↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world image datasets suffer from noisy labels (incorrectly labeled images), significantly impacting the performance of machine learning models trained on them. Existing methods for handling noisy labels often struggle to balance robustness and accuracy. This paper tackles this challenge by using the power of pre-trained vision-language models, which inherently possess strong alignment between their visual and textual representations.
The proposed framework, DEFT, leverages this alignment to build a noisy label detector. DEFT uses carefully chosen textual prompts to identify noisy samples, then refines the model using parameter-efficient fine-tuning (PEFT) to improve alignment and only trains on the clean samples, improving downstream performance. This approach provides a generalizable solution that can be applied to various pre-trained models, outperforming prior methods on several benchmark datasets with noisy labels. The results demonstrate DEFT’s effectiveness in both noisy label detection and classification tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework, DEFT, that effectively leverages the power of vision-language models to detect and mitigate noisy labels in image classification datasets. This is a significant contribution because noisy labels are a pervasive problem in many real-world applications and effective solutions are crucial for building robust and reliable AI systems. The research also opens up new avenues for investigation into the intersection of vision-language models and noisy label learning.
Visual Insights#
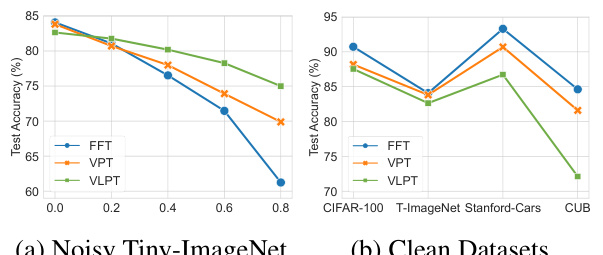
