TL;DR#
Sequential recommendation systems struggle to accurately predict user choices due to the inherent randomness and unpredictability of user behavior. Existing models often rely on deterministic approaches which fail to adequately capture this randomness. This paper introduces DDSR, a novel model that addresses these limitations.
DDSR employs fuzzy sets to represent user interests, allowing for a more flexible and nuanced representation of user preferences. The model uses discrete diffusion processes, which operate in discrete state spaces, to better capture the evolution of user interests. Furthermore, to enhance efficiency and mitigate cold-start problems, the paper proposes using semantic labels derived from item descriptions, enhancing the overall performance and reliability of the model. Extensive experiments demonstrate that DDSR significantly outperforms state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in sequential recommendation because it introduces a novel approach that directly addresses the limitations of deterministic models. By incorporating fuzzy logic and discrete diffusion processes, the DDSR model significantly improves accuracy and efficiency, especially in handling sparse data and cold-start problems. This opens new avenues for research in handling uncertainty and randomness inherent in user behavior, impacting the development of more robust and reliable recommendation systems.
Visual Insights#
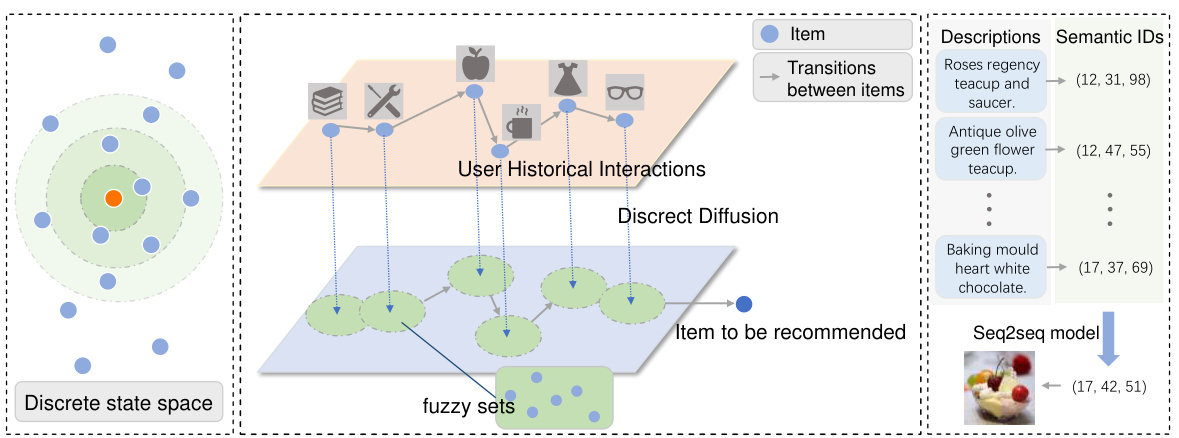
🔼 This figure illustrates the DDSR model’s core components and processes. The left panel depicts how a user’s interest might be diffuse and uncertain before a final selection. The middle panel shows how DDSR uses discrete diffusion to model the evolution of interests as fuzzy sets of items. Finally, the right panel explains how item descriptions are converted into semantic IDs for more efficient processing and to alleviate cold-start problems.
read the caption
Figure 1: Illustration of DDSR constructing fuzzy sets and incorporating semantic IDs to enhance sequential recommendations. In real-world scenarios, a user's final choice often reflects their immediate interests (left subfigure). We reconstruct the true evolution of interests by constructing fuzzy sets for each item in the interaction sequence (middle subfigure). The right subfigure provides an overview of the process of generating semantic IDs for recommendations based on item-related descriptions.

🔼 This table presents the key statistics of three datasets used in the paper’s experiments: Scientific, Office, and Online Retail. For each dataset, it shows the number of users, items, and interactions, as well as the average length of the item sequences and the average number of words in the item descriptions. These statistics are crucial for understanding the characteristics of the datasets and interpreting the experimental results. The average sequence length provides insight into user behavior patterns, indicating how frequently users interact with items, while the average number of words in item descriptions reveals the richness of textual information associated with each item.
read the caption
Table 1: Detailed descriptions and statistics of datasets. 'Avg. length' represents the average length of item sequences, while 'Avg. num' indicates the average number of words in item text.
In-depth insights#
Fuzzy SR Modeling#
Fuzzy set theory offers a powerful framework for handling the inherent uncertainty and ambiguity in sequential recommendation (SR) systems. Traditional SR models often rely on crisp representations of user preferences and item interactions, which fail to capture the nuanced and evolving nature of user interests. A fuzzy SR model, in contrast, would represent user preferences and item relationships as fuzzy sets, allowing for gradual transitions and the incorporation of uncertainty. This approach would enable the system to better model the fuzziness inherent in user behavior, such as occasional unexpected actions or changes in taste. The model could use fuzzy logic to define membership functions for items in user interest sets, allowing for partial membership and a more flexible representation of user preferences over time. A key advantage would be the capacity to handle incomplete or noisy data more robustly than crisp models, which are often highly sensitive to such imperfections. Furthermore, fuzzy SR models could incorporate various fuzzy inference techniques for making personalized recommendations. This flexibility could lead to more accurate and relevant recommendations than traditional crisp methods, particularly in domains with inherent ambiguity or a high degree of variability in user behavior.
