↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
High-resolution image generation using diffusion models is computationally expensive. Existing methods, while improving sampling speed, still demand significant resources. This necessitates more efficient training pipelines. This paper introduces PaGoDA, a novel approach designed to address this challenge.
PaGoDA employs a three-stage pipeline: 1) pre-training a diffusion model on downsampled data to drastically reduce training costs; 2) distilling the pre-trained model into a single-step generator; and 3) progressively upscaling the generator to achieve high resolutions. The study demonstrates that PaGoDA achieves state-of-the-art results in image generation across various resolutions, significantly reducing training costs compared to existing methods. Furthermore, it shows how this pipeline directly applies to Latent Diffusion Models, offering further possibilities for efficiency.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on diffusion models and generative AI. It presents a novel, cost-effective training pipeline that significantly reduces the computational burden associated with high-resolution image generation. The proposed method, PaGoDA, offers a significant advancement, allowing researchers with limited resources to contribute to cutting-edge research in this field. The findings also open exciting avenues for further investigation in model training optimization and high-resolution image generation techniques. This work contributes to the ongoing democratization of generative AI, making it more accessible to a wider research community.
Visual Insights#

This figure shows the pipeline of PaGoDA, which consists of three stages. Stage 1 is diffusion pretraining on downsampled data. Stage 2 is diffusion distillation (using DDIM inversion) to a one-step generator. Stage 3 is super-resolution, progressively upscaling the generator. The figure visually demonstrates how PaGoDA efficiently encodes high-resolution images by downsampling, then progressively grows its decoder to achieve high-resolution generation.
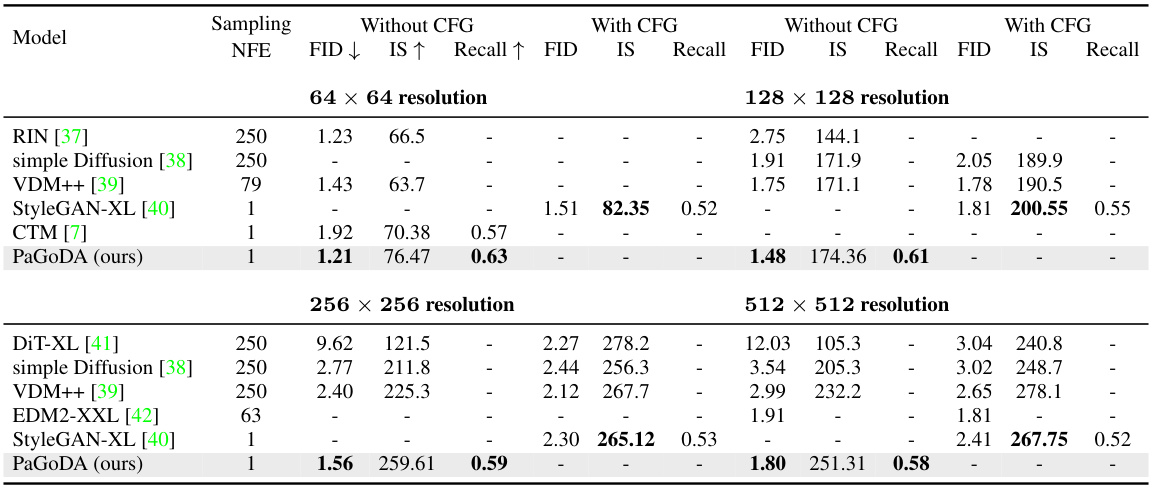
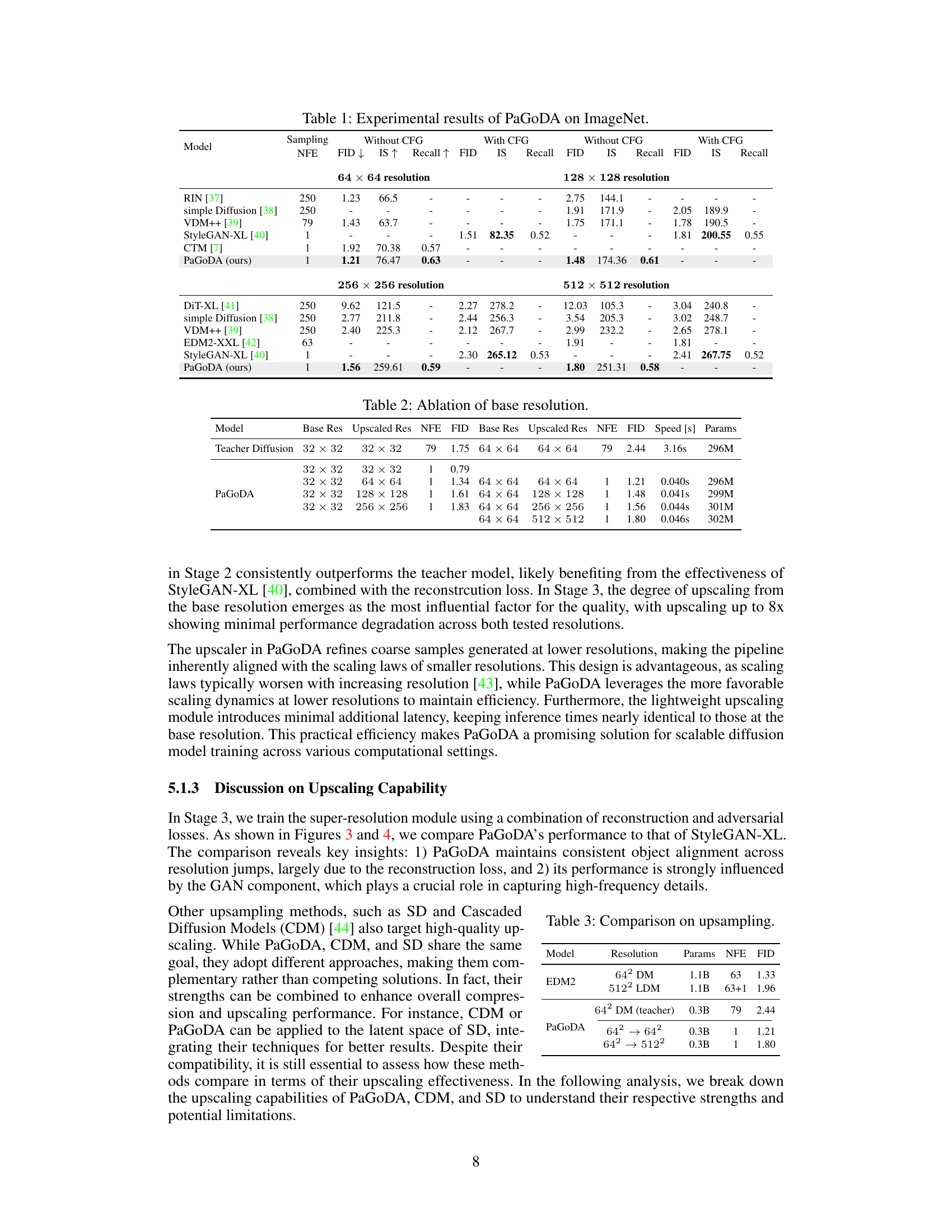
This table presents a quantitative comparison of PaGoDA’s performance against several state-of-the-art models on the ImageNet dataset. It showcases FID (Fréchet Inception Distance), Inception Score (IS), and Recall metrics for different image resolutions (64x64, 128x128, 256x256, and 512x512). The results are presented with and without Classifier-Free Guidance (CFG) to highlight PaGoDA’s performance in both settings. Lower FID scores indicate better image quality, higher IS values denote greater diversity, and higher Recall signifies improved sample diversity compared to the real data distribution. The NFE (number of forward Euler steps) column shows the computational efficiency of each method.