This figure compares the performance of three different fine-tuning methods for CLIP models: FFT (full fine-tuning), VPT (visual prompt tuning), and VLPT (vision-language prompt tuning). The comparison is done across various datasets with different noise ratios in (a) and clean datasets in (b). The results show that VPT is the most robust method in the presence of noisy labels, while FFT performs best on clean datasets. VLPT shows a good performance with noisy data but is inferior to VPT and FFT on clean datasets.
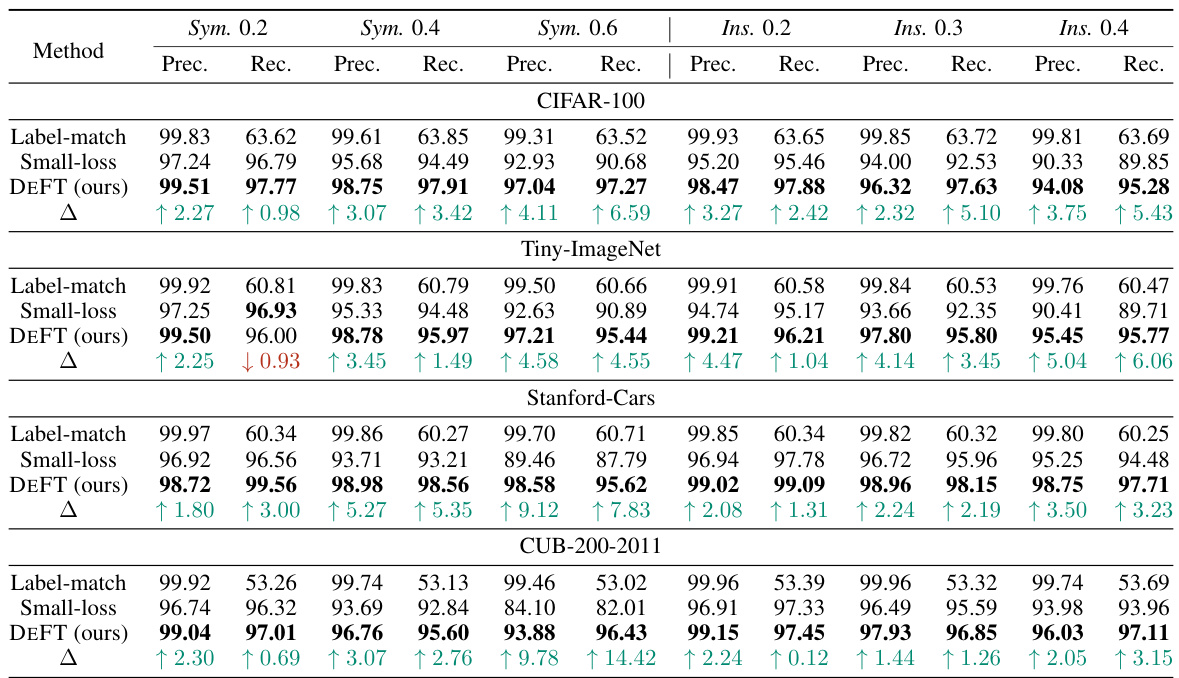
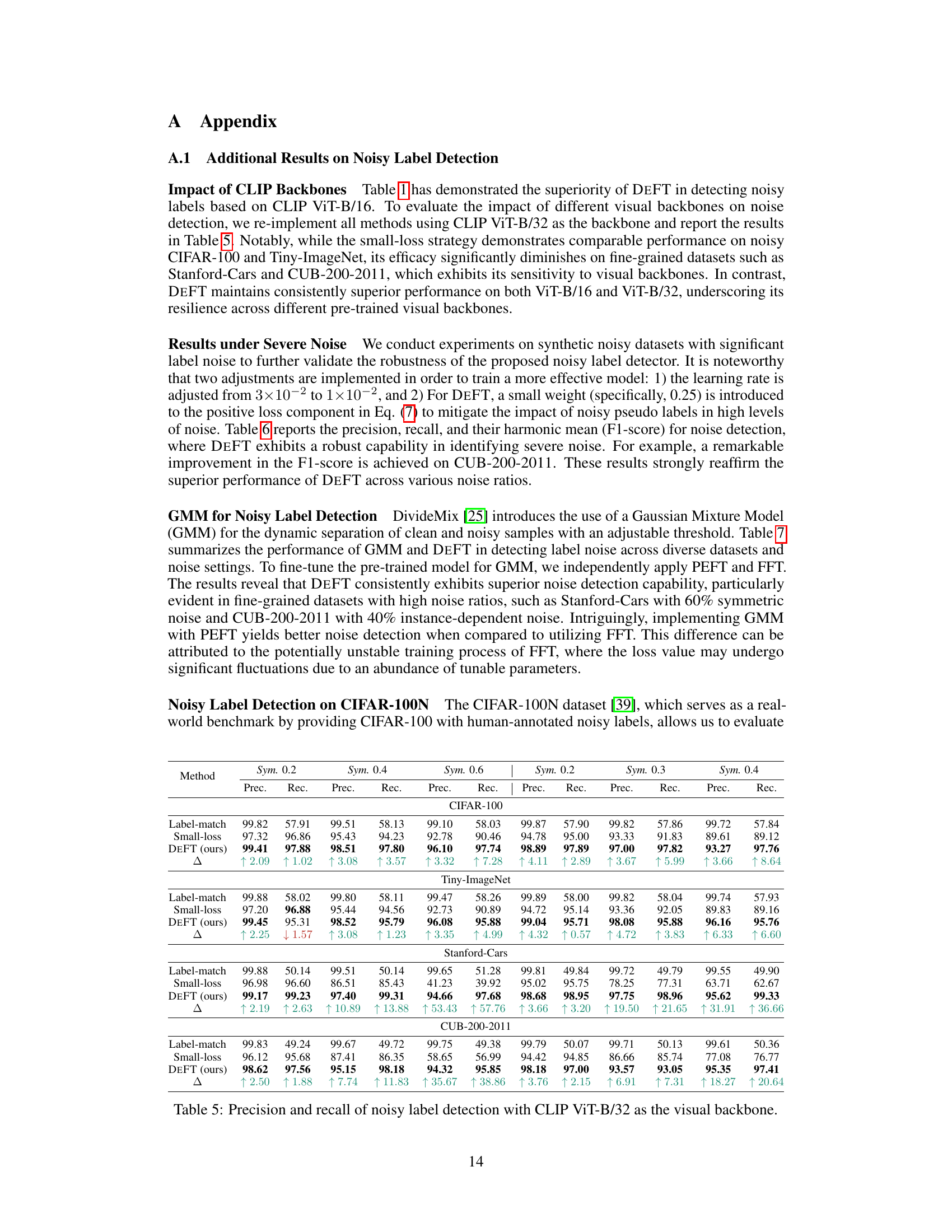
This table presents the performance comparison of three methods (DEFT, CLIP label-match, and small-loss) for clean sample selection on various datasets. Precision and recall are used as evaluation metrics, showing the effectiveness of DEFT in identifying clean samples. The Δ column highlights the performance improvement of DEFT compared to the small-loss method.
In-depth insights#
Noisy Label Detection#
The research paper explores methods for robust training of vision-language models in the presence of noisy labels. A key aspect is the development of a noisy label detector, leveraging the inherent alignment of visual and textual features within pre-trained models like CLIP. The detector uses dual textual prompts (positive and negative), where the positive prompt captures class-specific features while the negative prompt acts as a threshold, separating clean from noisy samples. This approach avoids the limitations of traditional loss-based methods that struggle with hard examples. This innovative dual prompt method uses parameter-efficient fine-tuning (PEFT) to efficiently enhance alignment and robustness to noise, ultimately refining the selection of clean data and improving model performance. The success of this method hinges on the powerful feature representations learned during pre-training, highlighting the advantages of using multimodal data for addressing noisy label challenges. Experimental results demonstrate significant improvements in both noisy label detection accuracy and downstream image classification tasks compared to existing approaches.
