↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current vision-language pre-training methods, like CLIP, rely on computationally expensive contrastive learning approaches and require substantial computational resources, limiting accessibility for many researchers. Furthermore, the complex process often involves text preprocessing that can discard valuable information. These challenges hinder the widespread adoption and exploration of this promising field.
SuperClass addresses these issues by employing a simple, classification-based approach. It directly uses tokenized raw text as labels, eliminating the need for text encoders and large batch sizes. This innovative methodology significantly reduces the computational cost while maintaining or even surpassing the performance of existing contrastive methods on various downstream tasks. The scalability of SuperClass, as demonstrated by experiments on different model and data sizes, makes it a highly attractive and accessible solution for researchers in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial because it offers a computationally efficient alternative to existing vision-language pre-training methods. By simplifying the training process, it lowers the barrier to entry for researchers, allowing them to explore this field without extensive resources. The results demonstrate comparable or even superior performance, opening up new avenues for research and applications in vision and language tasks.
Visual Insights#
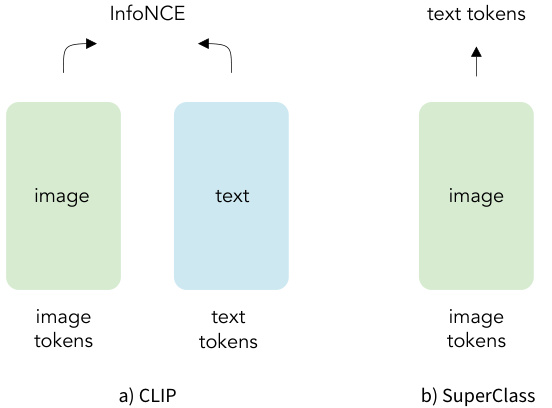
This figure compares the architectures of CLIP and SuperClass. CLIP uses two separate transformer encoders: one for images and one for text (processed at a subword level). SuperClass, in contrast, uses a single transformer encoder and directly uses tokenized raw text as classification labels, eliminating the need for a separate text encoder.
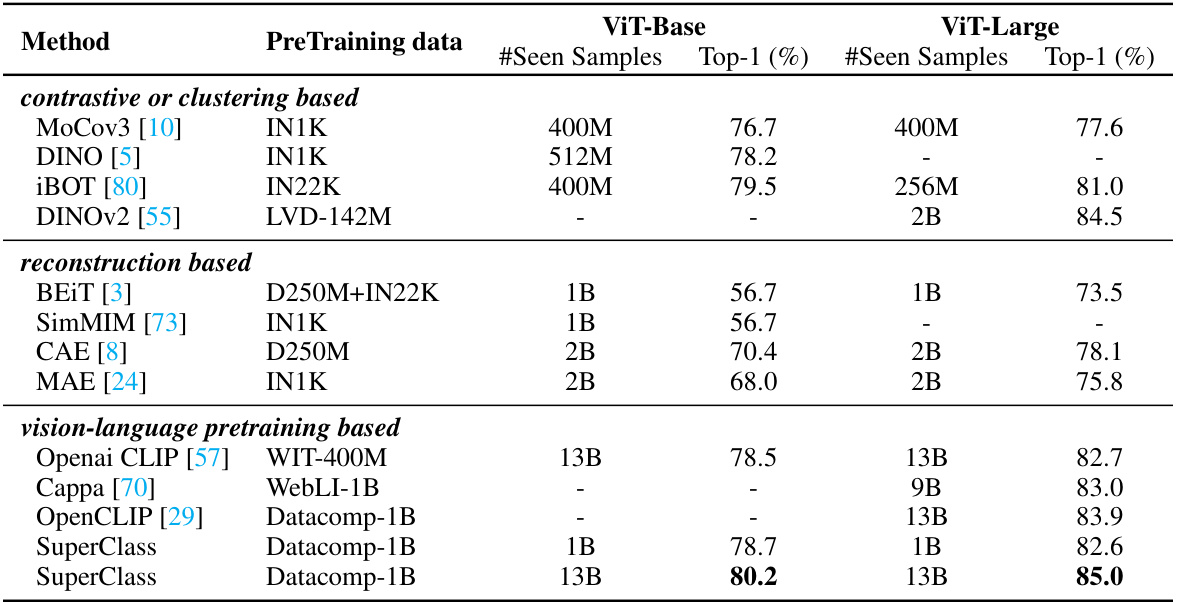
This table compares the linear probing top-1 accuracy on the ImageNet-1K dataset for various self-supervised and vision-language pre-training methods. It shows the number of seen samples and the achieved accuracy for both ViT-Base and ViT-Large models. The methods are categorized into contrastive or clustering-based, reconstruction-based, and vision-language pre-training-based approaches. The table highlights the performance of SuperClass in comparison to other state-of-the-art methods.
