↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current LLM serving systems struggle with multi-task scenarios due to limitations in model quantization and scheduling. Mainstream quantization methods hinder efficient base model sharing across multiple tasks, while existing scheduling algorithms don’t account for workload differences. This leads to memory inefficiencies and performance bottlenecks.
LoRA-Inlaid tackles these issues with a novel multi-task quantization algorithm (MLGPTQ) that allows efficient base model sharing. It also introduces a new multi-task scheduling algorithm guided by output length prediction and task grouping, leading to significant improvements in throughput, latency, job completion time, and SLO attainment. The system supports dynamic task addition without sacrificing service stability. Empirical results demonstrate that LoRA-Inlaid outperforms existing systems by up to 1.58x in throughput, 1.76x in average latency, and 2x in job completion time while improving SLO attainment by 10x.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) serving and efficient fine-tuning. It addresses the critical need for memory-efficient multi-task LLMs, offering significant performance improvements and enabling dynamic task addition, which are important aspects for real-world applications. The proposed multi-task quantization and scheduling algorithms are highly relevant to the current trends in efficient LLM deployment, paving the way for more efficient and scalable LLM systems.
Visual Insights#
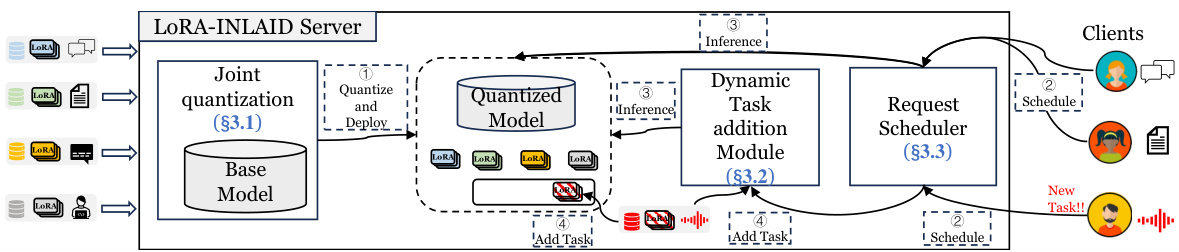
This figure illustrates the LoRA-Inlaid system’s architecture. It shows the process flow, starting from the base model through joint quantization, deployment of the quantized model and multiple LoRA adapters, dynamic task addition, request scheduling, and inference. The numbers correspond to steps described in the paper’s section 3.

This table compares several large language model (LLM) serving systems across four key features: multi-task serving, multi-task quantization, dynamic task addition, and multi-task scheduling. A checkmark indicates that the system supports the feature, while an ‘X’ indicates it does not. The table highlights the unique capabilities of the LoRA-Inlaid system proposed in the paper.
In-depth insights#
Multi-task LLM Quant#
Multi-task LLM quantization presents a significant challenge and opportunity. Existing single-task methods are inadequate because they require task-specific calibration, preventing efficient model sharing. A key innovation is the development of algorithms capable of performing joint quantization across multiple tasks, enabling a unified, quantized base model for all tasks. This reduces memory consumption significantly. Dynamic task addition is also crucial; the system should efficiently incorporate new tasks without requiring a complete requantization, ideally leveraging incremental update techniques. Finally, a smart scheduling algorithm is needed to manage diverse task workloads efficiently. It needs to factor in output length prediction to optimize resource allocation and minimize context switching latency, resulting in improved throughput and reduced average latency.
MLGPTQ Algorithm#
The core of the paper revolves around the MLGPTQ algorithm, a novel multi-task quantization method designed to overcome limitations of existing single-task approaches in large language model (LLM) serving. The algorithm is crucial because mainstream quantization techniques hinder the sharing of a quantized base LLM across multiple tasks, necessitating separate quantized models and increased memory consumption. MLGPTQ addresses this by performing joint quantization on multiple tasks simultaneously, using a carefully designed approach to leverage information from all tasks while avoiding information dilution. The innovation lies in its ability to generate a single, shareable quantized base model for all tasks, thereby significantly reducing memory usage and improving efficiency. A key aspect is its capacity for incremental quantization, allowing for the dynamic addition of new tasks without disrupting ongoing services, a significant advantage for real-world applications. This is achieved through a mechanism that efficiently incorporates new tasks’ data into the existing quantized model without the need for complete re-quantization. Overall, the MLGPTQ algorithm represents a significant improvement in multi-task LLM serving by enabling efficient memory usage and seamless task integration, contributing to enhanced overall system performance.
