↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current no-reference speech quality assessment methods struggle with generalization across different audio conditions and domains, often relying on minimizing L2 loss between predicted and actual Mean Opinion Scores (MOS). This paper highlights how L2 loss fails to capture the continuous nature of MOS and demonstrates poor generalization across various speech domains.
To address these issues, the authors propose SCOREQ, a novel method that employs contrastive regression with a triplet loss function. This approach effectively learns an ordered representation in the feature space, improving generalization. Extensive evaluation on diverse datasets and domains confirms that SCOREQ significantly outperforms existing methods, showcasing improved generalization and robustness in speech quality prediction.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the critical problem of generalization in no-reference speech quality assessment, a significant challenge in the field. By proposing a novel approach using contrastive regression and a triplet loss function, it offers a potential solution to improve the accuracy and reliability of speech quality metrics across diverse speech domains. This work opens new avenues for further research in contrastive learning for regression tasks and can significantly impact the development of speech technologies.
Visual Insights#
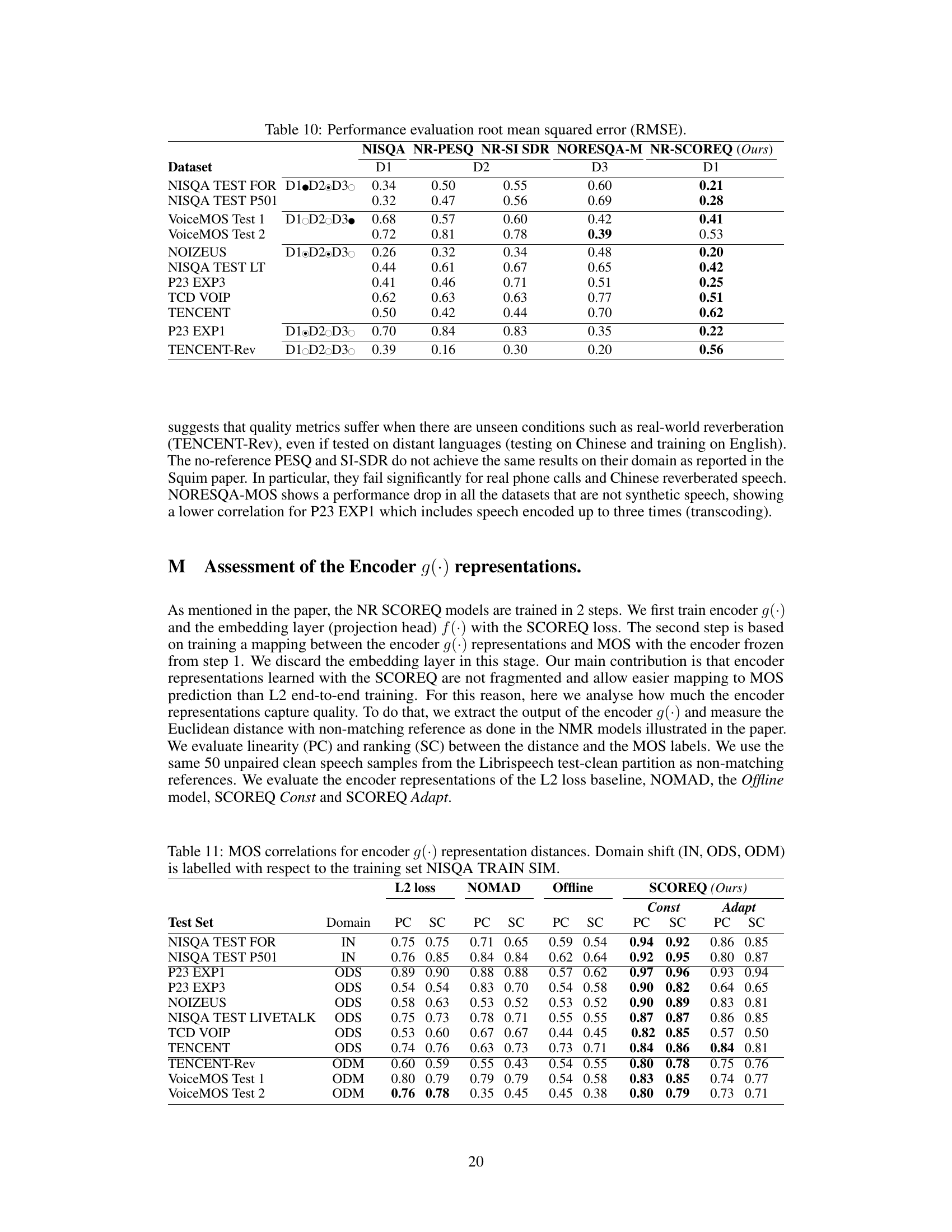
This figure compares the embeddings generated by using L2 loss and SCOREQ methods on the TCD VOIP dataset. The left panel (a) shows the embeddings from the L2 loss approach, where points are clustered by degradation type (NMI=0.39) but less well-ordered by MOS score (PC=0.53). The right panel (b) shows SCOREQ embeddings; points are less clustered by degradation but far better ordered by MOS (NMI=0.11, PC=0.79). This illustrates how SCOREQ improves MOS prediction by creating a representation that prioritizes quality score ordering over degradation type.

