↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current multimodal large language models struggle with capturing fine-grained semantic details, particularly at the pixel level, hindering applications requiring precise keypoint understanding. This limitation necessitates new approaches focusing on semantic keypoint comprehension across diverse scenarios, encompassing semantic understanding, visual and textual prompt-based detection.
This paper introduces KptLLM, a unified framework addressing this challenge. It uses an identify-then-detect strategy, first discerning keypoint semantics and then determining their locations. KptLLM incorporates several carefully designed modules to handle varied input modalities and interprets semantic contents and keypoint locations effectively. Experiments show KptLLM’s superiority in keypoint detection benchmarks and its unique semantic capabilities.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel challenge of Semantic Keypoint Comprehension and proposes a unified multimodal model, KptLLM, to address this challenge. KptLLM shows superior performance in various keypoint detection benchmarks and unique semantic capabilities, opening new avenues for research in fine-grained visual understanding and human-AI interaction. It also highlights the potential of large language models in addressing complex computer vision tasks, paving the way for future multimodal model development.
Visual Insights#

This figure illustrates the three tasks of semantic keypoint comprehension addressed in the paper. (a) Keypoint Semantic Understanding focuses on understanding the semantics of a keypoint given its location in an image. (b) Visual Prompt-based Keypoint Detection involves detecting keypoints in a query image based on information from a support image and its corresponding keypoints. (c) Textual Prompt-based Keypoint Detection utilizes textual descriptions of keypoints to achieve more generalized keypoint detection.

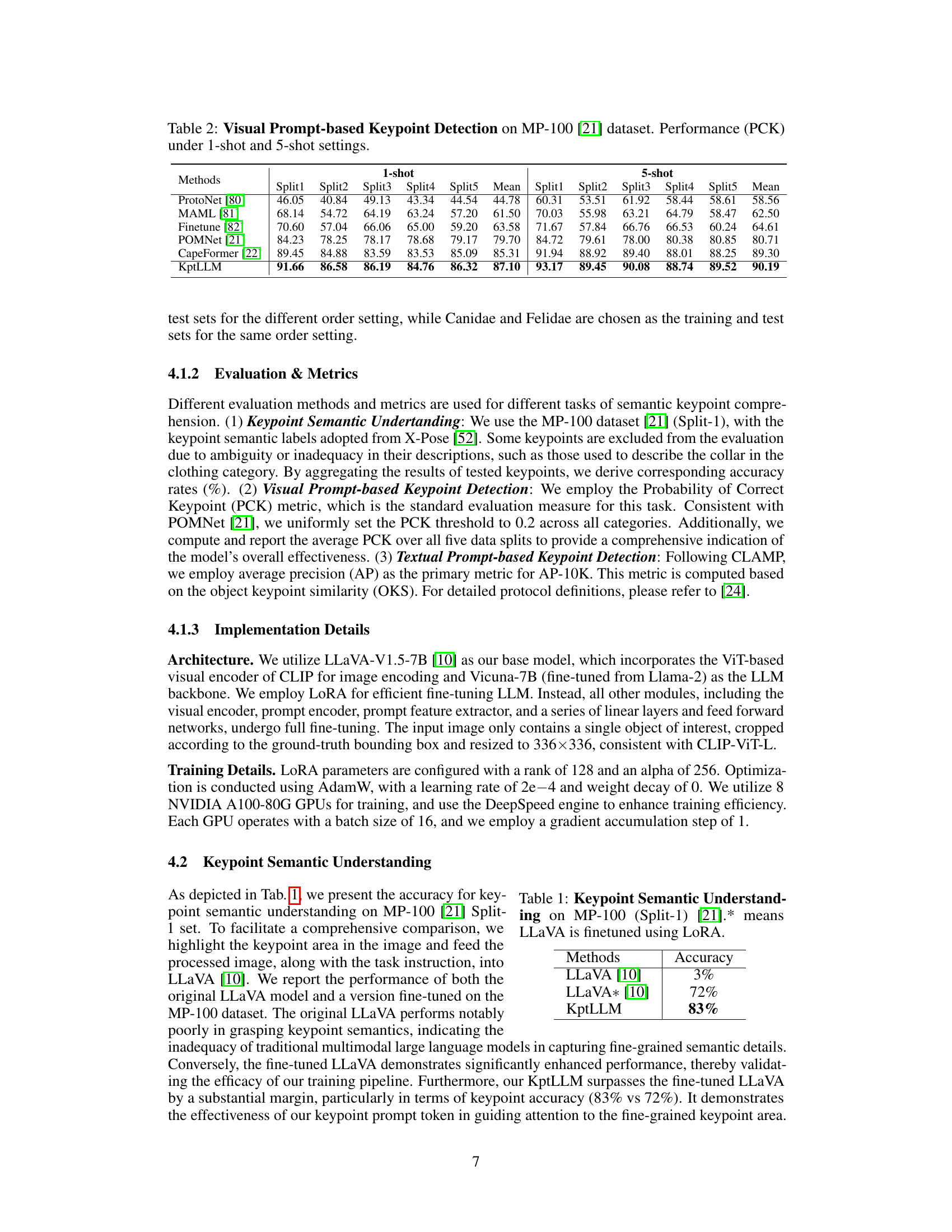
This table presents the Probability of Correct Keypoint (PCK) performance of different methods for visual prompt-based keypoint detection on the MP-100 dataset. The results are shown for both 1-shot and 5-shot settings, comparing KptLLM against ProtoNet, MAML, Finetune, POMNet, and CapeFormer. Each split represents a different subset of the dataset, and the mean PCK across all splits is also provided.
