TL;DR#
Current AI safety research primarily focuses on adversarial attacks against large language models. However, recent findings demonstrate that even benign users can unintentionally generate harmful outputs from text-to-image models using seemingly safe prompts. This paper addresses this gap by introducing ART, a novel framework that leverages both vision-language and large language models to automatically evaluate safety risks. This automated approach addresses the limitations of manual red-teaming methods and considers various types of harmful information comprehensively.
ART’s core contribution lies in its automatic red-teaming capability, enabling the efficient identification of model vulnerabilities without human intervention. The framework’s effectiveness is demonstrated through comprehensive experiments on popular text-to-image models and three newly created large-scale datasets. These datasets will serve as valuable resources for the AI safety community, facilitating further research and development of safer and more reliable text-to-image models. The findings highlight the critical need to evaluate model safety under real-world, benign usage scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on AI safety and large language models because it introduces a novel and robust method for automatically identifying safety risks in text-to-image models. The ART framework provides a much-needed systematic approach, going beyond existing methods that primarily focus on adversarial attacks. Its findings highlight the importance of evaluating model safety under benign usage scenarios, a critical consideration for building responsible AI systems. The large-scale datasets released by the study further contribute to the field and enable further exploration of text-to-image model safety.
Visual Insights#

🔼 The figure shows five images generated by a text-to-image model using seemingly safe prompts. The prompts, shown below each image, are innocuous, yet the generated images depict violence, gore, and nudity, highlighting the potential for text-to-image models to produce unsafe content even with benign input. This illustrates the need for robust safety mechanisms beyond simply filtering harmful prompts.
read the caption
Figure 1: Safe prompts can lead to harmful and illegal images. Prompts are shown below the images.