This table lists the speech quality metrics used in the paper and the datasets used to train them. The metrics include NISQA, NR-PESQ, NR-SI SDR, and NORESQA-MOS. Each metric is associated with a specific domain ID (D1, D2, D3), representing the domain of the training data, which are Sim Degradations (for NISQA), DL Speech Enhancement (for NR-PESQ, NR-SI SDR), and Speech Synthesis (for NORESQA-MOS). The bandwidth (BW) of the audio data used in each training dataset is also specified in kHz.
In-depth insights#
Contrastive Regression#
Contrastive regression, a novel approach in machine learning, tackles regression tasks by leveraging contrastive learning principles. Instead of directly minimizing the difference between predicted and actual values (as in traditional regression), it focuses on learning relationships between data points. This is achieved by constructing triplets of data points: an anchor, a positive sample (similar to the anchor), and a negative sample (dissimilar to the anchor). The model is trained to pull the anchor and positive samples closer together in the embedding space while pushing the anchor and negative samples further apart. This approach is particularly beneficial when dealing with high-dimensional data or complex relationships that are difficult for standard regression techniques to capture. The key advantage lies in improved generalization, as the model learns a more robust representation of the underlying data structure rather than simply memorizing individual data points. Furthermore, contrastive regression shows potential for various applications beyond speech quality assessment, including other fields involving regression-based predictive modeling.
Speech Quality Manifold#
The concept of a “Speech Quality Manifold” is intriguing. It suggests a geometrical representation of speech quality, where different points on the manifold correspond to varying degrees of quality. This manifold would likely be high-dimensional, reflecting the many factors influencing speech quality (e.g., noise level, codec artifacts, bitrate, speaker characteristics). The relationships between points could reveal how these different factors interact. Dimensionality reduction techniques might be necessary to visualize and analyze the manifold, perhaps revealing inherent clusters or continua of perceived quality. A key challenge would be defining a suitable distance metric on this manifold, one that accurately reflects human perception of speech quality differences. Machine learning could be applied to learn the structure of the manifold from labeled data, perhaps allowing for the development of more robust and generalizable speech quality assessment metrics. This also opens the possibility of identifying regions of the manifold with exceptionally high or low quality, providing valuable insights for speech enhancement or synthesis.
SCOREQ Loss Function#
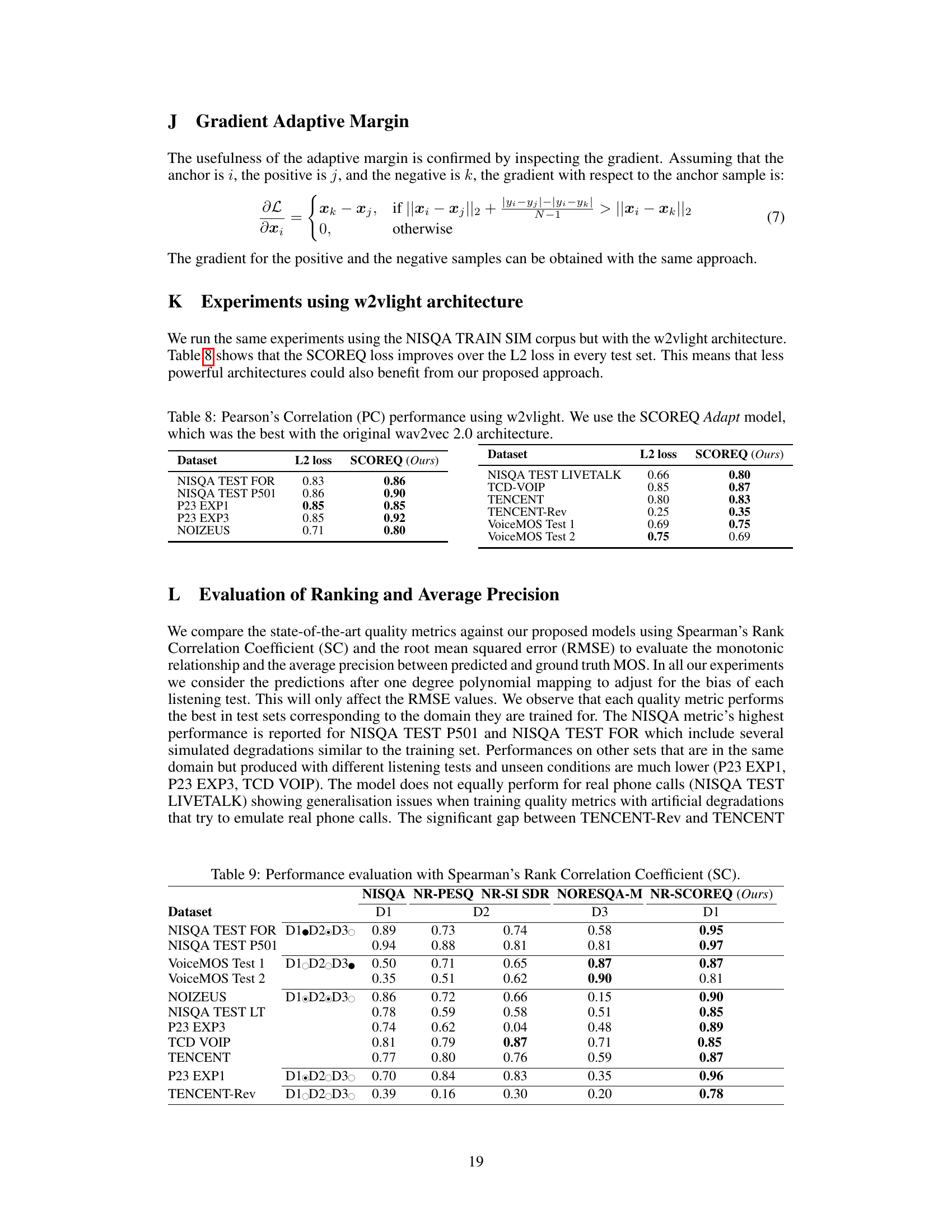
The SCOREQ loss function is a novel triplet loss function designed for contrastive regression, specifically addressing limitations of existing no-reference speech quality assessment metrics. It tackles the challenge of mapping high-dimensional speech data to a single continuous quality score (MOS) by leveraging triplet comparisons. Unlike traditional L2 loss, SCOREQ directly learns an ordered representation in the embedding space, where the relative distances between speech embeddings reflect their MOS differences. This is achieved through on-the-fly triplet mining and an adaptive margin, which