↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for detecting AI-generated text often rely on “logits” (probability values) from the AI model itself. However, many advanced AI models are treated as “black boxes,” meaning their internal workings and logits are not publicly available, hindering detection efforts. This limitation, coupled with the rapidly evolving nature of AI models, makes it challenging to create effective and lasting detection systems. Many existing methods falter when encountering newly released, closed-source models.
The researchers introduce a new approach called DALD (Distribution-Aligned LLMs Detection), which addresses this critical limitation. Instead of relying on logits, DALD focuses on aligning the distribution of a surrogate (open-source) model with that of the unknown AI model. This is achieved by fine-tuning the surrogate model using publicly available data from similar AI models. DALD significantly outperforms existing black-box detection methods, showing high accuracy and robustness across various models and datasets. The plug-and-play design of DALD also enhances existing zero-shot detection frameworks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on AI-generated text detection because it offers a novel framework that overcomes the limitations of existing methods. The distribution-aligned approach is particularly important given the frequent updates and closed nature of leading LLMs, which often render existing techniques obsolete. The proposed method’s robustness and adaptability open exciting avenues for future research in developing more effective and resilient detection models that can keep up with the rapid pace of LLM development. Its high accuracy and versatility make it immediately impactful to both research and applications related to authorship verification, misinformation detection, and other fields that rely on distinguishing between human-generated and AI-generated content.
Visual Insights#

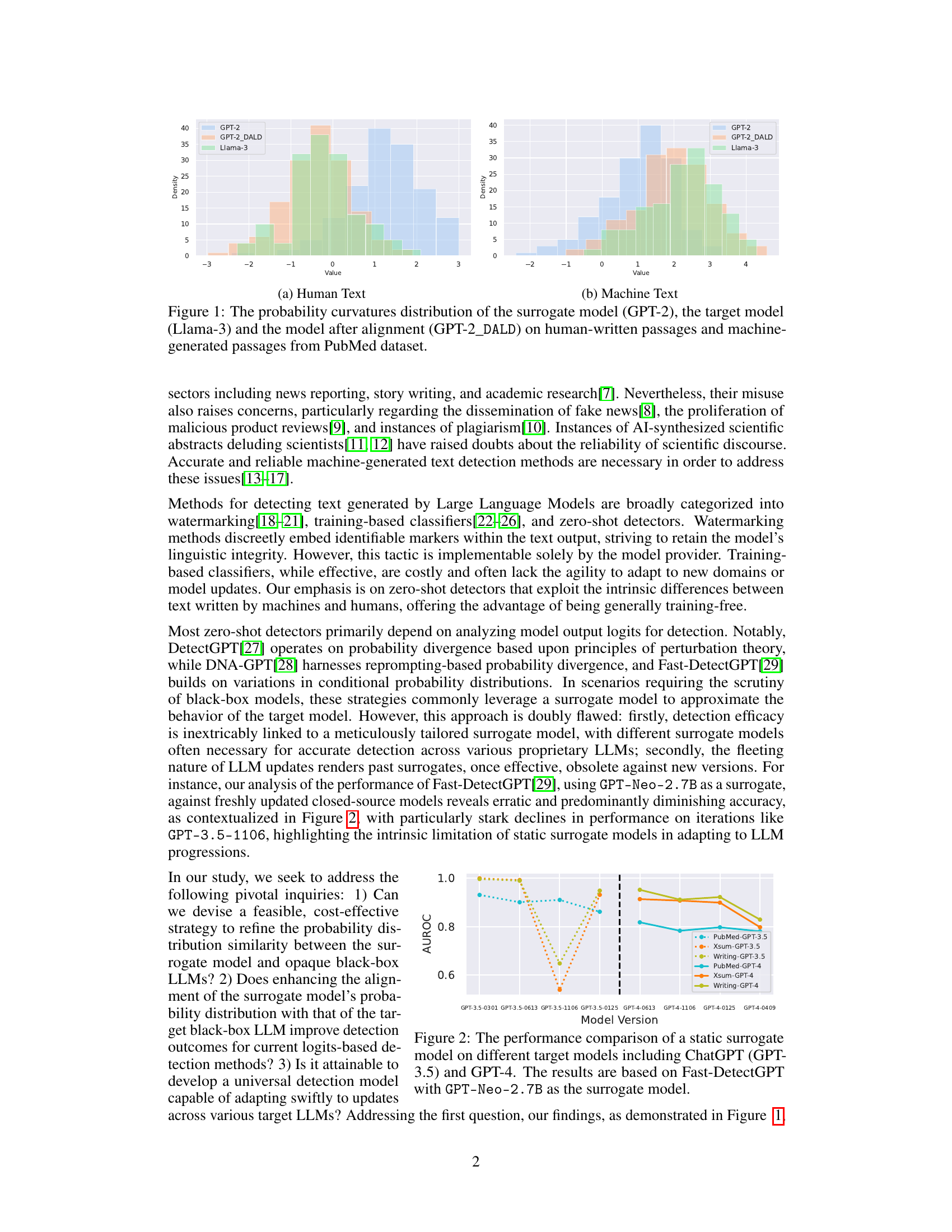
This figure compares the probability curvature distributions of three models: a surrogate model (GPT-2), a target model (Llama-3), and the surrogate model after alignment with the target model’s distribution (GPT-2_DALD). The distributions are shown separately for human-written and machine-generated text from the PubMed dataset. The alignment process aims to make the surrogate model’s distribution more similar to that of the target model, improving the accuracy of detecting machine-generated text in a black-box setting. The visual comparison shows that after alignment, the GPT-2_DALD model’s distribution becomes much closer to the Llama-3 model’s distribution for both human and machine-generated texts.

