TL;DR#
Large language models (LLMs) are increasingly used, yet their safety remains a critical concern. Recent studies demonstrate that even aligned LLMs can be easily compromised through adversarial fine-tuning. This necessitates the development of robust safety mechanisms to ensure safe and reliable LLM applications.
This paper introduces the concept of the “safety landscape” to measure and visualize the safety risks in LLM finetuning. The authors discover a universal phenomenon called a “safety basin”, where minor model parameter changes preserve safety, while larger changes lead to immediate safety compromise. They propose a new safety metric, VISAGE, to quantify this risk and highlight the importance of system prompts in safeguarding LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals a universal vulnerability in large language models (LLMs). It introduces a novel safety metric and visualization technique, directly impacting the development and deployment of safer LLMs. This work is highly relevant to current research trends focusing on LLM safety and opens avenues for improving LLM robustness against adversarial attacks and harmful fine-tuning.
Visual Insights#

🔼 Figure 1 shows two key findings from the paper. Panel A demonstrates that a ‘safety basin’ universally exists in the parameter space of several popular open-source large language models (LLMs). This basin is a region where random perturbations to the model’s weights do not significantly affect its safety. However, outside this basin, the model’s safety dramatically decreases. This discovery led to the creation of a new safety metric called VISAGE. Panel B illustrates how finetuning affects the model’s position within the safety landscape. Finetuning with only harmful data pushes the model out of the safety basin, compromising its safety. Conversely, finetuning with a mixture of harmful and safe data allows the model to remain within the safety basin and maintain its safety.
read the caption
Figure 1: A. 'Safety basin', a new phenomenon observed universally in the model parameter space of popular open-source LLMs. Our discovery inspires us to propose the new VISAGE safety metric that measures the safety in LLM finetuning by probing its safety landscape. B. Visualizing the safety landscape of the aligned model also enables us to understand why finetuning with harmful data compromises safety but finetuning with both harmful and safe data preserves the safety.
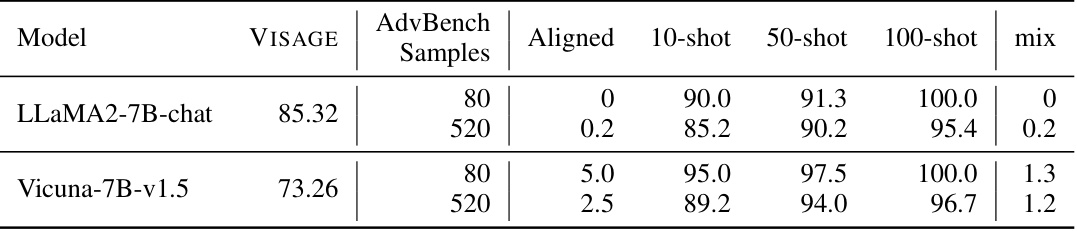
🔼 This table presents the results of fine-tuning two LLMs (LLaMA2-7B-chat and Vicuna-7B-v1.5) with varying amounts of harmful data (10-shot, 50-shot, 100-shot) and a mix of harmful and safe data. The VISAGE score, a new metric introduced in the paper, measures the robustness of the models’ safety. Lower ASR (Attack Success Rate) indicates better safety. The table shows that finetuning with harmful data significantly reduces the models’ safety, while incorporating safe data helps mitigate this effect. LLaMA2 consistently shows a higher VISAGE score and lower ASR than Vicuna, indicating greater safety and robustness.
read the caption
Table 1: Finetuning on few-shot harmful data breaks LLM's safety alignment at different rates and our VISAGE safety metric successfully measures the rate. LLaMA2 has a higher VISAGE score than Vicuna, and the ASRS on AdvBench indicate that when finetuned with the same amount of harmful data, LLaMA2 remains safer than Vicuna. Additionally, we demonstrate that finetuning with a mixture of safe and harmful data helps the model maintain its safety alignment. The 'aligned' column refers to the original off-the-shelf models.
In-depth insights#
LLM Safety Basins#
The concept of “LLM Safety Basins” proposes that within the vast parameter space of large language models (LLMs), localized regions exist where random perturbations to model weights do not significantly compromise safety. This contrasts with the sharp drop in safety observed outside these basins. The existence of these basins suggests that fine-tuning an aligned LLM can easily disrupt safety by moving the model out of its safety basin, highlighting the fragility of alignment. Visualizing this safety landscape can offer valuable insights into the robustness of an LLM’s alignment, providing a new perspective for evaluating safety risks during fine-tuning and the crucial role of system prompts in preserving safety within the basin.