dynamically adjusts the distance threshold based on the MOS values, making it more robust to variations in the data. This approach is shown to improve generalization across various speech domains and degradation types, outperforming traditional L2 loss-based methods and even other contrastive regression methods in the benchmarks presented. The use of all possible triplet combinations within a batch further enhances its efficiency compared to previous offline triplet-based approaches. Overall, the SCOREQ loss function represents a significant advance in speech quality assessment, highlighting the potential of contrastive learning techniques for regression tasks.
Generalization Analysis#
A robust generalization analysis of a machine learning model is crucial for assessing its real-world applicability. It should thoroughly investigate the model’s performance across diverse datasets and conditions, going beyond the training data. This involves examining performance metrics under various scenarios, including in-distribution, out-of-distribution, and out-of-domain settings. A key aspect is identifying and quantifying the extent of domain adaptation or transfer learning necessary for optimal performance across different domains. Furthermore, the analysis should delve into the model’s sensitivity to factors like noise, data variations, and distribution shifts. A strong generalization analysis not only provides valuable insights into model limitations, but also offers actionable guidance for model improvement and responsible deployment. Statistical significance testing of results is critical to avoid spurious conclusions. Ideally, it should also compare the model’s performance to established benchmarks and alternative methods for fair assessment.
Future Work:Beyond Speech#
The heading ‘Future Work: Beyond Speech’ suggests a promising research direction, expanding the applications of contrastive regression beyond speech quality assessment. The core methodology, successfully applied to speech, could be adapted to other regression tasks involving high-dimensional, continuous data where domain generalization is crucial. Potential applications could include image quality assessment, video quality scoring, or even more abstract domains like financial modeling or medical diagnosis where similar challenges of high dimensionality and continuous target variables exist. Further research should explore the effect of different data representations and architectural choices on the performance and generalization of contrastive regression in non-speech domains. Comparative studies against existing no-reference quality metrics in these new domains would provide critical validation of the approach’s effectiveness and identify potential limitations. Exploring different triplet loss variations and margin adaptation techniques tailored to the specific characteristics of each target domain is also essential for maximizing performance and achieving a robust solution.
More visual insights#
More on figures
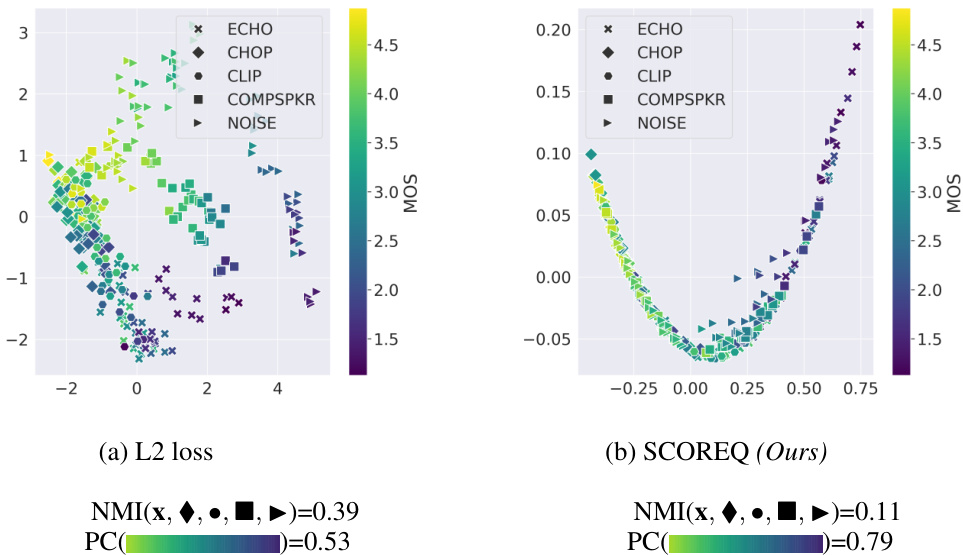
This figure illustrates how the SCOREQ loss function works with a batch of three samples. It shows how the distance between embeddings of different samples influences the training process. The focus is on how the negative samples are pushed away from the anchor sample and pulled closer to the positive sample, depending on their MOS values. This process helps the model to learn a continuous quality manifold in the embedding space where samples with similar MOS scores are closer together.

