↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) often struggle with factual accuracy and recalling knowledge. Integrating structured knowledge from Knowledge Graphs (KGs) is challenging, as most methods convert KGs into text, losing valuable structural information.
GraphVis solves this by visualizing KGs and using Large Vision Language Models (LVLMs) to understand them. It incorporates a unique curriculum fine-tuning process which first teaches the model to recognize basic visual graph features before progressing to more complex QA tasks. This cross-modal approach significantly improves performance on commonsense reasoning and zero-shot visual QA benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents GraphVis, a novel method that significantly improves the performance of Large Language Models (LLMs) by integrating knowledge graphs via a visual modality. This addresses the limitations of existing methods and opens new avenues for research in multimodal learning and knowledge graph integration. The findings are relevant to current trends in LLM enhancement and visual question answering.
Visual Insights#

This figure presents a comparison of GraphVis’s performance against a baseline model across various question-answering benchmarks. The left panel shows the accuracy improvements achieved by GraphVis on commonsense reasoning tasks (CSQA and OBQA), highlighting its effectiveness in enhancing LLMs’ reasoning capabilities. The right panel displays the performance gains of GraphVis on several visual question-answering (VQA) benchmarks (ScienceQA, MMBench, POPE-random, POPE-popular, POPE-adversarial). This demonstrates GraphVis’s ability to improve not only textual QA but also zero-shot VQA performance by leveraging visual knowledge graphs.

