↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Domain adaptive object detection (DAOD) aims to generalize object detectors trained on labeled source data to unlabeled target domains. Existing DAOD methods often struggle with domain shift, resulting in reduced performance on unseen data. A common approach uses a domain-agnostic adapter to learn domain-invariant features, but this can lead to a bias towards the source domain and limit generalization.
DA-Ada addresses this limitation by introducing a novel domain-aware adapter. This adapter cleverly separates and integrates both domain-invariant and domain-specific knowledge. This approach effectively reduces source domain bias, enabling significant performance improvements in DAOD tasks. Extensive experiments demonstrate that DA-Ada surpasses state-of-the-art methods on multiple benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves domain adaptive object detection, a crucial area in computer vision. DA-Ada’s novel approach of combining domain-invariant and domain-specific knowledge offers a significant advancement over existing methods. This opens avenues for researchers to improve object detection across diverse datasets and scenarios.
Visual Insights#
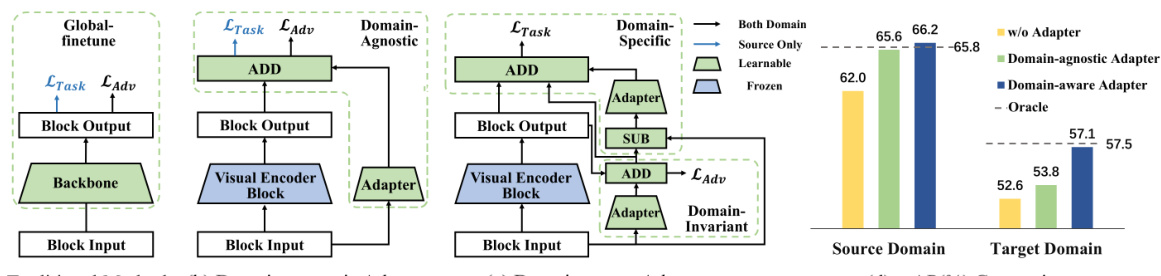