In-depth insights#
KptLLM Framework#
The KptLLM framework represents a novel approach to semantic keypoint comprehension, integrating the power of large language models (LLMs) with visual information processing. Its unified multimodal design allows it to handle various input modalities, such as images and text prompts, making it adaptable to different task scenarios, including keypoint semantic understanding, visual prompt-based detection, and textual prompt-based detection. The framework’s core strength lies in its identify-then-detect strategy, which mimics human cognition by first identifying the semantic meaning of keypoints before precisely determining their location. This approach, coupled with carefully designed components like visual and prompt encoders and a chain-of-thought process within the LLM, enables robust and accurate keypoint localization, even for novel objects or categories. The incorporation of common sense reasoning from the LLM enhances the model’s generalizability and improves accuracy in handling ambiguous keypoints. Overall, KptLLM provides a more comprehensive and interpretable method for keypoint understanding than traditional approaches, offering significant advancements in the field.
Semantic Kpt Analysis#
Semantic Keypoint Analysis (SKA) represents a significant advancement in computer vision, moving beyond simple localization to encompass a richer understanding of keypoints within their context. SKA aims to integrate semantic information with geometric keypoint data, enabling more robust and meaningful interpretations. This involves not just pinpointing keypoint locations but also understanding their roles within an object, scene, or action. Deep learning models, particularly those incorporating multimodal information (like text and images), are crucial for achieving SKA. Challenges include handling noisy or ambiguous data, generalizing across different object classes, and efficiently representing complex relationships between keypoints and their semantic meaning. Future directions include developing more sophisticated model architectures that can effectively fuse semantic and geometric cues, exploring new data representations that capture finer-grained contextual information, and addressing the limitations of current evaluation metrics which often focus on localization accuracy alone, overlooking the semantic aspect of SKA.
Multimodal Prompting#
Multimodal prompting represents a significant advancement in AI, enabling models to understand and respond to inputs from diverse modalities, such as text, images, and audio. This approach moves beyond unimodal processing, where models handle only one type of input at a time, opening up exciting possibilities for more natural and intuitive human-computer interaction. By combining different data types within a single prompt, multimodal models can leverage the strengths of each modality to generate more comprehensive and nuanced outputs. One key benefit is enhanced context understanding, allowing the model to draw on a richer understanding of the input to inform its response. For example, in image captioning, a multimodal model could analyze both the image content and a descriptive text prompt to generate a more detailed and accurate caption than a model relying solely on visual data. The effectiveness of multimodal prompting relies on careful design and integration of different input modalities, as well as the development of sophisticated models capable of processing and fusing this information efficiently. Key challenges include handling inconsistencies and ambiguities across modalities, designing effective strategies for prompt construction, and developing robust evaluation metrics for assessing performance. Despite these hurdles, the future of multimodal prompting looks bright, with potential for transformative applications in areas such as medical diagnosis, robotics, and education.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a detailed comparison of the proposed method against existing state-of-the-art techniques. This would involve reporting quantitative metrics on standard benchmark datasets, highlighting superior performance where applicable. Crucially, the selection of benchmarks should be justified, demonstrating their relevance to the problem being addressed. The results should be presented clearly, possibly using tables and figures to facilitate comparison. In addition to raw performance numbers, error analysis and ablation studies would provide deeper insights, revealing the strengths and weaknesses of the proposed method and shedding light on the factors driving its performance. Finally, qualitative results, such as visualizations or case studies, can offer valuable complementary insights, particularly in showcasing the method’s ability to handle complex or nuanced scenarios. A thoughtful analysis of these benchmark results is essential for establishing the significance and impact of the research.