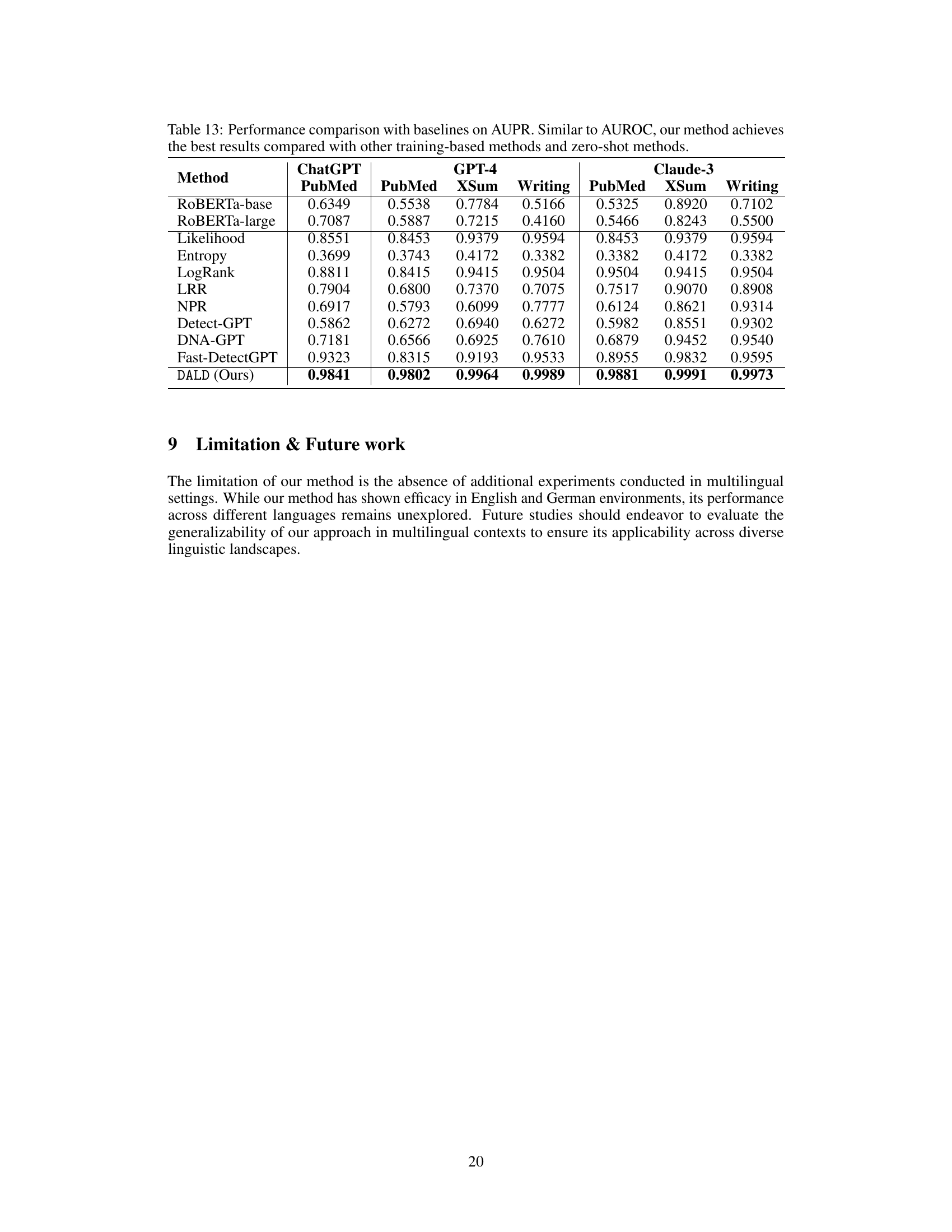
This table presents the performance comparison of different detection methods on three different Large Language Models (LLMs): ChatGPT, GPT-4, and Claude-3. The models are evaluated on three datasets: PubMed, XSum, and Writing, each representing a different text genre. The table shows the Area Under the Receiver Operating Characteristic (AUROC) for each method on each dataset and LLM. The results demonstrate that the proposed DALD method outperforms existing methods across all datasets and LLMs.
