↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
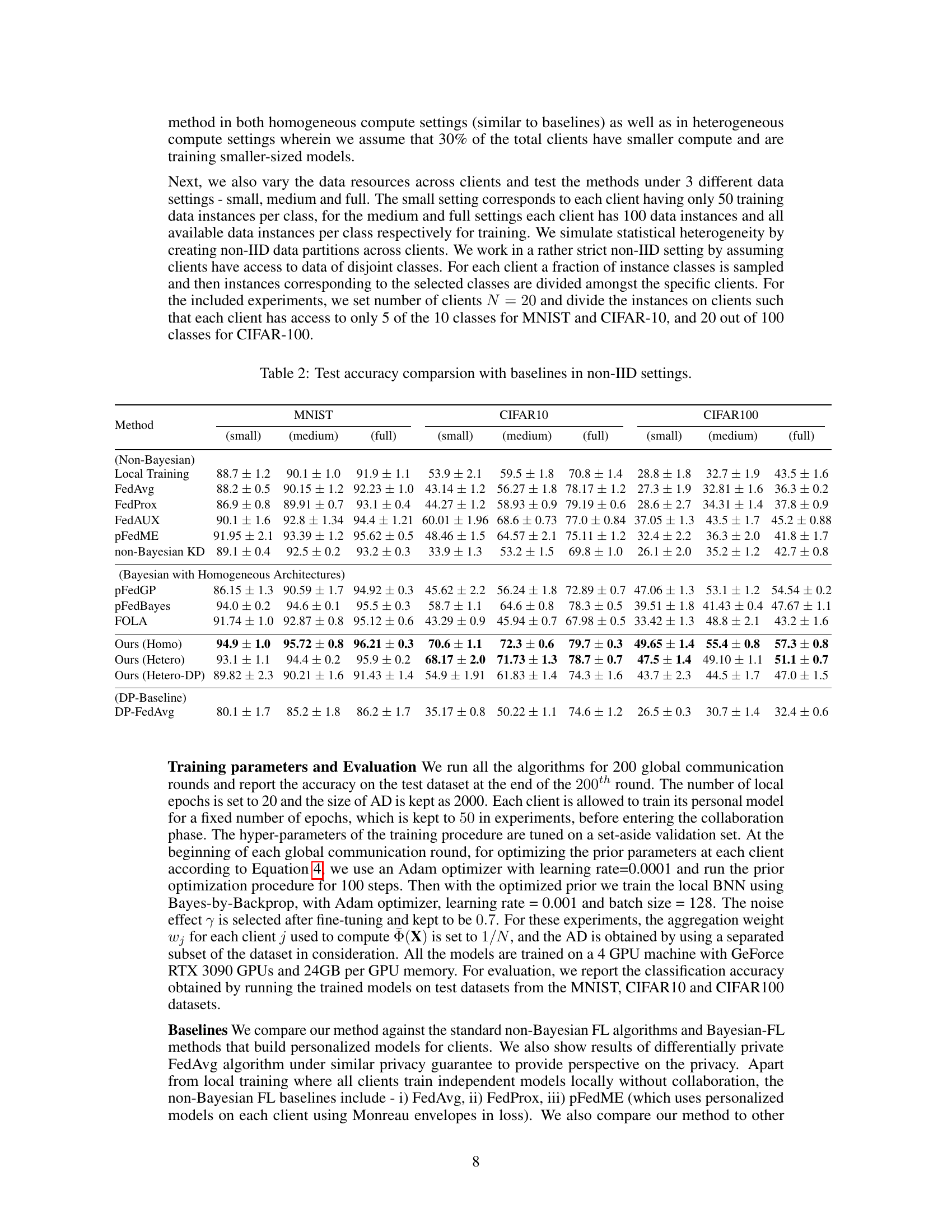
TL;DR#
Federated learning (FL) faces challenges from data heterogeneity and resource limitations among participating clients. Existing approaches often struggle with model training, overfitting, and privacy preservation in these diverse settings. This hinders the applicability of FL to real-world scenarios where data and computational resources are often unevenly distributed. Many existing solutions ignore such practical constraints, which severely limits their impact.
