↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The proliferation of Large Language Models (LLMs) raises concerns about misuse, particularly in areas like academic dishonesty and the spread of misinformation. Current AI-generated text detection methods often struggle to keep pace with advancements in LLMs, particularly commercial ones, and frequently lack robustness. Many existing methods focus on predicting the next token, neglecting the equally important information about preceding tokens present in the model’s internal states.
This paper introduces BISCOPE, a novel detection system that addresses these limitations. BISCOPE uses a bidirectional approach, calculating cross-entropy losses between output logits and both the next token (forward) and the preceding token (backward). This approach proves superior across multiple datasets and various commercial LLMs, achieving over 0.95 detection F1 score and outperforming existing methods including GPTZero. The accompanying publicly available dataset enhances the field’s ability to develop even more robust and efficient detection techniques.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on AI-generated text detection. It introduces a novel, high-performing method (BISCOPE) that surpasses existing techniques, especially those using commercial LLMs, improving the accuracy and efficiency of detection. This work addresses a growing concern regarding the misuse of powerful AI models and paves the way for more robust methods against increasingly sophisticated AI-generated content. Its large-scale, publicly available dataset enhances future research in this critical area.
Visual Insights#
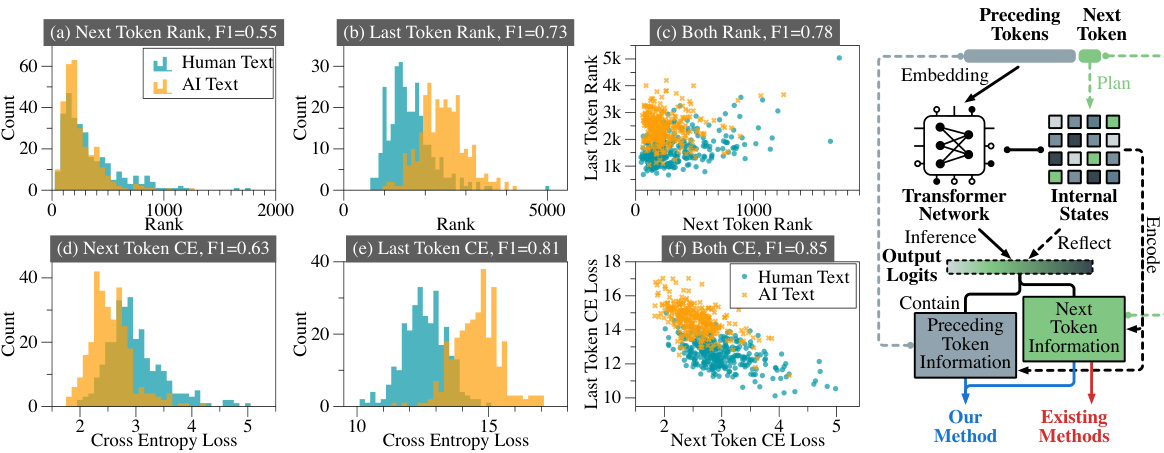
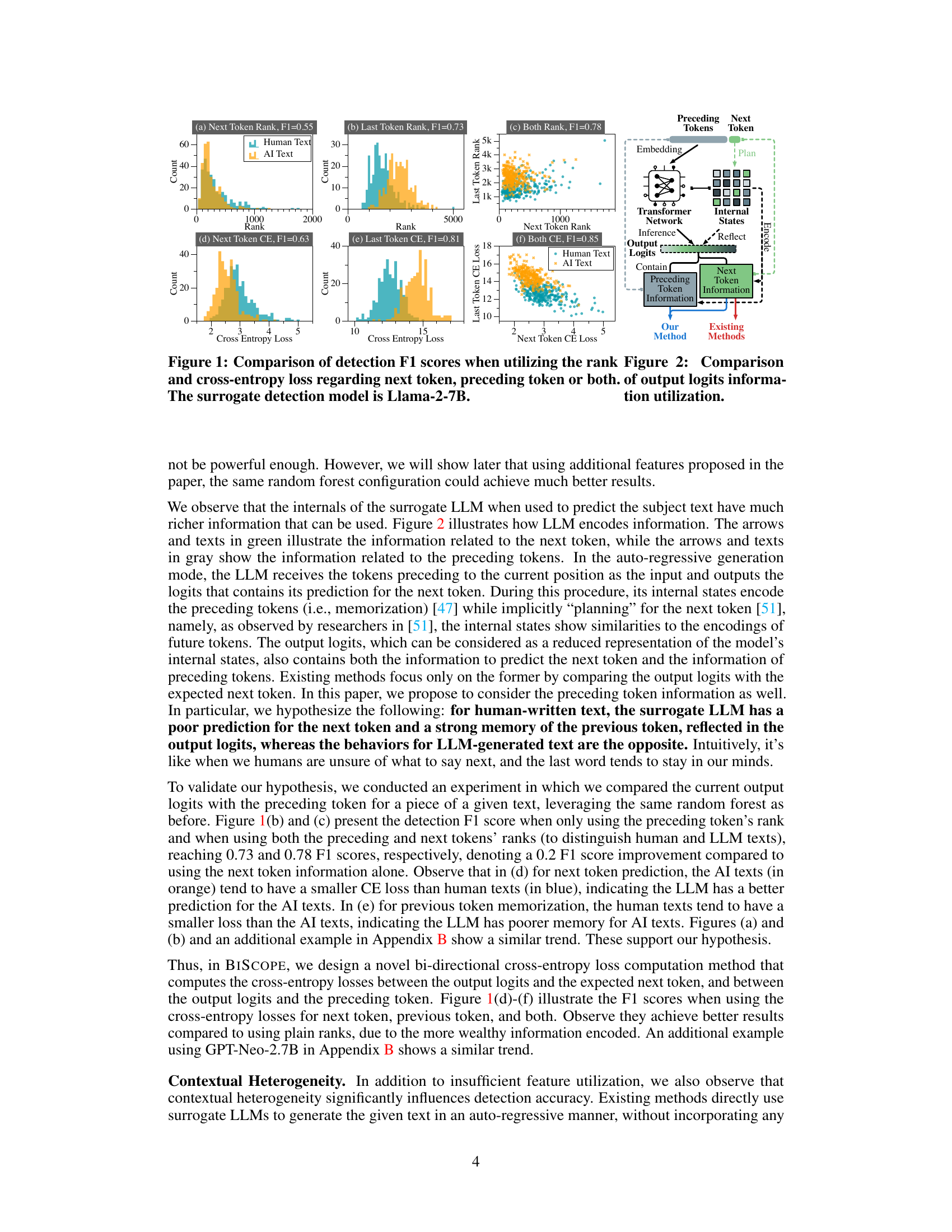
This figure compares the performance of AI-generated text detection using different features. The features compared include the rank and cross-entropy loss of the next token, the preceding token, and both combined. The results show that using both the next and preceding token features yields significantly better detection accuracy (F1 score). The Llama-2-7B model is used as the surrogate model for this analysis.