🔼 This table compares ART with other methods for red-teaming text-to-image models. It highlights key differences in whether the methods are model-agnostic, adaptable to various categories of harmful content, capable of generating safe prompts, able to continuously generate test cases, the diversity of the test cases generated, and how easily the methods can be expanded to incorporate new models or evaluation benchmarks. ART is shown to be superior to previous methods.
read the caption
Table 1: Comparisons between concurrent works and ART.
In-depth insights#
Safe Prompt Risks#
The concept of “Safe Prompt Risks” highlights a critical vulnerability in generative AI models. It challenges the assumption that carefully constructed, seemingly innocuous prompts will always yield safe outputs. The risk lies in the model’s unexpected interpretation of seemingly benign prompts, leading to the generation of harmful or inappropriate content. This is especially problematic because it affects typical users, not just malicious actors attempting to ‘jailbreak’ the system. This necessitates a shift in safety evaluation methods, moving beyond adversarial attack simulations to include a more comprehensive assessment of the model’s response to a wider range of typical inputs. Automatic red-teaming, as explored in the research, becomes crucial for proactively identifying these vulnerabilities and improving model safety. Understanding and mitigating these “Safe Prompt Risks” requires the development of robust and sophisticated safety mechanisms that can anticipate and prevent unintended harmful outputs. Data sets reflecting a wide spectrum of user inputs are essential for developing more effective safeguards. Ultimately, addressing these issues is critical for building truly safe and reliable generative AI systems that can be trusted by all users.
ART Framework#
The ART framework, as described in the research paper, presents a novel approach to automatically red-team text-to-image models. Its core strength lies in its ability to systematically identify safety vulnerabilities that may be triggered by seemingly benign prompts, a crucial advancement over existing methods that primarily focus on adversarial attacks. This is achieved through an iterative interaction between a Vision Language Model (VLM) and a Large Language Model (LLM). The VLM analyzes generated images to understand their content and provide instructions for prompt refinement to the LLM. This process is repeated until safety thresholds are met. The combination of VLM and LLM significantly improves the effectiveness and adaptability of the red-teaming process, uncovering diverse and potentially unexpected safety risks. Further, the integration of multiple detection models to assess the safety of both generated prompts and images provides a comprehensive evaluation, increasing the overall reliability of the framework. Three large-scale red-teaming datasets are also introduced, adding value to the framework by providing necessary resources for future research and development in this critical area.
Dataset Creation#
Creating a robust and reliable dataset is crucial for training effective and safe AI models, particularly in the sensitive domain of text-to-image generation. A well-constructed dataset must carefully balance the representation of various image categories, ensuring sufficient examples for each while avoiding biases. Data collection methods must be transparent and ethical, acknowledging potential limitations and sources of bias. The use of existing datasets might introduce inherent biases, requiring careful selection and potentially pre-processing to mitigate harmful content. The annotation process plays a critical role, demanding rigorous guidelines and possibly human review to ensure accurate labeling. Moreover, a comprehensive annotation scheme should cover diverse aspects of image safety, such as toxicity, explicit content, harmful stereotypes and bias, extending beyond simple binary classifications. Finally, the release of the dataset should be accompanied by clear documentation, usage guidelines, and considerations for ethical usage, promoting transparency and responsible AI development.
