↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large vision-language models (LVLMs) achieve impressive results but suffer from high computational costs, hindering their deployment on resource-limited devices. Existing quantization methods often fail to optimize performance due to neglecting cross-layer dependencies in the model, leading to suboptimal results. This often involves a significant search overhead, further complicating the optimization process.
Q-VLM tackles these issues by introducing a novel post-training quantization approach. This method leverages the correlation between activation entropy and cross-layer dependency to guide efficient block-wise quantization. By optimizing the visual encoder, the search space is further reduced, leading to improved accuracy and speed. The results demonstrate significant memory compression (2.78x) and a speed increase (1.44x) on a 13B parameter model without performance degradation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient large language models. It directly addresses the high computational cost and memory requirements of current models, offering a practical solution for deploying them on resource-constrained devices. The innovative approach using entropy and cross-layer dependency analysis opens new avenues for model compression and efficient inference.
Visual Insights#

This figure illustrates the Q-VLM framework. It shows how the model is quantized by using entropy as a proxy to mine cross-layer dependency for efficient block assignment. The large search space is decomposed into smaller blocks, improving efficiency. Furthermore, the visual encoder is optimized to further reduce the search cost and improve accuracy. The process begins with VQA datasets being fed into the visual encoder and language model. The language model generates a response based on the visual input. This figure is a key component of the paper, showing the proposed method in a visual manner.
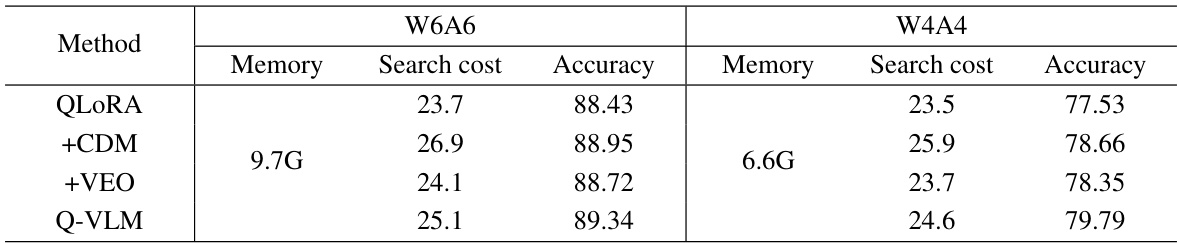
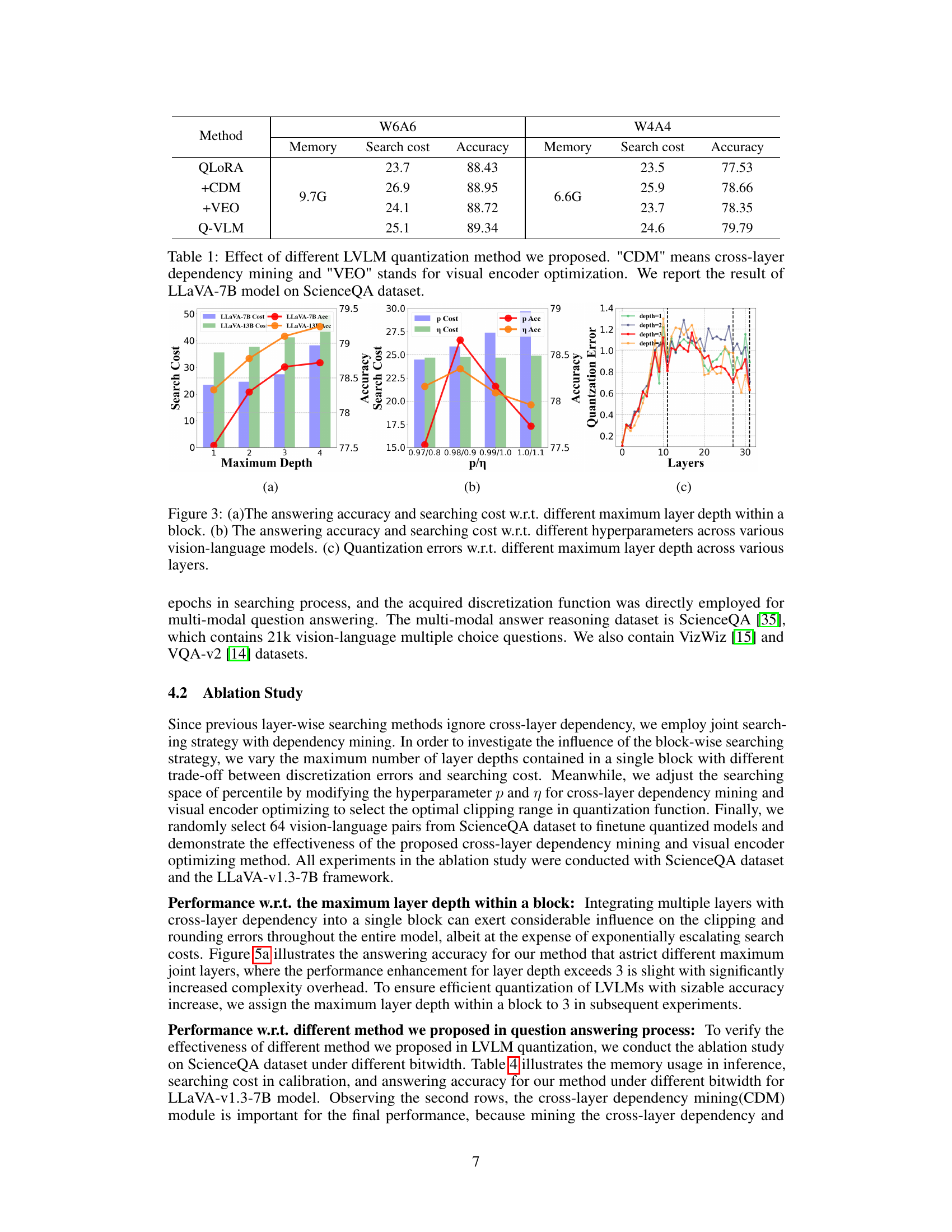
This table shows the impact of different components of the proposed Q-VLM method on the performance of the LLaVA-7B model. It compares the memory usage, search cost, and accuracy of the baseline QLORA method against three variations incorporating cross-layer dependency mining (CDM) and visual encoder optimization (VEO), culminating in the final Q-VLM model. The results are reported for the W6A6 (weight 6-bit, activation 6-bit) and W4A4 (weight 4-bit, activation 4-bit) quantization configurations. The ScienceQA dataset was used for evaluation.