Future Research#
The ‘Future Research’ section of this paper would ideally explore several key areas to advance the field. Improving the Vision Encoder by utilizing more powerful architectures like DINOv2 is crucial for enhanced performance. Refining the Keypoint Decoding Strategy is another vital area, potentially involving techniques to directly output coordinates as textual descriptions rather than relying on special tokens. This would require addressing challenges related to numerical value generation within the LLM framework. Expanding the dataset scale and category diversity is also crucial for broader applicability and generalization, especially towards open-world scenarios. Finally, research should address the computational limitations of LLMs through efficient fine-tuning techniques and model optimizations. Exploring alternative architectures specifically designed for keypoint comprehension or hybrid methods that combine the strengths of LLMs and traditional computer vision models would also be valuable contributions.
More visual insights#
More on figures
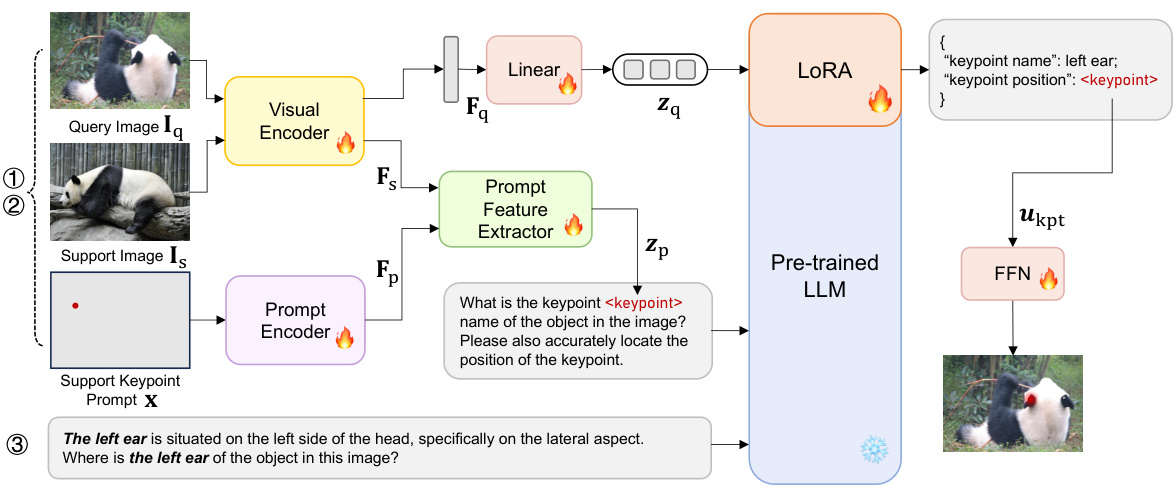
KptLLM is a unified framework designed to solve three tasks: Keypoint Semantic Understanding, Visual Prompt-based Keypoint Detection, and Textual Prompt-based Keypoint Detection. The model takes as input query and support images, a support keypoint prompt (position of the keypoint in the support image), and textual instructions from the user. The visual encoder processes both the query and support images. The prompt encoder handles the support keypoint prompt location data. A prompt feature extractor integrates the support keypoint and image features. The pre-trained LLM then uses query image features, prompt-oriented features, and textual instructions to generate the textual semantic description of the keypoint and the location of the keypoint in the query image. The chain of thought is used to identify the semantic meaning of the keypoint and then locate its position.

This figure shows the results of visual prompt-based keypoint detection. The leftmost image is a support image which is used as a reference by the model for keypoint detection. The model receives this image and the keypoints defined on it. Then, the model uses this information to detect the keypoints on query images, which are shown in the rest of the image. The results show that the model can successfully detect keypoints in various query images with differences in poses, appearance, and environmental conditions. This demonstrates the generalizability of the model.
More on tables

This table presents the accuracy of keypoint semantic understanding on the MP-100 dataset (Split-1). It compares the performance of the original LLaVA model, a version of LLaVA fine-tuned using LoRA, and the proposed KptLLM model. The results highlight the superior performance of KptLLM in grasping keypoint semantics compared to both LLaVA versions, demonstrating the effectiveness of the proposed method.
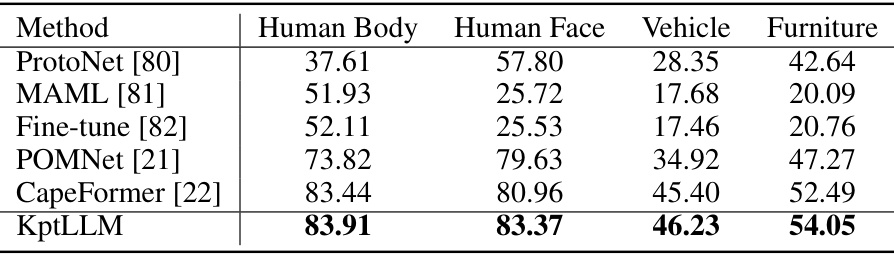
This table presents the performance of different visual prompt-based keypoint detection methods on the MP-100 dataset, focusing on cross-supercategory evaluation (1-shot setting). The methods are compared across four supercategories: Human Body, Human Face, Vehicle, and Furniture. The results are presented as the PCK (Percentage of Correct Keypoints) at a threshold of 0.2. This evaluation tests the generalization ability of the models across diverse object categories and visual characteristics.