In-depth insights#
DM Training Efficiency#
Diffusion models (DMs) excel at generating high-dimensional data but suffer from computationally expensive training. This paper tackles this limitation by proposing a novel three-stage training pipeline to significantly reduce training costs while maintaining state-of-the-art performance. The core idea is to leverage downsampling to train the initial DM on lower-resolution data, effectively reducing the computational burden. This lower-resolution DM is then distilled into a one-step generator, and finally, a progressive super-resolution stage expands the generator to the target resolution. This strategy significantly reduces computational costs, achieving a 64x reduction in training time in one specific experiment. The use of DDIM inversion enhances the quality of the distillation and super-resolution steps. Furthermore, the paper provides a theoretical analysis which proves the stability and convergence of this training pipeline under specific conditions, highlighting the algorithmic efficiency and theoretical robustness of this approach for DM training.
Progressive Upscaling#
Progressive upscaling, in the context of generative models, is a powerful technique for efficiently generating high-resolution images. It works by training a model on lower-resolution data initially, gradually increasing resolution in subsequent training stages. This approach offers significant advantages, including reduced computational cost and faster training times, since lower resolutions demand less processing power. A key aspect is the strategy of retaining and leveraging information from previous stages. The model learns features at coarser levels first, building a solid foundation upon which higher-resolution details are layered. This progressive strategy contrasts with direct, single-stage high-resolution training, which can be computationally expensive and prone to instability. Furthermore, progressive upscaling often incorporates intermediate steps to carefully refine image details at each new resolution, ensuring smooth transitions and high-quality outputs. The successful application of progressive upscaling hinges on the design of a carefully structured model architecture and training procedure that facilitates effective knowledge transfer between resolutions. The overall effect is a more efficient and robust method for generating high-fidelity imagery, especially important when dealing with limited computational resources or large datasets.