In-depth insights#
Cross-Layer Effects#
Analyzing cross-layer effects in deep learning models reveals crucial insights into the complex interplay between different layers. Understanding these effects is key to optimizing model performance and efficiency. While individual layers might perform well in isolation, their combined behavior can lead to unexpected outcomes and significant performance limitations. Ignoring cross-layer dependencies often results in suboptimal training strategies and hindered generalization. Investigating the propagation of errors and information flow across layers reveals the need for innovative training techniques and architecture designs that account for such dependencies. Careful consideration of these cross-layer interactions enables informed decisions in model design, leading to more effective and robust solutions. This includes selecting optimal layer types, connection schemes, and regularization methods. The challenge lies in finding ways to effectively capture and manage these dependencies, which necessitates advanced mathematical tools and computational methods. Future research should focus on developing robust methods for measuring and modeling cross-layer effects. This would ultimately lead to more efficient and effective training algorithms, optimized model architectures, and enhanced predictive performance.
Entropy-Based Proxy#
The concept of an ‘Entropy-Based Proxy’ in the context of a research paper likely revolves around using entropy as a surrogate measure for a more complex or difficult-to-compute quantity. In this case, it’s probably used to estimate cross-layer dependency in a deep learning model. Directly calculating the influence of one layer’s output on another’s error during quantization is computationally expensive. Entropy, a measure of information uncertainty, provides a computationally cheaper alternative. High entropy suggests a more spread-out distribution of activations, potentially indicating stronger cross-layer effects. By using entropy to partition layers into blocks for quantization, the method likely aims to balance quantization error minimization with reduced computational cost. The effectiveness of this proxy relies on a strong correlation between entropy and the true cross-layer dependency, a crucial aspect that needs validation within the paper.
Visual Encoder Tuning#
The concept of ‘Visual Encoder Tuning’ within the context of large vision-language models (LVLMs) is crucial for efficient and accurate multimodal reasoning. Fine-tuning the visual encoder, rather than the entire model, offers a compelling approach to optimize performance without incurring the substantial computational cost associated with full model retraining. By focusing on the visual encoder, which extracts image features, we can specifically address issues related to visual input processing and its impact on overall model accuracy. This targeted optimization is particularly relevant to post-training quantization techniques, where efficient processing of quantized visual representations is crucial. The tuning process might involve adjusting weights or parameters within the visual encoder to better align the extracted features with the language model’s expectations. This alignment could significantly reduce quantization errors, improve speed, and enhance overall model performance without the need to retrain the entire LVLMs. A key aspect to consider is the interplay between the visual encoder and the subsequent layers. Effectively tuning the visual encoder would require careful consideration of the cross-layer dependencies and the flow of information through the entire network. The methods for tuning the visual encoder could incorporate techniques such as minimizing entropy to streamline the process or leveraging backpropagation through the quantized model to refine its parameters. The overall effectiveness of visual encoder tuning will be significantly impacted by the careful choice of optimization strategies. The result would be more effective, efficient LVLMs that achieve similar or better performance in various multimodal tasks. Careful evaluation of the tuning method is necessary to verify that the improvements are substantial, quantifiable, and generalize across multiple datasets.
Quantization Strategies#
Effective quantization strategies for large vision-language models (LVLMs) are crucial for efficient inference. Post-training quantization (PTQ) is preferred over quantization-aware training due to reduced computational cost. However, naive PTQ methods often suffer from suboptimal performance due to neglecting cross-layer dependencies in quantization errors. Advanced PTQ techniques address this by employing methods like entropy-based block partitioning. This approach leverages the strong correlation between activation entropy and cross-layer dependency, enabling optimal trade-offs between minimizing quantization errors and computational cost. Furthermore, techniques like visual encoder optimization aim to disentangle these dependencies to further refine the quantization process. The selection of the quantization scheme (e.g., uniform, non-uniform) and bit-width also plays a vital role in balancing accuracy and efficiency. Ultimately, the optimal quantization strategy needs to consider the specific characteristics of the LVLMs and the target deployment platform.
Future of Q-VLM#
The future of Q-VLM hinges on addressing its current limitations and exploring new avenues for improvement. Extending Q-VLM’s applicability to even lower bitwidths (e.g., below 4-bit) while maintaining accuracy is crucial for maximizing resource efficiency on mobile and edge devices. This will likely require advancements in quantization techniques and potentially new architectural designs. Further research into cross-layer dependencies is needed to optimize block partitioning for even greater compression and speed improvements. Investigating alternative proxies for efficiently capturing these dependencies beyond entropy could unlock significant gains. Improving the robustness of Q-VLM to different model architectures and datasets is also key. Its current performance is specific to LLaVA-like models, and demonstrating broad generalizability across diverse architectures and various multi-modal tasks is essential to establish its broader impact. Finally, exploring the integration of Q-VLM with other model compression techniques (e.g., pruning, low-rank approximation) holds potential for synergistic improvements. By combining these methods, even greater efficiency can be achieved without significant accuracy loss.