In-depth insights#
Vision-Language Pretraining#
Vision-language pre-training aims to leverage the power of large-scale image-text datasets to learn joint representations of visual and textual data. This approach contrasts with traditional methods that train vision and language models separately. Key advantages include enabling zero-shot and few-shot capabilities, allowing models to generalize to unseen tasks and data without extensive fine-tuning. However, significant computational resources are required, particularly for contrastive methods that often necessitate large batch sizes for optimal performance. Alternative approaches, such as classification-based methods, aim to simplify the training process while maintaining competitive performance. The field is actively exploring novel training strategies, model architectures, and evaluation benchmarks to further improve the scalability and efficiency of vision-language pre-training and unlock its full potential across various downstream applications.
SuperClass Method#
The SuperClass method presents a novel approach to vision-language pre-training, diverging from the contrastive learning paradigm employed by methods like CLIP. Instead of contrasting image and text embeddings, SuperClass leverages the raw, tokenized text as direct supervised labels for image classification. This simplification eliminates the need for a separate text encoder and allows for smaller batch sizes during training, making the method significantly more computationally efficient. The core idea is surprisingly effective, achieving competitive performance on downstream tasks, which include both standard computer vision benchmarks and vision-language tasks. The authors demonstrate a strong scaling behavior of SuperClass with respect to model and data size, further highlighting the method’s practicality and potential as a foundational technique in vision-language pre-training.
Scaling Experiments#
Scaling experiments in vision-language models are crucial for understanding performance limits and resource efficiency. A well-designed experiment would systematically vary model size, training duration, and dataset size, measuring downstream performance metrics on multiple benchmarks. Careful attention to experimental design is key to avoid confounding variables. Analysis should explore scaling laws and compare the efficiency of different training methods (e.g., contrastive vs. classification). Results must be presented clearly showing not just performance gains but also the computational cost and resource implications. Comparing with prior work allows for assessing the advancements made by a new model, especially considering different hardware and software environments. This would demonstrate the scalability and efficiency of the approach, highlighting advantages in terms of computational cost, model size, and data requirements. Finally, discussing the limitations of the scaling approach is essential for providing a complete picture and guiding future research.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In a vision-language model, this might involve removing specific layers of the image encoder or the text encoder, altering attention mechanisms, or changing the loss function. By observing how performance degrades with each ablation, researchers can pinpoint crucial elements and understand the overall architecture’s strengths and weaknesses. For instance, removing a particular attention layer might significantly impact performance on certain downstream tasks, highlighting that layer’s importance in handling specific types of visual-linguistic relationships. Careful selection of ablated components is key to drawing meaningful conclusions. Ablation studies can also reveal redundancies within the model, identifying areas that could be simplified or removed without impacting performance. Furthermore, they could illuminate potential bottlenecks or areas requiring further optimization to improve the model’s efficiency and accuracy. Ultimately, robust ablation studies provide valuable insights into the inner workings of the model, informing future design choices and architectural improvements.
Future Directions#
Future research could explore several promising avenues. Improving the scalability of classification-based methods to even larger datasets and model sizes is crucial. Investigating alternative loss functions beyond Softmax to better handle noisy image-text data and better capture nuanced relationships within the data would also be valuable. Addressing the limitations of ignoring word order and object relationships in the current approach by incorporating techniques that capture contextual information more effectively, such as transformers or graph neural networks, is a key priority. Further research should explore the potential of incorporating external knowledge sources or utilizing techniques from other domains, such as knowledge graphs, to further enhance the model’s performance on downstream tasks. Finally, a rigorous comparison with other state-of-the-art methods across various benchmarks would solidify the approach’s place within the broader field.
More visual insights#
More on tables

This table presents the performance of the frozen visual representations (features extracted from the image encoder before the classification head) of several models on three different image classification datasets: ImageNet, Pets, and Cars. The evaluation metric is 10-shot linear evaluation accuracy, indicating how well a linear classifier can distinguish the categories when using the frozen features as input. The table shows that SuperClass achieves competitive results on ImageNet and Pets and a similar performance on Cars compared to other models, including those using contrastive learning.