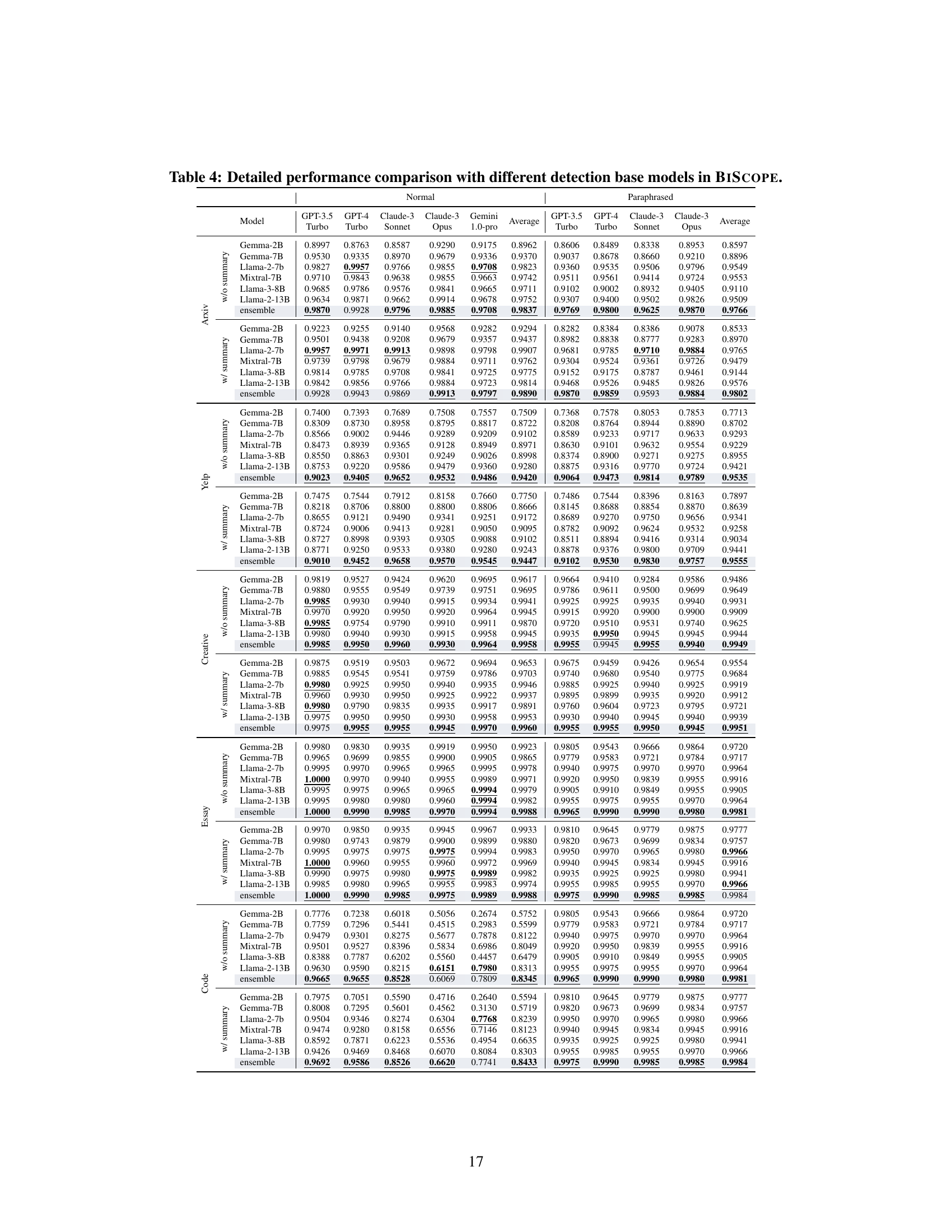
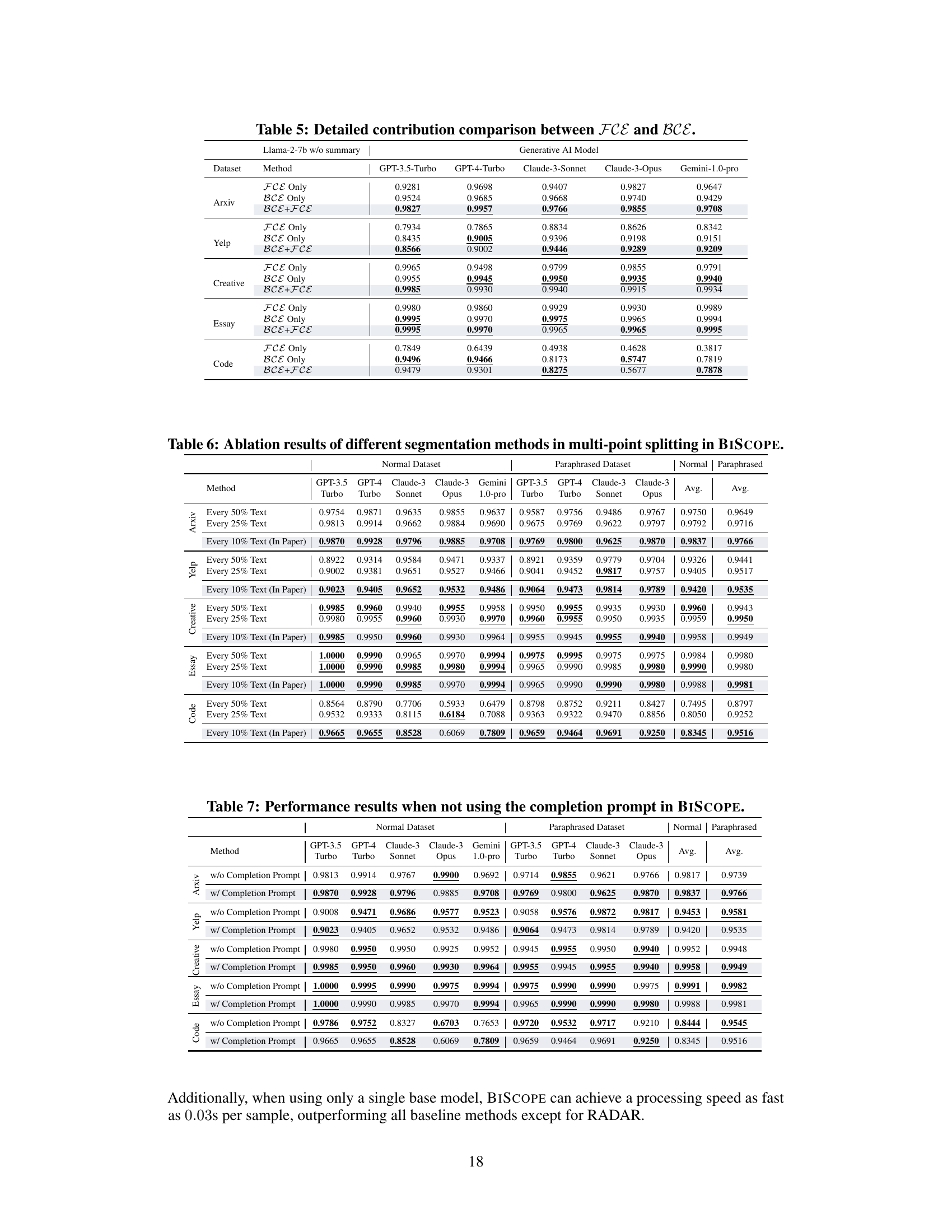
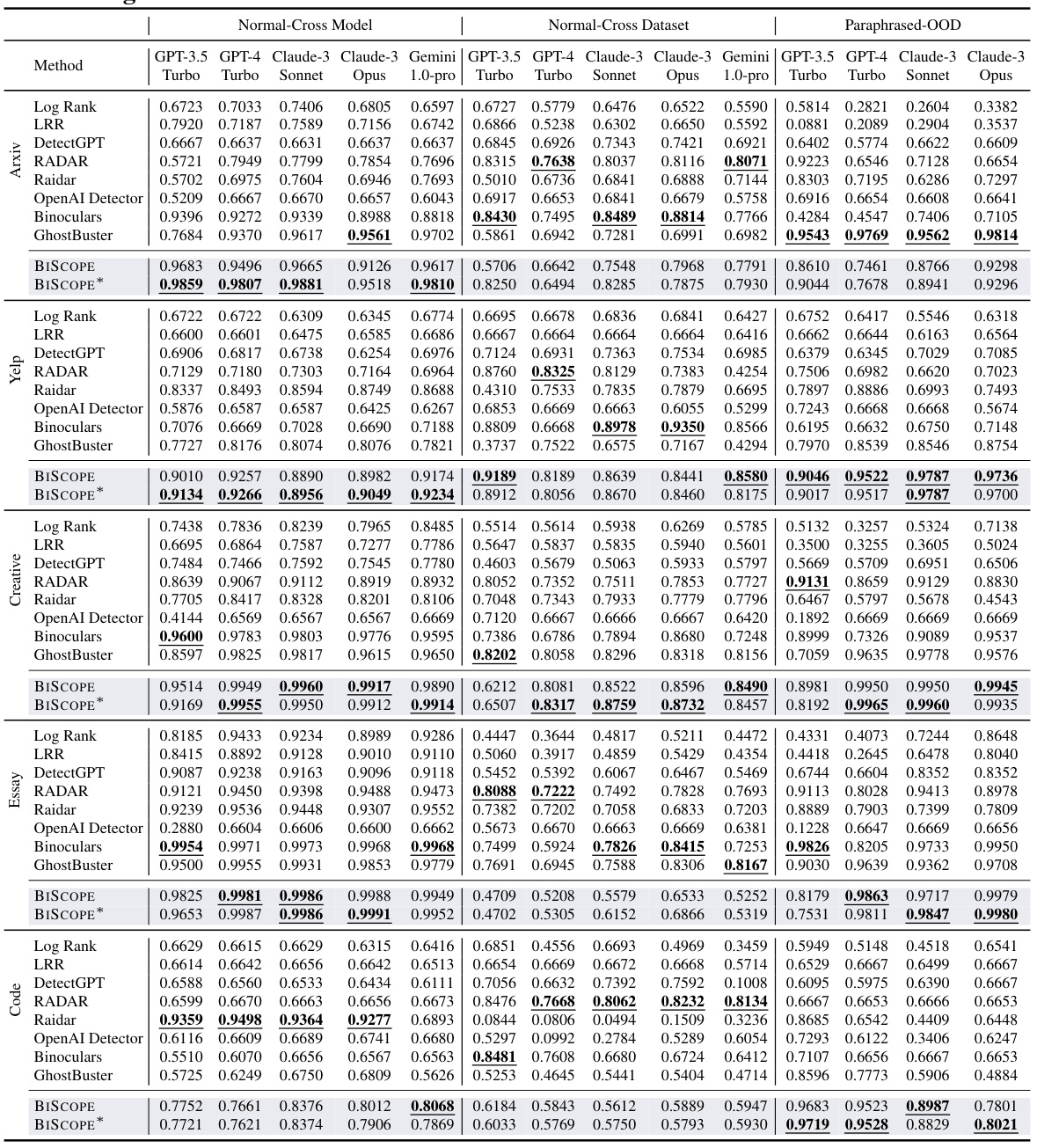
This table presents a comprehensive comparison of the performance of BISCOPE and nine other AI-generated text detection methods across five different datasets. The datasets include both normal and paraphrased versions of text from different domains. The table shows the F1 scores for each method in both in-distribution (the test data comes from the same source as the training data) and out-of-distribution settings (the test data comes from a different source than the training data). The out-of-distribution settings further break down into cross-model (CM) and cross-dataset (CD) scenarios. The results demonstrate BISCOPE’s superior performance and robustness across various conditions.
In-depth insights#
LLM Text Detection#
LLM text detection is a rapidly evolving field driven by the increasing sophistication and accessibility of large language models (LLMs). Current methods often struggle with the diversity and advancement of LLMs, demonstrating limitations in accurately distinguishing AI-generated text from human-written content. This challenge necessitates the development of more robust and effective detection techniques. Key approaches involve analyzing the statistical properties of the text, measuring the predictability of next tokens, and utilizing surrogate models to assess the likelihood of LLM authorship. Future research directions include exploring new features, improving robustness against adversarial attacks like paraphrasing, and enhancing efficiency to meet