DDIM-Based Distillation#
DDIM-based distillation, a crucial technique in the paper, focuses on efficiently creating a single-step image generator. It leverages the power of pre-trained diffusion models while significantly reducing computational costs. The method cleverly distills knowledge from a computationally expensive, high-resolution diffusion model into a faster, more efficient single-step model. This is achieved by using DDIM (Denoising Diffusion Implicit Models) inversion, which maps real images to their latent representations in a low-dimensional space. This latent space is much more efficient to train on. The distillation process refines the single-step generator until its output closely matches the original high-resolution diffusion model’s. Key advantages include decreased training time and computational resources. The single-step generator produced through this method is then leveraged for super-resolution upscaling, further enhancing efficiency and the image quality, leading to state-of-the-art results on benchmarks like ImageNet. The integration of DDIM inversion within this distillation process provides a novel and effective pipeline, establishing strong connections between the multiple stages of the approach. The use of DDIM enables the generation of high-quality images from low-dimensional latent representations, thus enabling improvements to computational efficiency without sacrificing image quality.
Controllable Generation#
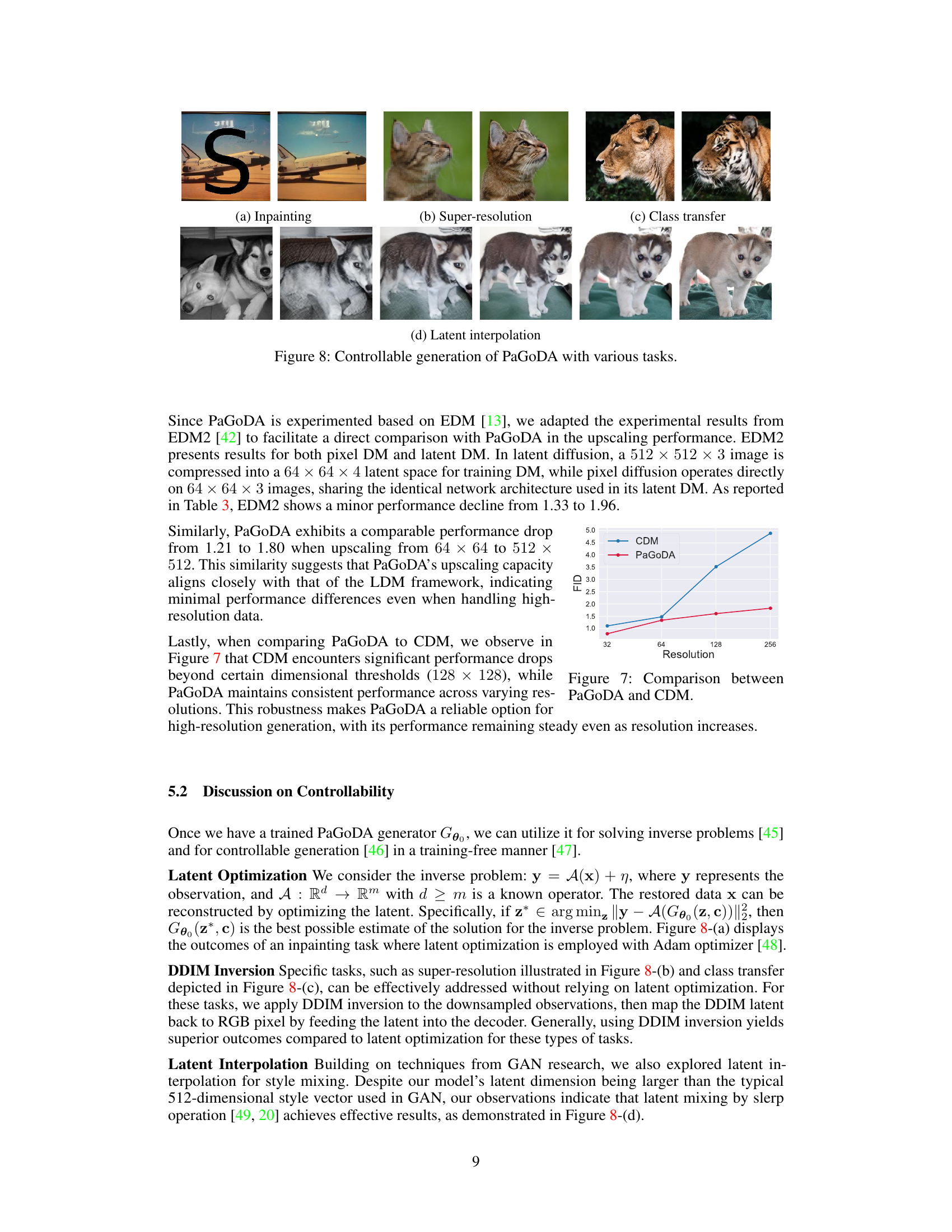
The section on “Controllable Generation” would explore the paper’s capacity to generate images beyond simple random sampling. It would delve into techniques enabling specific control over image attributes, such as inpainting (filling in missing parts of an image), super-resolution (enhancing image resolution), and class transfer (transforming one object into another). The authors likely showcase the model’s ability to perform these tasks effectively by manipulating latent representations. A key aspect would be demonstrating the model’s flexibility by using latent interpolation, blending characteristics of different images to create novel outputs. The effectiveness of these control mechanisms would be critically evaluated, possibly by comparing results against existing state-of-the-art methods, highlighting improvements in image quality and controllability. Furthermore, limitations such as potential challenges in achieving fine-grained control or handling complex manipulations could be addressed. The overall goal is to showcase how PaGoDA’s architecture facilitates a range of user-specified image manipulations, emphasizing its advanced control over image generation.