DEFT Framework#
The DEFT framework, designed for adapting vision-language models, tackles the challenge of noisy labels in real-world datasets. Its core innovation lies in using the inherent robustness of vision-language models’ alignment between visual and textual features to detect and filter noisy labels. This is achieved through the creation of a noisy label detector employing dual textual prompts (positive and negative) for each class. The positive prompt aims to capture class-specific features while the negative serves as a threshold for sample separation. Parameter-efficient fine-tuning (PEFT) is then used to optimize these prompts in alignment with the visual encoder. A crucial aspect is the subsequent model adaptation phase which, after identifying clean samples, uses full fine-tuning (FFT) for enhanced downstream task performance. This two-stage approach, leveraging both PEFT and FFT strategically, demonstrates superior performance to various existing methods in noisy label detection and image classification. DEFT’s simplicity and generalizability across multiple pre-trained models make it a strong contender for real-world applications where perfectly labeled data is scarce.
CLIP Adaptation#
CLIP adaptation techniques are crucial for leveraging the power of pre-trained vision-language models in downstream tasks. Fine-tuning, a common approach, modifies the model’s parameters to improve performance on specific datasets, but suffers from the risk of catastrophic forgetting and potential overfitting, particularly with noisy labels. Parameter-efficient fine-tuning (PEFT) methods offer a more stable alternative, updating only a small subset of parameters while preserving the pre-trained knowledge. These techniques are explored extensively in research. However, a critical aspect often overlooked is the presence of noisy labels in real-world datasets. This necessitates robust methods for detecting and handling such inaccuracies, impacting the effectiveness of any adaptation strategy. The interplay between adaptation strategy (fine-tuning vs. PEFT) and handling noisy labels significantly affects downstream performance. Future research should focus on developing more sophisticated methods for noisy label detection within the context of CLIP adaptation, considering various noise types and mitigating catastrophic forgetting to achieve optimal performance in real-world scenarios.
PEFT vs. FFT#
The choice between Parameter-Efficient Fine-Tuning (PEFT) and Full Fine-Tuning (FFT) for adapting pre-trained vision-language models is crucial, especially when dealing with noisy labels. PEFT methods, such as VPT and LoRA, modify only a small subset of model parameters, making them less prone to overfitting and catastrophic forgetting of pre-trained knowledge. This is particularly advantageous when noisy labels are present, as FFT’s extensive parameter updates can amplify the negative impact of these inaccuracies. Conversely, FFT offers potentially higher accuracy on clean datasets due to its greater capacity for adaptation. The optimal choice depends on the specific task, dataset quality, and computational resources. In scenarios with abundant noisy data, PEFT’s robustness outweighs the potential performance gains of FFT. Further investigation is needed to fully understand the trade-offs and explore hybrid approaches which combine the benefits of both techniques.
Future Works#
Future research directions stemming from this work on noisy label detection in vision-language models could explore several avenues. Extending the framework to handle multi-label classification tasks and noisy image-text pairs would significantly broaden its applicability. Investigating the impact of different types of noise, beyond the symmetric and instance-dependent noise studied, is also warranted. This includes exploring scenarios with class-dependent noise rates or more complex noise distributions. A thorough examination of the interplay between model architecture, pre-training data, and noisy label characteristics on the effectiveness of the proposed method would provide valuable insights. Additionally, future research should focus on developing more efficient and scalable methods for noisy label detection, especially for extremely large datasets. Finally, exploring the use of DEFT with other vision-language models, and in various downstream applications beyond image classification, could further demonstrate its versatility and impact.
More visual insights#
More on figures

The figure illustrates the DEFT framework, which consists of two phases. In the first phase (noisy label detection), dual textual prompts (positive and negative) are learned to identify noisy labels by comparing the similarity between image and text embeddings. The visual encoder is adapted using parameter-efficient fine-tuning (PEFT) methods to improve image-text alignment. In the second phase (model adaptation), the pre-trained model is further adapted using full fine-tuning (FFT) on the selected clean samples to boost visual recognition performance. The left side shows the noisy label detection phase, while the right side illustrates the model adaptation phase using the clean subset of the data. Arrows indicate data flow and the different network components (learnable, frozen).

