↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Offline reinforcement learning (RL) aims to train RL agents using only pre-collected data, avoiding costly real-time interactions. Multi-task offline RL further aims to train a single agent capable of handling various tasks. However, existing multi-task offline RL methods struggle with generalization to entirely new, unseen tasks due to difficulties in managing conflicting gradients and extracting useful cross-task knowledge. This is a significant limitation for real-world application, as these methods do not adapt well to unexpected scenarios.
The proposed Decomposed Prompt Decision Transformer (DPDT) tackles this challenge. DPDT uses a two-stage approach: In the first stage (decomposed prompt tuning), it efficiently learns a general prompt and task-specific prompts by leveraging pre-trained language models. The second stage (test-time adaptation) further tunes these prompts using test data. The results demonstrate that DPDT significantly outperforms other approaches in zero-shot and few-shot generalization scenarios, showcasing its effectiveness in multi-task offline RL and its potential to enhance the robustness of RL algorithms in real-world settings.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in offline reinforcement learning and multi-task learning. It addresses the critical challenge of efficient generalization to unseen tasks, a key limitation of current methods. The proposed DPDT framework offers a novel solution that improves performance and efficiency by combining prompt engineering techniques with pre-trained language models, paving the way for enhanced adaptability and robustness in real-world applications. The findings open new avenues of research in developing more sample-efficient and generalizable RL agents.
Visual Insights#

This figure illustrates the architecture of the Decomposed Prompt Decision Transformer (DPDT). The left side shows the ‘Decomposed Prompt Tuning’ stage, highlighting the decomposition of the task prompt into cross-task and task-specific components, leveraging a teacher prompt for distillation. The right side depicts the ‘Test Time Adaptation’ stage, focusing on how the model dynamically adjusts the cross-task prompt based on the distribution of unseen test samples, using mean and variance calculations for alignment.

