TL;DR#
Current visual generative models rely on tokenizers specialized for either images or videos, limiting flexibility and scalability. This often results in suboptimal performance due to data scarcity in a single modality and lack of synergy between different visual data types. Moreover, existing joint image-video tokenizers often train separate models for each modality, failing to capture the true synergy between them.
OmniTokenizer tackles these issues with a transformer-based architecture that integrates window and causal attention for spatial-temporal modeling, enabling joint image-video tokenization. A progressive training strategy is introduced where the tokenizer is first pre-trained on images before joint training with video data, capitalizing on the complementary nature of both modalities. Extensive experiments demonstrate state-of-the-art reconstruction performance across various image and video datasets, showcasing the effectiveness of the proposed approach. Integration with language model-based and diffusion models further reveals superior visual synthesis capabilities, highlighting the versatility of OmniTokenizer.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel joint image-video tokenizer, addressing limitations of existing methods. This opens new avenues for visual generation, improving model versatility and scalability. Its state-of-the-art results on various datasets demonstrate significant advancements. The progressive training strategy and the unified framework are valuable contributions to the field. This research will likely inspire further research on multimodal tokenization and visual synthesis.
Visual Insights#
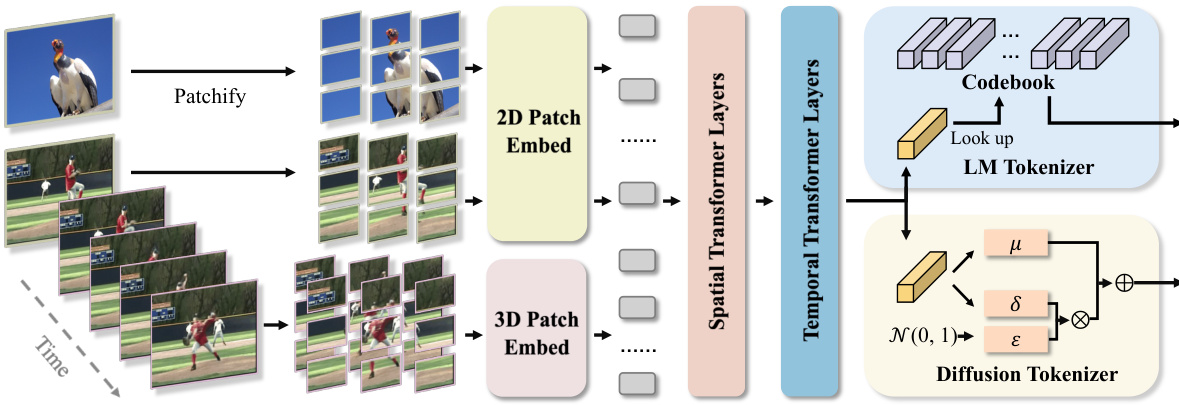