VISAGE Safety Metric#
The VISAGE safety metric, as proposed in the paper, offers a novel approach to quantifying the risk in fine-tuning large language models (LLMs). It leverages the concept of a safety basin in the LLM parameter space, a region where random perturbations to model weights maintain the model’s safety. VISAGE measures the size and depth of this basin. A larger, deeper basin suggests greater robustness to adversarial fine-tuning attacks, as the model remains safe even with parameter variations. This contrasts with the capability landscape, where performance degrades with perturbations. By visualizing the safety landscape, VISAGE helps understand how fine-tuning compromises safety by moving the model away from this basin, offering a task-agnostic measure of risk. The metric’s effectiveness is demonstrated across multiple LLMs and safety benchmarks, showcasing its potential as a valuable tool for LLM safety research and development.
Finetuning Risks#
Finetuning large language models (LLMs) presents significant risks, as highlighted in the research. A key finding is the existence of a ‘safety basin’ in the model’s parameter space. Within this basin, random perturbations maintain the model’s safety, but outside this region, safety dramatically degrades. This emphasizes the fragility of aligned models and the potential for catastrophic failure with even minor adjustments. The research introduces the VISAGE metric to quantify this risk, enabling the measurement of safety resilience during finetuning. Furthermore, the system prompt plays a crucial role; removing it or using simple prompts significantly compromises safety. Visualizing the safety landscape reveals how finetuning, even with benign datasets, can shift the model away from the safety basin, increasing the risk of harmful outputs. However, finetuning with a mixture of safe and harmful data helps retain safety by keeping the model within the basin. This underscores the importance of careful finetuning strategies and robust safety mechanisms to mitigate these risks.
Prompt Engineering#
Prompt engineering is crucial for effectively interacting with large language models (LLMs). Well-crafted prompts can significantly impact the quality and safety of LLM outputs. Poorly designed prompts can lead to unsafe or biased responses, highlighting the need for careful consideration of prompt construction. The paper explores the interplay between prompts and LLM safety, showing how subtle changes in prompt design can dramatically shift the model’s behavior. This underscores the importance of systematic prompt engineering methodologies, enabling the creation of robust and reliable prompts that ensure safe and aligned LLM behavior. The research emphasizes the need for further investigation into prompt design techniques to enhance LLM safety and minimize unwanted outcomes. Prompt engineering is not just about eliciting desired information; it’s about safeguarding against potential harms and biases inherent in LLM technology.
Jailbreak Sensitivity#
Jailbreak sensitivity in large language models (LLMs) explores how susceptible these models are to adversarial attacks designed to circumvent their safety mechanisms. A key aspect is the sensitivity of the model’s output to small perturbations in its internal parameters or input prompts. This sensitivity can be exploited by attackers to trigger unsafe behaviors, such as generating harmful or biased content. Analyzing jailbreak sensitivity reveals crucial insights into the robustness and vulnerabilities of LLMs. Understanding how slight modifications can lead to significant changes in model behavior is crucial for developing more robust and secure LLMs. The research into jailbreak sensitivity could inform the development of new defense mechanisms against these attacks, potentially incorporating techniques like parameter regularization or input sanitization. Furthermore, investigating the relationship between jailbreak sensitivity and model architecture or training data could reveal critical vulnerabilities in current LLM development processes. Ultimately, a comprehensive understanding of jailbreak sensitivity is vital for improving the safety and reliability of LLMs and mitigating their potential risks.
More visual insights#
More on figures

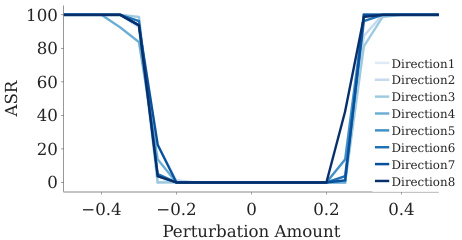
🔼 This figure shows the safety landscape of LLaMA2. The left panel (a) shows the 1D interpolation safety landscape between the pre-trained LLaMA2-7B and the aligned LLaMA2-7B-chat models. It demonstrates how the safety changes as the model parameters are linearly interpolated between the two models, considering two different chat formats: text completion and LLaMA2 chat template. The right panel (b) illustrates the 1D random safety landscape of the aligned LLaMA2-7B-chat model, showing how safety varies when the model weights are randomly perturbed along different directions. Both panels use ASR as the safety metric.
