↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Model-based reinforcement learning (MBRL) shows promise in efficient policy optimization. However, a major challenge is the world model’s limited capacity, easily overwhelmed by distracting details that are easily predictable but irrelevant to the learning process. Existing methods struggle to address this issue, especially with intricate but ultimately useless details.
Policy-Shaped Prediction (PSP) directly tackles this problem. By using a pretrained segmentation model and policy gradients, PSP focuses the world model’s attention on important parts of the environment. A novel action prediction head further enhances this by mitigating distractions stemming from the agent’s own actions. PSP significantly outperforms other approaches, demonstrating improved robustness in various scenarios without compromising performance in distraction-free environments. This advancement is crucial for creating more efficient and reliable model-based reinforcement learning agents.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical vulnerability in model-based reinforcement learning (MBRL): the susceptibility of world models to irrelevant details. This is a significant step towards more robust and efficient MBRL, impacting various fields using AI agents, and opening avenues for improved model explainability and learning algorithms.
Visual Insights#
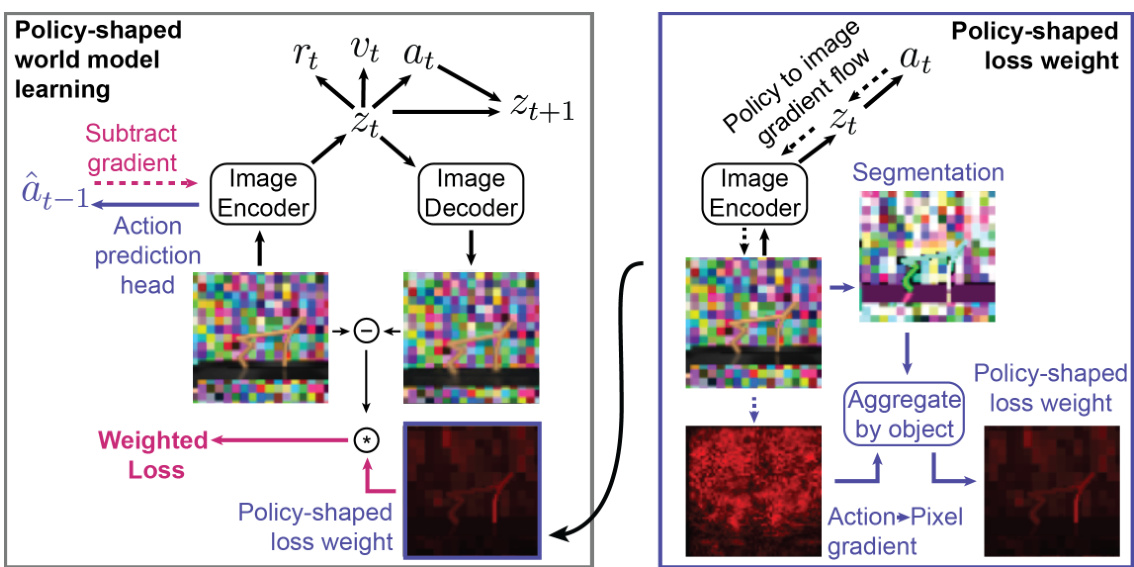
The figure illustrates the architecture of Policy-Shaped Prediction (PSP). The left panel shows how the standard DreamerV3 model is modified by adding an action prediction head and a policy-shaped loss weighting mechanism. The action prediction head helps mitigate distractions caused by the agent’s own actions. The policy-shaped loss weighting focuses learning on important parts of the image. The right panel shows how image segmentation and gradient aggregation refine the loss weighting process, focusing the model’s capacity on task-relevant information.
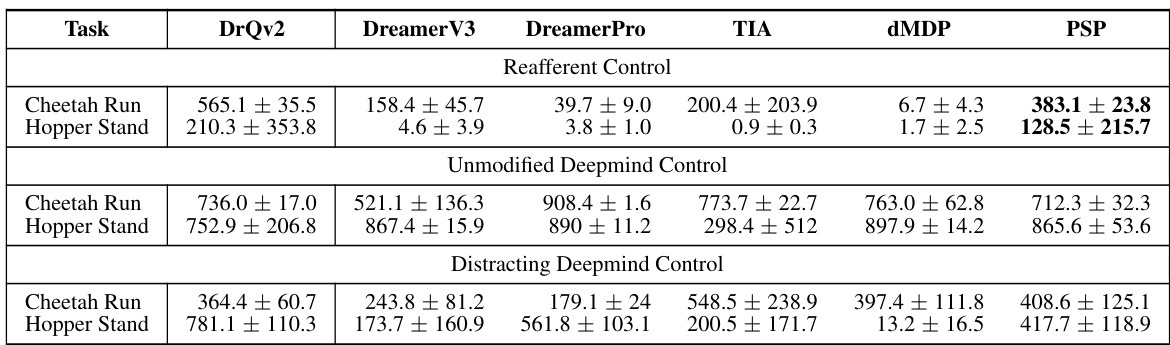
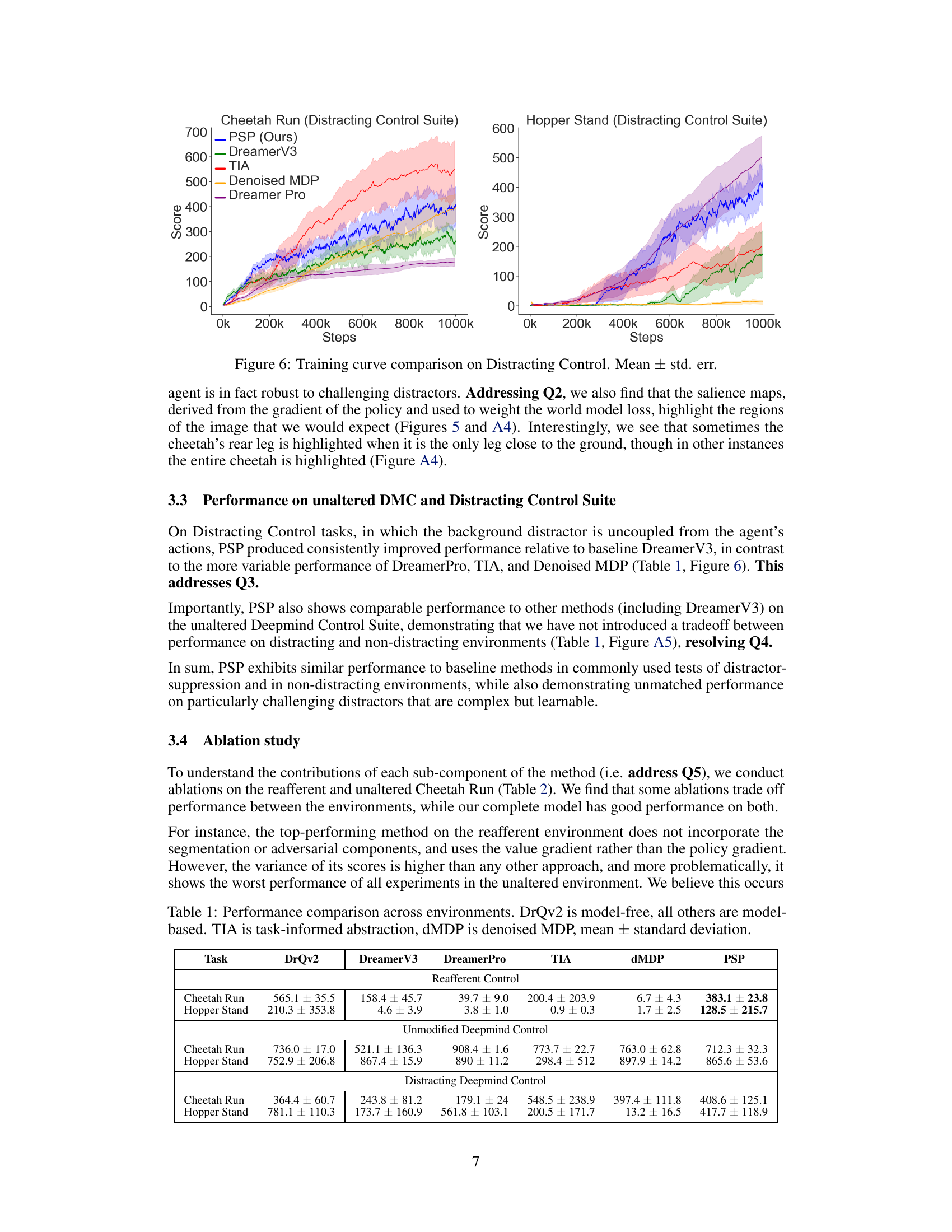
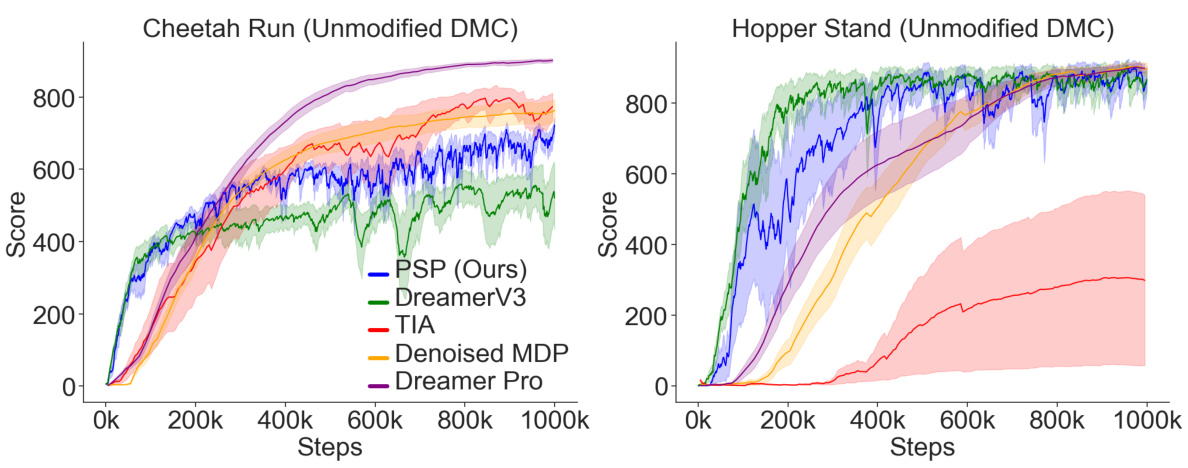
This table compares the performance of different model-based reinforcement learning (MBRL) agents and one model-free agent (DrQv2) across three different environments: Reafferent DeepMind Control, Unmodified DeepMind Control, and Distracting DeepMind Control. For each environment, the table shows the average scores achieved by each agent on two tasks: Cheetah Run and Hopper Stand. The scores represent the performance of the agents in each environment and task, showing their mean and standard deviation across multiple runs. The table highlights the relative performance of PSP against existing MBRL methods, particularly in challenging environments with distractions.