Dynamic Task Add#
The ability to dynamically add tasks, specifically adding new LoRA adapters in a live system, is a crucial aspect of efficient multi-task LLM serving. This functionality presents significant engineering challenges, as it requires seamless integration without disrupting ongoing services. The paper addresses this by proposing an incremental re-quantization approach. Instead of fully re-quantizing the model each time a new task is added, which would cause significant downtime and resource consumption, the system performs incremental updates, leveraging previously computed data to minimize the overhead. This allows the system to adapt to changing workloads without requiring a complete restart. The authors further claim that this approach maintains stability and avoids compromising the online service quality during dynamic task addition. The efficiency and stability of this approach are key to the practicality of a multi-task LLM serving system, and this feature is highlighted as a significant improvement over existing systems that lack the capacity for dynamic task management.
Multi-task Sched#
In a multi-task LLM serving system, efficient scheduling is crucial. A thoughtful multi-task scheduler should dynamically adapt to varying workloads, considering not only the number of tasks but also their individual resource demands (e.g., memory, processing time). Prioritizing tasks based on predicted output length, potentially using a strategy like Shortest Remaining Time First (SRTF), can significantly reduce average latency and improve throughput. The scheduler also needs to effectively manage resources, especially GPU memory, by grouping related tasks to minimize frequent context switching between LoRA adapters. Handling dynamic task addition without service disruption is also critical; the system should gracefully integrate new tasks by efficiently updating the scheduling logic and resource allocation. Finally, a sophisticated scheduler might implement mechanisms to mitigate starvation and ensure fair resource distribution among all tasks, avoiding situations where some tasks are consistently delayed.
