↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current retrieval-augmented generation (RAG) methods for large language models (LLMs) struggle with efficient knowledge integration. They often fail to effectively integrate new information across different passages, limiting their ability to perform complex reasoning tasks. This is particularly challenging for tasks that require integrating knowledge from multiple sources, such as multi-hop question answering. The challenge stems from current methods encoding passages in isolation, hindering the ability to establish connections across different pieces of information.
HippoRAG addresses this limitation by using a novel framework inspired by the human brain’s hippocampal indexing theory. It leverages LLMs, knowledge graphs, and the Personalized PageRank algorithm to mimic the functions of the neocortex and hippocampus. This allows for a more efficient integration of new knowledge across different passages. HippoRAG significantly outperforms existing state-of-the-art RAG methods in multi-hop question answering, demonstrating remarkable improvements of up to 20%. Furthermore, it achieves comparable or better performance than iterative methods while being significantly more efficient, achieving speed and cost reductions of up to 10-20 times and 6-13 times, respectively.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on long-term memory in LLMs and multi-hop question answering. It introduces a novel framework that significantly outperforms existing methods, offering substantial efficiency improvements. The neurobiologically inspired approach opens exciting avenues for future research on more efficient and effective knowledge integration in AI.
Visual Insights#
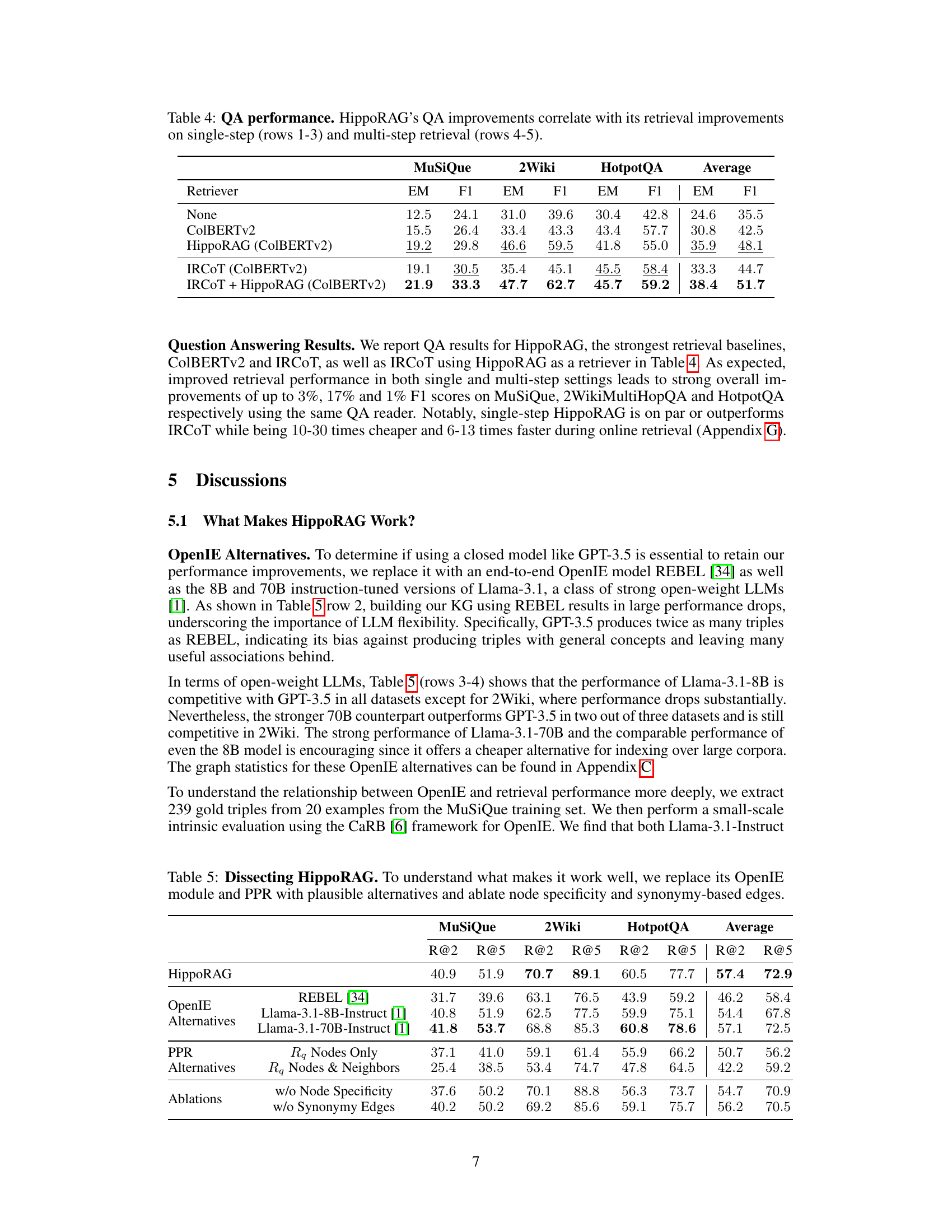
This figure illustrates the challenge of knowledge integration in current RAG systems compared to human memory. It uses an example of finding a Stanford professor specializing in Alzheimer’s research. Current RAG struggles because it encodes passages individually, requiring both characteristics to be mentioned in a single passage. Human memory, however, excels due to associative memory (represented by the hippocampus). HippoRAG aims to mimic this human capability by creating and using a graph of associations to improve knowledge integration in LLMs.