real-world demands for rapid and accurate detection. The development of larger, more diverse datasets is crucial for improving the performance and generalization of LLM text detectors, and the ethical implications of these technologies must be carefully considered to prevent misuse and maintain integrity.
BiScope’s Mechanism#
BiScope employs a novel mechanism for AI-generated text detection. It leverages a surrogate LLM to assess both the predictive ability (forward) and the memorization capabilities (backward) of the model that generated the text. This bidirectional approach calculates cross-entropy losses between the output logits and the ground-truth next token, as well as the preceding input token. This dual assessment provides a richer representation of the LLM’s internal states than existing methods that focus solely on predictive accuracy. The incorporation of text summarization further enhances the robustness of the system, helping to contextualize the input and reduce the impact of contextual heterogeneity. A binary classifier then combines the statistical features extracted from these losses to provide the final prediction. This mechanism differentiates itself from prior work through its bidirectional analysis and contextual guidance, achieving superior performance and robustness.
Evaluation Metrics#
Choosing the right evaluation metrics is crucial for assessing the performance of AI-generated text detection models. Common choices include precision, recall, and F1-score, which offer a balanced perspective on both true positives and false positives. However, the optimal metrics depend heavily on the specific application and its priorities. For instance, in high-stakes scenarios like academic integrity checks, false negatives (failing to identify AI-generated text) are far more problematic than false positives, requiring a focus on high recall. Conversely, in less critical applications, precision might be prioritized to minimize false alarms. The choice of metrics must also consider the nature of the data itself. Are the datasets balanced, or do they suffer from class imbalance? If the latter, metrics that account for such imbalances, like macro-averaged F1-score, are necessary. Considering multiple metrics in tandem provides a more holistic understanding of model effectiveness. Finally, evaluating performance across various datasets and LLMs is critical to ensure the model’s generalizability and robustness.
Future Enhancements#
Future enhancements for AI-generated text detection should prioritize addressing limitations in out-of-distribution generalization and robustness against sophisticated paraphrasing techniques. Improving the efficiency of the detection process while maintaining high accuracy remains crucial. This could involve exploring more efficient surrogate models or optimizing feature extraction methods. Investigating the potential of incorporating multimodal features (e.g., combining text with visual or audio data) offers a promising avenue for enhancing detection capabilities. Further research should also focus on evaluating the impact of evolving LLM architectures and improving methods to tackle adversarial attacks which are often used to obfuscate AI-generated text.