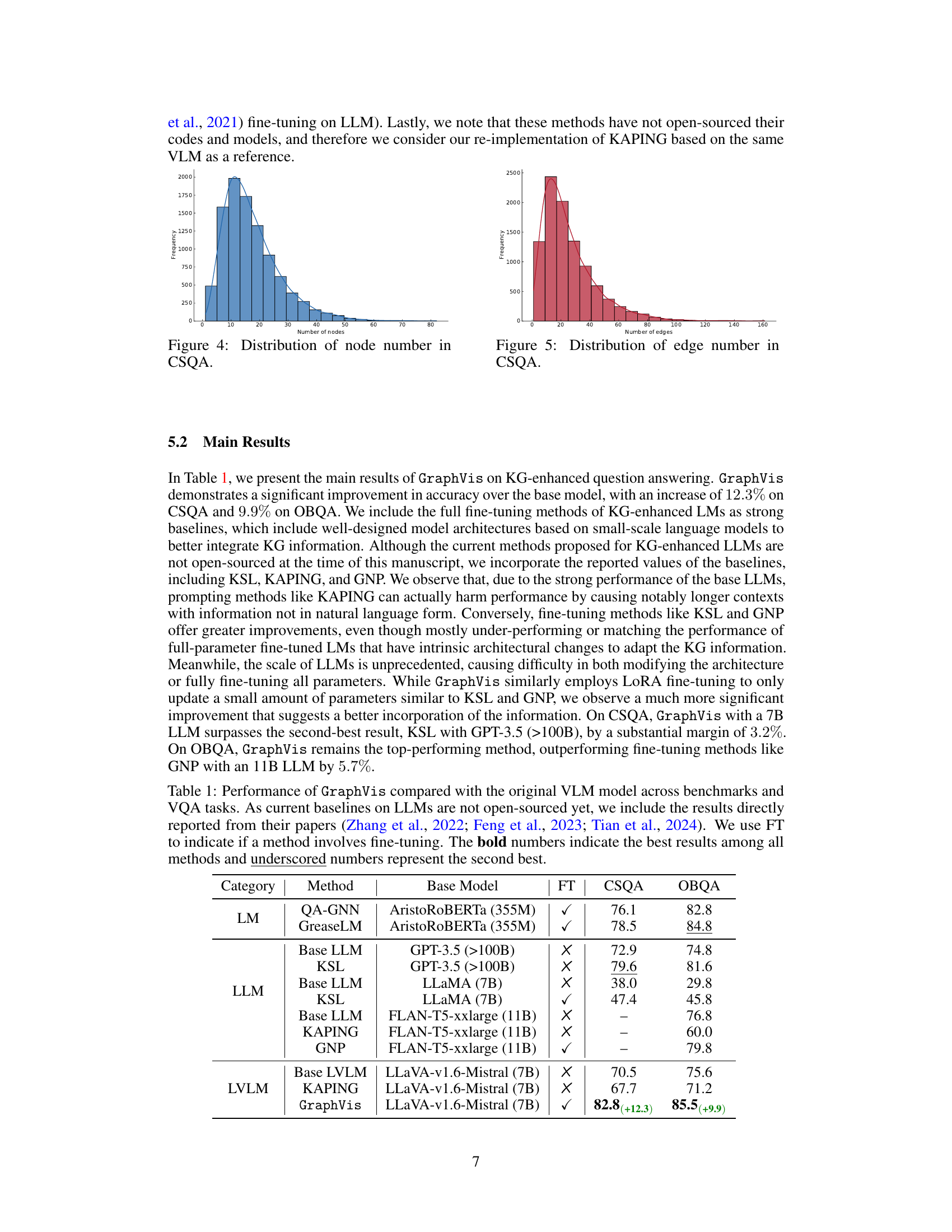
This table presents a comparison of the performance of GraphVis against various baseline models on commonsense reasoning QA tasks (CSQA and OBQA). It shows the accuracy achieved by different methods, including those that use fine-tuning (FT) and those that do not. The baseline models represent a range of approaches, from smaller language models enhanced with knowledge graphs to larger language models with and without KG integration. GraphVis consistently outperforms other methods, demonstrating a significant improvement in accuracy, especially when compared to methods which use prompting rather than fine tuning. Note that results for some baselines are from published papers, as their code was not available.
In-depth insights#
LLM-KG Integration#
LLM-KG integration aims to leverage the strengths of Large Language Models (LLMs) and Knowledge Graphs (KGs) for enhanced reasoning and improved factual accuracy. Current approaches often linearize KGs into text triples, losing the rich relational information inherent in the graph structure. This limitation motivates research into more effective integration methods, such as those utilizing visual representations of KGs. Visualizing KGs allows LLMs to process information in a more intuitive way, potentially leading to better performance on tasks requiring complex reasoning. A key challenge lies in training LLMs to effectively understand and reason with visual graph representations. Curriculum learning, where LLMs are initially trained on simple visual graph features before progressing to more complex tasks, is a promising approach for addressing this challenge. Further research is needed to explore different visualization techniques and efficient methods for integrating KG information into LLMs at scale, particularly for larger, more complex LLMs that pose unique challenges for existing integration strategies. The effectiveness of different LLM-KG integration approaches will depend on various factors, including the complexity of the task, the structure of the KG, the capabilities of the LLM, and the quality of the visual graph representations.
GraphVis Method#
The GraphVis method proposes a novel approach to integrating knowledge graphs (KGs) into large language models (LLMs) by leveraging the visual modality. Instead of directly converting KG structures into text, GraphVis visualizes subgraphs as images. This allows leveraging the capabilities of large vision language models (LVLMs) to better understand and reason with the information within the KGs. A key innovation is the curriculum-based fine-tuning scheme. The model first learns to recognize basic graphical features like node counts and degrees from the images before progressing to more complex question-answering tasks that require deeper understanding of the graph structure and relational information. This cross-modal approach significantly improves performance on commonsense reasoning and visual question answering benchmarks, demonstrating the power of combining visual and textual reasoning for enhanced knowledge graph integration within LLMs. GraphVis also explores the use of synthetic graph images generated from textual QA data to augment training data for LVLMs, addressing the scarcity of labeled image data in visual graph understanding. This method represents a significant advancement in how KGs are integrated into LLMs, offering a potentially more effective and efficient way to enhance factual knowledge and improve reasoning capabilities.
Visual Curriculum#