🔼 This figure illustrates the architecture of OmniTokenizer, a transformer-based tokenizer for joint image and video data. It shows how image and video patches are processed separately through embedding layers and then fed into spatial and temporal transformer layers. The output is then processed by two different tokenizers: an LM tokenizer using a codebook and a diffusion tokenizer sampling from a Gaussian distribution. The decoder is omitted for simplicity, focusing solely on the tokenization aspect.
read the caption
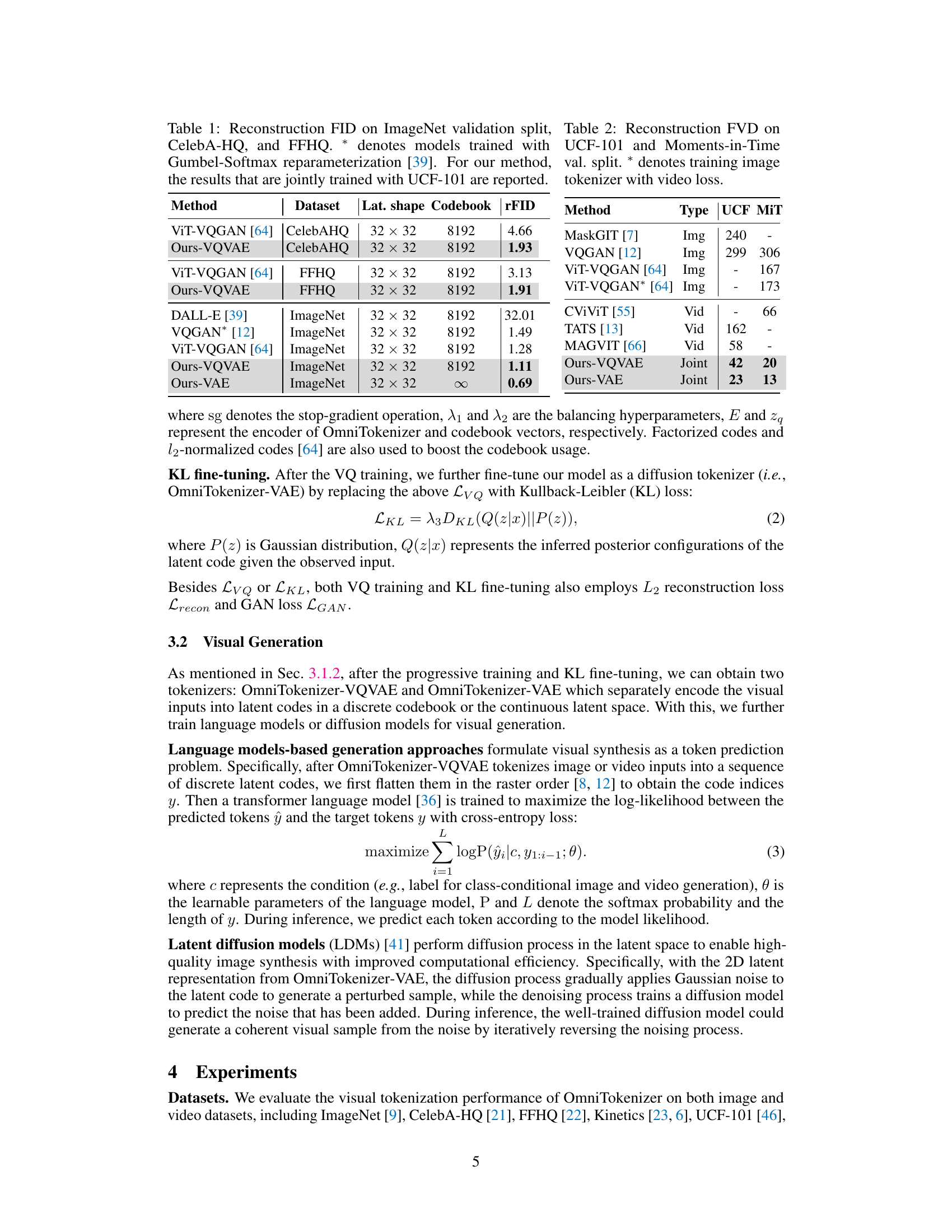
Figure 1: Architecture of OmniTokenizer, which consists of patch embedding layers, and separate spatial-temporal attention blocks. To obtain the latent representations, OmniTokenizer-VQVAE looks up a codebook to quantize the encoder embeddings, while OmniTokenizer-VAE samples from a Gaussian distribution. We omit the decoder and only show the tokenization process.
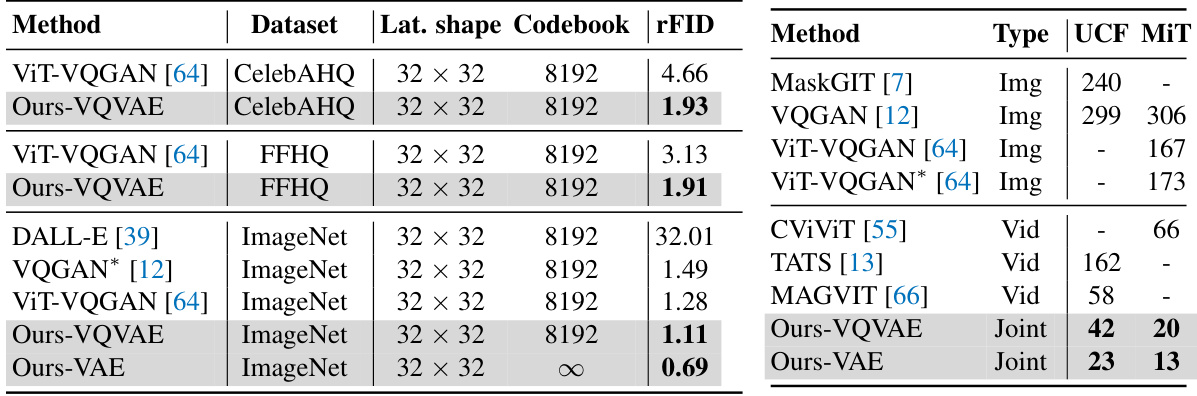
🔼 This table presents the reconstruction FID (Fréchet Inception Distance) scores for different models on three image datasets: ImageNet, CelebA-HQ, and FFHQ. The FID score measures the similarity between the generated images and real images; lower scores indicate better reconstruction quality. The table compares the performance of the proposed OmniTokenizer-VQVAE and OmniTokenizer-VAE models against several state-of-the-art methods. The results show that OmniTokenizer achieves significantly lower FID scores, demonstrating superior reconstruction performance.
read the caption
Table 1: Reconstruction FID on ImageNet validation split, CelebA-HQ, and FFHQ. * denotes models trained with Gumbel-Softmax reparameterization [39]. For our method, the results that are jointly trained with UCF-101 are reported.
