↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Fine-tuning large language models (LLMs) using human preferences is a dominant paradigm. Two common approaches are online reinforcement learning (like Proximal Policy Optimization, or PPO) and offline contrastive methods (like Direct Preference Optimization, or DPO). Prior work treated these as equivalent, but this paper challenges that assumption. It highlights a critical limitation: the diversity and coverage of the offline preference data significantly impact the performance of DPO, while online methods (PPO) are less affected.
To address this limitation, the researchers propose a hybrid method called Hybrid Preference Optimization (HyPO). HyPO combines the efficiency of DPO with the robustness of PPO by utilizing both offline preference data for contrastive optimization and online unlabeled data for KL regularization. Theoretically and empirically, HyPO outperforms DPO, showcasing its effectiveness in various benchmark tasks. The core contribution is the introduction of HyPO, a novel algorithm that bridges the gap between offline and online approaches, offering improved performance and efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning and large language models because it offers a novel hybrid approach, HyPO, that improves upon existing methods for preference fine-tuning. It provides a theoretical understanding of the differences between online and offline preference learning, which can guide future algorithm design and improve the performance of LLMs. The empirical results demonstrate HyPO’s superior performance and efficiency, opening new avenues for research in human-in-the-loop machine learning.
Visual Insights#

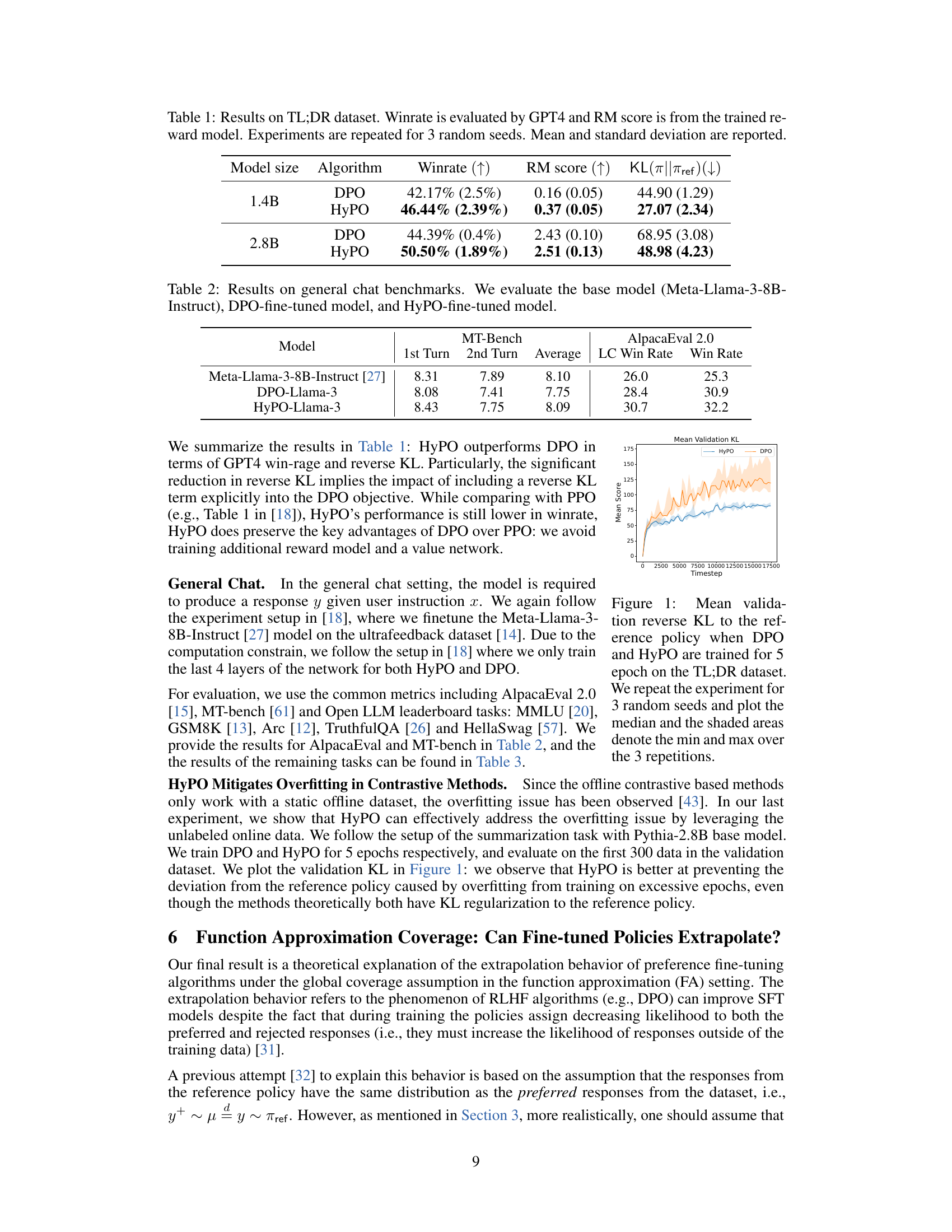
This figure shows the mean validation reverse KL divergence to the reference policy over training timesteps for both DPO and HyPO algorithms on the TL;DR summarization dataset. The experiment was repeated three times with different random seeds, and the median KL divergence is plotted along with shaded regions representing the minimum and maximum KL values across these repetitions. The plot visually demonstrates the effect of including KL regularization in the HyPO algorithm.
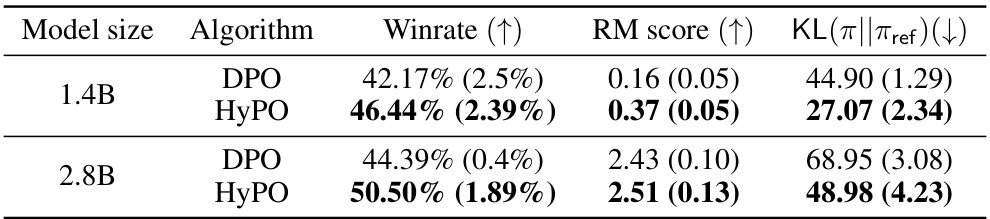
This table shows the results of the TL;DR summarization experiment using two different algorithms, DPO and HyPO, with two different model sizes (1.4B and 2.8B parameters). The metrics evaluated include Winrate (GPT-4 evaluation), Reward Model (RM) score, and KL divergence between the learned policy and the reference policy. Higher winrate and RM scores indicate better performance, while a lower KL divergence suggests the learned policy is closer to the reference policy.