A visual curriculum is a crucial aspect of GraphVis, a novel method designed to enhance the integration of knowledge graphs into large language models using the visual modality. It’s a multi-stage training process, initially focusing on basic visual graph comprehension tasks, enabling the model to understand fundamental graphical features such as node counts, edge connections, and node degrees before progressing to more intricate reasoning tasks. This gradual progression, starting with simpler tasks and gradually increasing complexity, is key to the effectiveness of GraphVis. By mastering simpler aspects first, the model develops a robust foundation and is better prepared for more complex reasoning which significantly enhances overall performance on knowledge graph related question-answering benchmarks. The use of synthetic graph images, generated from knowledge graphs, is also a unique feature, allowing the model to effectively learn from a curated dataset that is designed to systematically teach the visual aspects of graphs. This synthetic approach complements the textual data used in the traditional curriculum, enabling better generalization and improved understanding of graph structures within the visual modality. This curriculum is designed to address the limitation of Large Vision Language Models in handling graph-structured data, effectively integrating KG information and visual learning capabilities.
VQA Benchmark#
A thorough analysis of VQA benchmarks in the context of a research paper would involve examining the specific datasets used, the types of questions asked, and the evaluation metrics employed. Key considerations include the diversity of images within the benchmark, spanning various domains and complexities. The types of questions posed are also crucial, ranging from simple factual questions to more complex ones involving reasoning and commonsense knowledge. The evaluation metrics should be carefully scrutinized, paying attention to whether they accurately assess the model’s ability to understand the visual content and answer the questions correctly. A robust benchmark should encompass diverse aspects of visual question answering capabilities and offer a meaningful comparison between different models. Furthermore, the accessibility and size of the benchmark dataset matter, as it determines the feasibility of training and evaluating models. Bias and fairness are also critical considerations, as biases in the dataset can lead to unfair and inaccurate evaluations. Finally, a good VQA benchmark should encourage ongoing improvements in the field by setting high standards and providing a platform for fair and rigorous comparisons.
Future of GraphVis#
The future of GraphVis hinges on several key areas. Scaling to larger knowledge graphs and LLMs is crucial; current implementations are limited by computational resources. Exploring alternative visualization techniques beyond Graphviz could significantly improve the LVLM’s understanding of complex graph structures. Furthermore, research into more effective subgraph retrieval methods is essential for optimal knowledge integration. The approach’s success on zero-shot VQA suggests promising applications in domains with limited labeled data, like scientific diagram analysis. Addressing potential biases present in KGs and the LLM itself is vital for responsible AI development. Finally, integrating GraphVis with other multimodal modalities, such as audio or video, could unlock even more powerful reasoning capabilities. Ultimately, the future success of GraphVis depends on successfully tackling these challenges and realizing its potential for enhanced cross-modal reasoning and improved factual accuracy.
More visual insights#
More on figures
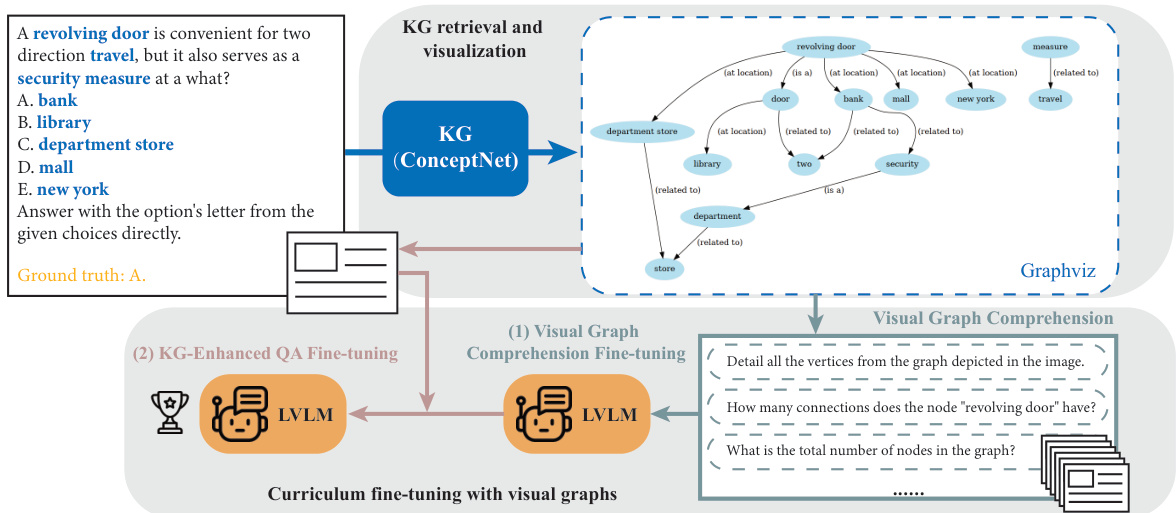
This figure illustrates the GraphVis framework. It shows how a question-answer pair is used to retrieve a subgraph from a Knowledge Graph (KG). This subgraph is then visualized using Graphviz and used for two-stage fine-tuning of a Large Vision Language Model (LVLM). The first stage is visual graph comprehension fine-tuning, where the LVLM is trained to understand basic visual features of the graph (e.g., node count, edge count). The second stage is KG-enhanced QA fine-tuning, where the LVLM is trained to answer questions using both the visual graph and the original question-answer pair. This curriculum learning approach helps the LVLM effectively integrate knowledge from the KG into its reasoning process.