Future Research#
Future research directions stemming from this paper could explore robustness to adversarial attacks within the multi-task framework, ensuring the system’s resilience against malicious inputs. Another crucial area is fairness and bias mitigation, investigating techniques to ensure equitable performance across diverse tasks and prevent amplification of biases present in the training data. Furthermore, scalability to extremely large language models and a broader range of tasks beyond those currently tested would be valuable. Finally, research into more sophisticated scheduling algorithms that optimize for diverse task characteristics and resource constraints, potentially incorporating reinforcement learning approaches, could significantly improve system efficiency and performance. Exploring alternative quantization methods and their integration with the proposed framework could lead to further memory efficiency and throughput gains.
More visual insights#
More on figures
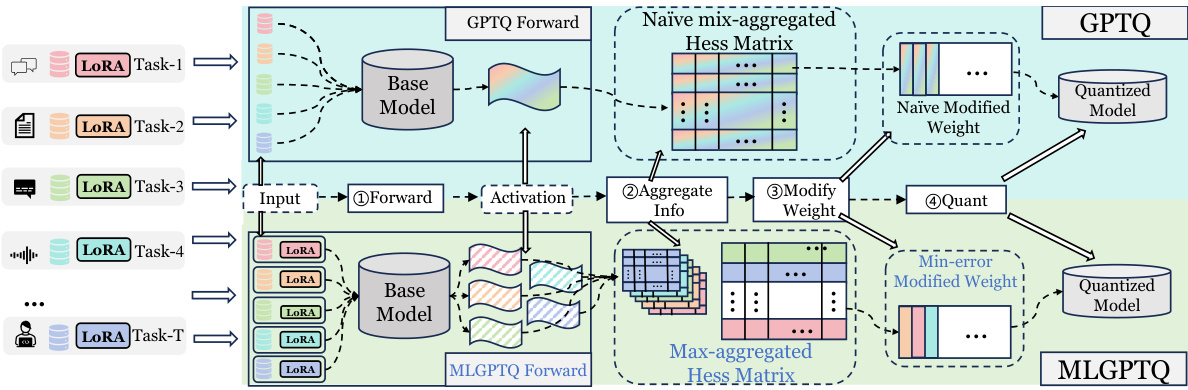
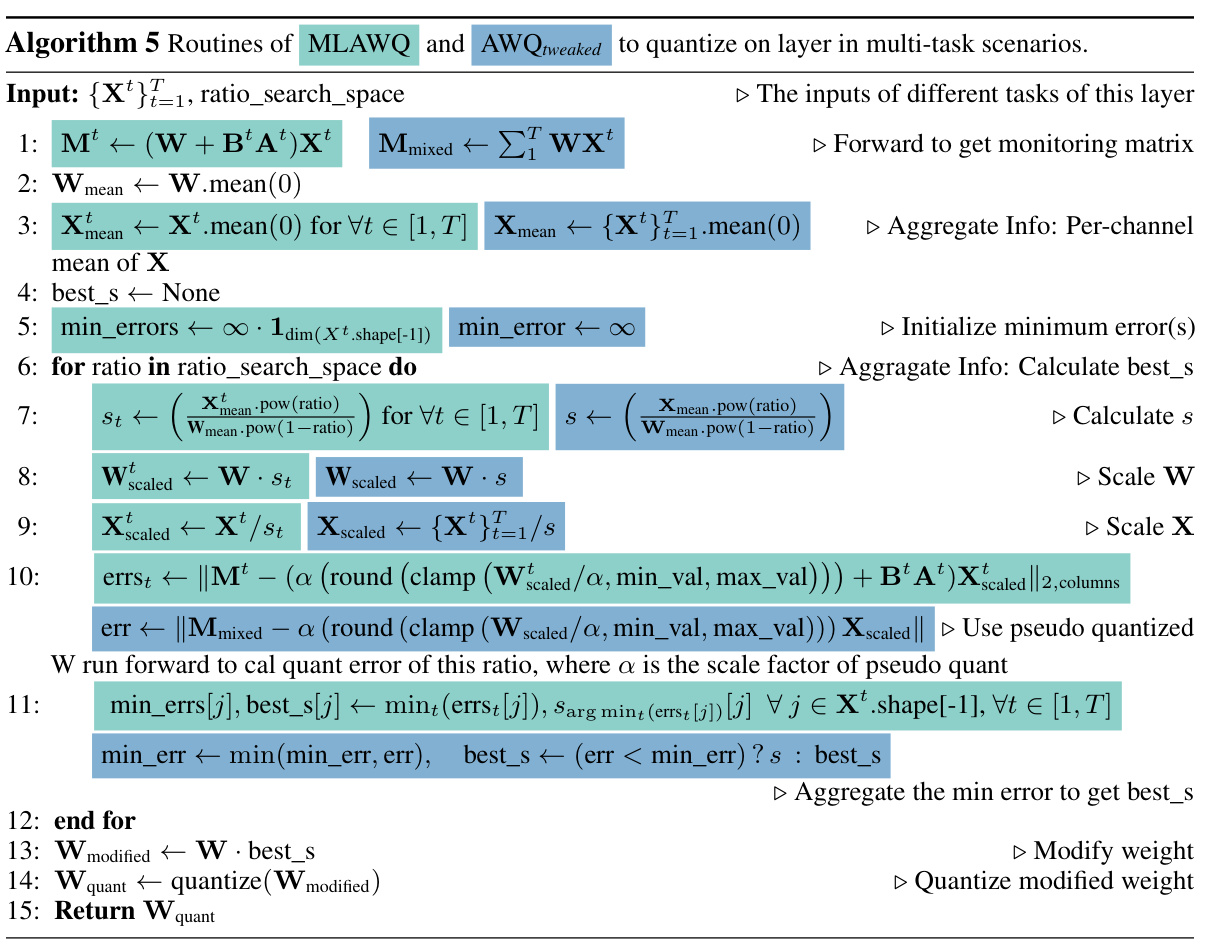
This figure compares the multi-task quantization algorithm MLGPTQ with the single-task GPTQ algorithm. Both algorithms follow a four-step process: Forward, Aggregate Info, Modify Weight, and Quant. The key difference is in how they handle multiple tasks. GPTQ uses a naive mix-aggregated Hessian matrix, which dilutes task-specific information. In contrast, MLGPTQ uses a max-aggregated Hessian matrix, which effectively captures and highlights critical information for each task, leading to better accuracy.