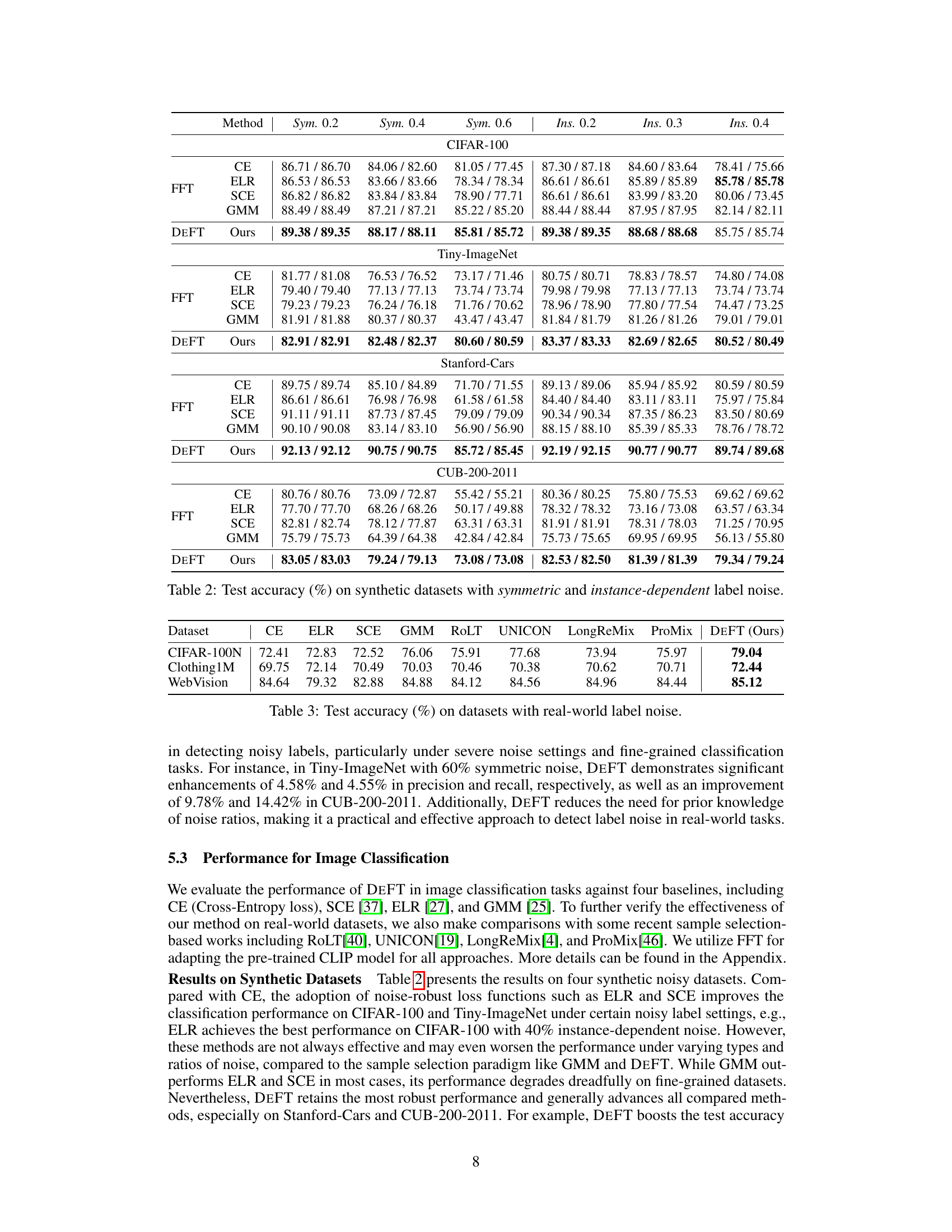
This figure presents the results of ablation studies conducted to evaluate the impact of different model adaptation techniques on the performance of DEFT. Four datasets (CIFAR-100, Tiny-ImageNet, Stanford-Cars, CUB-200-2011) were used, each with varying levels of synthetic label noise. The bars show the test accuracy achieved under three conditions: 1. DEFT without the model adaptation phase (w/o adap.) 2. DEFT using Parameter-Efficient Fine-Tuning (PEFT) for the adaptation phase. 3. DEFT using Full Fine-Tuning (FFT) for the adaptation phase. The results demonstrate the effectiveness of the model adaptation phase and show that FFT generally outperforms PEFT when the data is clean but can be negatively affected by noise.