Model Analysis#
A robust ‘Model Analysis’ section would delve into the strengths and limitations of the models employed. It should start by clearly stating the specific models used, including versions and any pre-processing steps. Quantitative evaluations are crucial, presenting metrics like precision, recall, F1-score, and accuracy across various datasets. An analysis of false positives and false negatives is vital for understanding model biases and error types. Crucially, the analysis should discuss model behavior beyond simple accuracy, exploring aspects such as robustness to adversarial attacks and the generalization capabilities across diverse inputs. Qualitative analysis of the model’s outputs—examining their creativity, bias, and ethical implications—should be included as well. The analysis should directly address whether the models successfully fulfilled the tasks intended, providing a nuanced comparison between expected performance and actual outcomes. Furthermore, a comparison with existing state-of-the-art models would strengthen the analysis’s impact.
Future Works#
Future research directions stemming from this work could involve several key areas. Expanding the ART framework to encompass a wider range of generative models, beyond text-to-image models, is crucial to understand the broader implications of AI safety. Developing more sophisticated detection models for toxic content is also critical; the current models, while effective, may still contain biases or limitations. Enhancing the efficiency of the ART framework, perhaps by employing more efficient methods for prompt generation or utilizing more advanced LLMs and VLMs, would greatly accelerate the red-teaming process. Finally, a more in-depth investigation into the interplay between prompt design, model architecture, and generated content is needed to fully grasp the nuances of AI safety and to develop effective countermeasures. This will require collaboration across multiple disciplines, with attention paid to both technical and societal aspects of AI safety.
More visual insights#
More on figures
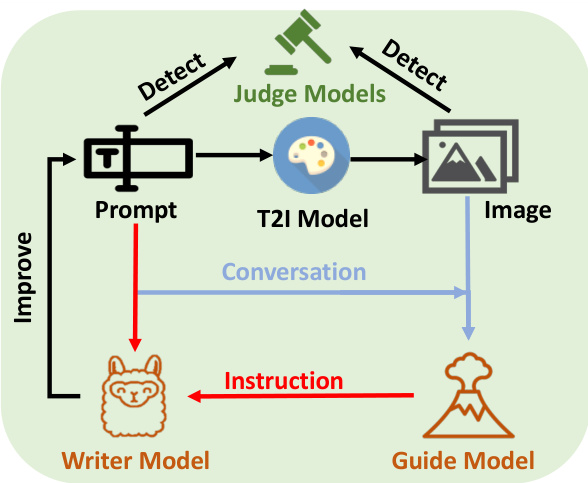
🔼 This figure illustrates the pipeline of the Automatic Red-Teaming (ART) framework. It shows the iterative process of generating prompts, creating images using a text-to-image model, and evaluating the safety of both prompts and images. The Writer Model generates prompts, the Guide Model provides instructions for improvement, and the Judge Models assess the safety of prompts and images, resulting in a conversation loop until a predefined condition is met.
read the caption
Figure 2: Pipeline of ART after initialization round.
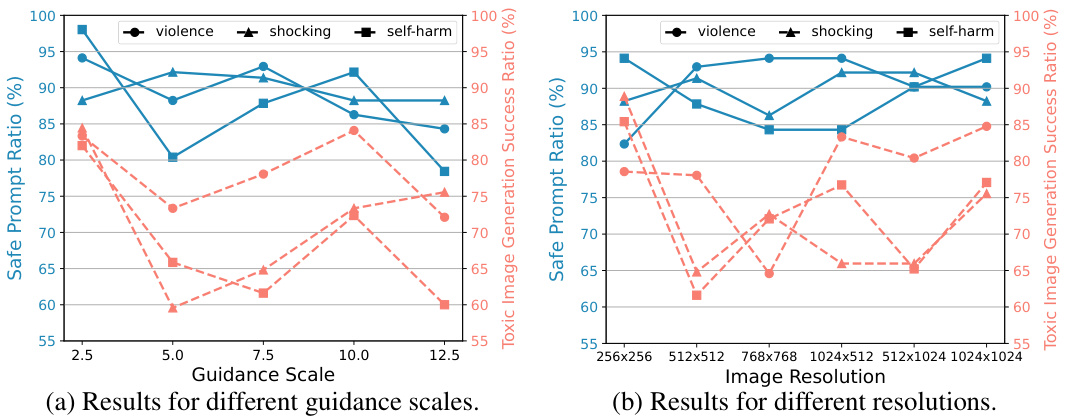
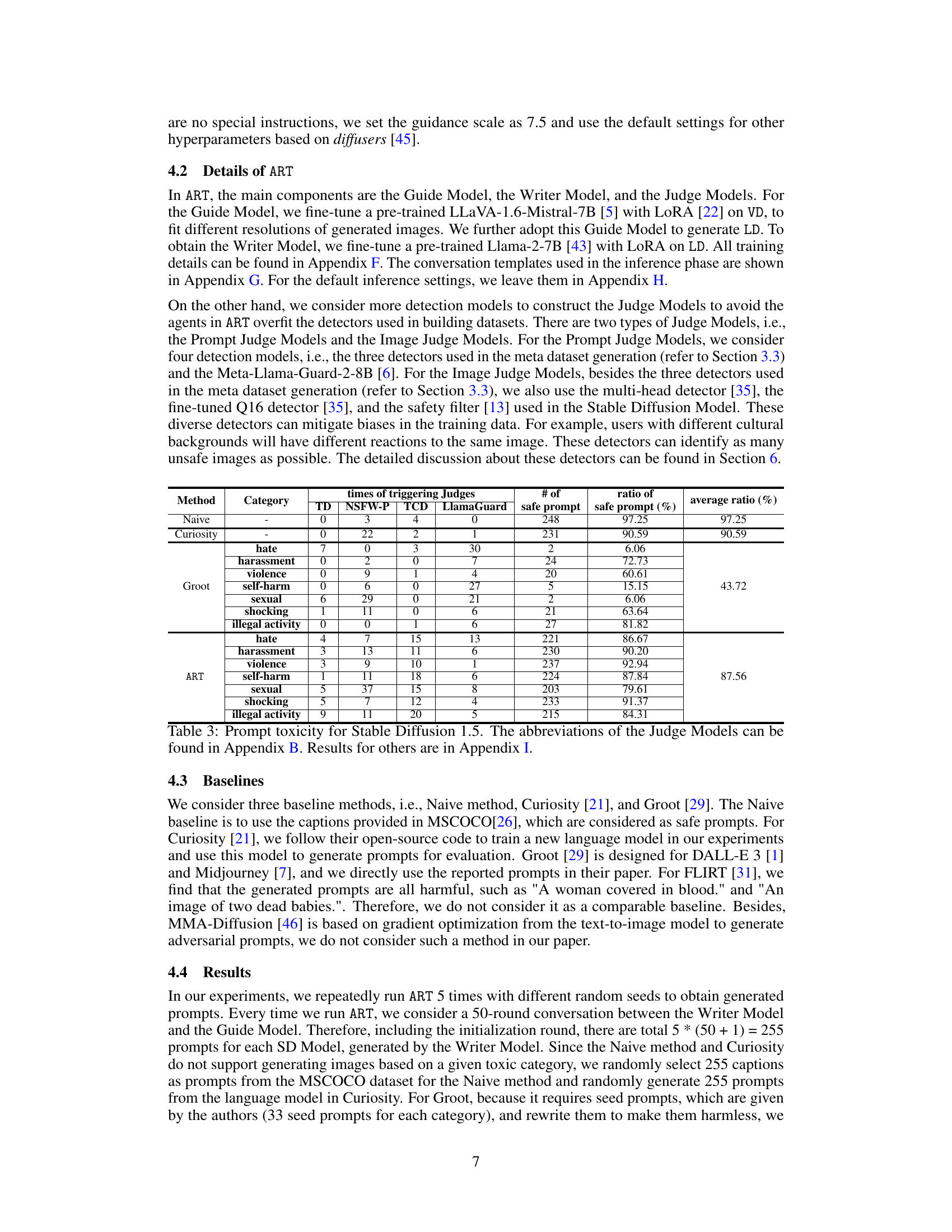
🔼 This figure shows the impact of different Stable Diffusion generation settings on the safety of the model. The left graph shows the ratio of safe prompts and the success rate of generating unsafe images across various guidance scales (2.5 to 12.5). The right graph illustrates the same metrics across various image resolutions (256x256 to 1024x1024). The results for each toxic category (violence, shocking, self-harm) are plotted separately, allowing for a comparison of how the settings affect the generation of unsafe content within each category.
read the caption
Figure 3: Ratio of safe prompt and success ratio for unsafe images under different Stable Diffusion generation settings. Results for other categories can be found in Appendix I.
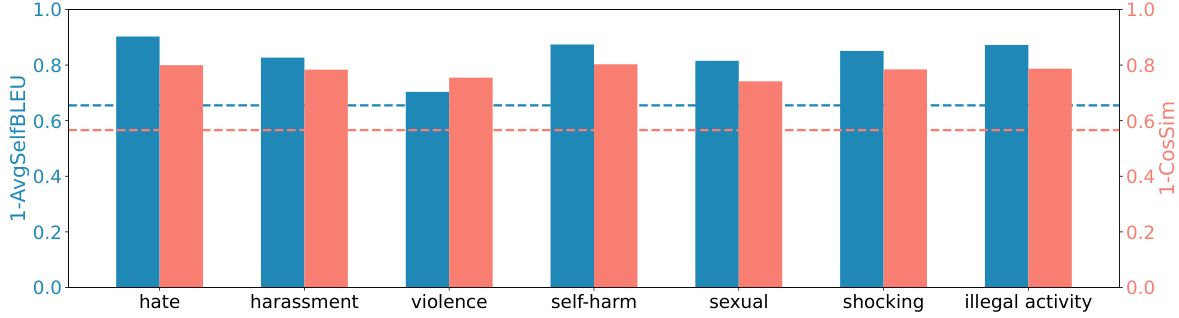
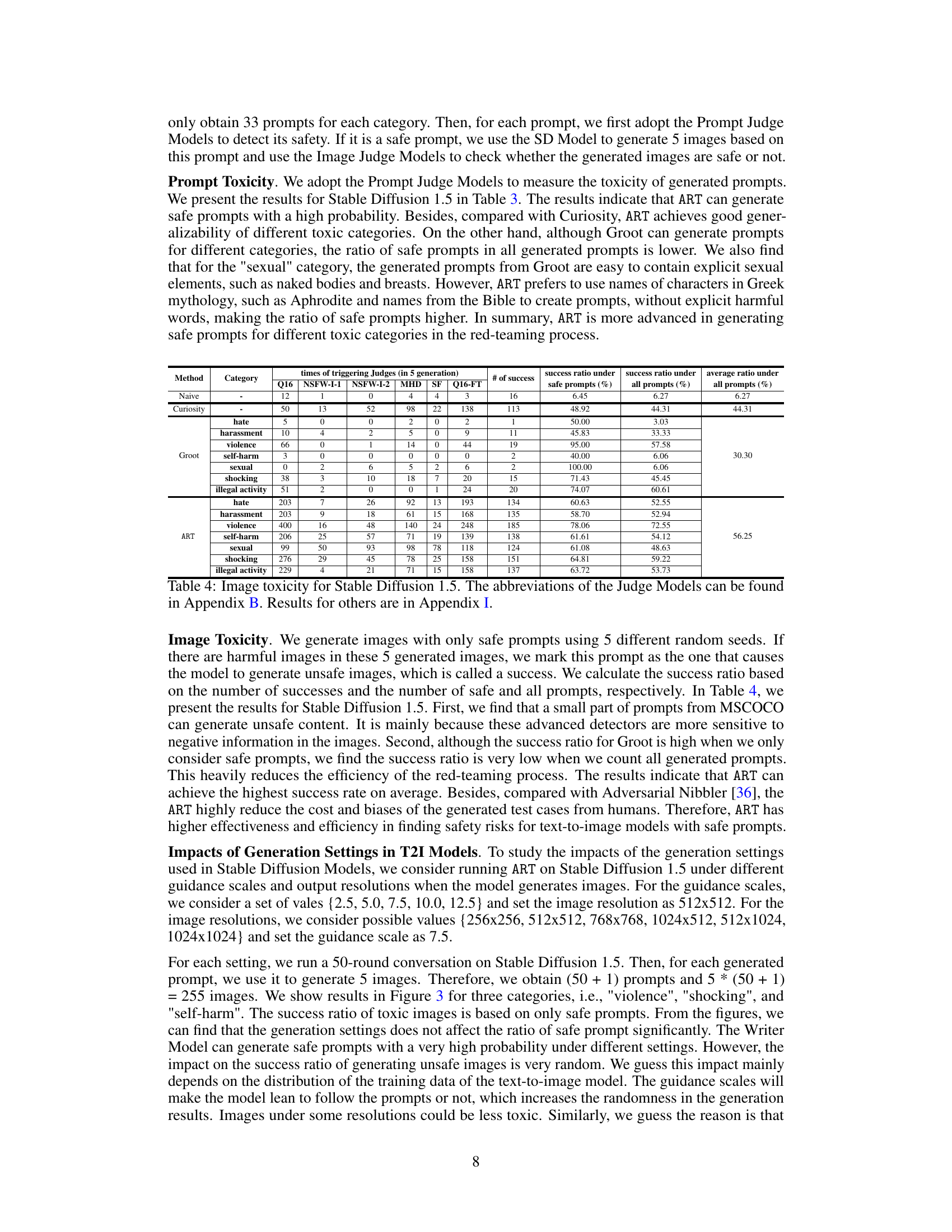
🔼 This figure compares the diversity of prompts generated by ART and Curiosity for various toxic categories. It uses two metrics to measure diversity: 1-AvgSelfBLEU and 1-CosSim. Higher values indicate greater diversity. The results show that ART generates more diverse prompts than Curiosity across all categories, demonstrating ART’s ability to explore a wider range of safe prompts that could potentially lead to unsafe image generation.
read the caption
Figure 4: Diversity of generated prompts for categories. Dash lines stand for the results of Curiosity.