This figure shows a comparison of three different approaches to domain adaptive object detection (DAOD): traditional methods, domain-agnostic adapter, and domain-aware adapter. Traditional methods fine-tune the entire backbone, leading to potential overfitting. The domain-agnostic adapter inserts a module into a frozen visual encoder to learn domain-invariant features, but it may discard useful domain-specific information. The domain-aware adapter, in contrast, captures both domain-invariant and domain-specific knowledge, resulting in better performance, as shown in the mAP comparison on a Cross-Weather Adaptation task.
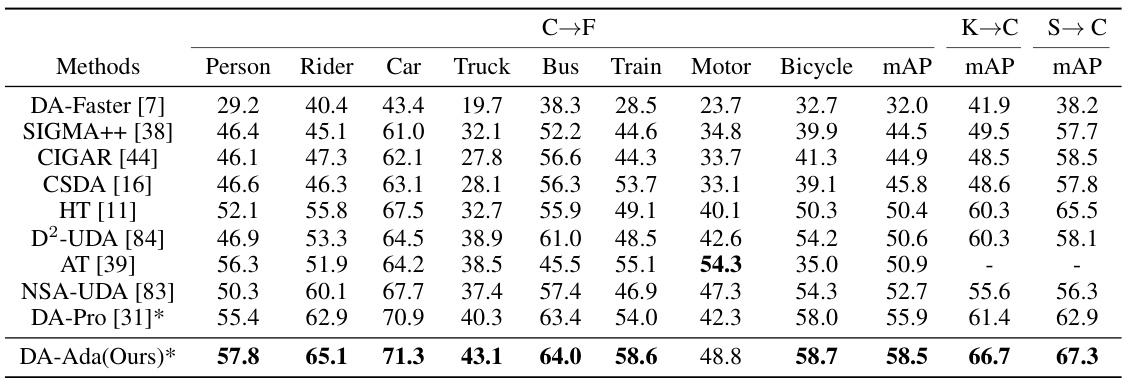
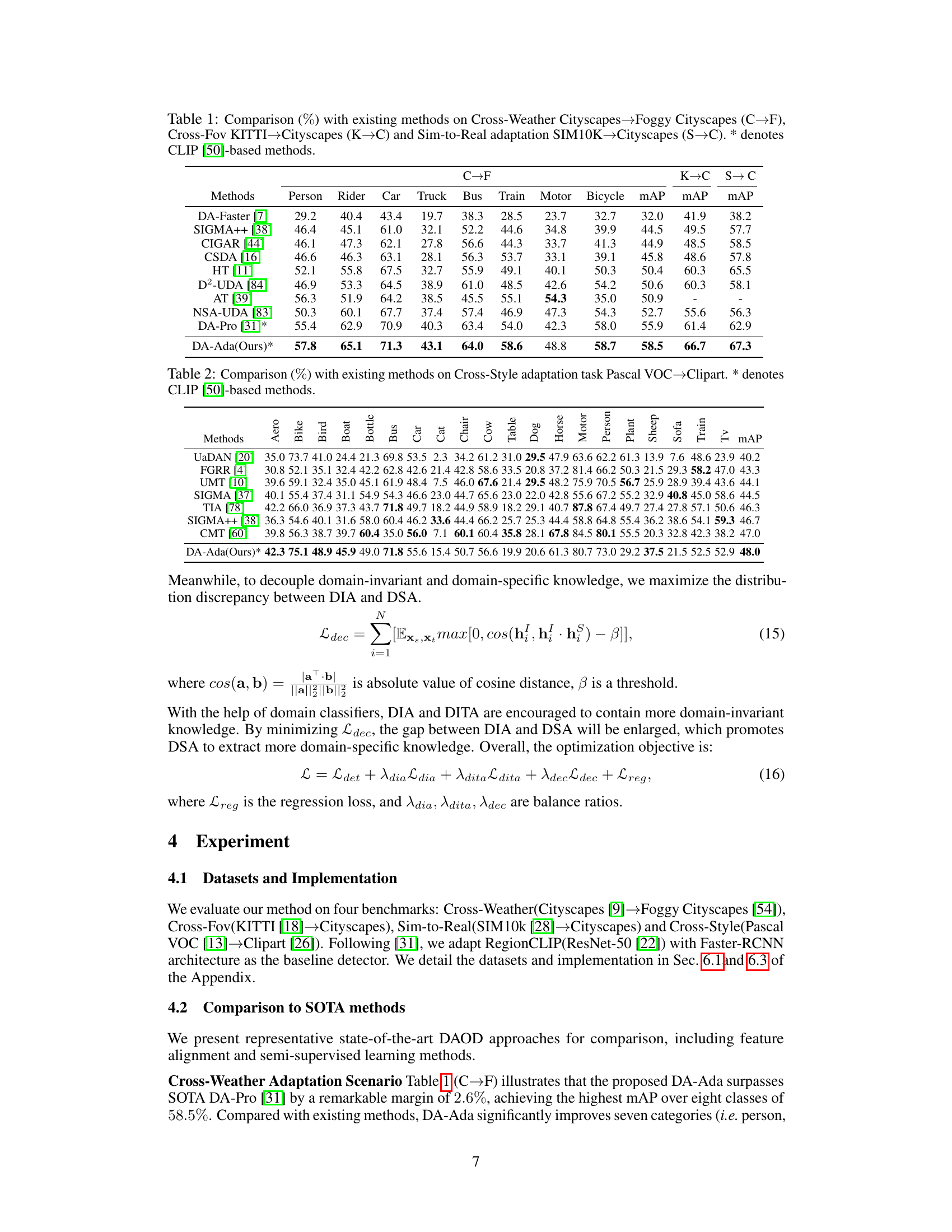
This table presents a comparison of the proposed DA-Ada method with several state-of-the-art domain adaptive object detection methods on three different cross-domain adaptation scenarios: Cross-Weather, Cross-FOV, and Sim-to-Real. The results are shown in terms of mean Average Precision (mAP) and per-class AP for eight classes (person, rider, car, truck, bus, train, motor, bicycle) in the Cityscapes dataset, showcasing the superiority of DA-Ada in handling domain shifts. The asterisk (*) indicates methods based on the CLIP visual-language model.
