↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current diffusion-based human image animation methods struggle with generating high-quality videos when the input reference image and target pose are not well-aligned in terms of scale and rotation. This compositional misalignment is very common in real-world scenarios and reduces the practical usefulness of the technology. The inconsistency and low fidelity in outputs stem from the diffusion model’s reliance on visual similarity between reference image and target pose; when they are misaligned, the attention mechanism can fail to accurately match relevant features, resulting in artifacts and inconsistencies.
To address this, the authors propose Test-time Procrustes Calibration (TPC). This method pre-processes the reference image using Procrustes analysis to align its human shape with the target pose before feeding it into the diffusion model. By doing so, TPC ensures that the model’s attention mechanism is always properly guided, resulting in improved fidelity and consistency of the output animation even in cases with compositional misalignment. Experimental results on various benchmarks and datasets demonstrate TPC’s effectiveness in improving animation quality, especially when dealing with real-world scenarios and compositional misalignment. The method is shown to be model-agnostic and easily adaptable to a range of diffusion-based animation systems.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles a significant challenge in diffusion-based human image animation: inconsistent output quality due to misalignment between reference and target images. This is a common issue hindering practical applications. The proposed solution, TPC, enhances robustness and generalizes well, opening new avenues for improving image animation and related generative models. Its model-agnostic nature makes it broadly applicable, impacting various fields using similar techniques.
Visual Insights#
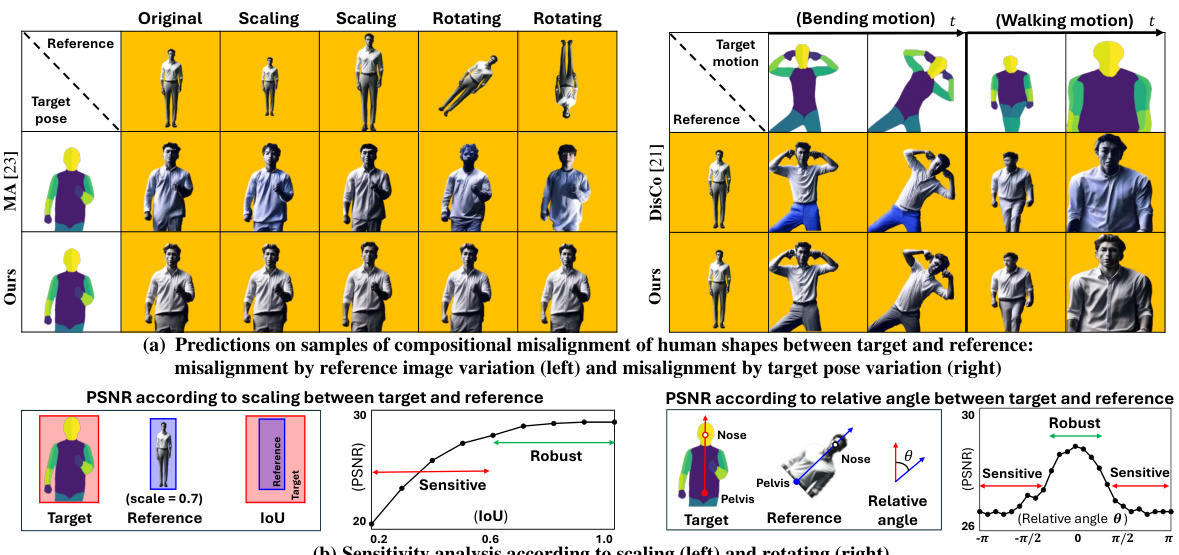
This figure shows the impact of compositional misalignment on human image animation. (a) demonstrates that current methods struggle when the scale or rotation of the human in the reference image differs from that in the target pose. Inconsistent results with varying fidelity are shown when scaling or rotating the reference image, and low fidelity is consistently observed when providing motion sequences with varying dynamic movements. (b) provides a sensitivity analysis showing the performance drop in terms of PSNR (Peak Signal-to-Noise Ratio) and IoU (Intersection over Union) as compositional misalignment (scaling and rotation) increases.
