content replication in the age of generative AI, addressing both the technical and ethical challenges involved.
PDF-Embedding#
The proposed PDF-Embedding method offers a novel approach to image copy detection, particularly effective for diffusion-model generated images. Instead of directly comparing image embeddings, it leverages the replication level annotation by transforming it into a probability density function (PDF). This PDF represents the likelihood of neighboring replication levels, ensuring smoothness and continuity. The method then learns a set of representative vectors for each image, allowing for a more nuanced comparison than traditional similarity scores. The intuitive advantage is that PDF-Embedding captures the probability distribution rather than just a single score, potentially offering higher accuracy and robustness to variations inherent in diffusion-generated images. The experimental results highlight its superior performance compared to existing methods, demonstrating the effectiveness of modeling replication levels as PDFs. However, future research may need to address potential challenges in handling various distributions or scenarios where the replication level is ambiguous.
D-Rep Dataset#
The creation of a robust and specialized dataset is crucial for evaluating image copy detection models tailored for diffusion models. A dataset like “D-Rep” is vital because existing datasets primarily focus on detecting hand-crafted replicas, failing to address the unique challenges presented by diffusion-model-generated images. D-Rep’s strength likely lies in its comprehensive representation of various levels of replication, ranging from minor alterations to near-identical copies. This graded scale allows for a more nuanced evaluation beyond simple binary classifications of copied or not copied. The inclusion of a large number of pairs (40,000 image-replica pairs) enhances the statistical power of any subsequent analysis. Manually annotating these pairs is resource-intensive but ensures high accuracy in labeling, crucial for the reliability of results and model training. Its division into training and testing sets facilitates rigorous model evaluation, with the 90/10 split allowing for a reliable assessment of model generalization capabilities.
Replication Analysis#
A thorough replication analysis in a research paper would involve a multifaceted approach. It should begin with a clear definition of what constitutes a “replication,” specifying the metrics used to quantify the degree of similarity between original and generated images. The methodology should detail how replications are identified and quantified, perhaps using techniques like perceptual similarity metrics or deep learning-based comparison methods. The analysis must then go beyond simple counts, examining the types of content most prone to replication and exploring potential causes within the diffusion models themselves or biases within the training datasets. The results should be presented visually, maybe with representative examples, and statistically, possibly through significance testing to validate findings. Crucially, the analysis should acknowledge and address any limitations. A thoughtful replication analysis isn’t simply about identifying copies but uncovering insights into the mechanisms of replication and its implications for originality, copyright, and the responsible development of AI.
Future Directions#
Future research directions stemming from this Image Copy Detection for Diffusion Models (ICDiff) paper could explore several promising avenues. Improving the robustness of ICDiff to various image manipulations and styles beyond those included in the D-Rep dataset is crucial. This might involve incorporating generative adversarial networks (GANs) to augment the training data with more realistic and diverse variations. Another key area involves enhancing the efficiency of the PDF-Embedding method, potentially through architectural optimizations or exploring alternative embedding techniques that are computationally less expensive. The investigation of different PDF functions and their impact on accuracy is another avenue worth pursuing. Finally, the extension of ICDiff to other generative models beyond diffusion models and the exploration of more sophisticated evaluation metrics that capture nuanced aspects of replication should also be explored. The development of effective and practical countermeasures to prevent replication in diffusion models is a significant ethical and technological concern that warrants further investigation.
More visual insights#
More on figures
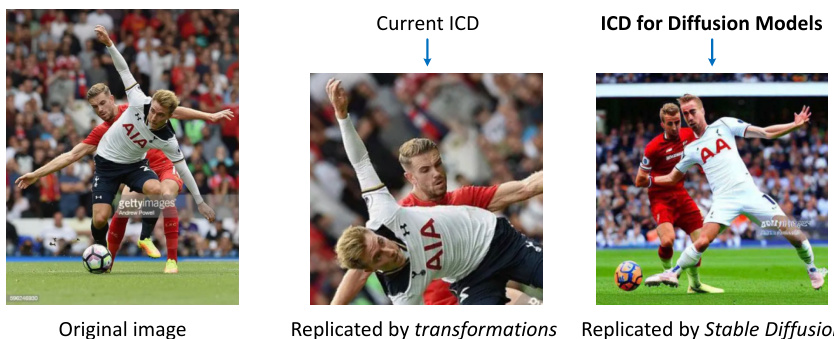
🔼 This figure compares the capabilities of current Image Copy Detection (ICD) methods and the proposed ICDiff method. The left shows a standard ICD method detecting an image modified by simple transformations (flip, rotation, crop). The right shows the proposed ICDiff method successfully detecting an image replicated by a diffusion model (Stable Diffusion). The original image is sourced from a Getty Images lawsuit, highlighting a real-world application of this challenge.
read the caption
Figure 2: The comparison between current ICD with the ICDiff. The current ICD focuses on detecting edited copies generated by transformations like horizontal flips, random rotations, and random crops. In contrast, the ICDiff aims to detect replication generated by diffusion models, such as Stable Diffusion [2]. (Source of the original image: Lawsuit from Getty Images.)