This figure compares the embeddings generated by a model trained with the L2 loss and SCOREQ. The TCD VOIP dataset is used. The x and y axes represent the embedding space, with each point representing an audio sample. Colors indicate the MOS score, and different markers represent different types of audio degradation. The L2 loss model’s embeddings show clear clustering based on degradation type (high NMI), but poor correlation with MOS scores. In contrast, SCOREQ’s embeddings show less clustering based on degradation but a much stronger correlation with MOS, suggesting better performance in capturing the continuous nature of speech quality.

This figure illustrates the two modes of operation for the SCOREQ model: No-Reference (NR) and Non-Matching Reference (NMR). The NR mode is a two-step training process. First, the encoder is pre-trained using the SCOREQ loss. Then, a linear layer (MOS head) is added and trained to predict MOS scores. The NMR mode uses the pre-trained encoder from the NR mode’s first step, and does not require further training to produce a quality score.
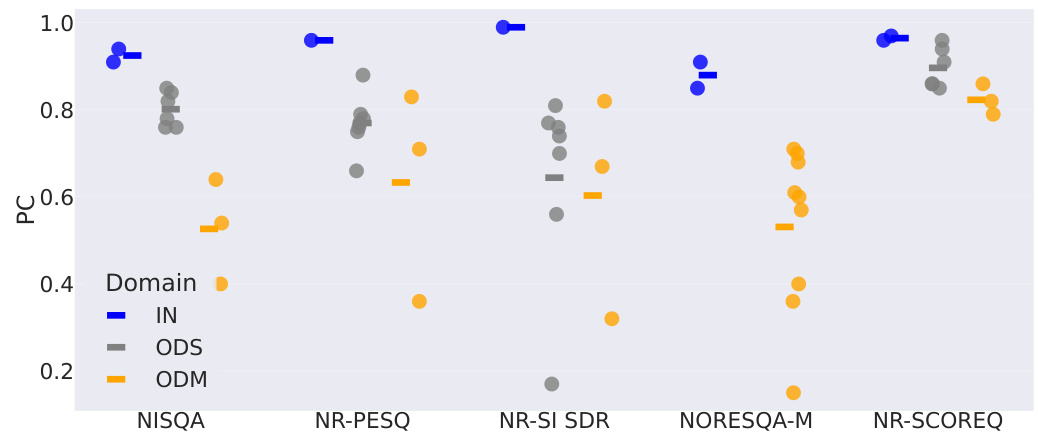
This figure displays the Pearson Correlation (PC) values for different speech quality metrics across various datasets. Each point on the graph corresponds to a specific dataset tested on. The datasets are categorized into three groups based on the domain shift from the training data: IN (in-domain), ODS (out-of-distribution), and ODM (out-of-domain). Horizontal lines show the average PC for each group, indicating the generalization performance of the metrics under different testing conditions. The purpose is to show how well the metrics generalize beyond their training data; poor generalization across these categories indicates a lack of robustness.

This figure compares the performance of L2 loss and SCOREQ methods on TCD VOIP dataset. The left panel shows the embeddings generated by L2 loss, while the right panel shows those generated by SCOREQ. Each point represents a speech sample with its color indicating the MOS score and its marker indicating the type of degradation applied. The NMI (Normalized Mutual Information) and PC (Pearson Correlation) metrics are used to evaluate how well the embeddings capture the degradation information and MOS score respectively. SCOREQ shows much better correlation with MOS scores, suggesting better performance in speech quality prediction than L2 loss.
More on tables

This table presents a comparison of the performance of different speech quality assessment metrics across various datasets. It compares in-domain (IN), out-of-distribution (ODS), and out-of-domain (ODM) performance. The results highlight the generalisation capabilities of different methods, demonstrating a lack of robustness in some state-of-the-art approaches and showcasing the improved performance of the SCOREQ model proposed in the paper. Note that results for the DNS Squim dataset were taken from another source due to unavailability.