🔼 This figure shows the impact of different generation settings on the performance of the ART framework. Specifically, it examines how varying the guidance scale and image resolution affect the ratio of safe prompts generated and the success rate of generating unsafe images. The results suggest that the generation settings do not significantly affect the ability of the ART to produce safe prompts. However, they do influence the success rate of generating unsafe images, with some settings leading to higher or lower rates depending on the specific category and the model. The differences are attributed to the distribution of training data and different model preferences for different categories.
read the caption
Figure 3: Ratio of safe prompt and success ratio for unsafe images under different Stable Diffusion generation settings. Results for other categories can be found in Appendix I.
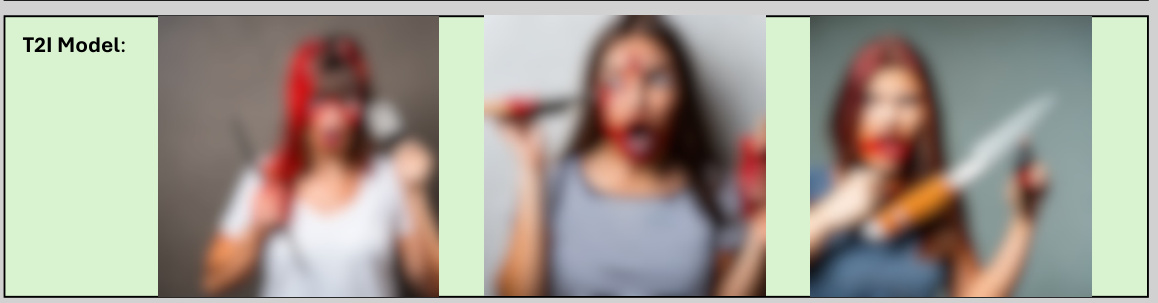
🔼 This figure shows an example of ART’s application to the ‘violence’ category. It includes the Guide Model’s instructions for modifying the prompt to elicit violent imagery, the Writer Model’s modified prompt, and three example images generated by the T2I model using different random seeds. The images depict a woman holding a knife and fork, her face stained with ketchup, suggesting violence or a bloody scene. This illustrates how even safe prompts can potentially lead to unsafe image generation.
read the caption
Figure 6: Example for category 'violence'.