Future Research#
The paper’s exploration of efficient high-resolution image generation using diffusion models opens exciting avenues for future work. Extending PaGoDA’s application to other LDM architectures, beyond the Stable Diffusion model explored in this paper, is a crucial next step. This could significantly broaden the technique’s applicability and potentially unlock further computational efficiency gains. Investigating the impact of varying the number of data-latent pairs in the adversarial training of PaGoDA warrants attention to optimize quality and diversity. A deeper investigation into the stability analysis of PaGoDA, particularly focusing on relaxing the strong assumptions made for theoretical guarantees, would enhance the robustness and provide broader applicability. Finally, exploring PaGoDA in more sophisticated applications like video generation or 3D model synthesis could expand the scope of the method and solidify its role in the future of generative modeling. These research directions could significantly advance efficient training and high-fidelity generation in large-scale generative AI tasks.
More visual insights#
More on figures

This figure illustrates the three stages of the PaGoDA pipeline. First, a high-resolution image is downsampled. Then, DDIM inversion is applied to the downsampled image, which creates a latent representation. This latent representation is then used by a one-step generator to reconstruct the image at the lower resolution. Finally, a super-resolution stage progressively upscales the generated low-resolution image to the original high resolution.
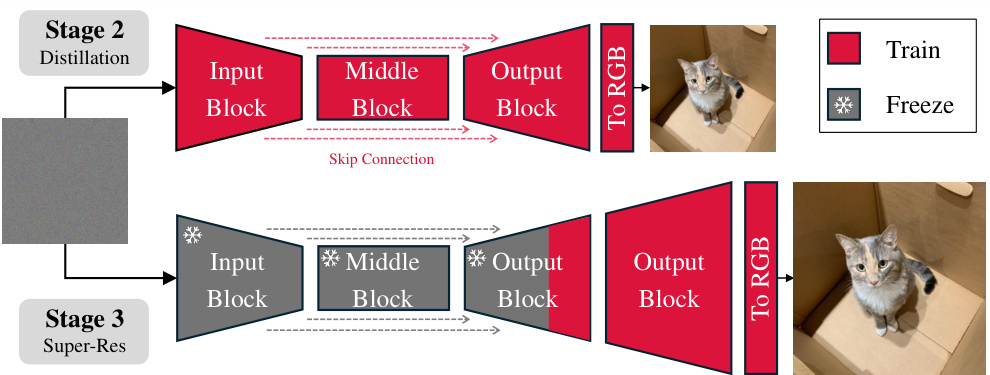
This figure illustrates the architecture of PaGoDA’s decoder during the progressive growing stage. The top half shows the network architecture at Stage 2 (distillation), which takes a latent vector as input and generates an image at the base resolution. The bottom half shows the architecture at Stage 3 (super-resolution), where additional blocks are added to progressively increase the resolution of the generated image. The blocks marked with an asterisk (*) are frozen during training.

This figure shows the effect of using the reconstruction loss in Stage 3 of the PaGoDA model. Two sets of images are shown: one where the reconstruction loss was used (a) and one where it was not used (b). Each set shows an image upscaled progressively from 64x64 to 512x512 resolution. The images in (a) show consistent object positioning across all resolutions, highlighting the stabilizing effect of the reconstruction loss. In contrast, the images in (b) demonstrate that the object moves slightly as the resolution increases when the reconstruction loss is omitted. This clearly shows the value of the reconstruction loss in ensuring consistent object placement during upscaling.
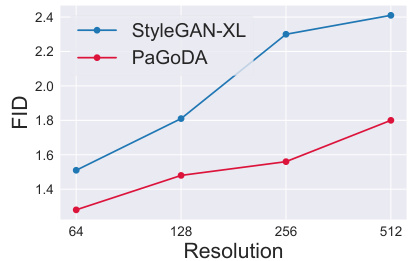
The figure shows a plot comparing the Fréchet Inception Distance (FID) scores achieved by PaGoDA and StyleGAN-XL across different image resolutions (64x64, 128x128, 256x256, and 512x512). The results demonstrate that PaGoDA, with the help of the adversarial loss, achieves FID scores comparable to those of StyleGAN-XL, a state-of-the-art GAN-based super-resolution model, particularly at higher resolutions. This supports PaGoDA’s effectiveness in Stage 3 (Super-Resolution) of its progressive growing pipeline.