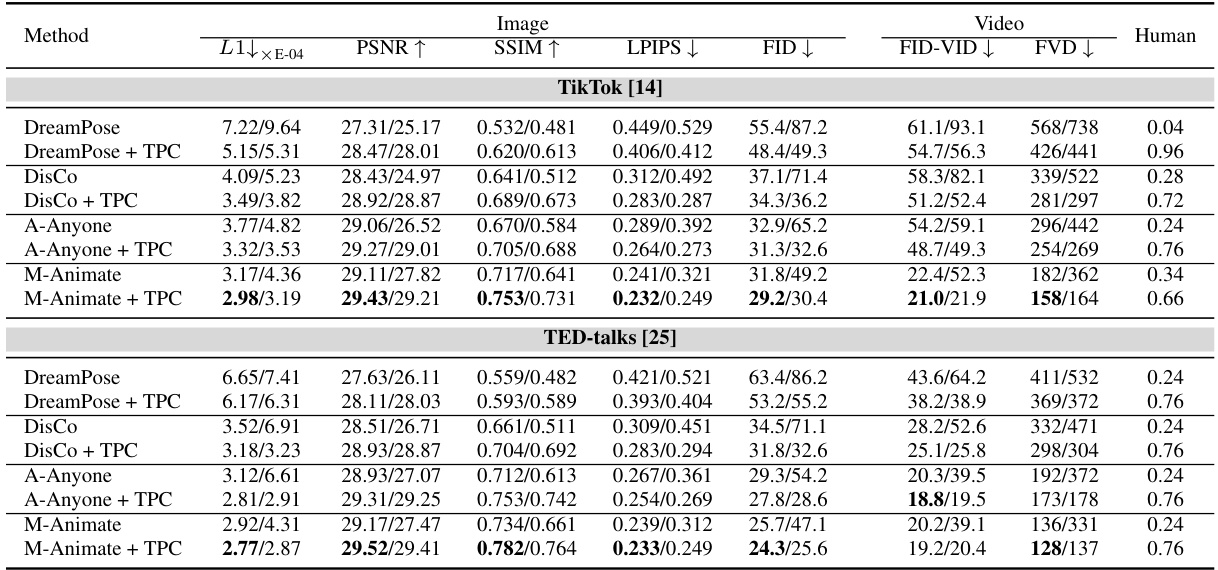
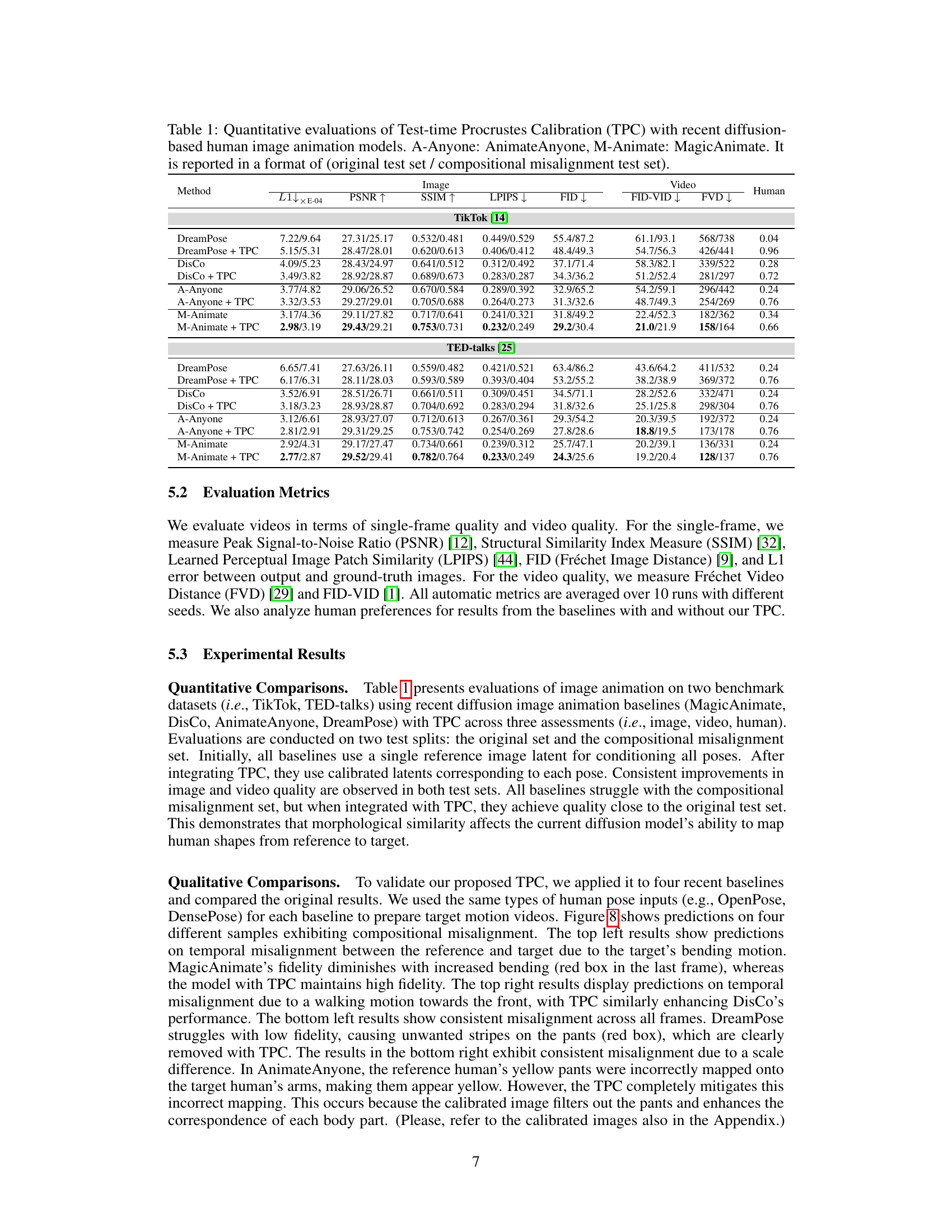
This table presents a quantitative comparison of different human image animation methods, with and without the proposed Test-time Procrustes Calibration (TPC). It evaluates the performance on two datasets (TikTok and TED-talks) across various metrics, including L1 error, PSNR, SSIM, LPIPS, FID, FID-VID, and FVD. Results are shown for both the original test set and a subset with compositional misalignment, highlighting the effectiveness of TPC in improving robustness to misalignment.