In-depth insights#
DAOD Adaptation#
Domain Adaptive Object Detection (DAOD) tackles the challenge of applying object detectors trained on one dataset (source domain) to a different, unlabeled dataset (target domain). DAOD’s core issue is the domain shift, where discrepancies in visual characteristics, such as lighting, weather, or object appearance, hinder the model’s performance. Approaches to address this shift involve techniques like feature alignment, which aims to reduce domain-specific differences in feature representations, and semi-supervised learning, which leverages limited labeled data from the target domain to guide adaptation. Recent advancements utilize visual-language models (VLMs), which provide a rich source of general knowledge, to improve DAOD. However, naively applying VLMs can be limiting, and approaches such as adapter tuning are employed to minimize overfitting and enhance adaptability to the target domain while preserving the VLM’s beneficial pre-trained knowledge. A key area of innovation is creating domain-aware adapters that can learn both domain-invariant (common to both datasets) and domain-specific features, thus optimizing detector performance across both domains more efficiently.
Domain-Aware Adapter#
The proposed Domain-Aware Adapter is a novel approach to address the limitations of existing domain adaptation methods in object detection. It tackles the problem of source domain bias inherent in domain-agnostic adapters by explicitly incorporating both domain-invariant and domain-specific knowledge. This dual approach leverages the strengths of pre-trained visual-language models (VLMs) while mitigating their tendency to overfit to the source domain. The Domain-Invariant Adapter (DIA) learns shared features, effectively capturing the generalizable aspects of the model. Simultaneously, the Domain-Specific Adapter (DSA) focuses on extracting knowledge discarded by the DIA, essentially recovering information that is discriminative for the target domain. The clever integration of these two components, combined with a Visual-guided Textual Adapter (VTA), allows for significant improvements in cross-domain object detection performance. The architecture demonstrates a sophisticated understanding of the challenges inherent in domain adaptation and presents a practical solution for enhancing the generalization capabilities of VLMs in this challenging setting.
VLM Tuning#
Visual Language Models (VLMs) offer powerful pre-trained features for object detection, but standard fine-tuning can lead to overfitting and hinder generalization. VLM tuning techniques aim to leverage these pre-trained weights effectively without extensive retraining. This involves methods like prompt tuning, which modifies the input prompts to guide the model’s behavior, and adapter tuning, which inserts small, trainable modules into the network. Prompt tuning offers parameter efficiency, but may limit the model’s adaptability. Adapter tuning strikes a balance, allowing for adaptation while preserving the pre-trained knowledge; however, careful design is needed to prevent bias towards the source domain and to effectively learn domain-invariant features. The choice of tuning method depends on the specific task and dataset, with a focus on achieving high accuracy while maintaining efficiency and generalizability to unseen data.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contribution. In the context of a domain adaptive object detection model, these studies might involve removing the domain-invariant adapter, the domain-specific adapter, or the visual-guided textual adapter. By observing the performance drop after each removal, the importance of the specific component to the model’s success can be determined. The ablation study results would reveal if a balanced approach, using both domain-invariant and domain-specific knowledge, indeed yields superior results compared to using only one type of knowledge. The effectiveness of the multi-scale down-projector could also be assessed by comparing various configurations. These studies help to understand the model’s architecture, identify critical components, and justify design choices, ultimately leading to a more robust and efficient object detection model for diverse domains.
Future Works#
Future work could explore several promising avenues. Extending DA-Ada to handle more complex scenarios such as those with multiple source domains or completely unlabeled target domains is crucial. Investigating the impact of different visual backbones and exploring alternative adapter architectures beyond the current design would further enhance performance and adaptability. A deeper analysis of the learned domain-invariant and domain-specific knowledge representations could offer valuable insights into the underlying mechanisms of domain adaptation. Finally, developing more rigorous evaluation metrics that go beyond standard mAP scores to capture the nuances of domain adaptation and address potential biases in current benchmark datasets would provide a stronger foundation for future research and comparison of methods.
