↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Open-vocabulary part segmentation (OVPS) is a complex task due to ambiguous boundaries and diverse granularity of parts. Existing methods often struggle with generalization to unseen categories and accurate prediction of small or less frequent parts. These limitations hinder the application of OVPS in various fields, including robotics and medical imaging.
PartCLIPSeg, the proposed method, addresses these limitations by using generalized parts and object-level contexts to improve generalization. It incorporates attention control to enhance activation of under-represented parts and minimize ambiguous boundaries. The results show significant improvement over state-of-the-art OVPS methods on multiple datasets, demonstrating the effectiveness of PartCLIPSeg in handling unseen categories and multi-granularity aspects of parts.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenging problem of open-vocabulary part segmentation (OVPS), a crucial task for various applications such as robotics, image editing, and medical imaging. By proposing PartCLIPSeg, the researchers introduce a novel framework that significantly outperforms existing methods, especially in handling unseen categories and ambiguous boundaries. This opens new avenues for further research in OVPS and related fields.
Visual Insights#

This figure shows the prediction results of the PartCLIPSeg model on unseen categories from the Pascal-Part-116 dataset. The image shows a dog, which was not seen during training. The model successfully segments the dog into several parts (head, torso, ear, nose, paw) by incorporating both object-level context and generalized parts. Note that the model successfully handles the smaller part (nose) despite the intricate boundaries and diversity of the granularity.
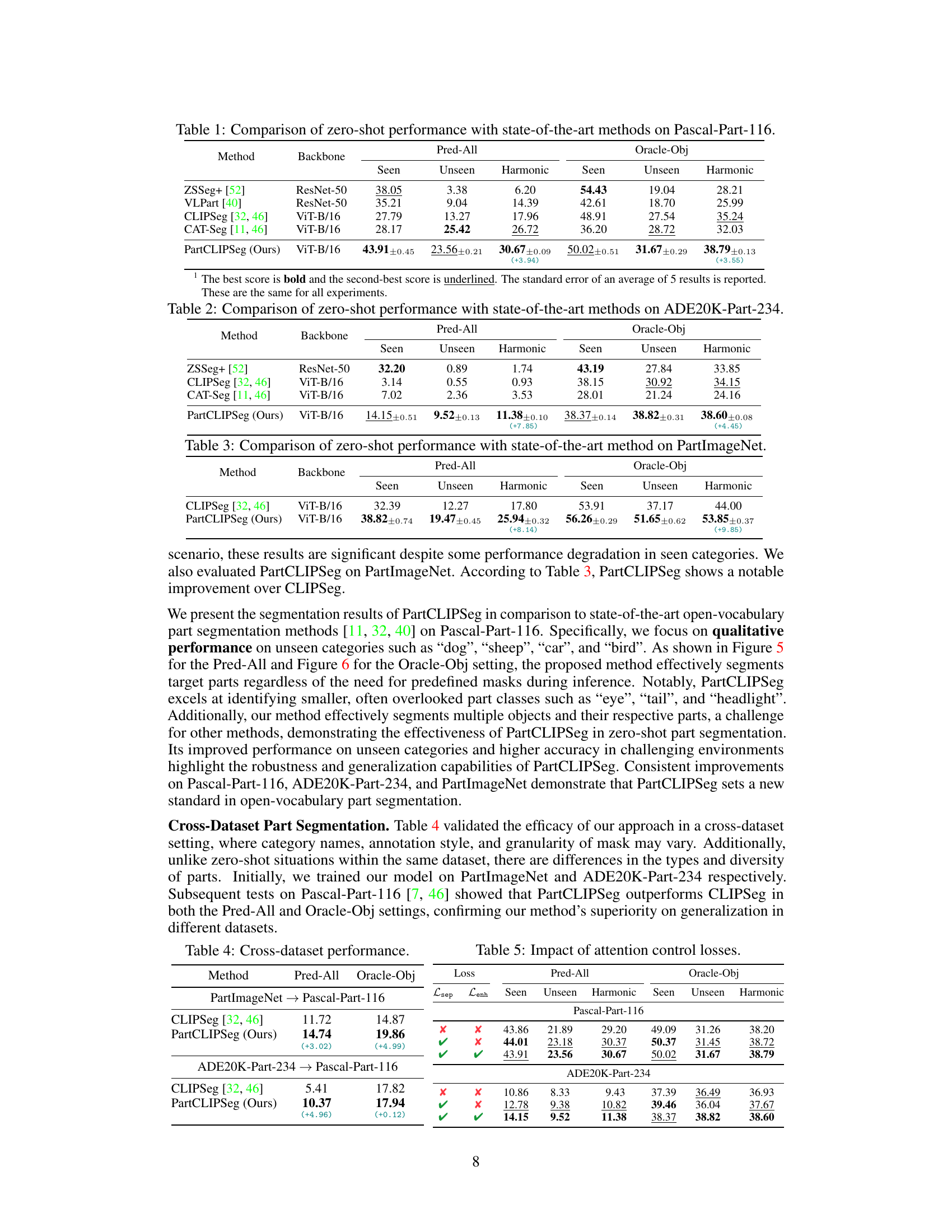
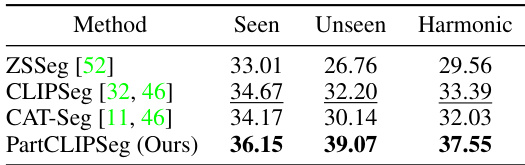
This table compares the zero-shot performance of the proposed PartCLIPSeg model with several state-of-the-art methods on the Pascal-Part-116 dataset. The performance is evaluated using three metrics: the mean Intersection over Union (mIoU) for seen categories, unseen categories, and the harmonic mean of the two. The results demonstrate the superior performance of PartCLIPSeg in the zero-shot setting, particularly for unseen categories.