In-depth insights#
Joint Tokenization#
The concept of ‘Joint Tokenization’ in the context of visual data processing is a significant advancement. It proposes a unified framework capable of handling both images and videos, unlike traditional methods that treat them as separate modalities. This unification allows for the exploitation of complementary information between the two data types, leading to improved performance in various downstream tasks. A key aspect is the synergy achieved, where the model learns a richer representation, potentially mitigating the challenges of data scarcity in one modality. The success relies heavily on the architecture’s ability to capture both spatial and temporal dynamics, likely through mechanisms like spatial-temporal decoupling and attention mechanisms tailored for each dimension. The results suggest a significant improvement in reconstruction accuracy when compared to independent image and video tokenization techniques, highlighting the effectiveness of the joint approach. Furthermore, the architecture’s ability to handle both LMs and diffusion models points towards a versatile and powerful method for visual generation. It represents a step towards more unified and comprehensive visual understanding and generative capabilities.
Progressive Training#
The concept of “Progressive Training” in the context of visual tokenization is a significant advancement. It addresses the challenge of training a model that effectively handles both image and video data by adopting a two-stage approach. First, the model is pre-trained on image data at a fixed resolution, allowing it to establish a robust understanding of spatial information. This initial stage focuses on the core task of static image representation learning. The subsequent stage introduces video data, enabling the model to learn the temporal dynamics, building upon the previously learned spatial features. This progressive strategy leverages the complementary nature of image and video data, facilitating the learning of a unified representation that captures both spatial and temporal aspects effectively. The gradual introduction of complexity improves training stability and efficiency, ultimately leading to a model that outperforms single-modality approaches in terms of reconstruction performance, and also enhances versatility, making the model applicable to diverse visual generation tasks.
Visual Synthesis#
Visual synthesis, the process of generating realistic images or videos from various inputs, is a core focus of the research. The paper investigates the crucial role of tokenization in achieving high-quality visual synthesis. The development of a joint image-video tokenizer is a significant contribution, allowing for unified processing of diverse visual data. This approach facilitates leveraging the complementary strengths of both image and video data for enhanced generative performance. A progressive training strategy, first focusing on image data and then jointly training on image and video, proves vital for learning robust and versatile visual representations. The effectiveness of the proposed tokenizer is demonstrated through improved reconstruction performance on several benchmark datasets. Importantly, the versatility of this new tokenizer is highlighted by its compatibility with both language model-based and diffusion model approaches, enabling advanced visual synthesis capabilities across different generative models. The research strongly suggests that a unified and efficient approach to tokenization represents a pivotal step toward substantial improvements in visual content generation.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of a research paper, these studies are crucial for understanding the interplay of different elements and isolating the effects of specific design choices. A well-designed ablation study will vary one aspect at a time, holding all other variables constant, to determine the impact of that component on the overall performance. This helps to validate the design decisions and potentially reveal unexpected interactions or redundancies. For instance, removing a particular module could show a significant drop in performance, thereby demonstrating its importance. Conversely, minimal impact suggests that component might be expendable, leading to simplification or optimization. The results of ablation studies are critical in establishing the generalizability of the model and demonstrating the robustness of the approach. They provide a deeper understanding of the methodology, contributing valuable insights beyond simply stating the final performance metrics.
Future Work#
Future research directions stemming from the OmniTokenizer paper could explore several promising avenues. Extending OmniTokenizer to handle more complex data modalities, such as point clouds or multi-spectral imagery, would significantly broaden its applicability. Investigating alternative attention mechanisms beyond window and causal attention, potentially incorporating more sophisticated spatiotemporal relationships, could improve performance and efficiency. A particularly intriguing area is exploring different training strategies, such as self-supervised learning or contrastive learning, to further enhance the model’s representation learning capabilities. Finally, applying OmniTokenizer to a wider range of downstream tasks, including video inpainting, generation of longer videos, and multi-modal video generation (incorporating text, audio, or other modalities), offers a wealth of opportunities to demonstrate its versatility and impact across various visual generation applications.
