↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Continual learning, particularly generalized category discovery (GCD), is crucial for creating robust AI systems that can adapt to evolving data. However, current methods struggle with ‘prediction bias’ (misclassifying new data as old) and ‘hardness bias’ (forgetting previously learned difficult classes). These biases hinder the incremental learning process, limiting the real-world applicability of such AI systems.
The paper introduces ‘Happy’, a new framework that directly addresses these biases. Happy uses ‘hardness-aware prototype sampling’ to selectively focus on difficult classes, reducing forgetting. It also employs ‘clustering-guided initialization’ and ‘soft entropy regularization’ for better new class discovery by reducing overconfidence in already-known classes. Through extensive experiments, Happy demonstrates significant improvements over existing methods across multiple datasets, showcasing its effectiveness in handling the challenges of continual GCD.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the realistic challenges of continual generalized category discovery, a crucial area for developing robust AI systems in dynamic environments. The proposed Happy framework effectively addresses prediction and hardness bias, offering a significant advancement for handling continual learning tasks. This research opens new avenues for improved AI models that can learn efficiently over time without catastrophic forgetting, thus impacting various fields such as computer vision and robotics.
Visual Insights#
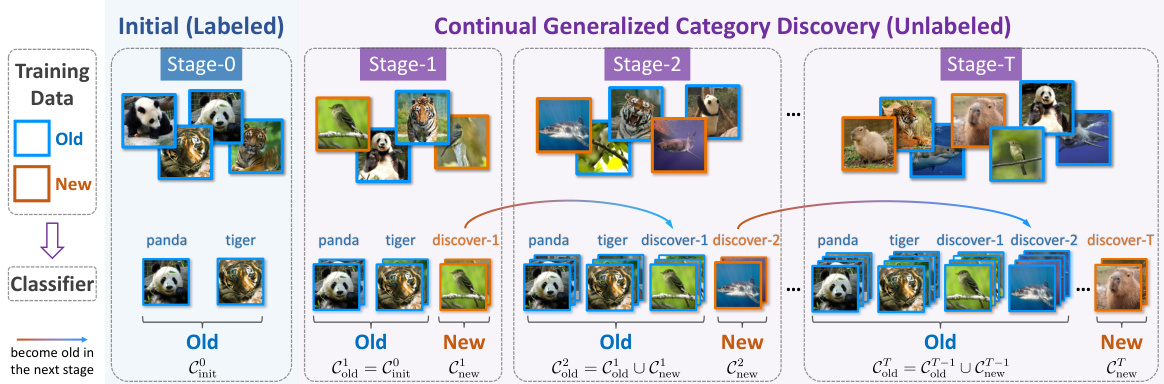
This figure illustrates the process of Continual Generalized Category Discovery (C-GCD). It starts with an initial training phase using labeled data (Stage-0). Subsequent stages involve incremental learning from unlabeled data containing both previously seen (‘old’) and unseen (’new’) classes (Stages 1-T). The key aspect highlighted is that the model does not retain past data samples and has to learn continuously. The figure emphasizes that the number of new classes increases over stages and that there’s no prior knowledge about the proportion of old and new class samples in each stage.

This table presents the performance comparison of various methods on four different datasets for a 5-stage continual generalized category discovery task. The methods are evaluated across multiple stages, comparing overall accuracy, accuracy on old classes, and accuracy on new classes. A similar starting accuracy (Stage-0) ensures fair comparison across different continual learning methods.
In-depth insights#
Debiased C-GCD#
The concept of “Debiased C-GCD” introduces a crucial advancement in continual learning, specifically addressing the inherent biases in Continual Generalized Category Discovery. Standard C-GCD methods often struggle with prediction bias, misclassifying novel categories as previously learned ones, and hardness bias, exhibiting inconsistent performance across categories of varying difficulty. A “Debiased C-GCD” framework directly tackles these issues by employing techniques like clustering-guided initialization for robust feature representation of new classes and soft entropy regularization to allocate appropriate probabilities, thus improving the model’s ability to discern between old and new categories. Furthermore, hardness-aware prototype sampling actively mitigates catastrophic forgetting by prioritizing the learning of difficult, previously seen classes. This results in a more balanced and robust continual learning system, capable of achieving significant performance gains across diverse datasets. The framework’s emphasis on bias mitigation showcases a deeper understanding of the inherent challenges in continual learning and offers a pathway toward more reliable and generalizable open-world AI systems.