In-depth insights#
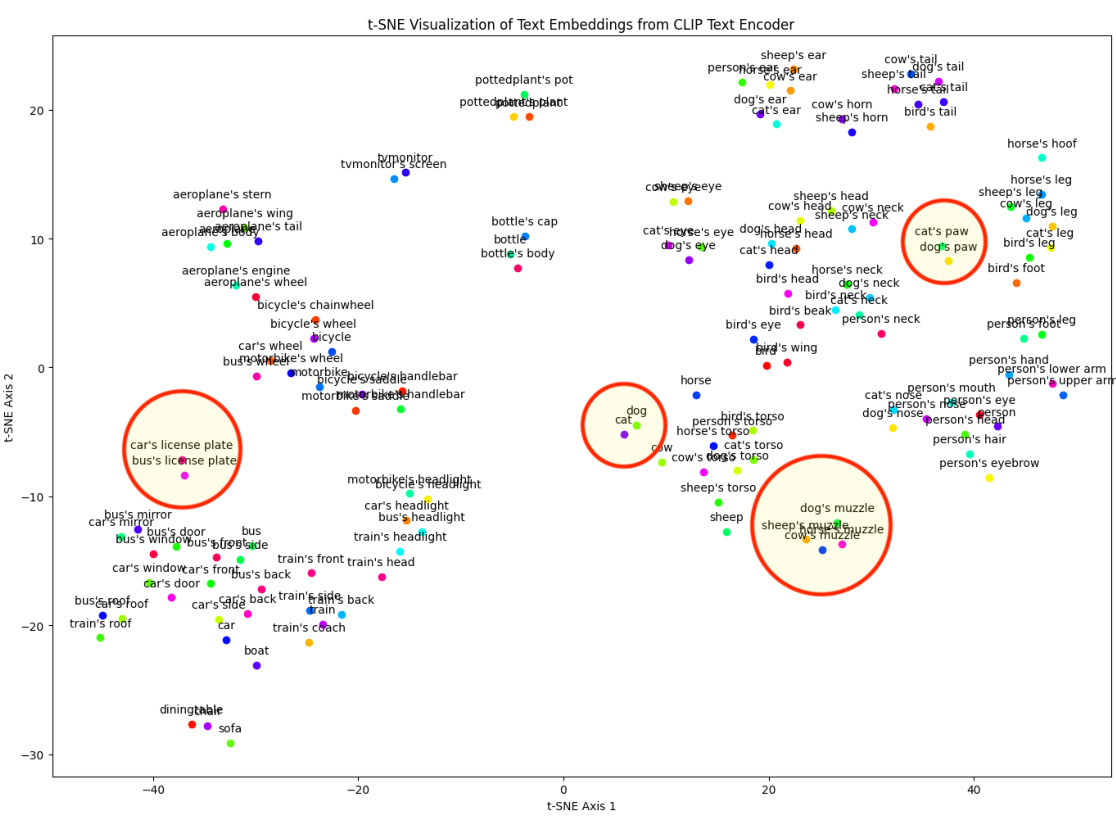
Multi-Granularity OVPS#
Multi-granularity Open-Vocabulary Part Segmentation (OVPS) presents a significant challenge in computer vision, demanding the ability to segment fine-grained entities from diverse and unseen vocabularies while handling varying levels of detail. The core difficulty stems from the inherent ambiguity in defining part boundaries; what constitutes a ‘dog’s head’ versus ‘dog’s neck’ is subjective and context-dependent. Existing OVPS methods often struggle with generalization, producing ambiguous boundaries, or overlooking small parts due to a lack of fine-grained contextual understanding. A multi-granularity approach is crucial to bridge the gap between object-level and part-level representations, effectively leveraging both generalized parts (shared across object categories, e.g., ‘head’, ’torso’) and object-specific parts (unique to individual objects). Addressing this challenge requires a system that integrates various levels of information (visual, semantic, contextual), perhaps using techniques like attention mechanisms to resolve boundary ambiguities and enhance activation for underrepresented, smaller parts. This might involve a hierarchical prediction scheme or a multi-stage process where generalized parts inform the segmentation of object-specific ones. Such a system could lead to more robust and accurate OVPS, particularly in real-world scenarios with diverse and complex visual data.
PartCLIPSeg Method#
The PartCLIPSeg method tackles open-vocabulary part segmentation by synergizing generalized parts with object-level contexts, thereby addressing the limitations of existing methods. Generalized parts act as foundational components shared across different objects (e.g., “torso” in animals), improving generalization to unseen categories. These parts, combined with object-level contexts, offer rich contextual information, refining part identification. PartCLIPSeg also incorporates attention control, using separation and enhancement losses to mitigate ambiguous boundaries and address the issue of underrepresented parts. Separation loss minimizes overlaps between predicted parts, enhancing boundary precision, while the enhancement loss boosts activation for smaller, less frequent parts, ensuring that fine-grained details are not ignored. The overall architecture uses a modified CLIP encoder-decoder, conditioned by both object and part category names via FiLM, followed by attention control and reconstruction modules. This integrated approach yields improved multi-granularity segmentation results.