More visual insights#
More on figures
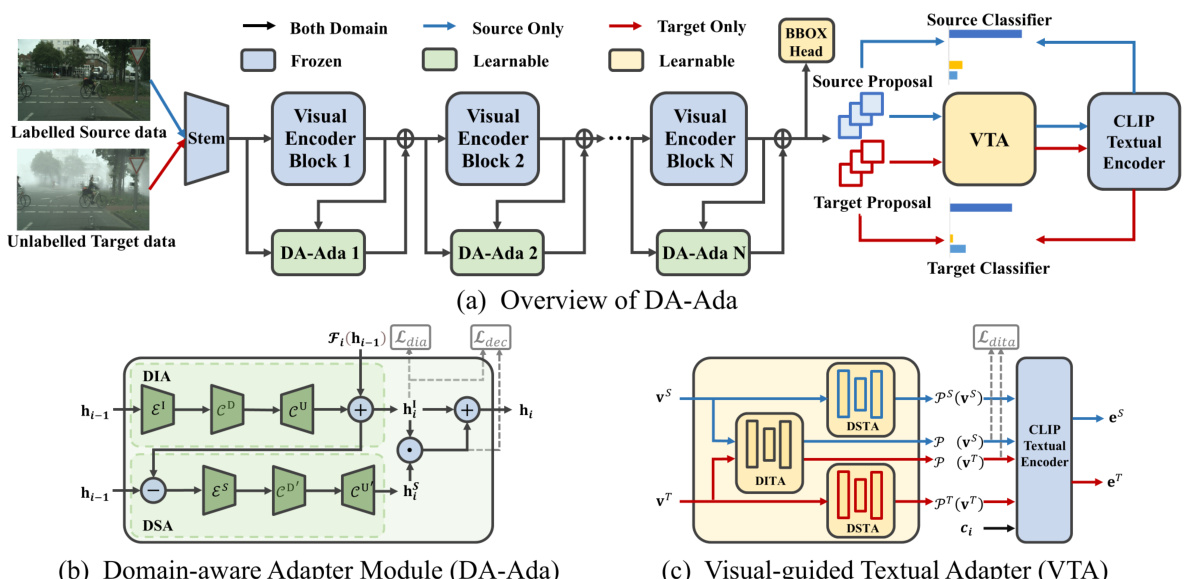
This figure shows the overall architecture of the proposed DA-Ada framework for domain adaptive object detection (DAOD). Part (a) presents a schematic of the entire system, illustrating how the DA-Ada modules are integrated into a visual encoder, and the interaction with textual encoders for improved cross-domain generalization. Parts (b) and (c) detail the DA-Ada module and the Visual-guided Textual Adapter (VTA), respectively. The DA-Ada module is a key component that exploits both domain-invariant and domain-specific knowledge, enhancing the robustness and generalization ability of the detector. The VTA further enhances the discriminative power of the detection head by leveraging visual features and textual information.
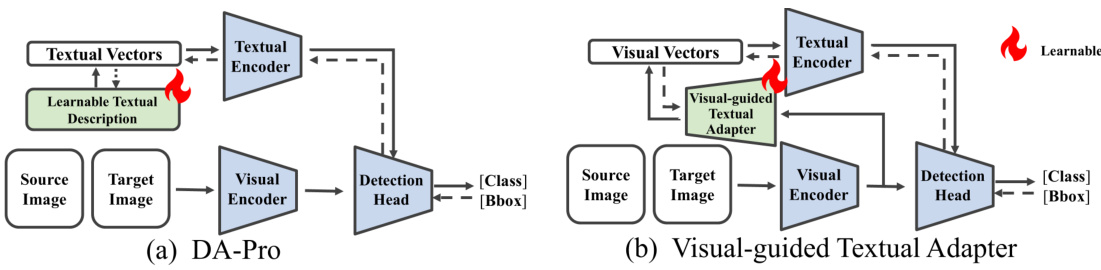
This figure compares two approaches for adapting visual-language models to domain adaptive object detection. (a) shows DA-Pro, which tunes only the textual encoder using learnable textual descriptions. (b) shows the proposed Visual-guided Textual Adapter (VTA), which leverages both domain-invariant and domain-specific knowledge from the visual encoder to enhance the textual encoder’s discriminative power, leading to improved detection performance on the target domain.