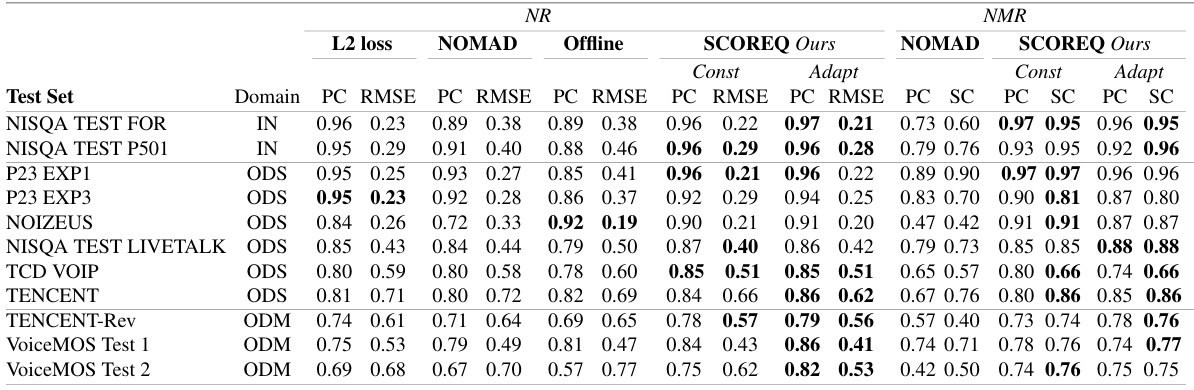
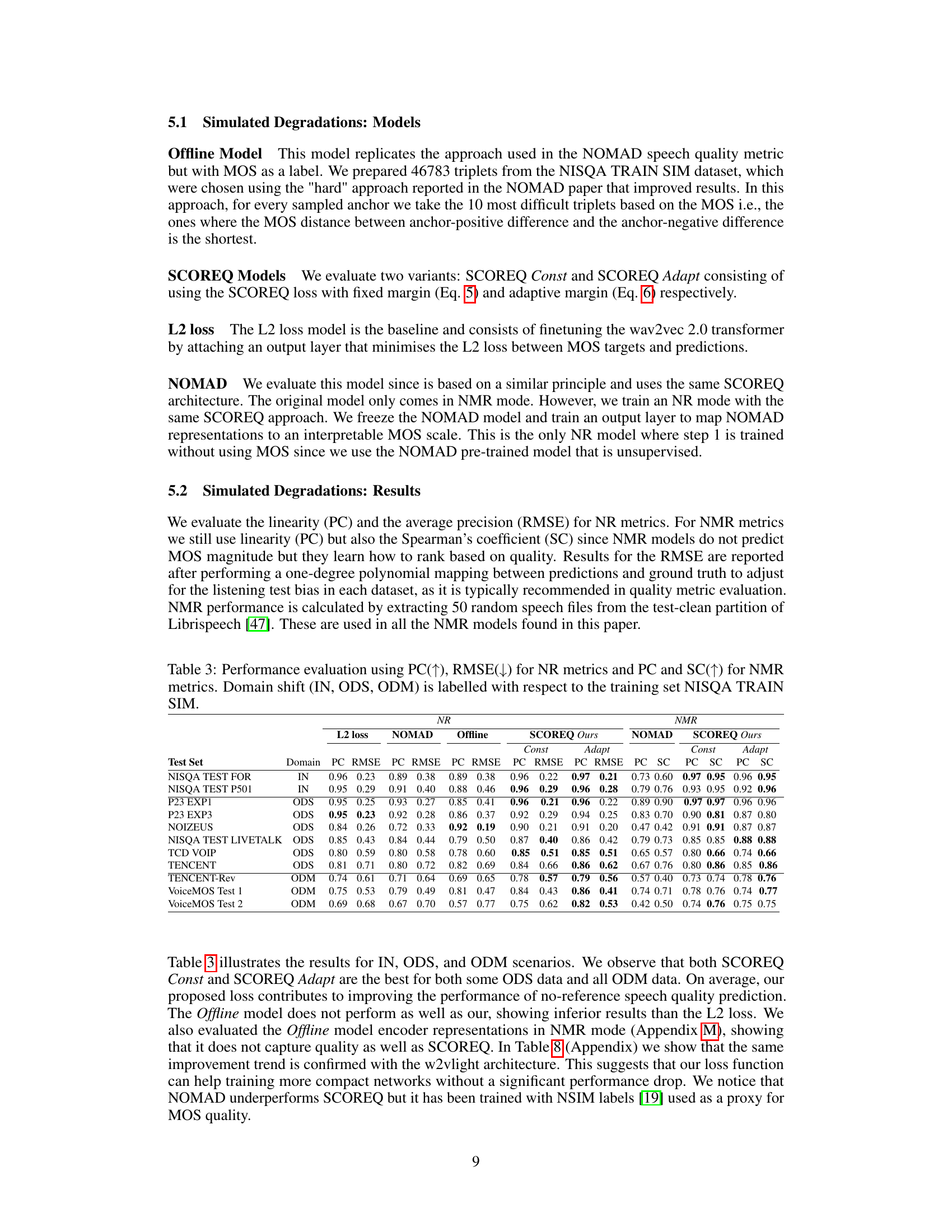
This table presents a performance comparison of different speech quality assessment methods across various datasets and conditions. The metrics are evaluated using Pearson Correlation (PC) and Root Mean Squared Error (RMSE) for no-reference (NR) and Pearson Correlation (PC) and Spearman’s rank correlation (SC) for non-matching reference (NMR). The results are categorized by domain shift: IN (in-domain), ODS (out-of-distribution), and ODM (out-of-domain). This allows for an analysis of the generalisation capabilities of each method across different types of speech degradation.