In-depth insights#
Procrustes Calibration#
Procrustes calibration, in the context of diffusion-based human image animation, addresses a critical challenge: maintaining consistent animation quality despite variations in the composition (scale and rotation) of the human shapes between the reference image and target frames. The core idea is to pre-process the reference image to align its composition with the target frame before feeding it to the diffusion model. This alignment, achieved through Procrustes analysis, ensures that the model’s attention mechanism focuses on corresponding features, improving the fidelity and temporal consistency of generated animations. The method’s strength lies in its model-agnostic nature, making it broadly applicable to existing diffusion-based animation systems without requiring retraining. However, limitations remain. While Procrustes calibration enhances robustness, it might not fully resolve issues arising from significant variations in body shape or pose between reference and target. Furthermore, the computational cost of Procrustes analysis for each frame, though manageable, could become an obstacle for real-time applications. Therefore, future improvements could focus on more efficient calibration techniques, possibly integrating deep learning methods for faster and more robust alignment.
Diffusion Robustness#
Diffusion models, while powerful, often exhibit sensitivity to input variations, impacting the quality and consistency of generated outputs. A key challenge lies in diffusion robustness, particularly concerning the effects of compositional misalignment between reference and target images in image animation tasks. This issue arises when scale, rotation, or other physical properties of the human subject differ between the reference image used for identity transfer and the target pose frame. Addressing diffusion robustness requires methods that effectively handle such discrepancies, maintaining high fidelity and coherence even under real-world conditions where perfect alignment is unlikely. Strategies to improve robustness might include data augmentation techniques that incorporate diverse compositional transformations during training, or model-agnostic calibration methods that adapt the reference image to better align with the target before it is fed into the diffusion model. The latter approach is particularly promising for practical application, as it allows enhancing existing models without requiring retraining. Ultimately, improving diffusion robustness is crucial for enabling reliable and practical image animation applications in diverse real-world scenarios.
Attention Mechanism#
Attention mechanisms are crucial in deep learning models for processing sequential data, allowing the model to focus on the most relevant parts of the input. In sequence-to-sequence models, they enable the model to selectively attend to different parts of the input sequence when generating each element of the output sequence. This is particularly valuable when dealing with long sequences where not all parts are equally important to the final output. Self-attention mechanisms, which attend to different parts of the same sequence, are especially powerful, capturing relationships between distant words in a sentence or elements in other sequences. Multi-head attention, which combines the outputs of multiple attention mechanisms, can capture diverse relationships. These mechanisms have shown great success in tasks like machine translation, text summarization, and image captioning. However, a key challenge lies in the computational complexity of attention, especially in self-attention, where complexity scales quadratically with the sequence length. Therefore, efficient approximations such as linear attention or sparse attention are important for handling very long sequences.
Model-Agnostic TPC#
The concept of “Model-Agnostic TPC” suggests a versatile and adaptable approach to enhancing human image animation. Instead of being tied to a specific diffusion model architecture, this method operates as a general-purpose calibration technique. It functions by aligning the compositional aspects (scale and rotation) between reference and target images before feeding them into any existing diffusion-based system. This “pre-processing” step ensures consistent and high-fidelity output regardless of the underlying animation model, making it particularly valuable for real-world applications where perfect alignment might be difficult to achieve. The method’s independence from any particular model architecture translates to improved robustness and broader applicability, while simplifying implementation and reducing the need for extensive model-specific training. Its effectiveness hinges on its ability to effectively capture and address compositional misalignments, a common source of inconsistencies in image animation tasks. A significant advantage is the potential for easy integration with diverse diffusion models, thereby maximizing the overall fidelity and effectiveness of the animation process.
Future Enhancements#
Future enhancements for this research could involve exploring more sophisticated methods for aligning human shapes between reference and target images, potentially leveraging advanced techniques in computer vision and 3D modeling. Improving the robustness to variations in lighting and pose is crucial for real-world applicability. Investigating the use of additional modalities, such as audio and text, to enhance the conditioning process could significantly improve the quality and expressiveness of the generated animations. Furthermore, researching techniques to improve the temporal consistency of the generated videos, ensuring smoother and more natural transitions, is essential. Addressing scalability and computational efficiency challenges will be critical for broader adoption of this technology. Finally, in-depth investigation into ethical implications and the development of safeguards against misuse are paramount for responsible technology deployment.
More visual insights#
More on figures

This figure shows how the attention mechanism of a diffusion model focuses on different parts of the reference image depending on the alignment between the target pose and reference image. When the shapes are aligned (top), the attention correctly focuses on the corresponding shoulder. When misaligned (bottom), the attention is scattered across unrelated areas.

This figure illustrates the architecture of a diffusion-based human image animation system (a) and how the proposed Test-time Procrustes Calibration (TPC) method is integrated into it (b). In (a), a reference image and a target pose are used as inputs for a diffusion model with a UNet architecture, generating an animation frame as output. In (b), a calibration branch is added using TPC, which generates a calibrated reference image latent feature, improving the model’s ability to understand the correspondence between human shapes in the reference and target images. This enhances the overall quality of the generated animation by handling compositional misalignments.
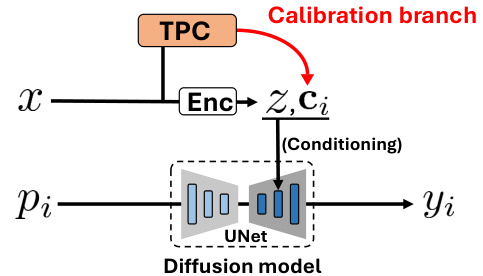
This figure illustrates the architecture of a diffusion-based human image animation system with and without the proposed Test-time Procrustes Calibration (TPC). Panel (a) shows a standard system where a reference image (x) and a target pose (pi) are fed into an encoder (Enc), which generates latent features (z) used to condition a diffusion model (UNet) that produces the animated frame (yi). Panel (b) shows the enhanced system incorporating TPC. A calibration branch, processing the reference image through the TPC module, adds a calibrated latent feature (ci) to the conditioning input, improving the accuracy and stability of the animation despite variations in the composition of the reference and target images.