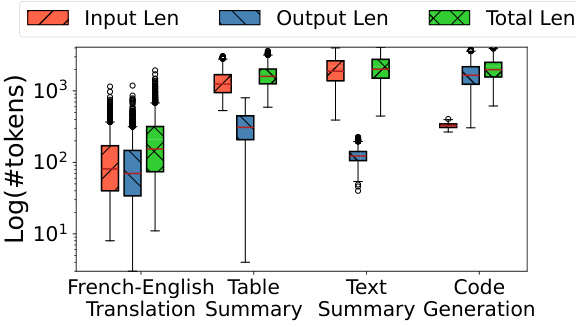
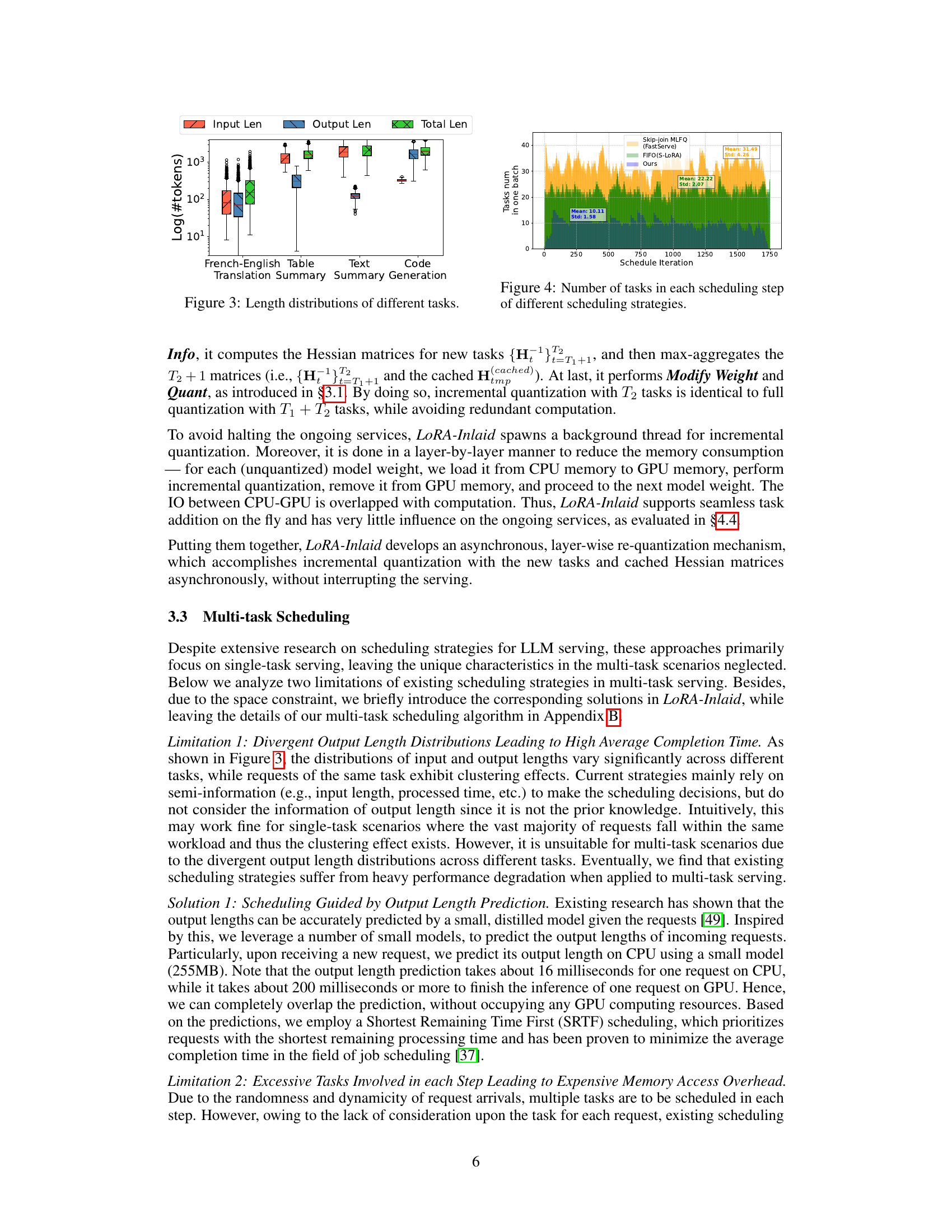
The figure shows the distribution of input length, output length, and total length (input+output) for four different tasks: French-English Translation, Table Summary, Text Summary, and Code Generation. The y-axis is the log (base 10) of the number of tokens, and the x-axis shows the task type. Each task has boxplots showing the distribution of lengths for each type. The boxplots illustrate the variability in sequence lengths for different tasks, highlighting the challenges for efficient scheduling in multi-task LLM serving systems.