Study Limitations#
This research, while groundbreaking in its approach to AI-generated text detection, acknowledges several limitations. The reliance on a surrogate model introduces inherent limitations, as the surrogate may not perfectly capture the behavior of the model used to generate the text. The study also points out that their large-scale dataset, while more extensive than previous works, may not encompass the full diversity of real-world scenarios. Another limitation is the computational cost associated with the parallel processing of multiple LLMs; this can affect the practicality of real-time implementation. Finally, the method’s efficacy under out-of-distribution settings could be improved, particularly concerning its performance on datasets with significant linguistic differences from its training data. Future research should address these limitations to further enhance the robustness and applicability of AI-generated text detection.
More visual insights#
More on figures
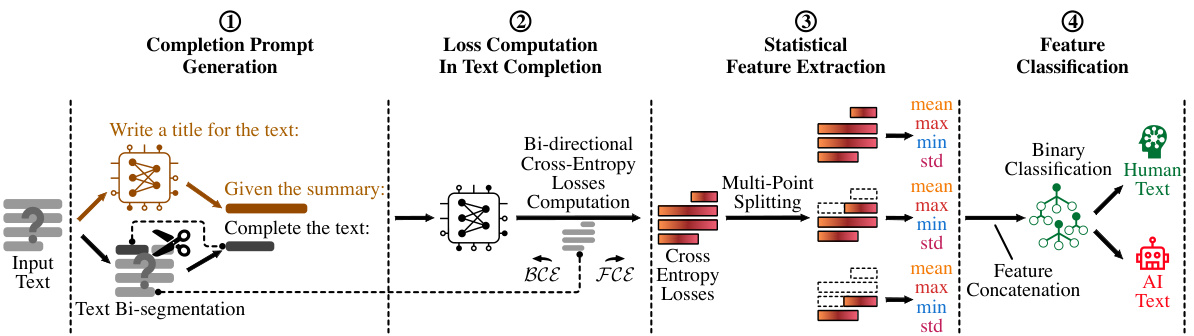
This figure presents a flowchart illustrating the four main steps of the BISCOPE AI-generated text detection system. Step 1 involves generating a completion prompt using a text summarization technique to provide contextual information to a Language Model (LLM). This prompt includes a summary of the input text and a portion of the input text itself, acting as a prompt for the LLM to complete the remaining text. Step 2 involves computing bi-directional cross-entropy losses within the LLM, measuring how well the output logits predict the next token (forward) and memorize the preceding token (backward). Step 3 involves extracting statistical features from the losses by splitting the input text into multiple segments and collecting loss statistics for each segment. Finally, Step 4 utilizes a binary classifier trained on these statistical features to determine if the input text is AI-generated or human-written.

This figure presents the Receiver Operating Characteristic (ROC) curves for BISCOPE and nine other baseline methods. Each subfigure (a-e) shows the ROC curve for a different large language model (LLM): GPT-3.5-Turbo, GPT-4-Turbo, Claude-3-Sonnet, Claude-3-Opus, and Gemini-1.0-Pro. The curves illustrate the trade-off between the true positive rate (TPR) and the false positive rate (FPR) for each method, allowing for a comparison of their performance in detecting AI-generated text. BISCOPE consistently demonstrates superior performance compared to the baselines, exhibiting higher TPR at similar FPR values.
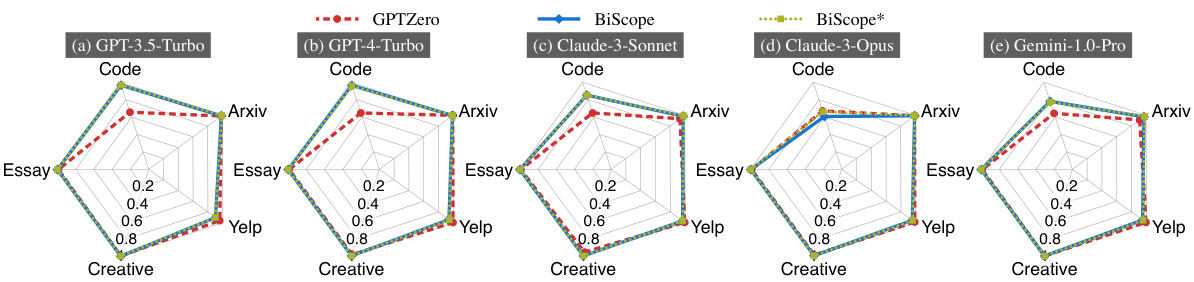
This figure compares the performance of BISCOPE and BISCOPE* (with and without text summarization) against GPTZero, a commercial AI-generated text detection tool, across five datasets generated using five different commercial LLMs. The comparison is made using the F1 score as a metric. Each subfigure represents a different LLM and displays the F1 score achieved by each method across the five datasets: Arxiv, Yelp, Creative, Essay, and Code. This visualization allows for a clear comparison of the relative performance of each method across various datasets and LLMs, demonstrating BISCOPE’s effectiveness in detecting AI-generated text.
This figure presents the Receiver Operating Characteristic (ROC) curves for BISCOPE and nine other baseline methods. ROC curves illustrate the performance of a binary classifier system as its discrimination threshold is varied. The x-axis represents the false positive rate (FPR), and the y-axis represents the true positive rate (TPR). A curve closer to the top-left corner indicates better performance, with a higher area under the curve (AUC) signifying improved classification accuracy. Each line represents the performance of a different method, allowing for direct comparison of their effectiveness in detecting AI-generated text. The results shown are for the Yelp dataset, but similar plots would exist for the other datasets mentioned in the study.