This paper introduces FedBNN, a novel personalized FL framework grounded in Bayesian learning. FedBNN trains personalized Bayesian models at each client tailored to their specific datasets, efficiently collaborating across clients using priors in the functional output space. This allows collaboration even with models of varying sizes and adapts well to heterogeneity. The paper also presents a differentially private version with formal privacy guarantees, demonstrating superior performance over baselines in both homogeneous and heterogeneous settings, while maintaining strong privacy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning because it addresses the key challenges of data heterogeneity and limited resources in a novel way. It introduces a framework that combines Bayesian learning with differential privacy, opening new avenues for developing robust and privacy-preserving collaborative learning methods, which are essential for many real-world applications.
Visual Insights#
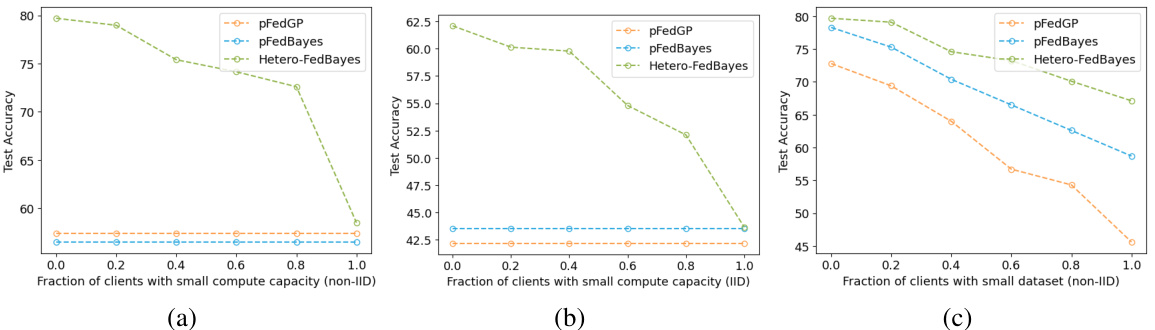
This figure compares the performance of the proposed method (FedBNN) against several baselines under various types of heterogeneity in an federated learning setting using the CIFAR-10 dataset. Three scenarios are presented: (a) heterogeneity in clients’ computational resources (non-IID data); (b) heterogeneity in clients’ computational resources (IID data); and (c) heterogeneity in the amount of data available to each client (non-IID data). The results demonstrate that FedBNN outperforms the baselines, particularly when clients have varying computational capabilities or data amounts, showcasing its robustness to heterogeneity.
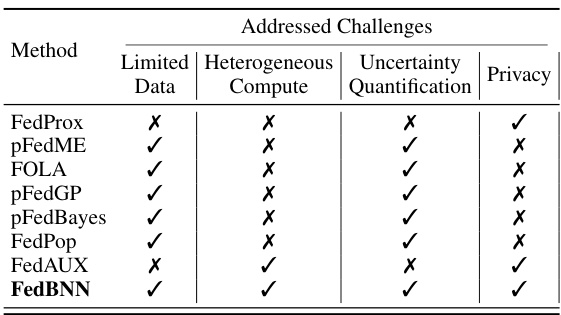
This table compares the proposed method FedBNN with other related methods in terms of their ability to handle challenges related to limited data, heterogeneous compute resources, uncertainty quantification, and privacy. It highlights the unique advantages of FedBNN in addressing all these challenges simultaneously.
In-depth insights#
Bayesian FL Framework#
A Bayesian Federated Learning (FL) framework offers a compelling approach to address the inherent challenges of traditional FL, particularly concerning data heterogeneity and limited resources. Bayesian methods provide a natural way to handle uncertainty, which is especially crucial in FL where data is often scarce and noisy across decentralized clients. By modeling the parameters of local models as probability distributions rather than point estimates, a Bayesian approach enhances robustness and allows for improved uncertainty quantification. Personalized Bayesian models can be trained locally, tailored to the unique characteristics of each client’s data. Collaboration then occurs at the functional level, indirectly sharing knowledge through prior distributions defined in the output space, thus addressing model heterogeneity. This functional approach is more efficient than direct parameter sharing, preserving privacy and avoiding communication bottlenecks. Furthermore, differential privacy mechanisms can be integrated to ensure strong privacy guarantees, mitigating the risk of data leakage. The framework’s adaptability to various data distributions and computational resources enhances its practicality in real-world scenarios.