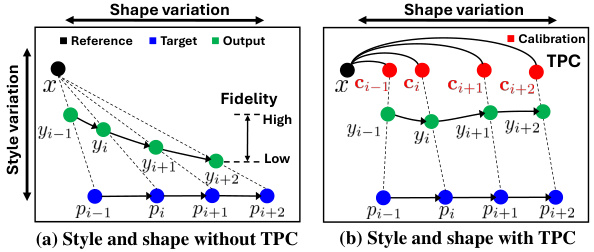
This figure conceptually illustrates how TPC improves the robustness of diffusion-based human image animation systems to compositional misalignment. Panel (a) shows the existing scenario without TPC where style and shape variations lead to low fidelity outputs when the reference and target human shapes are not well-aligned. In contrast, panel (b) demonstrates how TPC, by introducing a calibrated reference image, bridges the gap between reference and target shapes, enabling consistent high-fidelity animation outputs even under significant compositional misalignment.

This figure illustrates the proposed Test-time Procrustes Calibration (TPC) method for enhancing diffusion-based human image animation. The process begins with a reference image and a target pose sequence. Procrustes Warping aligns the shapes in the reference image to match the target poses, creating a calibrated reference image. This image is then processed by an iterative propagation module to ensure temporal consistency in the output animation. Finally, the calibrated latent features are fed into a diffusion model along with the original reference features to generate the final animated video. The figure shows the flow of data and the key components of the TPC method.
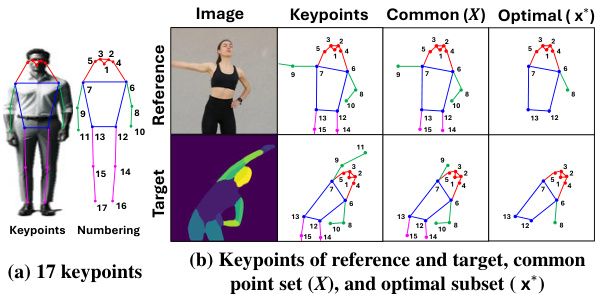
This figure shows the keypoints used in Procrustes Warping. (a) depicts the 17 keypoints selected to represent human shape, numbered for reference. (b) illustrates the process of selecting an optimal subset of keypoints for alignment. The reference and target images both have sets of 17 keypoints identified; a common subset (X) is selected from these points, representing features visible in both images. Further refinement selects the optimal subset (x*), focusing on the keypoints most crucial for accurate shape matching during the Procrustes alignment process. This subset is used to reduce the influence of keypoints which differ between the reference and target images due to differences in pose or other factors, leading to a more precise alignment.

This figure illustrates the iterative propagation process used in Test-time Procrustes Calibration (TPC). The process enhances temporal consistency among calibrated latent features by grouping sequential features and updating all features within a group with a randomly selected feature from that group. This helps to maintain consistent visual correspondence between the reference image and the target pose sequence throughout the animation process, even when there’s compositional misalignment between them. The process is applied during each denoising step of the diffusion model.

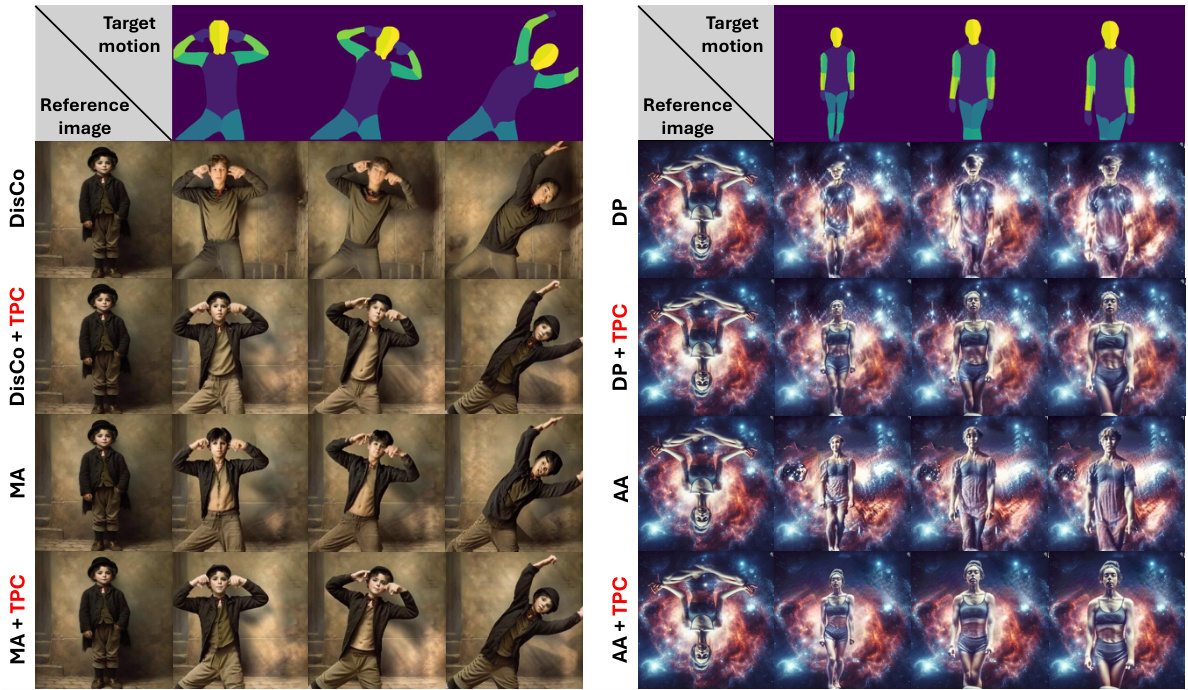
This figure demonstrates the effectiveness of Test-time Procrustes Calibration (TPC) in addressing compositional misalignment issues in human image animation. It showcases qualitative results comparing four different diffusion-based methods (MagicAnimate, DisCo, AnimateAnyone, DreamPose) with and without TPC applied. The results highlight how TPC improves the quality and consistency of generated animations, even when the reference image and target motion have misaligned composition (scale and rotation).
