↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Unsupervised anomaly detection is crucial in many fields, but the ‘black box’ nature of many machine learning models hinders understanding and trust. Existing methods often provide oversimplified explanations or struggle with high-dimensional data. This limits their usefulness in high-stakes applications where decisions must be transparent and reliable.
This paper introduces a new method, using a Segmentation Clustering Decision Tree (SCD-Tree) to break down data distributions and a Gaussian Boundary Delineation (GBD) algorithm to refine boundaries, generating an interpretable rule set. Experiments on various datasets and models demonstrate superior explanation accuracy, fidelity, and robustness, improving the interpretability of black-box anomaly detection and enhancing trust in automated systems. The method is especially relevant for high-stakes sectors like cybersecurity and IoT.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in anomaly detection and machine learning due to its focus on interpretability in high-stakes applications. The proposed SCD-Tree and GBD method offer a novel approach to extract rule-based explanations from complex models, enhancing transparency and trust, which is highly relevant to current research trends in explainable AI (XAI). It also opens up avenues for further research in high-dimensional data analysis and adapting explanations to dynamic environments.
Visual Insights#

This figure illustrates the integrated pipeline of the proposed anomaly detection and interpretation method. It starts with data preprocessing and normalization, followed by anomaly detection using various learning models (AE, IForest, SVM, Neural Networks). The SCD-Tree then segments the data based on the anomaly scores, and GBD refines the boundaries within each segment. Finally, rules are extracted to explain the model’s decisions. The figure visually depicts each step of the process, including data representation, model outputs, tree structures, and boundary delineation, providing a comprehensive overview of the method’s workflow.

This table presents the accuracy results of four different unsupervised anomaly detection models (Autoencoders, Variational Autoencoders, One-Class SVM, and Isolation Forest) applied to four distinct datasets representing various security domains (Web Security, IoT Security, and Cybersecurity). Each dataset is characterized by the number of features, the percentage of normal data instances, and the percentage of attack instances. The table demonstrates the performance of each model in terms of accuracy on each dataset, providing insights into their effectiveness in detecting anomalies within different security contexts and data characteristics.
In-depth insights#
Black Box Dissection#
Black Box Dissection in the context of machine learning, particularly within anomaly detection, refers to the methods and techniques used to understand and interpret the inner workings of complex models. These models, often referred to as “black boxes,” provide predictions without readily available explanations. The goal of Black Box Dissection is to gain insight into the decision-making process, improve trust in the model’s predictions, and potentially enhance model performance. This is achieved through various techniques, such as extracting rules, creating surrogate models, or employing visualization methods. A key challenge lies in balancing interpretability with the model’s accuracy and complexity. Oversimplification can lead to a loss of fidelity, while overly complex explanations may hinder the usability and comprehension for human users. Effective Black Box Dissection techniques should be model-agnostic and robust to diverse datasets and model architectures. The benefits extend beyond improved understanding; it often reveals valuable insights into the underlying data distribution, enhances model debugging, and facilitates the design of more transparent and trustworthy AI systems. Key aspects of Black Box Dissection often involve dealing with high-dimensional data and generating human-understandable rules or explanations.
SCD-Tree & GBD#
The proposed method uses a novel Segmentation Clustering Decision Tree (SCD-Tree) to dissect the structure of normal data distributions. Unlike traditional decision trees, the SCD-Tree incorporates anomaly detection model predictions into its splitting criteria, enhancing its ability to separate normal and anomalous data. This is followed by a Gaussian Boundary Delineation (GBD) algorithm that refines the segments by defining precise boundaries between normal and anomalous data points using Gaussian Processes. This two-stage process effectively addresses the curse of dimensionality, and its flexible boundary fitting ensures resilience against data variability. The combined approach transforms the complex operations of anomaly detection into an interpretable rule-based format, providing both robust performance and enhanced explainability. SCD-Tree excels at handling high-dimensional multimodal data, while GBD’s probabilistic framework enhances accuracy and model transparency. The overall system is designed to improve the reliability and trustworthiness of unsupervised anomaly detection, particularly in high-stakes sectors.
Rule Extraction#
Rule extraction in the context of this research paper is a crucial process that bridges the gap between complex, black-box anomaly detection models and human-understandable insights. The objective is to transform the model’s intricate internal workings into a set of easily interpretable rules. This is achieved by analyzing the decision boundaries identified by the model, typically through the visualization of data clusters. The resultant rules offer a simplified, yet informative representation of the model’s classification logic, allowing for a detailed analysis of how it categorizes normal and anomalous data points. The method’s effectiveness hinges on its ability to accurately capture the model’s decision boundaries without oversimplification. This means preserving crucial nuance and detail while still maintaining clarity and ease of understanding for non-experts. Therefore, the fidelity of the rule extraction process is paramount, ensuring that the extracted rules faithfully represent the original model’s behavior. Robustness and precision are additional critical factors, especially in high-stakes scenarios where the consequences of misinterpretations are significant. The successful extraction of such rules enhances the model’s trustworthiness and enables users to better understand its decision-making process.