Personalized Models#
The concept of “Personalized Models” in federated learning is crucial for addressing the inherent heterogeneity among clients. Individual clients possess unique data distributions and computational capabilities, leading to varying model performance if a single global model is used. Personalized models offer a solution by tailoring models to each client’s specific characteristics. This approach enhances accuracy and robustness by allowing models to better adapt to local data nuances. However, personalization introduces challenges, primarily in achieving efficient collaboration amongst diverse models. Strategies like knowledge distillation, functional-space priors, and Bayesian approaches are essential to facilitate effective model exchange and avoid excessive communication overhead. Balancing personalization with privacy and fairness also remains a crucial aspect, ensuring that the personalized model training doesn’t lead to unintended biases or information leakage.
Privacy-Preserving FL#
Privacy-preserving Federated Learning (FL) tackles the challenge of training machine learning models on decentralized data without directly accessing sensitive information. Differential Privacy is a common technique, adding carefully calibrated noise to local model updates to prevent data breaches while ensuring reasonable model accuracy. Secure Aggregation methods focus on protecting model parameters during the aggregation process on a central server. Homomorphic Encryption allows computations on encrypted data, protecting individual data points throughout the learning process. Federated Transfer Learning leverages pre-trained models to reduce the amount of data needed from individual clients, improving privacy. Secure Multi-Party Computation (MPC) techniques allow multiple parties to collaboratively compute a function without revealing their individual inputs, ideal for secure aggregation in FL. The choice of privacy-enhancing techniques depends on the specific application and the desired level of privacy and accuracy trade-off. Balancing privacy guarantees with model utility is crucial, and ongoing research is focused on developing more efficient and effective methods for privacy-preserving FL.
Heterogeneous Data#
Heterogeneous data in federated learning (FL) poses a significant challenge due to the variability in data distributions across participating clients. This heterogeneity can lead to model inaccuracies and performance degradation if not properly addressed. Non-IID (independent and identically distributed) data significantly impacts model generalization, as models trained on one client’s data may not perform well on another’s. Strategies for handling this include personalized models, tailored to each client’s unique data distribution, and data augmentation techniques which aim to balance the data across clients. Robust aggregation methods are crucial for combining model updates from heterogeneous sources effectively. Federated transfer learning or knowledge distillation methods can help transfer knowledge from data-rich clients to data-poor ones, improving overall model performance. The inherent difficulty in designing an FL system robust to all forms of heterogeneity requires addressing challenges related to client resource constraints and communication efficiency. Addressing these challenges is essential for the success and scalability of FL in real-world applications.
Future Research#
Future research directions stemming from this Bayesian personalized federated learning approach could involve several key areas. Extending the framework to handle even more complex heterogeneous settings is crucial, such as scenarios with significant variations in data distributions and model architectures across clients. Investigating the impact of different prior specifications, beyond the proposed functional space method, on model performance and privacy is warranted. A deeper exploration of the privacy-utility trade-off under various levels of privacy constraints is also essential. Furthermore, developing more efficient algorithms for local optimization and global collaboration would improve scalability. Addressing the challenges posed by non-IID data and limited computational resources in resource-constrained environments are important. Finally, applying the method to a wider range of real-world applications and rigorously evaluating its performance against existing state-of-the-art approaches in those domains would provide strong validation and highlight practical impact.
More visual insights#
More on figures
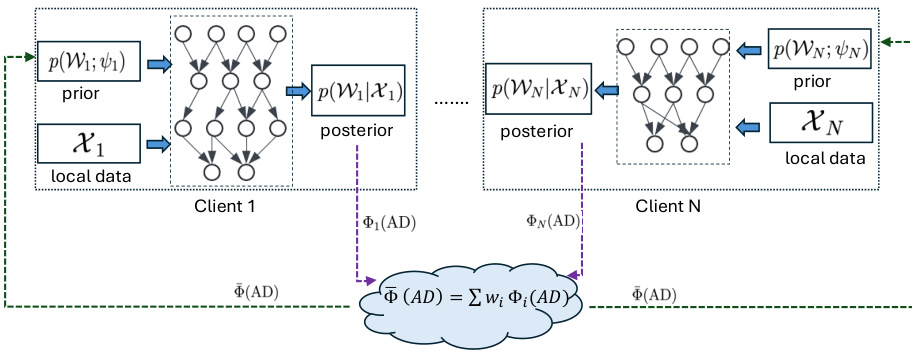
This figure shows a schematic overview of the FedBNN method. Each client trains a Bayesian neural network (BNN) using its local data and a prior distribution. The clients then use their trained BNNs to generate outputs on an alignment dataset (AD). The server aggregates these outputs and sends the aggregated output back to the clients. The clients use this aggregated output to update their prior distributions, which are then used to further train their BNNs. This process is iterated until convergence.
