↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current 4D generation methods struggle with spatiotemporal consistency and lack the ability to effectively leverage existing 3D assets. They often rely on text or single-view image conditioning, leading to limitations in generating realistic and detailed 4D content, particularly when animating complex objects.
Animate3D overcomes these limitations by introducing a novel multi-view video diffusion model (MV-VDM) trained on a new large-scale dataset (MV-Video). This model generates temporally consistent multi-view videos of static 3D objects, which are then used in a two-stage animation pipeline. The pipeline leverages reconstruction and 4D score distillation sampling to accurately reconstruct and refine both appearance and motion, enabling straightforward mesh animation without skeleton rigging.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Animate3D, a novel framework for animating any static 3D model, addressing the limitations of existing 4D generation methods. It introduces a new multi-view video diffusion model and a two-stage animation pipeline, significantly improving spatiotemporal consistency. This work also contributes a large-scale multi-view video dataset, advancing 4D generation research and opening avenues for improvements in AR/VR, gaming, and film industries.
Visual Insights#

This figure compares different methods for generating 4D content (spatiotemporal data). It shows that the proposed method, MV-VDM, produces significantly better results in terms of spatiotemporal consistency compared to using video diffusion alone (T2V) or combining video and 3D diffusion (SVD + Zero123). The improved consistency of MV-VDM makes it suitable as the foundation for the Animate3D framework, which can animate any 3D model.