High-Stakes Trust#
In high-stakes domains, trust in AI systems is paramount. Decisions made by AI models can have significant consequences, impacting safety, security, and operational success. This is especially true in sectors like healthcare and finance, where incorrect predictions can lead to severe outcomes. Achieving high-stakes trust requires not only accurate predictions but also transparency and explainability. People need to understand why a system made a particular decision, especially if it’s critical or unexpected. Rule-based explanations can improve trust by providing clear and understandable rationales. However, merely approximating the behavior of a complex black-box model isn’t sufficient; the explanations need to be accurate, robust, and comprehensive. A reliable high-stakes AI system needs to demonstrate consistently accurate performance and be resilient to various conditions and perturbations in its environment.
Future Directions#
Future research should prioritize enhancing the adaptability of interpretable anomaly detection models to dynamic, real-world conditions. This includes developing methods that can continuously learn and adjust their explanations in response to new data patterns and evolving environments. Integrating interpretable anomaly detection methods into decentralized edge computing systems holds immense promise for accelerating real-time decision-making in applications like cybersecurity and IoT. This requires exploring efficient and scalable techniques for deploying these models on resource-constrained devices while maintaining high accuracy and interpretability. Furthermore, a more thorough investigation into the human-in-the-loop aspect is needed. User studies incorporating domain experts can offer valuable insights for refining the interpretability and trustworthiness of these methods, fostering greater trust and adoption. Investigating the limitations of current methods for handling complex, unstructured data and non-linear decision boundaries is essential, and new techniques to address this limitation are crucial.
More visual insights#
More on tables
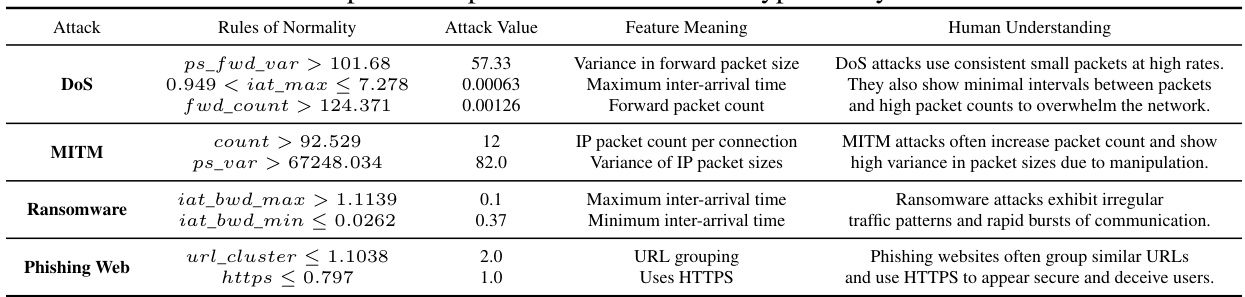
This table presents examples of rules extracted by the proposed method for different types of cyberattacks. Each row shows a different type of attack (DoS, MITM, Ransomware, Phishing Web) along with the rules generated by the model to identify them. For each rule, the table shows the attack value (how much the feature deviates from the norm during the attack), the feature meaning (what the feature represents), and a human-understandable explanation of why that rule helps detect that attack type.