Bias Mitigation#
The research paper tackles the crucial problem of bias in continual generalized category discovery (C-GCD). Bias, in this context, manifests as prediction bias (misclassifying new classes as old) and hardness bias (uneven difficulty across classes). The proposed framework, Happy, directly addresses these issues through a multi-pronged approach. Hardness-aware prototype sampling strategically samples from difficult classes to mitigate forgetting. Soft entropy regularization appropriately weighs probabilities for new classes, preventing overconfidence in old classes and enhancing the discovery of novel categories. Clustering-guided initialization ensures robust feature representation for new classes. These combined strategies highlight the significance of a multifaceted approach to bias mitigation in continual learning scenarios, emphasizing the importance of considering both prediction and hardness biases for robust model performance.
Prototype Sampling#
Prototype sampling, in the context of continual learning and specifically within the framework of generalized category discovery, is a crucial technique for managing the trade-off between learning new categories and retaining previously acquired knowledge. It addresses the problem of catastrophic forgetting, where the model’s performance on older categories degrades significantly as it learns new ones. The core idea is to selectively sample prototypes from the feature representations of previously learned categories. This sampling is not random; instead, it’s designed to prioritize categories exhibiting higher hardness (i.e., those more challenging to classify correctly or those with greater feature similarity to newly learned categories). By focusing on harder categories, the model reinforces its understanding of these challenging instances, reducing the likelihood of forgetting. Hardness-aware prototype sampling is a sophisticated approach that dynamically selects prototypes based on an estimated hardness score, ensuring that the model devotes sufficient attention to maintaining proficiency on the most difficult categories. This approach offers a principled way to address the complexities of continual learning by strategically managing the memory and computational resources. It prevents catastrophic forgetting while also contributing to robust feature representation learning, thereby facilitating the discovery of new classes effectively.
C-GCD Challenges#
Continual Generalized Category Discovery (C-GCD) presents unique challenges stemming from the inherent conflict between learning new categories and retaining previously acquired knowledge. The open-world nature of the problem, where the model continuously encounters unseen data, necessitates mechanisms to avoid catastrophic forgetting. The incremental nature of learning, with limited or no access to past data, severely restricts the ability to use traditional rehearsal strategies. Data scarcity for newly discovered classes compared to established classes adds another layer of difficulty, affecting both model accuracy and robust generalization. Addressing these issues requires innovative solutions that combine robust feature extraction and representation with efficient memory management strategies, and adaptive learning techniques capable of handling the uncertainty and class imbalance inherent in the continually evolving data streams.
Future Works#
The authors suggest several promising avenues for future research. Addressing the imbalance in labeling conditions between initial and continual stages in C-GCD is crucial, potentially through techniques like confidence calibration. Further exploration of competent class number estimation methods in unsupervised settings is also warranted. Extending the C-GCD framework beyond classification tasks to encompass object detection and semantic segmentation would broaden its applicability and impact. Finally, the authors highlight the need to mitigate potential bias and fairness issues, especially concerning the use of prior knowledge which can perpetuate existing biases, thus requiring careful consideration of ethical implications in future implementations.