Attention Control#
The heading ‘Attention Control’ suggests a mechanism to refine the model’s focus on specific image regions or features. This likely addresses two major challenges in part segmentation: ambiguous boundaries and underrepresented parts. Ambiguous boundaries arise when fine-grained parts overlap or their visual distinctions are unclear. Underrepresented parts often refer to smaller or less frequently appearing parts that are harder to segment accurately. The attention control strategy likely modulates the model’s attention weights using techniques such as self-attention refinement or feature-wise linear modulation (FiLM). This ensures that the model pays more attention to critical regions and details while suppressing noise or less relevant information, resulting in more precise segmentation. In essence, it enhances the model’s ability to discriminate between parts, resolve ambiguity in their boundaries, and avoid overlooking smaller, less prominent parts, leading to improved overall segmentation accuracy and more robust performance.
OVPS Limitations#
Open-Vocabulary Part Segmentation (OVPS) faces significant limitations. Lack of generalization is a major hurdle; existing methods struggle to accurately segment parts of unseen object categories, often misclassifying parts based on overall object similarity rather than fine-grained features. Ambiguous boundaries further complicate accurate segmentation, as imprecise definitions of part edges lead to inconsistencies in annotations and model predictions. A third key limitation is the omission of underrepresented parts. Smaller or less frequently occurring parts are often neglected by models focused on larger, more prominent features, creating a bias toward easily identified segments and neglecting crucial details for complete part representation. Addressing these limitations is crucial for advancing OVPS and achieving robust, comprehensive part segmentation across a wide variety of objects and scenes.
Future of OVPS#