In-depth insights#
Coverage & RLHF#
The interplay between coverage and RLHF (Reinforcement Learning from Human Feedback) is crucial for effective preference fine-tuning of LLMs. Coverage, signifying how well the training data represents the distribution of possible responses, directly impacts the performance and generalization ability of the learned model. Offline contrastive methods, like DPO, require strong global coverage to converge to the optimal policy; failure to meet this requirement leads to suboptimal performance. In contrast, online RL methods (like RLHF) require a weaker local coverage condition, benefiting from on-policy sampling and online regularization. This inherent difference explains why RLHF tends to outperform offline methods, especially when dealing with limited or biased data. A hybrid approach that leverages the strengths of both methods, such as HyPO, is proposed to address these limitations, enhancing performance while preserving efficiency. The theoretical analysis emphasizes the critical role of coverage in understanding the contrasting behaviors of online and offline approaches for preference fine-tuning in LLMs.
DPO’s Limits#
Direct Preference Optimization (DPO) is a popular offline method for fine-tuning large language models (LLMs), but it has limitations. DPO’s reliance on a fixed offline dataset can lead to suboptimal performance if the data doesn’t adequately represent the true reward function or target policy. This is particularly true when dealing with complex tasks where the optimal policy may lie outside the range of behaviors observed in the offline data. The lack of online interactions means DPO can’t adapt to new information or correct for biases present in the offline data. This can result in a policy that overfits the training data, leading to poor generalization to unseen examples. Furthermore, DPO’s theoretical guarantees often depend on strong assumptions about data coverage, which may not hold in real-world scenarios. Consequently, while efficient computationally, DPO often underperforms online methods like Proximal Policy Optimization (PPO) which can adapt and leverage online interactions to refine their policy. Hybrid approaches that combine aspects of both offline and online methods offer a promising avenue to overcome DPO’s limitations and leverage the benefits of both efficiency and adaptability.