🔼 This figure shows a comparison of images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) with their corresponding source images from the LAION-Aesthetics dataset. The purpose is to visually demonstrate the issue of content replication in diffusion-generated images, which is the main focus of the paper.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

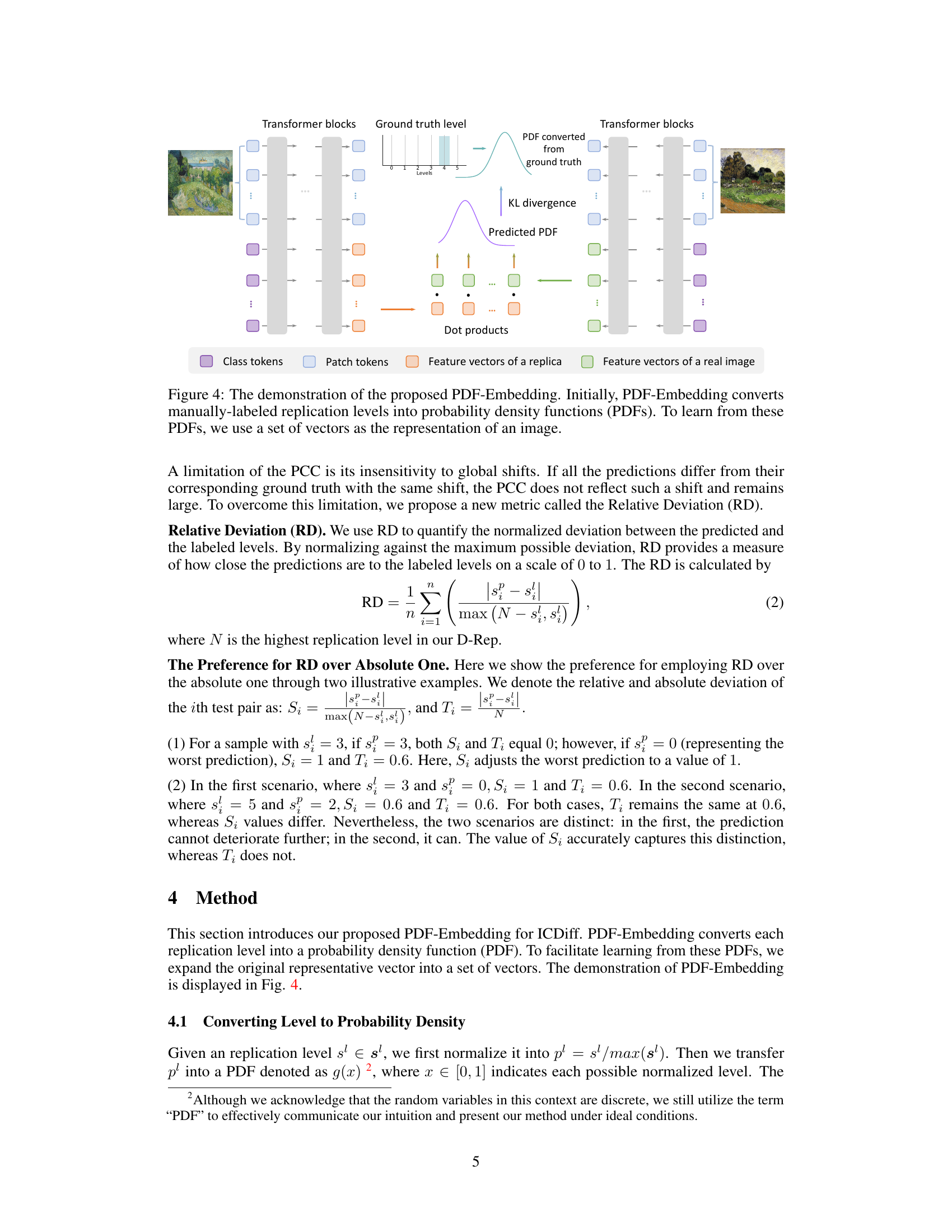
🔼 This figure illustrates the PDF-Embedding method. The method first converts the manually labeled replication levels (0-5) into probability density functions (PDFs). These PDFs represent the probability distribution of neighboring replication levels. Then, a Vision Transformer (ViT) is used to transform each image into a set of vectors. Finally, the KL divergence between the predicted and ground truth PDFs is used as the loss function during training. The goal is to learn a set of representative vectors for each image that reflects the probability distribution of its replication level.
read the caption