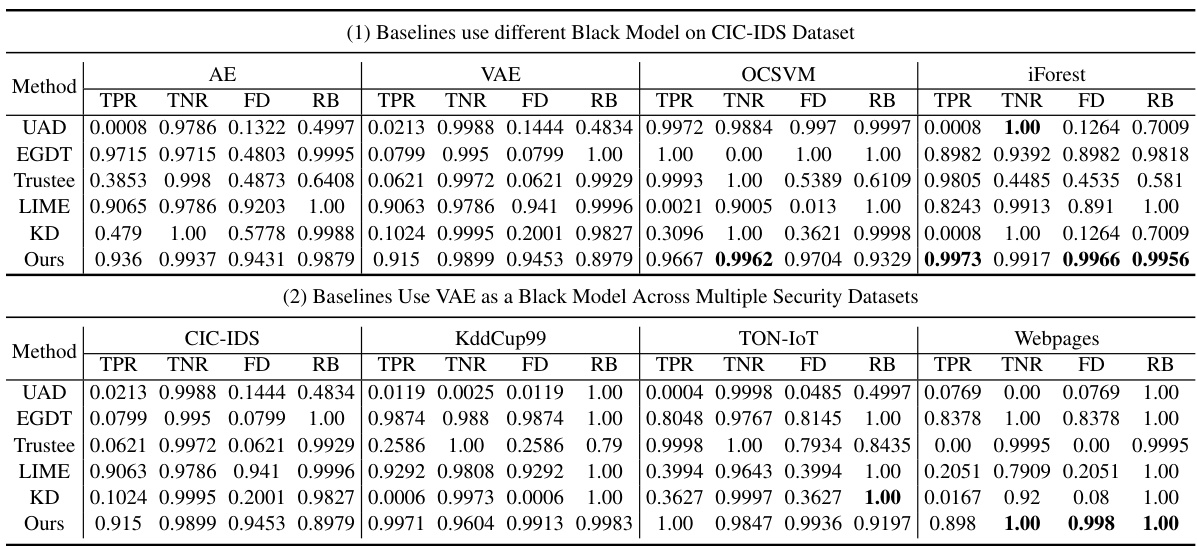
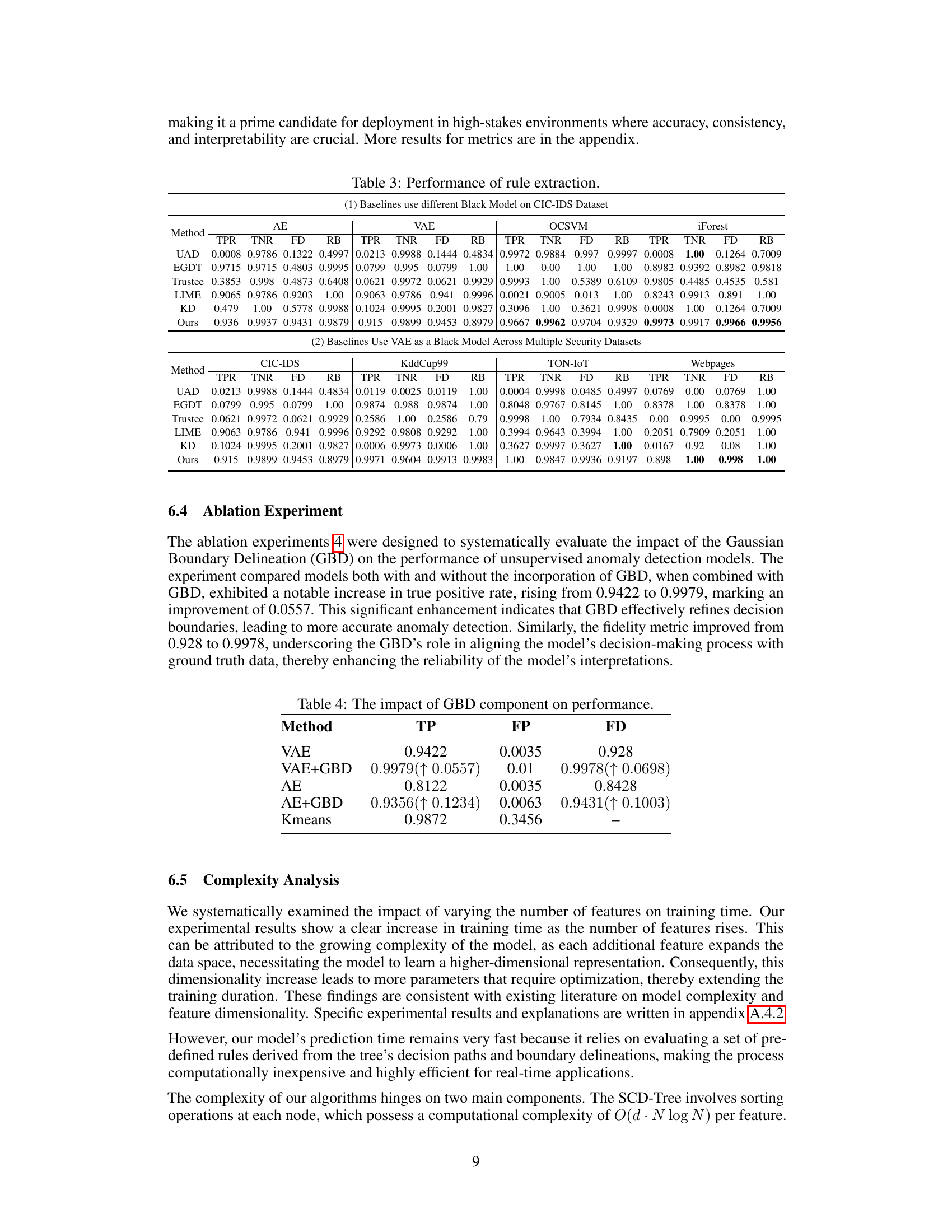
This table presents a comparison of the proposed method’s performance against five baseline methods (UAD, EGDT, Trustee, LIME, KD) in terms of True Positive Rate (TPR), True Negative Rate (TNR), Fidelity (FD), and Robustness (RB). The results are shown for different anomaly detection models (AE, VAE, OCSVM, iForest) and are broken down for different datasets (CIC-IDS, KddCup99, TON-IoT, Webpages). The table demonstrates the superior performance of the proposed method across all metrics and datasets.