read the caption
Figure 2: LLM safety landscape: (a) 1D-interpolation LLaMA2-7B → LLaMA2-7B-chat safety landscape. When given two models varied by fine-tuning, we utilize linear interpolation to visualize the changes between them. While interpolating the model weights between the base and the chat model, we need to ensure the chat format remains consistent. Thus, we ablate on both chat formats: text completion (no template) and LLaMA2 chat template. The chat model exhibits higher safety than the base model as expected. The base model also shows an increase in safety while using the LLaMA2 chat template. (b) 1D-random LLaMA2-7B safety landscape sampled over different random directions. When provided with a single model, we sample a random normalized direction to visualize its local variations along both positive and negative directions.
🔼 Figure 1 shows two key findings from the paper. Part A illustrates the ‘safety basin’ phenomenon. This shows that for several popular open-source LLMs, randomly perturbing the model’s weights within a certain local neighborhood preserves the model’s safety. However, outside this region, safety drops sharply. Part B shows how the safety landscape is useful for visualizing the impact of finetuning: finetuning with harmful data moves the model out of the safety basin and compromises its safety, while finetuning with a mix of harmful and safe data keeps it within the safety basin and preserves safety.
read the caption
Figure 1: A. 'Safety basin', a new phenomenon observed universally in the model parameter space of popular open-source LLMs. Our discovery inspires us to propose the new VISAGE safety metric that measures the safety in LLM finetuning by probing its safety landscape. B. Visualizing the safety landscape of the aligned model also enables us to understand why finetuning with harmful data compromises safety but finetuning with both harmful and safe data preserves the safety.

🔼 This figure shows the impact of different system prompts on the safety landscape of two LLMs: Mistral and Vicuna. It demonstrates that removing the default system prompt significantly reduces safety, while using a roleplaying prompt has a mixed effect. Conversely, using LLaMA2’s default system prompt or a safety prompt optimized for the specific LLM significantly improves safety across the entire safety basin. The figure visually represents the relationship between prompt variations, model safety, and perturbations to model weights.
read the caption
Figure 3: The system prompt has a strong impact on LLM safety landscape. From an attacker's standpoint, we find that both removing the default system prompt and using simple roleplaying prompt jeopardizes the safety alignment, with the former exhibiting greater potency. From a defender's perspective, we discover that LLaMA2's original system prompt universally enhances safety across models, and safety prompts optimized through prompt tuning for a specific model also enhances safety for all models inside the safety basin.
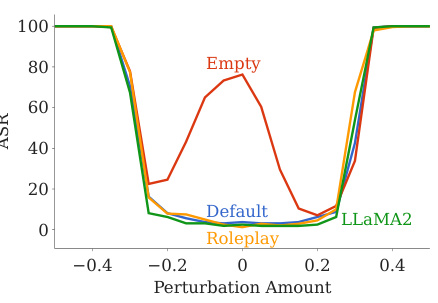
🔼 This figure shows the impact of different system prompts on the safety landscape of two LLMs: Mistral and Vicuna. It compares the effects of removing the default system prompt, using a roleplaying prompt, using the default LLaMA2 system prompt, and using a safety prompt optimized for each specific model. The results demonstrate that the system prompt significantly influences the safety of the LLMs, and that the original LLaMA2 prompt can enhance safety across models.
read the caption
Figure 3: The system prompt has a strong impact on LLM safety landscape. From an attacker's standpoint, we find that both removing the default system prompt and using simple roleplaying prompt jeopardizes the safety alignment, with the former exhibiting greater potency. From a defender's perspective, we discover that LLaMA2's original system prompt universally enhances safety across models, and safety prompts optimized through prompt tuning for a specific model also enhances safety for all models inside the safety basin.