This table compares the zero-shot classification accuracy on ImageNet-1k and the CIDEr score for COCO captioning of various vision-language pre-training models. It shows that SuperClass achieves competitive performance to other models, especially when using a ViT-L/16 backbone after lock-image tuning. The results highlight the effectiveness of SuperClass in zero-shot settings.
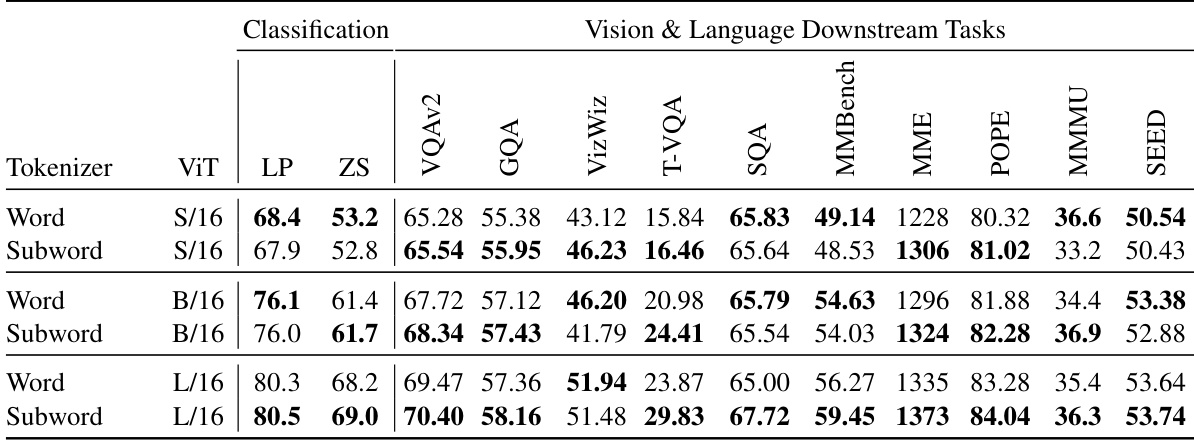
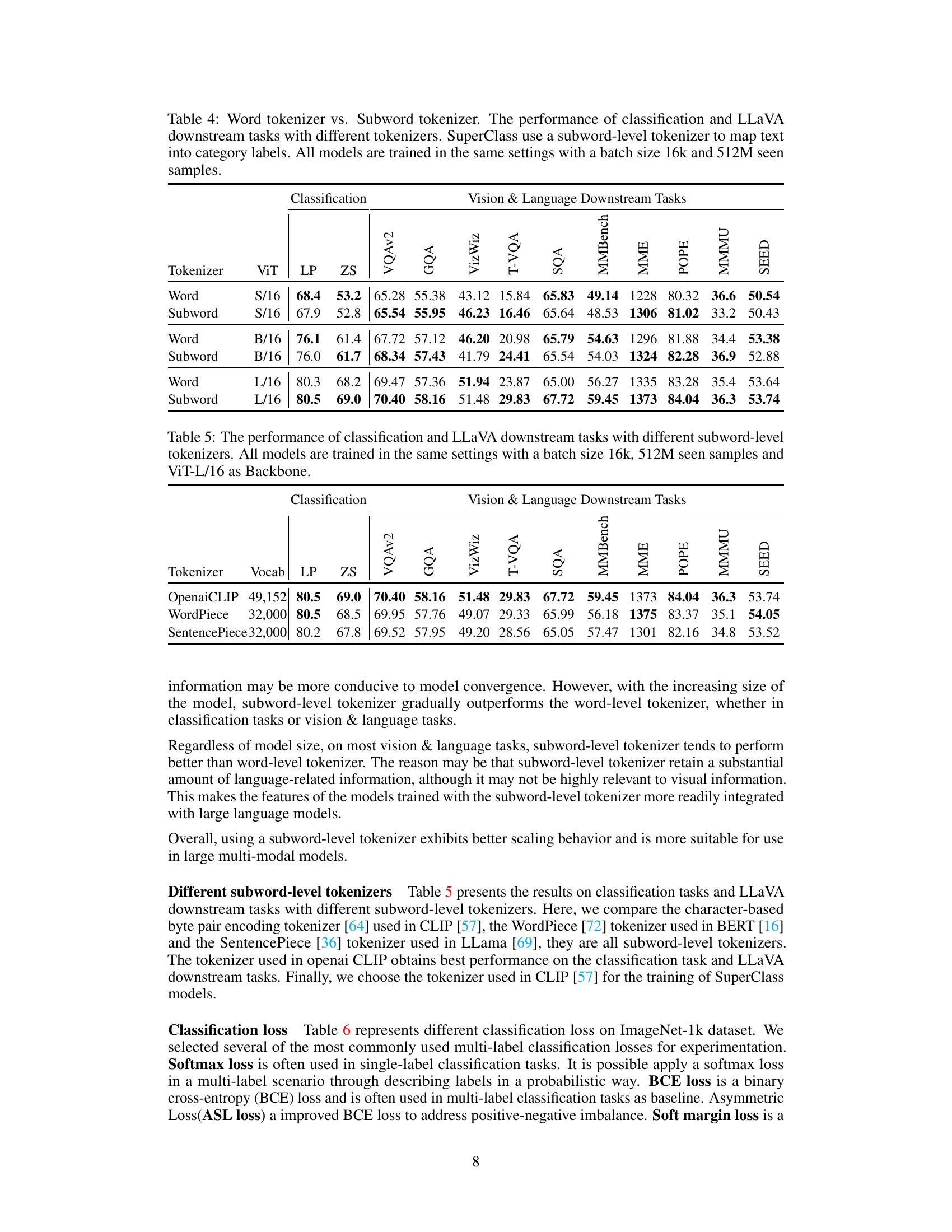