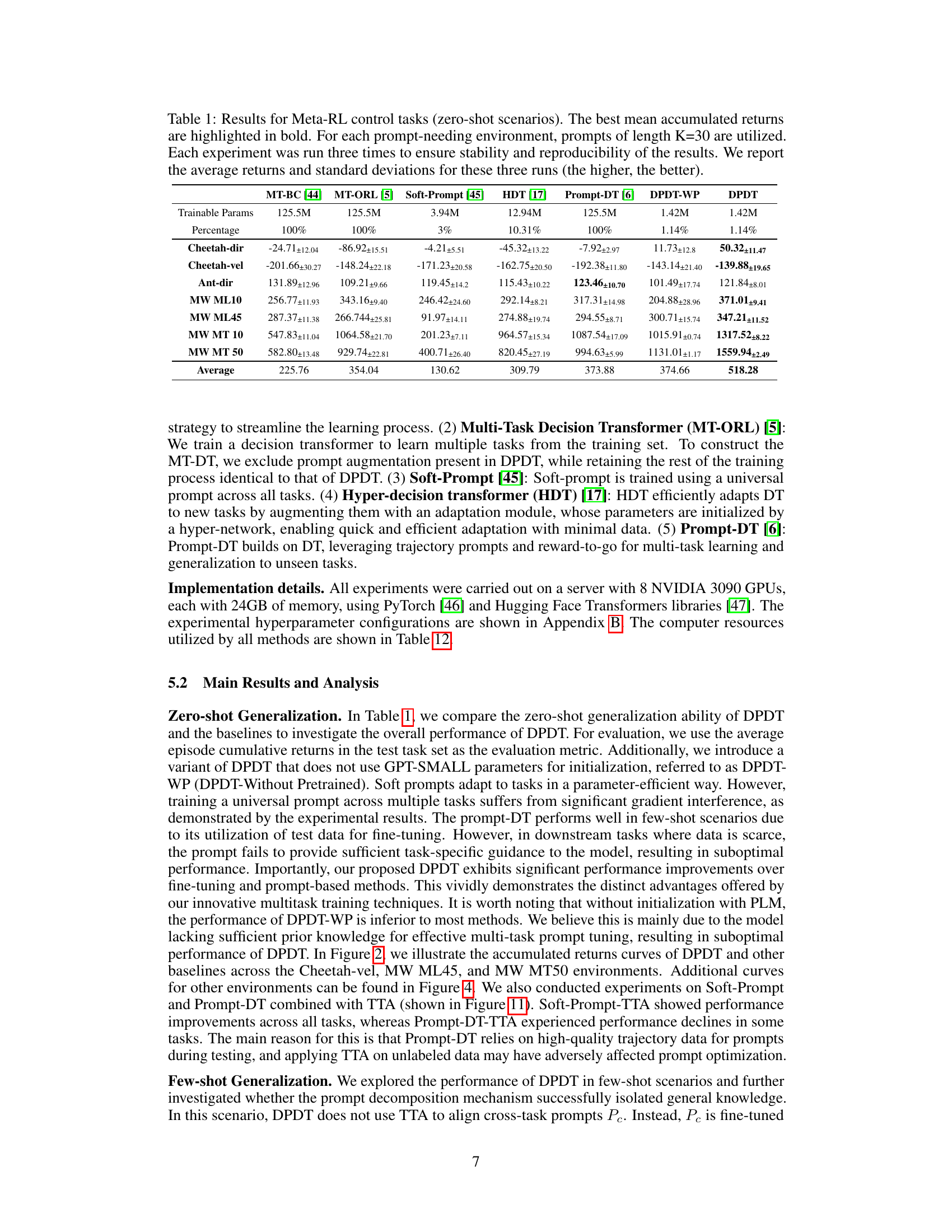
This table presents the zero-shot performance results of different offline reinforcement learning algorithms on various Meta-RL control tasks. The ‘best’ average accumulated returns are shown in bold for each task. Each algorithm’s performance is summarized with the mean and standard deviation across three runs for each task. The table also shows the number of trainable parameters for each algorithm and indicates the use of prompts with a length of 30.
In-depth insights#
Prompt Decomp Tech#
Prompt decomposition techniques in multi-task learning aim to disentangle shared and task-specific knowledge within prompts. This is crucial for efficient parameter usage and avoiding gradient conflicts when training a unified model for diverse tasks. By decomposing prompts into cross-task components (capturing general knowledge) and task-specific components, the method facilitates knowledge transfer while preventing negative interference between tasks. This approach enhances parameter efficiency because the shared knowledge is not redundantly learned for each task. The technique’s success hinges on the effective separation of shared and task-specific information within prompts. Proper decomposition enables the model to learn generalized representations effectively and adapt quickly to new tasks. A challenge lies in defining an appropriate decomposition strategy and ensuring that the components capture the intended information without redundancy or overlap. The effectiveness of prompt decomposition is ultimately evaluated on the model’s ability to generalize to unseen tasks efficiently and achieve superior performance compared to single-task or monolithic multi-task approaches.
Offline RL Advance#
Offline reinforcement learning (RL) has seen significant advancements, driven by the need to train RL agents using pre-collected datasets, eliminating the need for costly and time-consuming online data collection. Key breakthroughs include the development of algorithms that effectively handle the challenges of offline data, such as distributional shifts and insufficient data coverage. Transformer-based models, in particular, have demonstrated impressive capabilities in offline RL, leveraging their ability to learn long-range dependencies and complex relationships within sequential data. The incorporation of prompt engineering techniques, drawing inspiration from natural language processing, has further enhanced the flexibility and efficiency of offline RL models. While challenges remain, particularly regarding safety and generalization to unseen tasks, recent research focuses on leveraging multi-task learning to extract transferable knowledge and improve sample efficiency. Future directions in offline RL will likely involve addressing these remaining challenges, further improving the scalability and robustness of these methods, and exploring novel applications across various domains.
Meta-RL Superiority#
The concept of ‘Meta-RL Superiority’ in the context of a research paper likely refers to the demonstrated improved performance of a proposed Meta-Reinforcement Learning (Meta-RL) algorithm compared to existing state-of-the-art methods. A thorough exploration would involve analyzing the specific benchmarks used for evaluation. Key aspects to consider include the types of tasks, their complexity, and the metrics used to quantify performance (e.g., average return, sample efficiency). The paper should clearly articulate the novel aspects of the proposed algorithm that contribute to its superior performance. This could be due to enhanced techniques for knowledge transfer, better