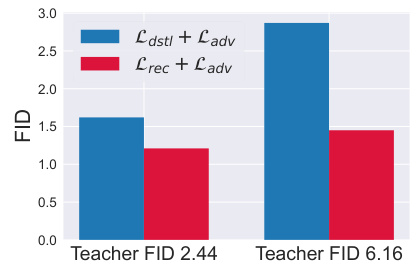
This figure compares the Fréchet Inception Distance (FID) scores achieved using two different loss functions: Ldstl (noise-to-data distillation loss) and Lrec (reconstruction loss), each combined with an adversarial loss (Ladv). The results demonstrate that the reconstruction loss (Lrec) shows significantly more robust performance than the noise-to-data distillation loss (Ldstl), even when using a weaker teacher model (higher Teacher FID score). This robustness is supported by Theorem 3.1 within the paper.

This figure shows examples of images generated by the PaGoDA model at a resolution of 512x512 pixels without using Classifier-Free Guidance (CFG). The left side displays images of class 31 (tree frog), while the right side shows images of class 33 (loggerhead turtle). The images are presented as an uncurated sample of the model’s output, meaning they are not hand-picked or specially selected to showcase the model’s best results but rather provide a representation of the model’s typical output.

This figure demonstrates the versatility of the PaGoDA model in handling various image manipulation tasks. Panel (a) showcases inpainting, where missing parts of an image are filled in realistically. Panel (b) shows super-resolution, where a low-resolution image is upscaled to a higher resolution with improved detail. Panel (c) presents class transfer, where the features of one object are transferred to another, changing the object’s appearance while maintaining its overall structure. Lastly, panel (d) illustrates latent interpolation, where smooth transitions are created between different images by blending their latent representations.

This figure compares the Fréchet Inception Distance (FID) scores of PaGoDA and CDM across different resolutions (32, 64, 128, 256). It demonstrates PaGoDA’s superior performance at higher resolutions, highlighting its robustness and ability to maintain image quality even at increased complexity. In contrast, CDM shows a significant increase in FID scores as the resolution increases, indicating a decline in image generation quality.

This figure compares the sampling speed of PaGoDA and LCM (Latent Consistency Model). It shows a stacked bar chart with two bars representing LCM and PaGoDA. The LCM bar is divided into two sections, ‘64x64 Latent (z)’ and ‘Decoder (z → x)’, representing the time taken for latent space processing and upscaling to image. The PaGoDA bar is similarly divided into ‘64x64 Pixel’ and ‘Prog. Growing’, representing processing time on the downsampled image and the progressive growing super-resolution stage. A red arrow points from the top of the LCM Decoder section to the PaGoDA Prog. Growing section, labeled with ‘2x Faster’, indicating that PaGoDA’s inference is significantly faster than LCM. This is due to PaGoDA’s use of a single-step generator with direct generation of high-resolution images compared to the multi-step approach of LCM.

This figure shows example images generated by the PaGoDA model at a resolution of 512x512 pixels, without using classifier-free guidance. The two example images shown represent different classes from the ImageNet dataset: a tree frog (class 31) and a loggerhead turtle (class 33). The images demonstrate the model’s ability to generate diverse and realistic-looking samples at high resolution.
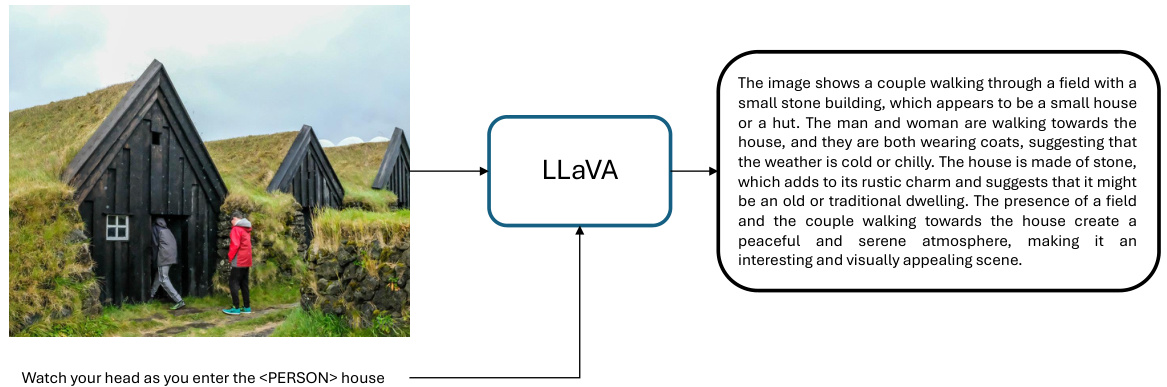
This figure shows an example of how the LLaVA model re-captioned an image-text pair. The original caption, ‘Watch your head as you enter the
house’, is contrasted with the LLaVA-generated caption, which provides a more detailed and descriptive rendering of the scene depicted in the image. This illustrates the use of LLaVA to improve the quality and accuracy of text-image pairings for the training data.