More visual insights#
More on figures
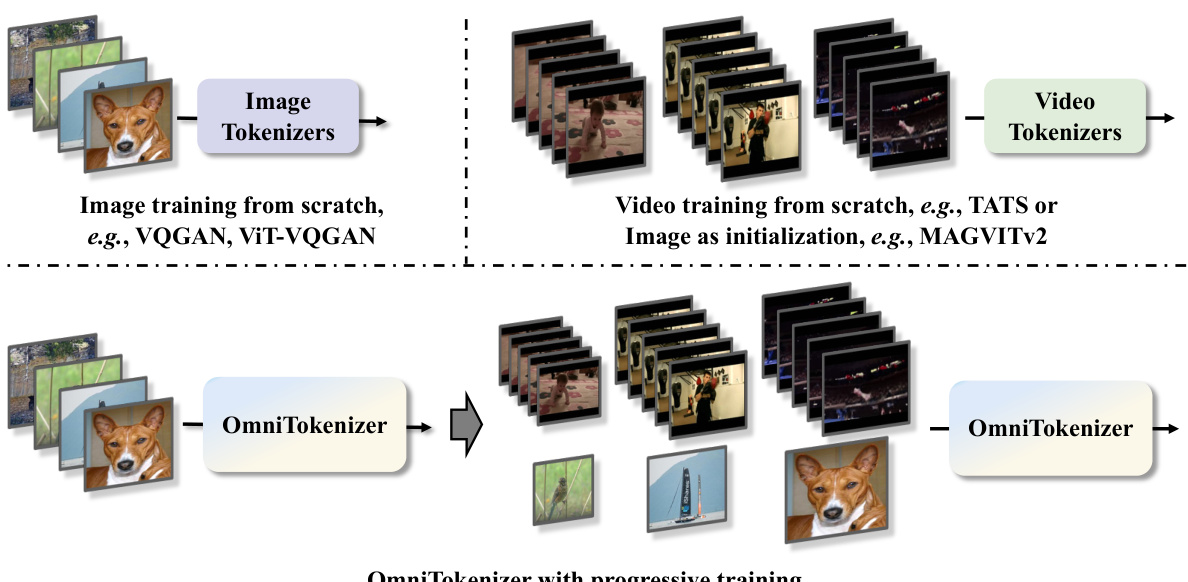
🔼 The figure illustrates the progressive training strategy used in OmniTokenizer. It shows that the model is first trained on image data alone (using existing image tokenizers like VQGAN or VIT-VQGAN as a starting point) to develop its spatial understanding. Then, it is jointly trained on both image and video data (potentially using methods like TATS or MAGVITv2 as video training initializations) to learn temporal dynamics. The result is a unified model (OmniTokenizer) capable of processing both image and video data using the same architecture and weights, demonstrating the synergy between the two modalities.
read the caption
Figure 2: Illustration of the proposed progressive training paradigm. With this, OmniTokenizer could tokenize both image and video inputs with the same architecture and weight.

🔼 This figure compares the image and video reconstruction capabilities of three different methods: VQGAN, TATS, and the proposed OmniTokenizer method. The top row shows ground truth (GT) images and videos. The second row shows the results from VQGAN, the third row shows the results from TATS, and the bottom row shows the results from OmniTokenizer. The red boxes highlight specific regions of the images and videos to better illustrate the differences in reconstruction quality between the methods. The figure visually demonstrates the superior reconstruction performance achieved by the OmniTokenizer method compared to the existing state-of-the-art techniques.
read the caption
Figure 3: Image and video reconstruction results of VQGAN [12], TATS [13], and our method.

🔼 This figure presents a comparison of image and video reconstruction results between three different methods: VQGAN, TATS, and the proposed OmniTokenizer method. The images showcase the superior performance of OmniTokenizer, particularly in reconstructing images with intricate details, such as faces and text. This demonstrates the effectiveness of the OmniTokenizer method in capturing complex visual information.
read the caption
Figure 3: Image and video reconstruction results of VQGAN [12], TATS [13], and our method.

🔼 This figure presents the architecture of OmniTokenizer, a transformer-based tokenizer for joint image and video processing. It shows two branches: one for OmniTokenizer-VQVAE (using a codebook for quantization) and one for OmniTokenizer-VAE (sampling from a Gaussian distribution). Both branches utilize patch embedding layers followed by spatial and temporal transformer layers to process image and video data, respectively. The decoder is omitted for simplicity, focusing only on the tokenization aspect.
read the caption
Figure 1: Architecture of OmniTokenizer, which consists of patch embedding layers, and separate spatial-temporal attention blocks. To obtain the latent representations, OmniTokenizer-VQVAE looks up a codebook to quantize the encoder embeddings, while OmniTokenizer-VAE samples from a Gaussian distribution. We omit the decoder and only show the tokenization process.