In-depth insights#
LLM Detection#
LLM detection is a rapidly evolving field driven by the increasing sophistication and prevalence of large language models (LLMs). Current approaches often leverage logits, the model’s internal probability distributions, for detection, but this method struggles with black-box LLMs where logits are unavailable. Zero-shot methods, which avoid explicit training on LLM-generated text, are gaining traction due to their adaptability to emerging LLMs. However, these methods rely heavily on the chosen surrogate model and its alignment with the target LLM, leading to performance degradation when the source LLM is unknown or frequently updated. Future research should focus on improving the robustness of zero-shot detection methods by developing more effective distribution alignment techniques for surrogate models, thereby enhancing their generalization ability across various LLMs. Additionally, exploring alternative detection signals beyond logits and addressing the challenges posed by adversarial examples and multilingual contexts would further advance the field. The development of a unified and versatile framework capable of handling both open and closed source LLMs remains a significant goal. Ultimately, advancements in this area are crucial for mitigating the risks associated with malicious use of LLMs, promoting trust, and fostering a responsible AI ecosystem.
DALD Framework#
The DALD framework, designed for black-box LLM detection, presents a novel approach to address the limitations of existing methods. Its core innovation lies in aligning the distribution of a surrogate model with that of the target, undisclosed LLM. This alignment significantly enhances detection accuracy and robustness against frequent LLM updates. Unlike traditional methods heavily reliant on logits, DALD operates effectively even without access to the target model’s internal probabilities. Instead, it leverages publicly available LLM outputs for training, making it adaptable and cost-effective. The framework’s plug-and-play nature allows seamless integration with existing zero-shot detection methods, further enriching their capabilities. DALD’s resilience against revised texts and its cross-lingual adaptability highlight its practical value and broad applicability. The theoretical analysis provided strengthens the framework’s foundation and showcases its effectiveness through rigorous experimentation.
Surrogate Alignment#
Surrogate alignment, in the context of detecting AI-generated text, is a crucial technique to improve the accuracy of black-box detection methods. These methods often rely on a surrogate model—a publicly available model—to approximate the behavior of a target model (a closed-source, proprietary model whose outputs need to be identified). The core challenge is that the surrogate and target models typically have differing probability distributions. Surrogate alignment aims to mitigate this distribution gap by fine-tuning the surrogate model on a dataset of outputs from the target model. This improves the surrogate model’s ability to mimic the statistical characteristics of the target model’s outputs, leading to enhanced detection capability. Effective surrogate alignment requires careful selection of both the surrogate model and the alignment dataset. The dataset should be of sufficient size and quality to capture the salient features of the target model’s distribution. Furthermore, a successful technique should be robust against model updates, enabling consistent detection performance even as the target models evolve. Overall, surrogate alignment is a critical component of advanced LLM detection, directly addressing a major limitation of traditional logits-based detection approaches.
Black-box Limits#
The hypothetical heading, ‘Black-box Limits’, in the context of a research paper likely explores the challenges and constraints of evaluating or utilizing black-box models. It would delve into the limitations of relying solely on input/output interactions without access to the model’s internal workings. Key aspects discussed might include: the difficulty of assessing model robustness, fairness, or the reasons behind specific outputs; limitations on explainability and debugging when issues arise; difficulties in detecting and mitigating biases. A crucial area would be the comparison of performance against models with accessible internal information, highlighting the trade-offs between black-box convenience and the depth of analysis possible. The section would likely conclude by discussing potential strategies to overcome or address these limitations, such as surrogate modeling, adversarial attacks, or the development of novel evaluation metrics suitable for opaque systems.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending DALD’s capabilities to multilingual settings is crucial for broader applicability. The current study’s focus on English and German hints at the potential for cross-lingual effectiveness, but rigorous evaluation across diverse languages is needed. Investigating the robustness of DALD against more sophisticated adversarial attacks is also important. While the paper demonstrates resilience to basic text modifications, advanced adversarial techniques might pose challenges. Exploring the integration of DALD with other detection methods could lead to a more robust and comprehensive detection system. A hybrid approach combining different techniques might overcome the limitations of individual methods, improving overall accuracy and reliability. Furthermore, research into the theoretical underpinnings of distribution alignment is warranted. A deeper understanding of why this approach works so effectively could lead to improved training techniques and further enhancements to DALD’s performance. Finally, assessing DALD’s efficacy on newer and evolving LLMs is essential to ensure its continued relevance. The rapidly changing landscape of large language models necessitates continuous evaluation and adaptation of detection methods to maintain their accuracy.