In-depth insights#
Policy-Shaped MBRL#
Policy-shaped Model-Based Reinforcement Learning (MBRL) addresses a critical weakness in standard MBRL: the tendency for world models to waste capacity on irrelevant details. Standard MBRL often struggles with distractions, focusing on predictable but unimportant aspects of the environment at the expense of crucial information for effective policy learning. Policy-shaped methods directly address this by leveraging the policy gradient to guide the world model’s learning process. By weighting the reconstruction loss based on the policy gradient, the model prioritizes learning aspects of the environment directly relevant to achieving the task’s objective, effectively filtering out distractions. This approach enhances sample efficiency and robustness by ensuring the model focuses its limited capacity on truly impactful environmental factors. The success of this approach relies on the ability to effectively identify and weight relevant information, requiring advanced techniques such as segmentation models to isolate object-level details and adversarial training to mitigate the impact of self-generated distractions. The ultimate goal is improved generalization and robustness, making MBRL methods less susceptible to the confounding influence of irrelevant details in complex environments.
Distraction Robustness#
The concept of distraction robustness in model-based reinforcement learning (MBRL) is crucial for real-world applications. The paper highlights that existing MBRL methods struggle with scenarios where highly predictable but irrelevant details overwhelm the model’s capacity, hindering learning of the actual task. Existing methods often rely on structural regularizations or pretraining, but these can be ineffective against complex, learnable distractors. The proposed method, Policy-Shaped Prediction (PSP), tackles this by focusing the model’s capacity on task-relevant information, synergistically using a pre-trained segmentation model, a task-aware loss, and adversarial learning to filter out distractions. PSP’s performance significantly surpasses existing methods, especially in environments with intricate, learnable distractors. The success of PSP suggests that actively shaping the model’s focus based on the policy’s needs is a highly effective approach to distraction robustness, moving beyond passive filtering techniques. This demonstrates a significant step forward in making MBRL more resilient and applicable to complex, real-world settings.