This figure compares the object detection results of the proposed DA-Ada model against the state-of-the-art DA-Pro model and a baseline on a sample image from the Cross-Weather dataset (Cityscapes → Foggy Cityscapes). Subfigures (a.1), (b.1), (c.1), and (d.1) provide zoomed-in views of a specific region of the image, highlighting the differences in detection accuracy. DA-Ada demonstrates superior performance, achieving a higher mean Average Precision (mAP) value compared to DA-Pro and the baseline. This showcases DA-Ada’s improved ability to handle challenging weather conditions.

This figure shows the proposed DA-Ada architecture for domain adaptive object detection (DAOD). (a) provides a high-level overview of how DA-Ada is integrated into a visual language model (VLM) for DAOD. (b) details the structure of a single domain-aware adapter module (DA-Ada), which consists of a domain-invariant adapter (DIA) and a domain-specific adapter (DSA). (c) illustrates the visual-guided textual adapter (VTA), which leverages the output of DA-Ada to improve the textual encoder’s discriminative ability. The figure highlights the key components and their interactions to achieve improved domain adaptation performance.
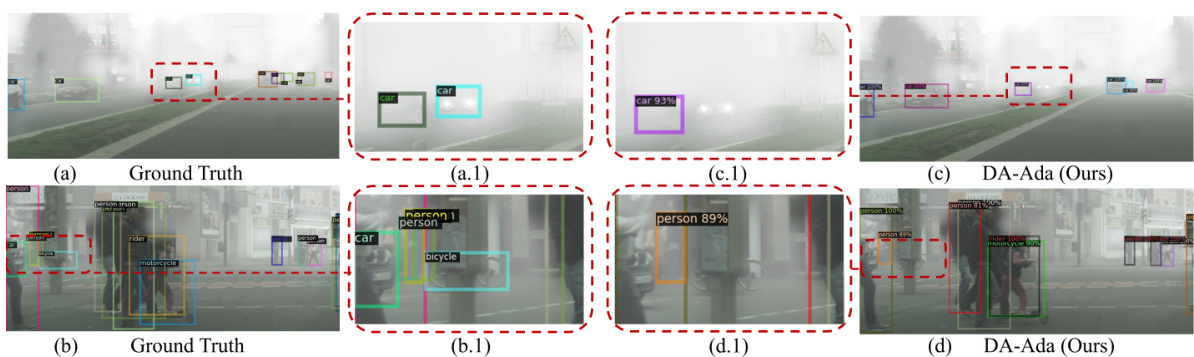
This figure compares the object detection results of the proposed DA-Ada method against the state-of-the-art DA-Pro method and a baseline method on the Cross-Weather dataset. It visually demonstrates the improved performance of DA-Ada by showing ground truth bounding boxes alongside the detection bounding boxes generated by each method. The zoomed-in sections highlight the differences in detection accuracy, particularly in challenging conditions such as fog.