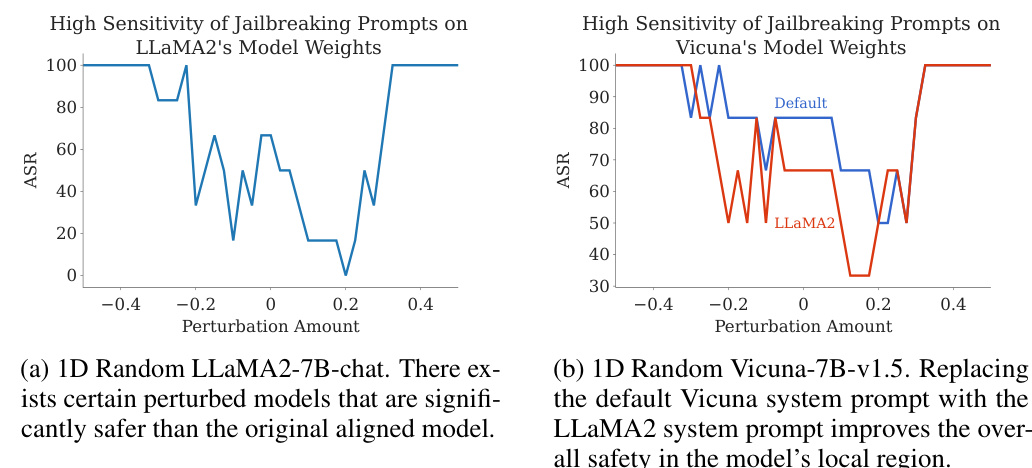
🔼 Figure 1 shows two key findings about the safety of Large Language Models (LLMs). Part A illustrates the concept of a ‘safety basin’ in the model’s parameter space. Randomly perturbing the model’s weights within this basin maintains its safety. Outside the basin, safety is immediately compromised. Part B demonstrates how fine-tuning with only harmful data moves the model out of the safety basin, compromising safety, while fine-tuning with a mixture of harmful and safe data helps keep the model within the safety basin, preserving safety.
read the caption
Figure 1: A. 'Safety basin', a new phenomenon observed universally in the model parameter space of popular open-source LLMs. Our discovery inspires us to propose the new VISAGE safety metric that measures the safety in LLM finetuning by probing its safety landscape. B. Visualizing the safety landscape of the aligned model also enables us to understand why finetuning with harmful data compromises safety but finetuning with both harmful and safe data preserves the safety.

🔼 The figure displays the results of perturbing the LLaMA2-7B-chat model’s weights and measuring the attack success rate (ASR) using two different safety metrics: keyword detection and LLaMAGuard 2. Both metrics reveal a similar ‘safety basin’ pattern. The ASR remains high near the original model’s weights but drops significantly when the weights are perturbed outside of a certain region. This illustrates the concept of a safety basin where small changes to model parameters maintain safety, while larger changes quickly compromise it.
read the caption
Figure 5: LLaMA2-7B-chat’s perturbation shows a basin shape similar to the safety keyword detection.
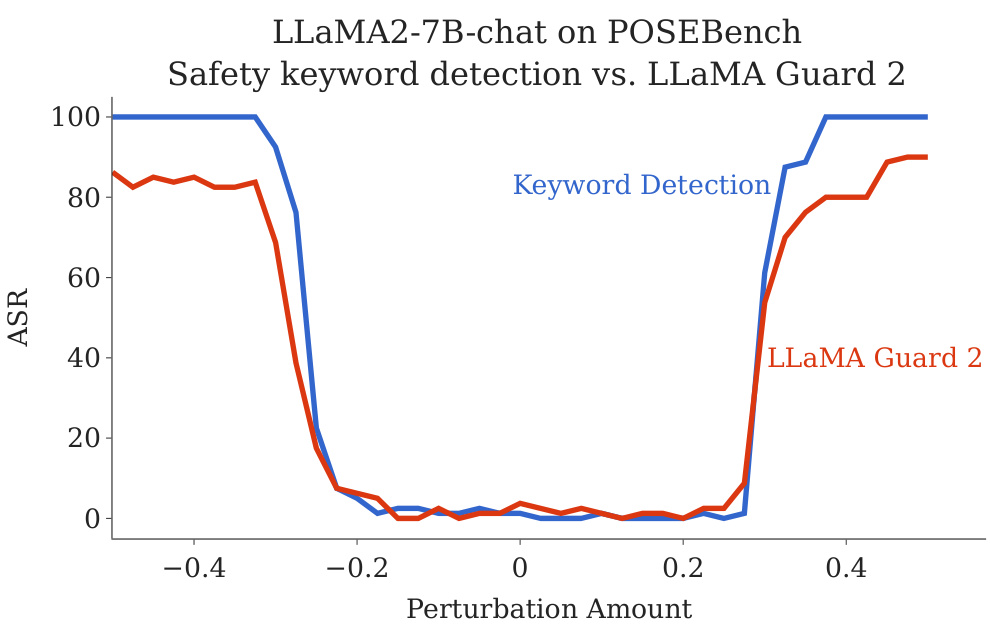
🔼 This figure shows the results of evaluating the safety of the LLaMA2-7B-chat model on the POSE benchmark using two different safety metrics: keyword detection and LLaMAGuard 2. The x-axis represents the perturbation amount, and the y-axis represents the ASR (attack success rate). Both metrics show a similar basin-like shape, indicating that the model’s safety is maintained within a local region of its parameter space, but it can be easily compromised outside of this region.