Object-Based Loss#
An object-based loss function in model-based reinforcement learning (MBRL) aims to improve learning efficiency and robustness by focusing the model’s learning on the most relevant parts of the input data. Instead of treating the entire image uniformly, it identifies and weighs image regions based on their importance to the task, often leveraging segmentation techniques. This selective weighting prioritizes relevant objects, reducing the model’s sensitivity to distracting or irrelevant details. The core idea is to assign higher weights to image regions strongly correlated with the agent’s actions and rewards, and lower weights to areas like backgrounds that are largely irrelevant. This approach helps to prevent the model from wasting capacity on insignificant details, leading to better generalization and more efficient learning. A potential drawback is the need for an effective segmentation model, but advancements in this field (e.g., Segment Anything Model) make object-based loss increasingly feasible. The loss function design should also carefully balance the emphasis on relevant and irrelevant elements to avoid the model ignoring crucial context while effectively focusing learning. Overall, object-based loss holds significant promise for creating more robust and sample-efficient MBRL agents.
Adversarial Learning#
Adversarial learning, in the context of this research paper, is a crucial technique used to enhance the world model’s robustness and efficiency. By introducing an adversarial action prediction head, the model learns to differentiate between sensory inputs generated by its own actions and those originating from the external environment. This is a clever approach inspired by biological mechanisms (efference copies), preventing the model from wasting capacity on redundant information. The effectiveness of this approach is demonstrated by improved performance, particularly in challenging environments with learnable distractions. The adversarial training process forces the model to learn more efficient representations, focusing its capacity on task-relevant features. This ultimately contributes to better policy learning and overall improved robustness of the model-based reinforcement learning (MBRL) system. The success of this technique highlights the power of incorporating biologically inspired designs into AI systems. The focus is shifted towards learning truly relevant features, leading to data efficiency and enhanced generalization abilities. This adversarial component works in synergy with other techniques such as a pre-trained segmentation model and task-aware reconstruction loss to create a more holistic and effective approach to distraction mitigation in MBRL.