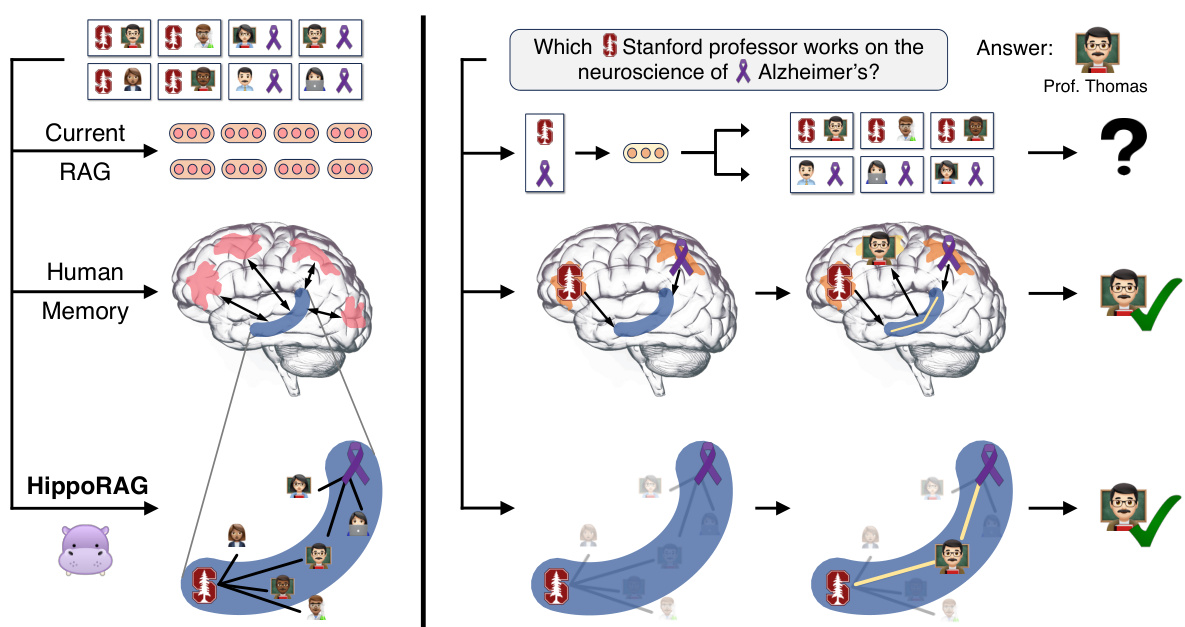
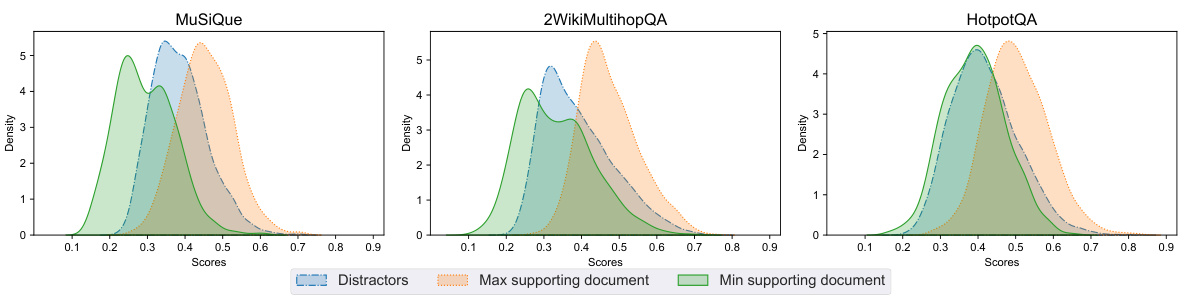
This table presents a quantitative overview of the three datasets used in the paper’s experiments: MuSiQue, 2WikiMultiHopQA, and HotpotQA. For each dataset, it lists the number of passages, the number of unique nodes and edges in the knowledge graph (KG) created, the number of unique triples extracted from the passages, and the number of synonym edges added to the KG using Contriever and ColBERTv2. This information helps to characterize the size and complexity of each dataset and the resulting KG used for retrieval.
In-depth insights#
Hippocampal RAG#
Hippocampal RAG presents a novel approach to integrating long-term memory into large language models (LLMs) by drawing inspiration from the human hippocampus. The core idea is to mimic the brain’s hippocampal indexing theory, using LLMs to build and query a schemaless knowledge graph (KG) that represents long-term memory. This contrasts with traditional retrieval-augmented generation (RAG) methods that process new information in isolation. The Personalized PageRank algorithm is used to effectively navigate this KG, allowing for multi-hop reasoning in a single retrieval step, overcoming the limitations of iterative RAG methods. The system’s architecture, comprising an LLM, retrieval encoders, and the PPR algorithm on the KG, elegantly simulates the key components of human long-term memory and demonstrates substantial improvements over existing approaches in multi-hop question answering tasks. The integration of Hippocampal RAG into existing systems leads to complementary gains, indicating its potential for broader implementation in various knowledge-intensive applications.