read the caption
Figure 6: Results on POSE benchmark again verifies the safety basin observed on the AdvBench benchmark. We evaluate the generated outputs using both safety keyword detection and LLaMAGuard 2 and both evaluation metrics show a similar basin shape.
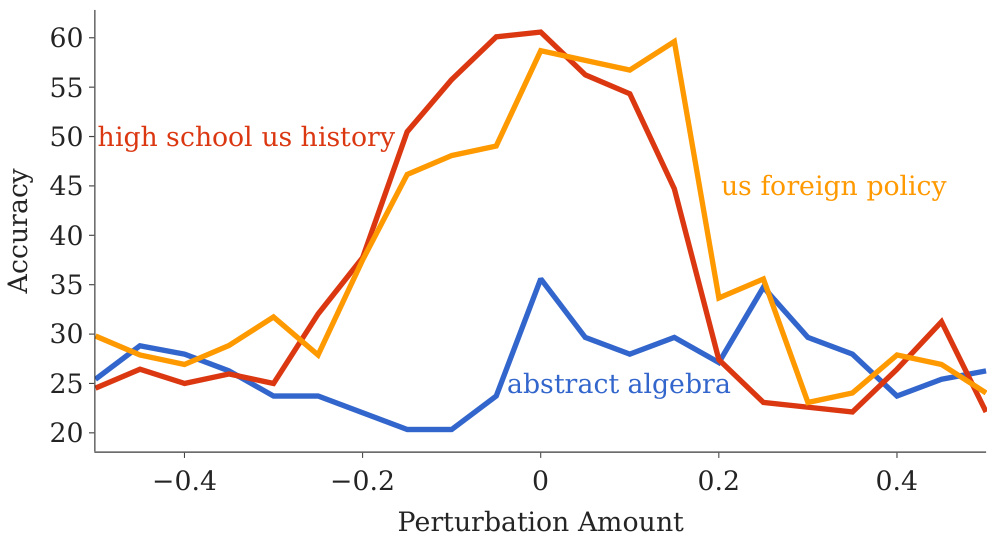
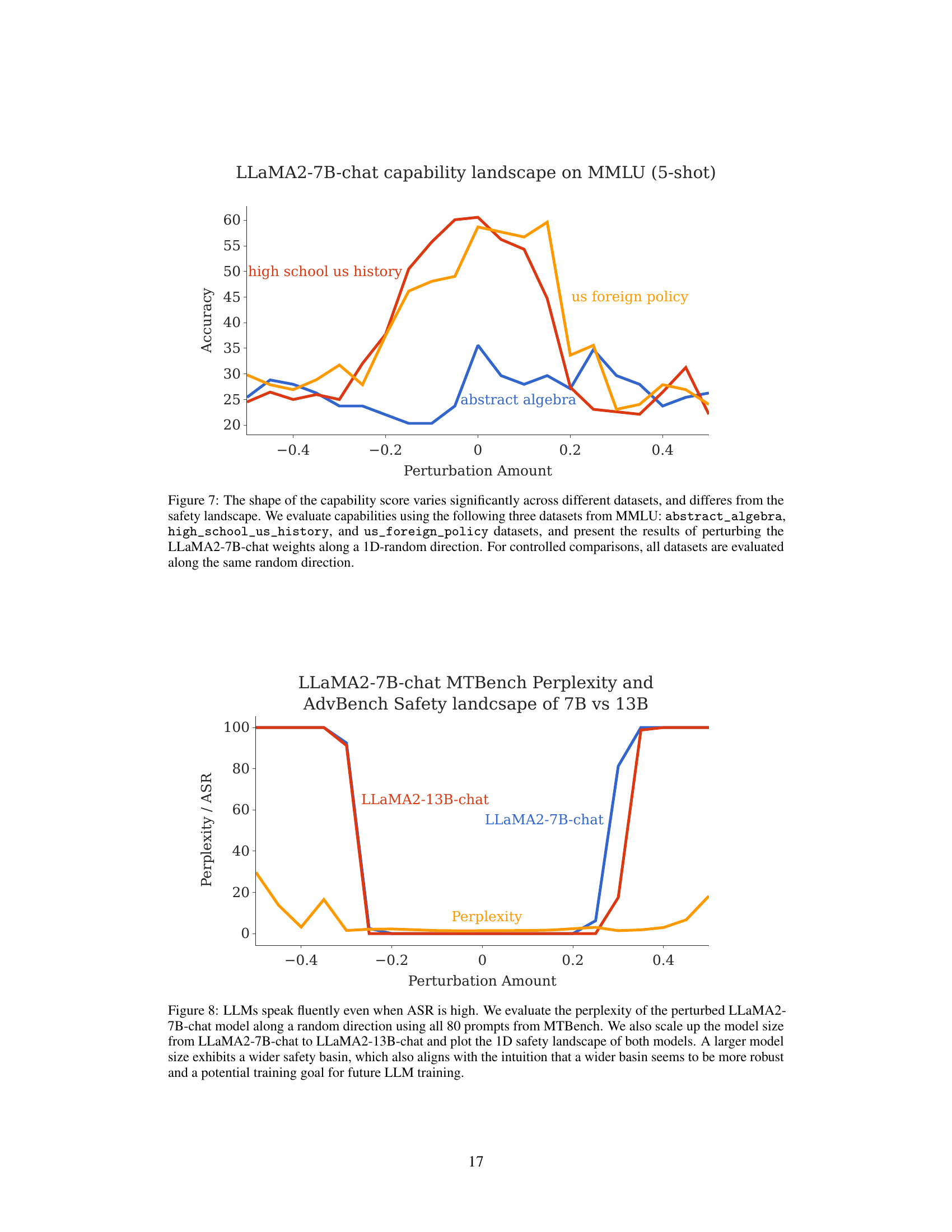
🔼 This figure compares the capability landscape across three different datasets from MMLU (abstract algebra, high school US history, and US foreign policy) with the safety landscape. The x-axis represents the perturbation amount, while the y-axis represents the accuracy. The figure shows that the shape of the capability landscape varies significantly across different datasets, unlike the safety landscape which exhibits a consistent basin shape. This confirms that the basin shape is unique to the safety of LLMs and not a general property of model landscapes.
read the caption
Figure 7: The shape of the capability score varies significantly across different datasets, and differs from the safety landscape. We evaluate capabilities using the following three datasets from MMLU: abstract_algebra, high_school_us_history, and us_foreign_policy datasets, and present the results of perturbing the LLaMA2-7B-chat weights along a 1D-random direction. For controlled comparisons, all datasets are evaluated along the same random direction.