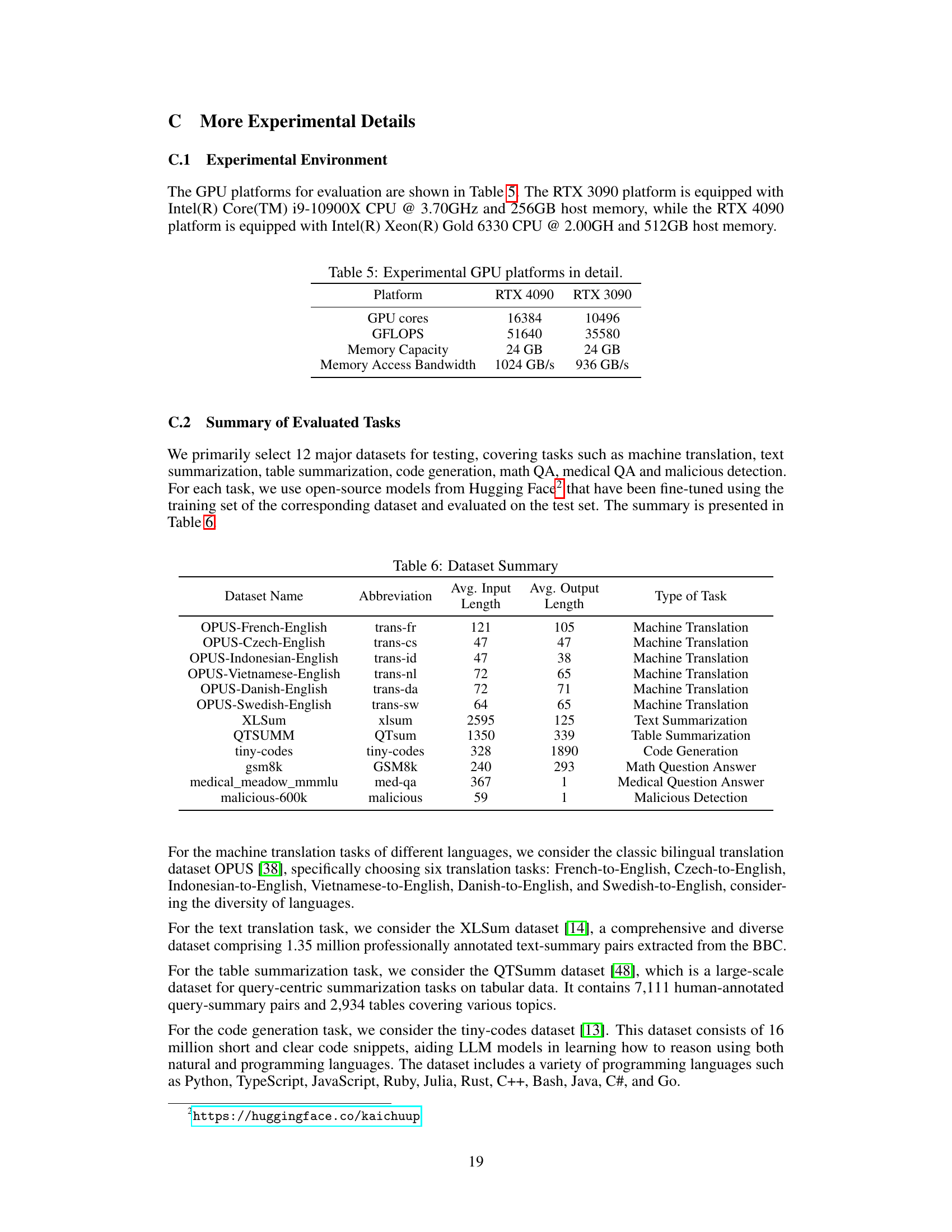
The figure shows the number of tasks processed in each scheduling step by three different scheduling strategies: Skip-join MLFQ (FastServe), FIFO (S-LORA), and the proposed LoRA-Inlaid approach. LoRA-Inlaid consistently processes a significantly smaller number of tasks per step compared to the baselines, leading to more efficient memory management and reduced swapping overhead. The mean and standard deviation of the number of tasks per step are shown for each strategy.