More on tables
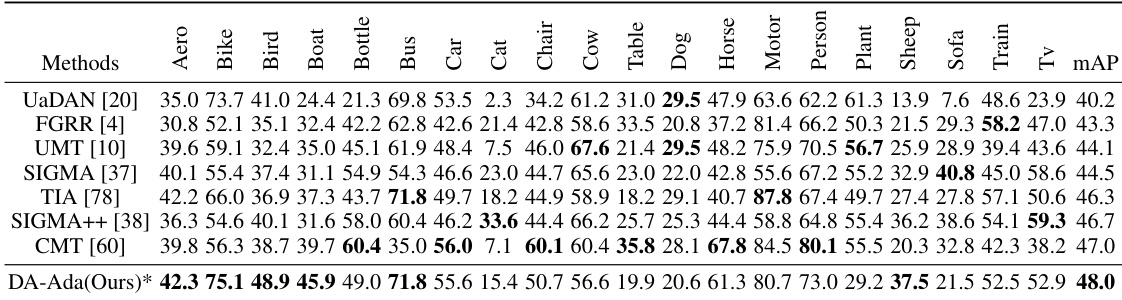
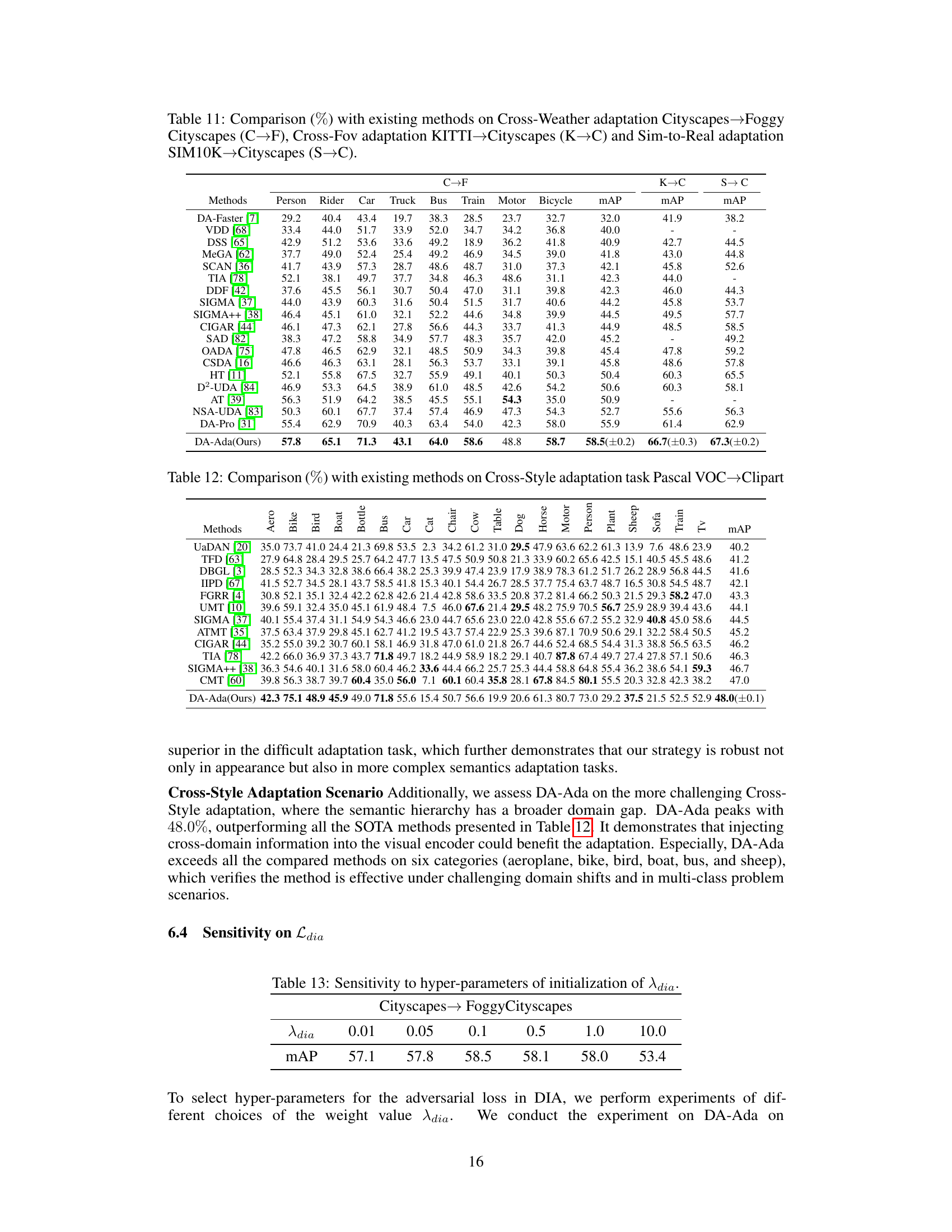
This table presents a comparison of the proposed DA-Ada method with other state-of-the-art methods on the Cross-Style adaptation task, which involves adapting a detector trained on the Pascal VOC dataset to the Clipart dataset. The results are shown as percentages and include the mean Average Precision (mAP) across various object categories. The asterisk (*) indicates methods that utilize the CLIP visual language model.