This table presents the key statistics of the MV-Video dataset used to train the MV-VDM model. It shows the total number of 3D model IDs, the total number of animations across all models, the average number of animations per model ID, the maximum number of animations found for a single model ID, and finally, the total number of multi-view videos generated for the dataset. These statistics highlight the scale and diversity of the dataset.
In-depth insights#
MV-VDM: Core Model#
A hypothetical ‘MV-VDM: Core Model’ section would delve into the architecture and functionality of the core model, likely a multi-view video diffusion model. It would detail the model’s building blocks, such as multi-view 3D attention modules for spatial consistency and temporal motion modules for temporal coherence. The training process would be described, emphasizing the use of a large-scale, multi-view video dataset for learning spatiotemporal relationships. Key innovations, like a novel spatiotemporal attention mechanism to enhance consistency or a conditioning method using multi-view renderings to preserve 3D object identity, would be highlighted. The section would likely include details about the model’s capacity for generating high-quality and consistent multi-view video animations. Finally, it might present ablation studies illustrating the contribution of each architectural component.
4D Animation#
The section on “4D Animation” in this research paper likely details the application of the proposed multi-view video diffusion model (MV-VDM) to animate 3D objects, particularly meshes. The authors probably present a two-stage pipeline: first, using MV-VDM to generate consistent multi-view video animations conditioned on a static 3D model and a text prompt, and second, leveraging this video data to drive mesh deformation. A key aspect is likely the handling of spatiotemporal consistency. The method probably avoids traditional techniques like skeleton rigging, opting for a more data-driven approach where the motion information inherent in the generated videos directly informs the mesh’s animation. Results would showcase the model’s ability to produce natural-looking animations while preserving the visual identity of the input 3D model. The discussion may include a comparison with existing animation techniques, highlighting the advantages of this novel, data-driven approach, especially in terms of ease of use and animation quality for diverse 3D assets. Ablation studies would investigate the contribution of various components, like the spatiotemporal attention module and the reconstruction method, in achieving high-quality 4D animations. Qualitative and quantitative evaluations would also be presented, potentially employing established video animation metrics and user studies. The ultimate goal would be to demonstrate that the proposed method allows for straightforward and high-quality 4D animation, even for complex 3D models.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper, this section would likely detail experiments where parts of the proposed method were deactivated or altered. The results would reveal the impact of each component on overall performance, identifying critical elements and revealing potential redundancies. For instance, an ablation study might involve removing a specific module (e.g., an attention mechanism) to observe its effect on accuracy or efficiency. By carefully analyzing changes in performance, the study would help justify design choices and highlight the key innovations of the proposed method. The strength of the ablation study rests in its rigor and in providing a clear picture of what makes the complete system successful, beyond simply demonstrating overall performance.
Dataset Creation#
The creation of a robust and comprehensive dataset is crucial for the success of any machine learning project, especially in the field of 4D generation. A well-designed dataset needs to capture the spatiotemporal dynamics of real-world objects or scenes accurately. This requires careful consideration of factors such as the number of views, the temporal resolution (frames per second), the variety of objects included, and the quality of the image or video data. Careful labeling and annotation are also necessary to enable the model to learn effectively. In addition, the dataset must be large enough to ensure sufficient training data, while being diverse enough to avoid overfitting to specific characteristics. Data augmentation techniques can also be used to improve the dataset’s size and diversity. Furthermore, the data needs to be readily available and usable to allow researchers to easily access and work with it. The availability of such high-quality data is critical in ensuring the reliability and reproducibility of research findings in this domain.
Future Work#
Future work for Animate3D could significantly expand its capabilities and address current limitations. Improving efficiency is crucial; the current animation process is time-consuming. Exploring more efficient architectures or optimization techniques could drastically reduce processing time, making it practical for real-time applications. Enhancing motion realism is another key area; while Animate3D produces impressive results, the motion can sometimes appear slightly artificial. Incorporating more sophisticated physics simulations or learning from larger and more diverse datasets, particularly focusing on human and animal motion capture data, would enhance naturalism. Expanding the range of supported 3D models would improve accessibility and utility. The current reliance on a specific 3D representation format limits the range of input models that Animate3D can effectively animate. Addressing this through format adaptability would significantly expand the use-cases. Lastly, exploring alternative loss functions to improve the balance between appearance, motion fidelity, and computational cost could enhance overall animation quality and efficiency. A detailed study of different loss functions’ impact on each aspect of the animation is vital.
More visual insights#
More on figures
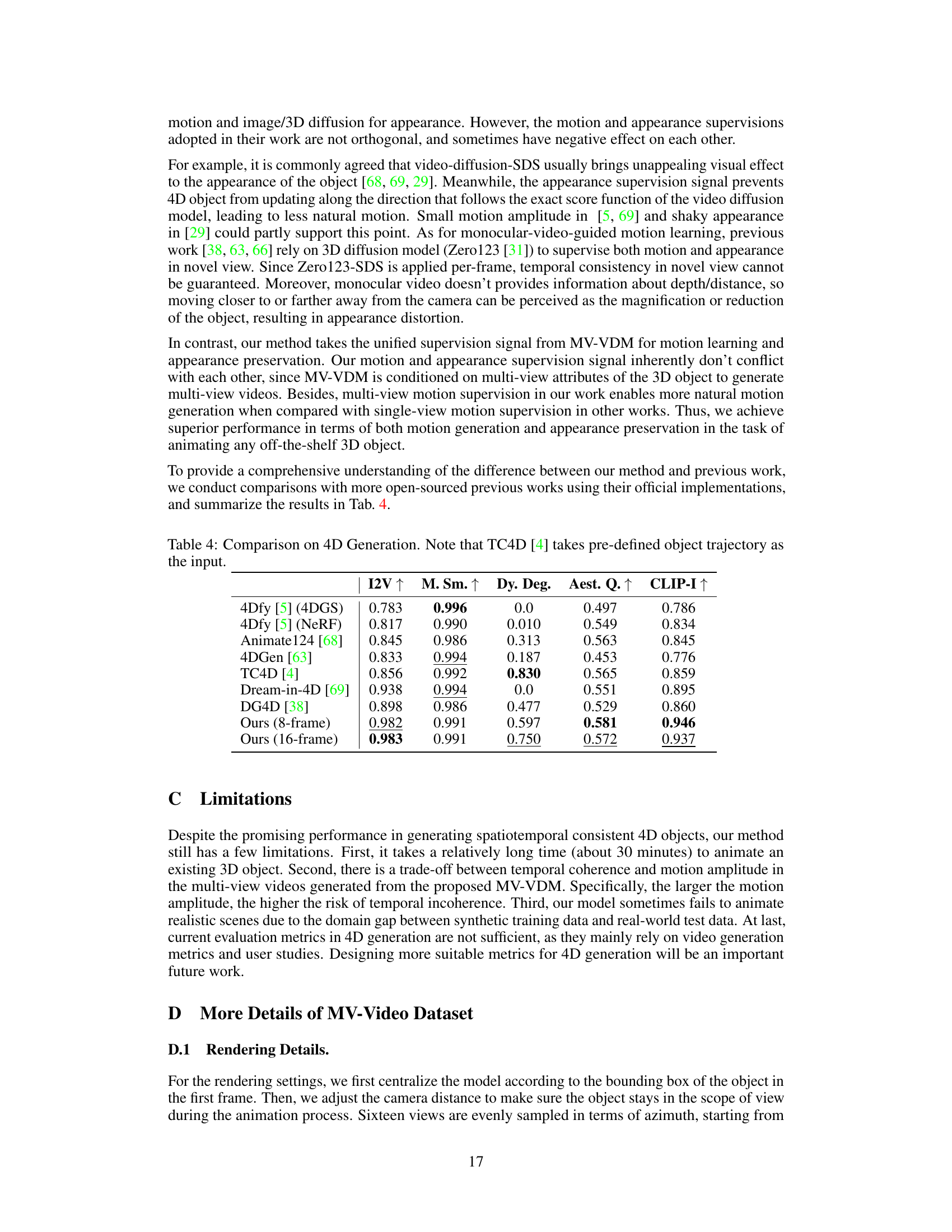
This figure illustrates the architecture of the proposed multi-view video diffusion model (MV-VDM) and the Animate3D framework. MV-VDM, trained on a large-scale 4D dataset (MV-Video), generates temporally and spatially consistent multi-view videos. The Animate3D framework then leverages MV-VDM for animating any static 3D model via a two-stage pipeline that combines motion reconstruction and 4D Score Distillation Sampling (4D-SDS) for motion refinement and appearance preservation. The diagram shows the flow of information from text prompt, multi-view renderings of the 3D object, to the generated multi-view videos and final animation.