This figure presents a comparison of the GraphVis model’s performance against a baseline model across two sets of tasks. The left panel shows improved accuracy on commonsense reasoning tasks, while the right panel demonstrates performance gains on visual question answering (VQA) benchmarks. The results highlight GraphVis’s effectiveness in both textual and visual reasoning domains.
This figure presents a comparison of GraphVis’s performance against a baseline model. The left side shows improvements in accuracy across various commonsense reasoning tasks. The right side displays GraphVis’s performance boost on multiple visual question answering (VQA) benchmarks compared to its base large vision language model (LLaVA-v1.6).

This figure presents a comparison of GraphVis’s performance against a baseline model on two sets of tasks: commonsense reasoning and visual question answering (VQA). The left panel shows a bar chart illustrating the accuracy gains achieved by GraphVis across several commonsense reasoning benchmarks (CSQA, OBQA, MMBench, POPE). The right panel displays a radar chart comparing the performance improvements of GraphVis against the baseline model across various VQA benchmarks (CSQA, OBQA, ScienceQA, POPE). The radar chart provides a visual representation of the relative improvements across different benchmarks.
This figure shows two example images from visual question answering (VQA) datasets, ScienceQA and MMBench. These images are included to highlight the similarity between the types of diagrams found in those datasets and the visualized knowledge graphs produced by the GraphVis method. The ScienceQA image is a food web, while the MMBench image is a chart. The paper argues that the visual similarity makes the GraphVis approach applicable and effective in enhancing the performance of Large Vision Language Models (LVLMs) on VQA tasks.

This figure shows two example images from visual question answering (VQA) benchmarks, ScienceQA and MMBench. These images are examples of diagrams that visually resemble knowledge graphs, illustrating the relevance of the GraphVis approach which leverages visual representations of knowledge graphs to enhance LLM performance on VQA tasks. The left image (ScienceQA) is a food web, while the right image (MMBench) is a chart. Both demonstrate how real-world VQA data contains visually similar graph structures to the synthetic graph images generated by the GraphVis methodology.

This figure compares the performance of GraphVis on the CSQA benchmark using different fine-tuning strategies. It shows that a curriculum-based approach, where the model is first trained on basic visual graph comprehension tasks before progressing to more complex reasoning tasks, yields the best results. Joint fine-tuning, where all tasks are trained simultaneously, performs significantly worse. Furthermore, the order of the detailed tasks within the curriculum also matters, with training on OCR tasks first followed by graph tasks, producing slightly better results than the reverse.

This figure shows an example of how GraphVis improves the performance of a Large Vision Language Model (LVLM) on a visual question answering (VQA) task from the ScienceQA benchmark. The task requires following the connections in a food web diagram to answer a question about the flow of matter. The original model (LLaVA-v1.6 7B) gives an incorrect answer (C), while the model fine-tuned with GraphVis correctly answers (A). This demonstrates GraphVis’s ability to improve LVLM performance on complex reasoning tasks involving graph-like images.

This figure shows a comparison of the performance of the GraphVis model against a baseline model across two types of tasks: commonsense reasoning and visual question answering (VQA). The left-hand side displays bar charts comparing accuracy on four commonsense reasoning benchmarks (CSQA, OBQA, MMBench, POPE). The right-hand side presents a radar chart comparing improvements in accuracy across several VQA benchmarks (CSQA, OBQA, Science QA). The figure demonstrates GraphVis’s improved performance over the baseline across both task types.
More on tables

This table presents the performance comparison of the base Large Vision Language Model (LLaVA-v1.6-mistral-7b) and the same model after applying the proposed GraphVis method on various Visual Question Answering (VQA) tasks. The tasks include ScienceQA (focused on scientific diagrams), MMBench (a multi-modal benchmark encompassing various task types), and POPE (assessing object hallucination). For each task, it reports the Image Accuracy (Img-Acc) and Overall accuracy/F1-score as relevant. The numbers in parentheses indicate the performance gain achieved by incorporating GraphVis.

This table compares the performance of GraphVis against various baselines on question answering tasks (CSQA and OBQA). It shows the accuracy improvements achieved by GraphVis over a base Large Vision Language Model (LLVM), and also compares it to existing Knowledge Graph (KG)-enhanced LLMs (KSL, KAPING, GNP) and other LLMs (GPT-3.5, FLAN-T5). The table highlights GraphVis’s significant accuracy gains, particularly when compared to methods involving fine-tuning, which are more costly and difficult to adapt to larger LLMs.

This table presents the performance of the LLaVA-v1.6 model on various graph comprehension tasks before and after fine-tuning. The tasks assess the model’s ability to extract information from visual graph representations. The metrics include accuracy in describing nodes, determining node degrees, identifying the node with the highest degree, counting nodes and edges, and listing graph triples. The table highlights the improvement in performance after fine-tuning, indicating that the model’s ability to understand and interpret visual graphs significantly enhanced after the fine-tuning process.
This table presents a comparison of the performance of GraphVis against various baselines on commonsense reasoning question answering benchmarks (CSQA and OBQA). It also includes results from zero-shot visual question answering (VQA) tasks. The table highlights GraphVis’s improvements over a base model and existing knowledge graph (KG)-enhanced language models. Note that fine-tuning (FT) is indicated, and the best and second-best results are highlighted.

This table presents the performance comparison of three different models on the ScienceQA benchmark: the base LLaVA-v1.6 model, GraphVis with joint fine-tuning, and GraphVis with the proposed curriculum fine-tuning. It shows the accuracy (in percentage) achieved by each model. The results demonstrate that the GraphVis model with curriculum learning outperforms both the base model and GraphVis with joint fine-tuning on ScienceQA.
Full paper#