TL;DR#
Semantic segmentation models struggle when faced with real-world data exhibiting both domain (covariate) and semantic shifts. Existing methods often fail to distinguish between these types, resulting in poor out-of-distribution detection or domain generalization. This research tackles this problem.
The proposed solution uses a novel generative augmentation method to create diverse training images incorporating both types of shifts at the image and object levels. It also introduces a training strategy that recalibrates uncertainty for semantic shifts and aligns features associated with domain shifts. This approach allows the model to generalize to covariate shifts while accurately detecting semantic shifts.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical need for robust semantic segmentation models that can handle real-world scenarios with multiple distribution shifts. Current models often fail in such situations, and this research provides a significant step towards creating more reliable and adaptable systems for various applications like autonomous driving. The methods introduced, especially the novel data augmentation and uncertainty recalibration techniques, offer valuable insights and tools for researchers in computer vision and related fields.
Visual Insights#
🔼 This figure illustrates the core idea of the paper. It shows that existing methods struggle to distinguish between domain shifts (changes in background, lighting, etc.) and semantic shifts (appearance of new objects). The authors’ method is designed to handle both types of shifts by effectively generating training data with both, and it improves performance in both out-of-distribution detection and domain generalization.
read the caption
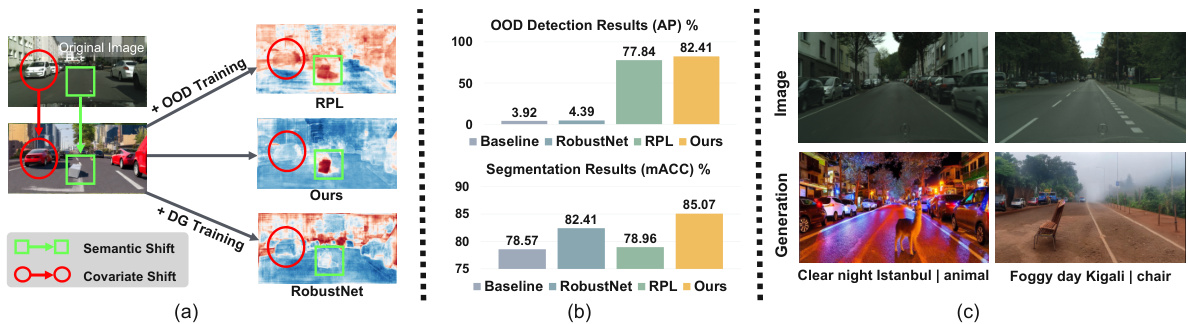
Figure 1: We study semantic segmentation with both semantic-shift and covariate-shift regions. (a) Training for Out-of-distribution (OOD) detection alone [31] yields high uncertainty for both types of shifts, whereas training for domain generalization (DG) alone [9] tends to produce low uncertainty for both. Our method effectively differentiates between the two, generating high uncertainty only for semantic-shift regions. (b) We achieve strong performance in both OOD detection and domain-generalized semantic segmentation. (c) This is achieved by coherently augmenting original images (first row) with both covariate and semantic shifts (second row).
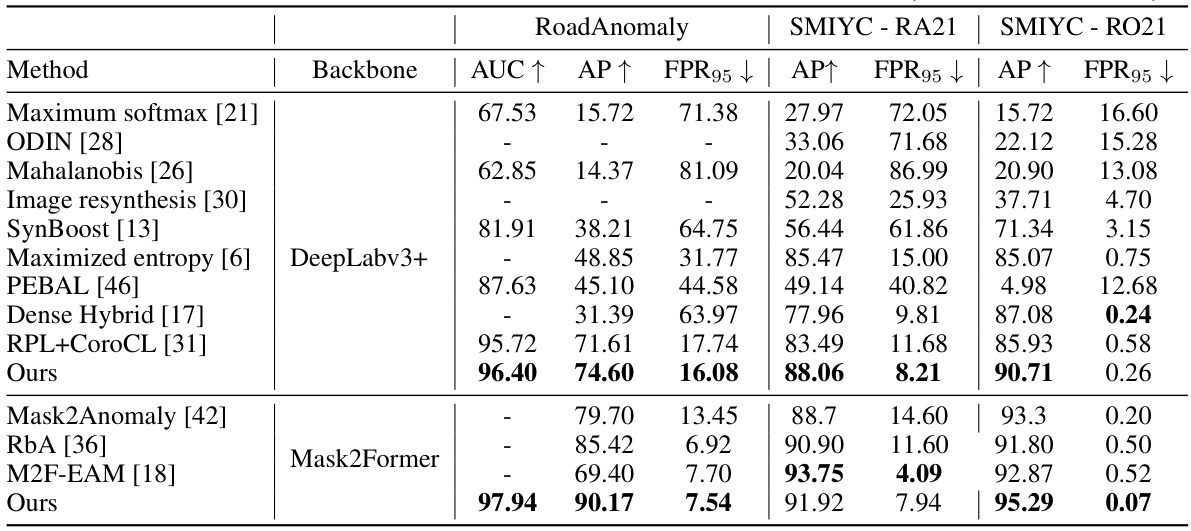
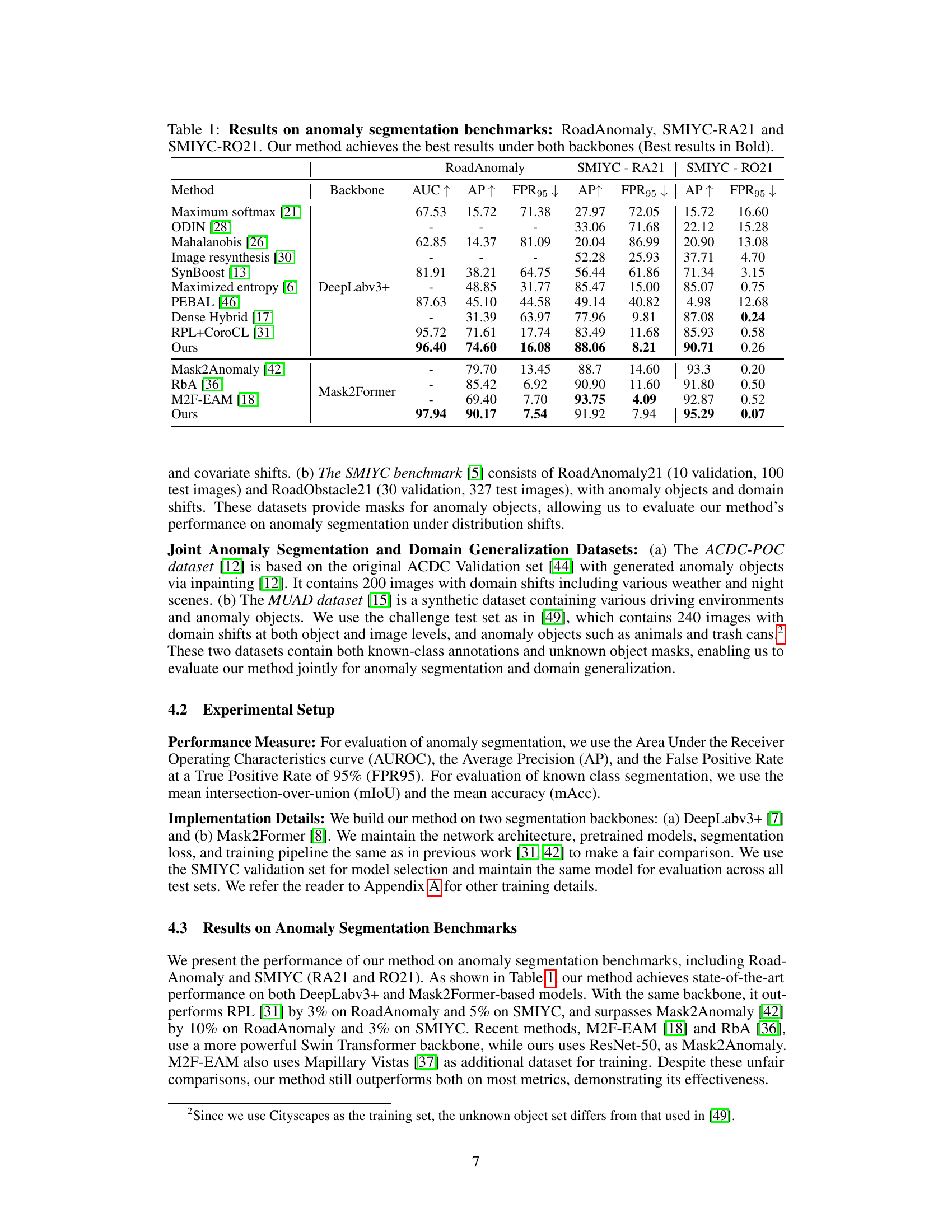
🔼 This table presents the results of anomaly segmentation experiments on three benchmark datasets: RoadAnomaly, SMIYC-RA21, and SMIYC-RO21. The results are shown for several different methods, including the authors’ proposed method. Metrics include AUC, Average Precision (AP), and False Positive Rate at 95% (FPR95). The table is broken down by backbone used (DeepLabv3+ and Mask2Former), allowing for comparison across different architectures. The authors’ method consistently outperforms other methods across all benchmarks and backbones.
read the caption
Table 1: Results on anomaly segmentation benchmarks: RoadAnomaly, SMIYC-RA21 and SMIYC-RO21. Our method achieves the best results under both backbones (Best results in Bold).