More visual insights#
More on figures
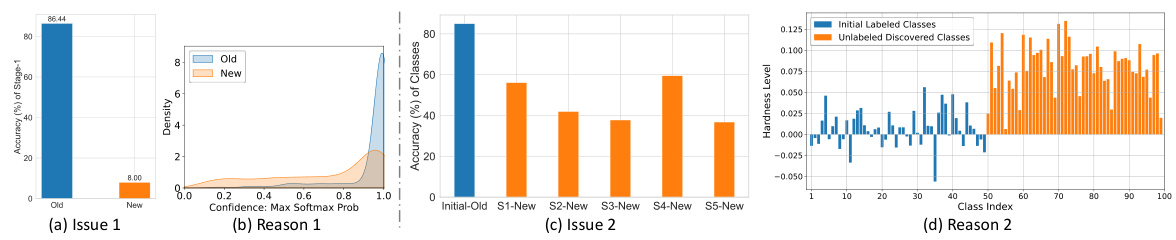
This figure presents preliminary experimental results that reveal two key issues in continual generalized category discovery (C-GCD): prediction bias and hardness bias. (a) shows a significant performance gap between accuracy on old and new classes. (b) illustrates that this is due to the model being overconfident in its predictions for old classes (prediction bias). (c) highlights accuracy fluctuations for new classes across multiple stages. (d) explains this is caused by varying difficulty levels across different classes (hardness bias). These findings motivate the proposed debiased learning framework in the paper.

This figure illustrates the Happy framework, a debiased learning framework for continual generalized category discovery. The top part shows the overall learning pipeline, while the bottom left focuses on clustering-guided initialization and soft entropy regularization for effective novel class discovery. The bottom right details hardness-aware prototype sampling to mitigate catastrophic forgetting of old classes.
This figure illustrates the Happy framework, which is a debiased learning framework for continual generalized category discovery. It shows the overall pipeline, which consists of initial supervised training and continual unsupervised discovery. The figure highlights two key components of the framework: clustering-guided initialization with soft entropy regularization to discover new classes, and hardness-aware prototype sampling to mitigate forgetting of old classes. The diagram visually explains how these components work together to address prediction bias and hardness bias in the continual learning setting.

This figure displays the distribution of confidence scores for old and new classes, using four different metrics: Max Softmax Probability, Max Logit, Margin, and Negative Entropy. The distributions highlight a significant difference in confidence scores between old (previously seen) and new classes, indicating a prediction bias towards old classes. This bias is visualized in each of the four subplots and underscores the challenges addressed by the Happy framework in the paper.
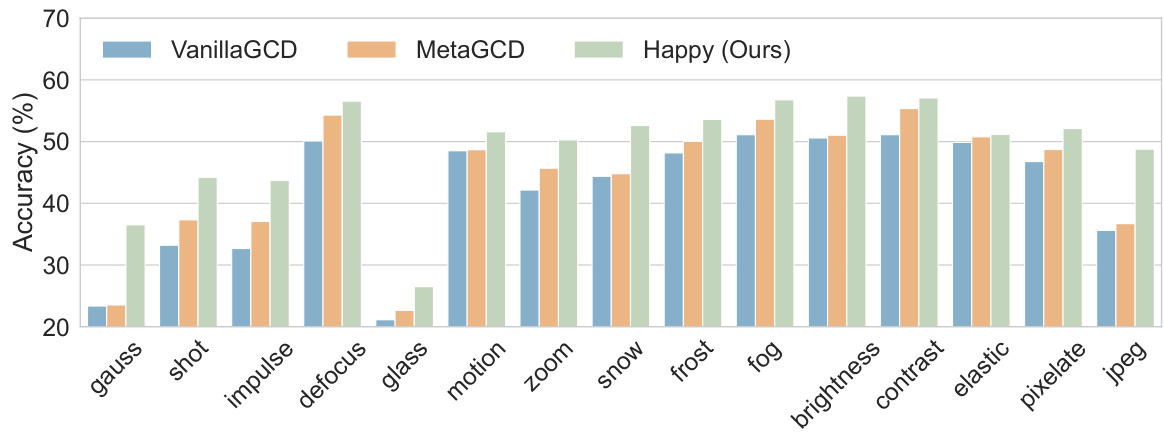
This figure shows the accuracy of three different continual learning methods (VanillaGCD, MetaGCD, and Happy) across 15 different unseen shifted distributions of the CIFAR100-C dataset. The severity level is set to 2. The results demonstrate that the Happy method consistently outperforms the other two methods across all 15 distributions, even over a longer duration (10 stages) of continual learning. This highlights Happy’s robustness and generalization capabilities in handling unseen data distributions.