This figure shows the results of ablation studies conducted to evaluate the impact of different components of the DEFT framework on its performance. Four different scenarios are compared: DEFT without model adaptation, DEFT using parameter-efficient fine-tuning (PEFT), DEFT using full fine-tuning (FFT), and a baseline without any adaptation. The results are shown across different levels of noise in the training data, indicating how well each version of DEFT handles varying amounts of noisy labels during model training. The x-axis represents the noise ratio (from 0 to 0.8), and the y-axis shows the test accuracy (percentage). Each subplot displays the accuracy for one of the four scenarios on a specific dataset (CIFAR-100, Tiny-ImageNet, Stanford-Cars, CUB-200-2011). This allows a visual comparison of the effects of different adaptation strategies on various datasets.
More on tables
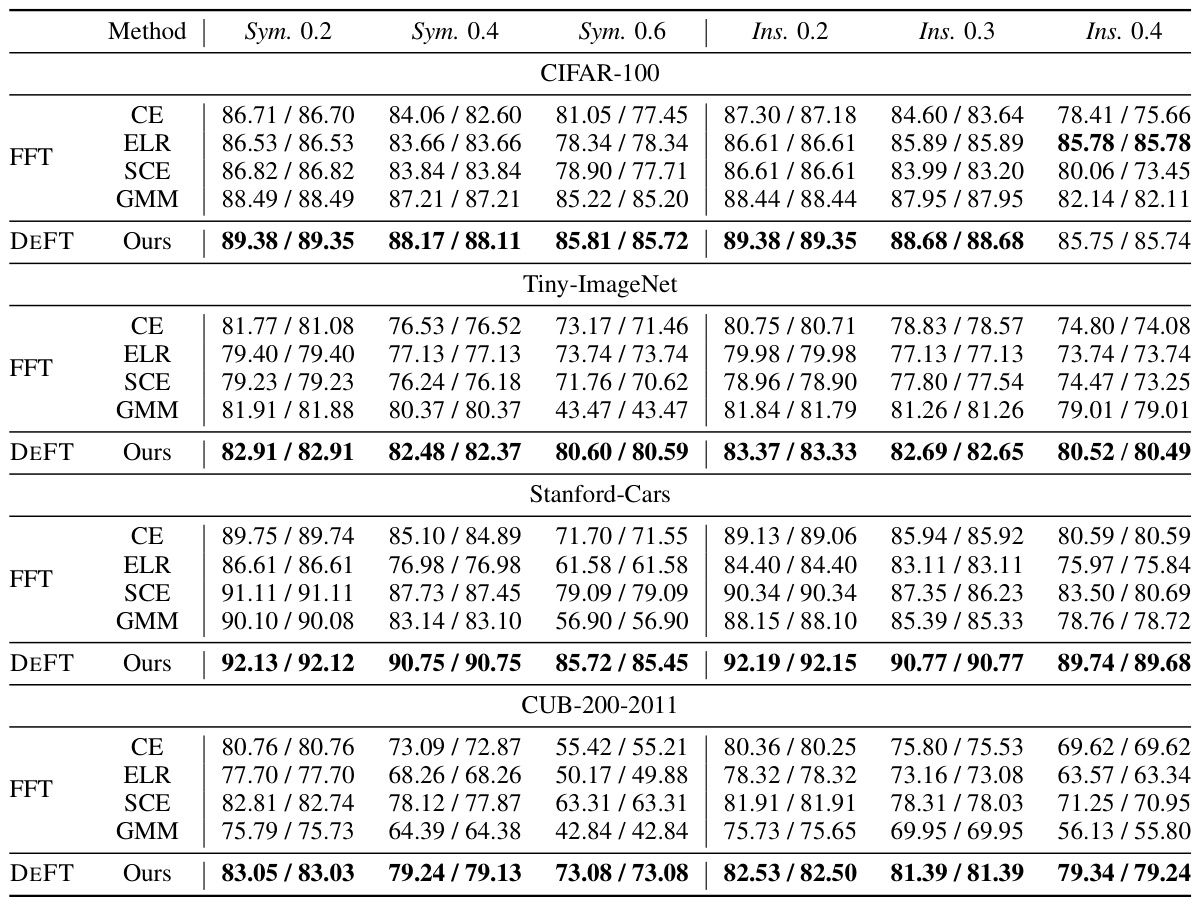
This table presents the results of image classification experiments conducted on four synthetic datasets (CIFAR-100, Tiny-ImageNet, Stanford-Cars, CUB-200-2011) with varying levels of symmetric and instance-dependent label noise. The results are broken down by noise type and ratio, showing the performance of different methods including CE (Cross-Entropy loss), ELR (Early-Learning Regularization), SCE (Symmetric Cross-Entropy loss), GMM (Gaussian Mixture Model), and DEFT (Denoising Fine-Tuning). The table allows for a comparison of the effectiveness of these different methods in handling various types and levels of noisy labels.

