↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) excel in logical, vertical thinking but struggle with creative, lateral thinking. Existing benchmarks inadequately assess this crucial capability, hindering the development of truly human-like AI. This creates a need for new evaluation methods that focus on creative problem-solving.
To address this, the researchers introduce SPLAT, a benchmark using graded situation puzzles. SPLAT employs a unique multi-turn player-judge framework, simulating an interactive game where the LLM (player) asks questions and a strong evaluation model (judge) answers. This approach avoids biases inherent in traditional model-based evaluations. Results demonstrate that SPLAT effectively evaluates lateral thinking, showing performance improvements on other benchmarks when using SPLAT’s data and reasoning processes. This suggests that SPLAT is a valuable tool for both evaluating and eliciting lateral thinking in LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the significant gap in evaluating Large Language Models’ (LLMs) lateral thinking abilities. By introducing a novel benchmark and a unique evaluation framework, it provides researchers with the tools to effectively assess and elicit creative problem-solving in LLMs, paving the way for developing more innovative and human-like AI systems.
Visual Insights#

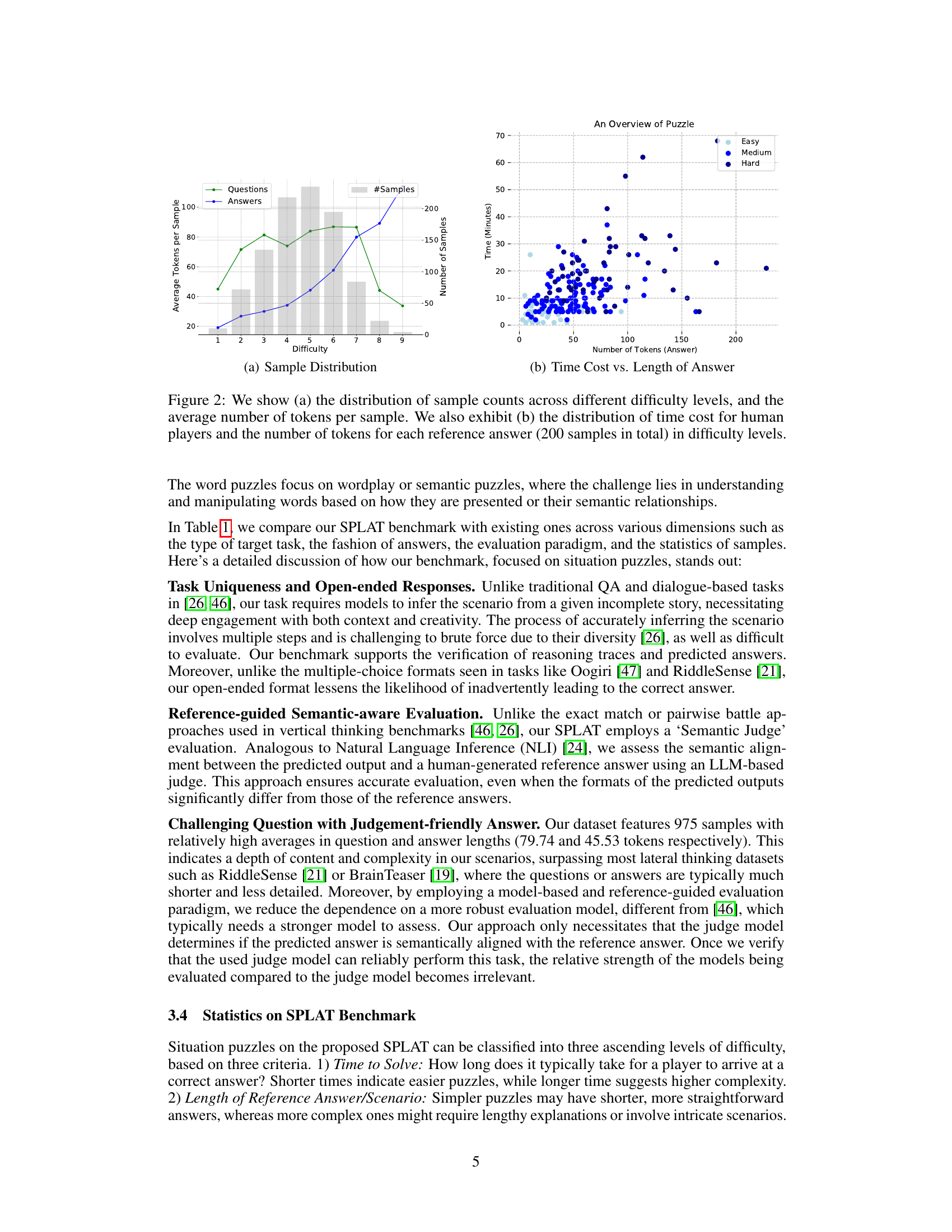
This figure presents two subfigures visualizing data related to the difficulty levels in the SPLAT benchmark. Subfigure (a) shows a bar chart illustrating the number of samples per difficulty level (1-9), overlaid with line charts showing the average number of tokens used in questions and answers for each difficulty level. Subfigure (b) displays a scatter plot correlating the time taken by human players to solve a puzzle with the number of tokens in the corresponding reference answer. This scatter plot helps illustrate the relationship between puzzle complexity (as measured by solution length and time to solve) and difficulty level.