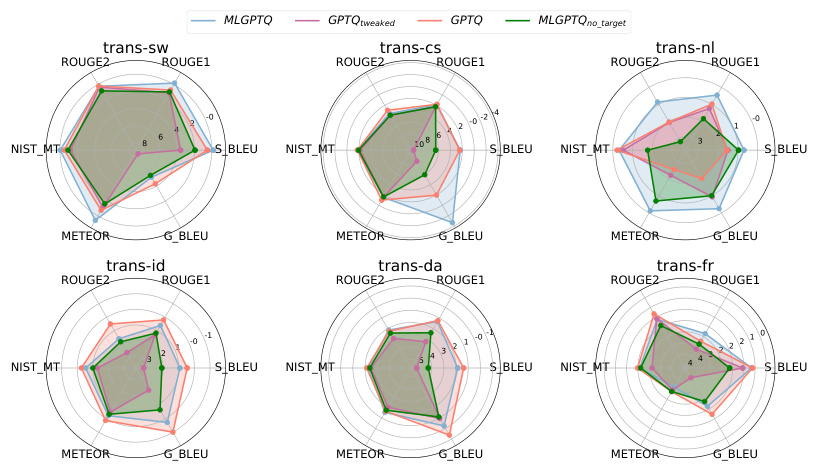
This figure presents a comparison of different quantization methods’ effectiveness in maintaining model accuracy across various machine translation tasks. Each radar chart represents a specific translation task (e.g., trans-sw, trans-cs, etc.), comparing the relative accuracy drops of four methods: MLGPTQ, GPTQtweaked, GPTQ, and MLGPTQno_target, against a baseline of unquantized models. The outer the data point is on the radar chart, the better is the method’s performance relative to the baseline in that specific metric. Each axis of the radar chart displays a different metric (ROUGE2, ROUGE1, NIST MT, S_BLEU, METEOR, G_BLEU) commonly used in machine translation evaluation. The figure’s goal is to illustrate that MLGPTQ effectively minimizes accuracy loss compared to other methods, highlighting the importance of its multi-task approach.
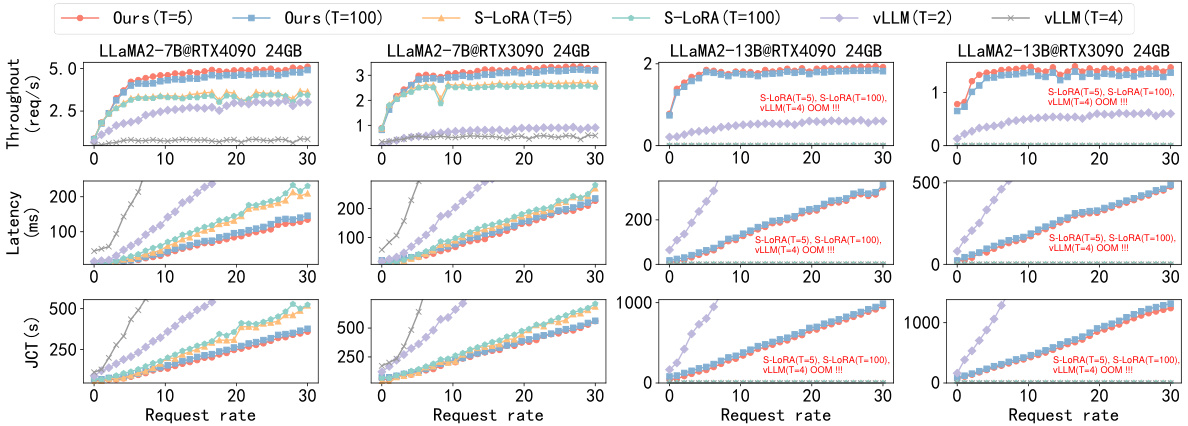
This figure shows the performance comparison of LoRA-Inlaid against S-LORA and vLLM in terms of throughput, latency, and job completion time (JCT). The performance is evaluated under different request rates and varying numbers of tasks. It highlights the superior performance of LoRA-Inlaid across various conditions.