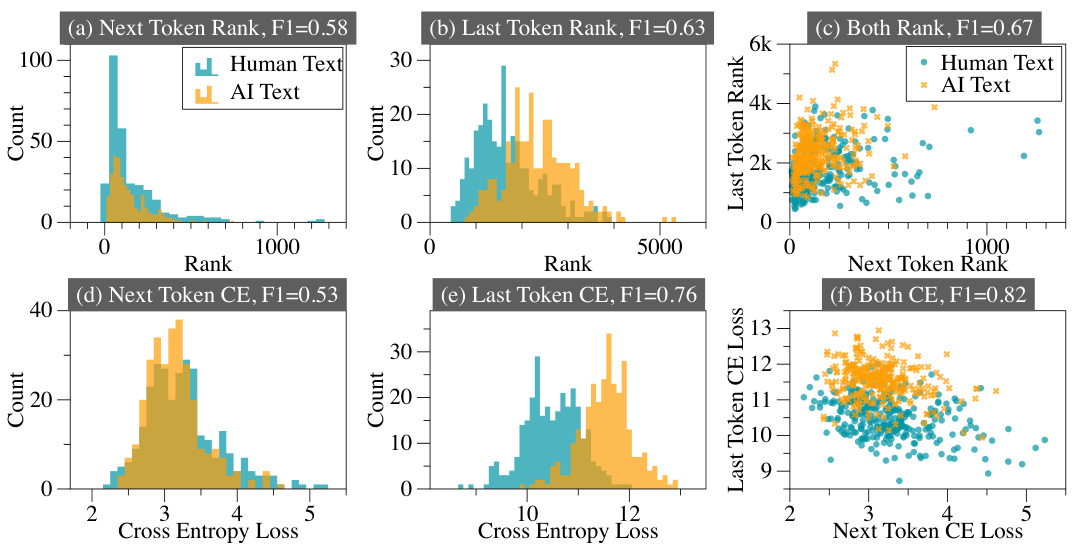
This figure compares the performance (F1 score) of AI-generated text detection models using different features. The features used are based on token rank (how easily the LLM predicts a token) and cross-entropy loss (how well the LLM’s prediction matches the actual token). It shows a comparison between using only the next token’s information, only the preceding token’s information, and both next and preceding token information. The results demonstrate that incorporating both next and preceding token information significantly improves the detection accuracy. The Llama-2-7B model served as the surrogate model for this experiment.
More on tables
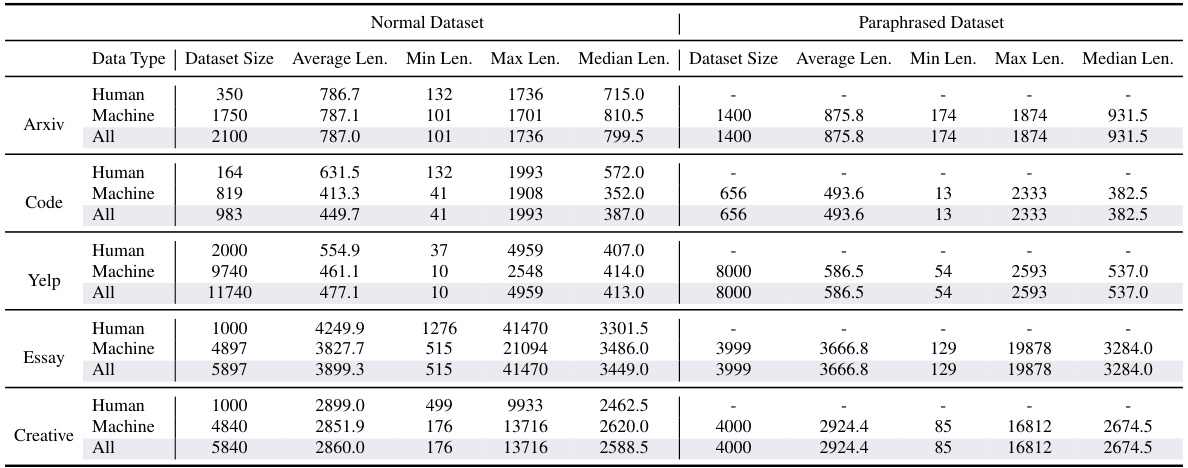
This table presents a comprehensive comparison of the detection performance of BISCOPE against nine other state-of-the-art methods. It shows the average F1 scores achieved by each method across five different datasets (Arxiv, Yelp, Creative, Essay, and Code) under various conditions. These conditions include in-distribution (ID) and out-of-distribution (OOD) settings for both normal and paraphrased versions of the datasets. The in-distribution settings assess performance using data from the same source as the training data, while the out-of-distribution settings evaluate the models on data from an unseen source. The table allows for a thorough assessment of each algorithm’s effectiveness and robustness.