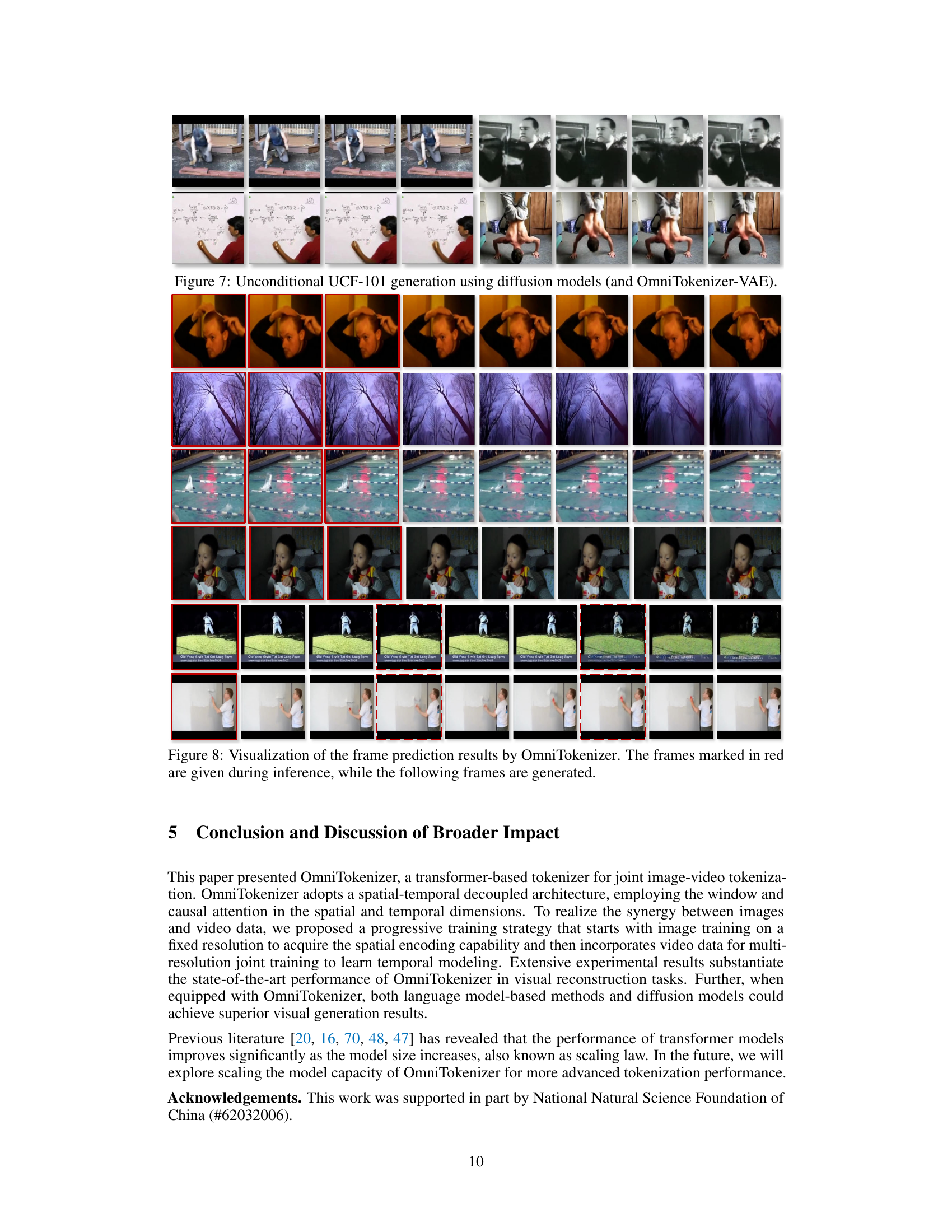
🔼 This figure visualizes the frame prediction capabilities of OmniTokenizer. The model is given a short sequence of frames (marked in red), and it predicts the subsequent frames. This demonstrates the model’s ability to extrapolate motion and temporal coherence, hinting at its potential for generating longer video sequences.
read the caption
Figure 8: Visualization of the frame prediction results by OmniTokenizer. The frames marked in red are given during inference, while the following frames are generated.