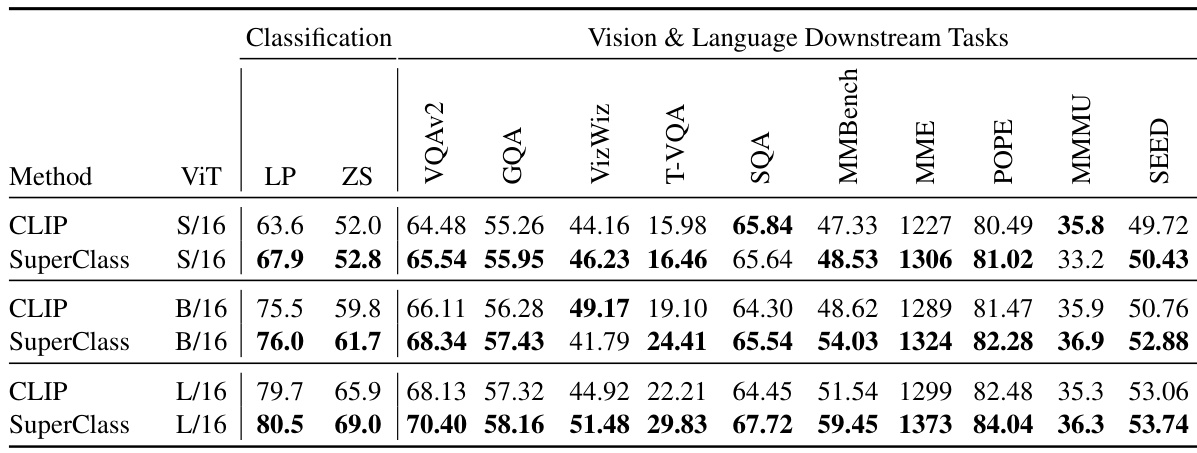
This table compares the performance of using word-level and subword-level tokenizers for both classification and vision & language downstream tasks using the SuperClass model. The results show the impact of tokenizer choice on model performance across different model sizes (ViT-S/16, ViT-B/16, ViT-L/16). All models were trained using the same parameters (batch size 16k, 512M seen samples).