More visual insights#
More on figures
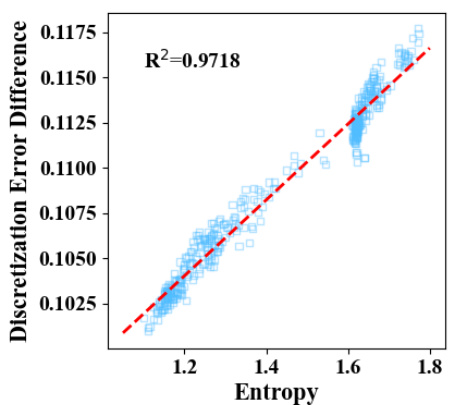
This figure shows the strong correlation between the discretization error difference (DED) and activation entropy in the 15th layer of the LLaVA architecture on the SQA dataset. The x-axis represents the entropy of the activations, and the y-axis represents the DED between layer-wise search and joint search for the optimal rounding function. Each data point represents a different input multimodal sample. The strong positive correlation (R²=0.9718) supports the paper’s claim that entropy can be used as a proxy for cross-layer dependency in quantization.
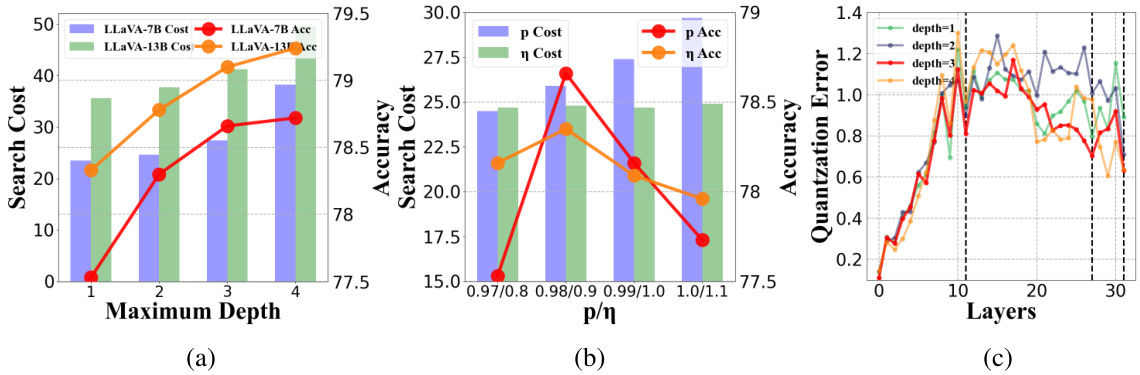
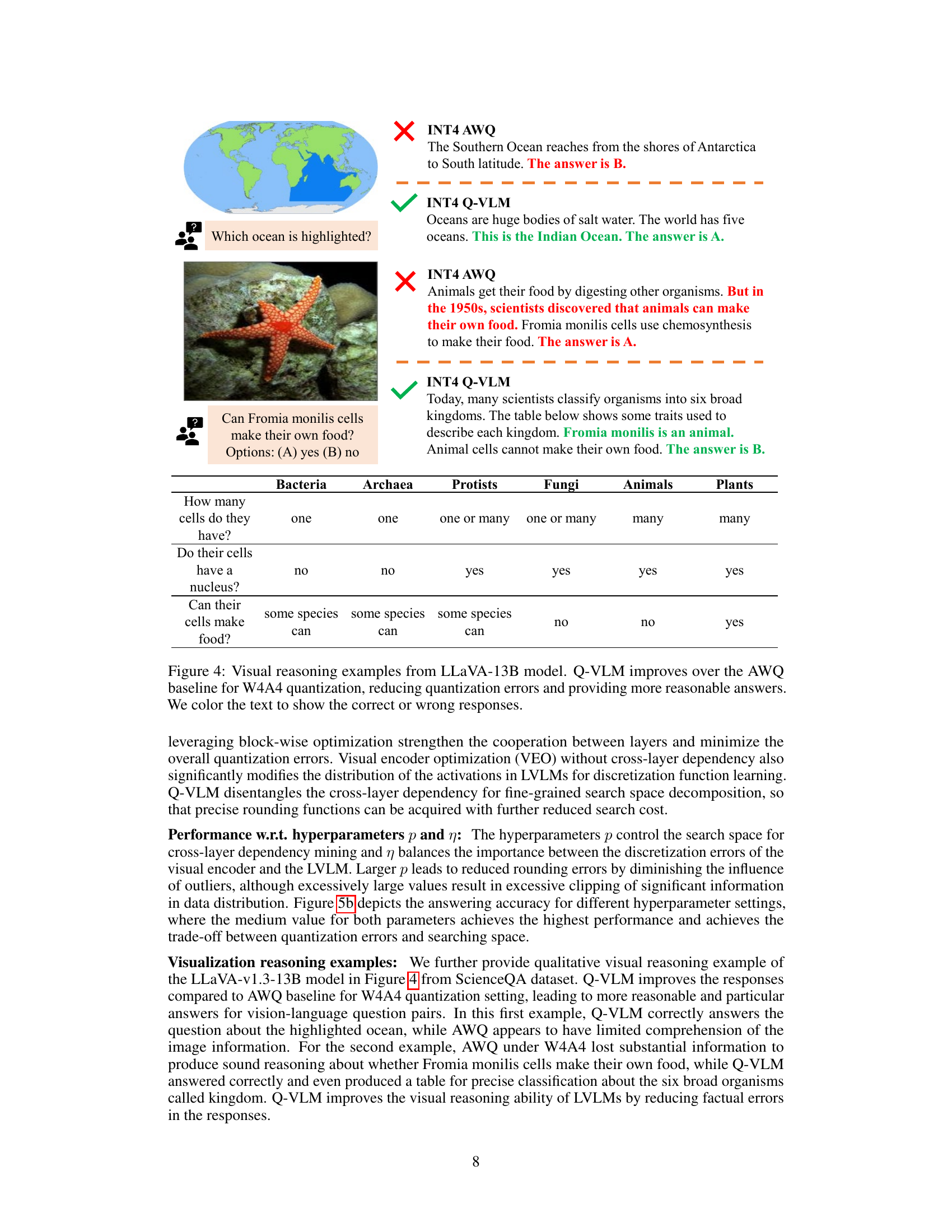
This figure presents the results of ablation studies conducted to analyze the impact of different hyperparameters on the performance of the proposed Q-VLM model. Specifically, it shows how the maximum depth within a block, the hyperparameters p and η (related to cross-layer dependency and visual encoder optimization, respectively), and the number of layers affect accuracy and search cost. Subfigure (a) focuses on the effect of block size. Subfigure (b) illustrates the combined impact of hyperparameters p and η. Subfigure (c) shows how the quantization error varies across layers with different maximum depths.