In-depth insights#
Multi-Shift Seg#
The concept of “Multi-Shift Seg” suggests a robust semantic segmentation model designed to handle multiple distribution shifts simultaneously. This is a significant advancement over existing methods that typically address either domain adaptation (covariate shift) or anomaly detection (semantic shift) separately. A key challenge addressed is the ability to differentiate between these types of shifts to avoid misinterpreting covariate changes as semantic anomalies. The proposed solution likely incorporates novel data augmentation techniques to generate diverse training samples encompassing both types of shifts. This, in combination with a refined uncertainty calibration mechanism that differentiates semantic from domain shifts, would allow the model to generalize well to new domains while accurately detecting novel objects. The effectiveness of this approach hinges on coherent data augmentation and effective model training strategies. The success of “Multi-Shift Seg” would demonstrate a significant improvement in the robustness of semantic segmentation in open-world scenarios where both novel objects and environmental changes are common.
Gen Augment#
Generative augmentation, or ‘Gen Augment’, is a crucial technique in addressing the challenges of semantic segmentation under distribution shifts. It aims to enrich training data with both covariate and semantic shifts, thereby enabling models to distinguish between these different types of shifts and enhancing generalization and anomaly detection capabilities. The core idea lies in generating realistic and diverse synthetic data that incorporates both image-level variations (covariate shifts) and object-level changes (semantic shifts) such as new objects and changes in attributes. This is achieved through a coherent generation pipeline, often involving semantic-to-image translation models, producing more natural data augmentation than simple rule-based methods. Careful filtering of generated images to remove low-quality or inaccurate augmentations is also necessary for effective model training. A critical aspect of this technique lies in striking a balance between generating diverse shifts to increase robustness and maintaining data fidelity to avoid introducing noise or artifacts that could negatively impact model training and performance. The success of Gen Augment hinges on its ability to create meaningful augmentations that reflect the complexity of real-world distribution shifts while simultaneously minimizing the negative effects of synthetically created data.
Uncertainty Recal#
The concept of ‘Uncertainty Recal’ in a research paper likely revolves around recalibrating or refining the uncertainty estimates produced by a model. This is crucial in scenarios where initial uncertainty measures might be inaccurate, unreliable, or not properly reflect the model’s confidence. A key aspect would be how recalibration is achieved, perhaps using techniques like temperature scaling, Platt scaling, or more sophisticated methods tailored to the specific model and task. The paper likely demonstrates the impact of uncertainty recalibration on downstream tasks, such as anomaly detection or out-of-distribution generalization. Improved uncertainty estimates enhance performance by leading to more reliable predictions and better identification of uncertain regions, particularly important in safety-critical applications. The success of ‘Uncertainty Recal’ would be judged by its effectiveness in improving the model’s calibration, reducing false positives and negatives, and ultimately leading to more robust decision-making based on the model’s output.
Two-Stage Training#
The paper proposes a novel two-stage training strategy to enhance the model’s ability to distinguish between semantic and covariate shifts. The first stage focuses on recalibrating the uncertainty function, training it separately to specifically enhance sensitivity to semantic shifts while maintaining invariance to covariate changes. This is achieved using a relative contrastive loss, which encourages higher uncertainty for semantic shifts compared to known-class regions with covariate shifts. The second stage fine-tunes the entire model, including the feature extractor, integrating both the relative contrastive loss and the standard segmentation loss. This two-stage approach effectively balances the integration of the uncertainty function and feature learning, preventing interference and improving overall performance. This strategy proves highly effective in differentiating between the two types of shifts, ultimately leading to state-of-the-art performance in both anomaly detection and domain generalization tasks.
Ablation Studies#
Ablation studies systematically assess the contribution of individual components within a machine learning model. By removing or altering parts of the model, researchers can isolate the effects of specific features, techniques, or hyperparameters. This helps determine which aspects are crucial for achieving strong performance and which may be redundant or even detrimental. A well-designed ablation study provides valuable insights into the model’s architecture and its internal workings, allowing for targeted improvements and a deeper understanding of the underlying mechanisms. Careful selection of components to ablate is essential for drawing meaningful conclusions. The results should clarify the role each part plays, identifying strengths and weaknesses. Ultimately, ablation studies improve model interpretability and facilitate the design of more effective and efficient models by focusing resources on the most important components. They also help validate design choices and reveal any unforeseen interactions between different parts of the system.