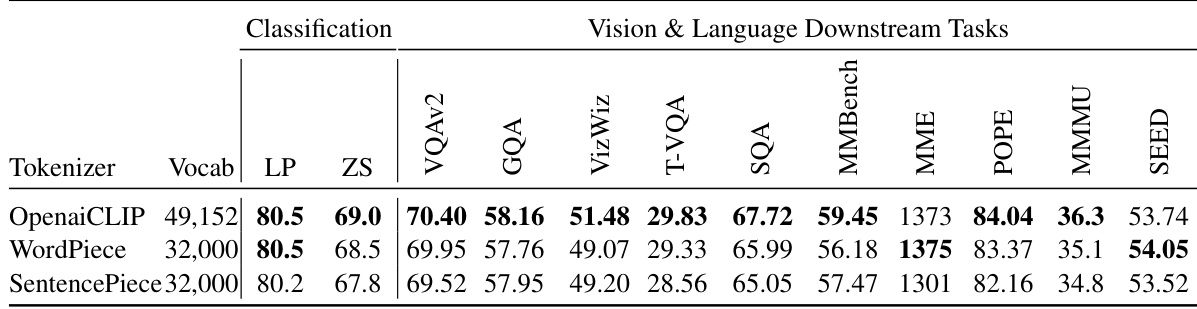
This table compares the performance of different subword-level tokenizers (OpenaiCLIP, WordPiece, SentencePiece) on classification and vision & language downstream tasks. The results highlight the impact of tokenizer choice on the model’s ability to learn effective representations for both image classification and downstream tasks that leverage both vision and language modalities. All models were trained using the same hyperparameters and data, using a ViT-L/16 backbone.

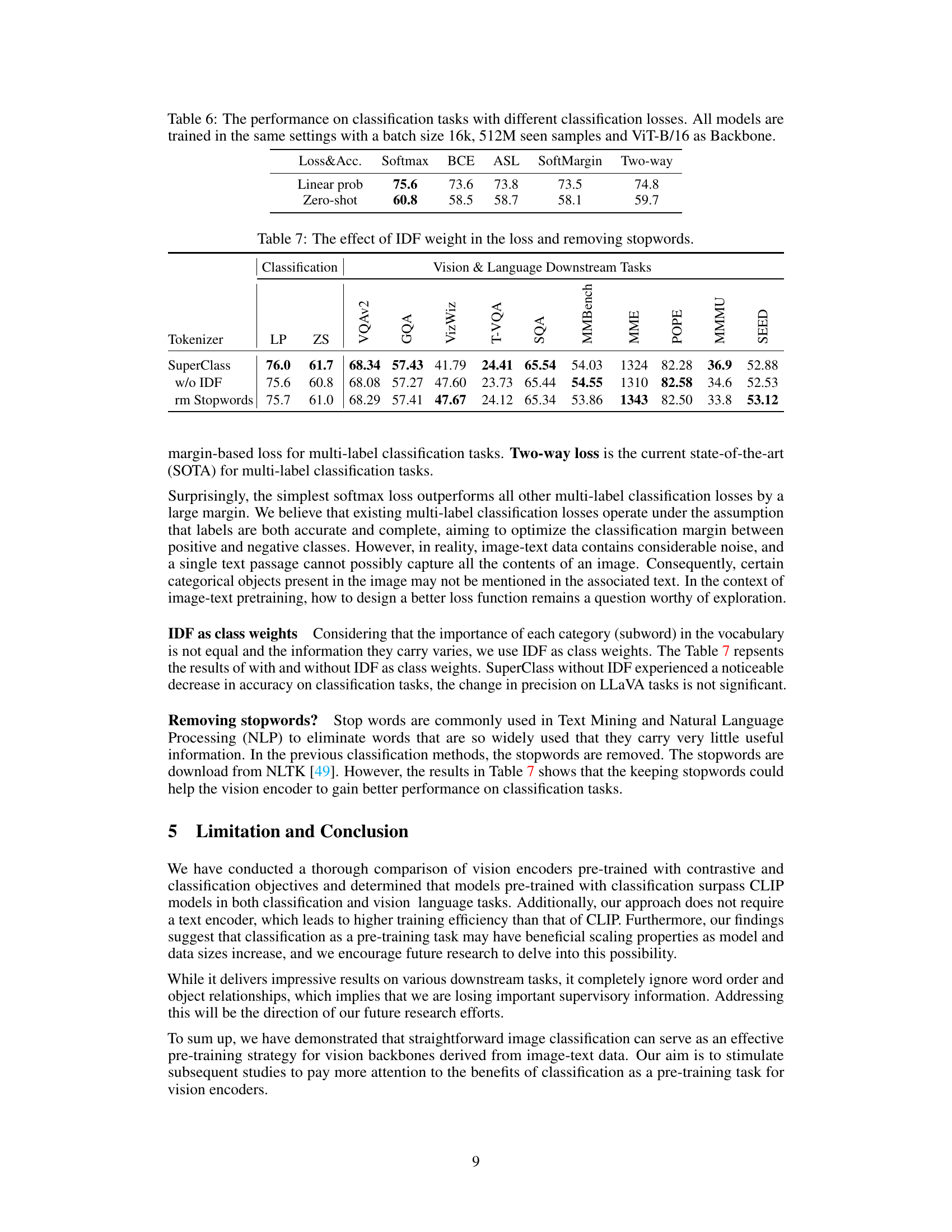
This table shows the performance of different classification losses (Softmax, BCE, ASL, SoftMargin, Two-way) on classification and zero-shot tasks using ViT-B/16 backbone. The models were trained with a batch size of 16k and 512M seen samples. The results highlight the performance differences between various loss functions and help determine the best-performing loss for this specific pre-training task.