This figure illustrates the Q-VLM method’s pipeline. It uses entropy to efficiently partition the model into blocks for quantization, reducing the search space. The visual encoder is also optimized to further reduce the search space and improve accuracy. Cross-layer dependencies between layers are mined and used to guide the block assignment and search process.
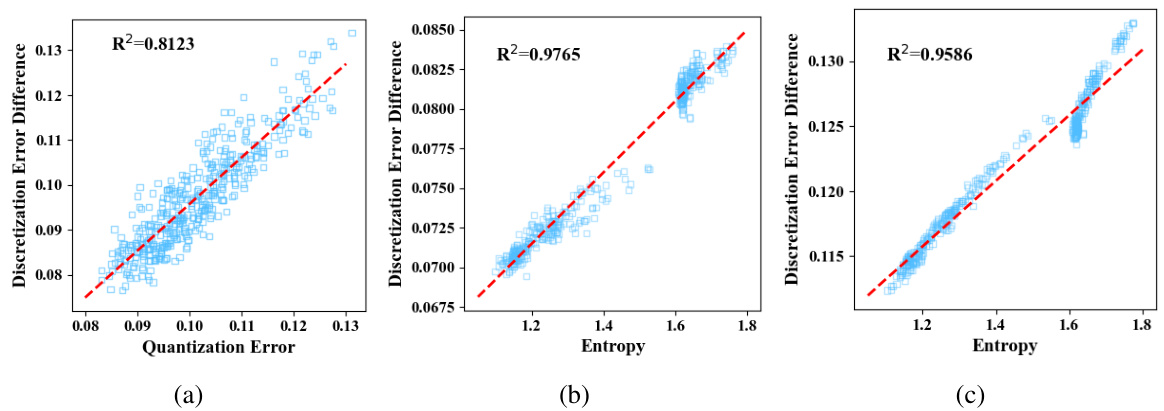
This figure shows the correlation analysis between the Discretization Error Difference (DED), quantization error, and entropy at different layers (5th, 15th, and 25th layers) of the model. It visually demonstrates the relationship between the entropy of the activations and the difference in discretization errors obtained using layer-wise versus joint searches across layers. High correlation coefficients (R²) are observed between entropy and DED, supporting the paper’s claim that entropy can effectively proxy for cross-layer dependency.
More on tables