Figure 4: The demonstration of the proposed PDF-Embedding. Initially, PDF-Embedding converts manually-labeled replication levels into probability density functions (PDFs). To learn from these PDFs, we use a set of vectors as the representation of an image.
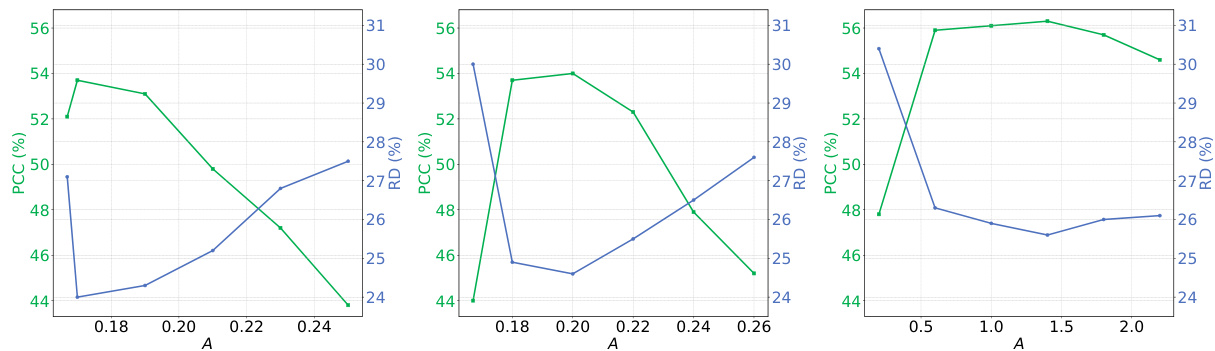
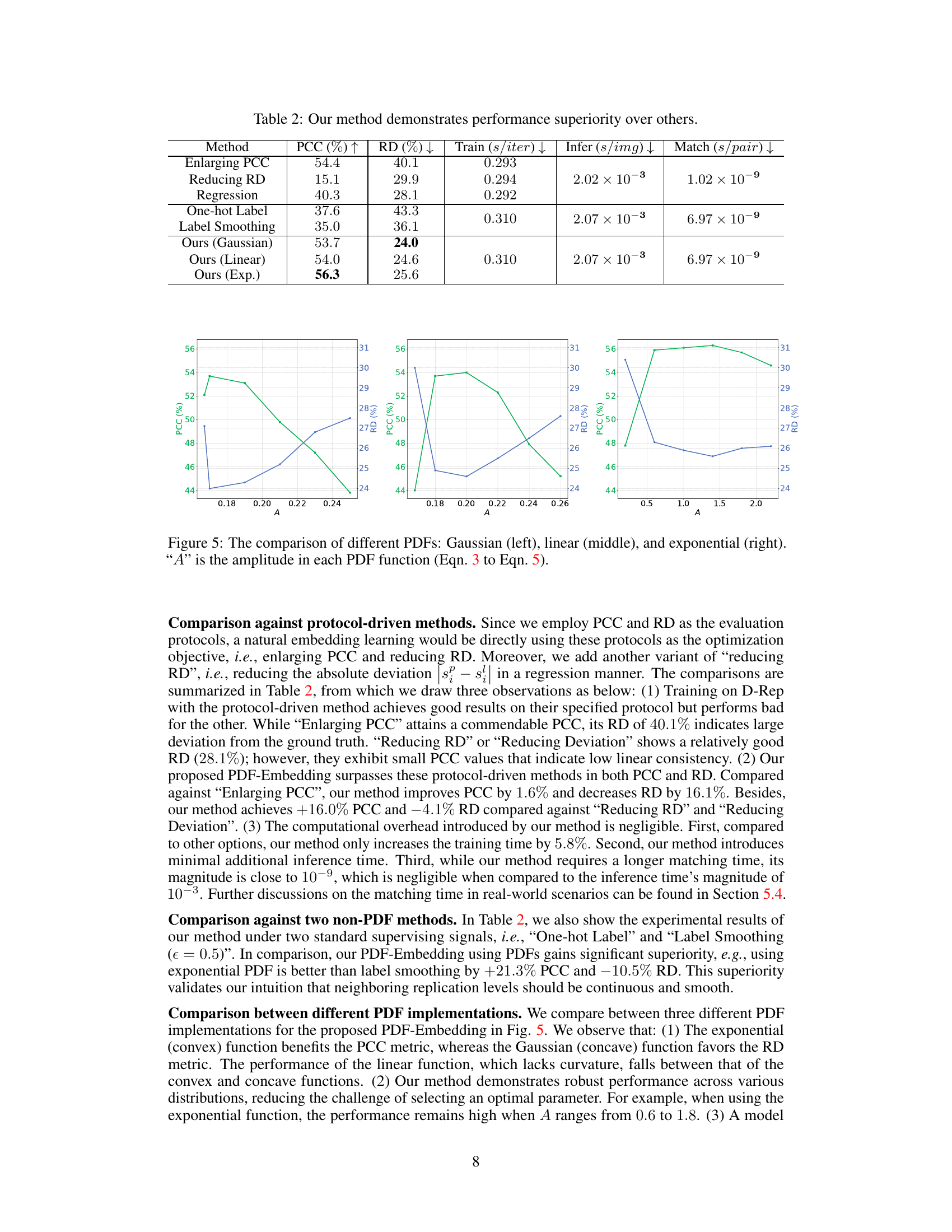
🔼 This figure compares the performance of three different probability density functions (PDFs) – Gaussian, linear, and exponential – used in the PDF-Embedding method. The x-axis represents the amplitude (A) parameter of each PDF, and the y-axis shows the PCC (Pearson Correlation Coefficient) and RD (Relative Deviation) values. The plots illustrate how the choice of PDF impacts the performance metrics. The optimal choice seems to be the exponential PDF with an amplitude (A) around 1.5-1.8, which balances the PCC and RD.
read the caption
Figure 5: The comparison of different PDFs: Gaussian (left), linear (middle), and exponential (right). 'A' is the amplitude in each PDF function (Eqn. 3 to Eqn. 5).