Discrete Diffusion#
Discrete diffusion, in the context of sequential recommendation, offers a novel approach to model user behavior by acknowledging its inherent randomness and unpredictability. Unlike continuous diffusion models that operate in a continuous state space, often adding arbitrary noise, discrete diffusion models operate directly within the discrete space of item interactions. This is advantageous as it avoids information loss and preserves the inherent structure of sequential data. By modeling transitions between items as a directed graph and using structured transitions instead of noise, the method captures the evolution of user interests more accurately. Furthermore, the use of semantic labels derived from quantization or RQ-VAE enhances efficiency, improving cold start issues and the model’s ability to generalize to unseen items. The framework successfully leverages the principles of information diffusion, theoretically guaranteeing a more reliable and effective modeling of user preferences, ultimately leading to improved recommendations. The fuzzy sets generated through discrete diffusion better represent the ambiguity inherent in real user interests which often converge only at the point of selection.
Semantic ID boost#
The concept of “Semantic ID boost” in the context of sequential recommendation systems is intriguing. It addresses the limitations of using raw item IDs, which lack semantic meaning, by leveraging richer representations. Replacing item IDs with semantic IDs derived from item descriptions, using techniques like quantization or RQ-VAE, allows the model to capture latent relationships and improve generalization. This is particularly impactful for cold-start problems, where limited user interaction data hinders accurate prediction. The boost isn’t merely about improved efficiency through a reduced state space. Semantic IDs provide contextual information, enhancing the model’s ability to understand user interests and preferences, leading to more relevant and accurate recommendations. Furthermore, incorporating semantic information enhances the model’s generalization capability and robustness to noise, as the semantic space is more meaningful and less sensitive to random fluctuations in raw interaction data. This approach offers a notable improvement in recommendation accuracy and overcomes the limitations of traditional methods. However, the effectiveness of this method depends on the quality of the semantic ID generation and its alignment with user perception and actual behavior.
Cold-Start Handling#
The effectiveness of recommendation systems often hinges on the availability of sufficient user-item interaction data. Cold-start problems, where the system lacks data for new users or items, significantly hinder performance. The research paper tackles this issue by employing a multi-pronged strategy centered around semantic information. By leveraging descriptions or textual features, the system creates richer item representations that go beyond simple IDs, mitigating the data sparsity issue. Discrete diffusion models further enhance this approach by handling the inherent uncertainty in user behavior and leveraging fuzzy sets for a more robust representation of user interests. This combination reduces reliance on direct interaction history, proving valuable for new items with limited interactions. The use of semantic IDs, derived from techniques like RQ-VAE, enhances the efficiency of the system while concurrently addressing cold start problems for both new users and items. The combination of semantic IDs and discrete diffusion models proves particularly effective, showcasing an innovative approach to recommendation system design and providing substantial improvements in performance metrics compared to conventional methods.
Future of DDSR#
The future of DDSR hinges on several key areas. Improving efficiency is paramount; the current model’s computational demands limit scalability. Exploring more efficient diffusion processes, potentially leveraging advancements in discrete diffusion models or algorithmic optimizations, is crucial. Enhancing the semantic representation of items is another vital direction; incorporating richer contextual information, perhaps through multimodal embeddings or advanced language models, would greatly improve performance, particularly in cold-start scenarios. Addressing the sparsity of data remains a challenge; innovative data augmentation techniques or methods that effectively leverage limited interaction data would boost the model’s robustness. Finally, exploring the theoretical foundations of fuzzy modeling in SR should be a priority. Deeper investigation into information diffusion in discrete spaces could unearth innovative modeling approaches that surpass current state-of-the-art performance, potentially resulting in a more accurate and nuanced representation of user behavior.