This figure compares the animation results of Animate3D against two state-of-the-art methods, 4Dfy and DreamGaussian4D, on three different 3D objects (bear, frog, penguin). Each row represents a different object and shows its animation at different time steps (t=0, t=t1, t=t2). The input 3D model is shown in the first column (t=0), followed by the animation results of 4Dfy, DreamGaussian4D, Reconstruction (Ours), and Ours. The comparison highlights Animate3D’s ability to generate high-quality and consistent animations, unlike the other methods that suffer from distortions or blurry effects.

The figure shows an ablation study on the proposed multi-view video diffusion model. It demonstrates the impact of removing the spatiotemporal attention module and pre-trained weights on the quality of generated videos. The results highlight the importance of these components for achieving high-quality spatiotemporal consistency in the generated videos.
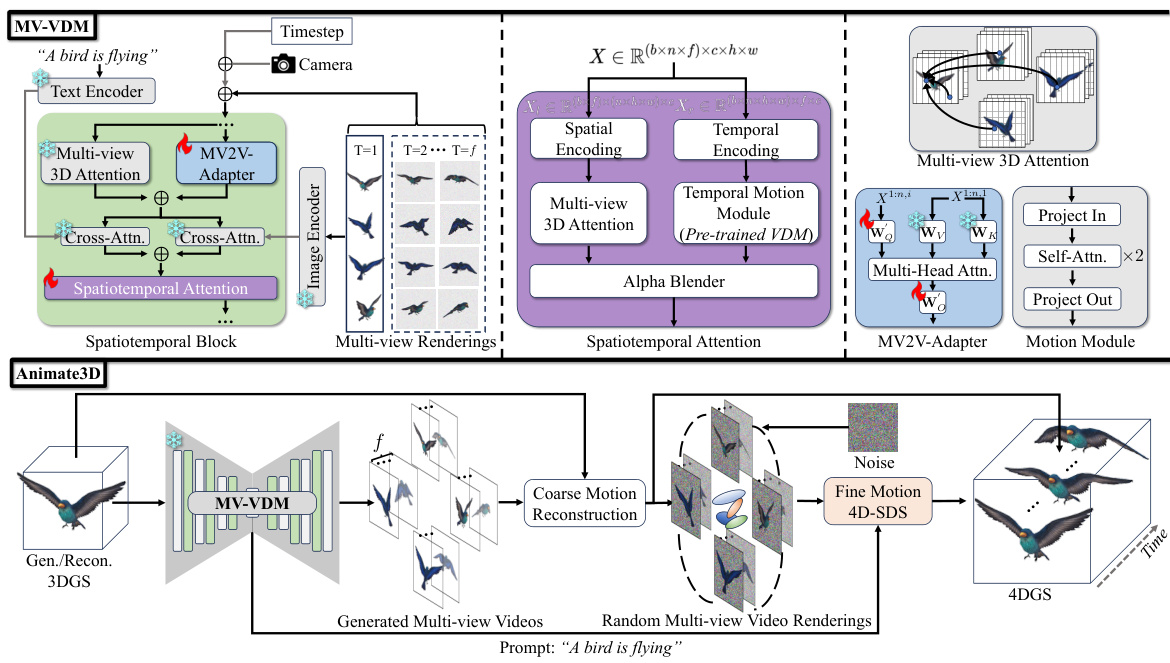
This figure shows the results of applying the Animate3D framework to animate 3D meshes. Two examples are provided: a wooden dragon head shaking from right to left, and a dog running and jumping. For each animation, both color (RGB) and textureless renderings of the mesh are shown at different points in time. The goal is to demonstrate the framework’s ability to directly animate meshes without requiring skeleton rigging or other complex procedures.