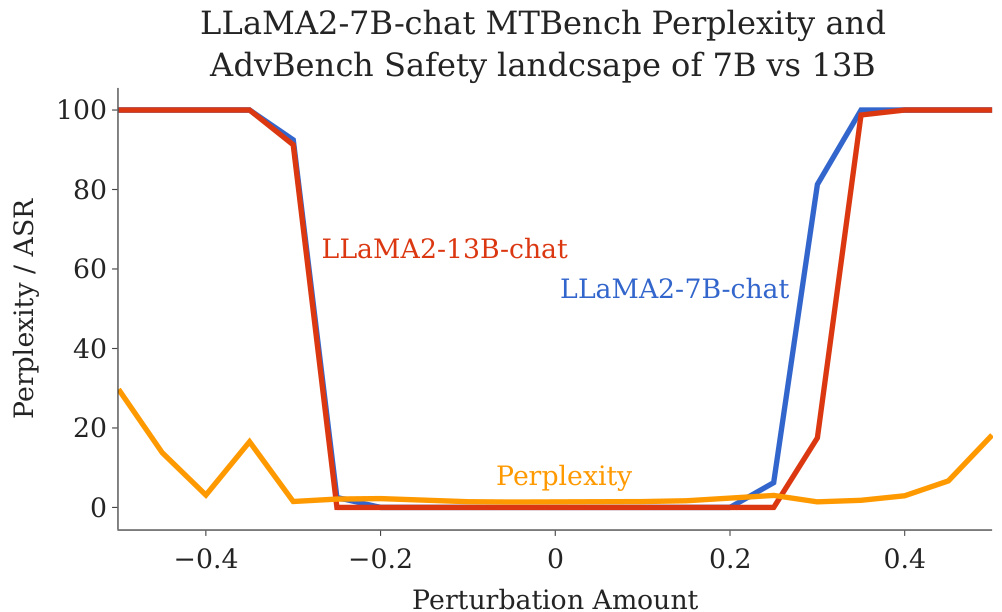
🔼 This figure shows the perplexity and ASR for LLaMA2-7B-chat and LLaMA2-13B-chat models as their weights are perturbed along a random direction. The perplexity, measuring fluency, remains relatively low even when the ASR (adversarial success rate), measuring safety, is high. The larger 13B model displays a wider safety basin (region of parameter space where the model remains safe), supporting the idea that larger models are more robust.
read the caption
Figure 8: LLMs speak fluently even when ASR is high. We evaluate the perplexity of the perturbed LLaMA2-7B-chat model along a random direction using all 80 prompts from MTBench. We also scale up the model size from LLaMA2-7B-chat to LLaMA2-13B-chat and plot the 1D safety landscape of both models. A larger model size exhibits a wider safety basin, which also aligns with the intuition that a wider basin seems to be more robust and a potential training goal for future LLM training.
More on tables
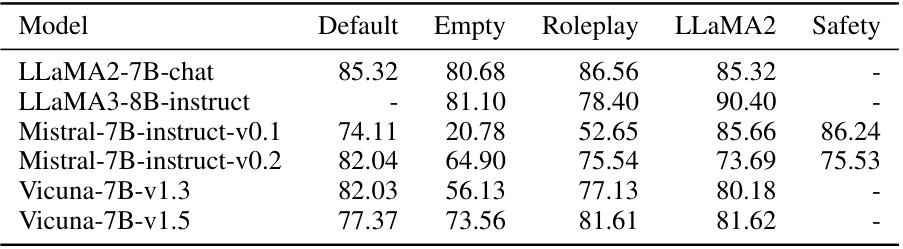
🔼 This table presents the VISAGE scores for various LLMs under different system prompts. The VISAGE score is a metric measuring the robustness of a model’s safety to perturbations. It shows how the default, empty (no prompt), roleplay, LLaMA2’s default prompt, and optimized safety prompts affect safety for each LLM. Higher scores indicate better safety.
read the caption
Table 2: LLM safety landscape highlights the system prompt's critical role in protecting a model, and how this protection transfers to its perturbed variants in the safety basin. We measure the VISAGE Score of different system prompt for popular open-source LLMs. Higher VISAGE means safer model and '-' means not applicable. For LLaMA3, there is no default system prompt in the initial release. For all other LLMs in the 'safety' column, we use the optimized safety prompts specific to each LLM from Zheng et al. [49], with only Mistral's safety system prompt provided.

🔼 This table presents the results of finetuning two LLMs (LLaMA2 and Vicuna) with varying amounts of harmful data (10, 50, and 100 examples). It shows the impact of this finetuning on the models’ safety, measured by both the VISAGE metric and the ASR (attack success rate) on the AdvBench benchmark. The table demonstrates that finetuning with harmful data significantly reduces safety, while finetuning with a mixture of harmful and safe data helps maintain safety. It also highlights that LLaMA2 is more robust to harmful finetuning than Vicuna.
read the caption
Table 1: Finetuning on few-shot harmful data breaks LLM's safety alignment at different rates and our VISAGE safety metric successfully measures the rate. LLaMA2 has a higher VISAGE score than Vicuna, and the ASRS on AdvBench indicate that when finetuned with the same amount of harmful data, LLaMA2 remains safer than Vicuna. Additionally, we demonstrate that finetuning with a mixture of safe and harmful data helps the model maintain its safety alignment. The 'aligned' column refers to the original off-the-shelf models.
Full paper#