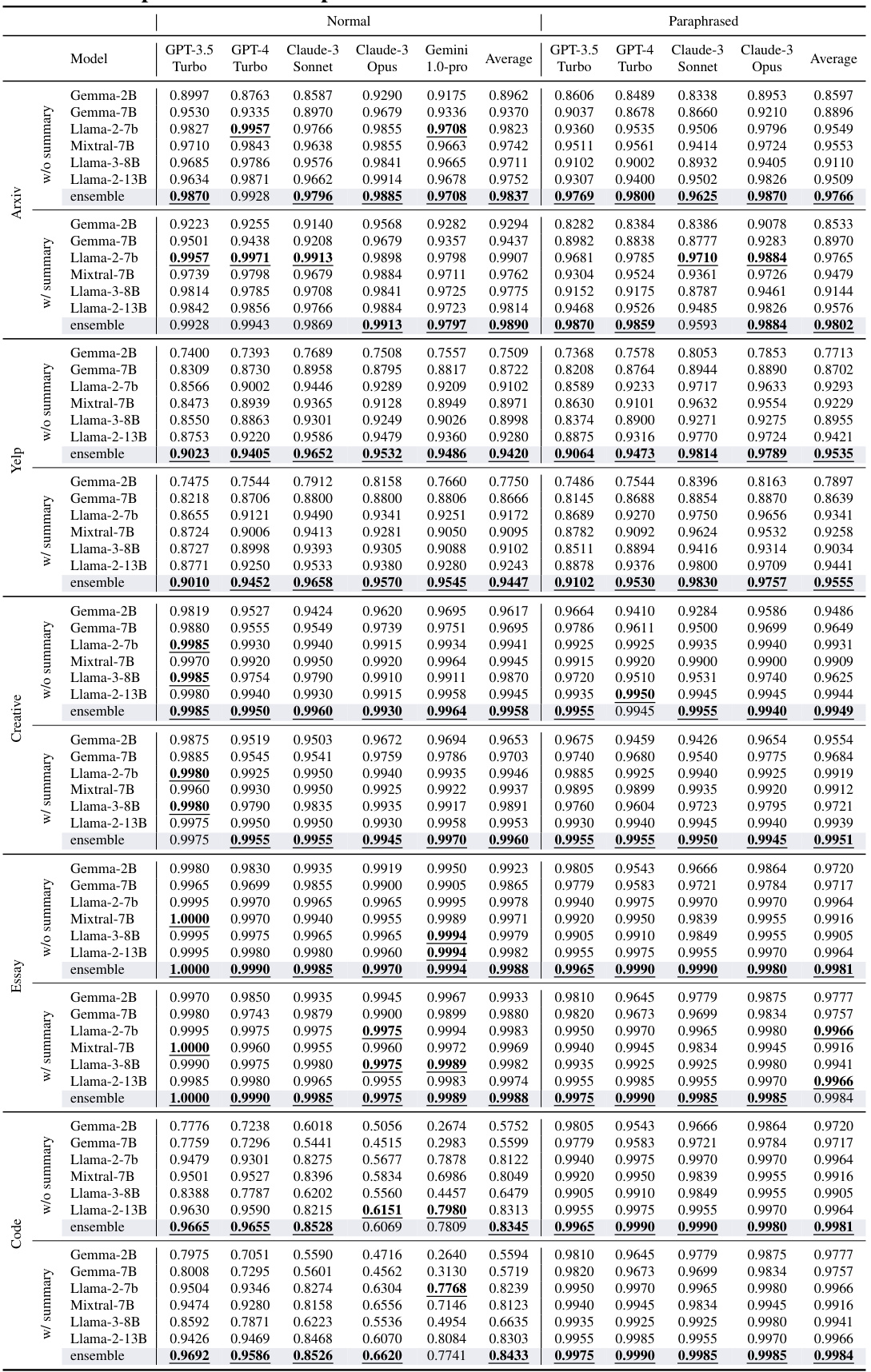
This table presents a comprehensive comparison of the performance of BISCOPE and nine other AI-generated text detection methods across five datasets. The datasets are split into normal and paraphrased versions. Performance is evaluated under both in-distribution (where the test data comes from the same source as the training data) and out-of-distribution (OOD) settings (where the test data comes from a different source than the training data). The table shows the F1 score for each method on each dataset, broken down by the type of data (normal or paraphrased) and the distribution type (in-distribution or OOD). This allows for a thorough assessment of the methods’ accuracy and robustness in various scenarios.
This table presents a comprehensive comparison of the performance of BISCOPE and nine other AI-generated text detection methods across five datasets. The datasets include both normal and paraphrased versions. The evaluation metrics used are the F1 score under both in-distribution (where the training and testing data come from the same source) and out-of-distribution (OOD) settings (where the testing data comes from an unknown source). The OOD settings are further broken down into cross-model (CM) and cross-dataset (CD) scenarios to show robustness in different contexts.
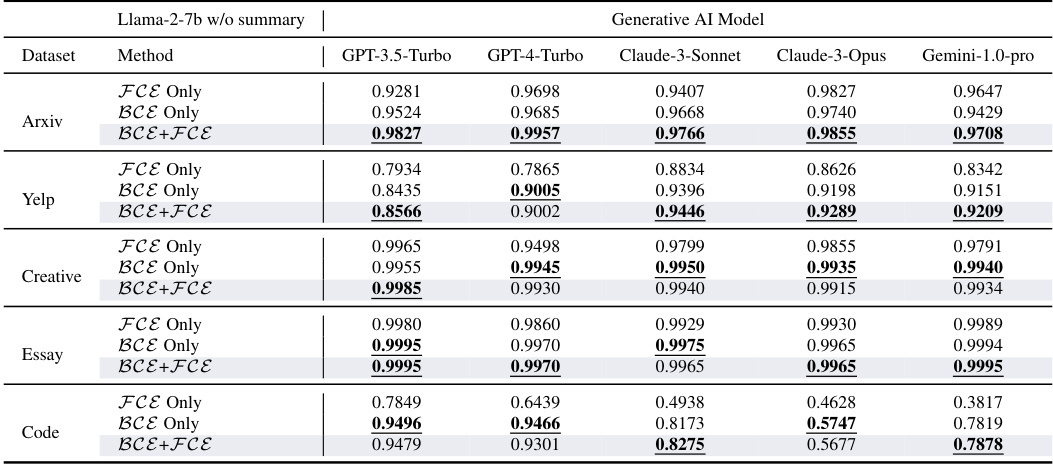
This table presents a comprehensive comparison of the performance of BISCOPE and nine other AI-generated text detection methods across five datasets. The datasets include both natural language and code, and are evaluated under both in-distribution (where the test data comes from the same source as the training data) and out-of-distribution (where the test data comes from a different, unseen source) settings. Results are given for both normal and paraphrased versions of the datasets. The metrics used are average F1 scores for different generative models, allowing for a detailed analysis of each method’s accuracy and robustness under various conditions.