HyPO Algorithm#
The HyPO algorithm, a hybrid approach to preference fine-tuning, cleverly combines the strengths of offline contrastive methods (like DPO) and online reinforcement learning (RLHF). Offline data is used for contrastive-based preference optimization, leveraging the efficiency and simplicity of DPO. However, unlike pure offline methods, HyPO incorporates online unlabeled data for KL regularization. This crucial addition mitigates overfitting issues and addresses the limitations of DPO in scenarios with insufficient data diversity. The theoretical analysis demonstrates that HyPO requires a weaker coverage condition than pure offline approaches and empirically, HyPO surpasses DPO in performance on summarization and general chat tasks while maintaining computational efficiency. HyPO’s key innovation lies in the principled integration of online KL-regularization, improving generalization and mitigating the tendency of purely offline methods to generate out-of-distribution responses. This makes HyPO a powerful tool for fine-tuning LLMs, balancing efficient offline training with the benefits of online feedback.
Extrapolation#
The concept of extrapolation in the context of preference fine-tuning for large language models (LLMs) is crucial. The core idea is that while training data may not contain optimal responses for all scenarios, effective algorithms should be able to generalize to these unseen cases. This is particularly relevant in offline methods like Direct Preference Optimization (DPO), where algorithms might surprisingly decrease the probability of both preferred and rejected responses during training. This seemingly counterintuitive behavior is explained by the authors through the lens of function approximation. Under the assumption of function approximation, the algorithms can extrapolate successfully, effectively predicting and generalizing to new optimal actions even without encountering them in the training data. This contrasts with cases where function approximation