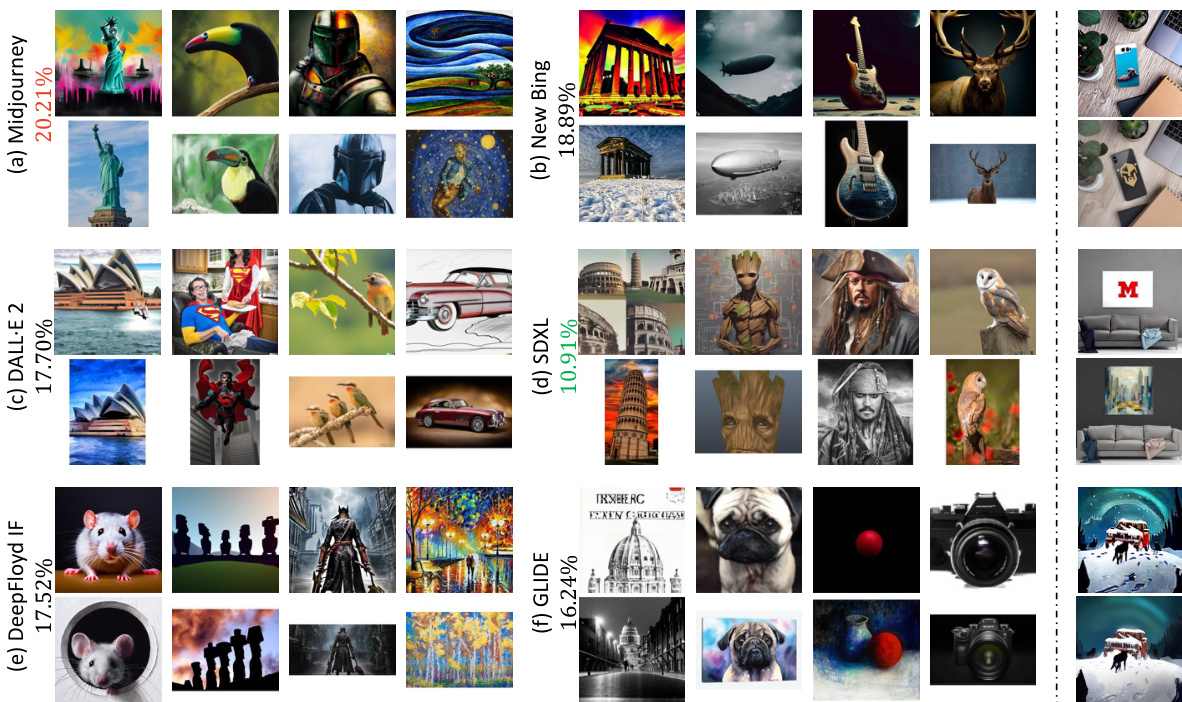
🔼 The figure shows examples of images generated by different diffusion models that replicate existing images. The left side displays images generated by six different diffusion models, showing varying degrees of replication (as indicated by percentages). The right side offers a comparison to results from a previous method (SSCD), highlighting that the new method (PDF-Embedding) finds more diverse and subtle cases of replication.
read the caption
Figure 6: Left: Examples of diffusion-based replication fetched by our PDF-Embedding. The accompanying percentages indicate the replication ratio of each model. Right: Examples filtered by SSCD [15] in [10]. Compared to them, our results are more diverse: For example, the 'Groot' generated by SDXL includes the whole body, whereas the original one features only the face; and the 'Moai statues' created by DeepFloyd IF are positioned differently compared to the original image.