More visual insights#
More on tables
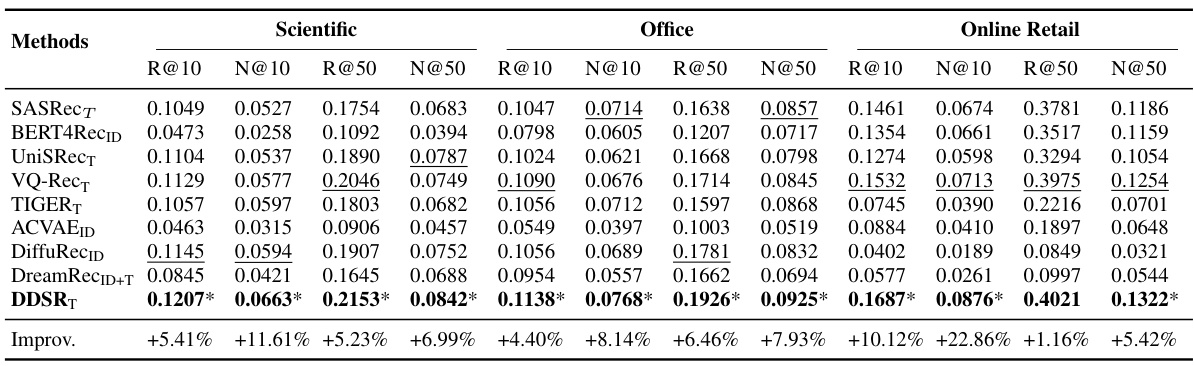
🔼 This table presents the performance comparison of different sequential recommendation models on three datasets (Scientific, Office, Online Retail). The models are evaluated using Recall@K and NDCG@K metrics (K=10,50). The table highlights the best and second-best performing models for each metric and dataset, and also notes statistically significant improvements compared to the best baseline model.
read the caption
Table 2: Performance of different models. Bold (underline) is used to denote the best (second-best) metric, and '*' indicates significant improvements relative to the best baseline (t-test P<.05). 'R@K' ('N@K') is short for 'Recall@K' ('NDCG@K'). The features of items have been listed, whether ID, text (T), or both (ID+T).

🔼 This table presents the performance comparison of different sequential recommendation models on three datasets (Scientific, Office, Online Retail). The models are evaluated using Recall@K and NDCG@K metrics (K=10, 50), and the best and second-best results are highlighted. The table also indicates whether item features used are IDs, text descriptions (T), or both (ID+T), providing a comprehensive performance analysis across various settings and item feature combinations.
read the caption
Table 2: Performance of different models. Bold (underline) is used to denote the best (second-best) metric, and '*' indicates significant improvements relative to the best baseline (t-test P<.05). 'R@K' ('N@K') is short for 'Recall@K' ('NDCG@K'). The features of items have been listed, whether ID, text (T), or both (ID+T).

🔼 This table presents the performance comparison of different sequential recommendation models on three datasets (Scientific, Office, Online Retail). The models are evaluated using Recall@K and NDCG@K metrics (K=10, 50). The table highlights the best and second-best performing models for each metric and dataset, indicating statistically significant improvements where applicable. It also shows whether item features used by each model included only IDs, text descriptions, or both.
read the caption
Table 2: Performance of different models. Bold (underline) is used to denote the best (second-best) metric, and '*' indicates significant improvements relative to the best baseline (t-test P<.05). 'R@K' ('N@K') is short for 'Recall@K' ('NDCG@K'). The features of items have been listed, whether ID, text (T), or both (ID+T).
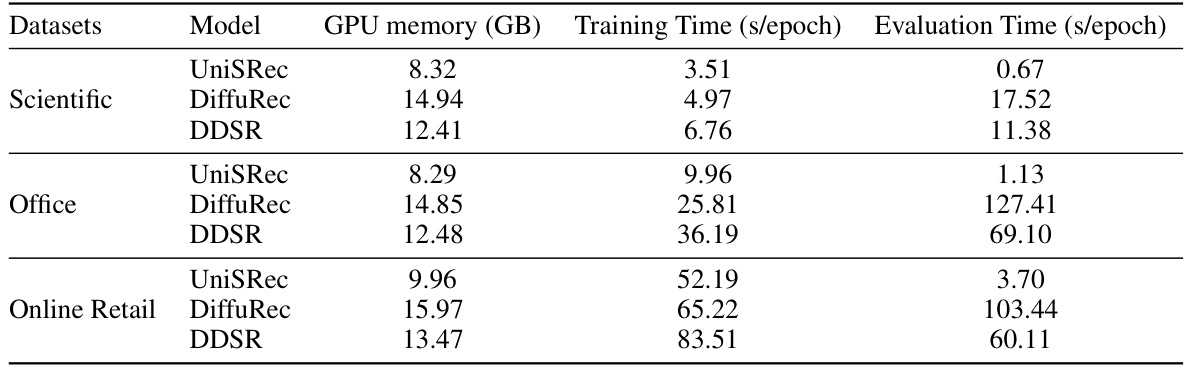
🔼 This table compares the GPU memory usage, training time per epoch, and evaluation time per epoch for three different models (UniSRec, DiffuRec, and DDSR) across three datasets (Scientific, Office, and Online Retail). It provides a quantitative assessment of the computational efficiency and resource demands associated with each model on datasets with varying sizes and characteristics.
read the caption
Table 5: Comparison of Actual Operational Costs.
Full paper#



