More visual insights#
More on figures
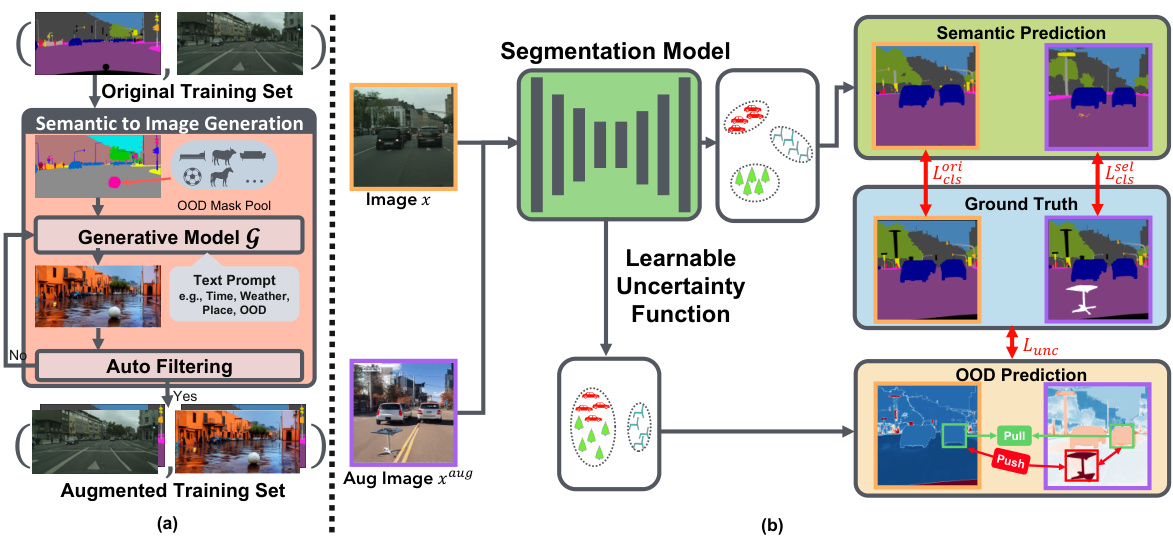
🔼 This figure illustrates the method overview of the proposed approach. The left side (a) shows the data augmentation strategy using a generative model to create images with both covariate and semantic shifts. The right side (b) shows the two-stage training process that refines the uncertainty function and features of the segmentation model. The two stages work in concert to enable the model to differentiate between covariate and semantic shifts. The resulting model generates high uncertainty for semantic shifts and low uncertainty for covariate shifts.
read the caption
Figure 2: Method Overview: (a) A novel generative-based data augmentation strategy that supplements training data with both covariate and semantic shifts in a coherent manner. (2) A semantic-exclusive uncertainty function with two-stage noise-aware training to encourage invariant feature learning for covariate-shift regions while maintaining high uncertainty for semantic-shift regions.

🔼 This figure compares uncertainty maps generated by the proposed method and the baseline method (RPL) across various datasets with both semantic and domain shifts. It demonstrates the ability of the proposed method to accurately identify semantic shifts (anomalies) while being robust to covariate shifts, unlike the baseline.
read the caption
Figure 3: Comparison of Uncertainty Maps. Our method robustly detects anomalies under covariate shifts across five datasets (first five columns) and generated data (last column). The previous method RPL [31] failed to distinguish domain from semantic shifts, producing high uncertainty in both cases. In Fig. 3, we visualize the uncertainty map output by our method using the DeepLabv3+ architecture. Compared to the previous state-of-the-art method, RPL [31], our model assigns higher uncertainty scores to anomalous objects and lower uncertainty scores to covariate shifts. This highlights the efficacy of our method in distinguishing between domain shifts and semantic shifts.

🔼 This figure shows a schematic overview of the proposed method. The left side (a) details a novel generative data augmentation strategy to create images with both covariate and semantic shifts. The right side (b) illustrates a semantic-exclusive uncertainty function used in a two-stage noise-aware training process. The goal is to learn a model that differentiates between the two types of shifts and responds appropriately to each.
read the caption
Figure 4: Method Overview: (a) A novel generative-based data augmentation strategy that supplements training data with both covariate and semantic shifts in a coherent manner. (2) A semantic-exclusive uncertainty function with two-stage noise-aware training to encourage invariant feature learning for covariate-shift regions while maintaining high uncertainty for semantic-shift regions.

🔼 This figure compares uncertainty maps generated by the proposed method and a previous state-of-the-art method (RPL). It shows that the proposed method more accurately distinguishes between semantic shifts (anomalies) and covariate shifts (changes in image appearance) by assigning higher uncertainty to anomalies and lower uncertainty to covariate shifts. The visualization uses the DeepLabv3+ architecture.
read the caption
Figure 3: Comparison of Uncertainty Maps. Our method robustly detects anomalies under covariate shifts across five datasets (first five columns) and generated data (last column). The previous method RPL [31] failed to distinguish domain from semantic shifts, producing high uncertainty in both cases. In Fig. 3, we visualize the uncertainty map output by our method using the DeepLabv3+ architecture. Compared to the previous state-of-the-art method, RPL [31], our model assigns higher uncertainty scores to anomalous objects and lower uncertainty scores to covariate shifts. This highlights the efficacy of our method in distinguishing between domain shifts and semantic shifts.