More visual insights#
More on figures
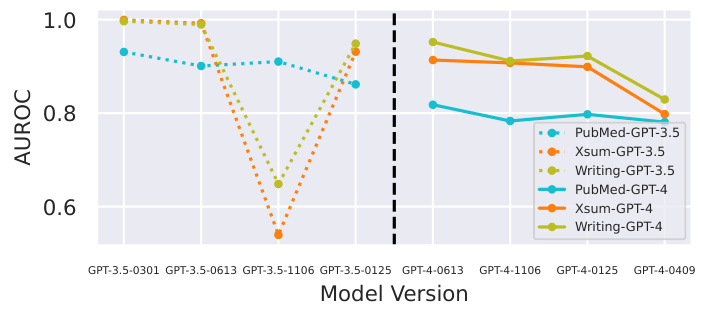
This figure shows the performance of a static surrogate model (GPT-Neo-2.7B) used within the Fast-DetectGPT framework when trying to detect various versions of the ChatGPT (GPT-3.5) and GPT-4 models. The x-axis represents different versions of the target models (GPT-3.5 and GPT-4 released on different dates). The y-axis shows the Area Under the ROC Curve (AUROC), a metric representing the model’s ability to distinguish between human-written text and AI-generated text. The significant drop in AUROC for later model versions highlights the limitation of using a static surrogate model for detecting constantly evolving LLMs.
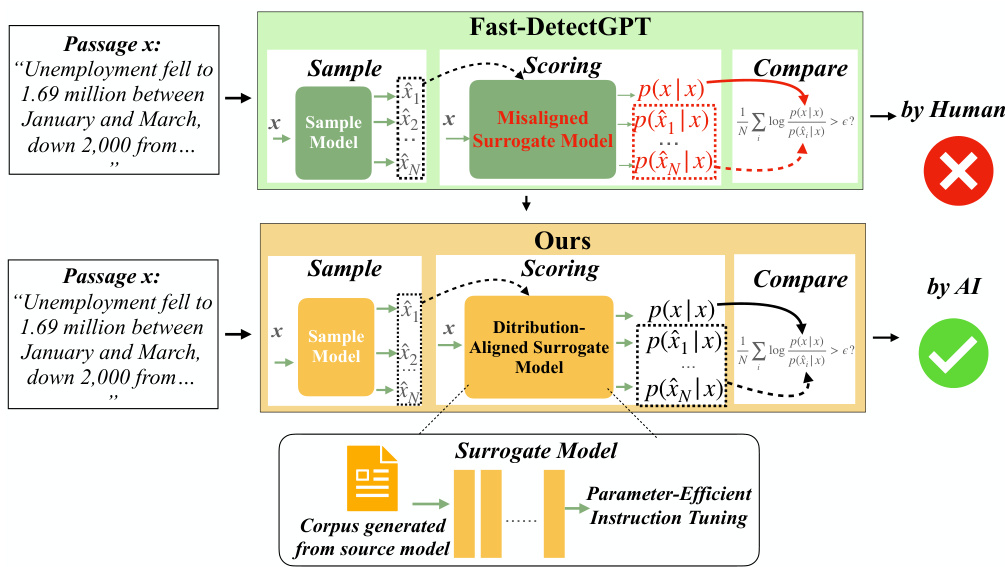
This figure illustrates the DALD framework, highlighting the key difference between existing methods (Fast-DetectGPT) and the proposed approach. Fast-DetectGPT uses a misaligned surrogate model, leading to inaccurate classification of human-written vs. AI-generated text. In contrast, DALD aligns the surrogate model’s distribution with the target model’s distribution using parameter-efficient instruction tuning on a corpus of known LLM-generated text. This alignment significantly improves the accuracy of the text classification. The figure visually shows how the DALD method addresses the distribution mismatch problem by fine-tuning the surrogate model to match the target model, thus leading to improved performance in black-box LLM detection.