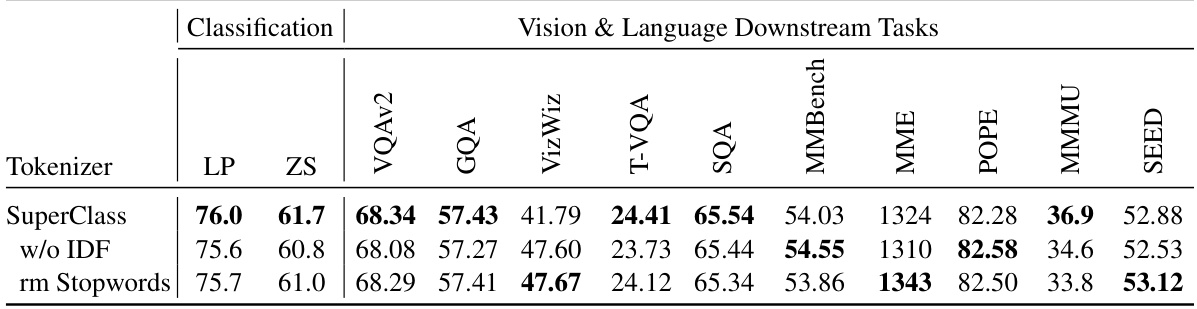
This table presents the ablation study results on the performance of SuperClass model with and without IDF (Inverse Document Frequency) weighting in the loss function and with and without removing stop words from the text. It shows the impact of these techniques on both classification tasks and several vision and language downstream tasks, providing a quantitative evaluation of their contribution to the overall performance of the model.