🔼 The figure shows a heatmap visualizing the cosine similarity between the learned vectors representing different replication levels. The heatmap reveals the relationships between these vectors in the embedding space, demonstrating that vectors representing similar replication levels exhibit higher cosine similarity, while vectors representing dissimilar levels have lower similarity. This illustrates the effectiveness of the PDF-Embedding method in capturing the relationships between different replication levels.
read the caption
Figure 7: The cosine similarity heatmap of the learned vectors.

🔼 This figure shows examples of images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE). The top row displays the generated images, while the bottom row shows the corresponding original images from the LAION-Aesthetics dataset, which the generated images replicate to varying degrees. This highlights the challenge of detecting image replication originating from diffusion models, as addressed in the paper.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

🔼 This figure shows a comparison between images generated by various diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) and their corresponding original images from the LAION-Aesthetics dataset. The top row displays the generated images, while the bottom row shows the original images that the generated images appear to replicate. This visually demonstrates the issue of content replication in diffusion models, which is the main focus of the paper.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.
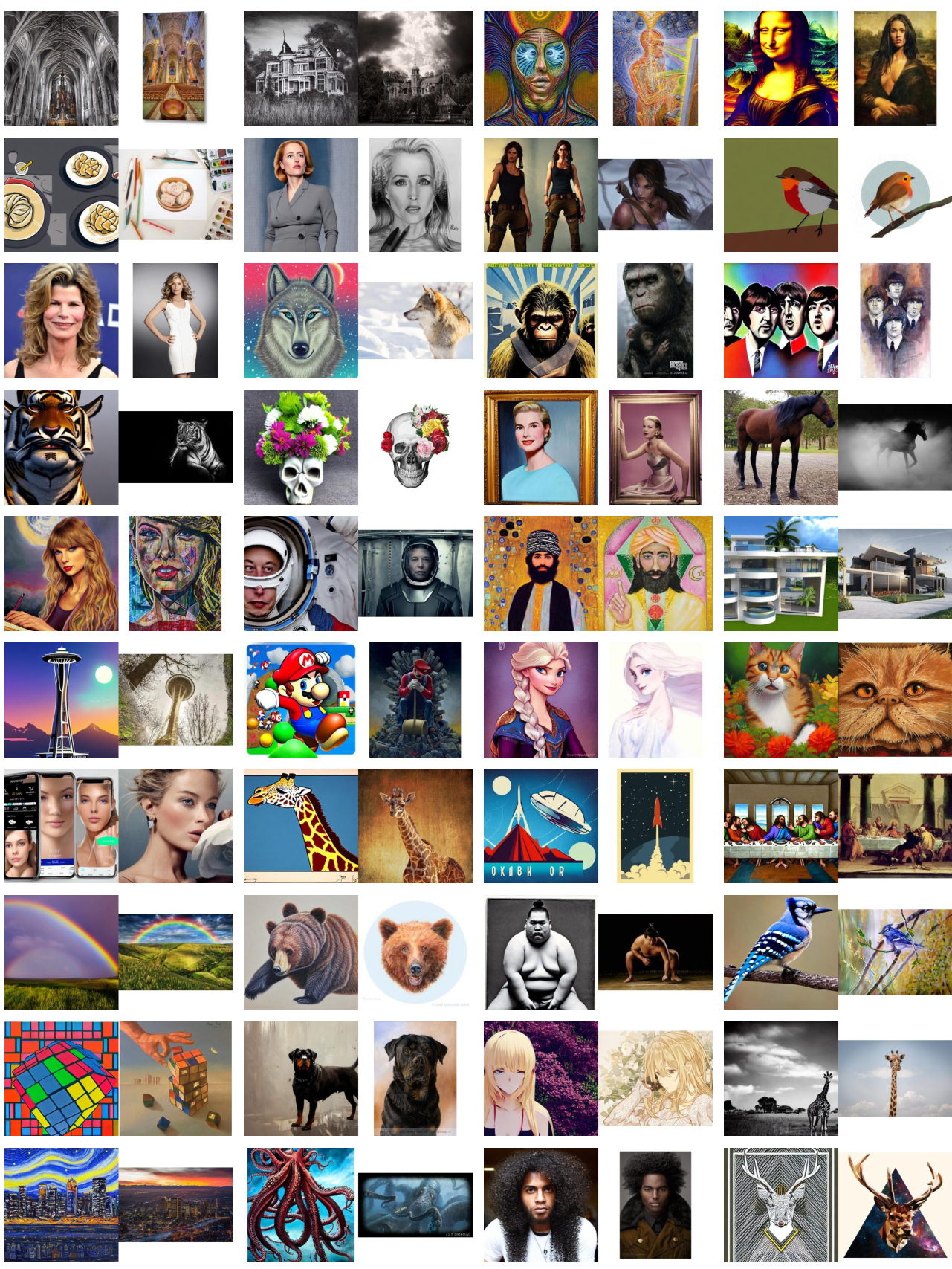
🔼 This figure shows the manual-labeled D-Rep dataset, which contains 40,000 image-replica pairs. Each pair consists of an image from LAION-Aesthetics V2 and its replica generated by Stable Diffusion V1.5. The image pairs are manually annotated with six replication levels, ranging from 0 (no replication) to 5 (total replication). The percentages on the left of the figure represent the proportion of images at each replication level in the dataset.
read the caption
Figure 3: The demonstration of the manual-labeled D-Rep dataset. The percentages on the left show the proportion of images with a particular level.

🔼 This figure shows a comparison of images generated by several different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) with their corresponding source images from the LAION-Aesthetics dataset. The top row displays the generated images, and the bottom row shows the original images that appear to have been replicated by the models. The figure highlights the challenge of detecting image replication in diffusion model outputs.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

🔼 This figure shows a comparison of images generated by several different diffusion models (Midjourney, New Bing, DALL-E 2, Stable Diffusion XL, DeepFloyd IF, and GLIDE) with their corresponding source images from the LAION-Aesthetics dataset. The purpose is to visually demonstrate the phenomenon of diffusion models replicating content from existing images, highlighting the challenge addressed by the paper.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

🔼 This figure shows a comparison of images generated by various diffusion models (Midjourney, New Bing, DALL-E 2, Stable Diffusion XL, DeepFloyd IF, and GLIDE) with their corresponding original images from the LAION-Aesthetics dataset. The top row displays the generated images, while the bottom row shows the original images they appear to replicate. This visualization highlights the challenge of detecting image copy in diffusion model outputs, as the generated images are often subtle variations of existing works.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