Future of PSP#
The future of Policy-Shaped Prediction (PSP) looks promising, with several avenues for improvement and expansion. Improving segmentation is key; exploring more advanced, efficient models beyond SAM could significantly boost performance and reduce computational overhead. Incorporating temporal information is crucial for handling real-world scenarios, where distractions aren’t static. Adapting PSP to work with video data directly and better handling long-term dependencies would enhance its applicability to dynamic environments. Addressing the limitations of the object-centric approach is also vital; exploring techniques that handle non-object-based distractions and complex scene interactions more effectively is necessary for wider applicability. Integrating with other MBRL methods could also lead to further advancements, creating hybrid approaches that benefit from PSP’s focus and other methods’ strengths. Finally, thorough testing and validation in more diverse and complex real-world settings will be needed to confirm PSP’s robustness and practical impact. Research should focus on these key areas to unlock PSP’s full potential in more challenging and realistic applications.
More visual insights#
More on figures
This figure illustrates the core idea behind Policy-Shaped Prediction (PSP). The left panel shows how a modified DreamerV3 architecture is trained. A new action prediction head helps mitigate distractions caused by the agent’s own actions, and the reconstruction loss is weighted based on the gradient of the policy w.r.t. the image. The right panel shows how this weighting is computed using image segmentation to focus on task-relevant parts of the image.
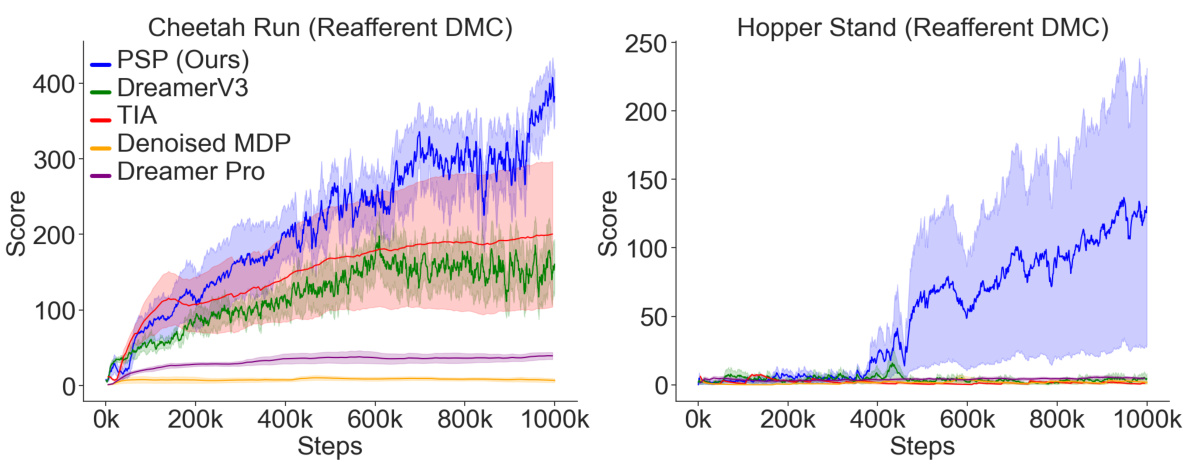
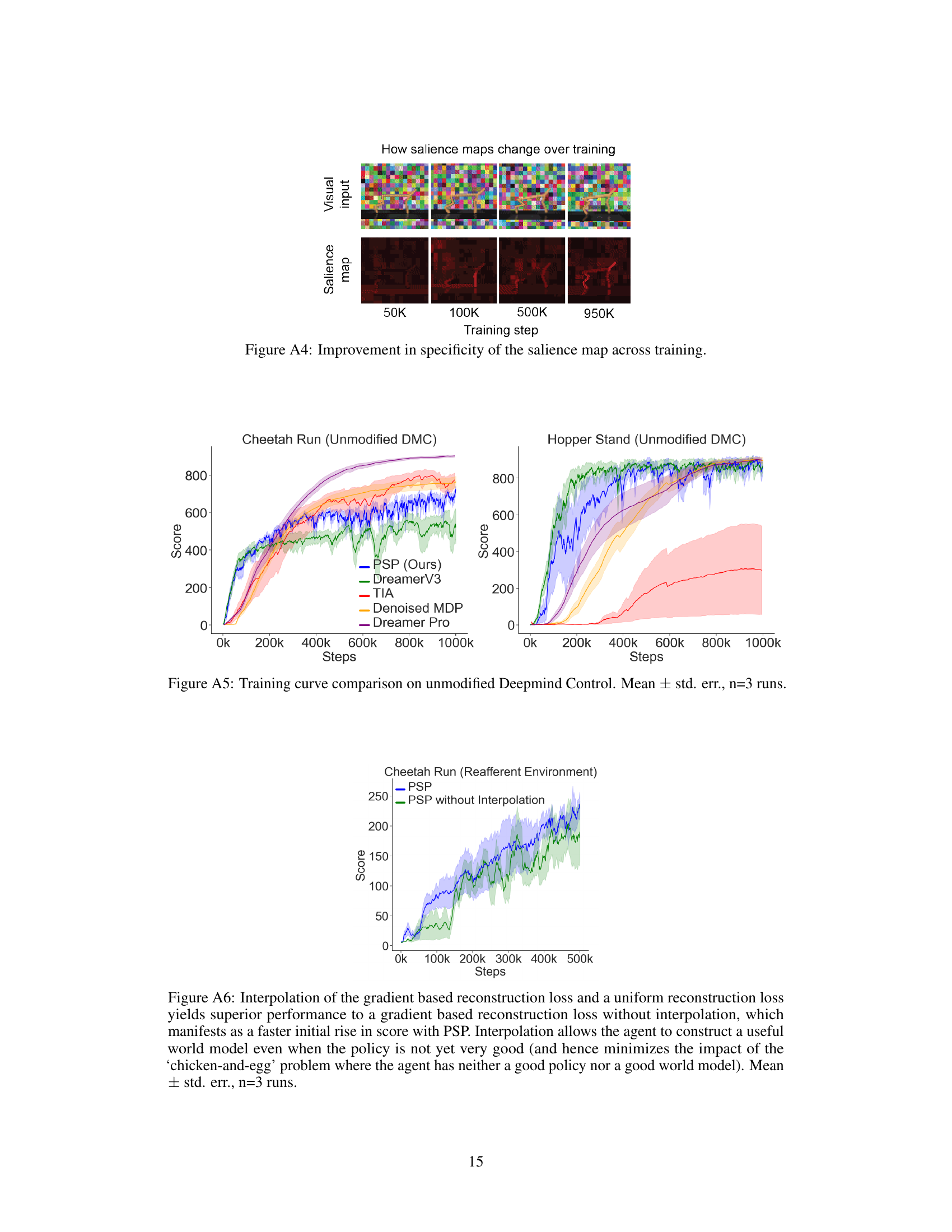
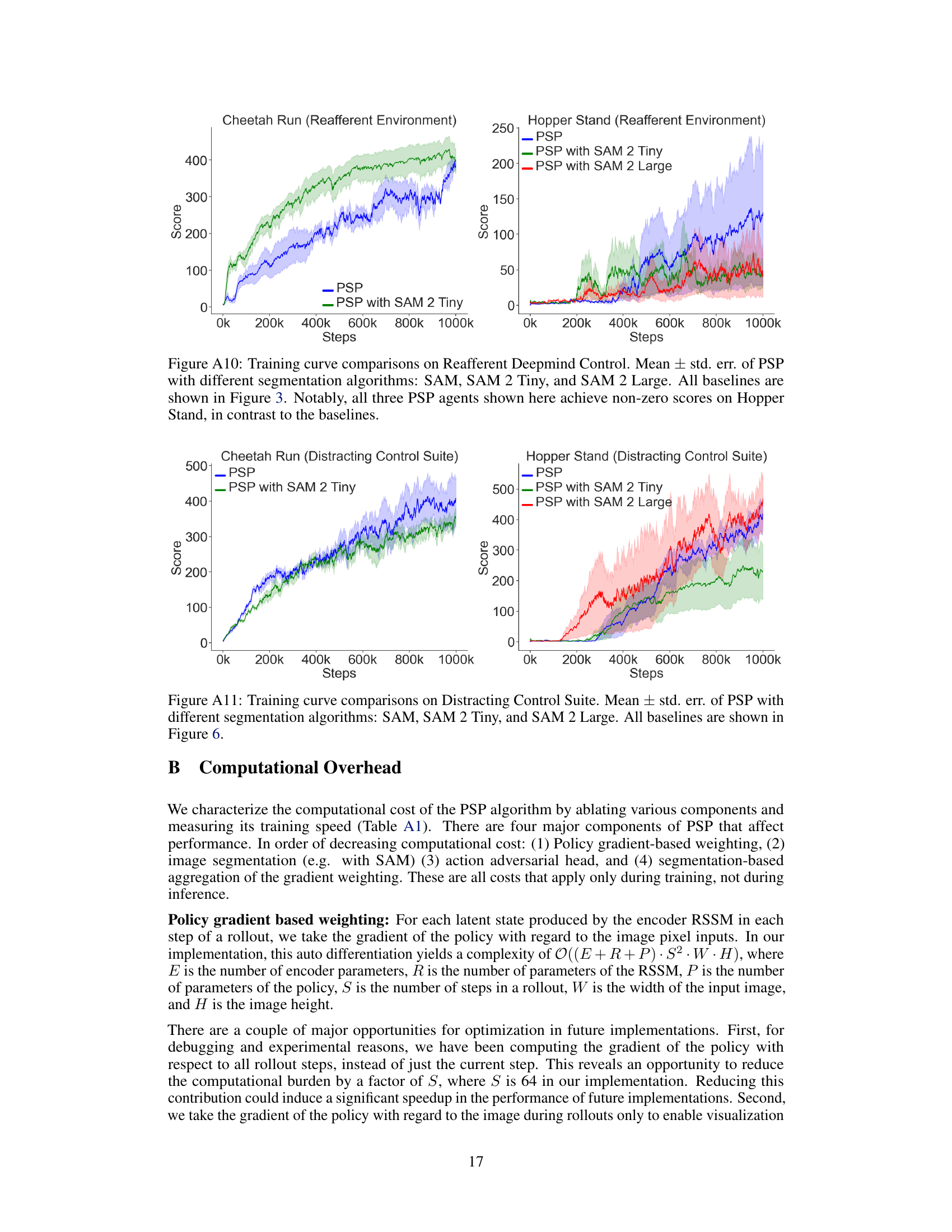
This figure displays the training curves for different model-based reinforcement learning (MBRL) agents on the Reafferent DeepMind Control Suite. The Reafferent environment introduces learnable but irrelevant distractions to challenge the agents’ ability to focus on important information. The figure showcases the performance of the proposed method (PSP) in comparison to several baselines, including DreamerV3, Task Informed Abstractions (TIA), Denoised MDP, and DreamerPro. The results demonstrate that PSP significantly outperforms the baselines in handling the distractors while maintaining similar performance in non-distracting environments. The y-axis represents the score achieved by the agents, and the x-axis shows the number of training steps taken.