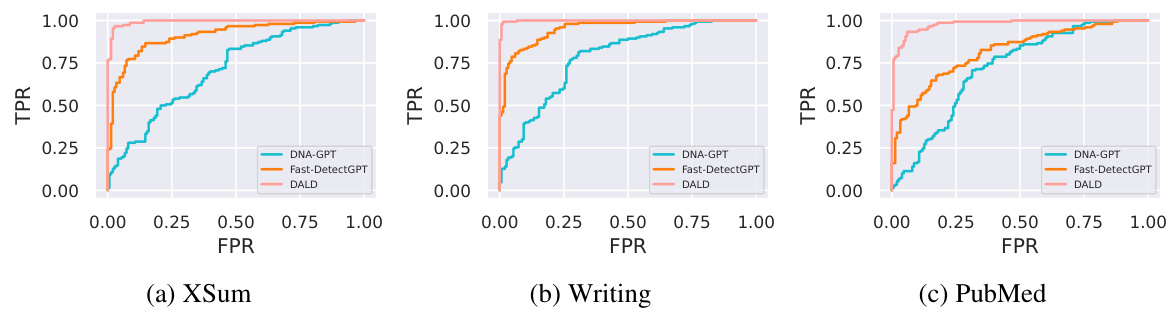
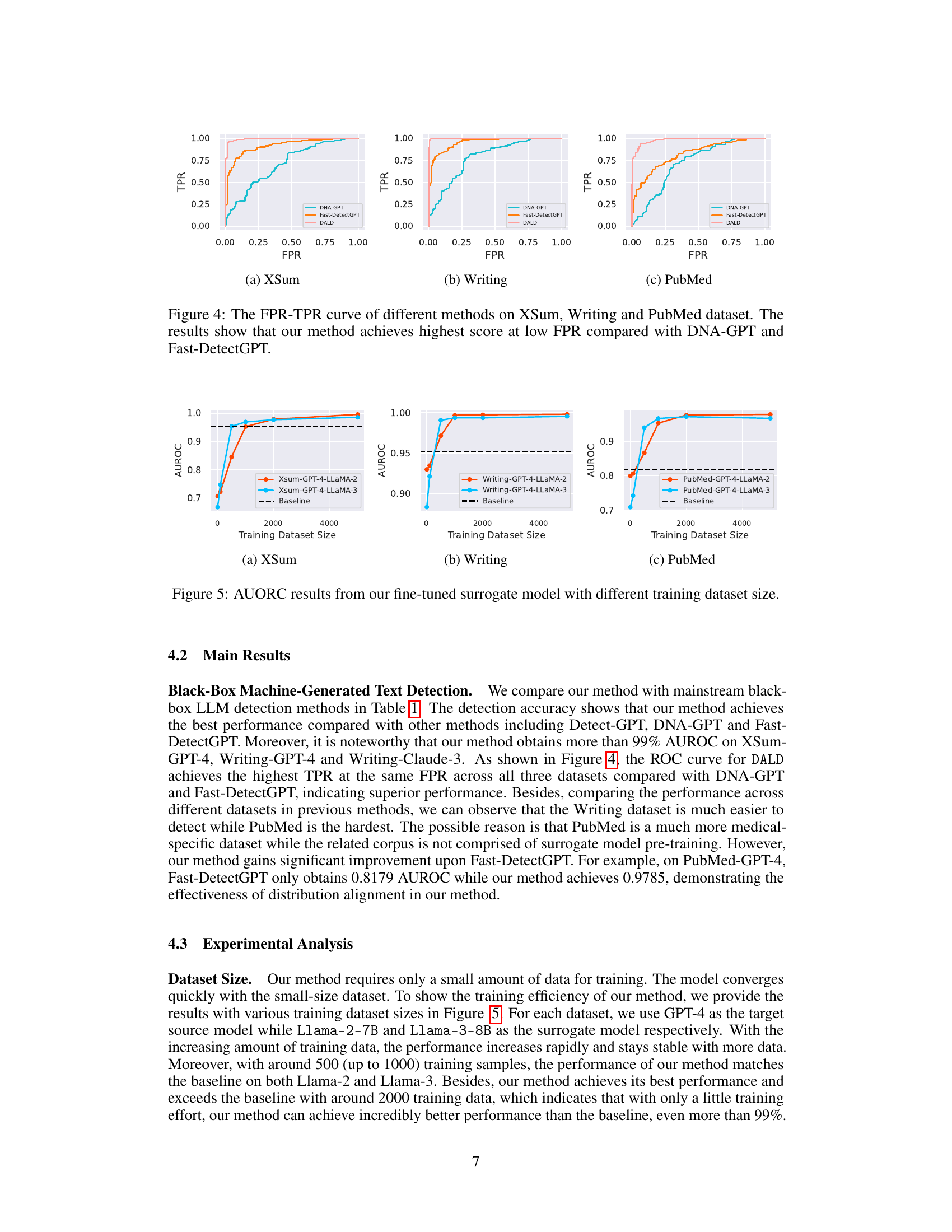
This figure displays the Receiver Operating Characteristic (ROC) curves for three different LLM detection methods (DNA-GPT, Fast-DetectGPT, and DALD) across three distinct datasets (XSum, Writing, PubMed). The ROC curve plots the True Positive Rate (TPR) against the False Positive Rate (FPR) at various threshold settings. The curves visually demonstrate the performance of each method, highlighting DALD’s superior performance at lower FPR values indicating a better balance between correctly identifying LLM-generated text and minimizing false positives.

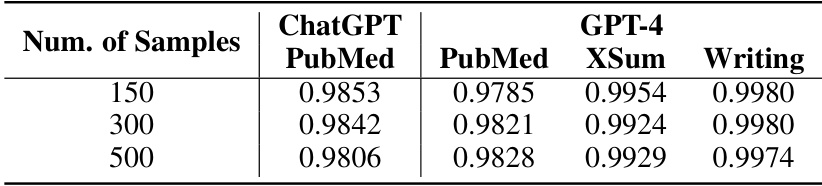
This figure demonstrates the impact of training dataset size on the Area Under the Receiver Operating Characteristic (AUROC) curve for the proposed Distribution-Aligned LLMs Detection (DALD) method. Three datasets (XSum, Writing, PubMed) are used to evaluate the model’s performance with two different surrogate models (LLaMA-2 and LLaMA-3). The results show how AUROC increases as the size of the training dataset grows, eventually plateauing, indicating that DALD is effective with a relatively small training dataset, and the performance difference between two surrogate models are insignificant.