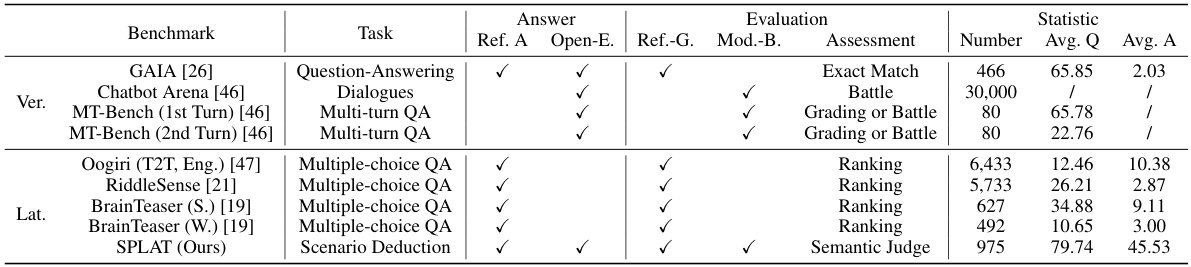
This table compares the SPLAT benchmark with other related benchmarks focusing on both vertical and lateral thinking. It analyzes key characteristics like the type of task, answer format (open-ended or not), evaluation method (reference-guided, model-based, or other), and assessment strategies. Statistical information such as the number of samples, average question length, and average answer length are also provided for each benchmark.
In-depth insights#
Lateral Thinking Eval#
In evaluating lateral thinking, a crucial aspect is assessing the capacity for creative problem-solving beyond conventional approaches. A key challenge lies in designing evaluation methods that accurately capture this nuanced cognitive ability. Situation puzzles, which require indirect reasoning and unconventional thinking, offer a promising avenue. Effective evaluation frameworks must move beyond traditional, model-based approaches to account for the open-ended nature of lateral thinking tasks. Human evaluation, while time-consuming, provides a valuable ground truth for assessing model performance. Multi-turn player-judge frameworks simulate interactive problem-solving, allowing for a more nuanced evaluation of the reasoning process. The ability to elicit lateral thinking, not just measure it, is vital, meaning benchmarks must encourage creative solutions. Integrating benchmarks with diverse lateral thinking tasks enhances the evaluation’s overall comprehensiveness. Combining quantitative metrics (like accuracy and rounds to solution) with qualitative assessments of the reasoning process itself provides a complete picture. Ultimately, robust evaluation methods for lateral thinking are essential for advancing AI’s creative problem-solving abilities.
SPLAT Benchmark#
The SPLAT benchmark, designed for evaluating Large Language Models’ (LLMs) lateral thinking abilities, presents a significant advancement in assessing creative problem-solving. Its core innovation lies in employing situation puzzles, a task type requiring indirect reasoning and unconventional thinking, unlike traditional benchmark tasks. The multi-turn player-judge framework, simulating an interactive game between the LLM and an evaluation model, is crucial; it reduces reliance on a superior evaluation model and allows for nuanced assessment of the LLM’s reasoning process. The 975 graded situation puzzles, categorized by difficulty, provide a robust and scalable dataset for evaluation. Importantly, SPLAT’s design not only evaluates but also elicits lateral thinking, as demonstrated by performance improvements on other lateral thinking benchmarks when using SPLAT’s data and reasoning processes. This dual functionality makes SPLAT a powerful tool for both assessing current LLM capabilities and guiding future development toward more creative and flexible AI systems.