This table presents the test accuracy achieved by different methods (CE, ELR, SCE, GMM, RoLT, UNICON, LongReMix, ProMix, and DEFT) on three real-world datasets with noisy labels: CIFAR-100N, Clothing1M, and WebVision. The results show the effectiveness of each method in handling real-world label noise and highlight DEFT’s superior performance.
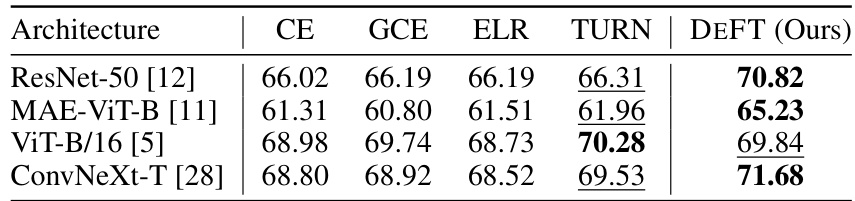
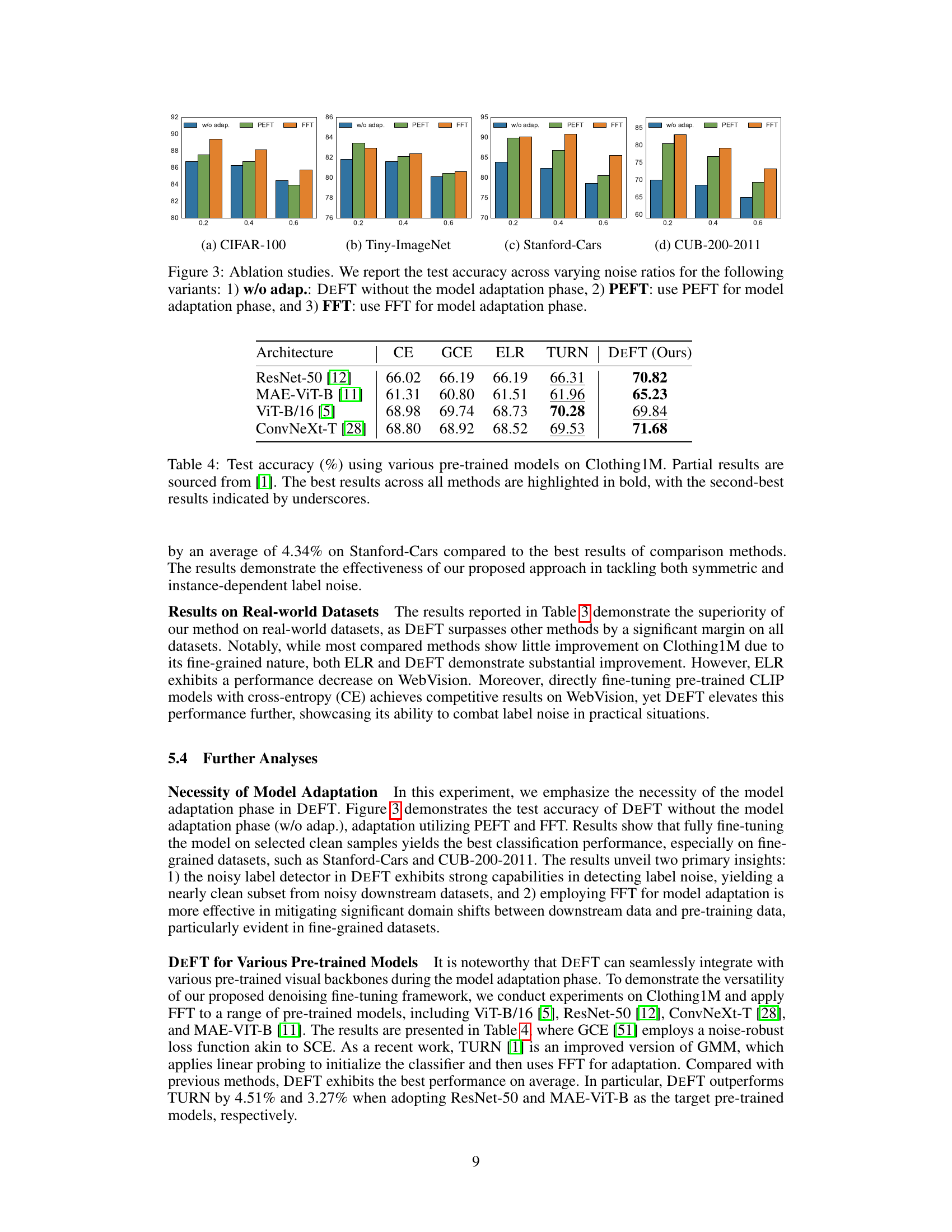
This table shows the test accuracy achieved by using different pre-trained models on the Clothing1M dataset. The models tested include ResNet-50, MAE-ViT-B, ViT-B/16, and ConvNeXt-T. The accuracy is reported for each model using cross-entropy loss (CE), generalized cross-entropy loss (GCE), early learning regularization (ELR), TURN, and the proposed DEFT method. The best performing model for each architecture is highlighted in bold, and the second-best is underlined.