This table compares the inference time, memory usage, and accuracy of three different post-training quantization methods (QLORA, AWQ, and Q-VLM) for the LLaVA-v1.3-13B model on the ScienceQA dataset. It shows the performance trade-offs between these methods at different bitwidth settings (W8A8 and W4A4). Lower inference time and memory usage represent better efficiency, while higher accuracy represents better performance.
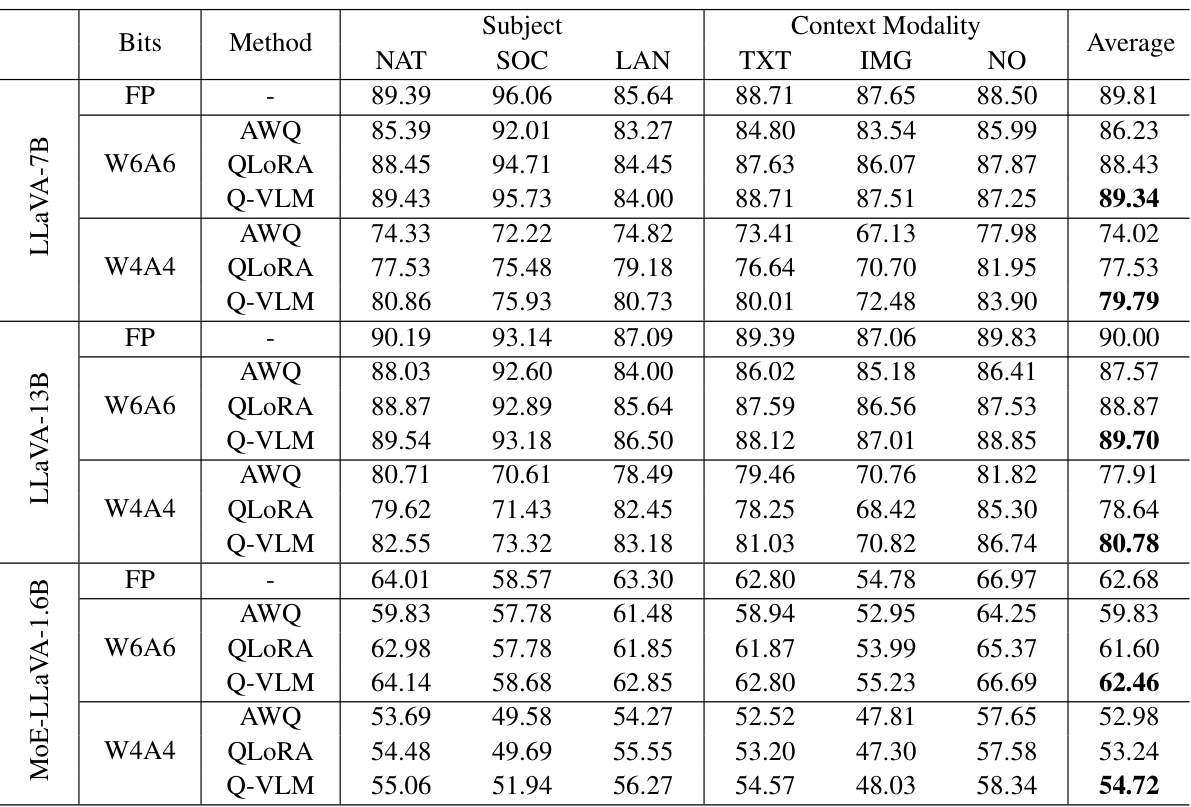
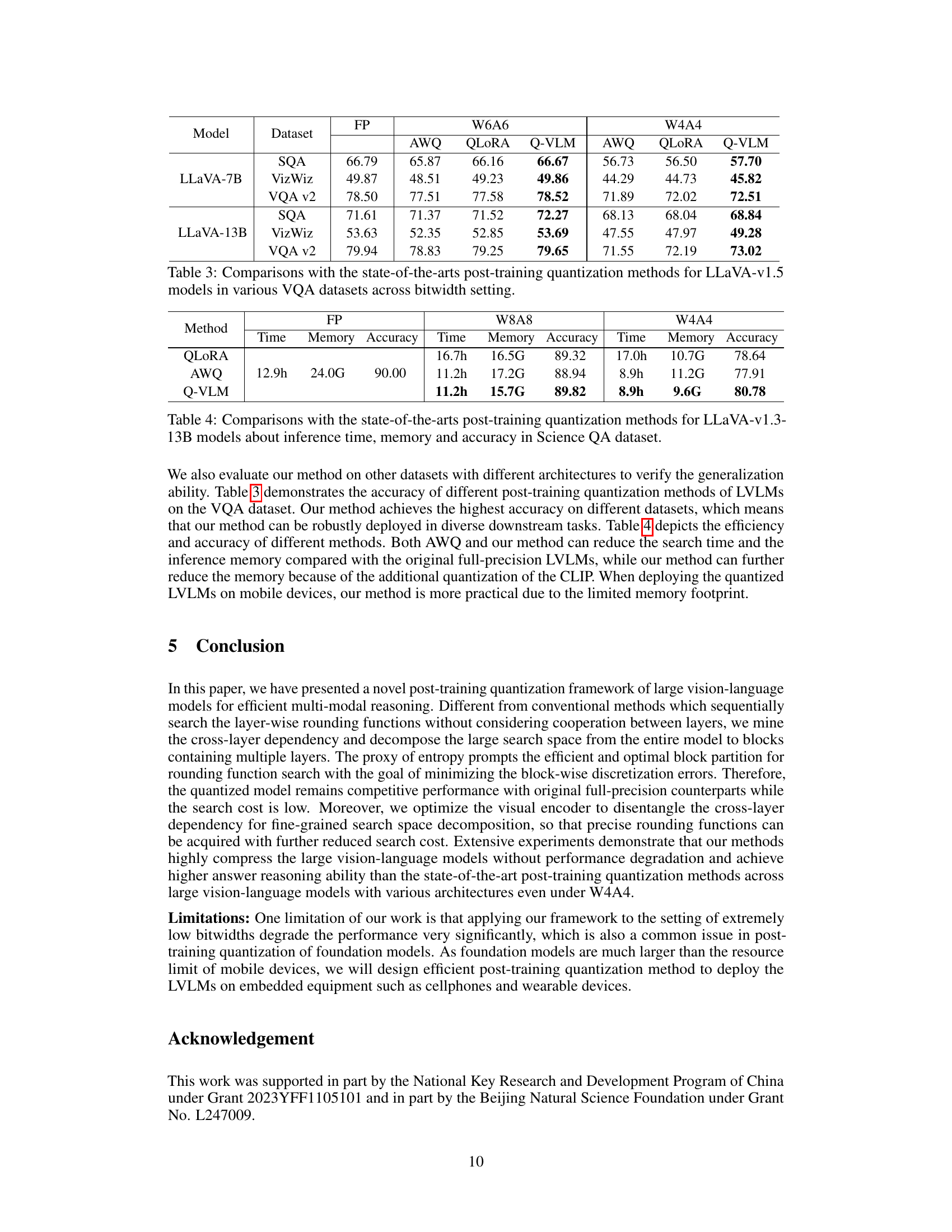
This table compares the performance of the proposed Q-VLM method against other state-of-the-art post-training quantization methods (AWQ and QLORA) for different large vision-language models (LLaVA and MoE-LLaVA) under various bitwidth settings (W6A6 and W4A4). The results are presented as accuracy scores on the ScienceQA dataset, broken down by question category (natural science, social science, language science, text context, image context, and no context). It shows how the different methods affect the model’s accuracy while using lower precision.