KG Indexing#
KG indexing, in the context of the research paper, is a crucial process that involves structuring information from a large corpus of text into a knowledge graph (KG). This process leverages the capabilities of large language models (LLMs) to extract key relationships and entities from the text, transforming unstructured data into a structured, interconnected network of nodes (entities) and edges (relationships). The choice of using an LLM is pivotal, offering flexibility and the ability to build a schemaless KG, adapting to the nuances and complexities inherent in natural language. The offline nature of this KG construction is highlighted, suggesting a pre-processing step that prepares the data for efficient online querying. The method likely uses techniques like Open Information Extraction (OpenIE) to automatically identify and extract the triples that form the edges of the KG, with further refinement or optimization steps potentially applied for improved accuracy and structure. A key challenge lies in balancing detail and comprehensiveness in representing the information; the paper likely explains the trade-offs involved and the methodologies employed to manage this, including considerations for computational cost and efficiency.
Multi-hop QA#
Multi-hop question answering (QA) presents a significant challenge in natural language processing, demanding the integration of information from multiple sources to arrive at a correct answer. Current RAG methods often fall short, struggling with tasks requiring complex reasoning across passages. The paper highlights this limitation, illustrating how existing systems fail on path-finding multi-hop questions that require identifying connections between disparate pieces of information, unlike the human ability to swiftly integrate knowledge from various sources. HippoRAG addresses this shortcoming, by mimicking the hippocampal indexing theory of human memory. This novel approach leverages a knowledge graph (KG) built from input passages via an LLM as an artificial hippocampal index. Personalized PageRank (PPR) efficiently explores the KG, enabling multi-hop reasoning in a single step. The single-step retrieval yields significant improvements over current iterative methods, showcasing both computational efficiency and accuracy gains. The paper’s focus on handling integration across passage boundaries provides an important contribution towards developing LLM systems with more robust and human-like long-term memory capabilities.
Retrieval Gains#
Retrieval gains in the context of large language models (LLMs) and long-term memory systems represent significant improvements in the efficiency and effectiveness of information retrieval processes. These gains stem from advancements in techniques that allow LLMs to better integrate and leverage external knowledge sources. The core idea is to move beyond simple keyword matching to more sophisticated methods that capture semantic relationships and contextual information within knowledge graphs. This enables more accurate and nuanced retrieval of relevant information, even across multiple documents or passages. This is crucial for complex tasks like multi-hop question answering, where understanding relationships between various pieces of information is essential for finding a correct answer. The resulting retrieval improvements directly translate to better overall LLM performance on downstream tasks, allowing the models to draw upon more comprehensive knowledge bases and resulting in substantial gains in accuracy and speed compared to traditional methods. Further research will likely focus on expanding these techniques to ever-larger datasets and more complex question types, continually pushing the boundaries of efficient and effective knowledge access for LLMs.
Future work#
Future research directions stemming from this HippoRAG model are multifaceted. Improving the OpenIE component is crucial; while LLMs offer flexibility, more robust and efficient methods are needed for knowledge graph construction. Addressing the concept-context tradeoff is vital to improve retrieval performance in cases where subtle contextual cues are essential. This could involve incorporating contextual information into the graph structure or developing alternative indexing mechanisms that balance precision and recall. Furthermore, thorough exploration of alternative PPR-based graph traversal algorithms could yield better performance and scalability. While PPR shows promise, other methods might offer better solutions for large-scale applications. Finally, extensive scalability testing is necessary to confirm HippoRAG’s effectiveness across vastly larger datasets, potentially requiring a shift to distributed computing or more efficient graph data structures.
More visual insights#
More on figures

This figure provides a detailed illustration of the HippoRAG methodology, showing how it mimics the human brain’s long-term memory system. The offline indexing phase uses an LLM to transform passages into a knowledge graph (KG), representing the neocortex. Retrieval encoders act as the parahippocampal regions, identifying synonymous concepts. The KG, along with the Personalized PageRank algorithm, serves as the hippocampus, performing pattern separation and completion. The online retrieval phase extracts named entities from a query using the LLM and uses PPR to retrieve relevant information from the KG, mirroring the hippocampus’s ability to retrieve memories based on partial cues.