This table compares the performance of three methods (DEFT, CLIP label-match, and small-loss) in terms of precision and recall for clean sample selection on seven different datasets (CIFAR-100, Tiny-ImageNet, Stanford Cars, CUB-200-2011, with symmetric and instance-dependent noise at different ratios). The Δ column shows the improvement of DEFT over the small-loss method.
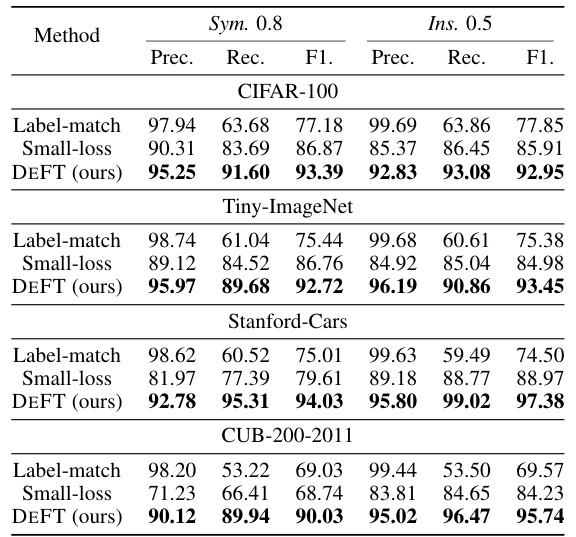
This table compares the performance of three methods (DEFT, CLIP label-match, and small-loss) in terms of precision and recall for clean sample selection on seven datasets (CIFAR-100, Tiny-ImageNet, Stanford Cars, CUB-200-2011, with symmetric noise at 0.2, 0.4, and 0.6 ratios and instance-dependent noise at 0.2, 0.3, and 0.4 ratios). It demonstrates DEFT’s superior performance in identifying clean samples compared to the other methods.
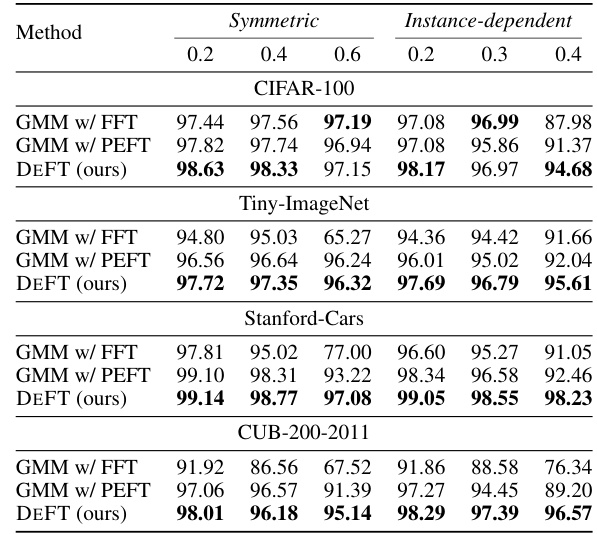
This table presents the test accuracy achieved by different methods on four synthetic datasets with varying levels of symmetric and instance-dependent label noise. The methods compared include Cross-Entropy (CE), Early-Learning Regularization (ELR), Symmetric Cross-Entropy (SCE), Gaussian Mixture Model (GMM), and the proposed DEFT method. The results are shown for different noise ratios (0.2, 0.4, 0.6 for symmetric noise and 0.2, 0.3, 0.4 for instance-dependent noise). The table allows for a comparison of the robustness of different methods against various types and intensities of label noise across different datasets.

This table presents the performance of different noisy label detection methods on the CIFAR-100N dataset. The methods compared include Label-match, Small-loss, GMM, RoLT, UNICON, LongReMix, ProMix, and DEFT (the authors’ method). The table shows the precision, recall, and F1-score for each method, providing a comprehensive comparison of their performance in identifying noisy labels in a real-world dataset. DEFT achieves the highest F1-score, demonstrating its effectiveness in noisy label detection.

This table presents the performance comparison of three methods for clean sample selection: DEFT, CLIP label-match, and small-loss. The comparison is done across multiple datasets (CIFAR-100, Tiny-ImageNet, Stanford Cars, CUB-200-2011) with varying levels of symmetric and instance-dependent noise. Precision and Recall are reported for each method on each dataset, showing DEFT’s superiority in selecting clean samples and highlighting the improvement achieved over the small-loss baseline.