This table presents the performance evaluation results of various speech quality metrics, including the proposed SCOREQ model, across different test sets categorized by domain shift (IN: in-domain; ODS: out-of-distribution; ODM: out-of-domain). The metrics are evaluated using Pearson Correlation (PC) for linearity, Root Mean Squared Error (RMSE) for average precision, and Spearman’s rank correlation coefficient (SC) for ranking, depending on whether the metric is no-reference (NR) or non-matching reference (NMR). The table helps demonstrate the generalization ability of the proposed model and compare it against existing state-of-the-art metrics.

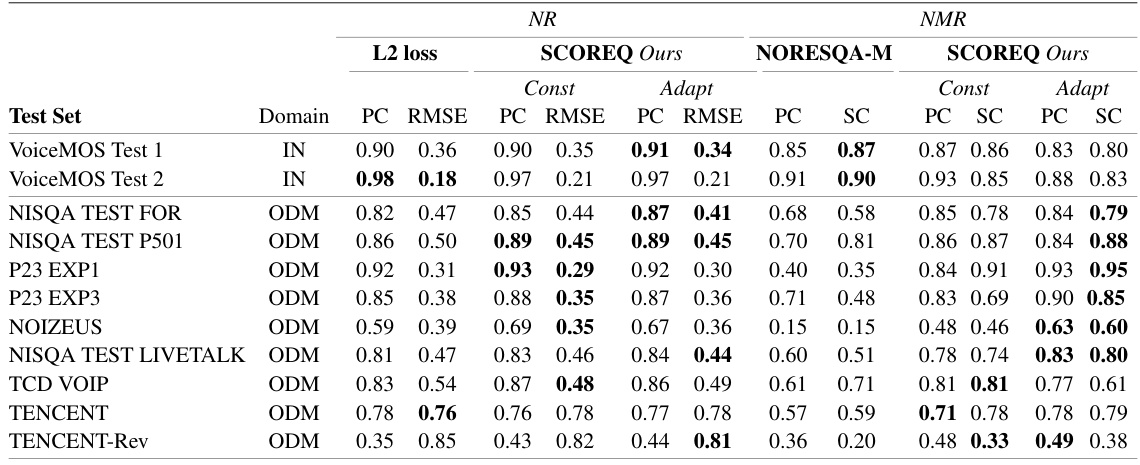
This table presents the performance evaluation results for various speech quality metrics, including the proposed SCOREQ model. It compares the performance of different models (L2 loss, NOMAD, Offline, SCOREQ Const, and SCOREQ Adapt) across three different scenarios: in-domain (IN), out-of-distribution (ODS), and out-of-domain (ODM). The evaluation metrics used are Pearson Correlation (PC) and Root Mean Squared Error (RMSE) for NR (no-reference) metrics and PC and Spearman’s rank correlation (SC) for NMR (non-matching reference) metrics. The table shows the PC and RMSE values for each model and scenario. The domain shift indicates how similar the test data is to the training data used for each specific metric.
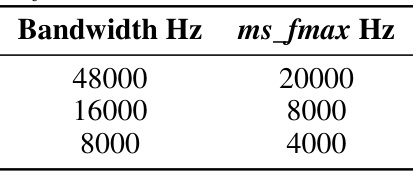
This table shows the different values used for the parameter
ms_fmaxin the NISQA model, based on the input bandwidth. Thems_fmaxparameter determines the maximum frequency used to calculate the mel spectrograms. The table indicates that for a 48000 Hz bandwidth,ms_fmaxis set to 20000 Hz; for 16000 Hz, it’s 8000 Hz; and for 8000 Hz, it’s 4000 Hz. This adjustment is made to ensure that the NISQA model processes input signals of different bandwidths appropriately.
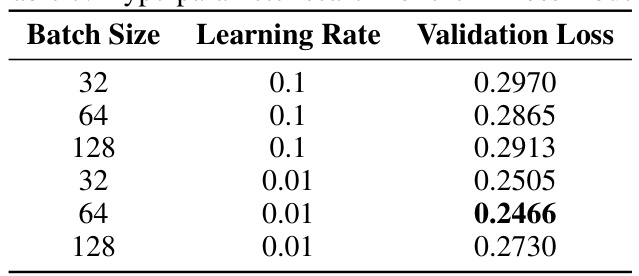
This table presents the results of a hyperparameter search conducted for an L2 loss model. The search involved varying batch size (32, 64, 128) and learning rate (0.1, 0.01) to determine the optimal combination that minimizes validation loss. The validation loss for each combination of hyperparameters is shown, indicating the best performing configuration.