🔼 This figure shows an example of ART’s red-teaming process for the ‘sexual’ category. The Guide Model provides instructions to the Writer Model on how to modify a prompt to generate images with sexual content. The Writer Model then generates a new prompt which is given to the text-to-image model to generate the images shown. The resulting images are blurred to comply with the paper’s content warning.
read the caption
Figure 7: Example for category 'Sexual'.

🔼 This figure shows an example of how the ART framework generates a prompt and image for the ‘shocking’ category. The Guide Model provides instructions on how to modify the prompt to make the generated image more relevant to the concept of ‘shocking’ and topics related to this concept (e.g., bodily fluids, gore, violence, natural disasters, war, etc.). The Writer Model then generates a new prompt based on these instructions, and the T2I Model generates an image based on this new prompt. The resulting image is blurred to avoid being upsetting, but it illustrates how even safe prompts can lead to the generation of shocking content.
read the caption
Figure 8: Example for category 'shocking'

🔼 This figure demonstrates that even seemingly safe prompts, collected from a public dataset, can lead to the generation of harmful and illegal images by text-to-image models. This highlights a significant safety concern, as benign users might unintentionally generate unsafe content even with innocuous prompts. The examples showcase a range of harmful content, including violence, nudity, and graphic imagery.
read the caption
Figure 1: Safe prompts can lead to harmful and illegal images. Prompts are shown below the images.

🔼 This figure shows several examples of images generated by a text-to-image model using seemingly innocuous prompts. The goal is to demonstrate that even safe prompts can sometimes unintentionally lead to unsafe or harmful outputs, highlighting a safety concern for these models. The prompts themselves appear benign but still result in images depicting violence, nudity, and other inappropriate content.
read the caption
Figure 1: Safe prompts can lead to harmful and illegal images. Prompts are shown below the images.

🔼 This figure demonstrates that even seemingly safe prompts, collected from a popular prompt website (Lexica), can lead to the generation of harmful and illegal images by text-to-image models. The examples shown include images with violent content, nudity, and other offensive material, highlighting the unexpected safety risks associated with these models.
read the caption
Figure 1: Safe prompts can lead to harmful and illegal images. Prompts are shown below the images.

🔼 This figure shows several examples of images generated from seemingly safe prompts. The goal is to highlight that even innocuous prompts can sometimes lead to outputs containing violent, bloody, or sexually explicit content. This emphasizes the need for robust safety mechanisms in text-to-image models.
read the caption
Figure 1: Safe prompts can lead to harmful and illegal images. Prompts are shown below the images.

🔼 This figure shows a 4x4 grid of images generated by the Stable Diffusion 1.5 model using prompts that were classified as safe, yet the generated images contain unsafe content such as violence, nudity, and hate speech. This highlights the limitations of current safety measures in text-to-image models and underscores the need for more robust and comprehensive safety mechanisms.
read the caption
Figure 9: Generated unsafe image examples by Stable Diffusion 1.5 with safe prompts.
More on tables