Multi-turn Framework#
The proposed multi-turn framework offers a novel approach to evaluating lateral thinking in LLMs, departing from traditional single-turn methods. Its interactive nature, where the LLM acts as a player querying a judge (either another LLM or a human) about an incomplete story, allows for a more nuanced assessment of reasoning abilities. This iterative process, involving multiple question-answer exchanges, better mirrors human problem-solving strategies that often involve gradual information gathering and hypothesis refinement. The framework’s strength lies in its reduced reliance on a highly sophisticated evaluation model, mitigating biases potentially introduced by a superior judge model. By focusing on the process of inference rather than solely on the final answer, it provides a richer understanding of the LLM’s creative thinking capabilities. This makes the framework particularly suitable for evaluating complex open-ended problems typical of lateral thinking puzzles. However, a limitation could be the increased computational cost associated with multi-turn interactions.
LLM Lateral Ability#
The concept of “LLM Lateral Ability” probes a crucial, underexplored area in large language model (LLM) research. It challenges the prevalent focus on vertical, linear reasoning by examining LLMs’ capacity for creative, unconventional problem-solving. Lateral thinking, unlike its vertical counterpart, involves exploring multiple perspectives and breaking free from established patterns. Assessing this ability requires novel evaluation methods, as traditional benchmarks often prioritize straightforward, logical solutions. Therefore, developing methods to elicit and evaluate lateral thinking in LLMs presents a significant methodological hurdle. This necessitates creating new benchmarks and frameworks focused on tasks that demand creative, indirect approaches, such as puzzles or open-ended storytelling. The development of robust evaluation metrics is equally critical, potentially involving human judgment, model-based comparison, or a hybrid approach. Ultimately, understanding and enhancing LLM lateral ability is key to unlocking their full potential and realizing the goal of Artificial General Intelligence (AGI), which fundamentally requires both logical deduction and imaginative problem-solving.
Future Research#
Future research directions stemming from this work could involve exploring the scalability of the SPLAT benchmark to a wider range of LLMs and puzzle types. Further investigation into the interpretability of the multi-turn player-judge framework could lead to better understanding of the underlying reasoning processes used by LLMs in solving lateral thinking puzzles. Cross-benchmark analysis could identify shared characteristics and common challenges between situation puzzles and other lateral thinking benchmarks. Additionally, research could focus on developing more advanced techniques to quantify creativity and originality in LLM responses. Finally, it would be valuable to explore the ethical implications of using LLMs for lateral thinking tasks, considering potential biases and misuse, and developing mitigation strategies.
More visual insights#
More on figures

This figure shows two subfigures. Subfigure (a) presents a bar chart illustrating the distribution of situation puzzles across three difficulty levels (Easy, Medium, Hard), indicating the number of samples in each level and the average number of tokens in questions and answers for each level. Subfigure (b) displays a scatter plot showing the relationship between the time taken by human players to solve the puzzles and the length (number of tokens) of the reference answers for 200 samples across all difficulty levels.

This figure shows the performance comparison of several LLMs on the RiddleSense benchmark. It highlights the impact of using auxiliary reasoning prompts derived from the SPLAT benchmark. Llama3 (8B & 70B) and GPT-4 are evaluated in a zero-shot setting, while other models are fine-tuned on RiddleSense and CSQA datasets. The ‘*’ indicates models that incorporated auxiliary reasoning prompts from the SPLAT benchmark, demonstrating improved performance compared to their zero-shot counterparts.
More on tables

This table presents the level of agreement between three different judge models (WizardLM-2, Llama3-70B, and human judges) on the final answer accuracy of the SPLAT benchmark’s puzzles. The agreement is measured separately for three difficulty levels: Easy, Medium, and Hard. Each entry in the table shows the percentage agreement between the specified judge model and the human judgments.

This table presents the agreement rate between three different types of judges (WizardLM-2, Llama3-70B, and human evaluators) on the reasoning process of solving situation puzzles within the SPLAT benchmark. The agreement is measured across three difficulty levels (easy, medium, and hard). A higher percentage indicates a stronger agreement between the judge and human evaluations on the reasoning process.