This figure shows the comparison between caption generation and recaption generation using DeepFloyd-IF and PaGoDA models. The left two images display the original captions generated by both models, and the right two images show the recaptioned results. Each row represents a different CFG scale, demonstrating how the quality of generation changes with the scale. The recaptioned samples generally outperform the original captions, especially when CFG scale is small. The recaptioning method is used to generate more relevant and accurate text-image pairs.
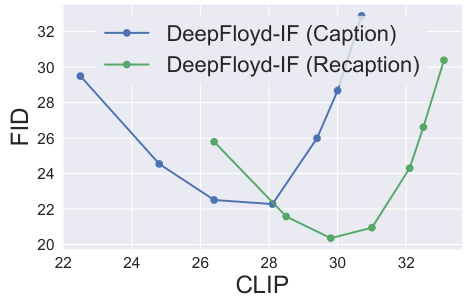
This figure compares the caption generation results of the DeepFloyd-IF model and the PaGoDA model with different CFG scales. It shows that the recaptioned samples generally outperform the original caption samples, particularly when the CFG scale is small. The recaptioning process involves using a language model with vision assistance to generate more relevant and accurate descriptions of the images based on the text prompts.
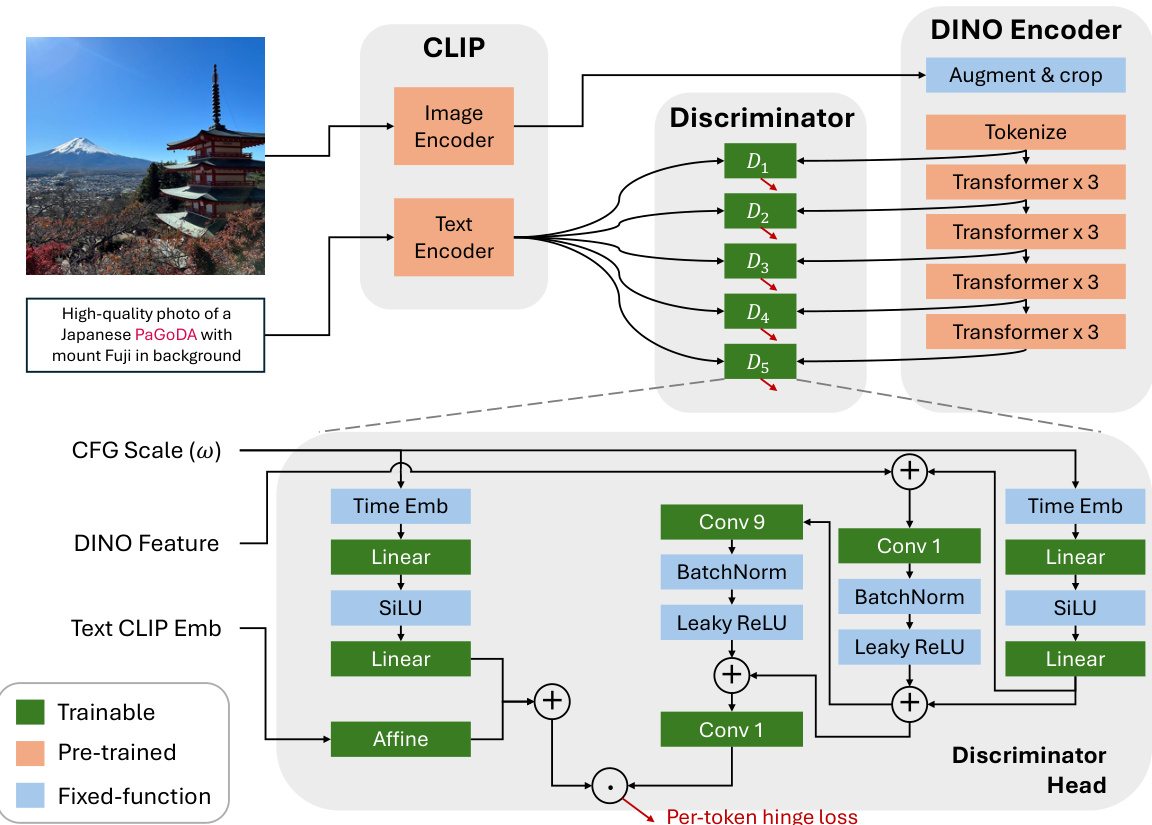
This figure shows the architecture of the discriminator used in PaGoDA. The discriminator takes as input DINO features, text CLIP embeddings, and the CFG (classifier-free guidance) scale (ω). It consists of multiple transformer blocks processing the text embedding and multiple convolutional layers processing the DINO features. The CFG scale is incorporated into the discriminator through an additional embedding that’s combined with the feature and text embeddings before being passed to the discriminator head. The per-token hinge loss is used for training the discriminator.