handling of gradient conflicts, improved parameter efficiency, or a more robust architecture. Furthermore, a convincing demonstration of ‘Meta-RL Superiority’ must include a rigorous statistical analysis showing the significance of any performance gains. The study should address potential confounding factors and provide a nuanced comparison, acknowledging the limitations of both the new approach and the existing baselines. Ultimately, a convincing argument for ‘Meta-RL Superiority’ needs to demonstrate generalizable improvements across a diverse range of tasks and environments, not merely superior results on a few specific scenarios.
Test-Time Adaptability#
Test-time adaptability, a crucial aspect in machine learning, focuses on enhancing a model’s performance on unseen data without retraining. This is particularly important for resource-constrained environments or when real-time adaptation is necessary. Effective test-time adaptation strategies often involve techniques that leverage previously learned knowledge to quickly adjust to new data distributions or task specifics. Prompt-based methods, for instance, offer a parameter-efficient approach, enabling fine-tuning of prompts for unseen tasks without extensive retraining of the entire model. Techniques like test-time augmentation and knowledge distillation can further improve robustness and generalization, particularly valuable when labeled data is scarce. A key challenge lies in balancing the speed of adaptation with the model’s accuracy and stability, requiring careful consideration of various tradeoffs. The ability to seamlessly integrate these adaptation techniques with existing model architectures and frameworks is also crucial for practical implementation. Future research should focus on developing more efficient and robust test-time adaptation strategies, capable of handling complex real-world scenarios and adapting to diverse unseen tasks.
PLM Knowledge Transfer#
The concept of “PLM Knowledge Transfer” in the context of reinforcement learning is intriguing. It leverages the rich semantic information encoded within pre-trained language models (PLMs) to improve the efficiency and effectiveness of multi-task reinforcement learning (MTRL). By initializing the model with PLM parameters, the model gains a substantial head start, requiring less training data to achieve satisfactory performance, hence addressing the data-hungry nature of transformers. Prompt-based techniques, often intertwined with PLM knowledge transfer, provide a mechanism to effectively adapt the model to diverse tasks by learning task-specific and cross-task prompts. This decomposition strategy not only enhances parameter efficiency but also alleviates the issue of gradient conflicts inherent in MTRL. The integration of PLMs thus acts as a form of effective prior knowledge injection, promoting faster convergence and improved generalization to unseen tasks. This approach ultimately results in more efficient and robust algorithms for MTRL
More visual insights#
More on figures
This figure illustrates the architecture of the Decomposed Prompt Decision Transformer (DPDT) model. It shows the two main stages: Decomposed Prompt Tuning and Test Time Adaptation. The left side depicts the prompt decomposition process during training, where a task prompt is decomposed into cross-task and task-specific prompts to avoid gradient conflicts. The right side shows the test-time adaptation phase, where the cross-task prompt is further optimized on unseen tasks using test-time adaptation techniques by comparing the statistics of training and testing samples across all layers of the model.