🔼 This figure visualizes the generated images with both semantic and domain shifts. The first row shows the original images from the Cityscapes dataset. The second row displays the generated images, where novel objects are seamlessly integrated into the scenes with various covariate shifts (e.g., weather, lighting). The third row shows the selection maps used to calculate the cross-entropy loss during training. The fourth row displays the cross-entropy loss maps, highlighting the regions with high uncertainty scores. The captions below each column specify the weather conditions, time, and location prompts used to generate these images, along with the type of novel objects added.
read the caption
Figure 6: Visualization of Generated Images. Row 1: Original images from Cityscapes. Row 2: Generated images featuring both semantic and domain shifts. Row 3: Selection map used to calculate selected cross-entropy loss during training. Row 4: Cross-entropy loss map used to produce the selection map (excluding the OOD regions, which are not involved in known class segmentation loss calculation). Below each column, we display the weather, time, and location prompts that guide the model in generating diverse covariate shifts, along with the OOD prompts for object generation. Red boxes highlight generation errors.
More on tables
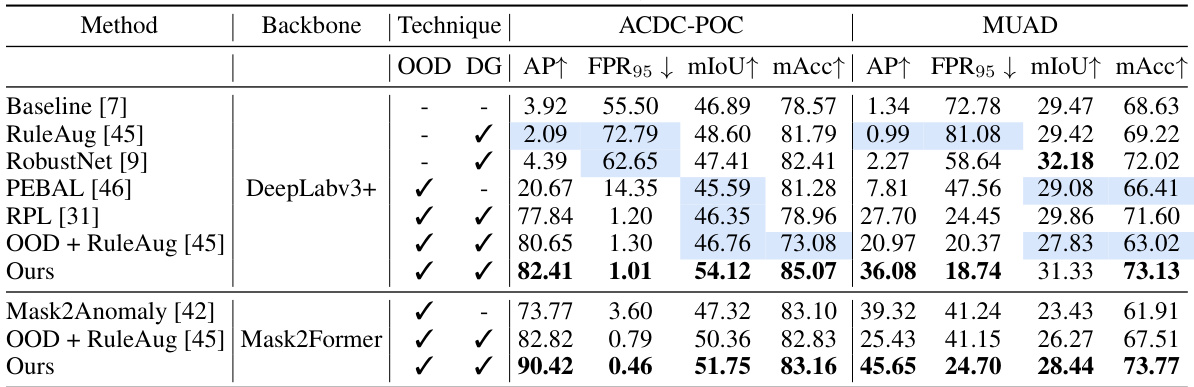
🔼 This table presents the results of the proposed method on two benchmark datasets, ACDC-POC and MUAD, evaluating both anomaly segmentation and domain generalization performance. It compares the method against various baselines, including those focused solely on OOD detection or domain generalization. The table highlights that the proposed method outperforms these baselines in both tasks, demonstrating its ability to effectively handle both semantic and domain shifts.
read the caption
Table 2: Results on ACDC-POC and MUAD. Our model achieves the best performance in both anomaly segmentation (AP↑, FPR↓ ) and domain-generalized segmentation (mIoU↑,mAcc↑ ). Anomaly segmentation methods typically perform worse than the baseline for known class segmentation, while domain generalization methods fall below the baseline on OOD detection. (Best results are in bold; results below baseline are in blue.)

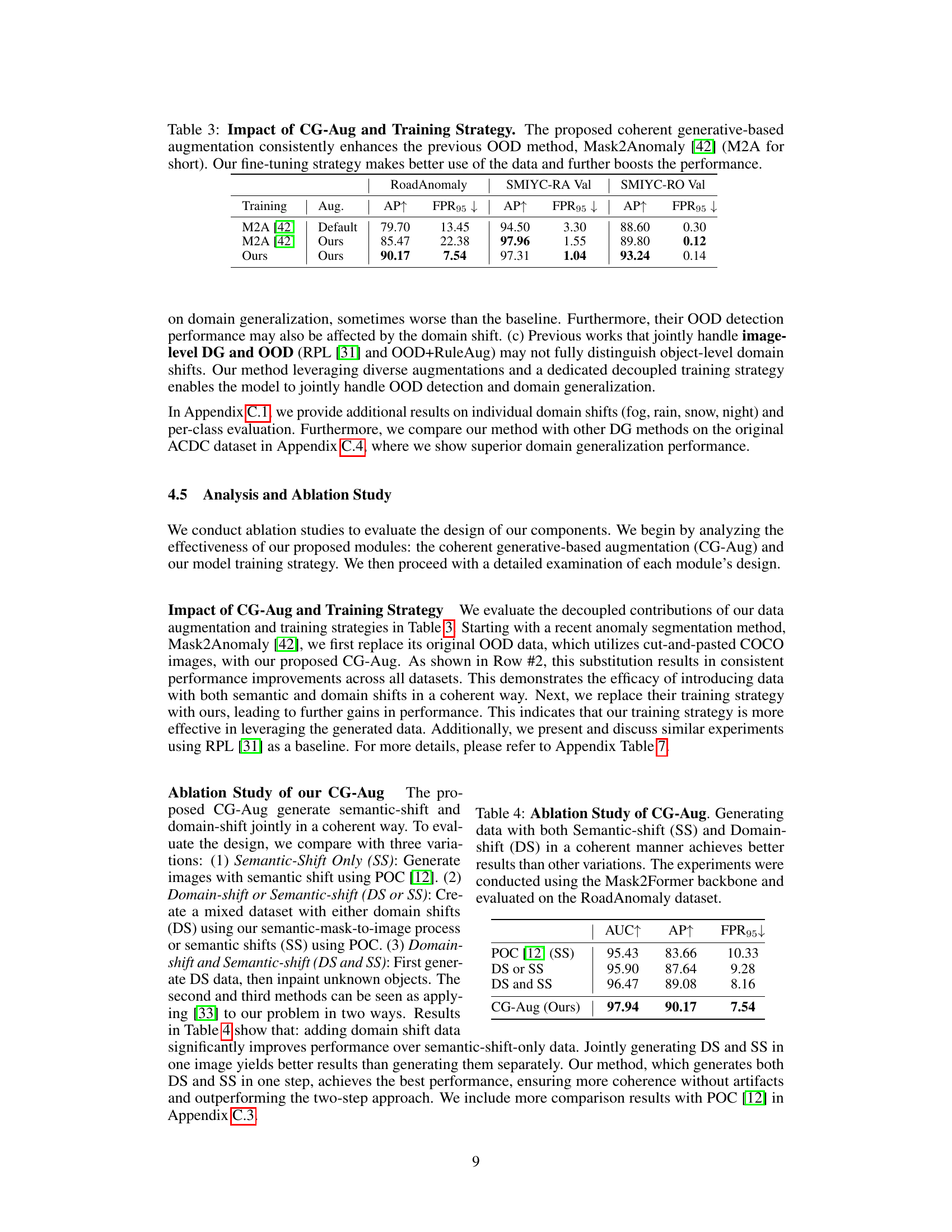
🔼 This table presents the results of an ablation study comparing the performance of three different training approaches on three different datasets. The first approach uses the default settings of the Mask2Anomaly method. The second approach replaces the default data augmentation with the proposed coherent generative-based augmentation (CG-Aug), and the third approach also incorporates the proposed two-stage training strategy. The results show that CG-Aug consistently improves performance, and that the two-stage training strategy further enhances the improvements.