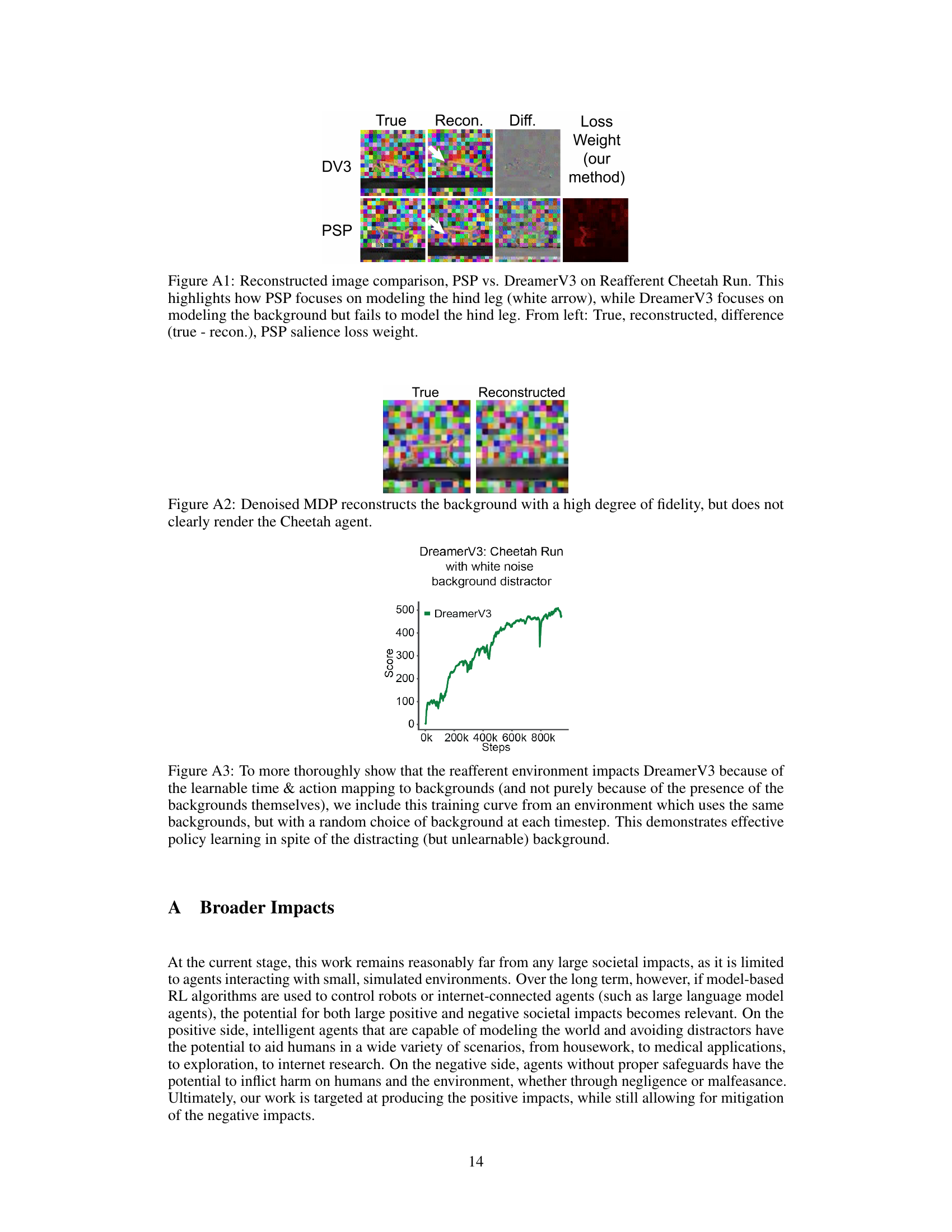
This figure compares the image reconstruction quality of DreamerV3 and the proposed method, PSP, on the Reafferent Cheetah Run environment. DreamerV3 accurately reconstructs the background but fails to accurately reconstruct the cheetah’s hind leg, demonstrating its susceptibility to distractions. PSP, in contrast, successfully focuses on the relevant parts of the image, resulting in a much more accurate reconstruction of the agent.

This figure illustrates the modifications made by the Policy-Shaped Prediction (PSP) method to the DreamerV3 architecture. The left side shows the training process modifications: a new action prediction head is added to reduce the impact of self-linked distractions, and a policy-shaped loss weight is calculated and applied to the loss. The right side shows how this loss weight is generated using the gradient of the policy and image segmentation to focus the model on task-relevant parts of the image.
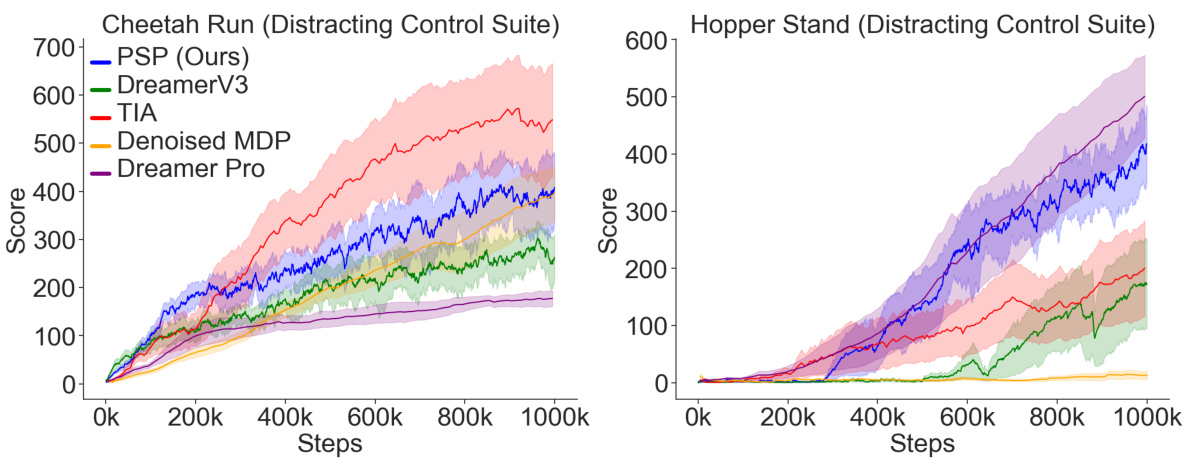
This figure compares the training performance of different model-based reinforcement learning (MBRL) agents on the Distracting Control Suite environment. The x-axis represents the number of training steps, and the y-axis represents the average score achieved by each agent. The figure shows that the proposed Policy-Shaped Prediction (PSP) method significantly outperforms other state-of-the-art MBRL methods in terms of robustness to distracting stimuli.