This figure shows the ablation study on the effect of prompt length on the performance of DPDT in zero-shot generalization scenarios. The x-axis represents different prompt lengths (3, 9, 30, 60, 90), and the y-axis shows the average scores achieved by DPDT on three different tasks: Cheetah-vel, Ant-dir, and MW ML45. The plot demonstrates the impact of prompt length on model performance, allowing one to determine the optimal length that balances model convergence and generalization performance.

This figure illustrates the architecture of the Decomposed Prompt Decision Transformer (DPDT). The left side shows the ‘Decomposed Prompt Tuning’ phase, where the task prompt is decomposed into cross-task and task-specific components using a pre-trained GPT model. The right side illustrates the ‘Test Time Adaptation’ phase, which involves dynamically adjusting the cross-task prompt on unseen tasks using the training data mean and variance for comparison.
More on tables
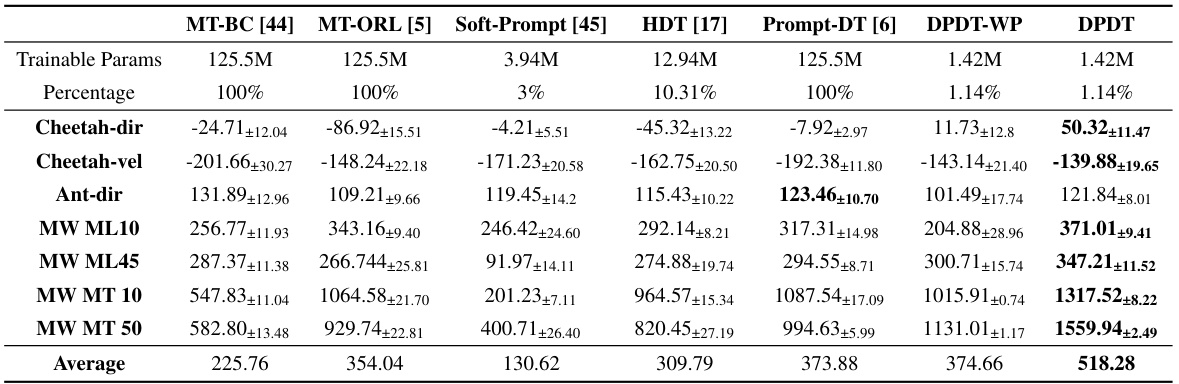
This table presents the zero-shot performance results of different offline reinforcement learning algorithms on several Meta-RL control tasks. The algorithms are compared based on their mean accumulated returns, with the best-performing algorithm highlighted for each task. The table includes the number of trainable parameters for each algorithm as a percentage of the largest model, providing a context for parameter efficiency. The consistent prompt length of 30 across tasks and three runs per experiment ensure fair comparison and reliability.