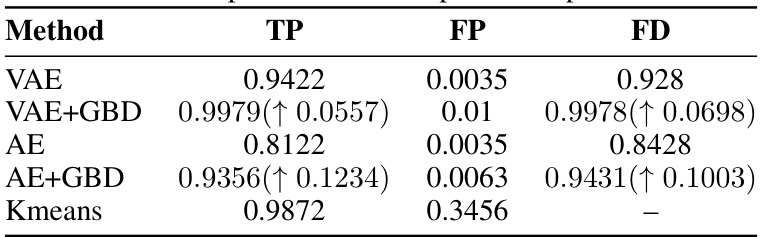
This table presents the results of an ablation study comparing the performance of VAE and AE models with and without the Gaussian Boundary Delineation (GBD) method. The metrics reported are True Positive (TP) rate, False Positive (FP) rate, and Fidelity (FD). The increase in TP rate and FD when using GBD indicates that GBD effectively refines decision boundaries, resulting in more accurate anomaly detection.
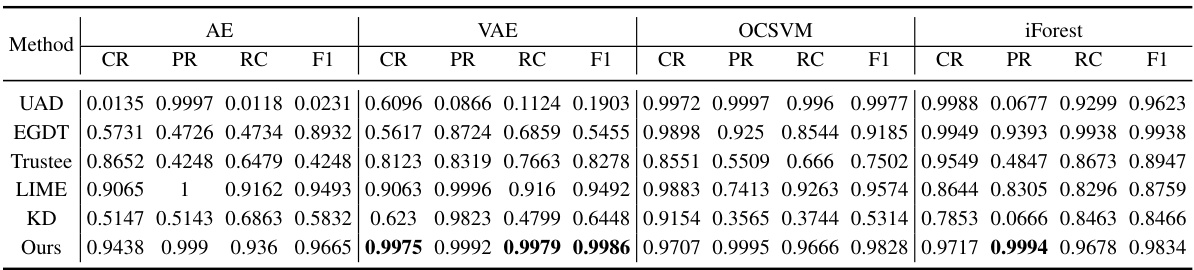
This table presents the performance comparison of six different methods for rule extraction on the CIC-IDS2017 dataset using four different anomaly detection models: Autoencoder (AE), Variational Autoencoder (VAE), One-Class SVM (OCSVM), and Isolation Forest (iForest). The methods compared are UAD, EGDT, Trustee, LIME, KD, and the authors’ proposed method. Evaluation metrics include Classification Rate (CR), Precision (PR), Recall (RC), and F1 score (F1). The table shows the superior performance of the authors’ proposed method compared to baselines across all metrics and models. High CR, PR, RC, and F1 scores indicate the effectiveness of the method.