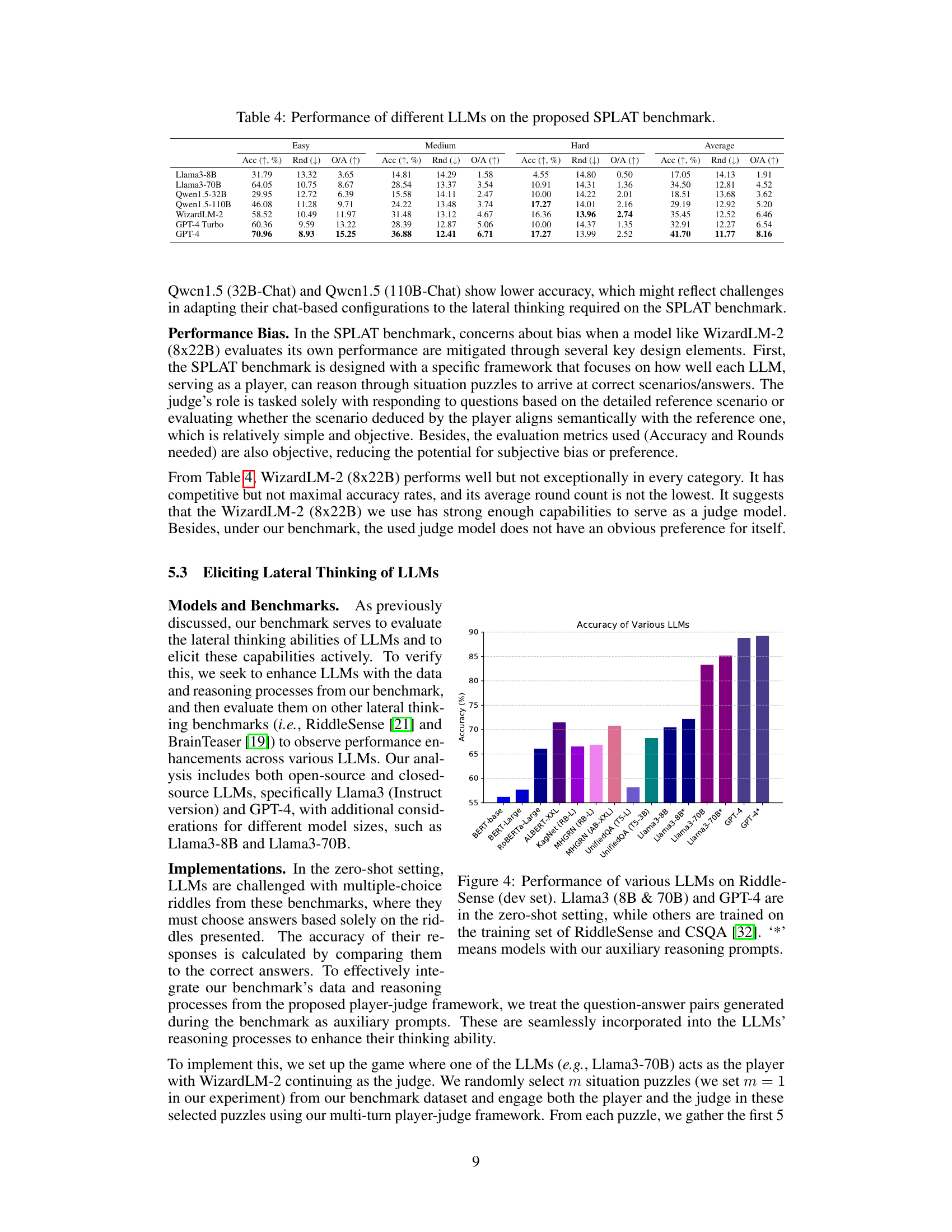
This table presents the performance of various Large Language Models (LLMs) on the Situation Puzzles for LAteral Thinking benchmark (SPLAT). The performance is evaluated across three difficulty levels (Easy, Medium, Hard) and overall. Three metrics are reported for each LLM and difficulty level: Accuracy (Acc, %), representing the percentage of correctly solved puzzles; Average Round (Rnd, ↓), indicating the average number of interaction rounds needed to solve a puzzle (lower is better); and Overall (O/A, ↑), a combined metric that considers both accuracy and the number of rounds (higher is better). The table allows for a comparison of LLMs’ lateral thinking capabilities across difficulty levels.

This table presents the performance of various Large Language Models (LLMs) on the Situation Puzzles for Lateral Thinking benchmark (SPLAT). It shows the accuracy (Acc), average number of rounds (Rnd) needed to solve the puzzles, and an overall performance score (O/A) for each LLM across three difficulty levels (Easy, Medium, Hard) of the SPLAT benchmark. The results highlight the varying capabilities of different LLMs in solving situation puzzles, demonstrating the challenges and opportunities in developing LLMs with stronger lateral thinking abilities.