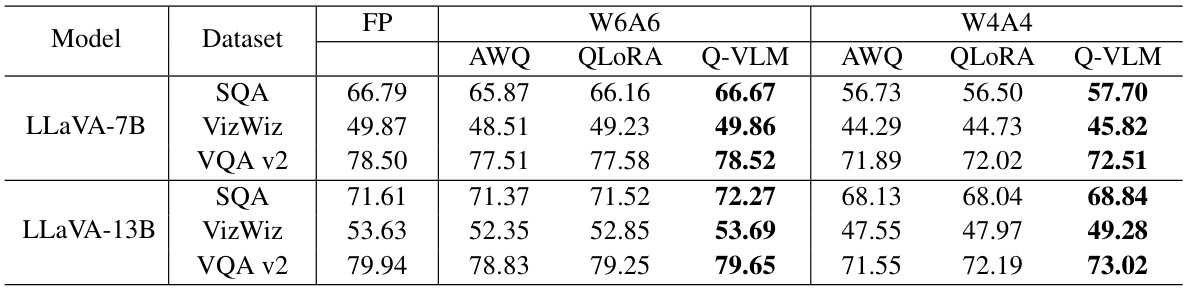
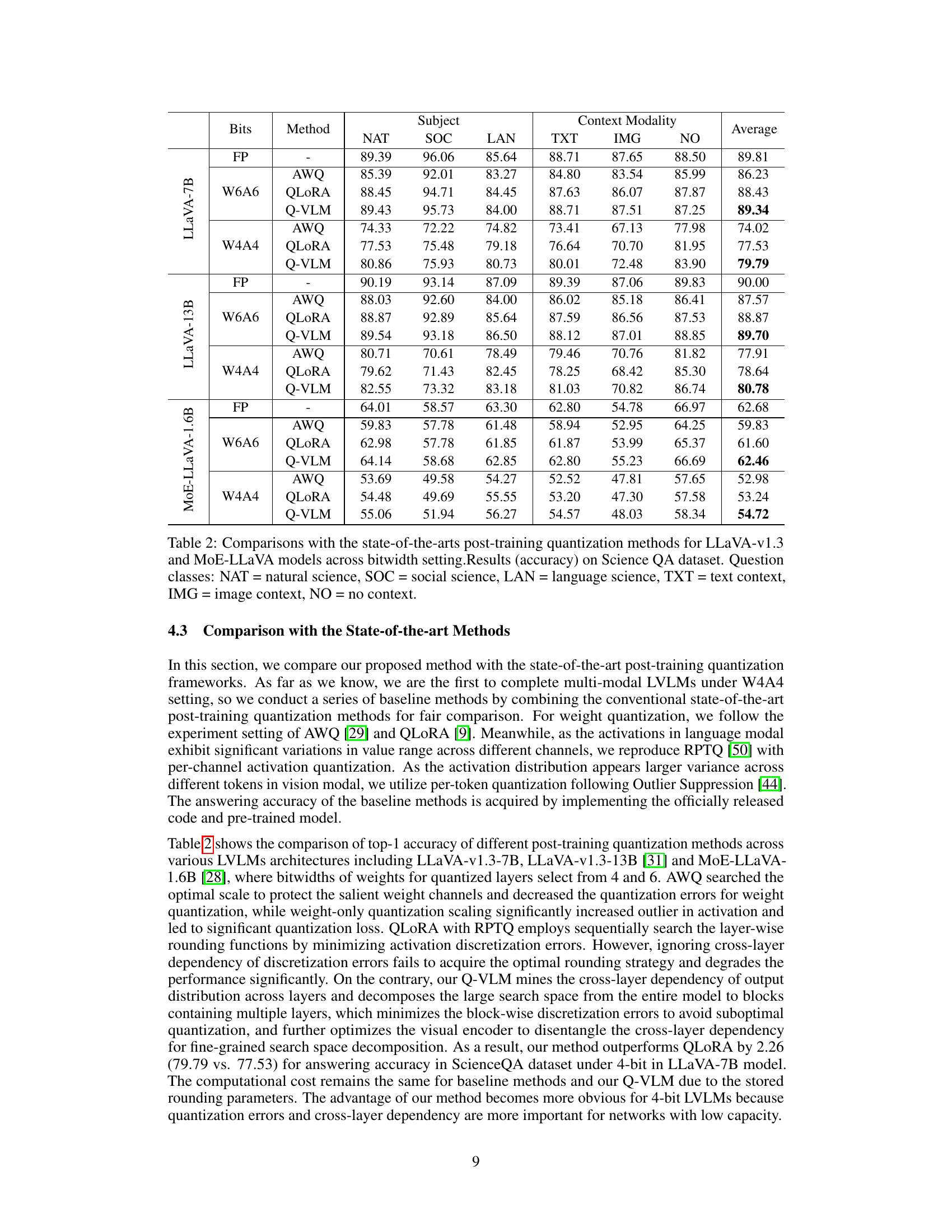
This table compares the performance of different post-training quantization methods (AWQ, QLoRA, and Q-VLM) against the full-precision (FP) model on three different visual question answering (VQA) datasets (ScienceQA, VizWiz, and VQA v2). The comparison is done for two different bitwidth settings (W6A6 and W4A4), representing different levels of model compression. The results show the accuracy achieved by each method on each dataset and bitwidth setting. This allows for an evaluation of the trade-off between model compression and performance.

This table compares the inference time, memory usage, and accuracy of three different quantization methods (QLORA, AWQ, and Q-VLM) applied to the LLaVA-v1.3-13B model on the ScienceQA dataset. The comparison is done for different bitwidths (W8A8 and W4A4, representing 8-bit weights and 8-bit activations and 4-bit weights and 4-bit activations respectively), alongside full precision (FP) results for comparison. The table shows that Q-VLM achieves the best balance between speed, memory efficiency and accuracy.
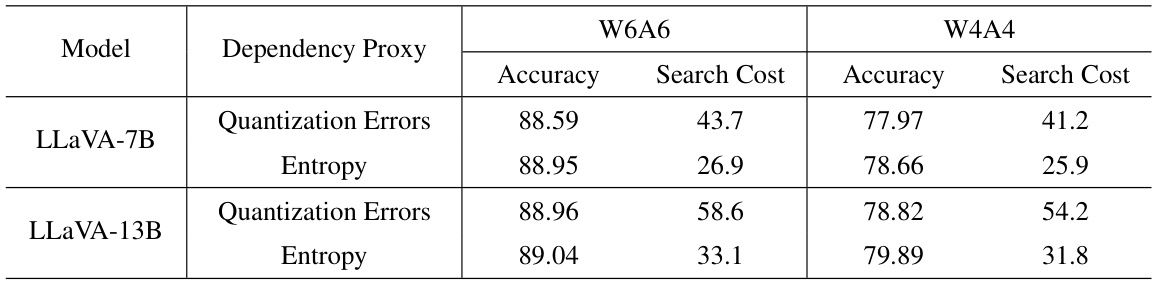
This table presents a comparison of the accuracy and search cost achieved using two different proxies (Quantization Errors and Entropy) for mining cross-layer dependencies in the LLaVA-v1.3 model for both 6-bit and 4-bit quantization. The results are presented for two different model sizes (LLaVA-7B and LLaVA-13B) on the ScienceQA dataset. This allows the reader to evaluate the impact of the chosen dependency proxy on both model accuracy and the computational cost involved in the search process.