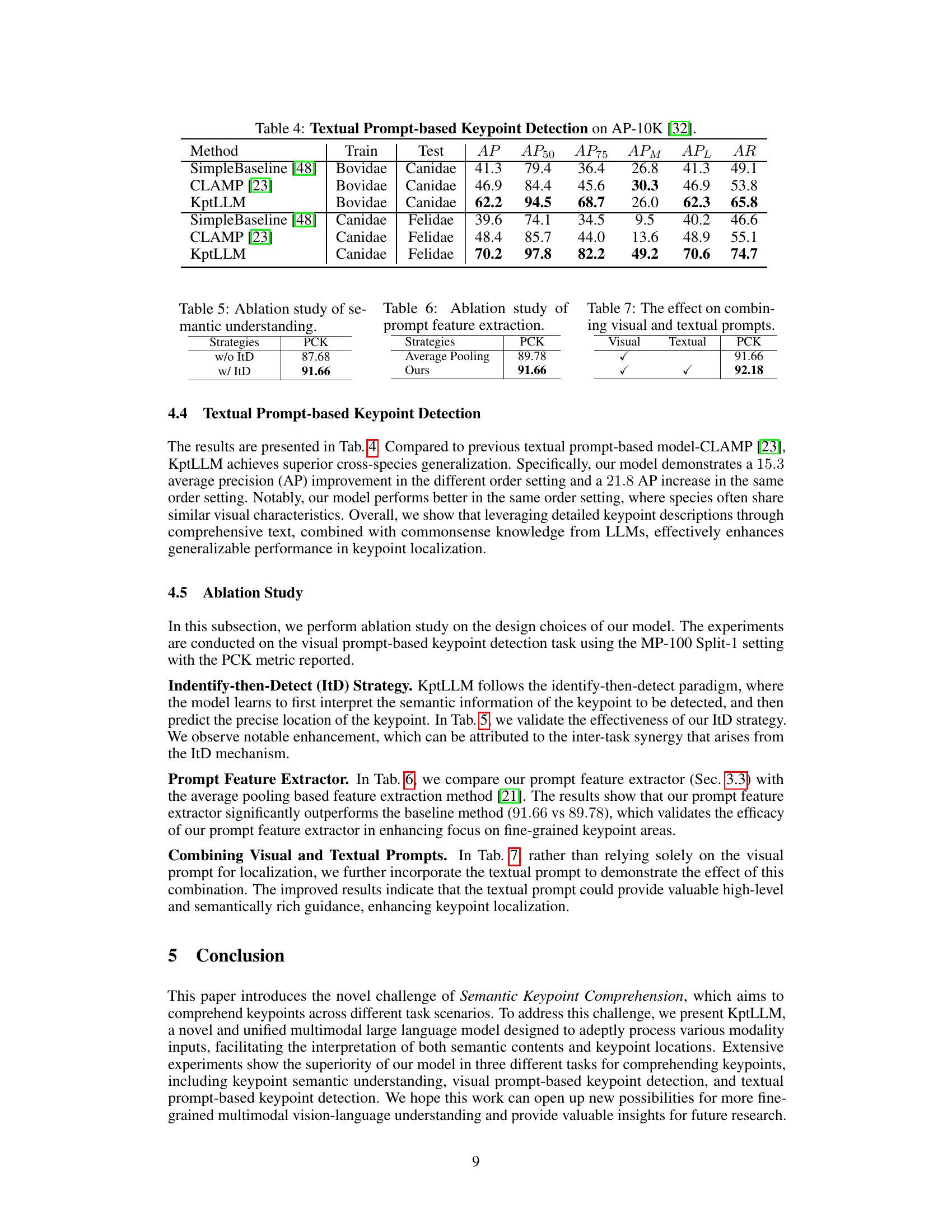
This table presents the results of textual prompt-based keypoint detection on the AP-10K dataset. It compares the performance of three different methods: SimpleBaseline [48], CLAMP [23], and the proposed KptLLM model. The evaluation is performed across two scenarios: (1) training on Bovidae and testing on Canidae, and (2) training on Canidae and testing on Felidae. The results are measured using average precision (AP), and several variations of AP at different Intersection over Union (IoU) thresholds (AP50, AP75, APM, APL) along with Average Recall (AR). The table showcases KptLLM’s superior performance in terms of generalization and accuracy compared to the baseline methods.

This table presents the results of an ablation study on the semantic understanding aspect of the KptLLM model. It compares the performance (PCK) of the model with and without the Identify-then-Detect (ItD) strategy. The results show a significant improvement in performance when using the ItD strategy.
Full paper#