fails, resulting in less desirable behavior. The theoretical analysis highlights that successful extrapolation hinges on the interplay between the dataset’s coverage and the algorithms’ ability to represent the reward function accurately. Thus, the analysis reveals that extrapolation is not merely an empirical observation but rather a theoretically grounded capability stemming from appropriate function approximation and suitable coverage conditions.
Future Work#
Future research directions stemming from this paper could explore several promising avenues. Extending the coverage analysis to hybrid methods that combine offline and online preference data is crucial, as this approach is becoming increasingly popular. Investigating the impact of different reward model architectures and their interaction with coverage conditions would offer valuable insights into the relative strengths and weaknesses of online and offline approaches. A deeper exploration into the theoretical underpinnings of extrapolation and its relationship to function approximation, particularly within a non-linear function setting, could refine our understanding of policy generalization in preference-based learning. Finally, a comprehensive study comparing the performance of HyPO with other state-of-the-art hybrid methods would further solidify its position and identify potential areas for improvement.
More visual insights#
More on figures
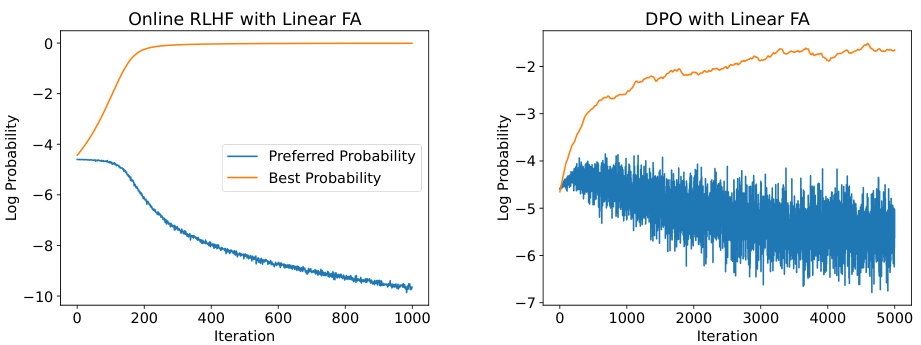
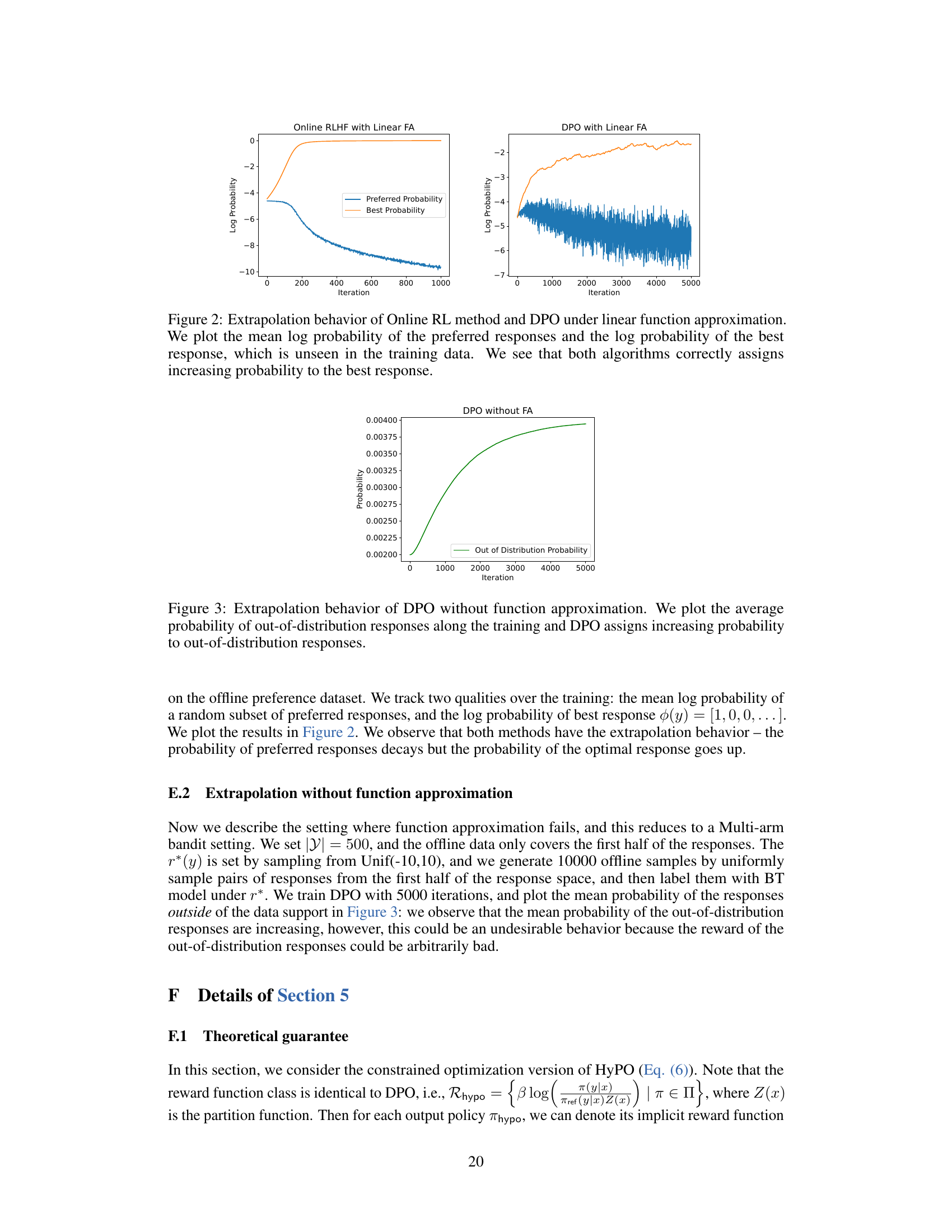
The figure shows the extrapolation behavior of online RLHF and DPO methods under the linear function approximation setting. The left panel shows that the online RLHF method correctly increases the probability of the best response (unseen in training) while simultaneously decreasing the probability of the preferred responses (seen in training). The right panel shows that DPO also exhibits this behavior, although with higher variance in its log probability trends. This demonstrates the generalization ability of both methods.