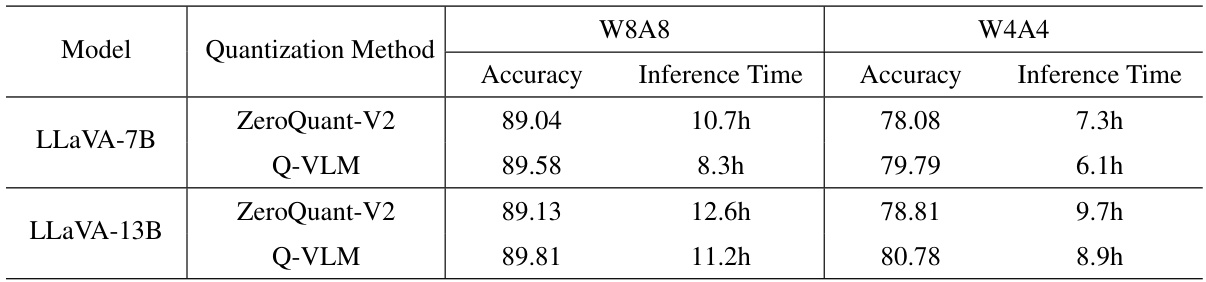
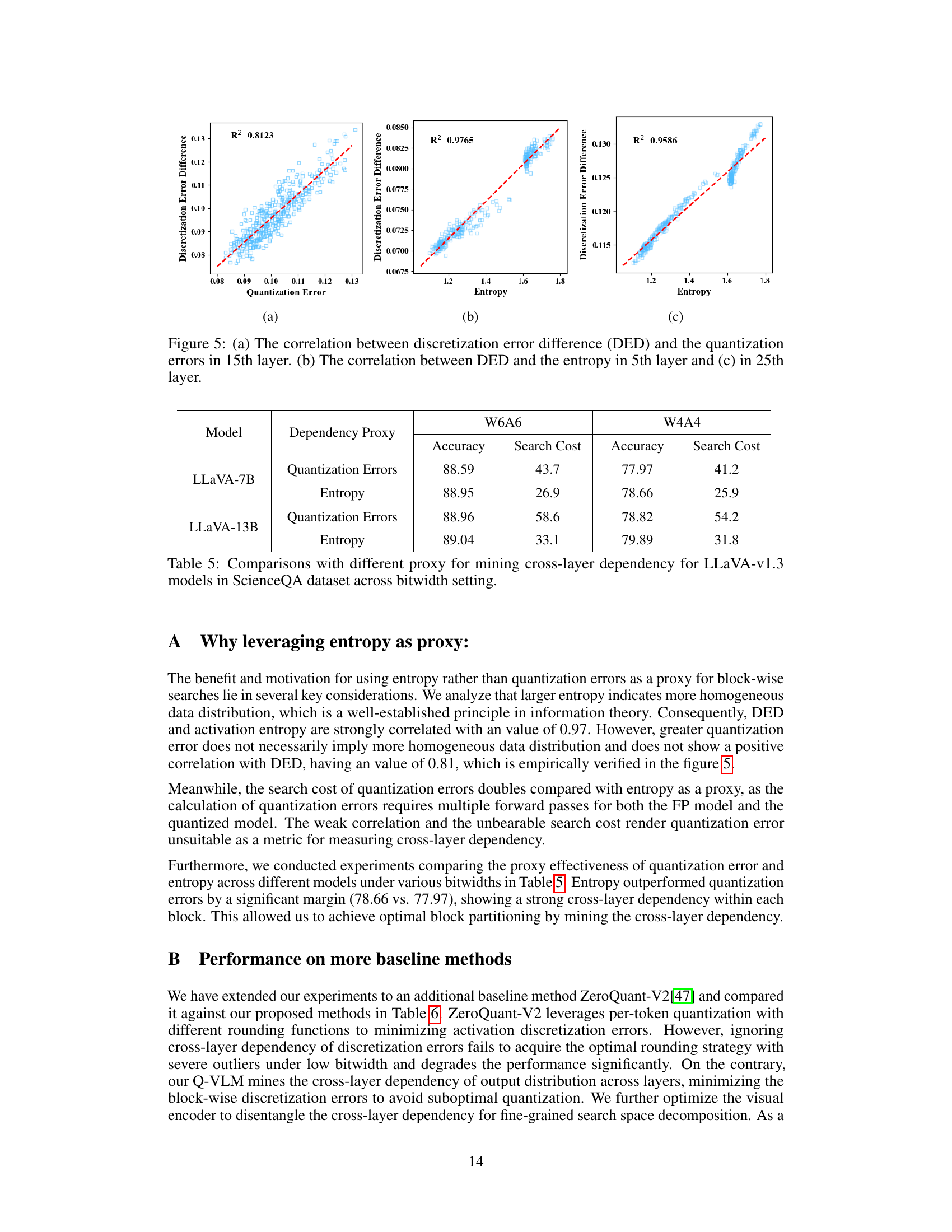
This table compares the performance of the proposed Q-VLM method against the ZeroQuant-V2 baseline method for two different Large Vision-Language Models (LLaVA-7B and LLaVA-13B) under two bitwidth settings (W6A6 and W4A4). It presents the accuracy and inference time for each model and quantization method, highlighting the improvements achieved by Q-VLM in both accuracy and efficiency.