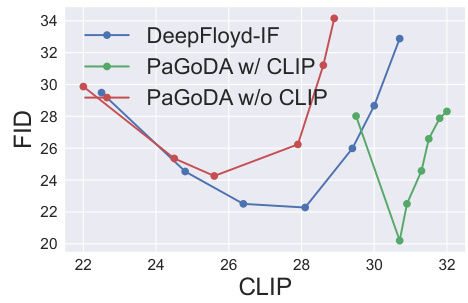
The figure shows the FID and CLIP scores for three different models: DeepFloyd-IF, PaGoDA with CLIP regularization, and PaGoDA without CLIP regularization. The x-axis represents the CLIP score, and the y-axis represents the FID score. The figure demonstrates that CLIP regularization improves both FID and CLIP scores, indicating improved sample quality and alignment between text and images.
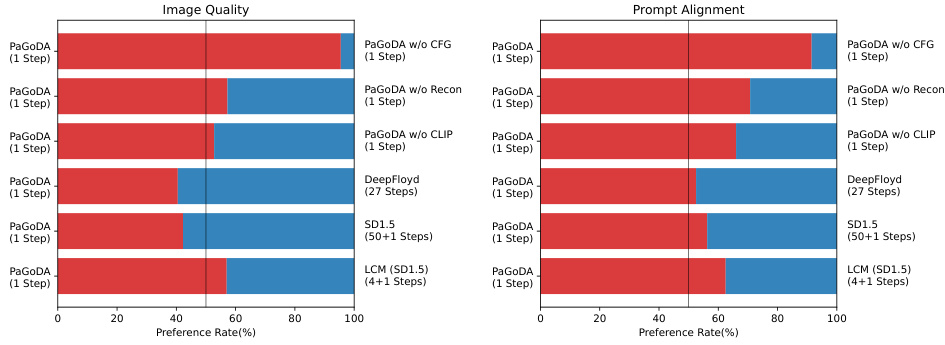
This figure shows the results of a human evaluation comparing the image quality and prompt alignment of different text-to-image models. The models compared include PaGoDA (with and without several components such as CFG, reconstruction loss, and CLIP), DeepFloyd, SD1.5, and LCM (SD1.5). The evaluation uses a preference rate, with higher scores indicating better performance. PaGoDA generally performs well against the other models, and removing key components negatively impacts its performance.
More on tables
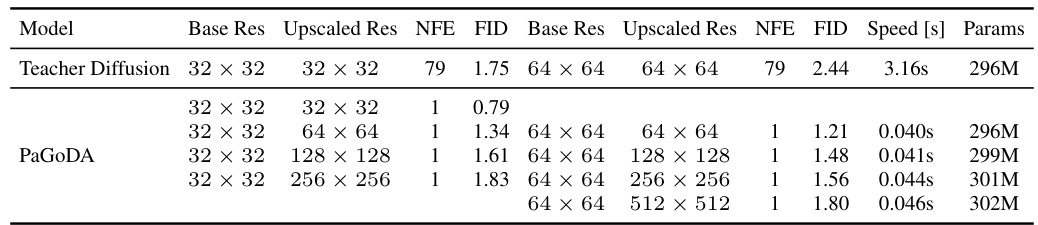
This table shows the ablation study of base resolution used in Stage 1 of PaGoDA. It compares the FID scores of PaGoDA trained on different base resolutions (32x32 and 64x64) and upscaled to various higher resolutions (64x64, 128x128, 256x256, 512x512). The table also includes the number of forward diffusion steps (NFE), training speed, and model parameters for each configuration, illustrating the computational efficiency of PaGoDA’s approach.
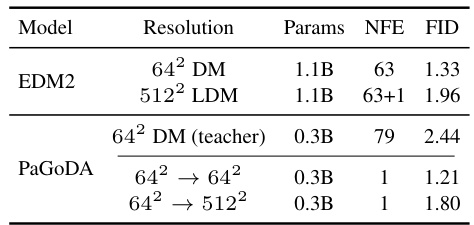
This table presents the ablation study of base resolution on PaGoDA. It shows the performance (FID) of PaGoDA models trained with different base resolutions (32x32 and 64x64) and upscaled to various resolutions (64x64, 128x128, 256x256, 512x512). The table also includes the number of function evaluations (NFE), inference speed, and the number of parameters in the models. It demonstrates the efficiency of PaGoDA in handling high resolutions even when starting from a lower-resolution base.
This table presents a comparison of PaGoDA’s performance against other state-of-the-art models on the ImageNet dataset for image generation. It shows the FID (Fréchet Inception Distance) and Inception Score (IS) metrics, along with the number of forward diffusion steps (NFE) and sampling speed. The results are broken down by resolution (64x64, 128x128, 256x256, and 512x512) and whether classifier-free guidance (CFG) was used. Lower FID scores indicate better image quality, higher IS scores indicate greater diversity, and faster sampling speeds mean better efficiency. PaGoDA consistently outperforms other methods across all resolutions.