🔼 This figure shows a comparison of images generated by different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) with their corresponding original images from the LAION-Aesthetics dataset. The top row displays the generated images, while the bottom row shows the original images they seem to replicate. The purpose is to illustrate the phenomenon of content replication in images generated by diffusion models, highlighting a key challenge the paper addresses.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.
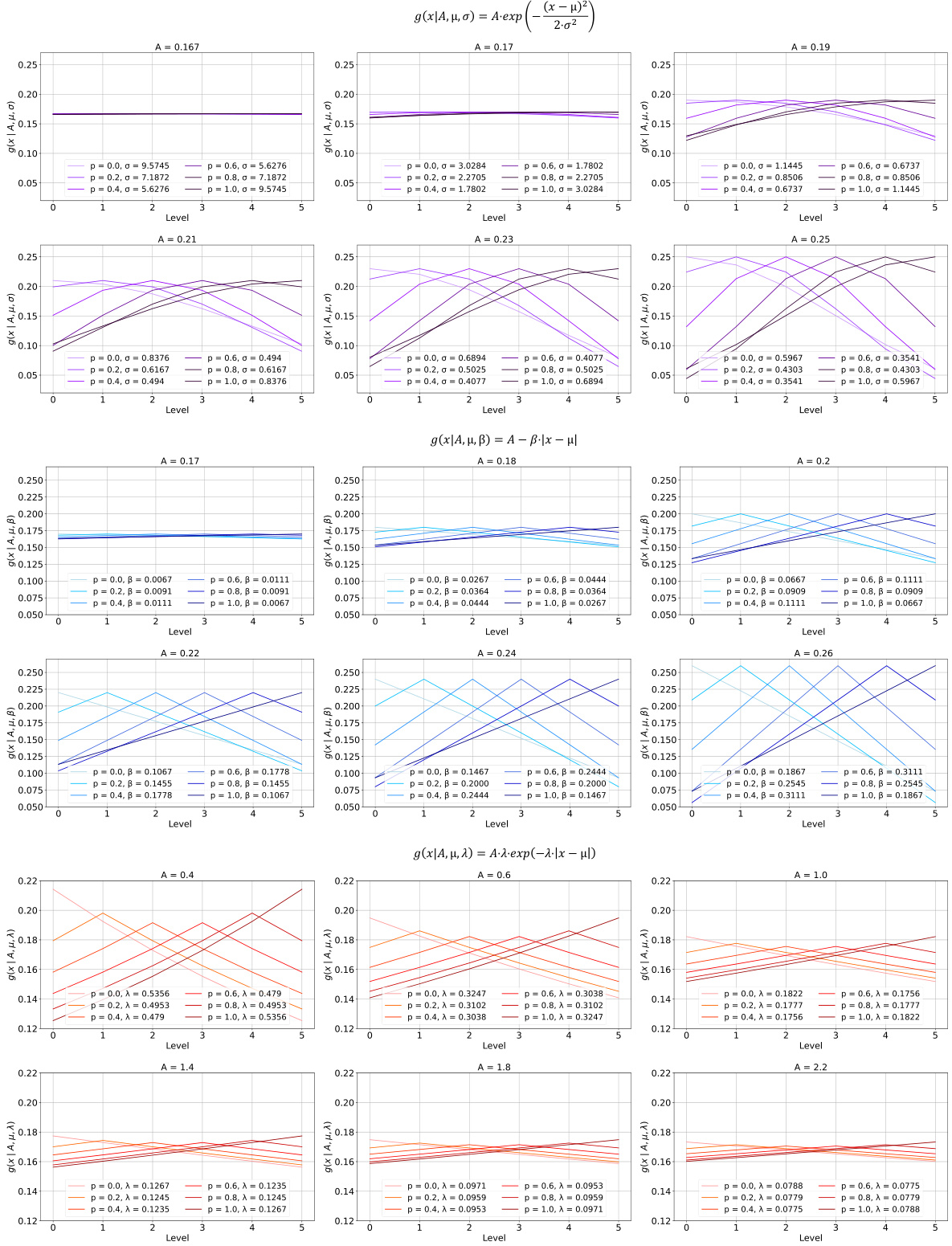
🔼 This figure visualizes the probability density functions (PDFs) derived from different replication levels using three different functions: Gaussian, linear, and exponential. Each function is shown for various normalized levels (p¹), representing the transformation of replication levels into probability distributions. The different shapes of the curves illustrate how the rate at which each function deviates from its peak value changes based on the function. The Gaussian function shows a slow rate of change, the linear function has a constant rate, and the exponential function exhibits a rapid rate of change. This visualization helps illustrate the choice of PDF functions in their proposed PDF-Embedding method.
read the caption
Figure 15: The distributions converted from replication levels. We use Gaussian, linear, and exponential functions as the representative demonstrations.

🔼 This figure shows the distribution of replication levels in the manually labeled D-Rep dataset. The dataset consists of 40,000 image-replica pairs, each manually annotated with a replication level from 0 (no replication) to 5 (total replication). The figure visually represents the percentage of images belonging to each of these six replication levels.
read the caption
Figure 3: The demonstration of the manual-labeled D-Rep dataset. The percentages on the left show the proportion of images with a particular level.

🔼 This figure shows a comparison of images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) with their corresponding original images from the LAION-Aesthetics dataset. The top row displays the generated images, and the bottom row shows the original images that the generated images appear to replicate. This visual demonstrates the challenge of detecting image replication when dealing with diffusion models, as the generated images are often subtly different from, but still clearly based on, the original images. The models used represent a mix of both commercial and open-source options.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

🔼 This figure shows a comparison of images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) with their corresponding source images from the LAION-Aesthetics dataset. The top row displays the generated images, while the bottom row shows the original images from LAION-Aesthetics that they appear to replicate. This visually demonstrates the potential for diffusion models to reproduce existing content.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