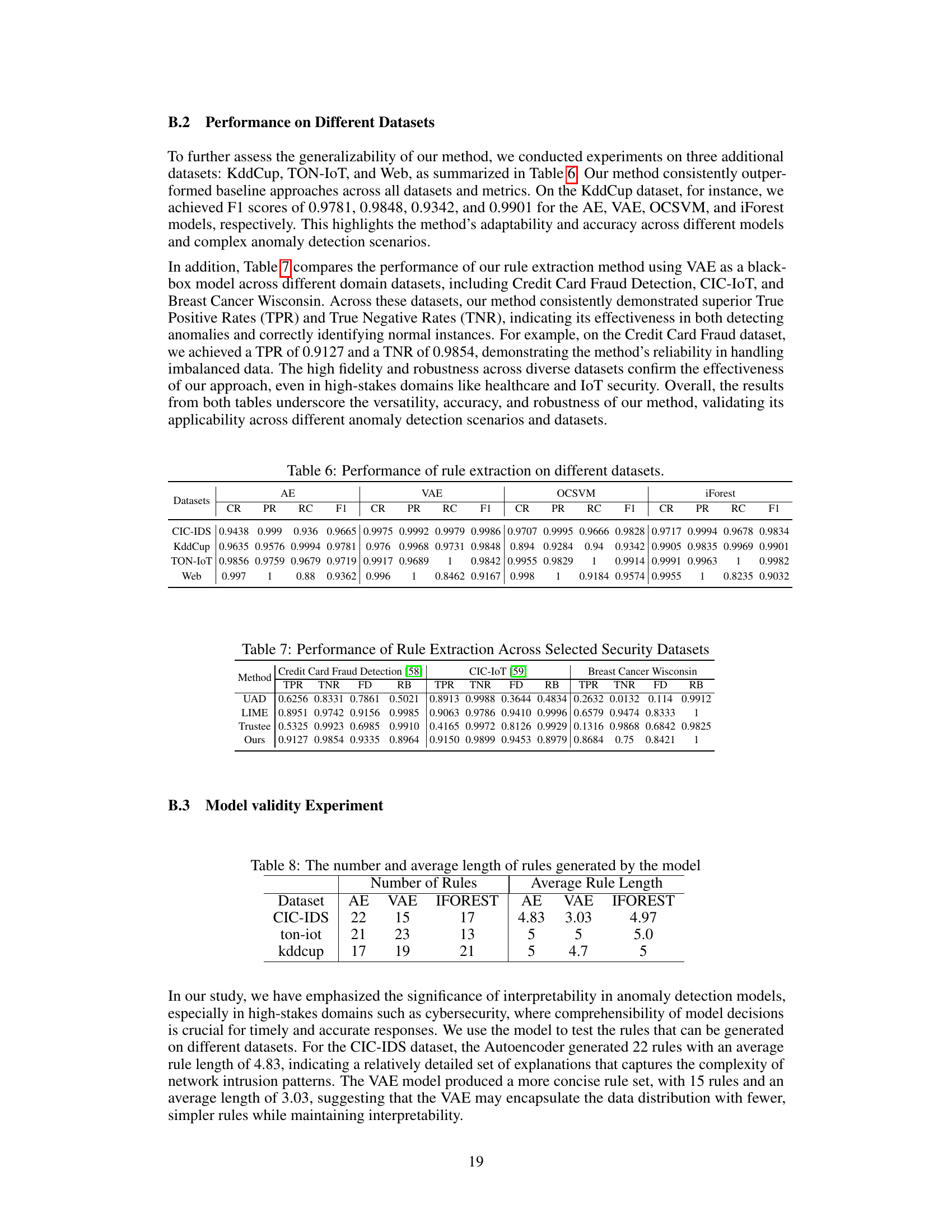
This table presents the accuracy results for four different unsupervised anomaly detection models (Autoencoder (AE), Variational Autoencoder (VAE), One-Class SVM (OCSVM), and Isolation Forest (iForest)) applied to four different datasets from security-related domains. Each dataset has a different number of features and a different proportion of normal and attack data. The accuracy is calculated as the percentage of correctly classified instances. The table shows the performance of each model on each dataset, indicating which models perform best on specific types of data. The results can help to understand the strengths and weaknesses of different anomaly detection techniques for different security applications.

This table compares the performance of the proposed rule extraction method against baseline methods (UAD, LIME, Trustee) across three security-related datasets: Credit Card Fraud Detection, CIC-IoT, and Breast Cancer Wisconsin. The metrics used are True Positive Rate (TPR), True Negative Rate (TNR), Fidelity (FD), and Robustness (RB). The results highlight the superior performance of the proposed method in terms of TPR, TNR, and FD across all three datasets, demonstrating its effectiveness and reliability in various scenarios.
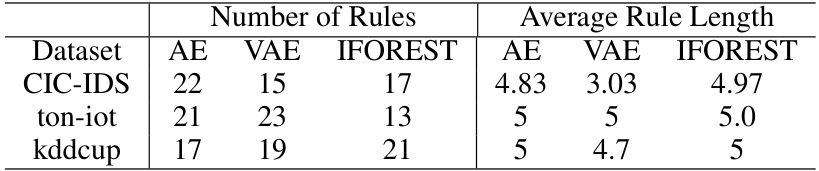
This table presents the number of rules and the average length of rules generated by the proposed model for three different anomaly detection models (Autoencoder, Variational Autoencoder, and Isolation Forest) across three different datasets (CIC-IDS, TON-IoT, and Kddcup). The average rule length indicates the complexity of the rules generated, with longer rules implying more detailed explanations of model decision-making.
Full paper#