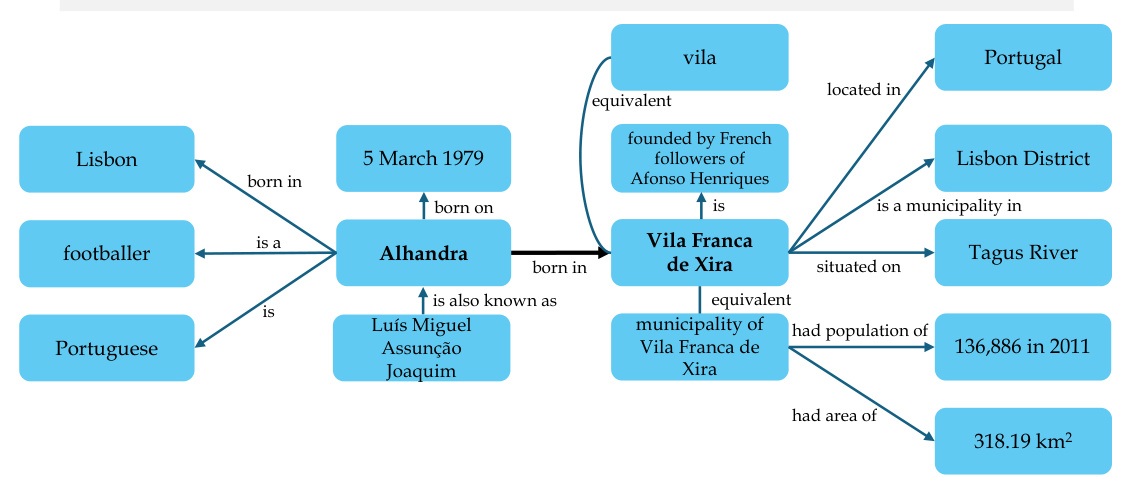
This figure illustrates the HippoRAG methodology, showing how it mimics the human memory system. The offline indexing stage uses an LLM to create a knowledge graph (KG) from text passages, representing the neocortex. A retrieval encoder acts as the parahippocampal region, identifying synonymous terms to enhance the KG. The online retrieval stage uses the LLM to extract key concepts from a query, then utilizes the PPR algorithm on the KG to find relevant passages based on these concepts. This mimics the role of the hippocampus in retrieving contextual memories.

This figure illustrates the challenge of knowledge integration for current RAG systems. It uses the example of finding a Stanford professor who researches Alzheimer’s disease. Current RAG systems struggle because they encode passages in isolation. The figure contrasts this with human memory, which leverages associative memory, potentially via hippocampal indexing. HippoRAG aims to replicate this human ability by using an LLM and knowledge graph to build associations.
This figure illustrates the challenges of knowledge integration for current RAG systems and contrasts them with the human brain’s associative memory capabilities. It uses the example of finding a Stanford professor who researches Alzheimer’s to highlight how current RAG struggles to integrate information across passages, unlike the human brain, which leverages associative memory. The figure introduces HippoRAG as a solution inspired by the hippocampal indexing theory.
This figure illustrates the challenge of knowledge integration for current Retrieval Augmented Generation (RAG) systems and how HippoRAG addresses this by mimicking the human brain’s associative memory. The example shows the difficulty in retrieving information about a specific Stanford professor who works on Alzheimer’s disease using traditional RAG, highlighting the limitation of isolated passage encoding. In contrast, HippoRAG leverages a graph-based approach inspired by the human hippocampus to connect and integrate information across passages, facilitating more effective knowledge retrieval.
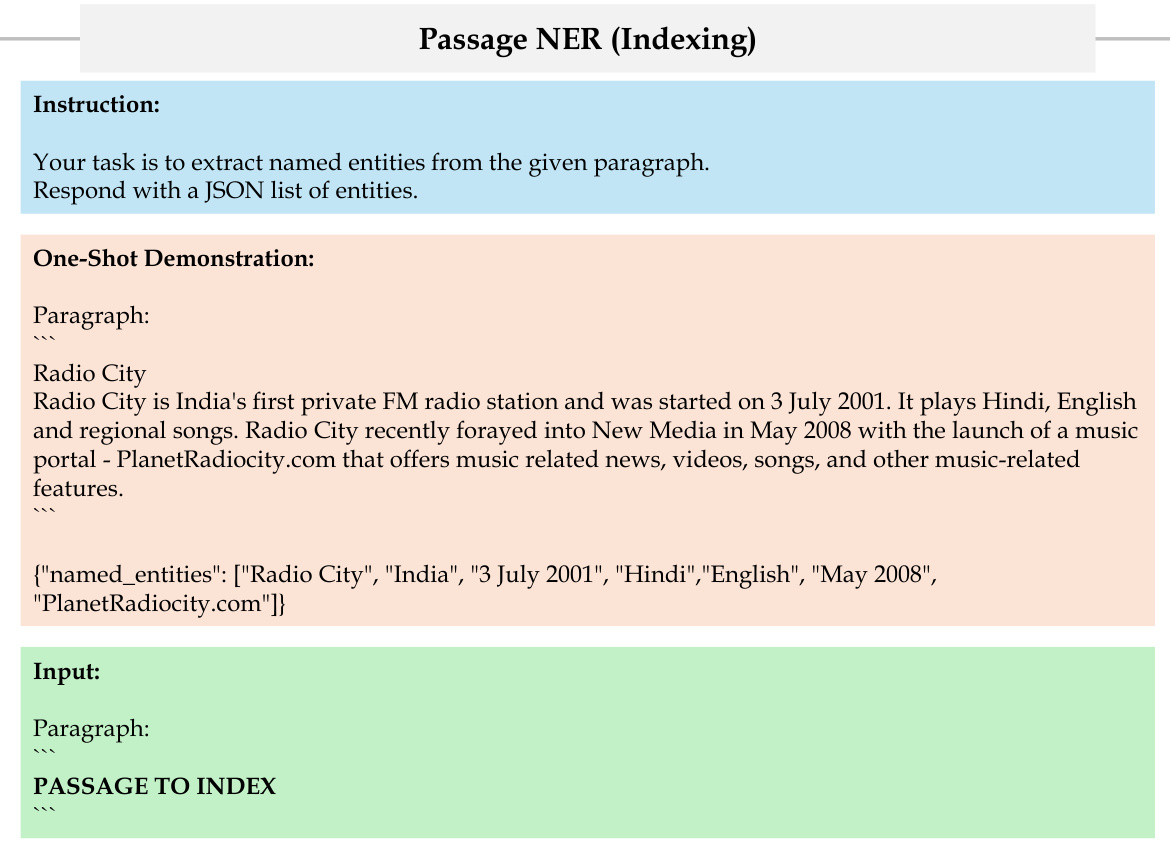