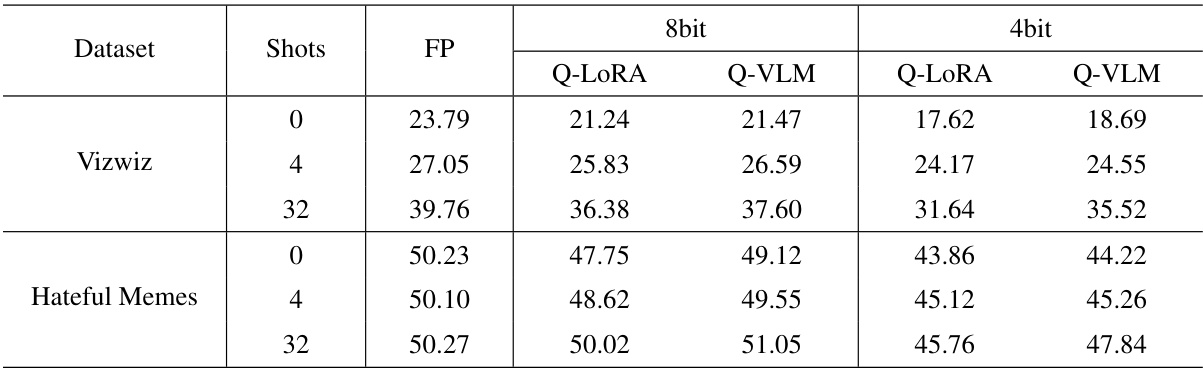
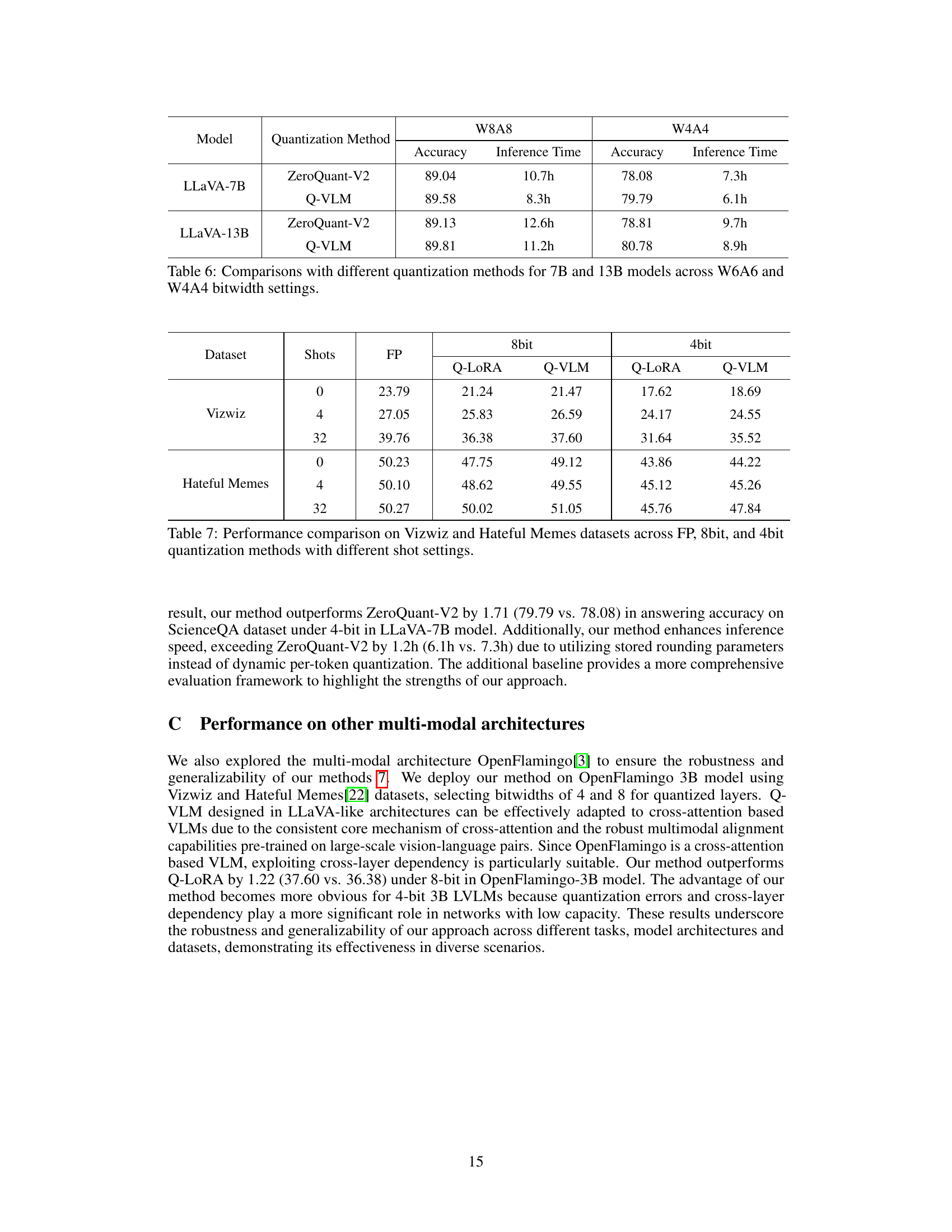
This table presents the performance comparison results on two datasets, Vizwiz and Hateful Memes, across different shot settings (0, 4, and 32 shots). The performance is measured using three different quantization methods: full precision (FP), Q-LORA (8-bit and 4-bit), and Q-VLM (8-bit and 4-bit). The table shows that Q-VLM consistently outperforms Q-LORA in both 8-bit and 4-bit settings across different numbers of shots on both datasets.
Full paper#