The future of Open-Vocabulary Part Segmentation (OVPS) is bright, driven by several key directions. Improving generalization capabilities remains paramount; current methods struggle with unseen objects and parts, necessitating more robust feature representations and learning strategies. Addressing ambiguous boundaries is another crucial area; innovative approaches using attention mechanisms and refined loss functions are needed to accurately delineate part boundaries. Handling the multi-granularity challenge requires further advancements in model architectures to effectively capture the diverse scales and levels of detail in parts. Addressing imbalanced datasets and the lack of annotation for rare parts is crucial for practical applications. Further research should explore incorporating more contextual information for improved part recognition and leveraging multi-modal learning with better fusion of visual and textual data. Developing more efficient and scalable models is also important for deployment on real-world systems and diverse platforms.
More visual insights#
More on figures
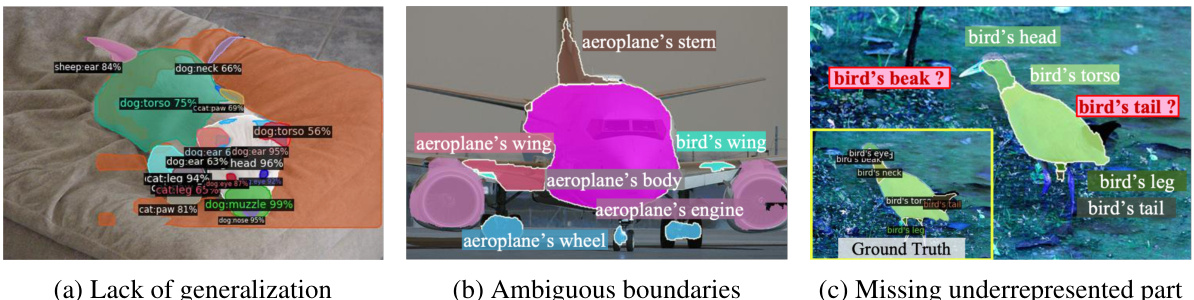
This figure illustrates three major limitations of existing open-vocabulary part segmentation (OVPS) methods. (a) shows the lack of generalization ability, where the model misidentifies parts of a novel object as parts of other objects. For example, a dog’s tail is misclassified as a sheep’s ear. (b) highlights the ambiguous boundaries issue, where the predicted part boundaries are vague and overlap with other parts, such as the aeroplane’s body overlapping with other components. (c) demonstrates the problem of missing underrepresented parts, where the model fails to predict smaller parts, such as a bird’s beak and leg.
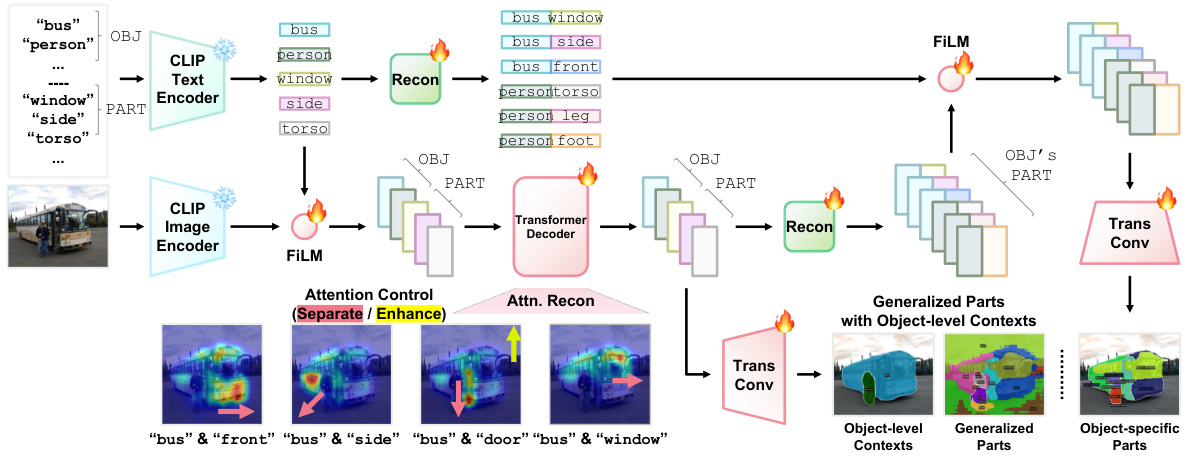
This figure illustrates the architecture of PartCLIPSeg, a novel framework for open-vocabulary part segmentation. It shows how object and part embeddings are generated using CLIP, modulated by FiLM, and processed through a transformer decoder and attention control mechanisms to produce object-specific part segmentations. Generalized parts with object-level contexts are used to address challenges in generalization, and attention control addresses ambiguity in part boundaries and under-represented parts. The overall process integrates object-level and part-level information to improve the accuracy and detail of the segmentation results.