This figure illustrates the HippoRAG methodology, which models the human brain’s long-term memory system. The offline indexing phase mirrors encoding, processing input passages via an LLM to create knowledge graph triples. These are indexed in an artificial hippocampus (KG) aided by a retrieval encoder (simulating the parahippocampal region). During online retrieval, mimicking memory retrieval, an LLM extracts entities from a query, linking them to the hippocampus via retrieval encoders. The Personalized PageRank algorithm then performs multi-hop retrieval.
More on tables

This table presents the results of single-step retrieval experiments on three multi-hop question answering datasets: MuSiQue, 2WikiMultiHopQA, and HotpotQA. It compares the performance of HippoRAG against several baseline methods (BM25, Contriever, GTR, ColBERTv2, RAPTOR, and Propositionizer) using two different retrieval backbones (Contriever and ColBERTv2). The results are reported in terms of Recall@2 and Recall@5, showing the proportion of times the top 2 and top 5 retrieved passages included all relevant passages for answering the multi-hop questions. The table highlights HippoRAG’s superior performance on MuSiQue and 2WikiMultiHopQA and its comparable performance to the baselines on HotpotQA.
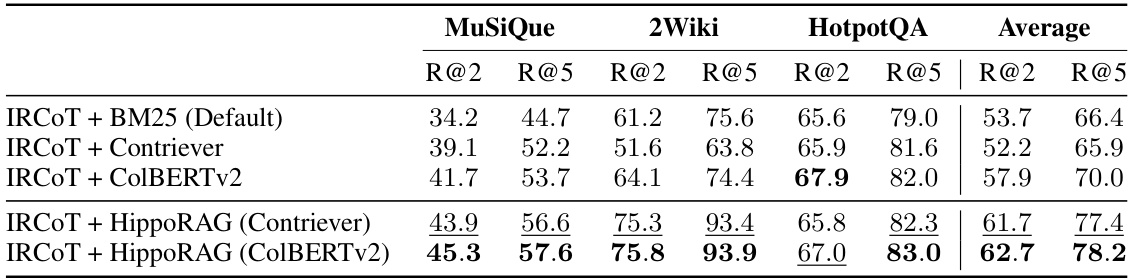
This table presents the results of multi-step retrieval experiments, comparing the performance of integrating HippoRAG with existing multi-step retrieval methods (like IRCOT) across three datasets: MuSiQue, 2WikiMultiHopQA, and HotpotQA. The metrics used are Recall@2 (R@2) and Recall@5 (R@5), indicating the proportion of times the top 2 and top 5 retrieved documents, respectively, included all relevant documents needed to answer the question. The table shows that combining HippoRAG with these methods consistently improves performance over using the multi-step method alone.
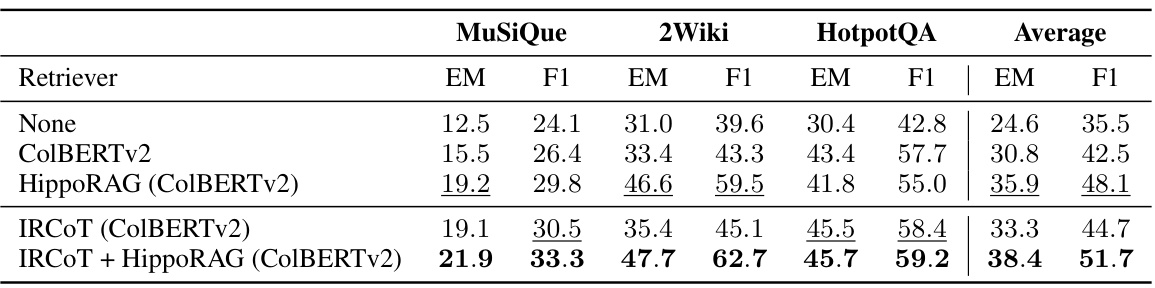
This table presents the Question Answering (QA) performance of different retrieval methods, including the proposed HippoRAG and several baselines. It shows the Exact Match (EM) and F1 scores for QA performance on three datasets: MuSiQue, 2WikiMultiHopQA, and HotpotQA. The table highlights the correlation between improved retrieval performance and improved QA performance, demonstrating that HippoRAG’s retrieval enhancements lead to better QA results. The results are broken down for single-step retrieval methods (rows 1-3) and multi-step retrieval methods (rows 4-5) to showcase the effect of integrating HippoRAG into iterative retrieval approaches.