This table presents the Pearson Correlation Coefficient (PC) scores for various speech quality assessment metrics across different test datasets. The metrics are evaluated based on three domain conditions: In-domain (IN), Out-of-Distribution (ODS), and Out-of-Domain (ODM). The table highlights the generalisation performance of each metric and shows how the proposed SCOREQ metric performs compared to the state-of-the-art. The results show SCOREQ’s improved generalisation capabilities, especially in out-of-domain scenarios.
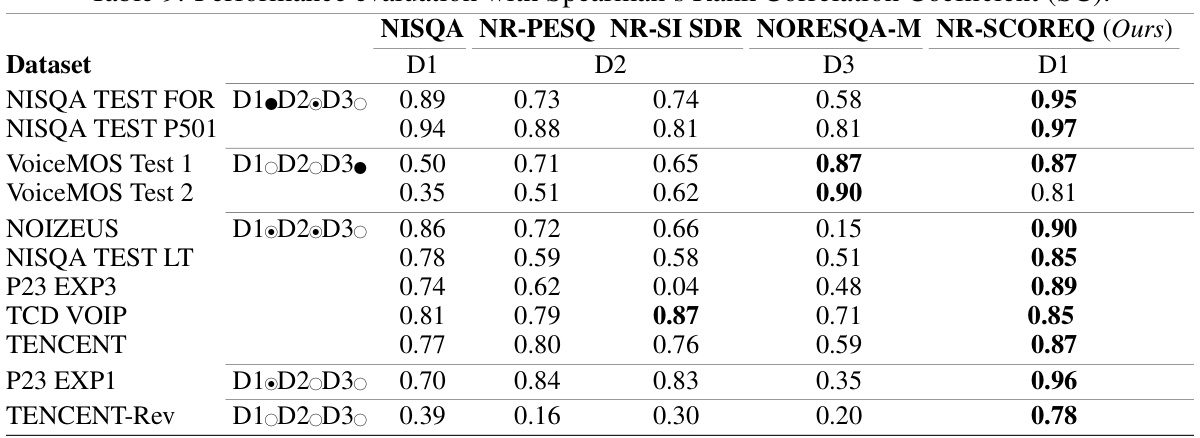
This table presents a comparison of different speech quality metrics’ performance across various datasets, categorized by domain match (in-domain, out-of-distribution, out-of-domain). The Pearson Correlation Coefficient (PC) is used as the evaluation metric. The table highlights the superior generalization capabilities of the proposed NR-SCOREQ metric compared to existing state-of-the-art methods.
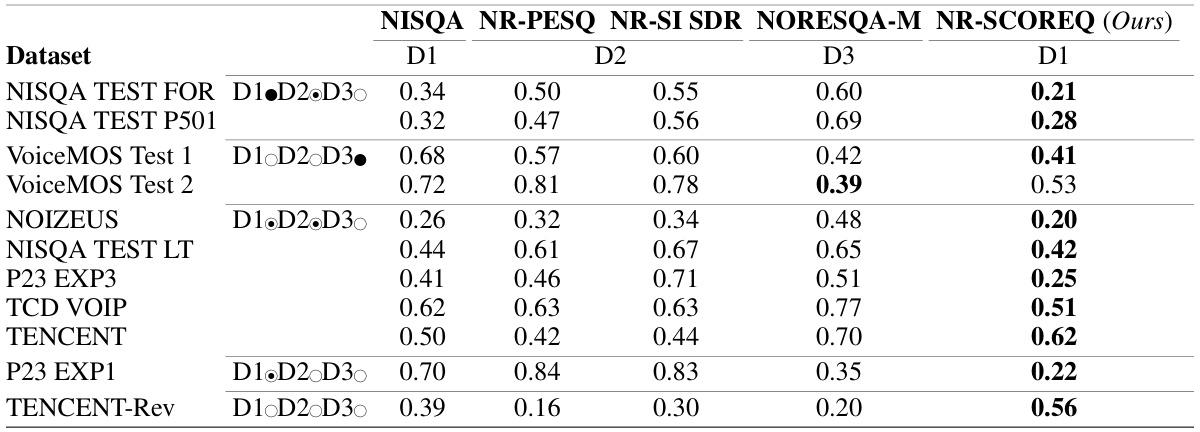
This table presents a comparison of different speech quality metrics’ performance across various datasets, categorized by in-domain (IN), out-of-distribution (ODS), and out-of-domain (ODM) scenarios. The table highlights the generalization capabilities of each metric, demonstrating the superior performance of the proposed NR-SCOREQ metric in most cases.