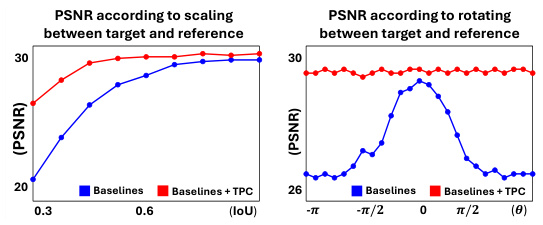
This figure demonstrates the impact of compositional misalignment on human image animation. Panel (a) shows examples of animation results from current models when the reference image and target pose have misaligned compositions (scale and rotation). The results show a decrease in fidelity and consistency. Panel (b) presents a quantitative sensitivity analysis illustrating the effect of scale and rotation differences on the performance of current models, measured as PSNR and IoU, showing that the models are sensitive to even small deviations from alignment.
This figure shows the qualitative results of applying Test-time Procrustes Calibration (TPC) to four different diffusion-based human image animation models. It demonstrates the impact of TPC on handling compositional misalignments (differences in scale and rotation) between the reference image and target poses. The examples illustrate how TPC improves the quality and consistency of the generated animations, particularly in challenging scenarios with significant misalignments.

This figure compares the results of applying an affine transformation versus a Procrustes transformation to calibrate reference images for human image animation. It visually demonstrates how the Procrustes transformation, which accounts for scaling, rotation, and translation, achieves better alignment of human shapes than the affine transformation, leading to more accurate and consistent animation results. This highlights the effectiveness of the Procrustes method used in the TPC (Test-time Procrustes Calibration) approach described in the paper.
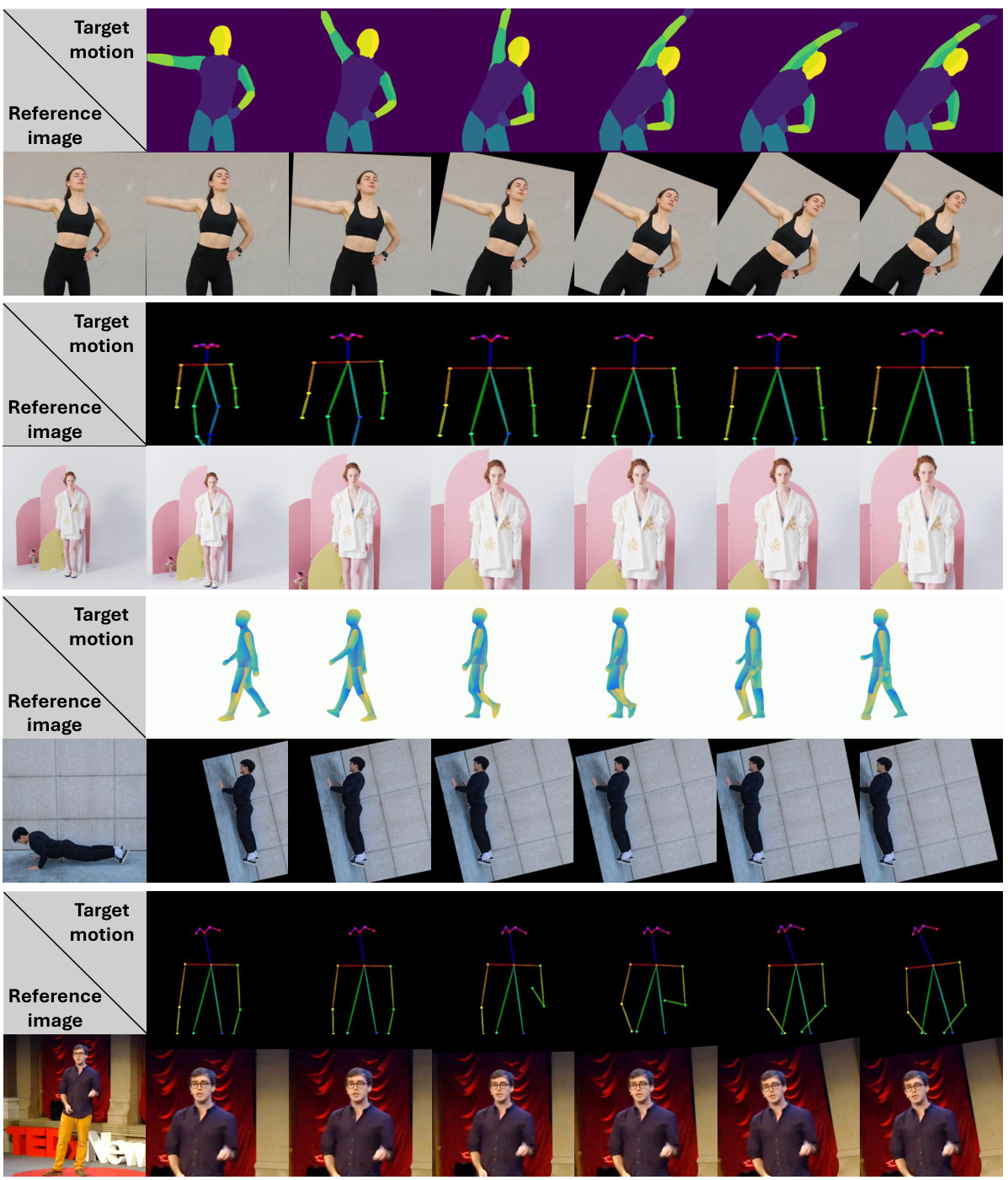
This figure demonstrates the effectiveness of Test-time Procrustes Calibration (TPC) in handling compositional misalignment in human image animation. It showcases four different scenarios with varying degrees of misalignment (rotation and scale) and shows how TPC improves the generated animation quality compared to baseline models. The top row depicts temporal misalignment due to bending and walking motions, while the bottom row shows consistent misalignment due to scaling and rotation. Each scenario includes ground truth, results without TPC, and results with TPC.