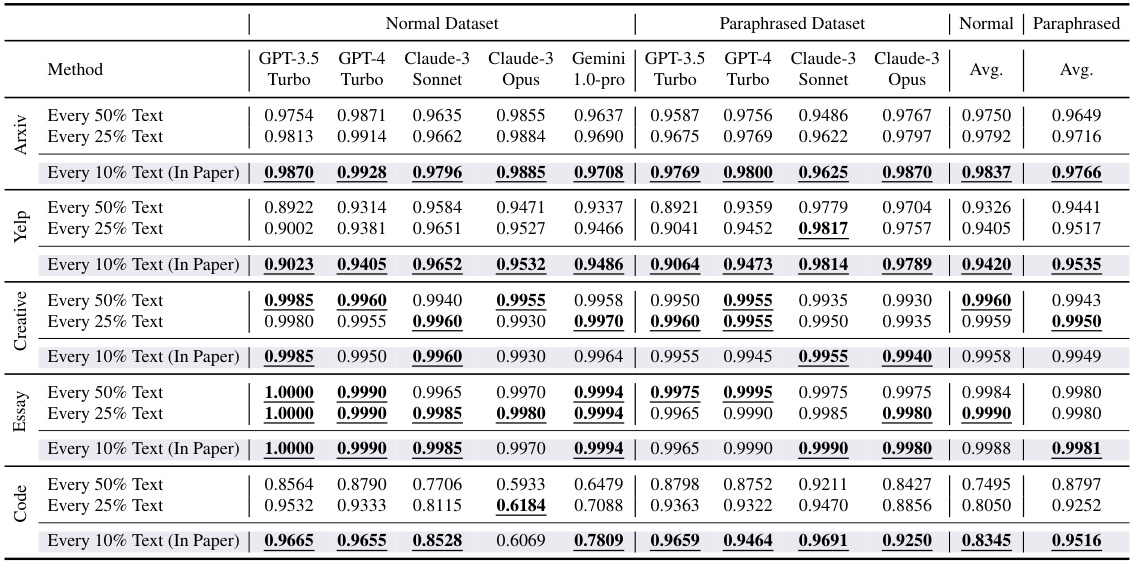
This table presents a comprehensive comparison of the performance of BISCOPE and nine other AI-generated text detection methods across five datasets. The datasets are categorized as normal and paraphrased versions. Performance is evaluated under both in-distribution (ID) and out-of-distribution (OOD) settings. The table shows the F1 scores for each method across different datasets and generative AI models (GPT-3.5-Turbo, GPT-4-Turbo, Claude-3-Sonnet, Claude-3-Opus, Gemini-1.0-Pro). The results showcase BISCOPE’s superior performance compared to existing methods in various scenarios, including the handling of paraphrased text and out-of-distribution data.
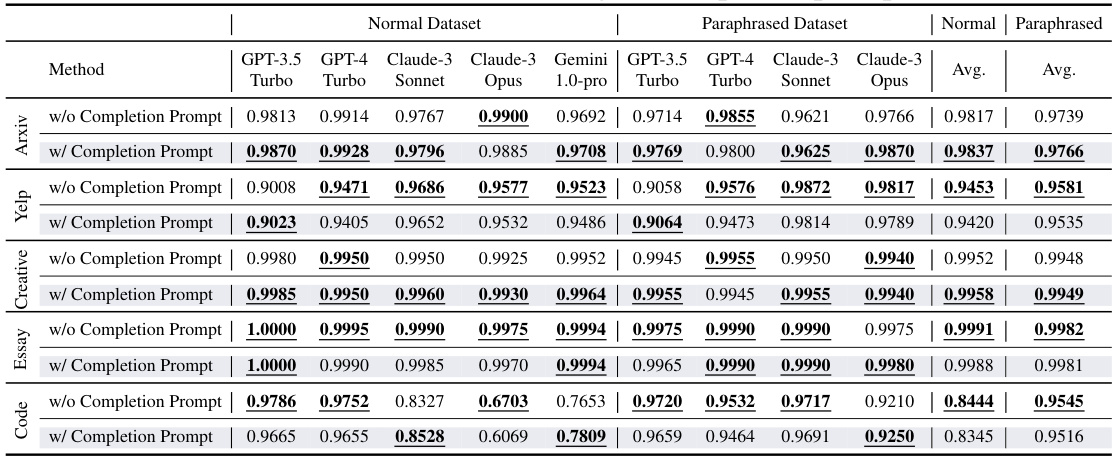
This table presents a comprehensive comparison of the detection F1 scores achieved by BISCOPE and nine other baseline methods across five datasets. The datasets include both normal and paraphrased versions of text data, encompassing various domains such as natural language and code. The results are broken down by AI model used for generation, and further categorized for in-distribution (same source as training) and out-of-distribution (different source than training) settings. This allows for a thorough evaluation of the models’ performance in different scenarios and their robustness to various data conditions.
Full paper#