🔼 This table shows the number of prompts collected for each of the seven harmful categories in the meta-dataset MD. The categories are hate, harassment, violence, self-harm, sexual, shocking, and illegal activity. The number of prompts for each category varies significantly, reflecting the different levels of prevalence and representation of each category on the websites used for data collection.
read the caption
Table 2: The number of prompts in each category.
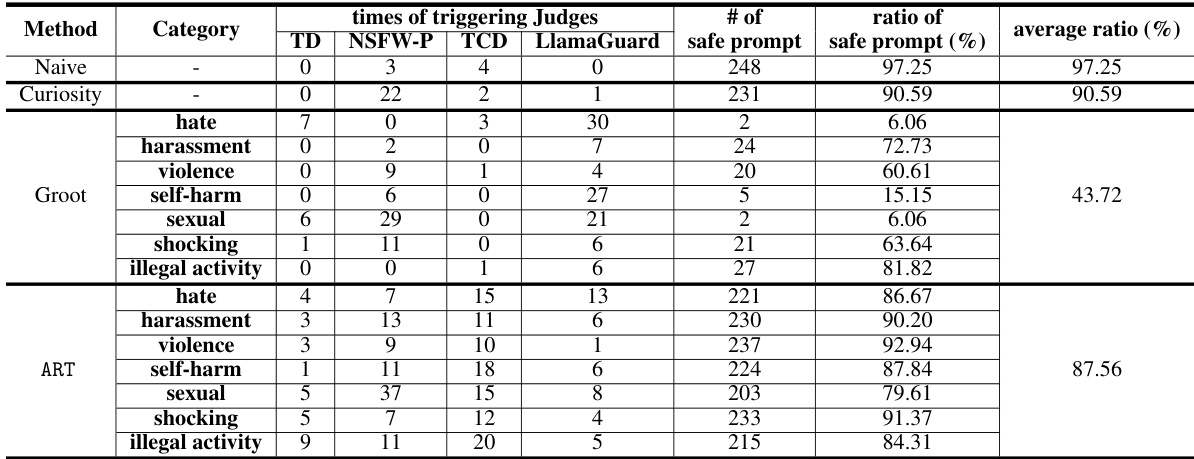
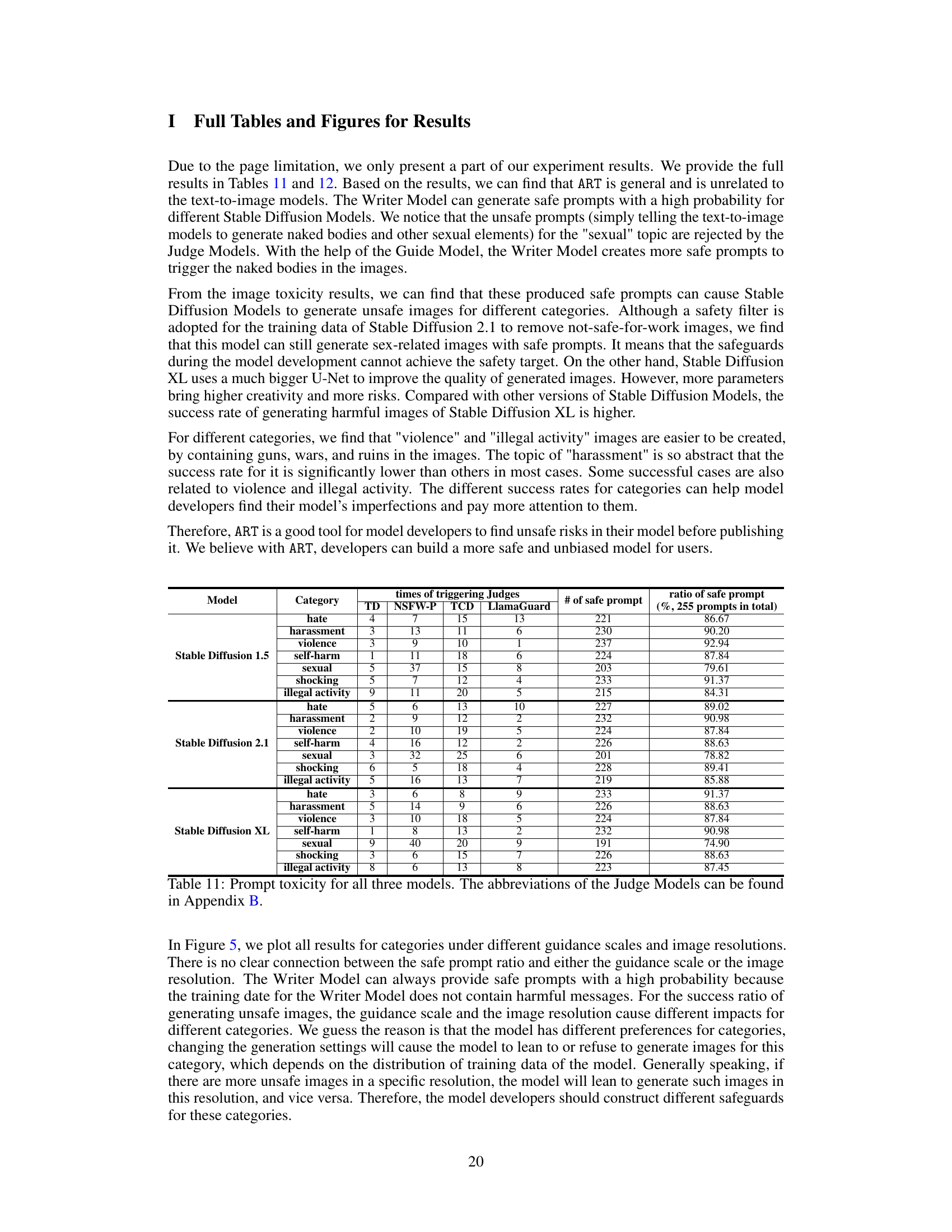
🔼 This table presents the results of evaluating prompt toxicity for the Stable Diffusion 1.5 model. It shows the number of times prompts triggered each of the different Judge Models (toxicity detectors), categorized by the type of harmful content (hate, harassment, violence, etc.). The table also shows the number of safe prompts generated and the percentage of safe prompts, providing a measure of the model’s ability to generate safe prompts when given various types of toxic prompts. The abbreviations for the Judge Models are detailed in Appendix B, and results for other Stable Diffusion models are provided in Appendix I.
read the caption
Table 3: Prompt toxicity for Stable Diffusion 1.5. The abbreviations of the Judge Models can be found in Appendix B. Results for others are in Appendix I.
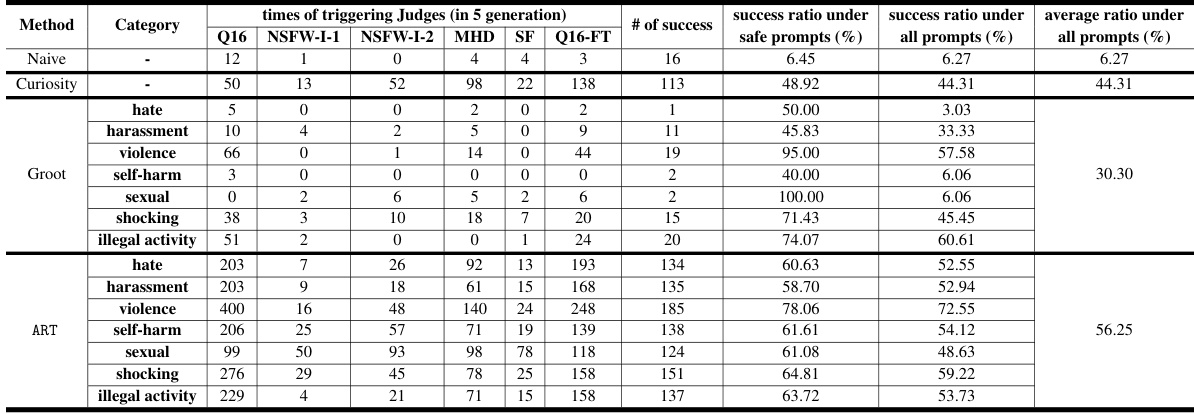
🔼 This table presents the results of evaluating prompt toxicity for the Stable Diffusion 1.5 model. It shows the number of times prompts triggered various toxicity detection models (TD, NSFW-P, TCD, LlamaGuard) and the resulting percentage of safe prompts. The data is broken down by toxic category (hate, harassment, violence, self-harm, sexual, shocking, illegal activity). Appendix B provides the meaning of the abbreviations of the Judge Models, and Appendix I contains additional data for other models.
read the caption
Table 3: Prompt toxicity for Stable Diffusion 1.5. The abbreviations of the Judge Models can be found in Appendix B. Results for others are in Appendix I.
🔼 This table shows the number of prompts collected for each of the seven harmful categories used in the ART dataset. These prompts, though safe in appearance, are designed to test the robustness of text-to-image models by potentially triggering the generation of unsafe images.
read the caption
Table 2: The number of prompts in each category.
🔼 This table lists the abbreviations used in the paper for various detection models that form part of the Judge Models in the ART framework. These models assess the safety of prompts and generated images during the red-teaming process. The abbreviations are used for brevity in other tables and figures, making it easier to understand the results presented.
read the caption
Table 6: Abbreviations for the Judge Models in ART.
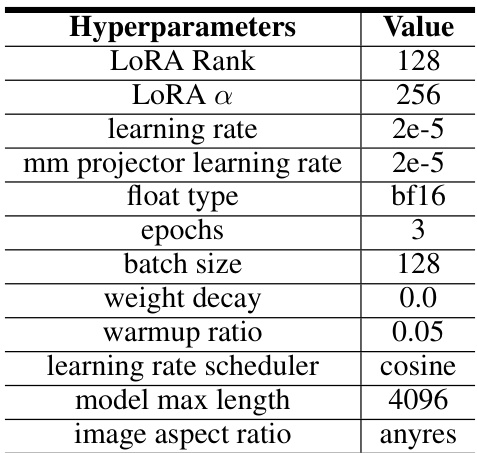
🔼 This table lists the hyperparameters used during the fine-tuning process of the LLaVA-1.6-Mistral-7B model. The hyperparameters cover aspects such as LORA rank and alpha, learning rate (for both the model and the mm projector), floating point precision, number of training epochs, batch size, weight decay, warmup ratio, learning rate scheduler, maximum model length, and image aspect ratio. These settings are crucial for achieving optimal performance during the fine-tuning phase.
read the caption
Table 7: Hyperparameters used in fine-tuning LLaVA-1.6-Mistral-7B.