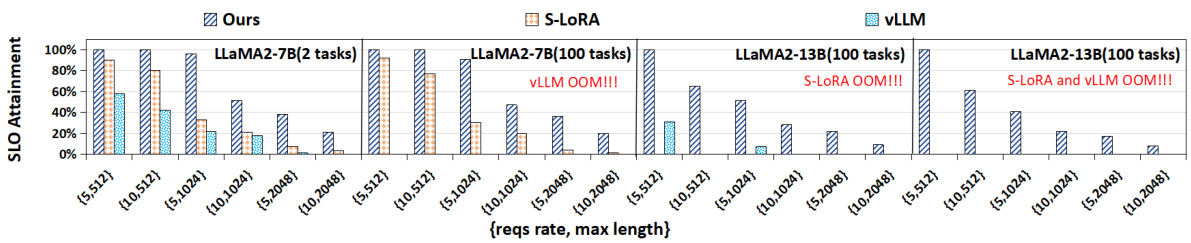
This figure displays the SLO attainment under different serving loads for three LLM serving systems: LoRA-Inlaid, S-LORA, and vLLM. The x-axis represents combinations of request rates and maximum sequence lengths. The y-axis shows the percentage of requests completed within the expected latency (SLO). The figure shows that LoRA-Inlaid consistently outperforms S-LORA and vLLM across all load conditions, and that S-LORA and vLLM experience a significant drop in SLO attainment at higher loads. The results highlight LoRA-Inlaid’s ability to maintain high performance and efficiency under various load conditions.

The left part of the figure shows the ablation study of the multi-task scheduling strategies proposed in the paper. Different scheduling strategies are compared based on SLO attainment with LLaMA2-7B and LLaMA2-13B models and 100 tasks. The right part shows the effectiveness of quantization on SLO attainment by comparing LoRA-Inlaid with and without quantization, along with S-LORA. LLaMA2-13B is excluded from the right graph because the other methods caused out-of-memory (OOM) errors.

This figure provides a high-level overview of the LoRA-Inlaid system architecture. It shows the main components and the workflow, highlighting the joint quantization process, dynamic task addition module, and the multi-task scheduling strategy. The diagram visually represents how the system handles multiple tasks concurrently, quantizes the base model efficiently, and adds new tasks without service interruption.

This figure shows a high-level overview of the LoRA-Inlaid system architecture. The system starts by jointly quantizing a base model and multiple LoRA adapters. Then, it uses a multi-task scheduling strategy to efficiently serve requests from multiple tasks. The system also includes a mechanism for dynamically adding new LoRA adapters as needed, allowing the system to adapt to changing workload demands without interruption.
This figure shows a high-level overview of the LoRA-Inlaid system architecture. It illustrates the different stages of the process, starting with joint quantization and deployment, moving to the online inference phase, which utilizes a multi-task scheduling strategy. The figure also highlights the dynamic task addition module, enabling the system to incorporate new tasks on-the-fly without disrupting existing services.
More on tables
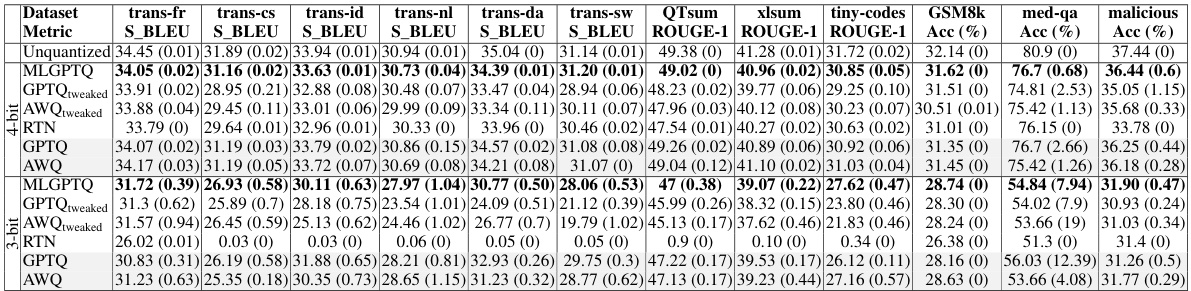
This table presents the results of comparing different model quantization techniques across twelve different tasks. The metrics used to evaluate the models are BLEU scores (for translation tasks), ROUGE scores (for summarization tasks), and accuracy (for other tasks). The table highlights that the proposed MLGPTQ method outperforms other methods in terms of model quality, especially when considering the limited memory constraints often associated with multi-task learning. The gray shading of the GPTQ and AWQ rows indicates that these methods were unable to share a quantized model across different tasks.