read the caption
Table 3: Impact of CG-Aug and Training Strategy. The proposed coherent generative-based augmentation consistently enhances the previous OOD method, Mask2Anomaly [42] (M2A for short). Our fine-tuning strategy makes better use of the data and further boosts the performance.
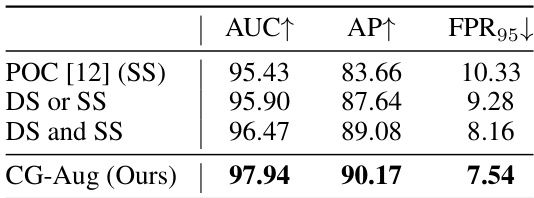
🔼 This table presents the ablation study of the coherent generative-based augmentation (CG-Aug) method. It compares the performance of generating data with only semantic shifts, only domain shifts, both semantic and domain shifts separately, and the proposed method that generates both shifts coherently. The results are evaluated on the RoadAnomaly dataset using the Mask2Former backbone and reported using AUC, AP, and FPR95 metrics.
read the caption
Table 4: Ablation Study of CG-Aug. Generating data with both Semantic-shift (SS) and Domain-shift (DS) in a coherent manner achieves better results than other variations. The experiments were conducted using the Mask2Former backbone and evaluated on the RoadAnomaly dataset.

🔼 This table presents the ablation study results on the effectiveness of different components in the proposed training pipeline. It shows the performance (AP↑, FPR95↓, mIoU↑, mAcc↑) on various datasets (SMIYC-RA Val, SMIYC-RO Val, MUAD, ACDC-POC) when different components (Learnable Uncertainty Function, Relative Contrastive Loss, and Noise-aware Sample Selection) are included or excluded. The results demonstrate the importance of each component in achieving good performance.
read the caption
Table 5: Abaltion Study of Our Training Pipeline: Learnable Uncertainty Function (Learnable-UF), Relative Contrastive Loss (RelConLoss), and Noise-aware Sample Selection (Selection). Experiments are conducted under DeepLabv3+ architecture.

🔼 This table presents an ablation study analyzing the impact of different loss margin values on the model’s performance. It shows that the model is robust to variations in margin scales. The results are reported using the Average Precision (AP), False Positive Rate (FPR) metrics from SMIYC-RA validation set and Mean Intersection over Union (mIoU) from MUAD dataset. The experiments were conducted using the DeepLabv3+ architecture.
read the caption
Table 6: Impact of Loss Margins. We examine model robustness across various loss margins by evaluating margin scale impacts in (a) and analyzing effects of individual margins in (b) and (c). Results are reported on SMIYC-RA Val(AP & FPR) and MUAD (mIoU) using the DeepLabv3+ architecture.