This table presents the results of zero-shot generalization experiments on various Meta-RL control tasks. It compares the performance of DPDT against several baselines (MT-BC, MT-ORL, Soft-Prompt, HDT, Prompt-DT, DPDT-WP). The table shows the mean accumulated reward and standard deviation for each algorithm across three runs for each task. Higher rewards indicate better performance. Prompts of length 30 were used for all methods requiring prompts. The best-performing algorithm for each task is highlighted in bold.
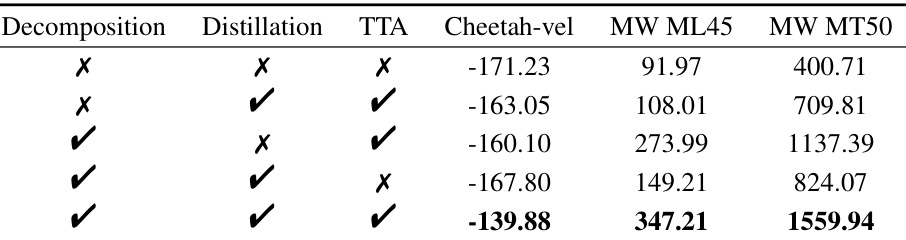
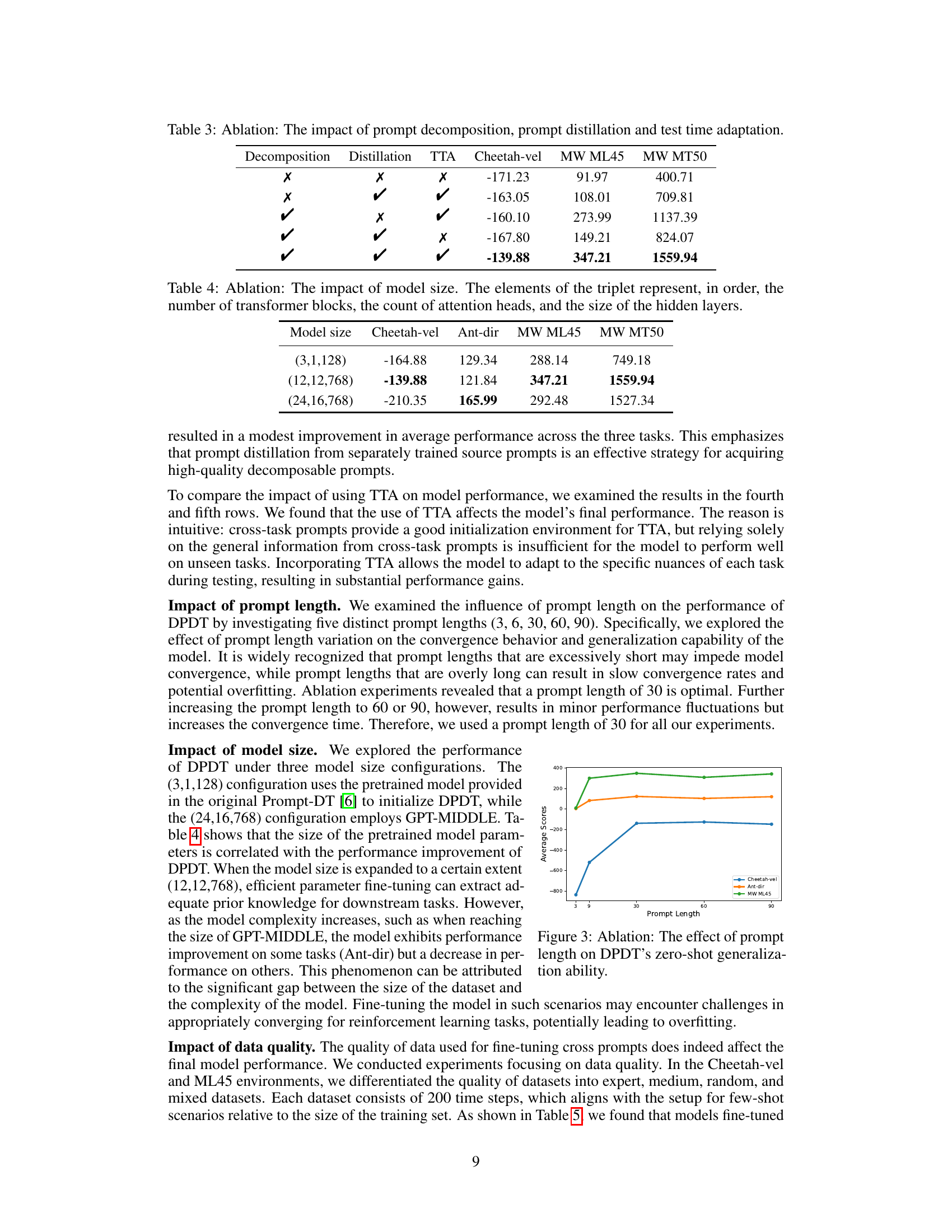
This table presents the ablation study results on the impact of three key components of the Decomposed Prompt Decision Transformer (DPDT) model: prompt decomposition, prompt distillation, and test-time adaptation. Each row represents a different combination of these components being enabled (✓) or disabled (✗). The final three columns show the average accumulated reward across three tasks (Cheetah-vel, MW ML45, and MW MT50). The results demonstrate how each component contributes to the overall performance of the model, and which combination yields the best results.
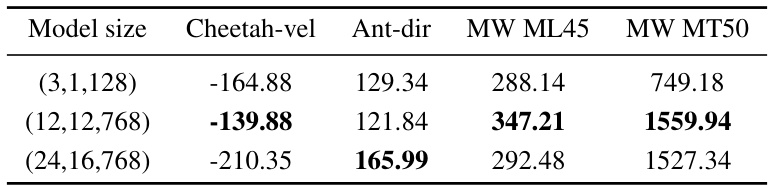
This table presents the ablation study on the impact of model size on the performance of the proposed Decomposed Prompt Decision Transformer (DPDT). Three different model sizes are evaluated: (3,1,128), (12,12,768), and (24,16,768). The numbers represent the number of transformer blocks, attention heads, and the size of hidden layers respectively. The table shows the average accumulated returns for each model size across different tasks (Cheetah-vel, Ant-dir, MW ML45, and MW MT50).
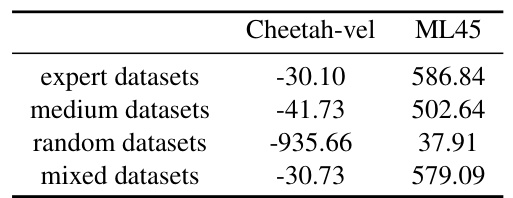
This ablation study investigates the effect of data quality on the performance of the DPDT model. Four different types of datasets—expert, medium, random, and mixed—were used for fine-tuning the cross-task prompts in the Cheetah-vel and ML45 environments. The results show that models fine-tuned using expert datasets perform the best, while models trained on random datasets perform the worst.