This figure illustrates the attention control mechanism in PartCLIPSeg, designed to address ambiguity in part boundaries and the omission of small parts. It shows how the method uses separation and enhancement losses to refine attention maps. The separation loss (Lsep) minimizes overlaps between predicted parts, while the enhancement loss (Lenh) boosts the activation of underrepresented parts. The result is a refined segmentation where small parts are more accurately identified and segmented, even those that might be close to larger parts.

This figure shows the prediction results of the PartCLIPSeg model on unseen categories from the Pascal-Part-116 dataset. The model successfully segments various parts of a dog, even though the ‘dog’ category was not seen during training. It demonstrates the model’s ability to leverage both object-level context and generalized parts to achieve accurate and detailed part segmentation, particularly highlighting its capability to handle smaller parts such as the nose.

This figure shows the prediction results of the PartCLIPSeg model for unseen categories in the Pascal-Part-116 dataset. The model successfully segments parts of a dog, an unseen category during training, by combining object-level context and generalized parts information. The figure highlights the model’s ability to handle different granularity levels and to distinguish between overlapping parts.

This figure shows a comparison between the ground truth part annotations and the result from the PartCLIPSeg model for a goldfish image from the PartImageNet dataset. The ground truth shows distinct segmentation masks for the goldfish’s body, head, fin, and tail. The PartCLIPSeg result shows that the model accurately segments these parts, although with some minor discrepancies in the boundary regions. This figure illustrates the model’s ability to perform accurate part segmentation on unseen categories, even when dealing with fine-grained details.

This figure shows an example of how the attention control mechanism in PartCLIPSeg helps in accurately identifying and segmenting small parts. The left side illustrates the results without attention control, showing ambiguities and missed small parts (e.g., the dog’s tail). The right side shows the results with the attention control, showcasing improved segmentation, clearly defining even small parts like the tail and paws, and minimizing overlaps between parts.
This figure presents the architecture of the PartCLIPSeg model, which uses a modified CLIPSeg encoder-decoder architecture. It shows how object and part embeddings are generated using a FiLM (Feature-wise Linear Modulation) operation, and how attention control is applied to refine the prediction of object-specific parts. The model leverages both generalized part information and object-level contexts to achieve robust multi-granularity segmentation.