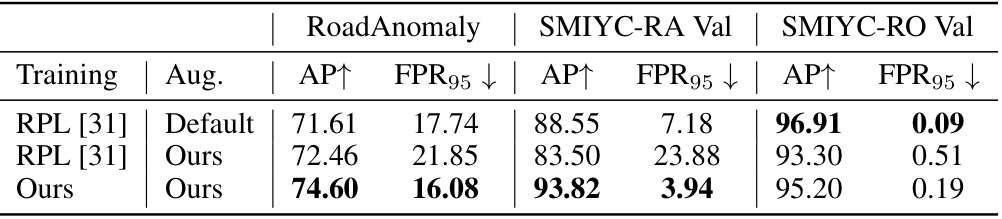
🔼 This table presents the ablation study results on the impact of the proposed coherent generative-based augmentation (CG-Aug) and the two-stage training strategy on the anomaly segmentation performance. It shows that CG-Aug consistently improves the baseline method (Mask2Anomaly), and the two-stage training further enhances the performance, indicating the effectiveness of both components.
read the caption
Table 3: Impact of CG-Aug and Training Strategy. The proposed coherent generative-based augmentation consistently enhances the previous OOD method, Mask2Anomaly [42] (M2A for short). Our fine-tuning strategy makes better use of the data and further boosts the performance.

🔼 This table presents the results of anomaly segmentation experiments conducted on three different benchmarks: RoadAnomaly, SMIYC-RA21, and SMIYC-RO21. The results are shown in terms of AUC, AP, and FPR95 metrics. Two different backbones, DeepLabv3+ and Mask2Former, were used for the experiments. The table highlights that the proposed method achieves state-of-the-art performance across all benchmarks and backbones.
read the caption
Table 1: Results on anomaly segmentation benchmarks: RoadAnomaly, SMIYC-RA21 and SMIYC-RO21. Our method achieves the best results under both backbones (Best results in Bold).
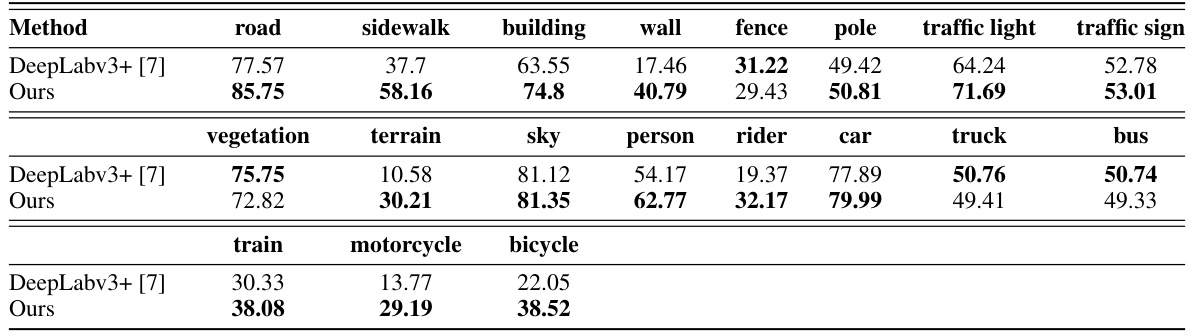
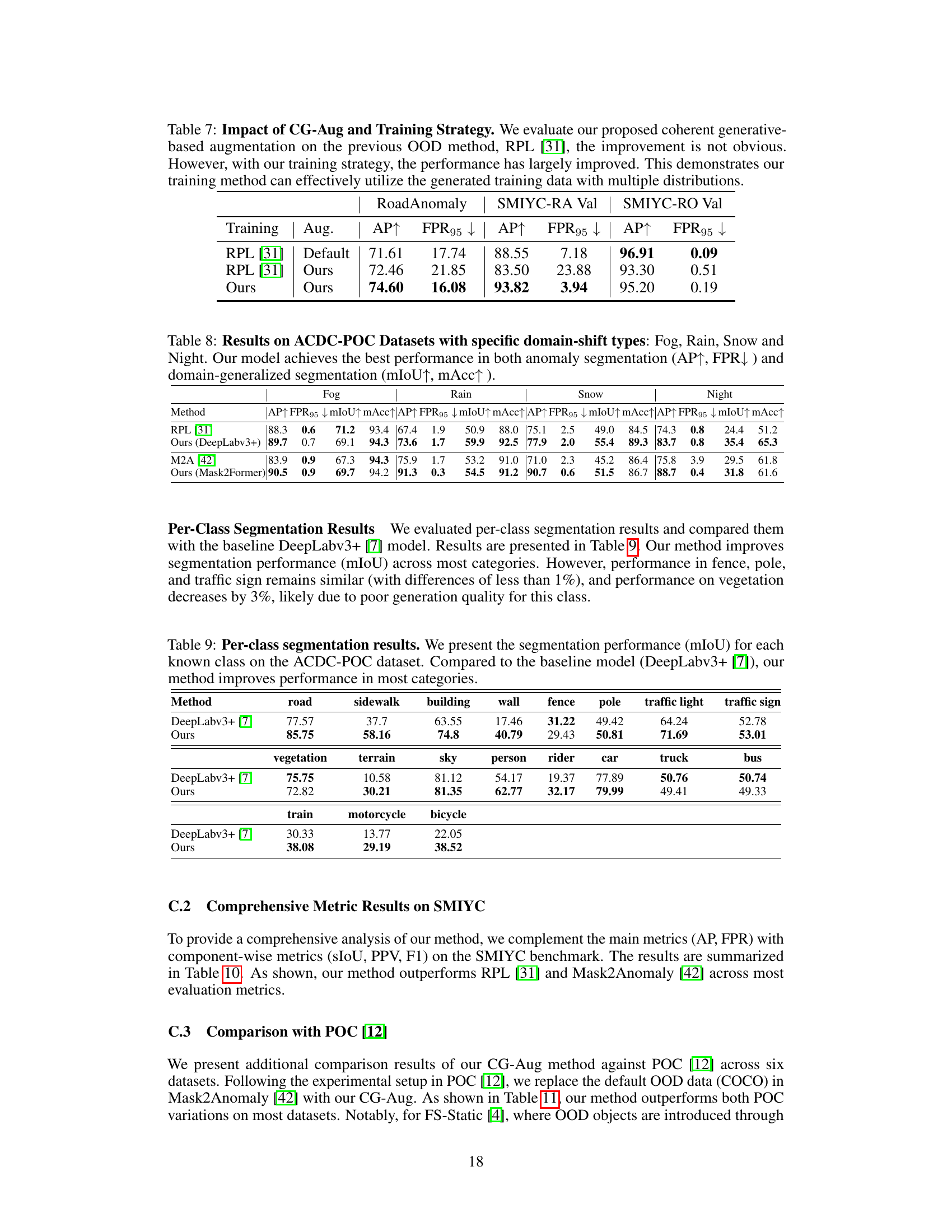
🔼 This table shows a comparison of the mean Intersection over Union (mIoU) for different semantic classes in the ACDC-POC dataset between the proposed method and the DeepLabv3+ baseline. It demonstrates the per-class performance gains achieved by the proposed method, showing improvements across various classes with a few exceptions.
read the caption
Table 9: Per-class segmentation results. We present the segmentation performance (mIoU) for each known class on the ACDC-POC dataset. Compared to the baseline model (DeepLabv3+ [7]), our method improves performance in most categories.