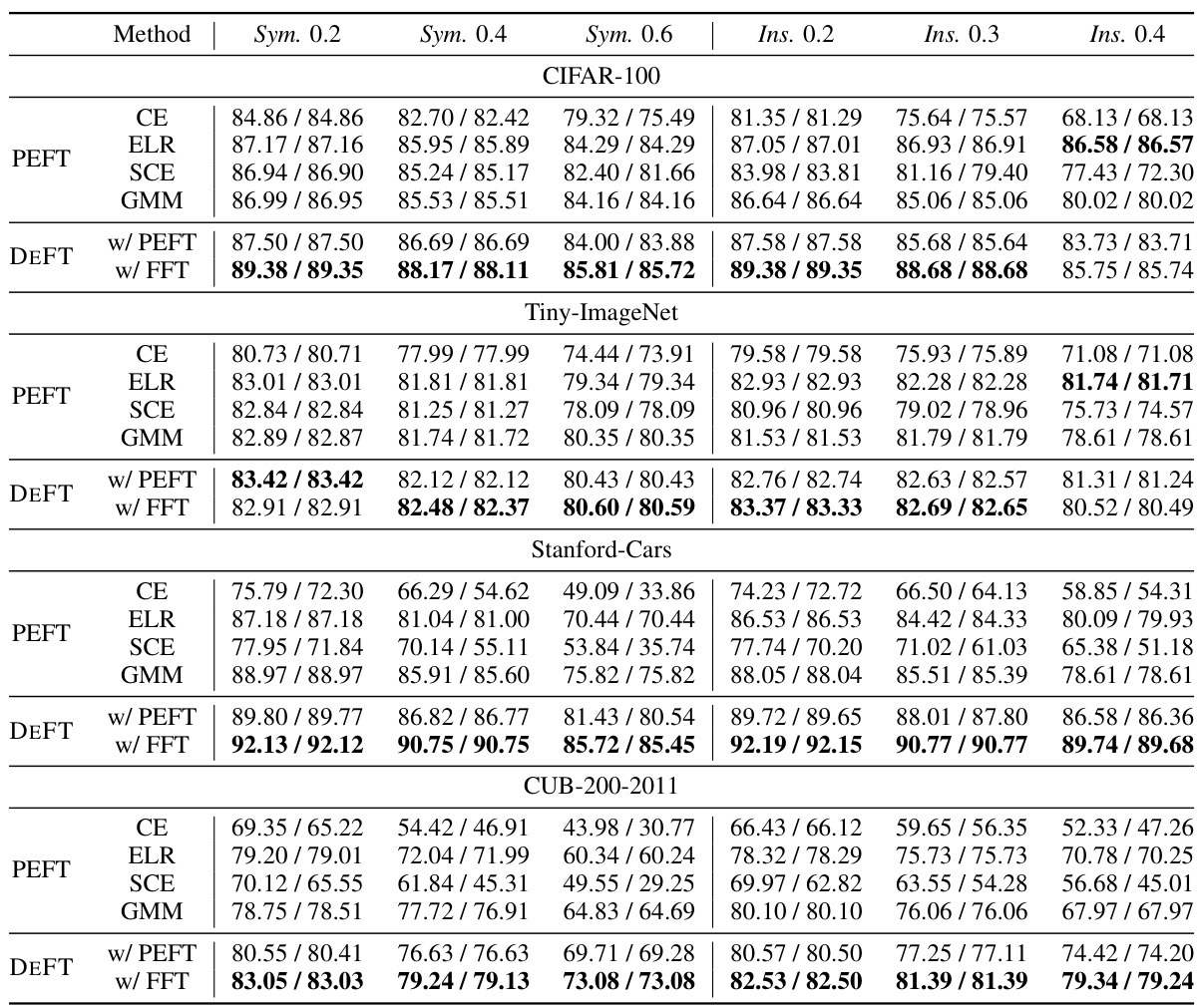
This table compares the precision and recall of three methods (DEFT, CLIP label-match, and small-loss) for selecting clean samples from noisy datasets. The results are shown for various datasets with different levels of symmetric and instance-dependent noise. The Δ column shows the difference in performance between DEFT and the small-loss method.

This table shows the hyperparameters used for training different pre-trained models in the DEFT framework. These hyperparameters include the optimizer used (SGD or AdamW), the learning rate, and the weight decay. The table lists the specific values used for each hyperparameter for four different models: ViT-B/16, ResNet-50, ConvNeXt-T, and MAE-ViT-B.
Full paper#