This table compares several LLM serving systems based on four key features: whether they support multi-task serving, multi-task quantization, dynamic task addition, and multi-task scheduling. It highlights the capabilities of each system, showing which features are supported (X) and which are not.
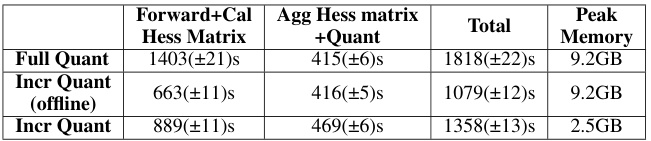
This table shows a breakdown of the time it takes to perform different quantization methods. The three methods compared are: Full Quant (performing full quantization), Incr Quant (offline) (performing incremental quantization offline), and Incr Quant (performing incremental quantization online). The time is broken down into the time it takes to perform forward and calculate the Hessian matrix, the time it takes to aggregate the Hessian matrix and perform quantization, and the total time for the entire process. The peak memory used is also given. The online incremental approach shows a significant reduction in total time and peak memory compared to the offline and full quantization.

This table compares several LLM serving systems across four key features: multi-task serving, multi-task quantization, dynamic task addition, and multi-task scheduling. It shows whether each system supports these capabilities, highlighting the unique capabilities of the LoRA-Inlaid system proposed in the paper.
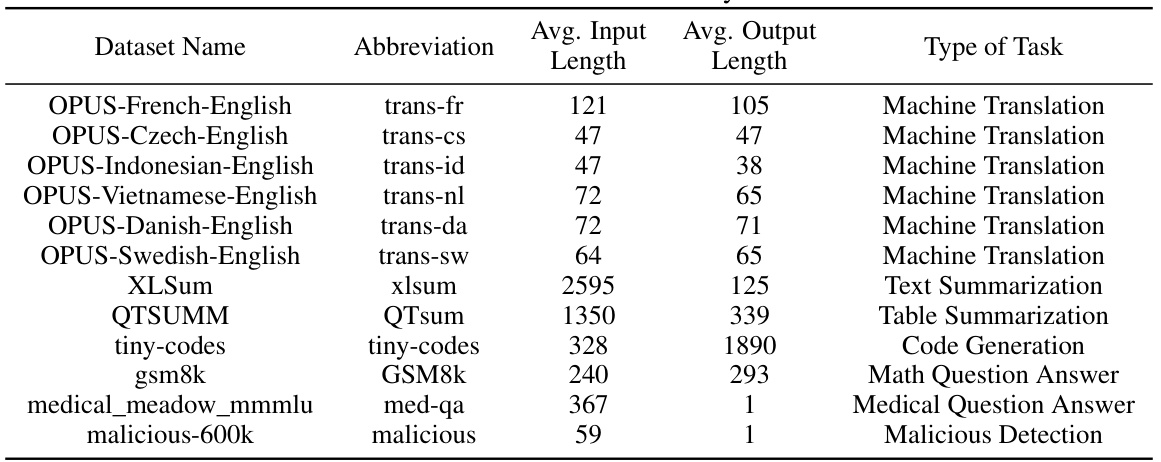
This table compares various LLM serving systems based on their support for multi-tasking, model quantization, dynamic task addition, and multi-task scheduling. It highlights the unique capabilities of LoRA-Inlaid, the system introduced in the paper, by showing its comprehensive support for all four features, unlike other systems that only partially support these functionalities.
Full paper#