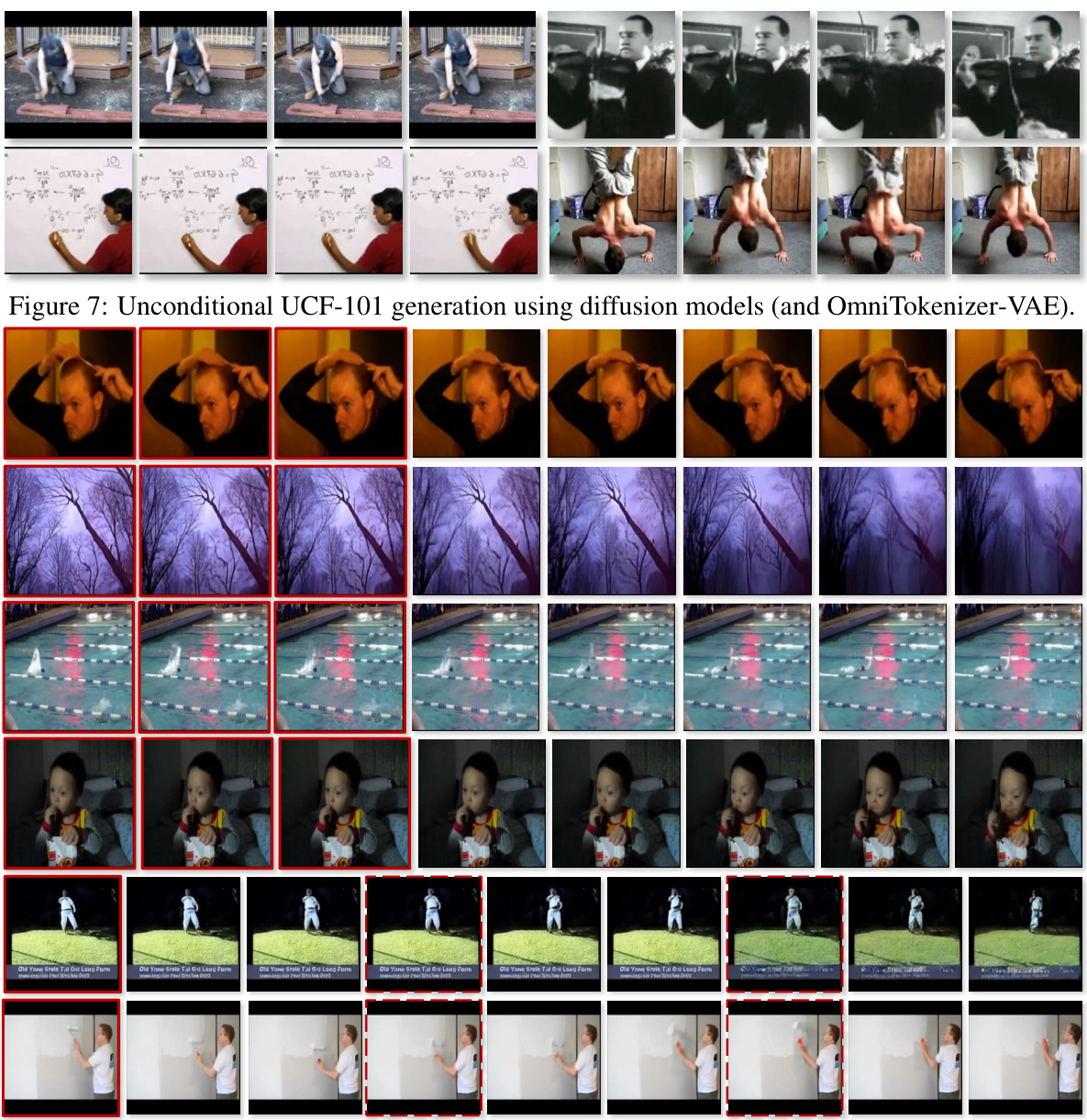
🔼 This figure shows several video sequences generated by diffusion models using OmniTokenizer-VAE for unconditional generation on the UCF-101 dataset. Each row represents a different generated video, demonstrating the model’s ability to produce various actions without specific prompts. The videos display a range of actions, showcasing the diversity achieved by the model.
read the caption
Figure 7: Unconditional UCF-101 generation using diffusion models (and OmniTokenizer-VAE).