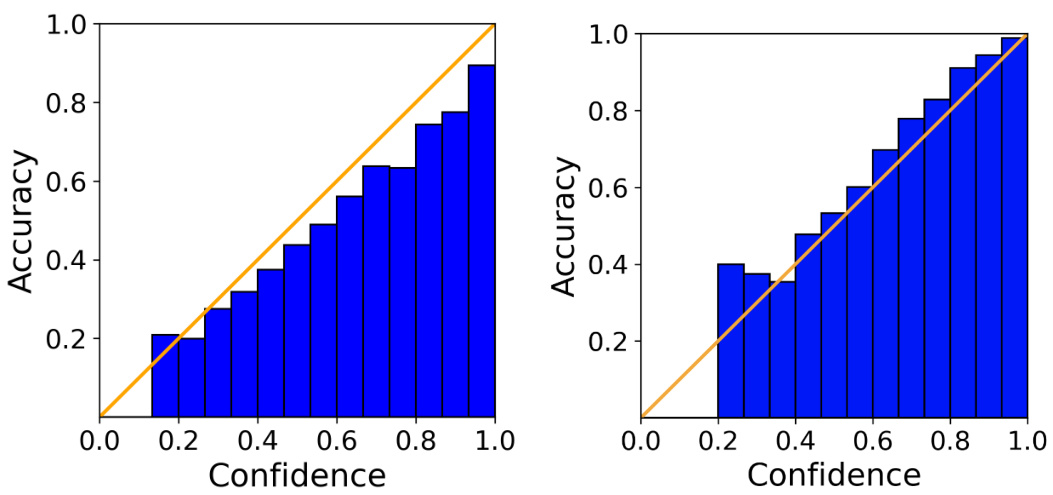
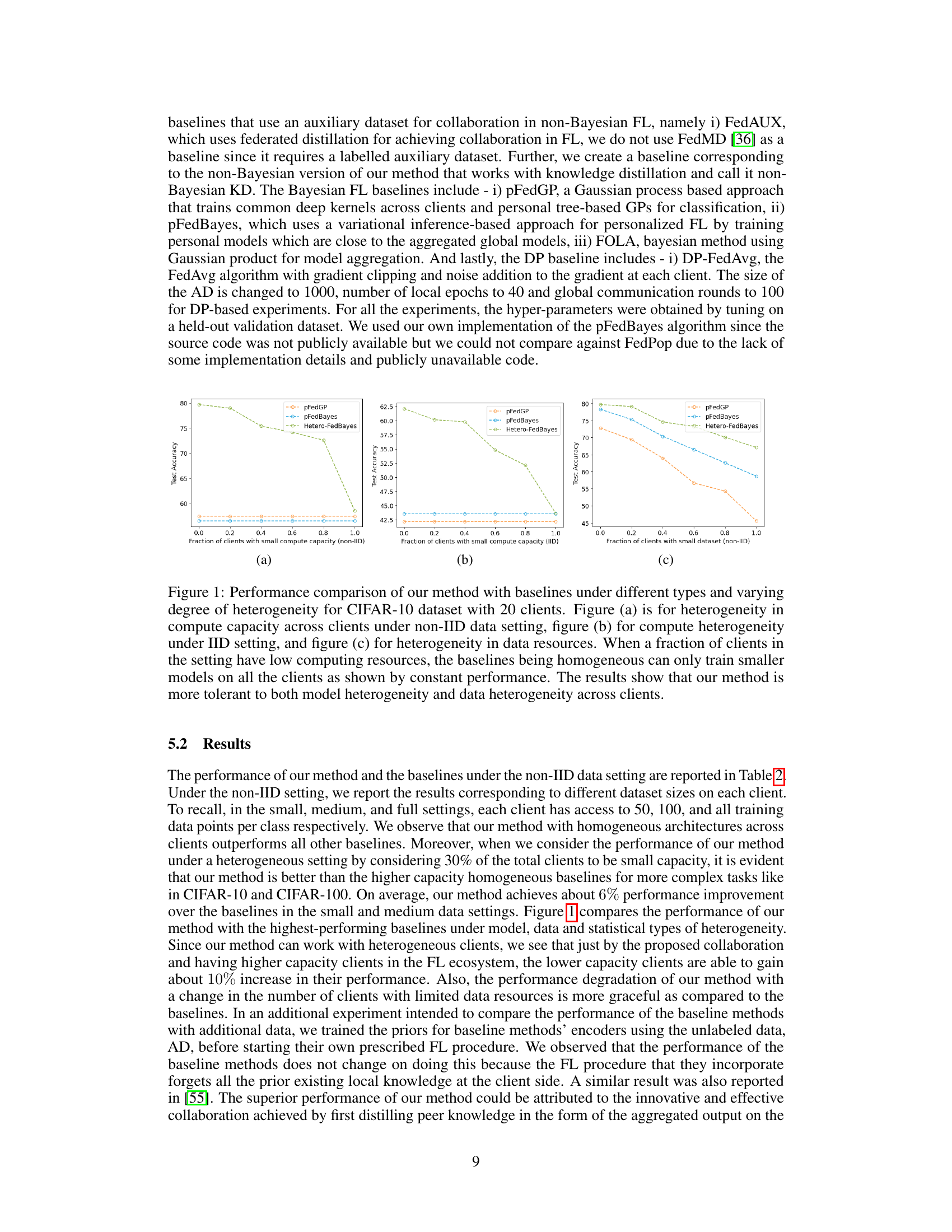
This figure shows the reliability diagrams for CIFAR-10 and MNIST datasets. A reliability diagram plots the accuracy of a model against its confidence. A perfectly calibrated model would show a diagonal line. Deviations from this line indicate miscalibration. The figure also provides the Expected Calibration Error (ECE) and Maximum Calibration Error (MCE) which are numerical metrics that quantify the deviation from perfect calibration. Lower values of ECE and MCE indicate better calibration.
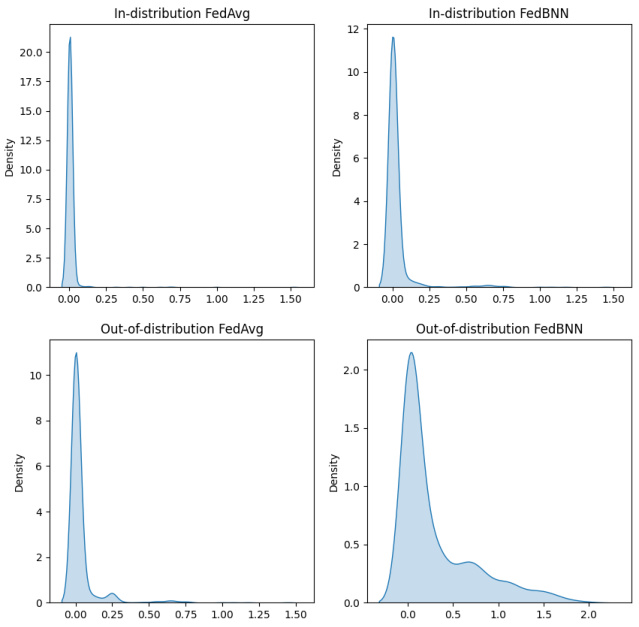
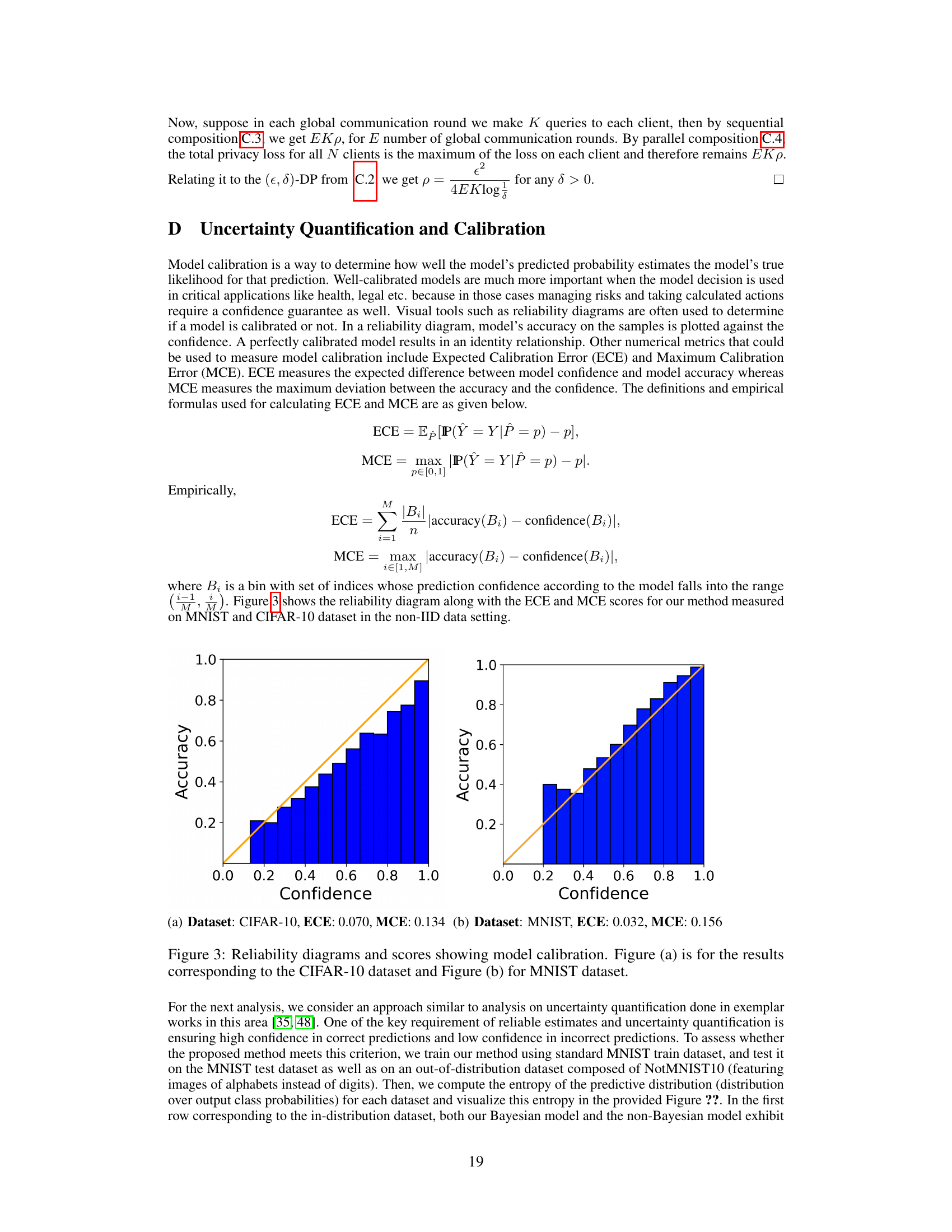
This figure shows the distribution of entropy of class probability distributions across different clients. The entropy measures the uncertainty of the model’s predictions. Lower entropy indicates higher confidence. The figure compares in-distribution (MNIST test set) and out-of-distribution (NotMNIST10) data. The Bayesian approach (FedBNN) shows significantly higher entropy for out-of-distribution data, indicating better uncertainty awareness compared to the non-Bayesian approach (FedAvg) which shows low entropy for both in-distribution and out-of-distribution data, suggesting overconfidence in out-of-distribution predictions.