🔼 This figure shows a comparison of images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) with their corresponding original images from the LAION-Aesthetics dataset. The purpose of this figure is to illustrate the phenomenon of content replication in images generated by diffusion models, highlighting that some generated images may closely replicate content from existing images.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.
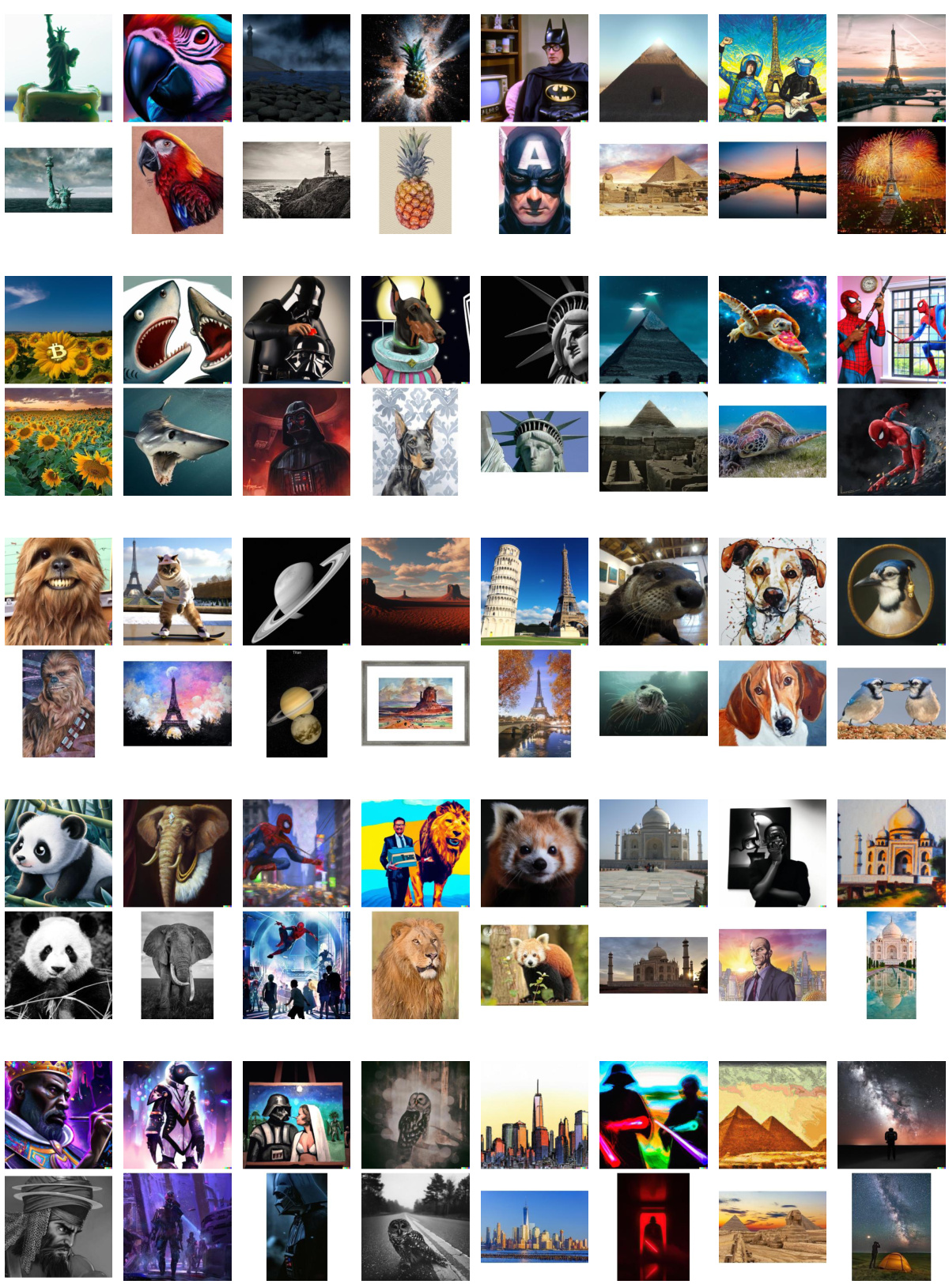
🔼 This figure shows a comparison between images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) and their corresponding source images from the LAION-Aesthetics dataset. The top row displays the generated images, while the bottom row shows the original images they seem to replicate. This visual comparison highlights the potential for diffusion models to reproduce existing content, raising concerns about originality and copyright.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

🔼 This figure shows a comparison between images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) and their corresponding original images from the LAION-Aesthetics dataset. The top row displays the generated images, while the bottom row shows the original images that they seem to replicate. The figure highlights the issue of diffusion models potentially replicating existing content, which is a core motivation for the paper’s work on Image Copy Detection for Diffusion Models.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

🔼 This figure shows a comparison between images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, Stable Diffusion XL, DeepFloyd IF, and GLIDE) and their corresponding original images from the LAION-Aesthetics dataset. The top row displays the generated images, and the bottom row shows the original images that they seem to replicate. This visual demonstrates the issue of content replication in diffusion model outputs, highlighting that generated images might not be entirely original.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.