This figure displays qualitative results demonstrating the effectiveness of Test-time Procrustes Calibration (TPC) in handling compositional misalignment during human image animation. Four different models (MagicAnimate, DisCo, AnimateAnyone, DreamPose) are used, showcasing their performance with and without TPC on four cases of misalignment. The results illustrate that TPC improves the image quality and consistency in animation outputs, especially in challenging scenarios.

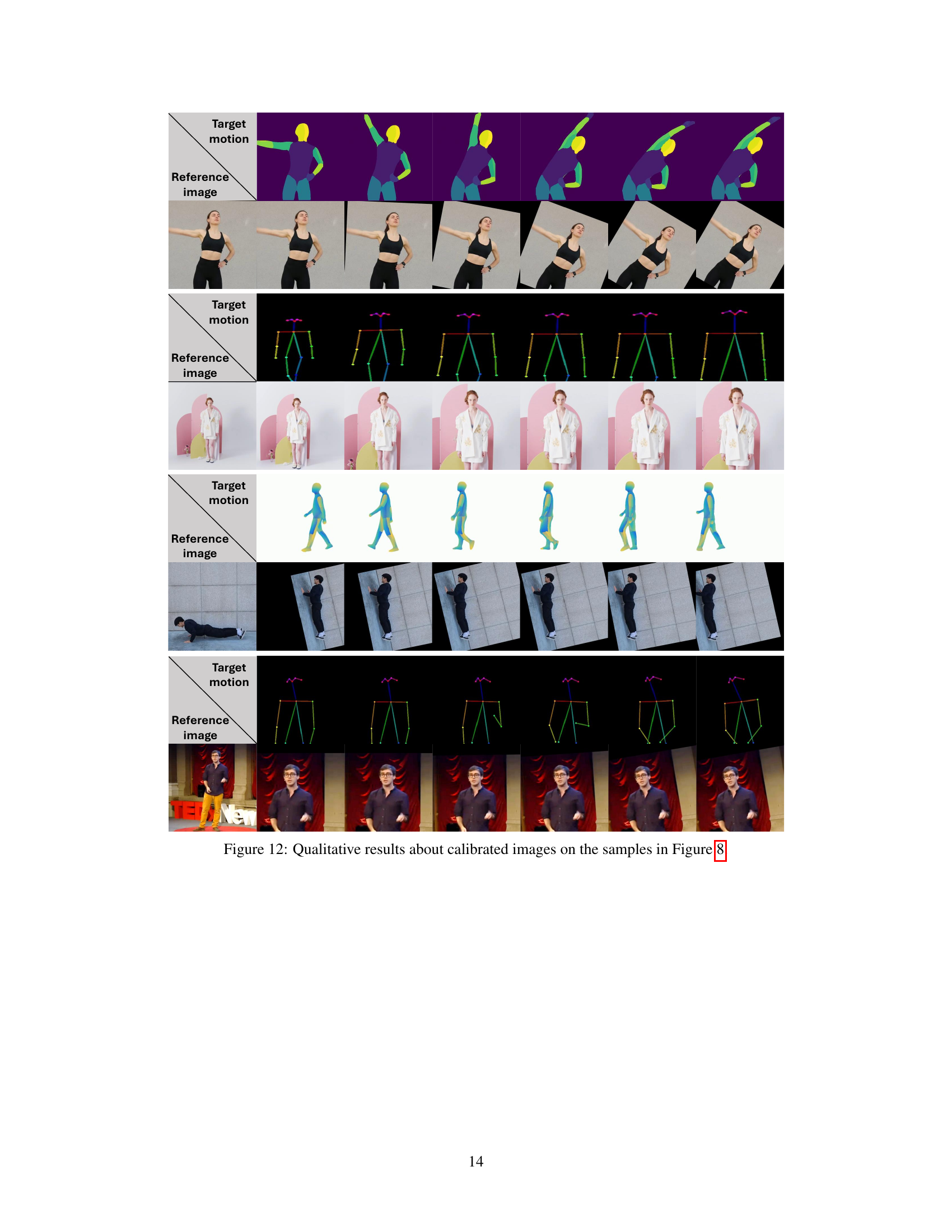
This figure shows a comparison between the original results from four different diffusion-based human image animation models (DreamPose, MagicAnimate, DisCo, and AnimateAnyone) and the results obtained after applying the proposed Test-time Procrustes Calibration (TPC) method. The results are shown for four different samples that exhibit compositional misalignment between the reference image and the target motion, as illustrated in Figure 8. The images illustrate how TPC improves the quality and consistency of the generated animation, especially in challenging scenarios where there is a significant compositional misalignment.