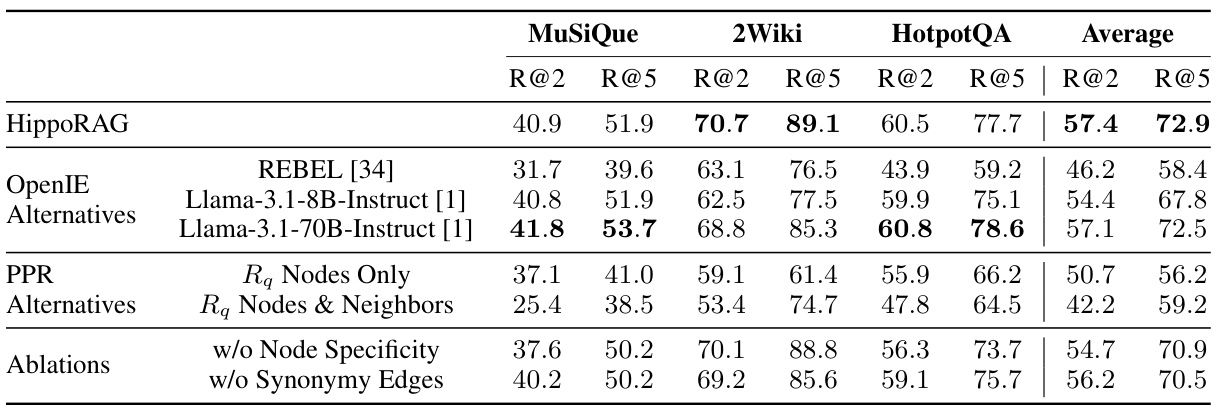
This table presents ablation studies on the HippoRAG model. It shows the performance of the model when different components are replaced with alternatives or when specific features are removed. Specifically, it examines the impact of using different OpenIE methods (REBEL, Llama-3.1-8B, Llama-3.1-70B), alternative PPR approaches (using only query nodes or query nodes and their neighbors), and the effects of removing node specificity and synonymy edges. The results highlight the relative importance of each component in achieving HippoRAG’s strong performance.

This table compares the performance of ColBERTv2 and HippoRAG on three datasets (MuSiQue, 2WikiMultiHopQA, and HotpotQA) using the All-Recall metric. The All-Recall metric measures the percentage of queries where all supporting passages are successfully retrieved. Higher percentages indicate better performance in multi-hop retrieval, showcasing HippoRAG’s ability to retrieve all necessary information in a single step.

This table presents the results of single-step retrieval experiments on three multi-hop question answering datasets: MuSiQue, 2WikiMultiHopQA, and HotpotQA. The performance of HippoRAG is compared against several baselines, including BM25, Contriever, GTR, ColBERTv2, RAPTOR, and Propositionizer. The metrics used are Recall@2 and Recall@5, which measure the proportion of queries for which at least two or five relevant passages are retrieved, respectively. The results show that HippoRAG outperforms all baselines on MuSiQue and 2WikiMultiHopQA, achieving comparable performance on HotpotQA, which is considered a less challenging dataset.

This table presents the single-step retrieval performance of HippoRAG against several strong baselines (BM25, Contriever, GTR, ColBERTv2, RAPTOR, and Propositionizer) on three multi-hop QA datasets: MuSiQue, 2WikiMultiHopQA, and HotpotQA. The results are presented in terms of Recall@2 and Recall@5, demonstrating HippoRAG’s superior performance on MuSiQue and 2WikiMultiHopQA and comparable performance on HotpotQA. The table highlights HippoRAG’s effectiveness even in a single retrieval step, unlike iterative methods which require multiple steps.
