↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current methods for creating animatable avatars often rely on neural radiance fields, resulting in slow rendering and limited generalization. These methods are computationally expensive and struggle to produce high-fidelity results for unseen identities. This paper tackles these challenges by presenting a novel approach.
The proposed method, GAGAvatar, utilizes a dual-lifting technique to generate the parameters of 3D Gaussians from a single image. This approach, combined with the use of global image features and a 3D morphable model, enables high-fidelity 3D Gaussian reconstruction that captures facial details and identity information, and allows for real-time expression control. Experiments show that GAGAvatar significantly outperforms existing methods in terms of reconstruction quality, expression accuracy, and rendering speed.
Key Takeaways#
Why does it matter?#
This paper is important because it presents GAGAvatar, a novel framework for one-shot animatable head avatar reconstruction that achieves real-time reenactment speeds. This addresses limitations of existing methods in terms of rendering speed and generalization capabilities, potentially impacting various applications, such as virtual reality and online meetings. The introduction of the dual-lifting method is a significant contribution to the field, paving the way for future research in efficient and generalizable avatar creation. The real-time performance is a particularly valuable advancement for interactive applications.
Visual Insights#
🔼 This figure illustrates the architecture of the proposed GAGAvatar model. It consists of two main branches: a reconstruction branch that reconstructs a 3D Gaussian-based head avatar from a single source image, and an expression branch that controls the facial expressions of the avatar using a driving image. The reconstruction branch employs a dual-lifting method to predict the parameters of 3D Gaussians from the source image. These Gaussians, along with additional expression Gaussians generated by the expression branch, are then rendered using splatting, followed by a neural renderer to refine the results and produce a high-fidelity reenacted image. The figure highlights that only a small portion of the model (the driving part) needs to be executed repeatedly for expression control, enhancing efficiency.
read the caption
Figure 2: Our method consists of two branches: a reconstruction branch (Sec. 3.1) and an expression branch (Sec. 3.2). We render dual-lifting and expressed Gaussians to get coarse results, and then use a neural renderer to get fine results. Only a small driving part needs to be run repeatedly to drive the expression, while the rest is executed only once.
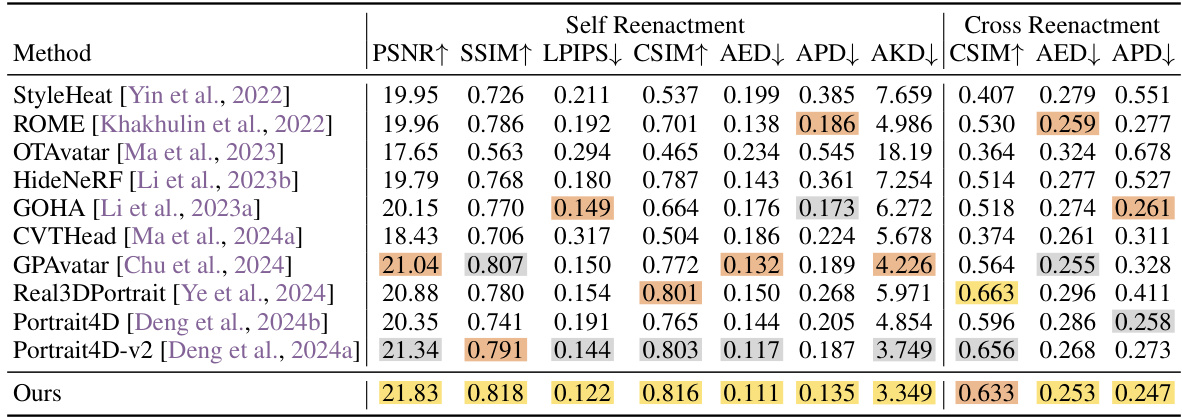
🔼 This table presents a quantitative comparison of the proposed GAGAvatar model against several state-of-the-art methods for one-shot head avatar reconstruction and reenactment on the VFHQ dataset. The metrics used for evaluation include PSNR, SSIM, LPIPS (for self-reenactment), and CSIM, AED, APD (for cross-reenactment). Higher PSNR and SSIM values indicate better image quality, while lower LPIPS and AED values indicate better perceptual similarity and expression accuracy respectively. The table highlights the superior performance of GAGAvatar across various metrics.
read the caption
Table 1: Quantitative results on the VFHQ [Xie et al., 2022] dataset. We use colors to denote the first, second and third places respectively.
In-depth insights#
Dual-Lifting 3D Gaussians#
The concept of “Dual-Lifting 3D Gaussians” presents a novel approach to reconstructing 3D head avatars from a single image. It cleverly addresses the challenge of estimating the parameters of numerous 3D Gaussians, which typically requires multiple views, by using a dual-lifting strategy. This method involves predicting forward and backward lifting distances from a feature plane, effectively creating a closed Gaussian point distribution. This approach leverages fine-grained image features, dramatically simplifying the reconstruction process and improving the model’s ability to capture identity and facial details. Combining this dual-lifting technique with 3D Morphable Models (3DMM) provides structural priors, further enhancing accuracy and ensuring consistent head pose and expression transfer. The overall effect is a robust and efficient method for generating high-fidelity animatable avatars, allowing for real-time reenactment. This innovative approach significantly improves reconstruction quality and allows for superior expression control compared to existing methods.