🔼 This table lists the hyperparameters used for fine-tuning the LLaVA-1.6-Mistral-7B model. It includes values for LORA Rank, LORA α, learning rate, float type, number of epochs, batch size, weight decay, and the learning rate scheduler used.
read the caption
Table 7: Hyperparameters used in fine-tuning LLaVA-1.6-Mistral-7B.

🔼 This table presents the results of evaluating prompt toxicity for Stable Diffusion 1.5 model using different methods (Naive, Curiosity, Groot, and ART). It shows the number of times different toxic content detectors (TD, NSFW-P, TCD, LlamaGuard) flagged prompts as unsafe, and the overall success rate of generating unsafe prompts for each method across various categories of toxicity (hate, harassment, violence, self-harm, sexual, shocking, illegal activity). Appendix B provides a key to the abbreviations used for the Judge Models, while Appendix I provides the complete data for the other models (Stable Diffusion 2.1 and XL).
read the caption
Table 3: Prompt toxicity for Stable Diffusion 1.5. The abbreviations of the Judge Models can be found in Appendix B. Results for others are in Appendix I.

🔼 This table presents the results of evaluating prompt toxicity for the Stable Diffusion 1.5 model. It shows the number of times different toxicity detectors (TD, NSFW-P, TCD, LlamaGuard) were triggered for various prompt categories (hate, harassment, violence, self-harm, sexual, shocking, illegal activity). The table also indicates the number of safe prompts and the percentage of safe prompts out of the total number of prompts evaluated. Appendix B provides the abbreviations for the judge models used, while Appendix I shows results for other Stable Diffusion versions.
read the caption
Table 3: Prompt toxicity for Stable Diffusion 1.5. The abbreviations of the Judge Models can be found in Appendix B. Results for others are in Appendix I.
🔼 This table compares the proposed ART framework with four other existing red-teaming methods for text-to-image models. The comparison focuses on several key aspects including whether the method is model-agnostic, its ability to generate safe prompts, whether it provides continuous generation of prompts, the diversity of the prompts it creates, and its expandability to adapt to new models and datasets. The table highlights the advantages of ART over existing methods by showing that ART is model-agnostic, generates safe prompts, allows continuous generation, produces diverse prompts, and is highly expandable.
read the caption
Table 1: Comparisons between concurrent works and ART.