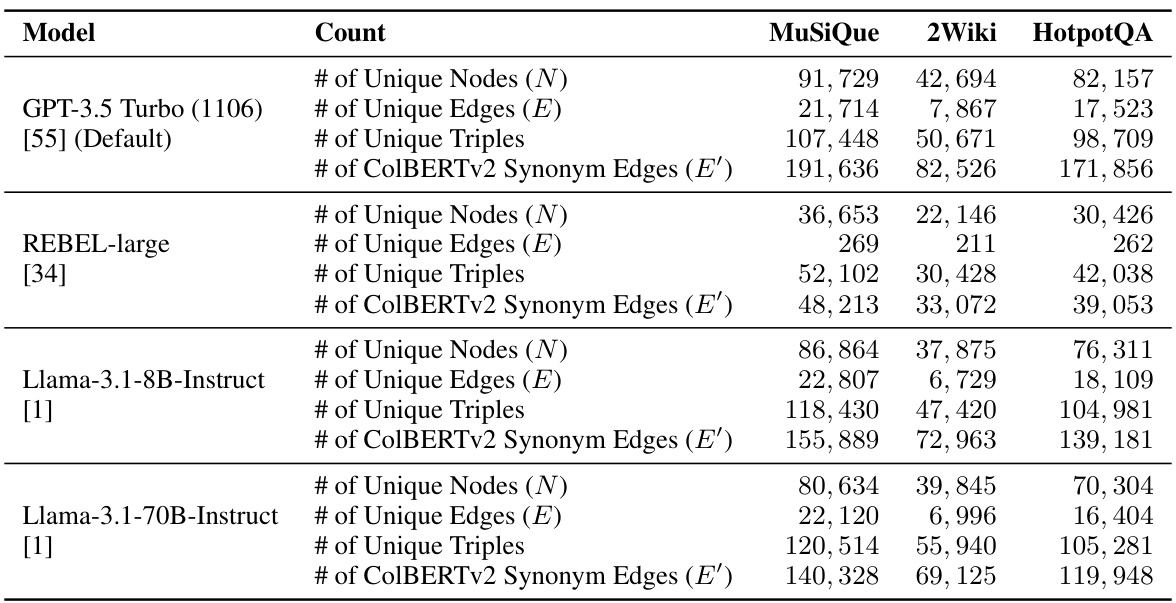
This table presents a comparison of knowledge graph statistics generated using four different OpenIE methods: GPT-3.5 Turbo, REBEL-large, Llama-3.1-8B-Instruct, and Llama-3.1-70B-Instruct. For each model, the table shows the number of unique nodes (N), unique edges (E), unique triples, and ColBERTv2 synonym edges (E’) extracted from three datasets: MuSiQue, 2Wiki, and HotpotQA. The data illustrates the differences in the quantity of knowledge extracted by each model and highlights the varying capabilities of these methods in constructing knowledge graphs for different datasets.
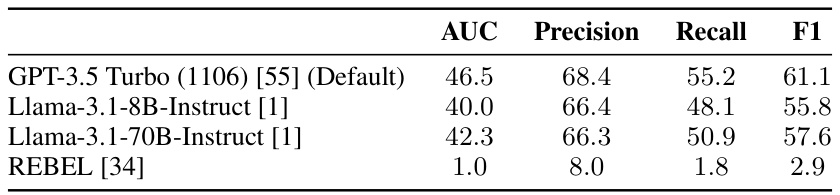
This table presents the results of an intrinsic evaluation of different OpenIE methods. The evaluation uses the CaRB framework on a set of 20 annotated passages. The table shows the AUC, Precision, Recall, and F1 scores for each method, providing a quantitative comparison of their performance in extracting knowledge triples.
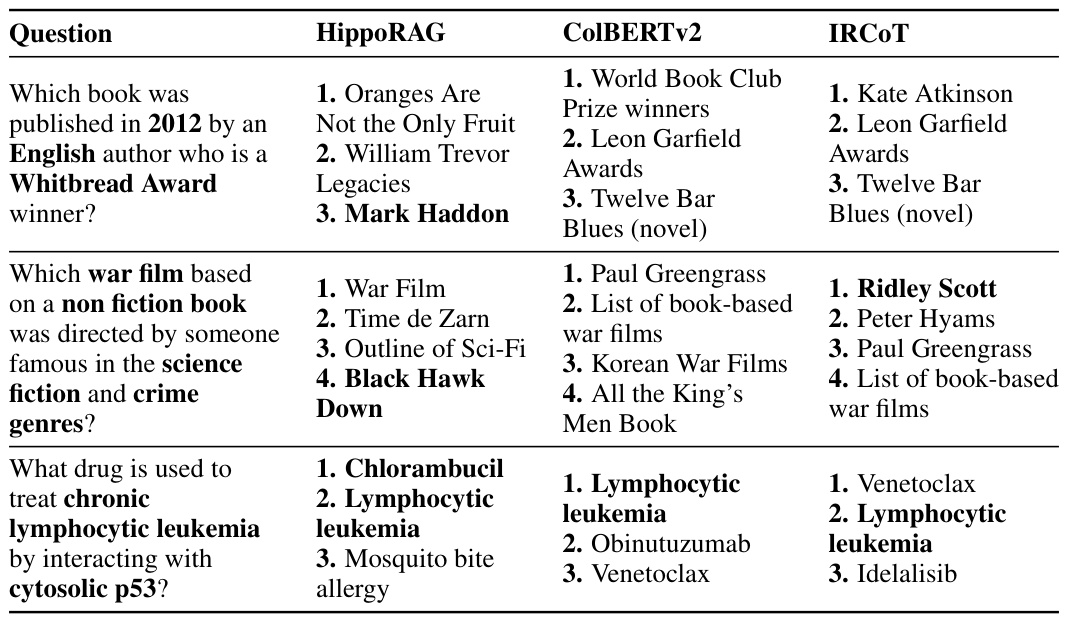
This table presents example results for three different multi-hop questions across three different methods (HippoRAG, ColBERTv2, and IRCOT). The questions are designed to be challenging, requiring the integration of information from multiple passages to find the answer. The table showcases how HippoRAG outperforms the other methods, particularly in situations where knowledge integration across passages is crucial, highlighting its ability to handle path-finding multi-hop questions.