Expression Control#
Expression control in one-shot 3D head avatar reconstruction is a crucial aspect, enabling realistic and animatable avatars. Methods often leverage 3D Morphable Models (3DMM) to represent facial expressions, binding learnable weights to vertices to control expression Gaussians. This approach decouples expression from identity, offering precise control. Combining global image features with 3DMM features enhances identity consistency across varying expressions. Neural renderers refine the splatting-rendered results to achieve high-fidelity, though this can be computationally expensive. A key challenge is efficiently controlling expressions from a single image, requiring sophisticated methods to integrate and avoid conflicts between static and dynamic Gaussian components. Real-time expression control presents a significant challenge, requiring efficient and scalable algorithms. Successful implementation significantly advances the realism and utility of digital avatars in applications such as virtual reality and video conferencing.
Real-time Reenactment#
Real-time reenactment, a crucial aspect of many applications like virtual avatars and video conferencing, presents significant challenges. The paper likely focuses on optimizing the computational process to achieve real-time performance, possibly through efficient network architectures or algorithmic improvements. This could involve reducing the computational load of the avatar generation and rendering processes, or leveraging hardware acceleration techniques such as GPUs. A key aspect would be balancing fidelity and speed. The authors likely explore different trade-offs between the level of detail in the avatar’s appearance and the speed at which it can be rendered and animated. Success hinges on the ability to efficiently control facial expressions and head movements while keeping the system responsive enough for interactive use. The paper’s discussion of real-time reenactment would undoubtedly highlight the technical achievements needed to overcome limitations of previous slower methods, and likely will delve into the methods used to achieve such speed, potentially drawing attention to a novel algorithm or a clever implementation strategy.
Generalization Limits#
A section titled “Generalization Limits” in a research paper would critically examine the boundaries of a model’s ability to perform well on unseen data. It would likely delve into specific scenarios where the model falters, perhaps exhibiting poor performance on data outside its training distribution. This could involve analyzing the impact of variations in data characteristics, such as image resolution, lighting conditions, or pose, on the model’s accuracy. Furthermore, the analysis might explore the influence of factors beyond the data itself, such as the model’s architecture, training methods, or hyperparameter settings. A strong analysis would also compare performance against existing state-of-the-art models and identify whether the limitations are inherent to the approach or generalizable across similar techniques. Quantifiable metrics, such as precision, recall, and F1-score, would be used to support the claims made. Crucially, discussion of these limitations would be vital, not only to understand the model’s capabilities but also to suggest avenues for future improvements and the overall direction of research.
Future Enhancements#
Future enhancements for this research could involve exploring more sophisticated 3D face models beyond the current 3DMM, allowing for greater realism in facial features and expressions. The integration of high-resolution imagery would significantly improve detail and accuracy of avatar reconstruction. Furthermore, research into real-time adaptation for diverse lighting and pose variations would enhance robustness and applicability across a range of real-world scenarios. A particularly promising area would involve developing methods to address challenges in unseen regions of the face, such as generating accurate representations of the back of the head or hidden facial features from single-view input. Finally, addressing ethical concerns through watermarking and other measures is crucial to preventing misuse and promoting responsible use of this technology.
More visual insights#
More on figures