🔼 This figure shows a comparison of images generated by six different diffusion models (Midjourney, New Bing, DALL-E 2, SDXL, DeepFloyd IF, and GLIDE) with their corresponding original images from the LAION-Aesthetics dataset. The top row displays the generated images, while the bottom row shows the original images that they seem to replicate. This visually demonstrates the challenge of detecting image replication in the output of diffusion models.
read the caption
Figure 1: Some generated images (top) from diffusion models replicates the contents of existing images (bottom). The existing (matched) images are from LAION-Aesthetics [1]. The diffusion models include both commercial and open-source ones.
More on tables
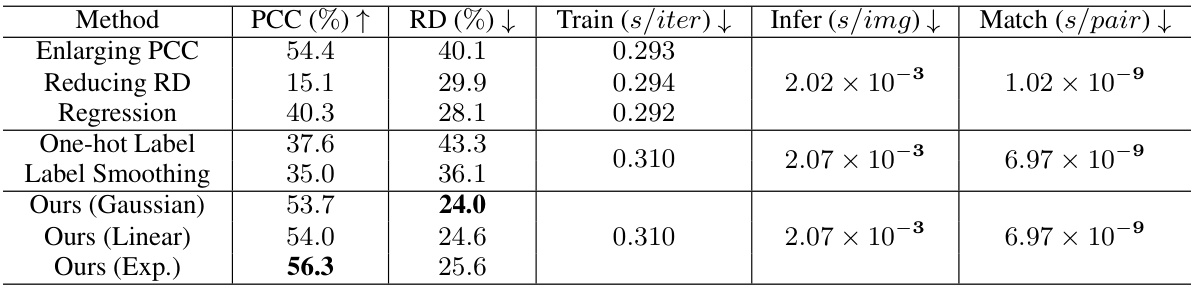
🔼 This table presents a comparison of the proposed PDF-Embedding method against several other methods for image copy detection. The methods compared include protocol-driven methods (Enlarging PCC, Reducing RD, Regression), non-PDF methods (One-hot Label, Label Smoothing), and the proposed method with different PDF implementations (Gaussian, Linear, Exponential). The table shows the performance of each method in terms of Pearson Correlation Coefficient (PCC), Relative Deviation (RD), training time per iteration, inference time per image, and matching time per pair. The results demonstrate that PDF-Embedding, particularly with the exponential PDF implementation, significantly outperforms the other methods.
read the caption
Table 2: Our method demonstrates performance superiority over others.
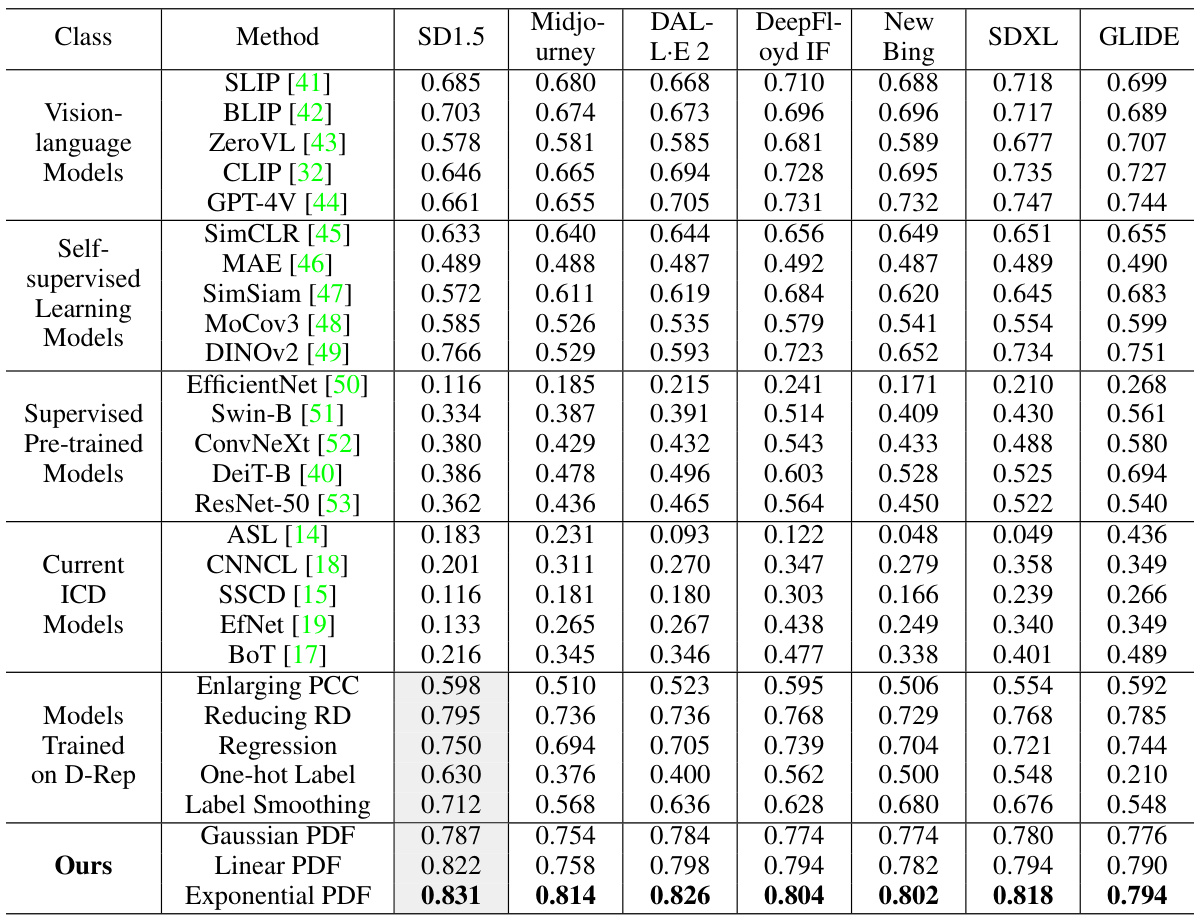
🔼 This table presents a comparison of the performance of various pre-trained models (vision-language, self-supervised, supervised, and current ICD models) and the proposed PDF-Embedding method on the D-Rep dataset. The performance is evaluated using two metrics: Pearson Correlation Coefficient (PCC) and Relative Deviation (RD). Higher PCC values indicate better correlation between predicted and ground truth replication levels, while lower RD values indicate smaller deviations. The table helps demonstrate the effectiveness of the PDF-Embedding method compared to existing approaches.
read the caption
Table 1: The performance of publicly available models and our PDF-Embedding on the D-Rep. For qualitative results, please refer to Section E in the Appendix.
Full paper#