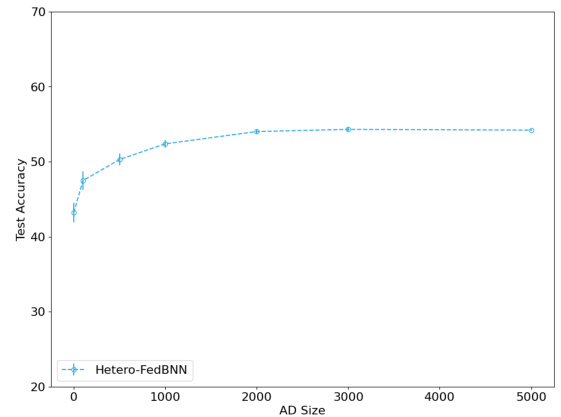
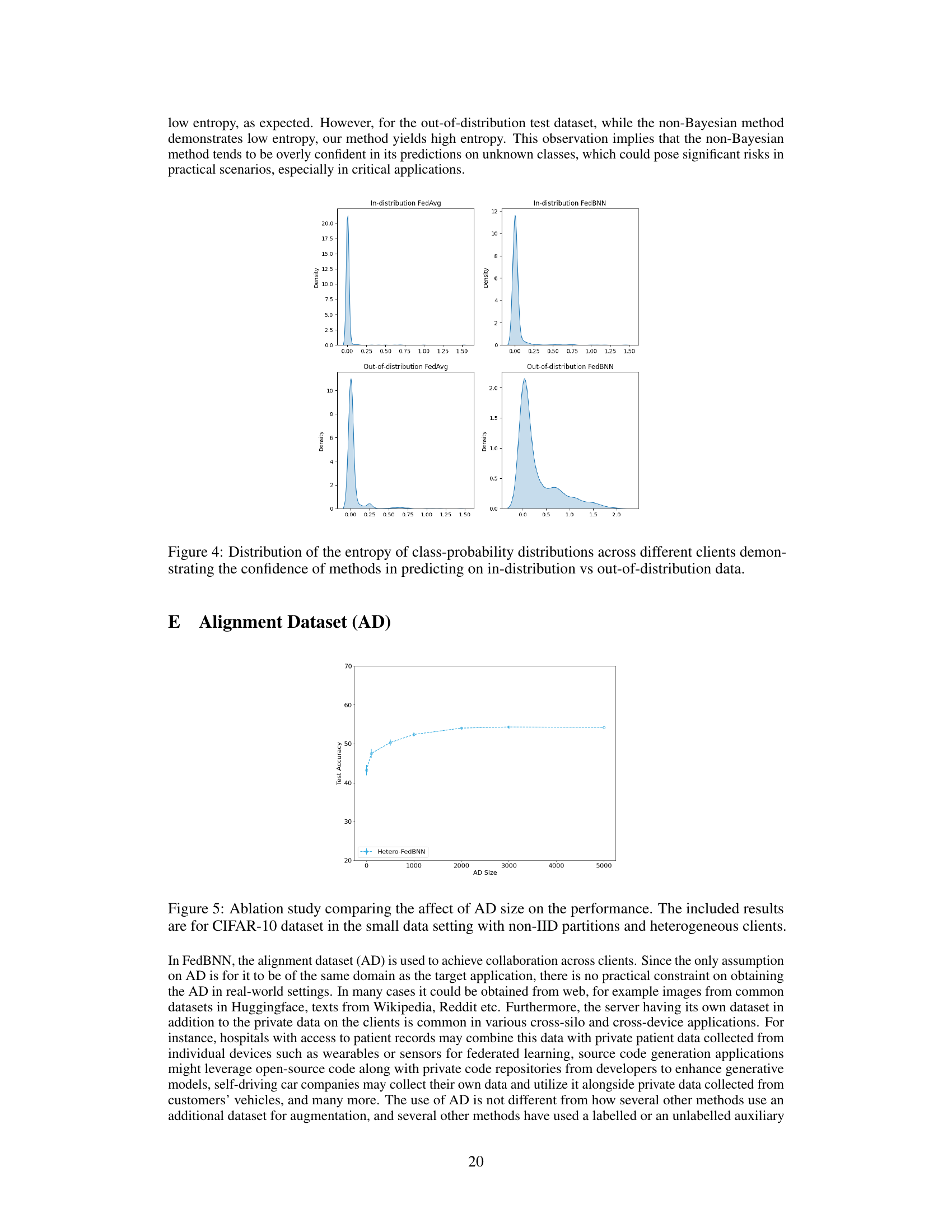
The figure shows an ablation study on the effect of the size of the alignment dataset (AD) on the performance of the proposed FedBNN method. The experiment was conducted on the CIFAR-10 dataset with a small data setting and non-IID data distribution across clients, where some clients have smaller computational resources than others. The x-axis represents the size of the AD, and the y-axis shows the test accuracy. The results demonstrate that increasing the size of the AD initially improves the test accuracy, but after a certain point, the accuracy plateaus, indicating that there is a limit to the benefits of increasing the size of the AD. This suggests that a moderate-sized AD is sufficient to effectively facilitate collaboration in heterogeneous settings.