🔼 This figure shows a detailed overview of the proposed method’s architecture. It consists of two main branches: a reconstruction branch and an expression branch. The reconstruction branch takes a source image as input and reconstructs the 3D structure of the head using a novel dual-lifting method. The expression branch leverages a 3D Morphable Model (3DMM) to control facial expressions by predicting expression Gaussians from both global and local features extracted from the source and driving images. Both branches’ outputs are combined and rendered using a neural renderer to generate the final, high-fidelity reenacted image. The diagram highlights that only a small portion of the process (the driving part) is executed repeatedly during reenactment.
read the caption
Figure 2: Our method consists of two branches: a reconstruction branch (Sec. 3.1) and an expression branch (Sec. 3.2). We render dual-lifting and expressed Gaussians to get coarse results, and then use a neural renderer to get fine results. Only a small driving part needs to be run repeatedly to drive the expression, while the rest is executed only once.

🔼 This figure presents a qualitative comparison of cross-identity head avatar reconstruction results between the proposed GAGAvatar method and several state-of-the-art baselines on the VFHQ dataset. Each row shows results for a different subject, where the first image is the source image, followed by driving images showing expression changes, and the remaining images show the reconstruction results from different methods. The results highlight GAGAvatar’s superior performance in terms of capturing fine facial details and accurate expressions compared to the other methods.
read the caption
Figure 3: Cross-identity qualitative results on the VFHQ [Xie et al., 2022] dataset. Compared with baseline methods, our method has accurate expressions and rich details.

🔼 This figure shows the ablation study results of the proposed method. By comparing different model variations, it demonstrates the impact of each component (dual-lifting, global feature, neural renderer, and lifting loss) on the overall performance of head avatar reconstruction. The results highlight that the full model with all components achieves superior performance, especially in preserving fine details like glasses, particularly at large view angles.
read the caption
Figure 4: Ablation results on VFHQ [Xie et al., 2022] datasets. We can see that our full method performs best, especially on facial edges such as glasses in large view angles.

🔼 This figure shows the results of the dual-lifting method on a real-world image, comparing the full dual-lifting approach to a simplified single-plane lifting and to a version without the lifting distance loss. The visualizations highlight the 3D structure of the reconstructed Gaussian points, revealing how the dual-lifting method produces a more complete and accurate 3D representation compared to the alternatives, particularly when considering the effects of including the lifting distance loss term.
read the caption
Figure 5: Lifting results of an in-the-wild image, include the front view and the top view. Points are filtered by Gaussian opacity. We color two parts of the dual-lifting separately, and the black points are the image plane. It can be seen that the lifted 3D structure is relatively flat without Llifting.

🔼 This figure demonstrates the robustness of the proposed method across various challenging conditions. It showcases reenactment results for images with low quality, challenging lighting, significant occlusions (e.g., sunglasses), and extreme expressions. The results highlight that even under these difficult scenarios, the model is able to generate plausible and realistic results, showcasing its robustness and generalizability.
read the caption
Figure 6: The robustness of our model. Our method can produce reasonable results for low-quality images, challenging lighting conditions, significant occlusions, and extreme expressions.

🔼 This figure shows the overall architecture of the proposed method, GAGAvatar. It consists of two main branches: a reconstruction branch and an expression branch. The reconstruction branch takes a source image as input and reconstructs the 3D Gaussian representation of the head using the proposed dual-lifting method. The expression branch leverages a 3D Morphable Model (3DMM) and combines it with global and local features extracted from the source and driving images to control the expression of the generated avatar. Both branches’ outputs are combined and rendered using a neural renderer to produce the final, high-fidelity reenacted image. The diagram highlights the efficient design, where only a small part of the network needs to be processed repeatedly for each frame of the driving video to produce real-time results.
read the caption
Figure 2: Our method consists of two branches: a reconstruction branch (Sec. 3.1) and an expression branch (Sec. 3.2). We render dual-lifting and expressed Gaussians to get coarse results, and then use a neural renderer to get fine results. Only a small driving part needs to be run repeatedly to drive the expression, while the rest is executed only once.

🔼 This figure shows several examples of the proposed method’s ability to reenact and generate novel views of faces from in-the-wild images. For each example, three images are shown. The first image is the input, which serves as the source for the reenactment. The second is the driving image, depicting the target expression and pose. Finally, the third section shows the reenacted image and multiple views of the head. The results demonstrate the method’s capability in producing realistic and consistent outputs across different viewpoints.
read the caption
Figure 8: Reenactment and multi-view results of our method on in-the-wild images. From left to right: input image, driving image, driving and novel view results.

🔼 This figure shows the results of rendering the dual-lifting Gaussians from the reconstruction branch and the Gaussians from the expression branch separately. The dual-lifting Gaussians reconstruct the head’s base structure and facial details, while the expression Gaussians control facial expressions. The visualization uses the first three dimensions (RGB) of the 32-dimensional Gaussian features, without the neural rendering module, for better understanding of each part’s role.
read the caption
Figure 9: Per-part rendering of the dual-lifting and expression Gaussians. We can see that the dual-lifting Gaussians reconstruct the head's base structure and facial details respectively. It is worth noting that our Gaussians are not purely RGB Gaussians. Instead, our Gaussians include 32-D features (as described in Sec. 3.3). We visualize the first 3 dimensions of these features (i.e., the RGB values of the Gaussians) here without the neural rendering module. So this visualization is intended to intuitively display the functionality of each part and the importance of each branch should not be judged based on RGB values alone.