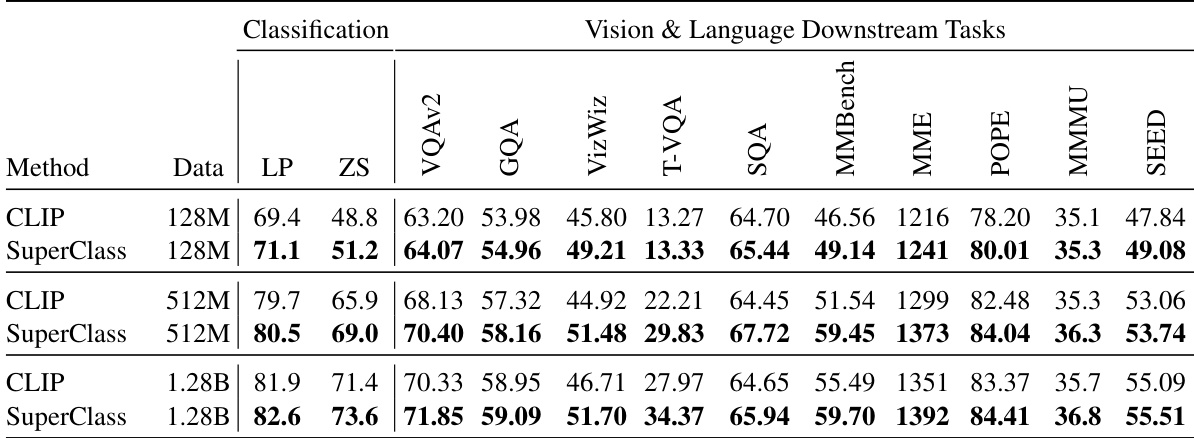
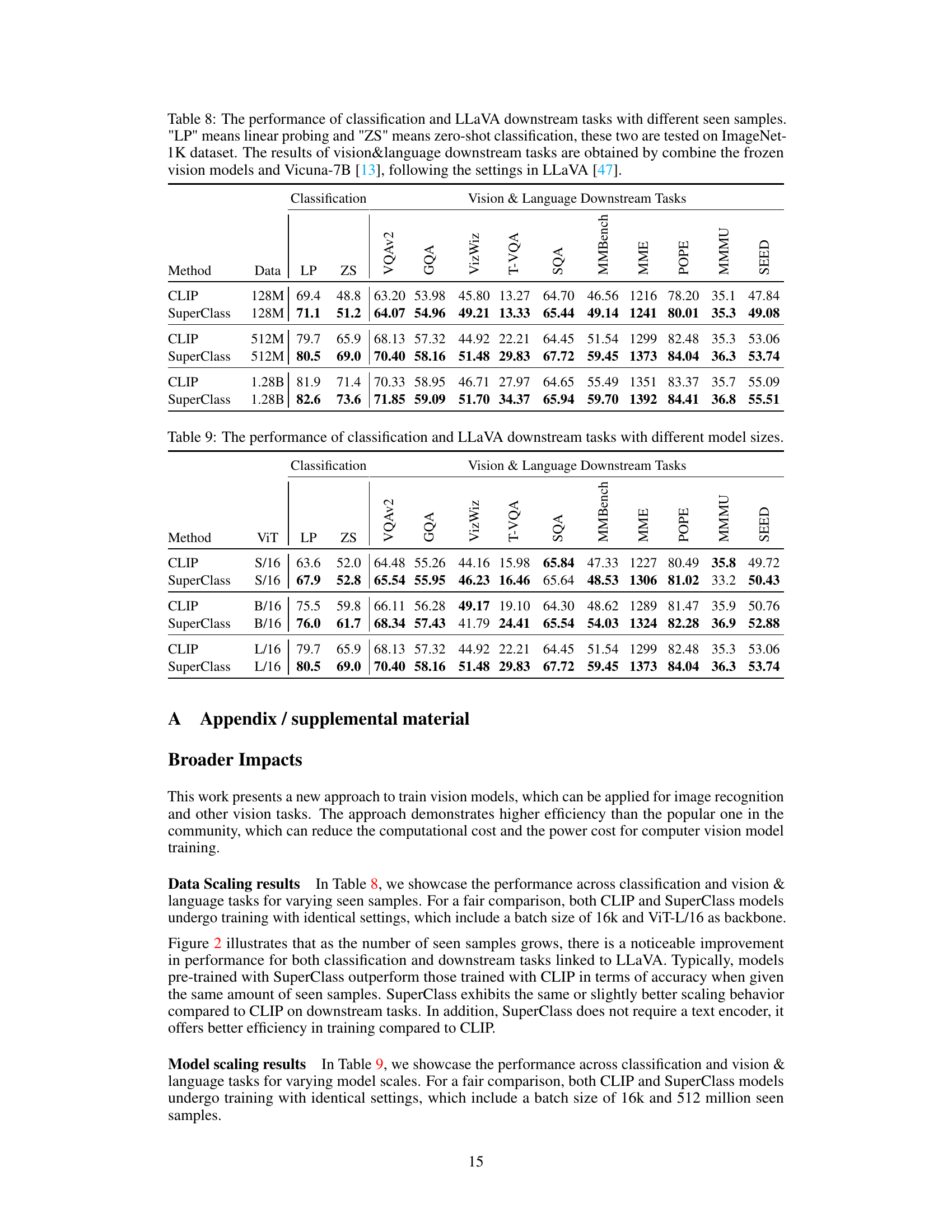
This table shows the performance comparison between CLIP and SuperClass on various tasks with different amounts of training data. The tasks include image classification (linear probing and zero-shot) and several vision-language downstream tasks using the LLaVA framework. The results show how both methods scale with larger amounts of training data.