More on tables
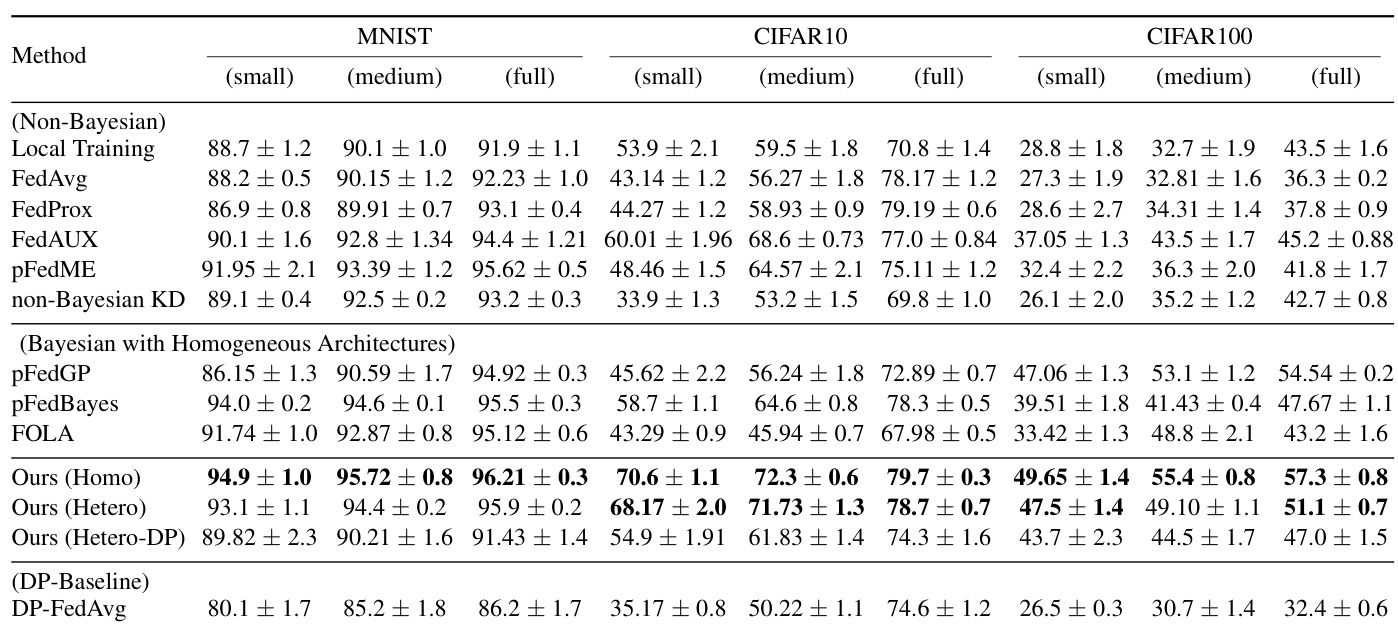
This table compares the performance of the proposed method, FedBNN, against several baseline methods in a non-IID setting. The comparison is done across three different datasets (MNIST, CIFAR-10, and CIFAR-100) and three different data resource settings (small, medium, and full). Results are presented for both homogeneous and heterogeneous client settings. The table also includes results for a differentially private version of FedBNN.

This table presents the results of an ablation study that investigates the impact of varying the distribution of the alignment dataset (AD) on the model’s performance. The experiment uses the CIFAR-10 dataset with a non-IID data distribution across 20 clients, where each client only has data from 5 out of 10 classes. Different AD compositions are tested (CIFAR10(10), CIFAR10(8), CIFAR10(5), CIFAR10(2)) to assess the effect of class representation within the AD on the overall model accuracy, as well as an AD comprised of images from the SVHN dataset. Both homogeneous and heterogeneous model architectures across the clients are considered in the evaluation.
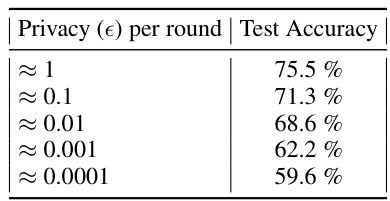
This table shows the relationship between the privacy guarantee (epsilon) and the test accuracy of the proposed method. As the privacy guarantee becomes stricter (smaller epsilon), the test accuracy decreases, indicating a trade-off between privacy and accuracy.
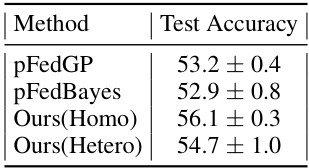
This table compares the test accuracy of different federated learning methods (pFedGP, pFedBayes, Ours(Homo), Ours(Hetero)) when the number of clients is increased to 500. The results show the performance of both homogeneous and heterogeneous settings of the proposed method.
Full paper#