This figure shows the prediction results of the PartCLIPSeg model on unseen categories from the Pascal-Part-116 dataset. The model successfully segments various parts of a dog, an object not seen during training. It leverages both object-level context and generalized parts, resulting in accurate segmentation, especially for smaller parts like the nose, despite the inherent ambiguity of part boundaries and variations in granularity.

This figure showcases the results of PartCLIPSeg on unseen categories from the Pascal-Part-116 dataset. The model successfully segments different parts of a dog (an unseen class) by combining object-level context with generalized part predictions. The final segmentation highlights the model’s ability to handle different granularities and accurately identify smaller parts, such as the nose.
More on tables

This table compares the zero-shot performance of the proposed PartCLIPSeg model with several state-of-the-art methods on the Pascal-Part-116 dataset. The comparison is broken down by whether the object class was seen (already known during training) or unseen (novel) and presents the harmonic mean of the performance on seen and unseen classes. The results demonstrate that PartCLIPSeg achieves superior performance compared to other models, especially for unseen categories.

This table presents the results of a cross-dataset experiment evaluating the generalization ability of PartCLIPSeg and CLIPSeg. The models are trained on either PartImageNet or ADE20K-Part-234 and then tested on Pascal-Part-116. The results show that PartCLIPSeg significantly outperforms CLIPSeg in both Pred-All and Oracle-Obj settings, highlighting its superior generalization capabilities. Pred-All indicates that object-level information wasn’t provided during testing, while Oracle-Obj means it was. The numbers in parentheses show the performance improvement of PartCLIPSeg over CLIPSeg.
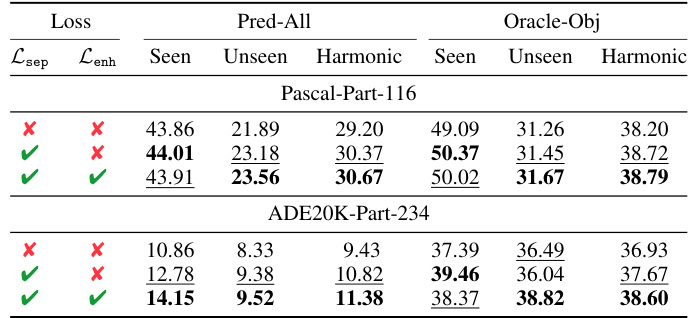
This table presents the ablation study results, focusing on the impact of attention control losses (Lsep and Lenh) on the model’s performance. It shows the mean Intersection over Union (mIoU) for seen and unseen categories, along with the harmonic mean, on Pascal-Part-116 and ADE20K-Part-234 datasets. The results are broken down for different combinations of the Lsep and Lenh losses (enabled or disabled), illustrating their individual and combined effects on the model’s ability to handle both easily recognized parts and smaller, less frequent parts. The results highlight the effectiveness of the proposed method in improving the overall segmentation performance, especially for unseen parts and ambiguous boundaries.
This table presents the performance comparison of different methods on Pascal-Part-116 dataset using mean Boundary IoU metric in the Oracle-Obj setting. It specifically highlights the performance on seen and unseen categories, providing a harmonic mean for a comprehensive evaluation.
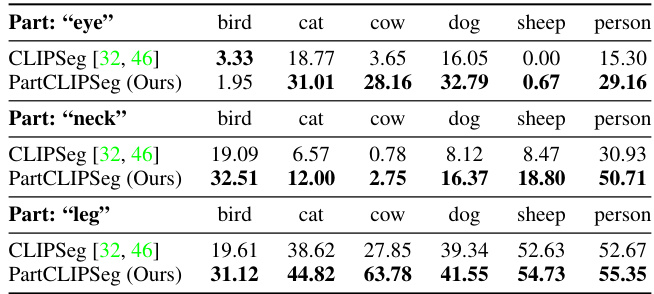
This table compares the mean Intersection over Union (mIoU) performance of CLIPSeg and PartCLIPSeg on small parts (eye, neck, leg) for different animal categories (bird, cat, cow, dog, sheep, person) in the Pascal-Part-116 dataset under the Oracle-Obj setting. It demonstrates PartCLIPSeg’s improved ability to segment these often-missed, smaller parts.

