↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Customizing actions in image generation using text-guided diffusion models is challenging because existing methods struggle to decouple actions from other semantic details, like the actor’s appearance. This leads to inaccurate or inconsistent results when generating images with customized actions performed by different actors. A lack of an effective inductive bias with few examples images exacerbates the problem.
TwinAct tackles this by introducing a common action space which focuses solely on action. This enables precise customization without relying on actor-specific information. TwinAct uses this common action space to imitate customized actions and then generates images with an action similarity loss to ensure that the generated images accurately reflect the intended actions. Experiments show that TwinAct outperforms other methods, generating accurate and consistent customized actions across different subjects, including animals, humans and customized actors. The common action space is key to achieving this high quality and consistent performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on text-guided diffusion models and image generation. It directly addresses the challenge of customizing actions in image synthesis, a significant limitation of existing methods. By introducing the novel concept of a common action space, the research opens new avenues for generating more accurate, context-independent customized actions across diverse subjects, significantly advancing the state-of-the-art. This will impact applications such as animation, gaming, and visual effects. The proposed benchmark dataset will also drive future progress in this area.
Visual Insights#

This figure shows a qualitative comparison of TwinAct against other methods for generating customized action images. Each row represents a different action (e.g., three-point landing), and each column represents a different method. The results demonstrate that TwinAct is superior at maintaining the visual identity of the actors while also accurately generating the specified actions, even across different actors. Other methods struggle to separate the actor from the action, leading to inconsistencies and less accurate results.