This figure compares the image reconstruction quality of DreamerV3 and PSP on a specific example from the Reafferent Cheetah Run environment. It shows that DreamerV3 accurately reproduces the distracting background but fails to accurately reconstruct the cheetah’s leg, indicating that it misallocates its capacity. In contrast, PSP successfully reconstructs the leg, demonstrating its ability to prioritize task-relevant information over distracting details. The salience map (loss weight) generated by PSP visually highlights the agent’s leg.

This figure compares the true image with the reconstructed image from a Denoised MDP model. The background is reconstructed with high fidelity, but the cheetah agent is not clearly rendered, indicating a failure of the model to focus on the task-relevant aspects of the image.
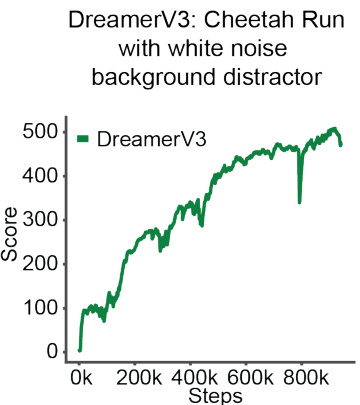
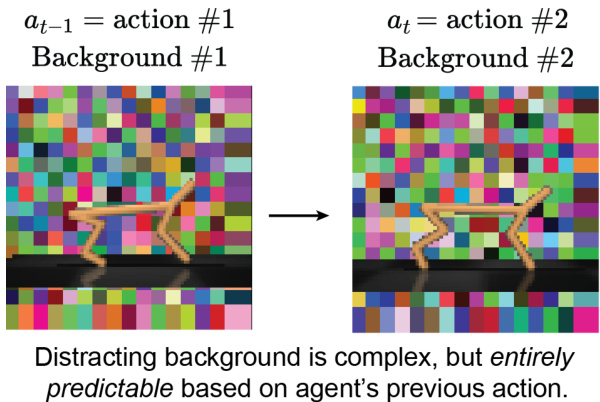
The figure shows a training curve for DreamerV3 agent on Cheetah Run task with a distractor. The distractor is white noise, which is randomly selected at each timestep, thus unlearnable by the agent. The goal is to demonstrate that the impact of the reafferent environment stems from the deterministic mapping of time and action to the backgrounds, not simply the presence of the distracting background itself.

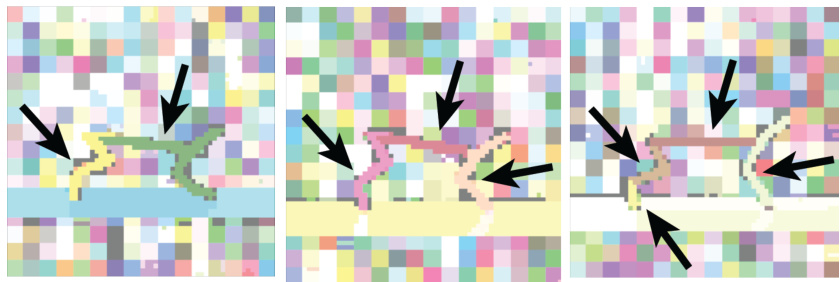
This figure shows how the salience maps, generated by the policy gradient, change over training. The top row shows the visual input at different training steps (50K, 100K, 500K, 950K). The bottom row shows the corresponding salience maps. As training progresses, the salience maps become increasingly focused on the agent, indicating that the model is learning to prioritize relevant information for policy learning. This shows that the method is learning to ignore the distracting information and focus on the relevant information that helps in making decisions.
This figure compares the training performance of different model-based reinforcement learning (MBRL) methods on the Reafferent DeepMind Control Suite. The Reafferent environment introduces highly predictable but irrelevant distractions to test the robustness of the algorithms. The plot shows the average score (mean ± standard error) of each algorithm over training steps. PSP (Policy-Shaped Prediction), the authors’ proposed method, is compared against several baselines designed to handle distractors, including DreamerV3, TIA (Task Informed Abstractions), Denoised MDP, and DreamerPro. The figure shows the training curves for two tasks: Cheetah Run and Hopper Stand.
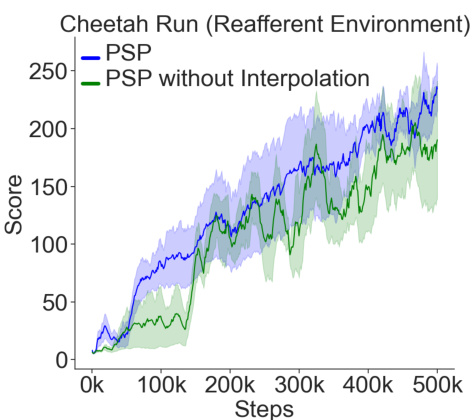
This figure shows the training performance curves for the Cheetah Run task in the Reafferent environment. Two versions of the Policy-Shaped Prediction (PSP) method are compared: one with and one without loss interpolation. The results demonstrate that incorporating loss interpolation leads to significantly improved performance, particularly during the initial stages of training. This highlights the benefit of preventing the world model from getting stuck in poor local minima by maintaining a balance between focusing on crucial information and reconstructing less important details.
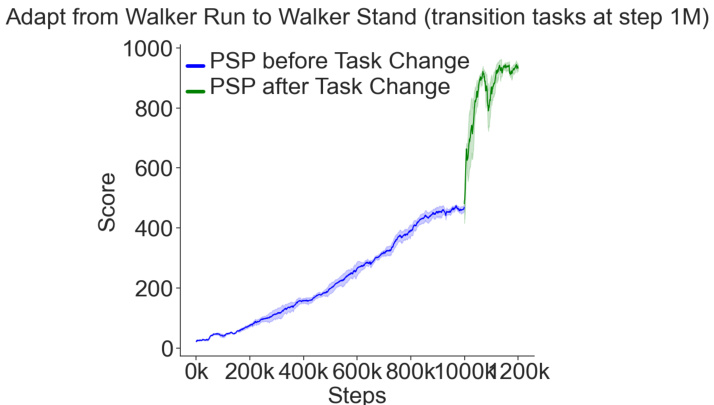
This figure shows the training performance of the Policy-Shaped Prediction (PSP) method on a task-switching scenario. Initially, the model is trained on the ‘Walker Run’ task of the Reafferent DeepMind Control Suite. At step 1 million, the task is switched to ‘Walker Stand’, while maintaining the same Reafferent background. The plot shows that the PSP agent quickly adapts to the new task, demonstrating its ability to transfer knowledge and adapt to changes in the task even with complex, predictable distractors. This highlights the robustness and adaptability of the PSP method.