More on tables
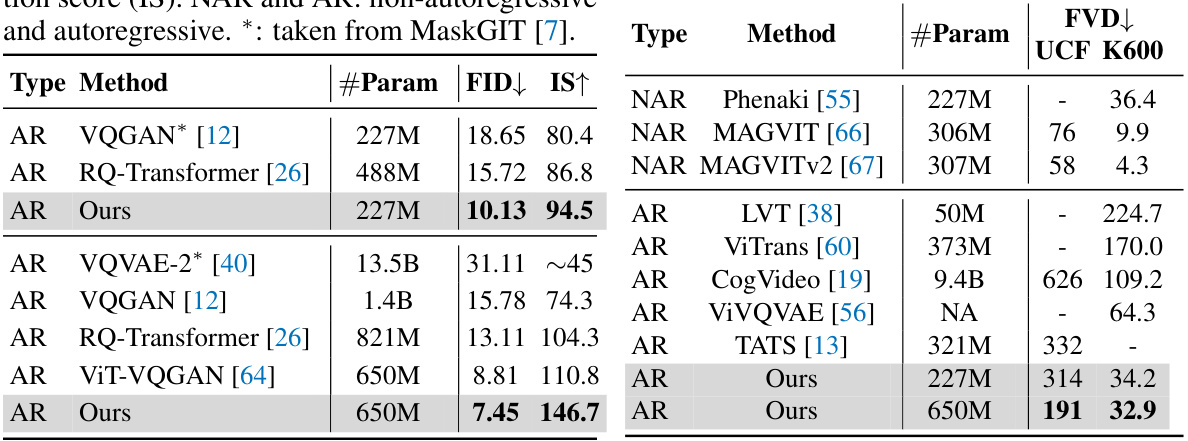
🔼 This table compares different autoregressive (AR) and non-autoregressive (NAR) language models for class-conditional image generation on the ImageNet dataset (256x256 resolution). The metrics used are Fréchet Inception Distance (FID) and Inception Score (IS), lower FID and higher IS indicating better performance. The table shows the number of parameters for each model.
read the caption
Table 3: Comparions of class-conditional results on ImageNet 256×256 using language models. “↓” (“↑”) indicates lower (higher) is better. Metrics include Fréchet inception distance (FID) and inception score (IS). NAR and AR: non-autoregressive and autoregressive. *: taken from MaskGIT [7].

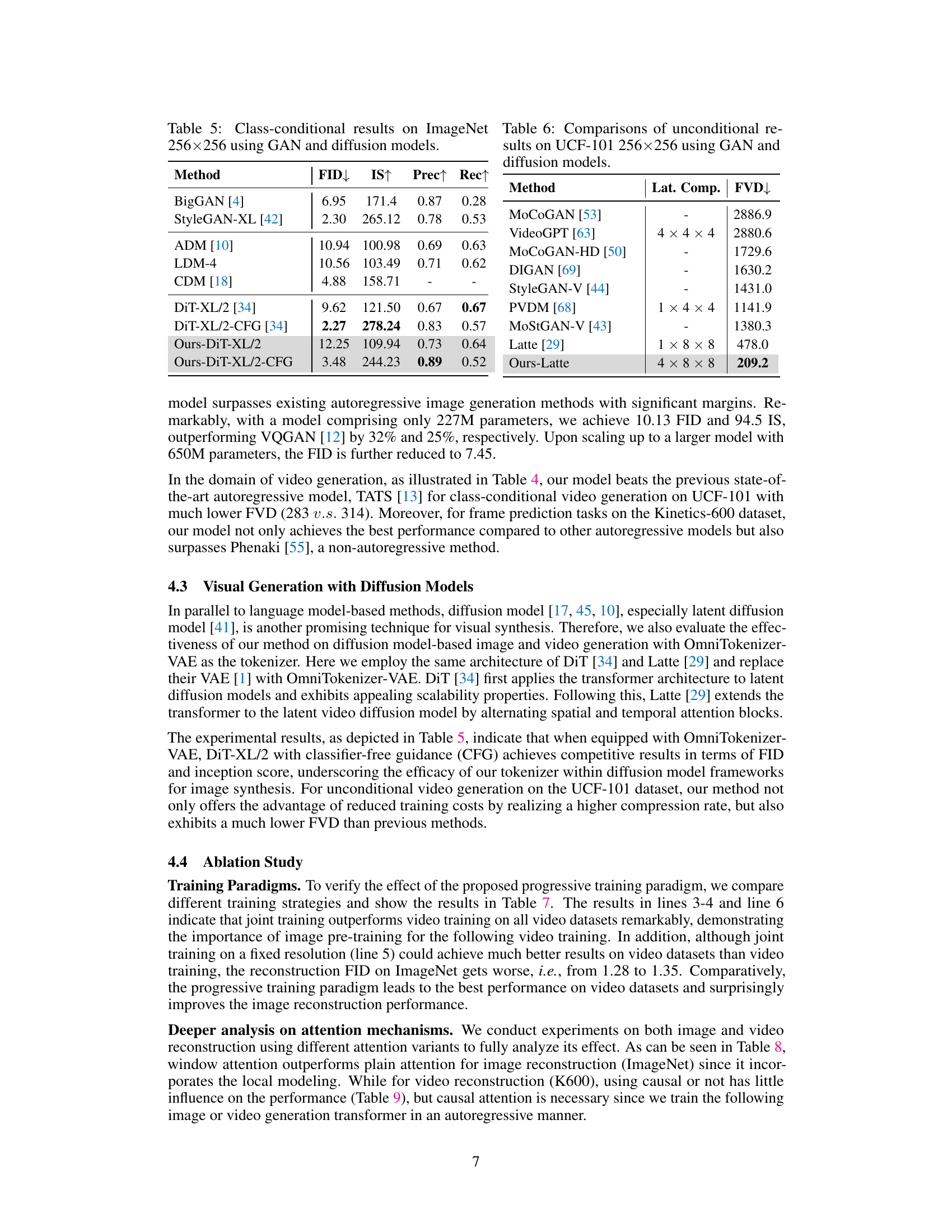
🔼 This table compares the performance of various GAN and diffusion models on the ImageNet dataset for class-conditional image generation. The metrics used are FID (Fréchet Inception Distance), IS (Inception Score), Precision, and Recall. Lower FID indicates better image quality. Higher IS, Precision, and Recall are desirable.