This figure compares the animation results of Animate3D with two state-of-the-art methods, 4Dfy(Gau.) and DreamGaussian4D, on three reconstructed 3D objects: a spiderman, a monstrous dog, and Superman. Each row shows the input static 3D object (t=0) and the animation results at different time steps (t=t1, t=t2) for each method. The results demonstrate that Animate3D achieves better quality in terms of appearance and motion consistency, generating more natural and visually pleasing animations compared to the other two methods.

This figure shows the ablation study results of the proposed method. The top two rows present ablation studies on the multi-view video diffusion model (MV-VDM), showing results without spatiotemporal attention and without pre-trained weights. The bottom two rows show ablation studies on the 4D animation optimization, presenting results without 4D Score Distillation Sampling (4D-SDS) and without As-Rigid-As-Possible (ARAP) loss. Each row displays multiple views of the same object at different time steps, illustrating the impact of each component on the quality and consistency of the animation. The objects used are a pink dinosaur and a blue treasure chest, each undergoing a specific animation (waving and opening, respectively). Comparing the results across rows for each object demonstrates the contributions of each component to the overall performance of Animate3D.

This figure demonstrates the ablation studies performed on the MV-VDM model and the 4D optimization process. The top row shows the impact of removing the spatiotemporal attention module and pre-training on the MV-VDM. The bottom row shows the impact of removing the ARAP loss and the SDS loss from the 4D optimization. The results illustrate the importance of each component for achieving high-quality results in generating consistent and detailed animations.
This figure illustrates the architecture of the proposed MV-VDM model and Animate3D framework. MV-VDM, a multi-view video diffusion model, takes multi-view renderings and text prompts as input to generate spatiotemporally consistent multi-view videos. Animate3D uses MV-VDM to reconstruct and refine motions for animating static 3D models. It uses a two-stage pipeline consisting of motion reconstruction and 4D Score Distillation Sampling (4D-SDS) to achieve high-quality mesh animation.

This figure shows the architecture of the proposed method, Animate3D, which consists of two main parts: the multi-view video diffusion model (MV-VDM) and the animation pipeline. MV-VDM takes multi-view renderings of a 3D object as input and generates spatiotemporal consistent multi-view videos. The animation pipeline reconstructs motions from the generated videos and refines them using 4D Score Distillation Sampling (4D-SDS) to create a final animation. The figure also highlights the use of a spatiotemporal attention module and MV2V-Adapter to improve the model’s performance.

This figure illustrates the architecture of the MV-VDM model (top) and the Animate3D framework (bottom). MV-VDM, trained on a large dataset of multi-view videos, generates consistent videos across multiple views and over time. The Animate3D framework leverages MV-VDM to animate static 3D models by combining reconstruction and a novel 4D score distillation sampling (4D-SDS) method for motion refinement. The diagram shows the flow of data through each component, highlighting the integration of text prompts, multi-view images, and the spatiotemporal attention module in MV-VDM.