This table presents a quantitative comparison of TwinAct against several baseline methods for generating customized action images. The comparison uses both objective metrics (SAction: action similarity, SActor: actor identity similarity) and user study scores (UAction: user rating for action quality, UActor: user rating for actor identity consistency). Higher scores indicate better performance. The results clearly show that TwinAct outperforms all the other methods in both objective measures and user evaluation.
In-depth insights#
Action Decoupling#
Action decoupling in the context of AI-driven image generation refers to the ability to separate the depiction of an action from other aspects of the image, such as the identity of the actor or the background scene. This is a crucial challenge because existing models often struggle to isolate the action, leading to unwanted artifacts or inconsistencies. Effective action decoupling is vital for generating diverse and realistic images featuring specific actions performed by various actors within various contexts. Successful approaches often involve creating a common action space, where actions are represented independently of actors or settings, allowing for more precise control and customization. This typically involves techniques that carefully disentangle the features of an action from other semantic elements during model training or generation. Such advancements are significant, enabling more realistic and adaptable AI-generated images that are not limited by the constraints of specific actor-action pairings. This allows for more creative and flexible generation, with the potential to improve applications ranging from animation and film to video games and virtual reality.
Common Action Space#
The concept of a ‘Common Action Space’ in the context of this research paper is a novel approach to address the challenge of decoupling actions from actors in few-shot action image generation. It’s a textual embedding space dedicated solely to actions, thus abstracting away actor-specific details (appearance, identity). This is crucial because existing methods struggle with disentangling actions from other semantic aspects within limited training data, resulting in inaccurate or inconsistent action imitation. By focusing exclusively on action, this common space provides a powerful inductive bias, enabling precise action customization without interference from irrelevant actor information. This is achieved by carefully curating a set of representative action phrases, converting them into embeddings and applying dimensionality reduction (PCA) to create a compact yet informative action space. The result is improved accuracy in generating customized actions adaptable across different actors and contexts. The common space facilitates the imitation of actions by combining basic action units (action bases) with learned weights in an MLP, ensuring high-fidelity and actor-consistent image generation. The success of this approach fundamentally relies on the effective separation of action and actor semantics within a shared, interpretable representational space.
TwinAct Framework#
The hypothetical “TwinAct Framework” for customized action image synthesis appears to be a multi-stage process. It begins by constructing a common action space, a textual embedding focused solely on actions, enabling precise control without actor-specific details. This space is crucial for decoupling actions from actors, a significant challenge in few-shot action image generation. The framework then proceeds by imitating the customized action within this common space, likely through a method like embedding manipulation or fine-tuning. Finally, it generates highly adaptable customized action images, leveraging a loss function to ensure action similarity and potentially addressing context variability. The key innovation seems to lie in the effective separation of action and actor semantics, allowing for greater flexibility in customizing actions across diverse subjects and scenarios, which is a significant advancement over existing methods.
Action Imitation#
The concept of ‘Action Imitation’ in the context of a research paper likely involves using machine learning to enable systems to replicate observed actions. This could range from simple motor skills to complex behavioral patterns. The core challenge involves disentangling the action itself from other factors, such as the actor’s appearance, context, or even the actor’s intent. Successful action imitation often relies on robust feature extraction to isolate relevant aspects of the movement, coupled with sophisticated algorithms that can learn and reproduce these features in novel situations. Generalizability is key; the system’s ability to imitate actions across different actors and contexts is a critical measure of success. The approaches might leverage techniques such as reinforcement learning, imitation learning, or generative models, each with its own set of strengths and weaknesses. Furthermore, ethical considerations surrounding the potential misuse of such technology, particularly in generating realistic deepfakes, are likely discussed. The success of an ‘Action Imitation’ system is judged by its accuracy, efficiency, and generalizability.
Future Directions#
Future research could explore enhancing TwinAct’s action representation by incorporating more nuanced action descriptions and diverse datasets, potentially improving its ability to generate complex actions accurately. Addressing the limitations related to action-irrelevant features in few-shot learning is crucial. Investigating alternative training strategies, like incorporating contrastive learning or generative adversarial networks, might significantly improve the model’s ability to disentangle action from actor-specific attributes. Furthermore, extending TwinAct to handle temporal sequences or videos would be a significant advancement, allowing for the generation of more dynamic and realistic action sequences. The current method’s reliance on a linear combination of action bases could also be improved by exploring non-linear combinations or more sophisticated methods to model action interactions. Finally, thorough ethical considerations and safeguards should be implemented to prevent misuse and address potential societal implications of action generation models.
More visual insights#
More on figures
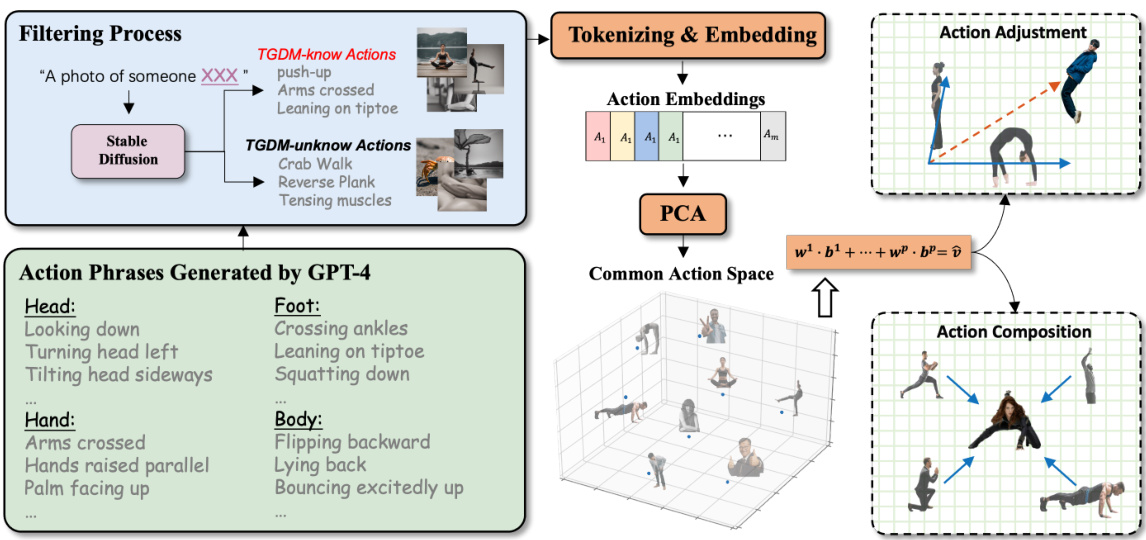
This figure illustrates the process of constructing a Common Action Space for representing actions. It starts with filtering actions that are known to a Text-Guided Diffusion Model (TGDM) from those unknown to the model. Action phrases are generated using GPT-4 and then tokenized and embedded. These embeddings undergo Principal Component Analysis (PCA) to create the common action space. Finally, action adjustment and composition are shown, indicating how customized actions can be built as combinations of basic actions within the common action space.
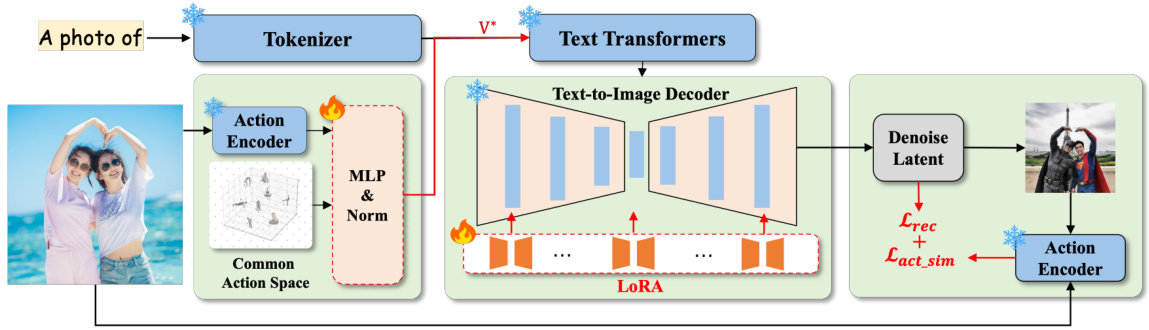
This figure shows a schematic overview of the TwinAct model architecture. The process begins with a user-provided image and text prompt. The prompt is tokenized and processed by a text transformer. An action encoder extracts action features from the input image. These features are used by an MLP to adjust weights for a set of action bases in a common action space. The weighted action bases are used to modulate the coefficients of the LoRA layers within the text-to-image decoder. The decoder generates a denoised image, and the action similarity loss refines the generated image based on the action similarity between the generated image and the input image. The final output is a generated image with a customized action, while minimizing the inclusion of action-irrelevant features.