This table shows the breakdown of errors made by the HippoRAG model on the MuSiQue dataset. It categorizes errors into three main types: limitations of the Named Entity Recognition (NER) process, errors in the Open Information Extraction (OpenIE) process, and errors in the Personalized PageRank (PPR) algorithm. The percentages for each error type are provided.

This table presents the results of single-step retrieval experiments on three datasets: MuSiQue, 2WikiMultiHopQA, and HotpotQA. The table compares the performance of HippoRAG against several baseline retrieval methods (BM25, Contriever, GTR, ColBERTv2, RAPTOR, and Propositionizer) using recall@2 and recall@5 as metrics. The results show that HippoRAG significantly outperforms other methods on MuSiQue and 2WikiMultiHopQA and achieves comparable results on HotpotQA, indicating its effectiveness in single-step multi-hop question answering.
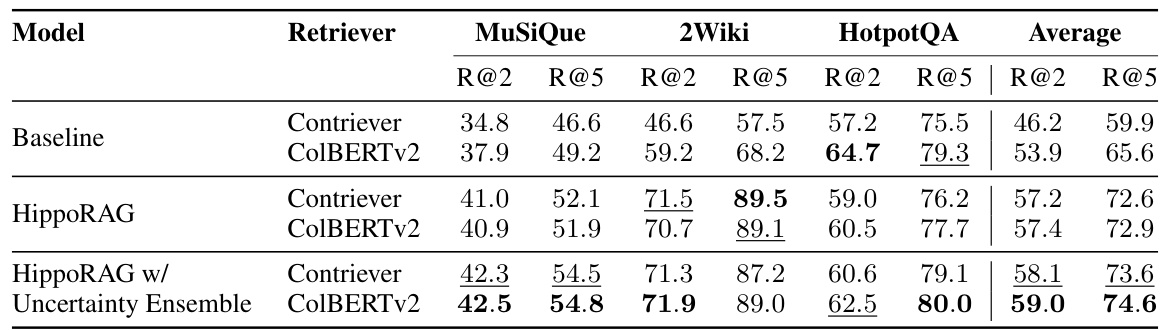
This table presents the results of a single-step retrieval experiment on three datasets: MuSiQue, 2WikiMultiHopQA, and HotpotQA. The performance of HippoRAG is compared against several baselines (BM25, Contriever, GTR, ColBERTv2, RAPTOR, Propositionizer) using Recall@2 and Recall@5 as metrics. The results demonstrate that HippoRAG significantly outperforms other methods on MuSiQue and 2WikiMultiHopQA, while achieving comparable performance on the easier HotpotQA dataset. This highlights HippoRAG’s effectiveness in single-step retrieval for multi-hop question answering, especially in more challenging scenarios.

This table presents the results of multi-step retrieval experiments, comparing the performance of integrating HippoRAG with a standard multi-step retrieval method (IRCoT) against baselines on three datasets (MuSiQue, 2WikiMultiHopQA, and HotpotQA). The metrics used are Recall@2 (R@2) and Recall@5 (R@5), showing the proportion of queries where at least two or five relevant passages, respectively, were retrieved. It demonstrates that HippoRAG and IRCoT provide complementary improvements in multi-hop retrieval.

This table presents the results of a single-step retrieval experiment on three datasets: MuSiQue, 2WikiMultiHopQA, and HotpotQA. It compares the performance of HippoRAG against several baseline retrieval methods (BM25, Contriever, GTR, ColBERTv2, RAPTOR, and Propositionizer). The results are shown in terms of Recall@2 and Recall@5 metrics. The table highlights HippoRAG’s superior performance on MuSiQue and 2WikiMultiHopQA, indicating its effectiveness in single-step multi-hop question answering.

This table presents the results of an intrinsic evaluation of the OpenIE method used in the HippoRAG model. It specifically compares the performance of the OpenIE model on two sets of passages: 10 shortest and 10 longest. The evaluation metrics used are AUC, Precision, Recall, and F1-score, providing insights into the model’s ability to extract accurate and relevant information from passages of different lengths. The results highlight a significant difference in performance based on passage length, showing a potential area for improvement in the model.

This table compares the average API cost and time taken for online retrieval using three different methods: ColBERTv2, IRCOT, and HippoRAG. It highlights HippoRAG’s significant efficiency gains in both cost and time compared to the iterative retrieval method, IRCOT. The cost savings are substantial (0.1$ for HippoRAG vs. 1-3$ for IRCOT) and the speed improvement is also significant (3 minutes for HippoRAG vs. 20-40 minutes for IRCOT).

This table compares the average API cost and time taken for online retrieval using three different methods: ColBERTv2, IRCOT, and HippoRAG. The results are based on processing 1000 queries. It highlights the significant cost and time savings offered by HippoRAG, especially compared to the iterative method, IRCOT. HippoRAG is shown to be dramatically more efficient in terms of both time and cost for online retrieval.
Full paper#