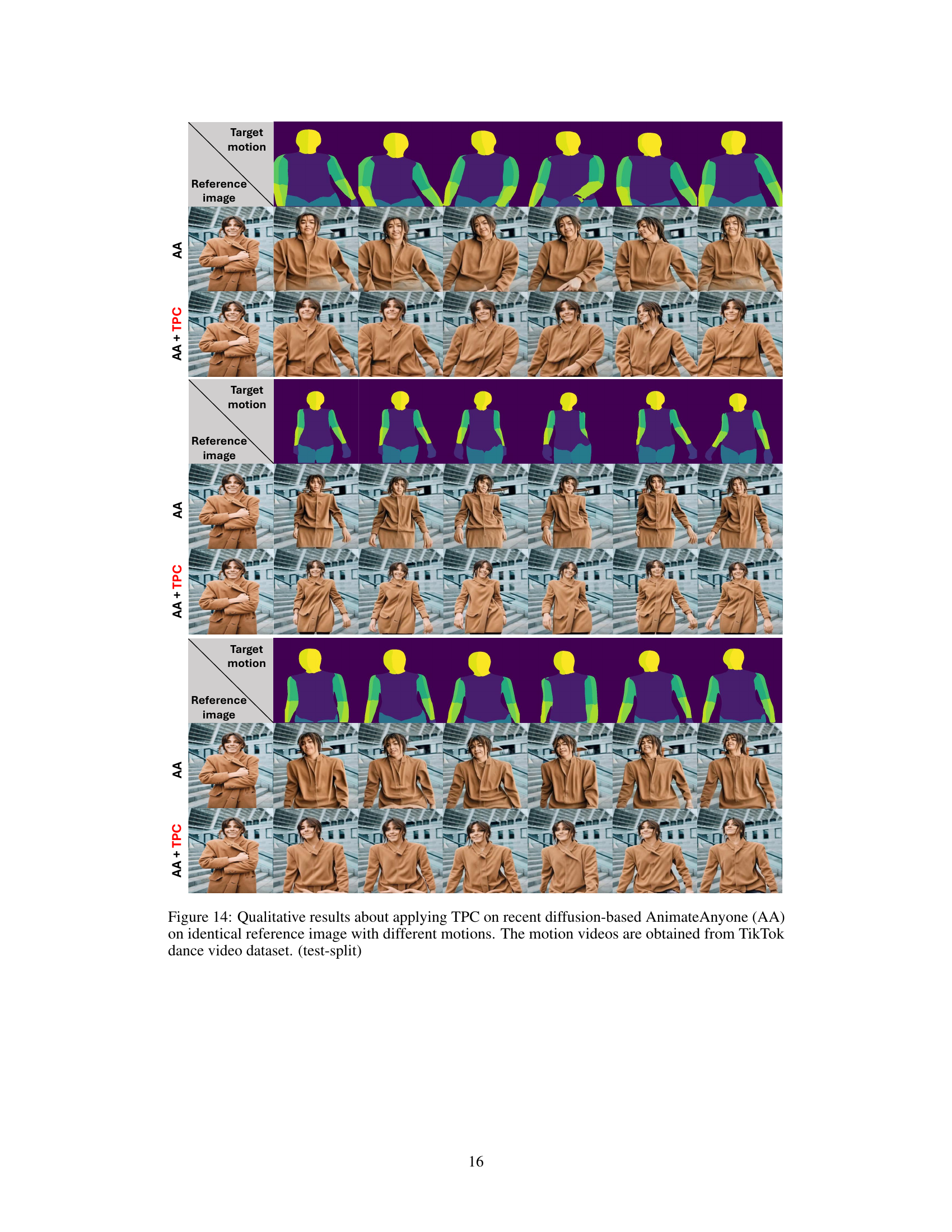
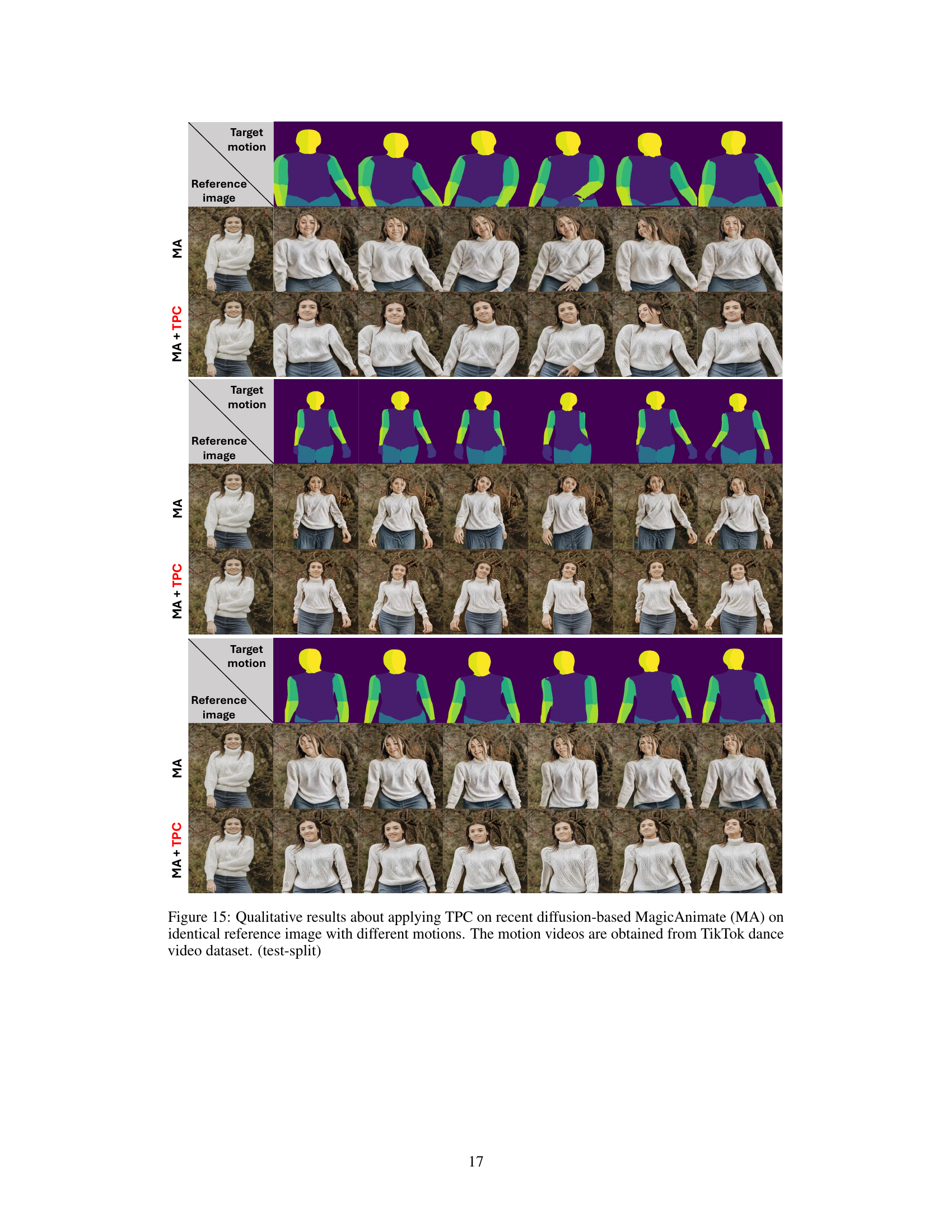
This figure shows a comparison of animation results between the MagicAnimate model alone and the same model enhanced with Test-time Procrustes Calibration (TPC). The experiment uses an identical reference image but varies the target motion videos from the TikTok dance dataset. The goal is to demonstrate how TPC improves robustness and consistency in human image animation when the target pose significantly differs from the reference image.

This figure shows qualitative results of applying Test-time Procrustes Calibration (TPC) to four different diffusion-based human image animation models (MagicAnimate, DisCo, AnimateAnyone, and DreamPose). It demonstrates TPC’s effectiveness in handling compositional misalignments between reference and target images under various scenarios: temporal misalignment due to rotation or scale changes, and consistent misalignment due to rotation or scale differences. The results highlight TPC’s ability to improve image quality and consistency by aligning human shapes in the reference and target images.
More on tables

This table presents the results of ablation studies conducted to evaluate the impact of different transformation methods (Linear, Affine, Procrustes) and the iterative propagation (IP) technique on the performance of the proposed Test-time Procrustes Calibration (TPC) method. The experiments were performed on two benchmark datasets, TED-talks and TikTok, using both compositional alignment and misalignment test splits. The table shows SSIM and FVD scores for both foreground and background, allowing for a comparison of the different approaches and their effectiveness in enhancing image animation quality.