This figure showcases the results of the TwinAct model in generating images with customized actions performed by various subjects, including celebrities and animals. The key takeaway is the model’s ability to maintain both the fidelity of the customized action and the identity consistency of the actor, even when the actor is different across images. The results demonstrate the model’s flexibility and robustness in handling diverse contexts and subjects.

This figure showcases the results of the TwinAct model in generating images of various actors performing customized actions. The model successfully generates images where actors (celebrities, animals) perform actions specified by user input. Importantly, it demonstrates the model’s ability to maintain consistency in the action’s performance across different actors while preserving the actor’s identity. This highlights the model’s capability to decouple actions and actors effectively.

This figure shows a schematic overview of the TwinAct model. It illustrates the process of generating customized action images, starting with a textual prompt (V*) and exemplar images. TwinAct uses a multi-layer perceptron (MLP) to optimize the coefficients of action bases within a common action space. These optimized coefficients and the action bases are then combined to generate images of the customized action, minimizing action-irrelevant details. The model incorporates both reconstruction loss and action similarity loss during training to improve accuracy and generalization.

This figure compares the results of generating customized action images using TwinAct and Stable Diffusion. It demonstrates that even when using very detailed textual descriptions, Stable Diffusion struggles to accurately generate the intended actions, while TwinAct is successful. This highlights TwinAct’s ability to understand and generate accurate action images despite limitations in textual description.

This figure compares the image generation results of TwinAct against sketch-based methods like ControlNet. The comparison highlights that using sketches as input for generating customized actions is challenging. ControlNet struggles to capture fine details (like fingers) when using skeleton-style input sketches, while using line-style sketches limits the diversity and generalization of generated images, especially when the actions involve animals. TwinAct, in contrast, generates images with better detail and broader applicability.