🔼 This figure shows the results of the dual-lifting method applied to an in-the-wild image. The left column shows the source images. The middle column shows the results of the dual-lifting method applied. The right column shows the results of dual-lifting method without the lifting distance loss. The results clearly show that the dual-lifting method with the lifting distance loss produces a 3D structure that is more consistent with the source image, while the dual-lifting method without the lifting distance loss produces a relatively flat 3D structure.
read the caption
Figure 5: Lifting results of an in-the-wild image, include the front view and the top view. Points are filtered by Gaussian opacity. We color two parts of the dual-lifting separately, and the black points are the image plane. It can be seen that the lifted 3D structure is relatively flat without Llifting.

🔼 This figure shows a comparison of self-identity reenactment results between the proposed method and several baseline methods on two datasets, VFHQ and HDTF. The top six rows display results from VFHQ, while the bottom three rows show results from HDTF. Each row represents a different video sequence, with the source image followed by the results generated by each method. This allows for a visual comparison of the quality and accuracy of different approaches in recreating head avatar expressions.
read the caption
Figure 11: Self-identity reenactment results on VFHQ [Xie et al., 2022] and HDTF [Zhang et al., 2021] datasets. The top six rows are from VFHQ and the bottom three rows are from HDTF.

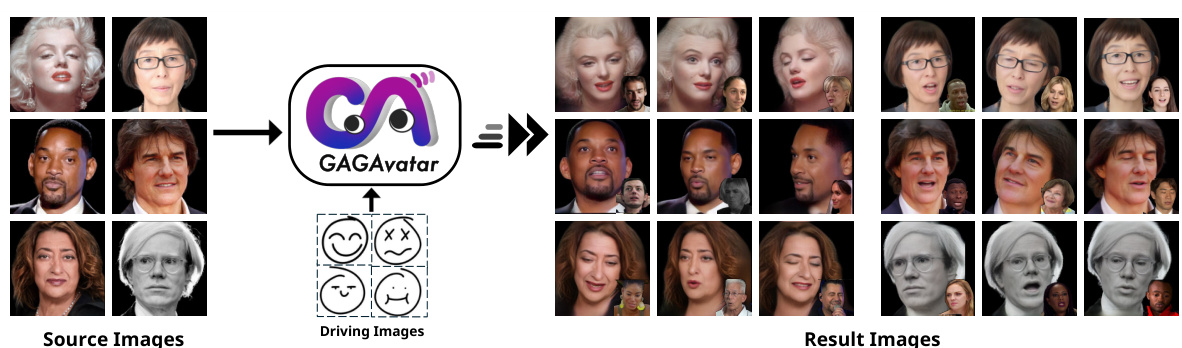
🔼 This figure demonstrates the results of the proposed Generalizable and Animatable Gaussian head Avatar (GAGAvatar) method. It shows that the model can successfully reconstruct animatable avatars from a single input image. The reconstruction maintains high fidelity to the source image, showing strong generalization capabilities. Furthermore, the avatars can be animated with real-time reenactment speeds, and they have strong controllability in terms of expressions. This showcases the core capabilities of the GAGAvatar method: one-shot reconstruction, strong generalization, high fidelity, and real-time reenactment.
read the caption
Figure 1: Our method can reconstruct animatable avatars from a single image, offering strong generalization and controllability with real-time reenactment speeds.

🔼 This figure displays a comparison of cross-identity qualitative results between the proposed method and several baseline methods using the VFHQ dataset. Each column represents a different method, with the first column being the source image and the second column being the driving image. The subsequent columns showcase the reenactment results of each method. The caption highlights that the proposed method outperforms the baselines in terms of expression accuracy and detail.
read the caption
Figure 3: Cross-identity qualitative results on the VFHQ [Xie et al., 2022] dataset. Compared with baseline methods, our method has accurate expressions and rich details.

🔼 This figure showcases the performance of the proposed method on real-world images. For each row, the leftmost image is the input source image, the second image is the driving image used to animate the avatar, and the remaining images present the reenactment results from various viewpoints. The results demonstrate the method’s ability to generate realistic and consistent avatars with accurate expression transfer, even under significant viewpoint changes and in complex scenarios.
read the caption
Figure 14: Reenactment and multi-view results of our method on in-the-wild images. From left to right: input image, driving image, driving and novel view results.