🔼 This table presents the performance comparison of different anomaly segmentation methods on three benchmark datasets: RoadAnomaly, SMIYC-RA21, and SMIYC-RO21. The results are shown in terms of AUC, Average Precision (AP), and False Positive Rate at 95% recall (FPR95). The table highlights that the proposed method achieves state-of-the-art results using both DeepLabv3+ and Mask2Former backbones.
read the caption
Table 1: Results on anomaly segmentation benchmarks: RoadAnomaly, SMIYC-RA21 and SMIYC-RO21. Our method achieves the best results under both backbones (Best results in Bold).

🔼 This table presents the results of the proposed method and other state-of-the-art anomaly segmentation methods on three benchmarks: RoadAnomaly, SMIYC-RA21, and SMIYC-RO21. The performance is evaluated using metrics such as AUC, AP, and FPR95. The table shows that the proposed method achieves the best performance across all three benchmarks, outperforming existing methods regardless of the backbone network (DeepLabv3+ or Mask2Former) used.
read the caption
Table 1: Results on anomaly segmentation benchmarks: RoadAnomaly, SMIYC-RA21 and SMIYC-RO21. Our method achieves the best results under both backbones (Best results in Bold).
🔼 This table presents the results of the proposed method on two benchmark datasets, ACDC-POC and MUAD, comparing its performance in anomaly segmentation and domain generalization against baseline and other state-of-the-art methods. It highlights the method’s superior performance in both tasks, showcasing its ability to effectively differentiate between semantic and covariate shifts. The table also demonstrates the limitations of existing techniques that focus solely on either anomaly detection or domain generalization.
read the caption
Table 2: Results on ACDC-POC and MUAD. Our model achieves the best performance in both anomaly segmentation (AP↑, FPR↓ ) and domain-generalized segmentation (mIoU↑,mAcc↑ ). Anomaly segmentation methods typically perform worse than the baseline for known class segmentation, while domain generalization methods fall below the baseline on OOD detection. (Best results are in bold; results below baseline are in blue.)
Full paper#