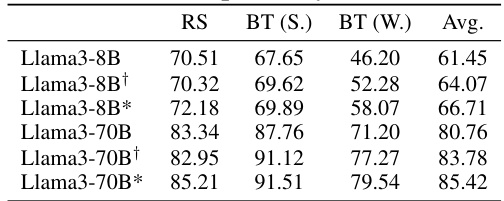
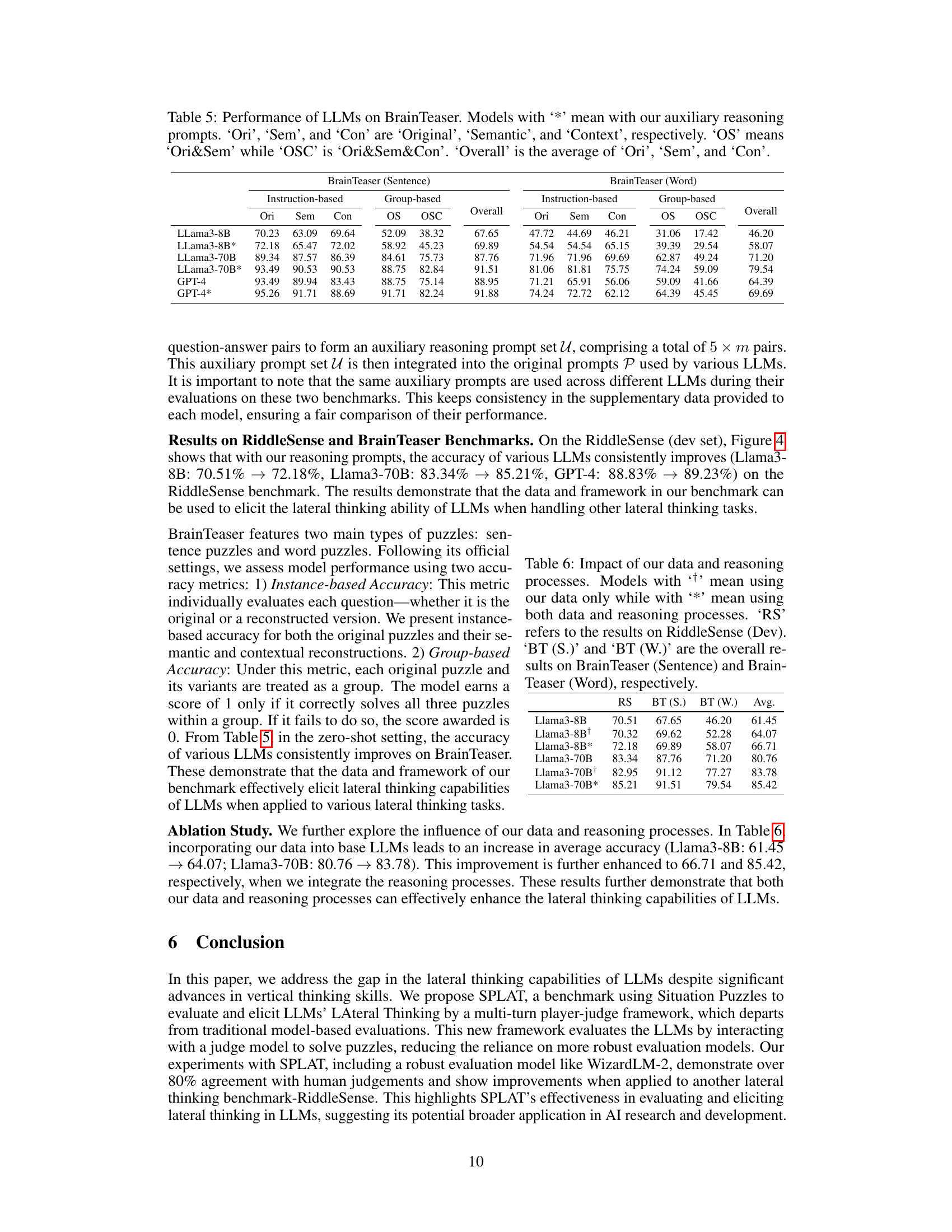
This table presents the results of applying the data and reasoning processes from the SPLAT benchmark to other lateral thinking benchmarks, RiddleSense and Brain Teaser. It compares the performance of Llama3 8B and 70B models under three conditions: 1. Original (no data or reasoning processes applied) 2. Using only the SPLAT data 3. Using both the SPLAT data and reasoning processes. The results show that incorporating both the data and reasoning processes improves performance across all benchmarks and models.
Full paper#