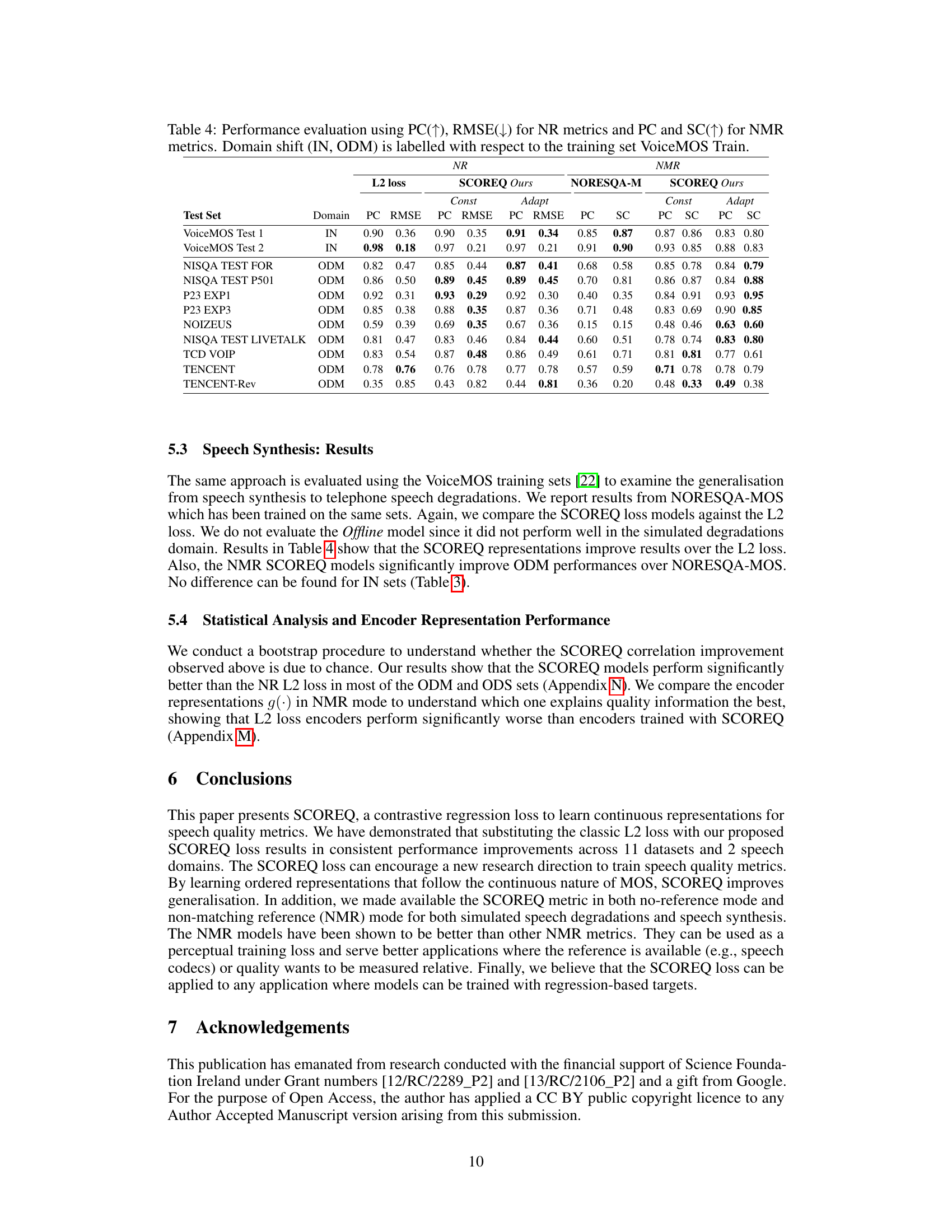
This table presents the performance evaluation results for different speech quality metrics, including the proposed SCOREQ model and several baselines. The evaluation is performed across various test sets and categorized by domain shift (IN: in-domain, ODS: out-of-distribution, ODM: out-of-domain) relative to the training data. The metrics used are Pearson Correlation (PC), Root Mean Squared Error (RMSE), and Spearman’s rank correlation (SC). PC and RMSE are used for no-reference (NR) metrics, while PC and SC are used for non-matching reference (NMR) metrics. Lower RMSE values indicate better performance. Higher PC and SC values indicate better performance. The table allows to assess the generalization capability of the different models across various domains and data distributions.

This table presents the performance evaluation results for different speech quality assessment metrics. It shows the Pearson Correlation (PC), Root Mean Squared Error (RMSE), and Spearman’s rank correlation (SC) for both No-Reference (NR) and Non-Matching Reference (NMR) modes across various datasets. The datasets are categorized into In-domain (IN), Out-of-distribution (ODS), and Out-of-domain (ODM) to assess the generalization capability of each metric.

This table presents the performance evaluation results for different speech quality metrics across various datasets. The evaluation considers three types of domain shifts: In-domain (IN), Out-of-Distribution (ODS), and Out-of-Domain (ODM). Metrics evaluated include Pearson Correlation (PC), Root Mean Squared Error (RMSE), and Spearman’s Rank Correlation (SC). The table compares the performance of the proposed SCOREQ method with L2 loss-based models and other state-of-the-art methods for both no-reference (NR) and non-matching reference (NMR) scenarios. The training data is the NISQA TRAIN SIM dataset.
Full paper#