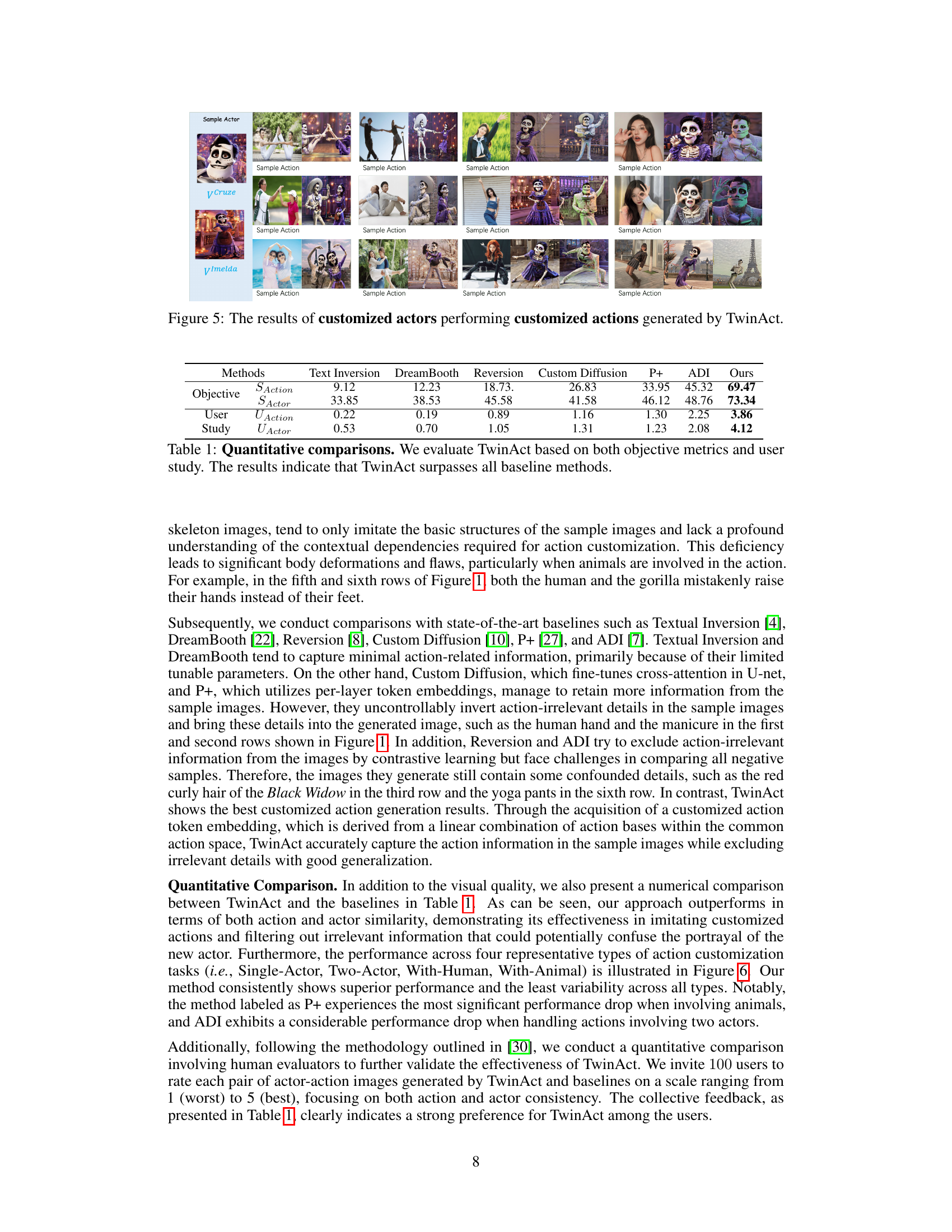
This figure compares the performance of TwinAct against other methods for generating images of customized actors performing customized actions. The results show that TwinAct excels at maintaining both the identity of the actor and the accuracy of the action in the generated image, unlike the other methods which struggle to balance these aspects.

This figure shows example results from the TwinAct model. It demonstrates the model’s ability to generate images of various actors (celebrities, animals) performing a customized action while preserving both the action’s characteristics and the actor’s identity. The top row shows the example action image used as input; subsequent rows showcase the generated images with various actors executing that same action.
Full paper#