This figure shows the robustness of the proposed method (DALD) against adversarial attacks. The AUROC (Area Under the Receiver Operating Characteristic curve) is plotted against the ratio of revisions made to the original text. The graph compares the performance of DNA-GPT and Fast-DetectGPT, both individually and after incorporating the DALD improvements. It demonstrates that DALD consistently improves the robustness of both DNA-GPT and Fast-DetectGPT against adversarial attacks, maintaining higher AUROC scores even when a significant portion of the text is revised.
More on tables

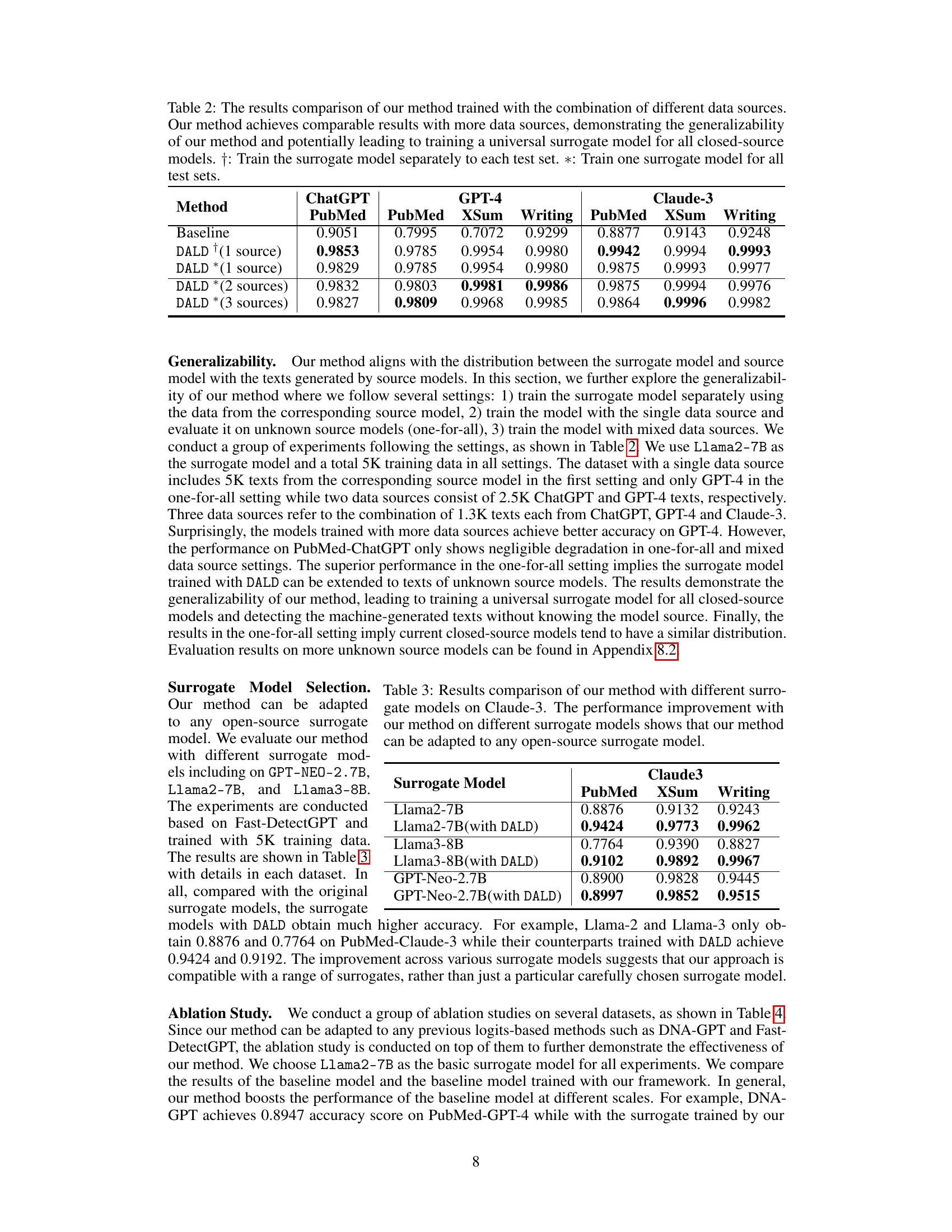
This table presents the results of the DALD method trained on different combinations of data sources. It compares the performance of the model trained on a single dataset, multiple datasets, and one universal model trained on all datasets. The goal is to demonstrate the generalizability and scalability of the DALD approach by showing that training on multiple datasets doesn’t harm performance and may even improve it, suggesting the potential to train a single model that can effectively detect various LLMs.