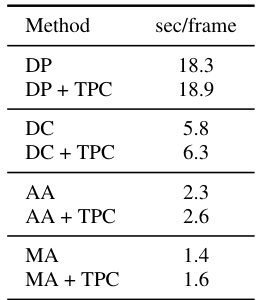
This table presents quantitative results of image and video quality using several metrics, comparing different diffusion-based human image animation models (DreamPose, DisCo, AnimateAnyone, MagicAnimate) with and without the proposed TPC method. The results are shown for two test sets: a standard test set and a specifically designed ‘compositional misalignment’ test set that evaluates model performance under conditions where the human shapes in the reference image and target pose are misaligned. The metrics used include L1 error, PSNR, SSIM, LPIPS, FID, FID-VID and FVD.

This table presents a quantitative comparison of different human image animation models, with and without the proposed Test-time Procrustes Calibration (TPC) method. It shows the performance of several state-of-the-art models on two datasets, TikTok and TED-talks. The results are broken down by different metrics (L1, PSNR, SSIM, LPIPS, FID, FID-VID, FVD) and are shown separately for the original test set and a test set with compositional misalignment (i.e., scale and rotation differences between the reference image and target pose). This allows for assessing the impact of TPC on model robustness in handling real-world scenarios where perfect alignment is unlikely.
Full paper#