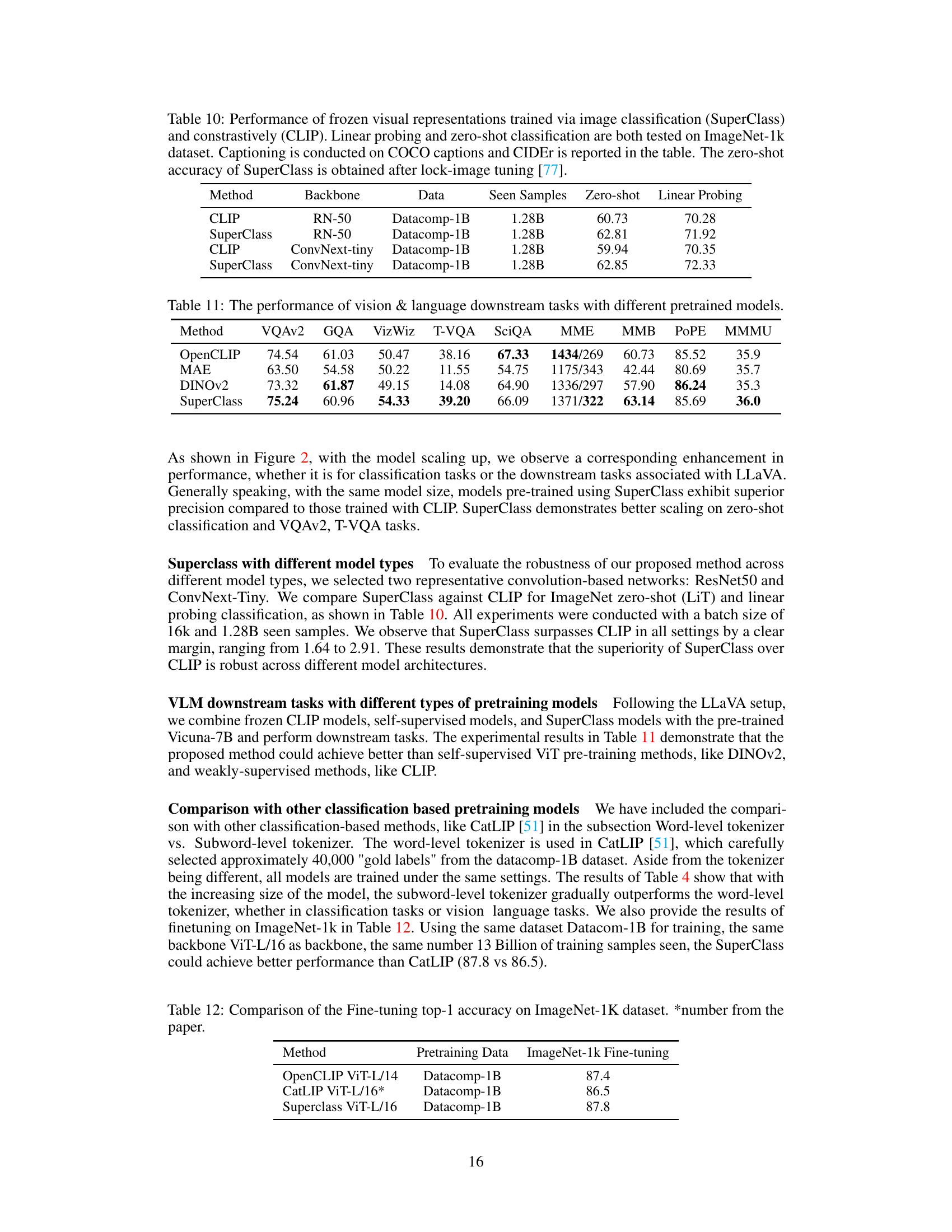
This table compares the performance of SuperClass and CLIP on various downstream tasks, including zero-shot and linear probing classification on ImageNet-1k and captioning on COCO. It shows the performance using different backbones (RN-50 and ConvNext-tiny) and highlights SuperClass’s superior performance in zero-shot and linear probing classification.

This table compares the performance of SuperClass and CLIP on various tasks using different backbones (RN-50 and ConvNext-tiny). It shows the zero-shot accuracy, linear probing accuracy on ImageNet-1k, and captioning performance (CIDEr score) on COCO captions. The results highlight the improved performance of SuperClass over CLIP across these tasks and backbones.

This table compares the performance of various vision-language pretrained models (OpenCLIP, MAE, DINOv2, and SuperClass) on several downstream tasks. The tasks include VQAv2, GQA, VizWiz, T-VQA, SciQA, MME, MMB, PoPE, and MMMU. The results show the performance of each model on each task, providing a comprehensive comparison of their abilities in various vision and language applications.

This table compares the fine-tuning top-1 accuracy on the ImageNet-1K dataset for three different methods: OpenCLIP, CatLIP, and Superclass. All models used the Datacomp-1B dataset for pretraining. The table highlights the fine-tuning performance achieved by each method, showing Superclass achieving the highest accuracy (87.8). The asterisk (*) indicates that the CatLIP result is taken from their paper.
Full paper#