This table presents the ablation study on the impact of different learning rates for the cross-task prompt (lrPc) and task-specific prompt (lrPk) during the prompt decomposition phase of the DPDT model. The results, measured in average episode return on the ML45 task, show how different learning rate combinations affect model performance.
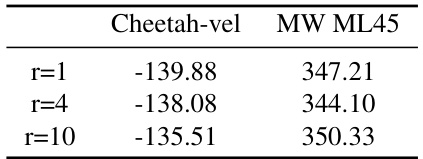
This table presents the zero-shot results of different algorithms on several Meta-RL control tasks. The algorithms are compared on their average accumulated returns, with the best performance highlighted. It shows the average return and standard deviation over three experimental runs for each algorithm and task.

This table presents the zero-shot performance results of different algorithms on various Meta-RL control tasks. The results are shown as mean accumulated rewards and standard deviations, with the best performing algorithm in bold for each task. The table includes the number of trainable parameters and the percentage relative to the largest model for each method.

This table presents the zero-shot performance results of different algorithms on several Meta-RL control tasks. The algorithms are compared based on the mean accumulated rewards and standard deviation across three runs per task, with the best-performing algorithm highlighted in bold. The table includes the number of trainable parameters for each model and indicates that prompts of length 30 were used for tasks requiring prompts.

This table presents the ablation study on the impact of different adaptation methods used in the Test Time Adaptation phase of the DPDT model. It compares the performance of DPDT using different initialization strategies for the cross-task prompts during testing on unseen tasks.

This table presents the results of zero-shot generalization experiments on various Meta-RL control tasks. The performance of DPDT is compared against several baseline methods (MT-BC, MT-ORL, Soft-Prompt, HDT, and Prompt-DT). For each task and method, the average accumulated reward and standard deviation over three runs are reported. The best performing method for each task is highlighted in bold. The table shows that DPDT generally outperforms the baselines, demonstrating its effectiveness in zero-shot settings.

This table presents the zero-shot results of different algorithms on various Meta-RL control tasks. The table compares the average accumulated returns achieved by each method, highlighting the best performing algorithm for each task. It includes details on the number of trainable parameters for each model, expressed both as a raw number and as a percentage relative to the largest model (125.5M parameters). The table also shows the average accumulated returns and their standard deviation across three experimental runs for each method and task.

This table presents the results of zero-shot generalization experiments on several Meta-RL control tasks. It compares the performance of DPDT to several baseline methods (MT-BC, MT-ORL, Soft-Prompt, HDT, and Prompt-DT) across various environments (Cheetah-dir, Cheetah-vel, Ant-dir, and MetaWorld tasks). The table shows the mean accumulated returns and standard deviations for each method and environment, highlighting the best performing method for each task. Prompt length (K) is kept constant at 30, and each experiment is repeated three times for reliability.
Full paper#