More on tables
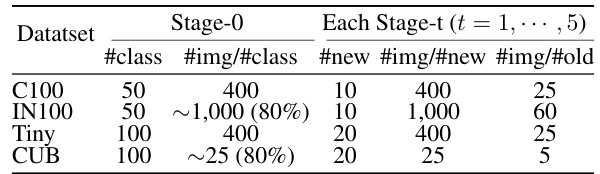
This table presents the data split settings used for the Continual Generalized Category Discovery (C-GCD) experiments. It shows the number of classes and images per class in the initial stage (Stage-0) and in each subsequent stage (Stage-t, where t = 1, …, 5). The ‘#old’ column indicates the number of images per class from previously learned categories in each stage.

This table presents the performance comparison of different methods on four datasets (CIFAR100, ImageNet-100, TinyImageNet, and CUB) across five stages of continual generalized category discovery. The accuracy is broken down into overall accuracy, accuracy on old classes, and accuracy on new classes for each stage. Stage 0 represents the initial supervised training stage, and subsequent stages represent incremental unsupervised learning stages. The table shows that the proposed Happy method achieves the highest overall accuracy across all datasets and stages.
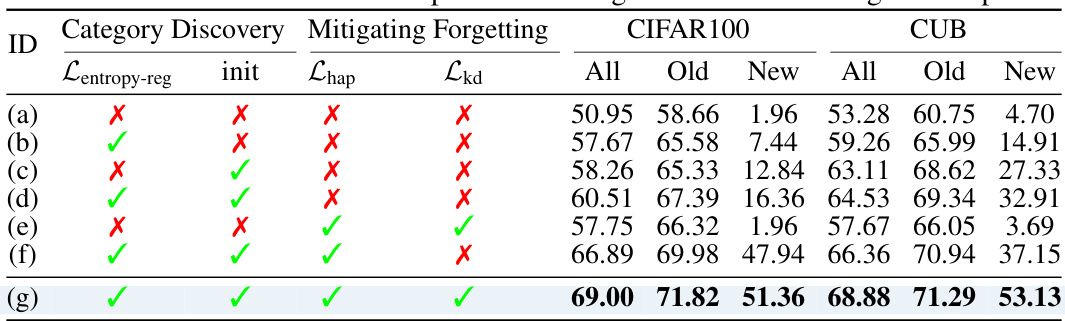
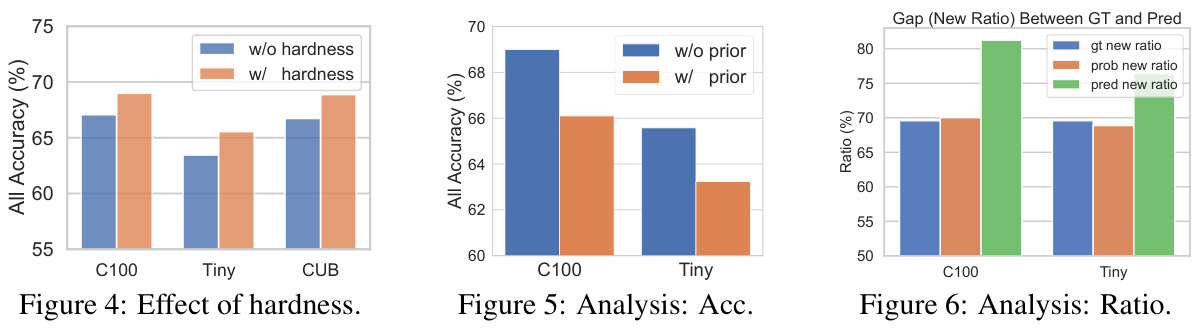
This table presents the ablation study results on the Happy framework, showing the impact of each component (clustering-guided initialization, soft entropy regularization, hardness-aware prototype sampling, and knowledge distillation) on the overall performance. It demonstrates the effectiveness of each component and their combined effect in improving the accuracy of both old and new classes in the continual generalized category discovery task.