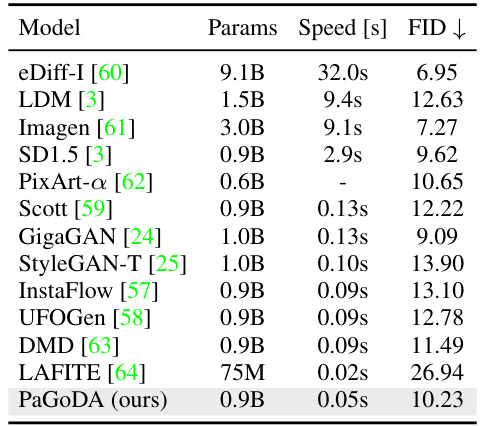
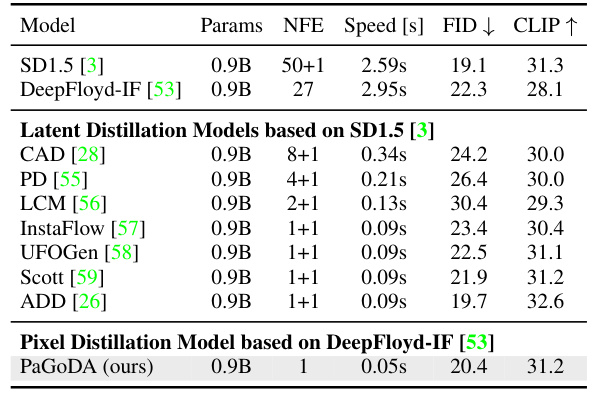
This table compares the performance of PaGoDA with other state-of-the-art Text-to-Image (T2I) models. The metrics used for comparison include FID (Fréchet Inception Distance) score on the MSCOCO-2014 validation dataset, speed (measured on an A100 GPU), and model parameters. The table highlights PaGoDA’s competitive performance in terms of FID and speed compared to much larger models.
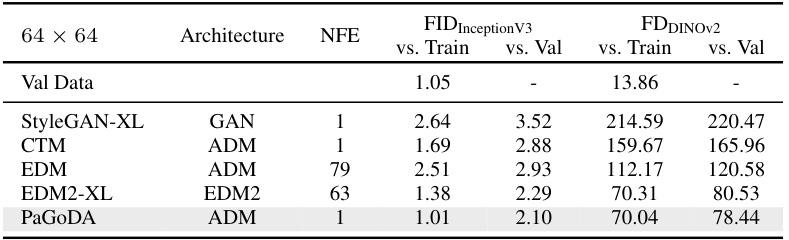
This table presents a quantitative comparison of different generative models on the ImageNet 64x64 dataset. It compares FID (Fréchet Inception Distance) and FD-DINOv2 scores, which measure the quality and diversity of generated images compared to real images from the validation set. The metrics are evaluated using 50,000 generated samples. The number of network evaluations (NFE) for each model is also included. The table highlights PaGoDA’s superior performance in terms of both FID and FD-DINOv2 scores compared to existing state-of-the-art models.
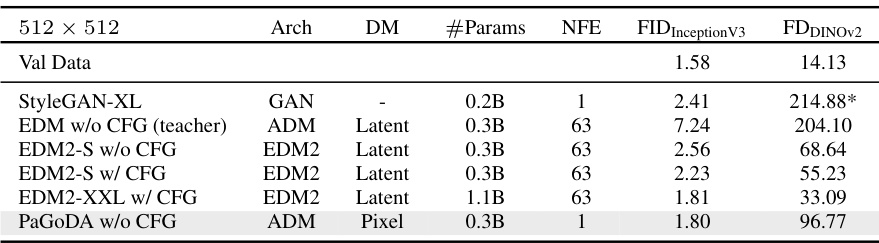
This table compares the performance of different models on ImageNet at 512x512 resolution. It shows FID and FDDINOv2 scores, key metrics for evaluating image quality and diversity. The table includes results for StyleGAN-XL, EDM with and without CFG, and PaGoDA with and without CFG, highlighting PaGoDA’s competitive performance and suggesting further experimentation with the EDM2 architecture.
This table presents a comparison of PaGoDA’s performance against other state-of-the-art models on the ImageNet dataset for image generation. It includes metrics such as Fréchet Inception Distance (FID), Inception Score (IS), and Recall, across different resolutions (64x64, 128x128, 256x256, and 512x512). The results showcase PaGoDA’s superior performance, particularly its ability to achieve state-of-the-art FID scores at all resolutions, even without classifier-free guidance (CFG). The table also compares results with and without CFG to demonstrate PaGoDA’s robustness.
Full paper#