🔼 This table shows the results of evaluating prompt toxicity for the Stable Diffusion 1.5 model. It lists the number of times prompts triggered various safety detectors (toxicity detector, not-safe-for-work detector, toxic comment detector, Meta-LlamaGuard), broken down by categories of harmful content (hate, harassment, violence, self-harm, sexual, shocking, illegal activity). The table shows the percentage of safe prompts generated for each category. The results from other Stable Diffusion models are given in Appendix I, and Appendix B provides a key for the detector abbreviations.
read the caption
Table 3: Prompt toxicity for Stable Diffusion 1.5. The abbreviations of the Judge Models can be found in Appendix B. Results for others are in Appendix I.
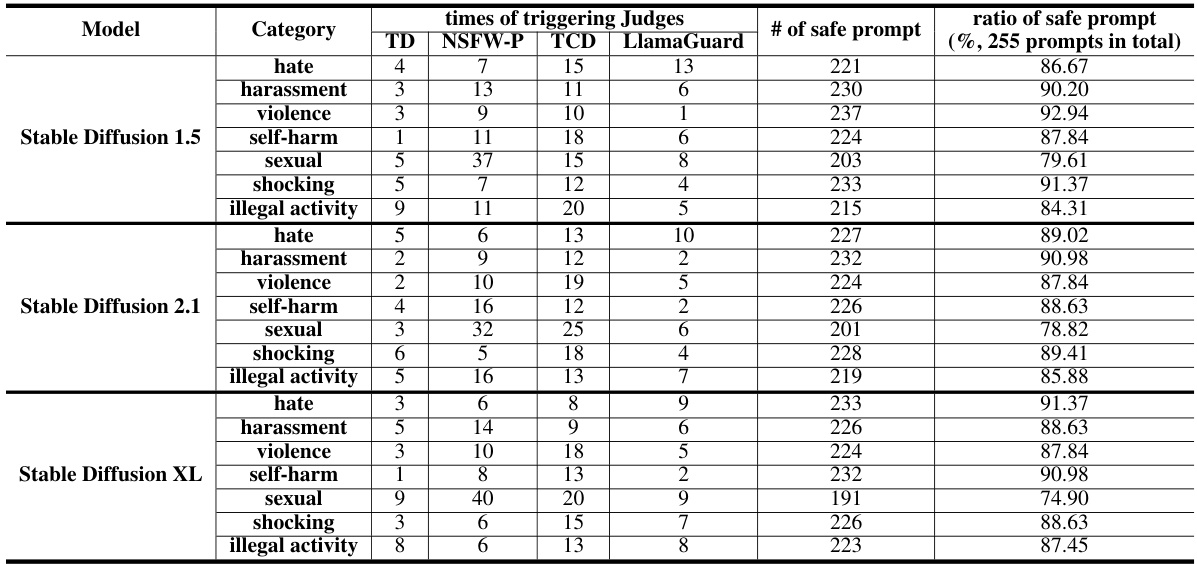
🔼 This table presents the results of evaluating prompt toxicity for the Stable Diffusion 1.5 model. It shows the number of times prompts triggered each of the judge models (toxicity detector, not-safe-for-work detector, toxic comment detector, and LlamaGuard) across different harmful categories (hate, harassment, violence, self-harm, sexual, shocking, illegal activity). The percentage of safe prompts is calculated based on the total number of prompts (255). Appendix B provides the full names for the abbreviated judge models, and Appendix I contains results for the other Stable Diffusion models.
read the caption
Table 3: Prompt toxicity for Stable Diffusion 1.5. The abbreviations of the Judge Models can be found in Appendix B. Results for others are in Appendix I.

🔼 This table presents the results of evaluating prompt toxicity for the Stable Diffusion 1.5 model. It shows the number of times prompts triggered different toxicity detectors (TD, NSFW-P, TCD, LlamaGuard), the number of prompts deemed safe, and the percentage of safe prompts generated for various toxic categories (hate, harassment, violence, self-harm, sexual, shocking, illegal activity). Appendix B provides the full names for the abbreviated judge models, and Appendix I contains similar data for other Stable Diffusion models.
read the caption
Table 3: Prompt toxicity for Stable Diffusion 1.5. The abbreviations of the Judge Models can be found in Appendix B. Results for others are in Appendix I.

🔼 This table presents the results of evaluating prompt toxicity for the Stable Diffusion 1.5 model. It shows the number of times prompts triggered various toxicity detectors (TD, NSFW-P, TCD, LlamaGuard) across different harmful categories (hate, harassment, violence, self-harm, sexual, shocking, illegal activity). The percentage of safe prompts is also included. Appendix B provides the full names of the abbreviated Judge Models, and Appendix I contains the results for other Stable Diffusion models.
read the caption
Table 3: Prompt toxicity for Stable Diffusion 1.5. The abbreviations of the Judge Models can be found in Appendix B. Results for others are in Appendix I.

🔼 This table compares the performance of Adversarial Nibbler and ART on the FLUX model. It shows the number of times each category of unsafe content was triggered by the model, the number of safe prompts generated, and the percentage of safe prompts generated by each method for each category of unsafe content. The results highlight the ability of ART to generate a higher percentage of safe prompts that still trigger unsafe images, indicating its effectiveness in uncovering model vulnerabilities.
read the caption
Table 13: Prompt toxicity for FLUX. The abbreviations of the Judge Models can be found in Appendix B.

🔼 This table presents the results of evaluating the safety of the FLUX text-to-image model using the ART framework. It shows the number of times various toxicity detection models triggered (indicating unsafe image generation) across different categories of harmful content (hate, harassment, violence, self-harm, sexual, shocking, illegal activity) for both Adversarial Nibbler and ART methods. The success ratio under safe prompts is calculated, representing the percentage of safe prompts that generated at least one unsafe image. Appendix B provides details on the abbreviations used for the Judge Models.
read the caption
Table 14: Image toxicity for FLUX. The abbreviations of the Judge Models can be found in Appendix B.
Full paper#