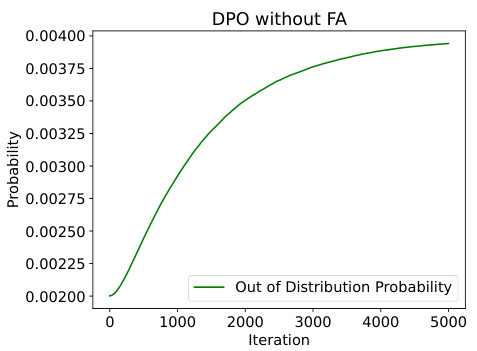
The figure shows the average probability of out-of-distribution responses during the training of DPO without function approximation. It demonstrates that as DPO trains, the probability of generating responses not seen in the training data increases. This is an interesting phenomenon because it indicates that DPO is extrapolating beyond the observed data.
More on tables

This table presents the results of evaluating three different language models on general chat benchmarks: the base Meta-Llama-3-8B-Instruct model, a model fine-tuned using Direct Preference Optimization (DPO), and a model fine-tuned using the Hybrid Preference Optimization (HyPO) method proposed in the paper. The benchmarks used assess the models’ performance across various aspects of conversational ability. The metrics used include MT-Bench scores (1st turn, 2nd turn, and average), and AlpacaEval 2.0 scores (LC Win Rate and Win Rate). The results highlight the comparative performance of DPO and HyPO against the base model.

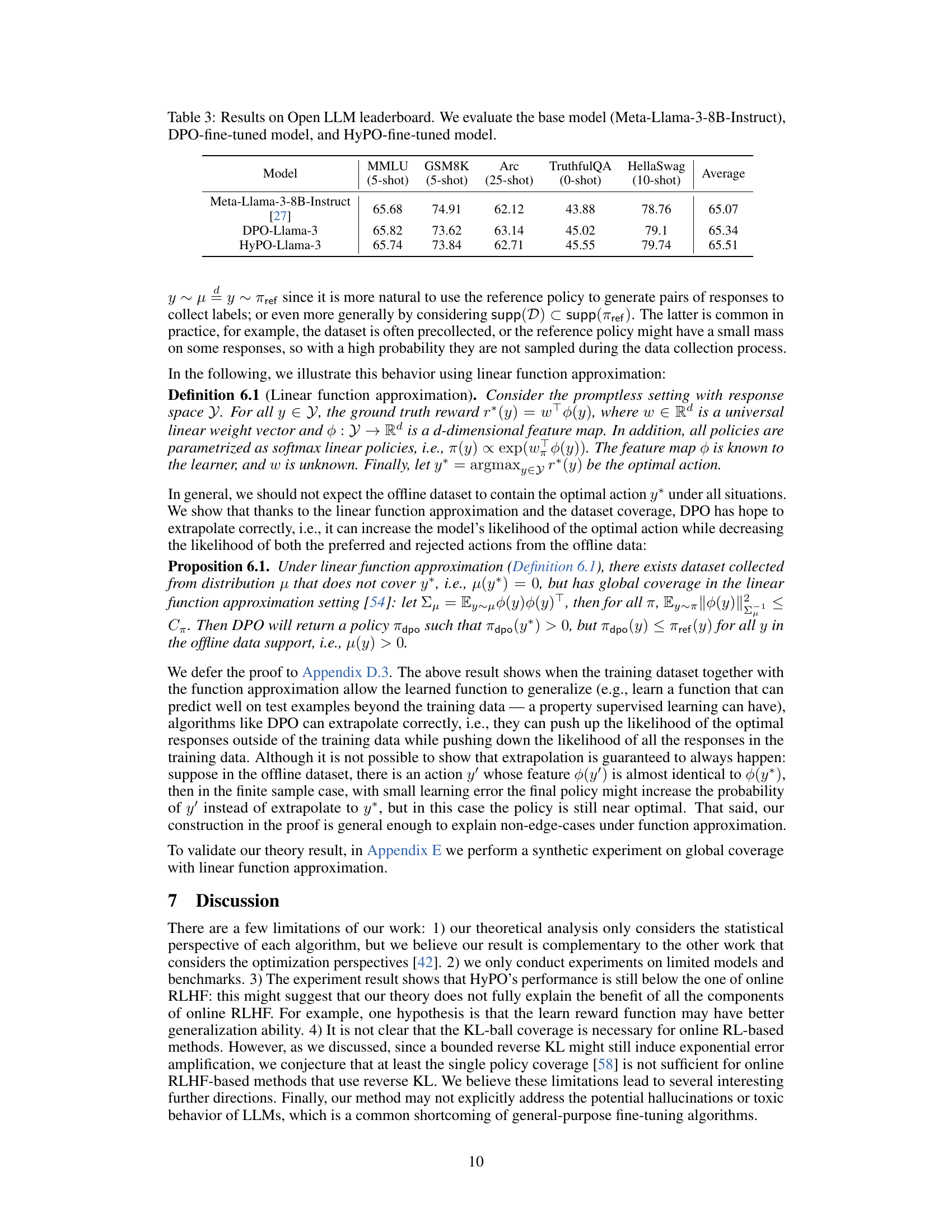
This table presents the results of evaluating three different language models on the Open LLM leaderboard benchmarks. The models are: the base Meta-Llama-3-8B-Instruct model, a model fine-tuned using the DPO (Direct Preference Optimization) method, and a model fine-tuned using the HyPO (Hybrid Preference Optimization) method. The benchmarks used are MMLU (5-shot), GSM8K (5-shot), Arc (25-shot), TruthfulQA (0-shot), and HellaSwag (10-shot). The table shows the average performance across all benchmarks for each model.

This table presents the results of experiments conducted on the TL;DR summarization dataset using two algorithms: DPO and HyPO. The table shows the win rate (evaluated by GPT-4), reward model score (RM), and the reverse KL divergence for both algorithms, across different model sizes (1.4B and 2.8B parameters). Experiments were repeated three times with different random seeds to assess the reliability of the results. Mean and standard deviation are included to reflect the variability in the results.