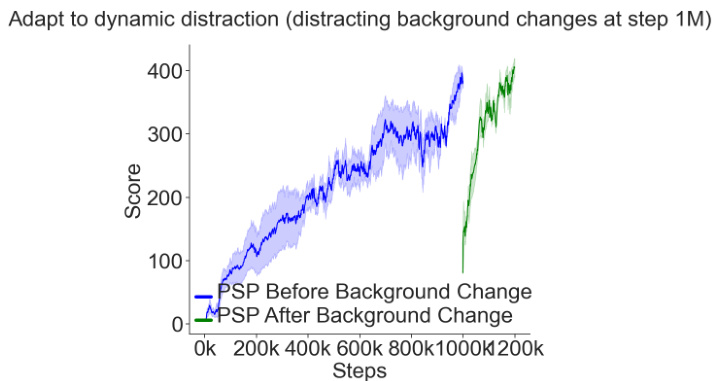
This figure shows the result of an experiment designed to test the adaptability of the Policy-Shaped Prediction (PSP) model to dynamic distractions. In this experiment, the background distractions in the Reafferent DeepMind Control environment were changed at step 1 million. The plot shows that the PSP model quickly adapts to the new distractions, demonstrating its robustness and adaptability.
This figure illustrates the Policy-Shaped Prediction (PSP) method. The left panel shows the modified DreamerV3 architecture, highlighting the addition of an action prediction head and policy-shaped loss weighting. The right panel details the process of calculating policy-shaped loss weights using image segmentation and gradients of the policy.
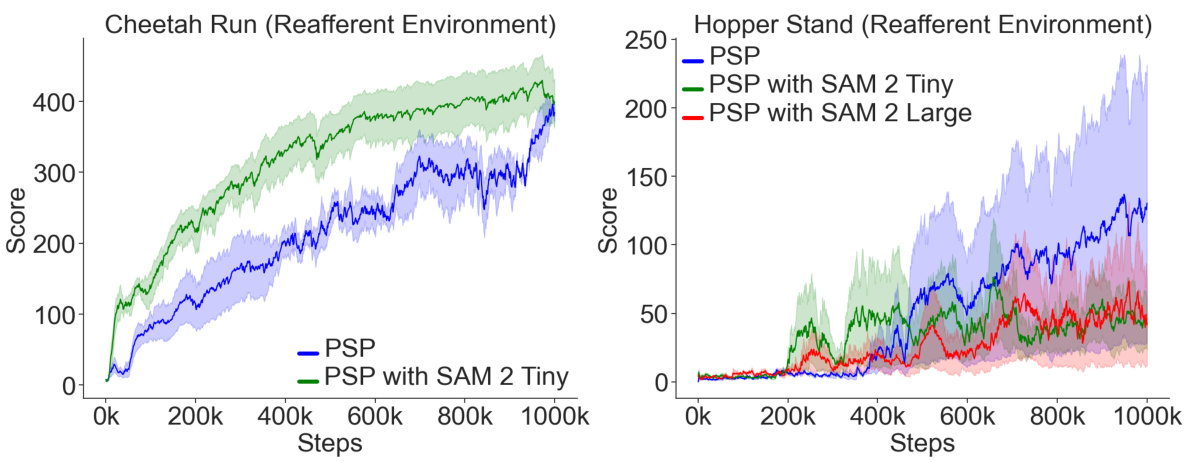
This figure compares the training curves of different model-based reinforcement learning (MBRL) agents on the Reafferent DeepMind Control Suite. The Reafferent environment introduces challenging distractors that are highly predictable but irrelevant to learning a good policy. The figure shows that the proposed Policy-Shaped Prediction (PSP) method significantly outperforms existing MBRL methods like DreamerV3, Task Informed Abstractions (TIA), Denoised MDP, and DreamerPro in this challenging environment. The y-axis represents the cumulative reward achieved during training (score), and the x-axis represents the number of training steps. Error bars show mean ± standard error.
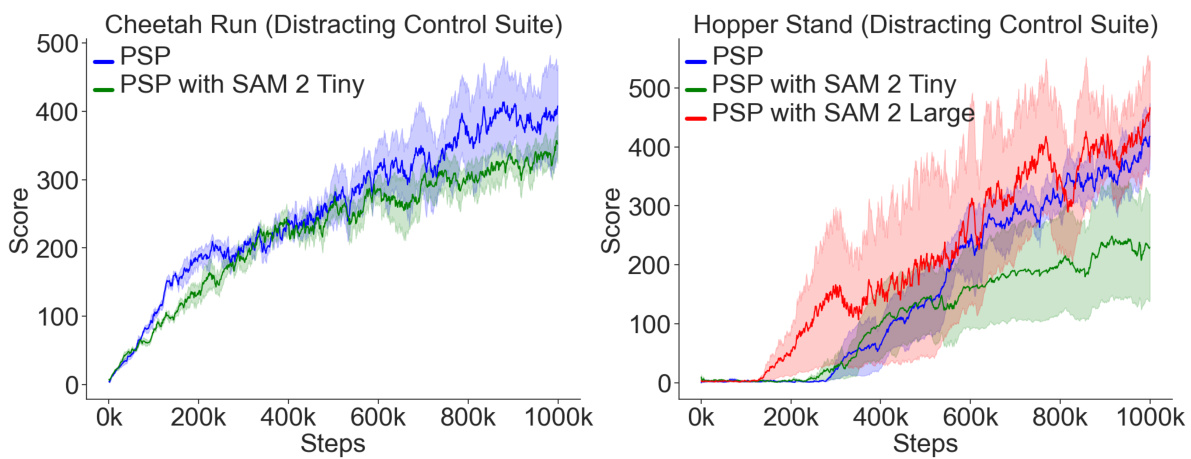
This figure compares the training performance of various model-based reinforcement learning (MBRL) agents on the Distracting Control Suite benchmark. The agents are trained on two tasks: Cheetah Run and Hopper Stand. The figure shows that PSP (ours) consistently outperforms other methods, including DreamerV3, TIA, Denoised MDP, and DreamerPro. The shaded areas represent standard error, indicating the variability of the results across multiple runs of each agent.