🔼 This figure shows the pipeline of the proposed method. Given a single source image, the model reconstructs an animatable 3D Gaussian-based head avatar. The figure demonstrates the input source images, the driving images used for animation, and the resulting reconstructed images, highlighting the method’s ability to generate realistic and animatable avatars from limited input.
read the caption
Figure 1: Our method can reconstruct animatable avatars from a single image, offering strong generalization and controllability with real-time reenactment speeds.

🔼 This figure shows a comparison of qualitative results between the proposed method and other state-of-the-art methods for self-reenactment and cross-reenactment tasks. The highlighted regions in the images draw attention to the details reconstructed by each method. The figure demonstrates that the proposed method achieves superior performance compared to existing methods by producing high-quality reconstruction, detailed expressions, and better handling of pose variations, especially in challenging views.
read the caption
Figure 16: Qualitative results and video continuous frame results with highlighted attention regions. We selected competitive methods to show continuous frames. Better to view it zoomed in.

🔼 This figure demonstrates the robustness of the proposed method across various challenging conditions. It showcases successful avatar reconstruction even with low-quality input images, images with challenging lighting, images with significant occlusions, and images featuring extreme facial expressions. This highlights the model’s ability to generalize well and produce high-quality results despite these difficulties.
read the caption
Figure 6: The robustness of our model. Our method can produce reasonable results for low-quality images, challenging lighting conditions, significant occlusions, and extreme expressions.
More on tables
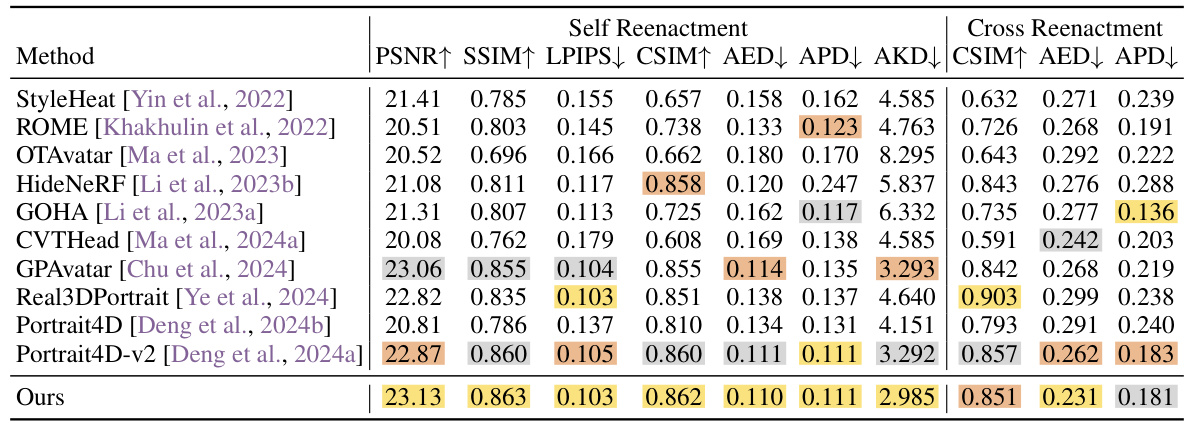
🔼 This table presents a quantitative comparison of the proposed GAGAvatar method against several state-of-the-art methods for head avatar reconstruction and reenactment on the VFHQ dataset. The metrics used for evaluation include PSNR, SSIM, LPIPS (for perceptual quality), CSIM (for identity consistency), AED (average expression distance), APD (average pose distance), AKD (average keypoint distance). The results are broken down into self-reenactment (using the same identity for source and driving images) and cross-reenactment (using different identities). Color coding highlights the top three performers for each metric.
read the caption
Table 1: Quantitative results on the VFHQ [Xie et al., 2022] dataset. We use colors to denote the first, second and third places respectively.

🔼 This table compares the inference speed (in FPS) of different methods for one-shot head avatar reconstruction. The FPS values represent the speed at which reenactment is performed, excluding the time taken to calculate pre-computable driving parameters. The average is calculated over 100 frames.
read the caption
Table 3: The time of reenactment is measured in FPS. All results exclude the time for getting driving parameters that can be calculated in advance and are averaged over 100 frames.

🔼 This table presents the ablation study results on the VFHQ dataset. It shows the impact of different components of the proposed method on the performance. The metrics evaluated are PSNR, SSIM, LPIPS, CSIM, AED, APD, and AKD for self-reenactment and CSIM, AED, and APD for cross-reenactment. By removing components such as the global feature, neural renderer, and lifting loss, the table demonstrates the contribution of each component to the overall performance.
read the caption
Table 4: Ablation results on the VFHQ [Xie et al., 2022] dataset.
Full paper#



