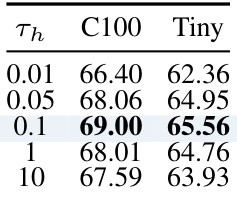
This table shows the sensitivity analysis of the hyperparameter (\tau_h) used in hardness-aware prototype sampling. The results, in terms of accuracy, are shown for different values of (\tau_h) on two datasets, CIFAR100 and TinyImageNet. The goal is to find the optimal value for (\tau_h) that balances the exploration of hard-to-learn classes and the prevention of forgetting previously learned classes. The best performance is observed with (\tau_h = 0.1).
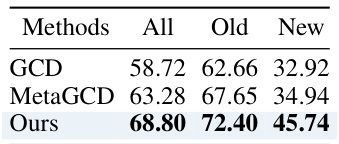
This table shows the performance of different methods on CIFAR-100 when the number of new classes is unknown. The results are presented in terms of overall accuracy (‘All’), accuracy on old classes (‘Old’), and accuracy on new classes (‘New’). The proposed method (‘Ours’) outperforms the other methods, demonstrating its effectiveness in handling scenarios with unknown class numbers.
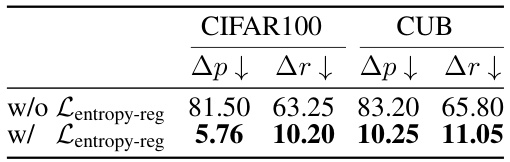
This table presents the ablation study results on the effectiveness of the proposed soft entropy regularization ((\mathcal{L}{\text{entropy-reg}})) and hardness-aware prototype sampling in mitigating prediction bias and hardness bias. The results are shown for CIFAR100 and CUB datasets, and for each dataset, it shows the improvements gained by introducing each module ((\mathcal{L}{\text{entropy-reg}}) and hardness-aware sampling) on the metrics: (\Delta p) and (\Delta r). (\Delta p) represents the difference in marginal probabilities between old and new classes, which is a measure of prediction bias; (\Delta r) represents the proportion of new classes’ samples misclassified as old classes, which is another measure of prediction bias. The table shows that both (\mathcal{L}_{\text{entropy-reg}}) and hardness-aware sampling significantly reduce both types of bias, improving the overall performance of the model.

This table presents the ablation study results demonstrating the effectiveness of the proposed soft entropy regularization (Lentropy-reg) and hardness-aware prototype sampling in mitigating prediction bias and hardness bias, respectively. It shows the variance of accuracy across old classes (Varo) and accuracy of the hardest class among old classes (Acch) with and without each component on CIFAR100 and CUB datasets. Lower Varo and higher Acch indicate better bias mitigation.

This table presents the performance comparison of various methods on four different datasets (CIFAR100, ImageNet-100, TinyImageNet, and CUB) across five stages of continual generalized category discovery. The results are shown for overall accuracy, accuracy on old classes, and accuracy on new classes for each stage, providing a comprehensive evaluation of each method’s ability to learn new categories while retaining knowledge of previously learned ones. The similar Stage-0 accuracy across methods ensures a fair comparison of their performance in the continual learning stages.