This table compares the performance of the proposed domain-aware adapter against two baseline adapter methods: source-only and domain-agnostic adapters. The results are presented as mean Average Precision (mAP) percentages across four different domain adaptation scenarios: Cross-Weather, Cross-FoV, Sim-to-Real, and Cross-Style. The domain-aware adapter consistently outperforms both baselines, highlighting its effectiveness in improving domain adaptation performance.
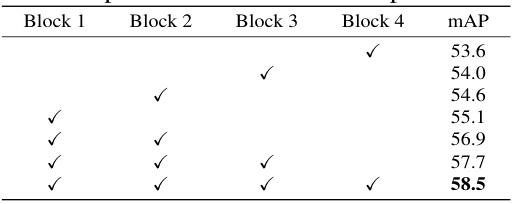
This table shows the ablation study of the insertion site of the domain-aware adapter in the proposed DA-Ada model. The results demonstrate the impact of placing the adapter at different block layers (Block 1 to Block 4) of the visual encoder on the model’s performance, measured by mAP (mean Average Precision) on the Cross-Weather dataset. The checkmarks indicate the presence of a DA-Ada module at a specific block. The results suggest that optimal performance is achieved by inserting the DA-Ada in the first block (55.1% mAP), with performance generally improving when more adapters are added.
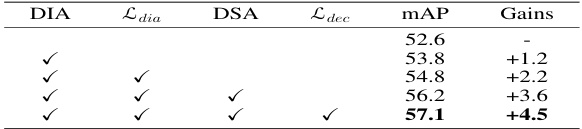
This table presents the ablation study results on the domain-aware adapter for cross-weather adaptation. It shows the impact of using the Domain-Invariant Adapter (DIA), the domain adversarial loss (L_dia), the Domain-Specific Adapter (DSA), and the decoupling loss (L_dec) on the mean Average Precision (mAP). The results demonstrate the contribution of each component to the overall performance improvement.

This table presents the ablation study on the input and injection operations within the domain-aware adapter module. It shows how different choices for the input to the Domain-Invariant Adapter (DIA), the input to the Domain-Specific Adapter (DSA), and the method of combining their outputs (injection operation) impact the final mean average precision (mAP) on the Cross-Weather object detection task. The results demonstrate the effectiveness of specific input and fusion strategies in improving performance.

This table compares the performance of the Visual-guided Textual Adapter (VTA) proposed in the paper against existing plain textual tuning methods on two cross-domain object detection tasks: Cross-Weather (Cityscapes → Foggy Cityscapes) and Cross-FOV (KITTI → Cityscapes). The results show that the VTA significantly improves upon the baseline methods, demonstrating the effectiveness of incorporating cross-domain visual information into the textual encoder for improved detection performance. The gains presented show the performance difference between the VTA and each of the comparison methods.

This table compares the computational efficiency of different methods on the Cross-Weather adaptation task, showing the number of backbone parameters, the number of learnable parameters, the mean average precision (mAP), the absolute gain in mAP compared to a baseline, and the method’s name.

This table compares the performance of DA-Ada with other state-of-the-art methods on three different domain adaptation tasks: Cross-Weather, Cross-FOV, and Sim-to-Real. The results are presented as mean Average Precision (mAP) percentages for each of eight object categories, along with overall mAP values. The table highlights DA-Ada’s superior performance, especially in comparison to the CLIP-based methods (denoted by *).