This table lists all the object-specific part categories used in the Pascal-Part-116 dataset. These categories represent the fine-grained parts of different objects (aeroplanes, bicycles, birds, etc.) that the model is trained to segment. The table is organized to show the object (e.g., aeroplane) and then lists the specific part of that object (e.g., aeroplane’s body, aeroplane’s wing).
This table presents a comparison of the zero-shot performance of PartCLIPSeg against other state-of-the-art methods on the Pascal-Part-116 dataset. The comparison includes metrics for both seen and unseen categories, highlighting PartCLIPSeg’s ability to generalize to new categories. The metrics used are for seen categories, unseen categories, and the harmonic mean of the two.

This table compares the zero-shot performance of the proposed PartCLIPSeg model with other state-of-the-art models on the Pascal-Part-116 dataset. It shows the mean Intersection over Union (mIoU) for seen and unseen categories, along with the harmonic mean of both. The results are broken down for two settings: Pred-All (where no ground truth object-level information is available) and Oracle-Obj (where ground truth object-level information is given). This demonstrates the model’s performance in challenging open-vocabulary settings.

This table compares the zero-shot performance of the proposed PartCLIPSeg model with several other state-of-the-art methods on the Pascal-Part-116 dataset. It shows the mean Intersection over Union (mIoU) scores for both seen and unseen categories, as well as the harmonic mean of these scores. This allows for a direct comparison of the models’ ability to generalize to novel categories in the zero-shot setting. The results indicate PartCLIPSeg achieves significant improvements over other methods.

This table presents the recall performance of different methods on the Pascal-Part-116 dataset under the Oracle-Obj setting. The Oracle-Obj setting means that the ground truth object-level mask and object class are known during evaluation. The table compares the performance of ZSSeg+, CLIPSeg, CAT-Seg, and PartCLIPSeg (with and without the separation and enhancement losses). The recall metric is used to assess how well the model captures underrepresented parts. Higher recall values indicate that the model effectively captures those underrepresented parts.

This table compares the zero-shot performance of PartCLIPSeg against other state-of-the-art methods on the ADE20K-Part-234 dataset. The performance is evaluated using the mean Intersection over Union (mIoU) metric, broken down into results for seen and unseen categories, and a harmonic mean of both. The table highlights PartCLIPSeg’s superior performance, particularly in unseen categories.

This table presents the ablation study on the impact of object-level and part-level guidance (Aobj and Apart) and the attention control losses (Lsep and Lenh) on the performance of the PartCLIPSeg model in the Oracle-Obj setting on Pascal-Part-116 dataset. It shows the mean Intersection over Union (mIoU) for seen and unseen categories, and the harmonic mean, for different combinations of these factors. The results indicate the relative contribution of each component to the overall performance improvement.
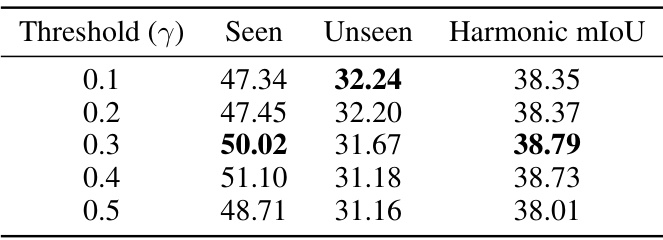
This table presents the result of an ablation study on the effect of varying the hyperparameter threshold (γ) on the Pascal-Part-116 dataset using the Oracle-Obj setting. The table shows the performance (mIoU) for seen and unseen categories, as well as the harmonic mean mIoU for different threshold values (γ = 0.1, 0.2, 0.3, 0.4, 0.5). The results demonstrate the robustness of the proposed method to the choice of this hyperparameter, with relatively stable performance across the range of values tested.
Full paper#