This figure shows more examples from the MV-Video dataset. The dataset contains a large variety of animated 3D objects, including animals, plants, humans, and other objects, which are rendered in multiple views for the purpose of training the MV-VDM model in the Animate3D framework. The images showcase different poses and motions of the objects to demonstrate the spatiotemporal diversity present in the dataset.

This figure compares different approaches to 4D generation (generating videos of 3D objects in motion). It shows three methods: simple video diffusion (T2V), a combined video and 3D diffusion approach (SVD+Zero123), and the authors’ proposed multi-view video diffusion model (MV-VDM). The figure highlights that MV-VDM produces more temporally and spatially consistent results, paving the way for their Animate3D framework which animates any 3D model.
More on tables

This table presents a quantitative comparison of the proposed Animate3D method with state-of-the-art 4D generation methods, 4Dfy and DG4D. Part (a) shows the comparison based on video generation metrics (I2V, Motion Smoothness, Dynamic Degree, and Aesthetic Quality). Part (b) displays user study results based on ratings of alignment with text and 3D model, motion quality, and appearance.
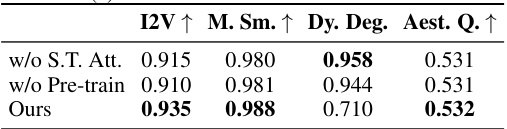
This table presents the ablation study results for the Animate3D framework. It shows the impact of removing key components of the model, such as the spatiotemporal attention module and pre-trained weights, on the performance of multi-view video diffusion and 4D object animation. The metrics used for evaluation include I2V, Motion Smoothness, Dynamic Degree, and Aesthetic Quality. The results reveal the importance of each component for achieving high-quality results.
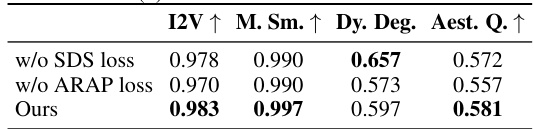
This table presents the ablation study results for the Animate3D framework. It shows the quantitative effects of removing different components of the model, specifically the spatiotemporal attention module, the pre-trained weights from the video diffusion model, the 4D-SDS loss, and the ARAP loss. The results are evaluated using four metrics: I2V (image-to-video alignment), M. Sm. (motion smoothness), Dy. Deg. (dynamic degree), and Aest. Q. (aesthetic quality). The ‘Ours’ row represents the full model’s performance, serving as a baseline for comparison.
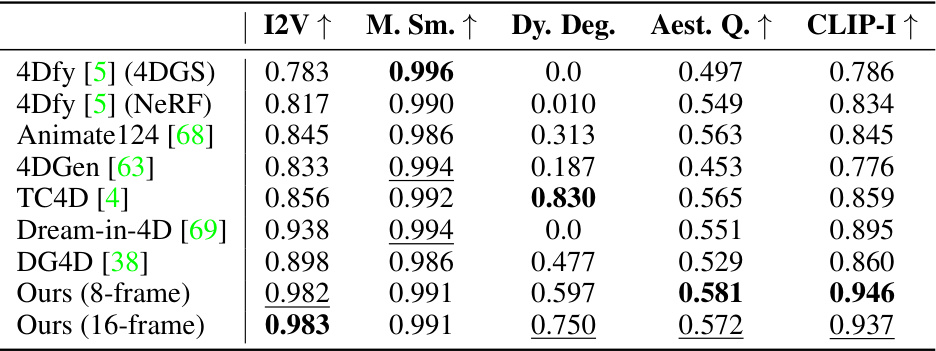
This table presents a quantitative comparison of the proposed Animate3D method against state-of-the-art 4D generation methods. Part (a) shows a comparison using video generation metrics (I2V, Motion Smoothness, Dynamic Degree, Aesthetic Quality). Part (b) presents results from a user study, evaluating the alignment with the given text and static 3D object, the appearance quality, and the motion quality of the generated animations.
Full paper#