This table presents the results of the TL;DR summarization experiment using different algorithms (DPO and HyPO) and model sizes (1.4B and 2.8B). It shows the win rate (as determined by GPT-4), reward model score (RM), and the reverse KL divergence (KL(π||πref)) for each setting. The experiments were run with three random seeds to assess variability.
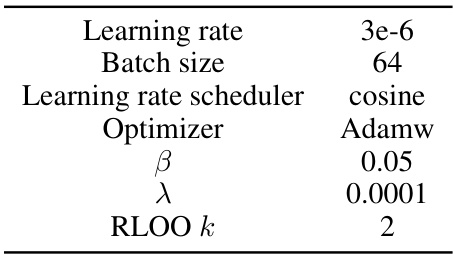
This table shows the hyperparameters used in the Hybrid Preference Optimization (HyPO) algorithm. These settings control aspects of the training process, including the learning rate, batch size, learning rate scheduler, optimizer, beta (β) which is related to the KL regularization strength, lambda (λ) which controls the weight of the KL regularization, and k which is parameter for RLOO (Reinforce with Leave One Out).
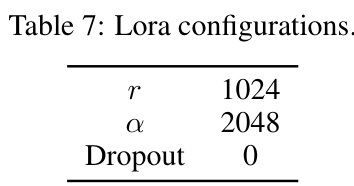
This table presents the hyperparameters used for the LoRA (Low-rank Adaptation) technique in the experiments. It shows the values for r (rank), α (scaling factor), and dropout rate. These settings determine how LoRA modifies the pre-trained language model during fine-tuning.

This table presents the results of evaluating three different language models on general chat benchmarks. The models are a base model (Meta-Llama-3-8B-Instruct) and two fine-tuned versions: one using Direct Preference Optimization (DPO) and one using the Hybrid Preference Optimization (HyPO) method proposed in the paper. The benchmarks used assess various aspects of conversational ability. The table shows the performance of each model on several metrics.

This table shows the hyperparameters used for the DPO (Direct Preference Optimization) algorithm in the general chat experiment. These settings control aspects of the training process, such as the learning rate, batch size, and learning rate scheduler. The beta (β) value is a hyperparameter that influences the balance between reward maximization and closeness to the reference policy.
Full paper#