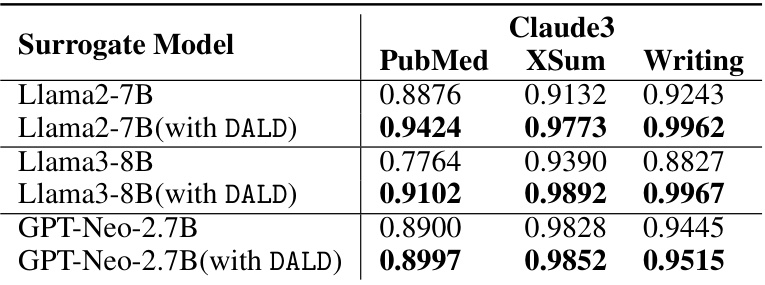
This table compares the performance of the proposed DALD method using different surrogate models (Llama2-7B, Llama3-8B, and GPT-Neo-2.7B) against their respective baselines on three datasets (PubMed, XSum, and Writing). It demonstrates that DALD improves the performance regardless of the selected surrogate model, highlighting its adaptability and robustness.
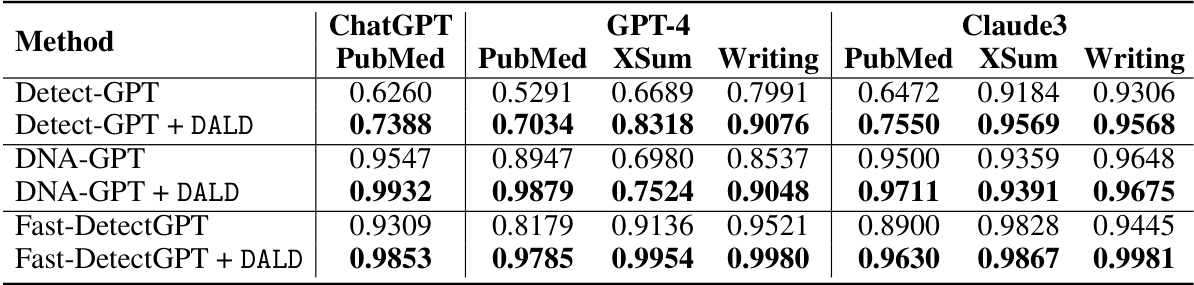
This table presents the ablation study results, comparing the performance of baseline methods (Detect-GPT, DNA-GPT, Fast-DetectGPT) against their corresponding versions enhanced by the proposed DALD framework. The improvement in performance across all baselines highlights the effectiveness of DALD in boosting the accuracy of existing logits-based LLM detection methods.
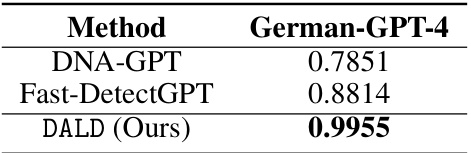
This table presents the performance comparison of three different methods (DNA-GPT, Fast-DetectGPT, and DALD) on detecting German texts generated by GPT-4. The AUROC scores are reported for each method, demonstrating the superior performance of DALD in identifying German language model-generated content compared to the baseline methods.

This table presents the performance comparison of the proposed DALD method against the Fast-DetectGPT method on three open-source large language models (LLMs): Llama-3, Llama-3.1, and Mistral. The evaluation is performed across three different datasets: PubMed, XSum, and Writing. The results are shown in terms of AUROC scores for each LLM and dataset combination, highlighting the relative performance of DALD compared to the baseline.

This table presents the results of a comparative study evaluating the performance of various methods in detecting text generated by three different large language models (LLMs): ChatGPT, GPT-4, and Claude-3. The models were tested on various datasets (PubMed, XSum, Writing), and the table compares the Area Under the ROC Curve (AUROC) achieved by different detection methods, including several baseline methods and the proposed method, DALD. The results demonstrate the superior performance of the proposed DALD method across all tested LLMs and datasets.

This table presents the complete detection accuracy results for ChatGPT (GPT-3.5-Turbo) across three datasets: PubMed, XSum, and Writing. It complements the results shown in Table 1 by providing a more detailed breakdown of the performance of different detection methods (DNA-GPT, Fast-DetectGPT, and DALD) on this specific LLM model. The table showcases the Area Under the Receiver Operating Characteristic (AUROC) scores, indicating the effectiveness of each method in distinguishing between human-written and machine-generated text.