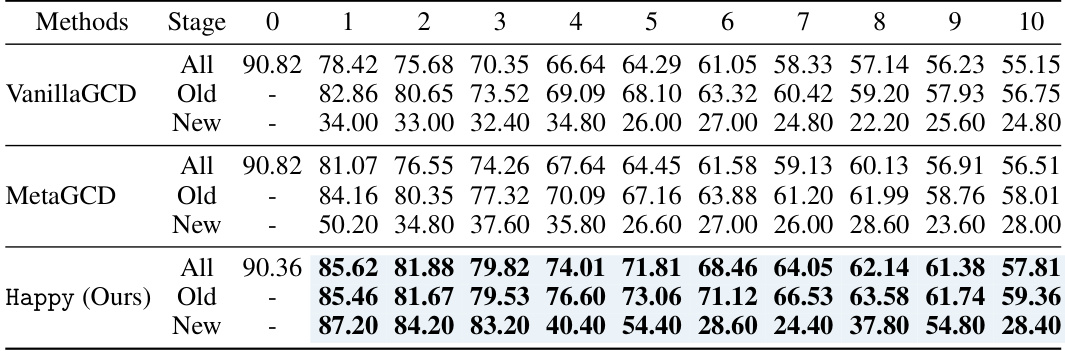
This table presents the performance comparison of various methods on four datasets (CIFAR100, ImageNet-100, TinyImageNet, and CUB) across five stages of continual generalized category discovery. The ‘All’, ‘Old’, and ‘New’ accuracy metrics are reported for each stage, along with the overall accuracy in Stage 0. The table highlights the superior performance of the proposed method, ‘Happy’, across all datasets and stages, particularly in its ability to discover new categories while maintaining performance on previously learned categories.
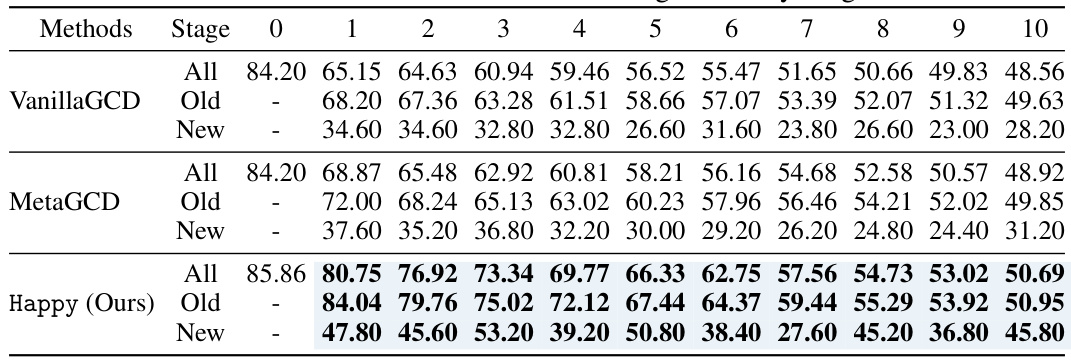
This table presents the performance comparison of various methods on four different datasets for a 5-stage continual generalized category discovery task. The performance is measured by the overall accuracy, accuracy on old classes, and accuracy on new classes for each stage. The table highlights that the proposed Happy method achieves superior performance compared to other methods across all datasets.

This table presents the performance comparison of three different continual generalized category discovery methods (VanillaGCD, MetaGCD, and Happy) on two fine-grained datasets: Stanford Cars and FGVC Aircraft. The results are shown as accuracy scores (‘All’, ‘Old’, and ‘New’) indicating the overall accuracy, accuracy on previously seen classes, and accuracy on newly discovered classes, respectively. The table highlights the superior performance of the Happy framework on both datasets compared to the baseline methods. The results demonstrate the effectiveness of Happy in continual learning scenarios, especially when dealing with fine-grained categories.

This table presents the performance comparison of various methods on the task of 5-stage Continual Generalized Category Discovery across four different datasets: CIFAR100, ImageNet-100, TinyImageNet, and CUB. The results are broken down by stage (0-5), showing the overall accuracy, as well as accuracy for old and new categories. The table highlights that the proposed method (‘Happy’) achieves the best performance overall across all datasets and stages.
Full paper#



