read the caption
Table 5: Class-conditional results on ImageNet 256x256 using GAN and diffusion models.
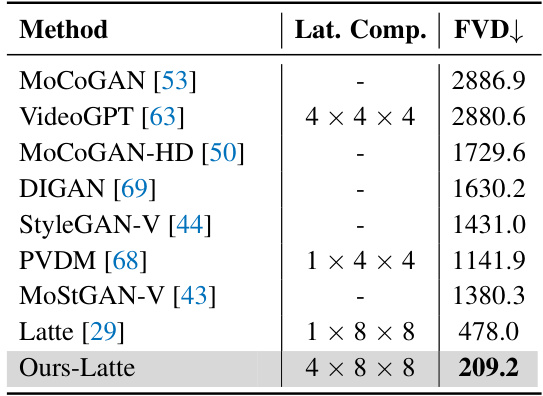
🔼 This table compares the unconditional video generation results on the UCF-101 dataset using various GAN and diffusion models. The metrics used for comparison are Fréchet Video Distance (FVD), a lower score indicating better performance. The table also shows the latent compression of each method. The ‘Ours-Latte’ row presents the results obtained when using the OmniTokenizer with the Latte model.
read the caption
Table 6: Comparisons of unconditional results on UCF-101 256x256 using GAN and diffusion models.
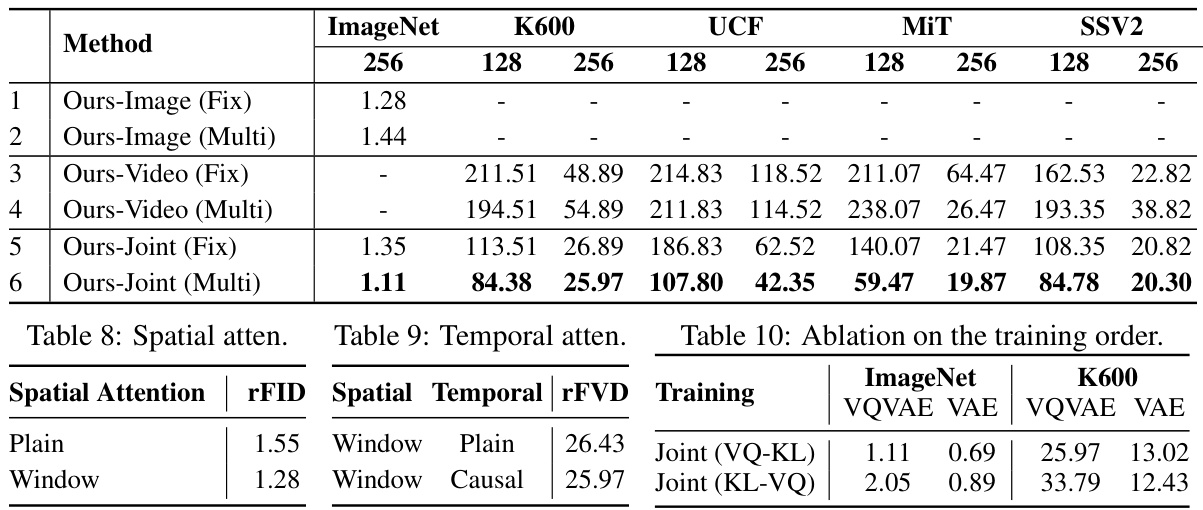
🔼 This table presents a comparison of reconstruction FID (Fréchet Inception Distance) scores on the ImageNet dataset and reconstruction FVD (Fréchet Video Distance) scores on various video datasets. The table compares different training strategies for the OmniTokenizer model: training only on images with fixed or multiple resolutions, training only on videos with fixed or multiple resolutions, and joint training on images and videos with multiple resolutions. The results show the impact of different training strategies on the model’s performance for both image and video reconstruction tasks.
read the caption
Table 7: Comparison of rFID on ImageNet and rFVD on various video datasets.
Full paper#