More on tables
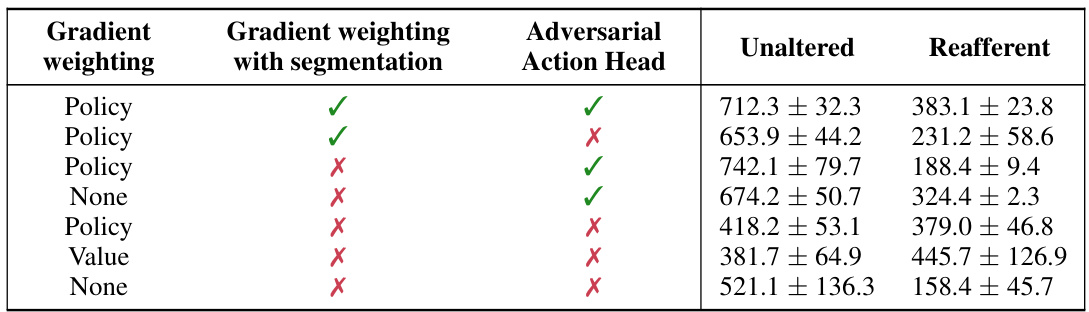
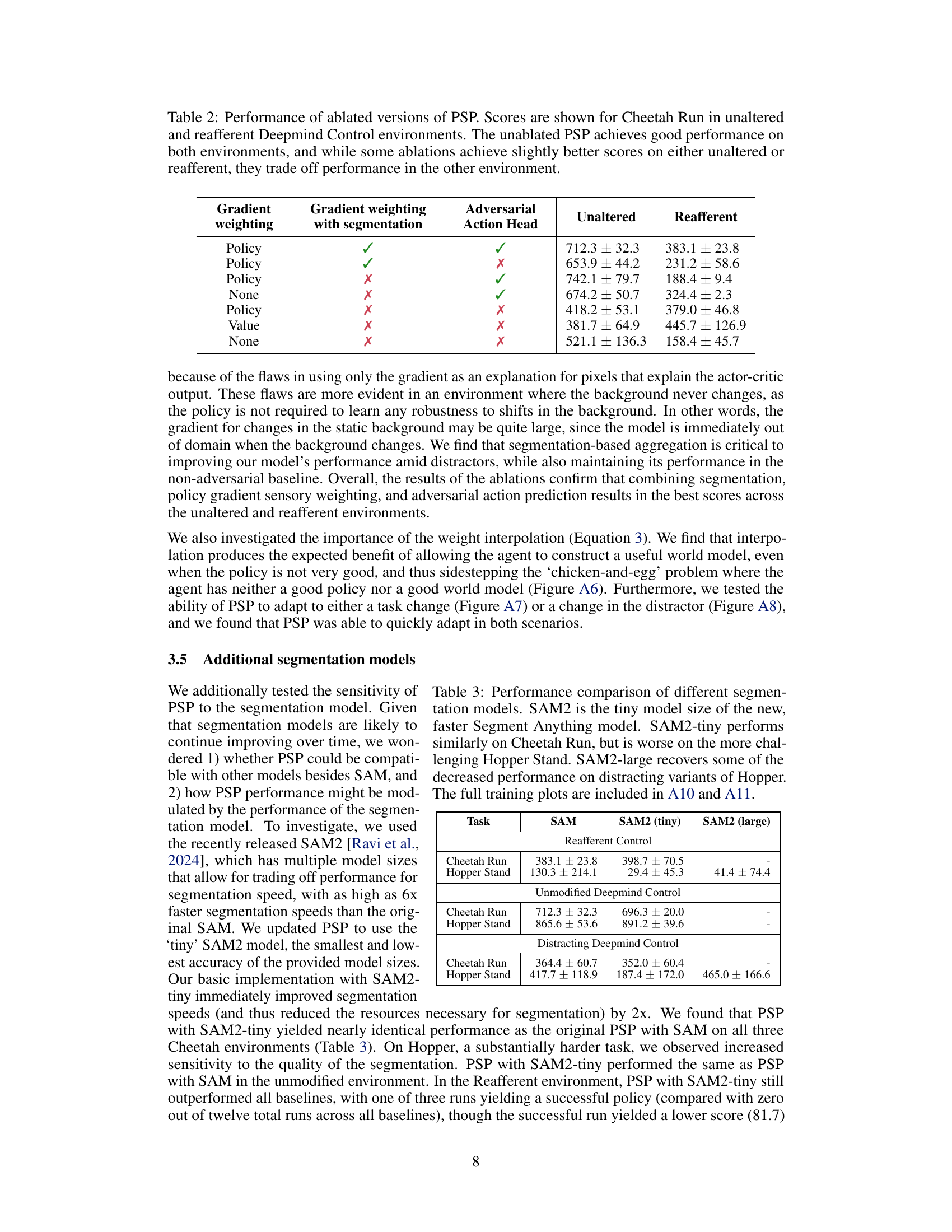
This table presents the results of an ablation study on the Policy-Shaped Prediction (PSP) method. It shows the performance of different versions of PSP, each lacking one or more components of the full method (gradient weighting, segmentation, and adversarial action head), on two environments: the standard DeepMind Control Suite and a modified version called Reafferent DeepMind Control. The results highlight the contribution of each component and demonstrate that the full PSP model achieves a good balance of performance across both environments.
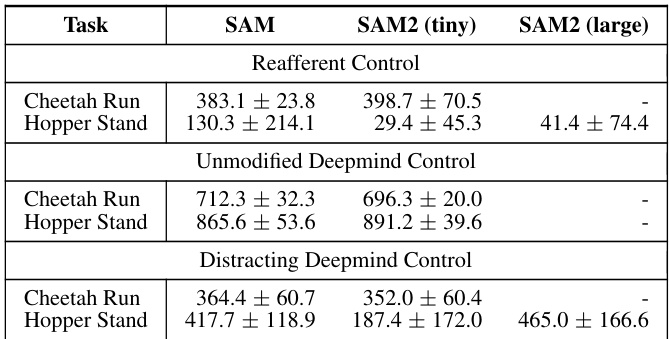
This table compares the performance of the proposed PSP method against several baselines (DreamerV3, TIA, Denoised MDP, DreamerPro, and DrQv2) across three different environments: Reafferent Deepmind Control, Unmodified Deepmind Control, and Distracting Deepmind Control. Each environment is tested on two tasks, Cheetah Run and Hopper Stand. The table shows the mean ± standard deviation of the scores achieved by each method on each task and environment. It highlights the superior performance of PSP, especially in the Reafferent Control environment, demonstrating its effectiveness in handling complex, learnable distractions.

This table presents a comparison of the computational overhead of different versions of the PSP algorithm. The various versions differ in terms of the inclusion of the adversarial action head, the use of the SAM segmentation model, the use of the policy-gradient weighting approach versus the Value-Gradient weighted Model loss (VaGraM), and the inclusion of the linear interpolation technique for loss weighting. The final column indicates the frames per second (FPS) achieved by each version of the algorithm.
Full paper#