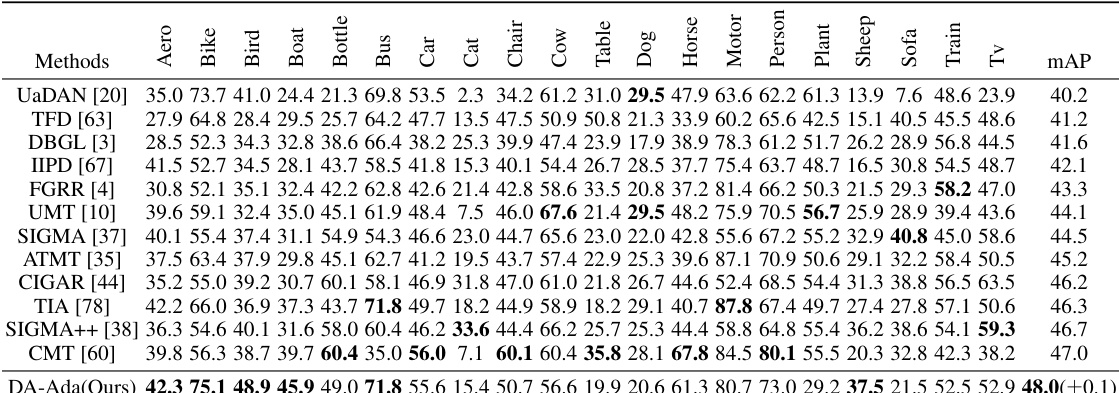
This table compares the performance of DA-Ada against other state-of-the-art methods on three different domain adaptation tasks: Cross-Weather, Cross-FOV, and Sim-to-Real. The results are presented as the mean average precision (mAP) for several object classes in each scenario. The table highlights DA-Ada’s superior performance compared to existing approaches.

This table shows the sensitivity analysis of the hyperparameter λdia, which is the weight of the adversarial loss in the domain-invariant adapter (DIA). The experiment was conducted on the Cross-Weather adaptation scenario (Cityscapes → Foggy Cityscapes). Different values of λdia were tested, and the corresponding mean average precision (mAP) is reported. The results indicate that the performance peaks around λdia = 0.1, demonstrating the effectiveness of balancing the adversarial loss for domain-invariant knowledge learning. Too small or too large values of λdia harm the overall performance.

This table shows the results of ablation studies on the hyperparameter λdita (weight for the adversarial loss in visual-guided domain prompt) in the DA-Ada model. The experiments were conducted on the Cityscapes → FoggyCityscapes adaptation scenario. Different values of λdita were tested, and the corresponding mAP (mean Average Precision) is reported. The table aims to demonstrate the sensitivity of the model’s performance to this hyperparameter and to identify its optimal value.
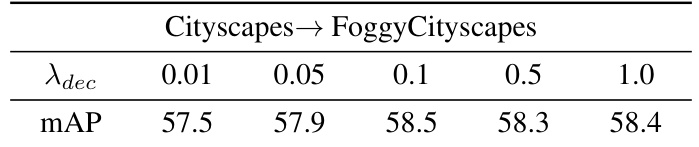
This table shows the sensitivity analysis of the hyperparameter λdec, which controls the weight of the decoupling loss between the Domain-Invariant Adapter (DIA) and the Domain-Specific Adapter (DSA). The results show the mean Average Precision (mAP) achieved on the Cityscapes→FoggyCityscapes domain adaptation task with different values of λdec. The optimal value of λdec appears to be around 1.0.

This table shows the ablation study on the impact of different resolutions used in the multi-scale down-projector CD (Convolutional Down-projection) within the Domain-Specific Adapter (DSA) module of the DA-Ada architecture. The results demonstrate the optimal number of resolutions and their impact on the model’s performance in the Cityscapes to Foggy Cityscapes domain adaptation task, as measured by mean Average Precision (mAP).

This table compares the performance of adding the DA-Ada module to two different baseline models for the Cross-Weather adaptation task (Cityscapes to Foggy Cityscapes). It shows the mean Average Precision (mAP) for each baseline (DSS and CLIP+Faster-RCNN) without DA-Ada, with DA-Ada, and the gain in mAP achieved by adding DA-Ada. This demonstrates the effectiveness of the DA-Ada across different baseline models.

This table compares the performance (mAP), inference time per iteration, training time per iteration, total number of iterations, and memory usage (MB) for three different methods: Global Fine-tune, DA-Pro, and DA-Ada, in the context of the Cross-Weather adaptation (Cityscapes → Foggy Cityscapes) task. DA-Ada shows a significant improvement in mAP while maintaining relatively efficient inference and training time compared to Global Fine-tune, which has much higher computational costs. DA-Pro offers a balance between performance and efficiency.
Full paper#