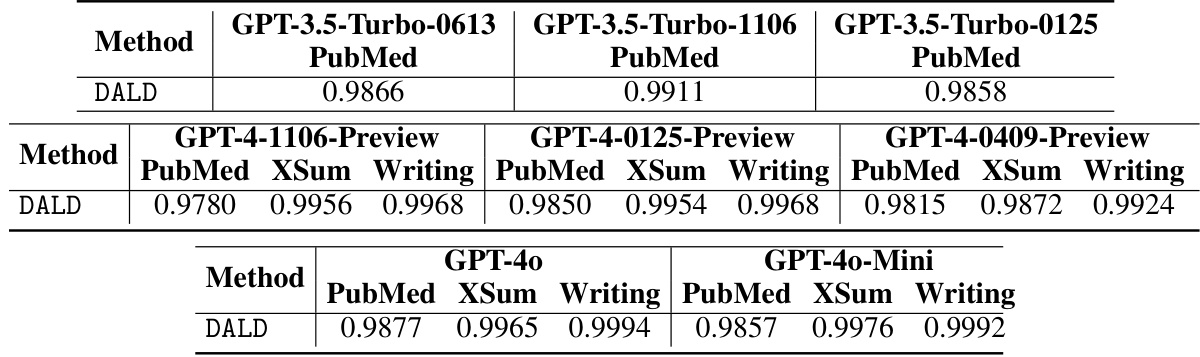
This table presents the AUROC scores achieved by various methods (including the proposed DALD) on three different LLMs (ChatGPT, GPT-4, and Claude-3) across three text datasets (PubMed, XSum, and Writing). The results demonstrate the superior performance of the DALD method compared to existing state-of-the-art (SOTA) approaches for detecting AI-generated text, even when the specific LLM used to generate the text is unknown (black-box setting).

This table presents the results of code detection experiments using the APPS dataset. It compares the performance of two methods, Fast-DetectGPT and the proposed DALD method, in detecting AI-generated code. The metric used is likely AUROC (Area Under the Receiver Operating Characteristic curve), a common measure of classification performance, although this is not explicitly stated in the provided text snippet. The table shows a significant improvement in performance using the DALD method compared to Fast-DetectGPT.

This table compares the performance of Fast-DetectGPT and DALD on various text genres using the RAID dataset. The RAID dataset is a domain-specific dataset that consists of different types of text. The table shows that DALD outperforms Fast-DetectGPT in all text genres, demonstrating its robustness and generalizability.
This table presents the AUROC scores achieved by different methods for detecting AI-generated text from three different models: ChatGPT (GPT-3.5-Turbo-0301), GPT-4 (GPT-4-0613), and Claude-3 (claude-3-opus-20240229). The results are broken down by dataset (PubMed, XSum, Writing) and method. The table highlights that the proposed DALD method significantly outperforms existing methods in all cases, demonstrating its superior performance across various models and datasets.
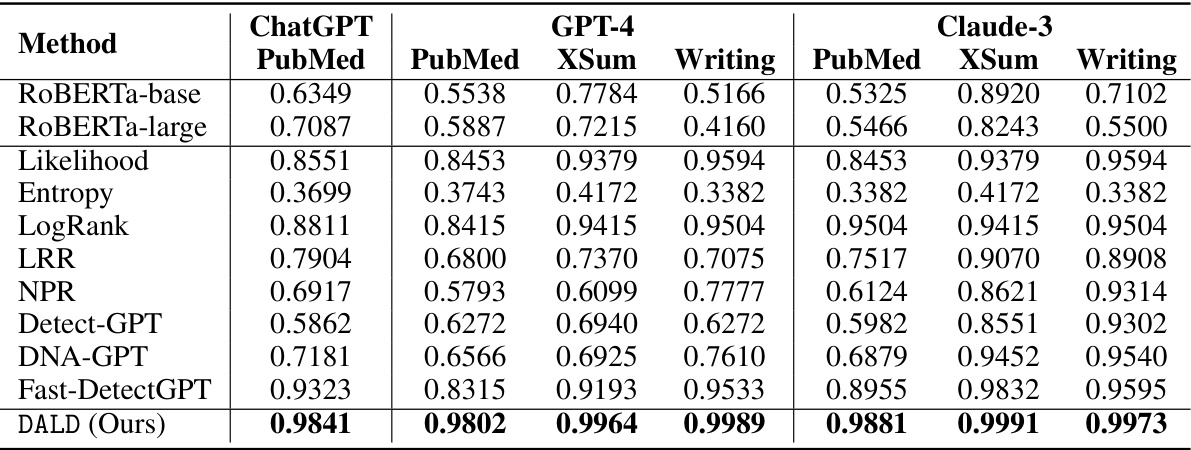
This table presents the performance comparison of different LLM detection methods on three different large language models (ChatGPT, GPT-4, and Claude-3). The performance is measured across three different datasets (PubMed, XSum, and Writing). The table highlights that the proposed method, DALD, outperforms existing methods in detecting AI-generated text from each of these models.

This table presents a comparison of the detection accuracy of several methods for identifying AI-generated text from three different large language models (LLMs): ChatGPT, GPT-4, and Claude-3. The accuracy is evaluated across three different datasets (PubMed, XSum, and Writing) for both human-written and machine-generated text. The table shows that the proposed DALD method outperforms existing state-of-the-art methods in all cases.
Full paper#