↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many machine learning models assume that training and test data share the same distribution, but this is often not true in real-world scenarios, leading to distribution shift. Previous research has primarily focused on offline settings where a single shift occurs. Online label shift adaptation is more challenging because the distribution shifts continuously over time. Existing methods mainly focus on updating the final layers of pre-trained classifiers, but this approach may be limited. Missing labels at test-time further complicates the problem.
This paper proposes a novel method called OLS-OFU (Online Label Shift adaptation with Online Feature Updates) which improves on existing methods. OLS-OFU leverages self-supervised learning to refine the feature extraction process at test time, using unlabeled data to adapt to changing distributions. This approach is theoretically sound, maintaining a similar convergence guarantee as other online learning methods. Empirical evaluations show that OLS-OFU significantly improves over existing methods, with gains comparable to those methods’ improvements over simple baselines, demonstrating its robustness across scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on online label shift adaptation because it introduces a novel method that significantly improves existing techniques. The research is relevant to current trends in online machine learning and self-supervised learning, opening new avenues for improving model adaptability in dynamic environments. The consistent improvements across various datasets and algorithms highlight the method’s robustness and general applicability.
Visual Insights#

This figure illustrates the process of online distribution shift adaptation. It starts with an offline training stage using labeled data from Ptrain distribution to train a model f0. Then, in the online test stage, unlabeled test samples from Ptest distribution arrive sequentially. At each time step t, predictions are made on the unlabeled samples using the current model ft. The model is then updated to ft+1 using algorithm A. The figure highlights the assumption of equal conditional distributions (Ptest(x|y) = Ptrain(x|y)) for online label shift and the existence of a transformation h making the conditional distribution equal in the feature space for online generalized label shift.

This table presents a comparison of the average error and computation time for six different online label shift (OLS) methods against the proposed OLS-OFU method. The OLS-OFU method is tested with different frequencies (τ) of feature updates using rotation degree prediction as the self-supervised learning technique. The table helps to demonstrate the effectiveness and efficiency gains of OLS-OFU compared to existing methods.
In-depth insights#
Online Label Shift#
Online Label Shift (OLS) presents a significant challenge in machine learning, focusing on scenarios where the label distribution changes continuously over time, making timely label acquisition difficult. The core issue lies in adapting models to these evolving distributions, especially with the scarcity of labeled data in online settings. Existing OLS methods often concentrate on retraining parts of a pre-trained model or re-weighting predictions, but often neglect the potential of improving feature representations. The research explores leveraging unlabeled data at test time via self-supervised learning to refine feature extraction, enhancing both sample efficiency and adaptation to label shifts. This approach offers improvements over methods that solely address prediction adjustments, demonstrating that enhancing feature representations is just as crucial for effective adaptation as modifying the prediction layers. Theoretical guarantees for the proposed method are explored, maintaining online regret convergence while incorporating improved features. Empirically, this combined approach shows substantial performance gains over existing techniques, highlighting the importance of adaptive feature extraction in solving online label shift problems.
Feature Updates#
The concept of ‘Feature Updates’ in the context of online label shift adaptation is a powerful innovation. Instead of solely focusing on recalibrating the final classifier layer, the approach dynamically refines the feature extraction process itself using unlabeled test-time data. This is achieved via self-supervised learning, thereby enhancing the model’s ability to adapt to evolving data distributions. The benefits are two-fold: improved sample efficiency and enhanced adaptability to label shifts, especially crucial in generalized label shift where underlying feature distributions change. Theoretically, the method maintains comparable online regret convergence to existing methods while leveraging the improved feature representation. Empirically, it demonstrates substantial performance gains over traditional methods, indicating that adapting feature extraction during the test phase is as impactful as refining the classifier alone. The approach’s flexibility to seamlessly integrate with diverse existing OLS algorithms is another key advantage, promising broader applications and future improvements.
SSL Integration#
The integration of self-supervised learning (SSL) is crucial to the paper’s success. It leverages unlabeled test-time data to enhance feature representations, a key innovation addressing the limitations of existing online label shift adaptation methods that focus solely on classifier adjustments. By carefully designing the algorithm to incorporate SSL, the authors maintain theoretical guarantees, satisfying underlying assumptions of online learning methods while avoiding excessive computational overhead. Self-supervision improves sample efficiency and enables adaptation to label shift, particularly in generalized label shift scenarios where feature transformations are unknown. The choice of SSL method is shown to impact performance, with Rotation Degree Prediction, Entropy Minimization, and MoCo all evaluated. The frequency of SSL updates is carefully considered, balancing the benefits of improved feature extraction against computational costs through batch accumulation. Overall, the SSL integration is a pivotal component showcasing how unlabeled data can significantly boost online adaptation in the presence of label shifts.
Empirical Gains#
An empirical gains analysis in a research paper would assess the practical improvements achieved by a new method compared to existing approaches. It would involve a rigorous comparison across multiple datasets and experimental settings. Key aspects to consider include the magnitude of improvement, demonstrated through metrics like accuracy or F1-score, statistical significance, ensuring the observed gains are not due to random chance, and generalizability, showing consistent gains across various datasets and conditions. The analysis should also account for computational costs and any additional complexity. A high-quality analysis should present both quantitative results and visualizations to effectively communicate the findings. It should also address potential limitations and confounding factors, providing a balanced and insightful assessment of the empirical gains.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending OLS-OFU to handle covariate shift scenarios, beyond the generalized label shift addressed, is a crucial next step. This would require developing novel techniques for adapting feature extractors when both the label and covariate distributions change. Investigating the impact of different self-supervised learning (SSL) methods on OLS-OFU performance should also be pursued. Benchmarking against a wider variety of online learning algorithms would enhance the evaluation and comparison. Furthermore, exploring the theoretical properties of OLS-OFU under various assumptions about the data distribution and the nature of the shift could provide deeper understanding and improved algorithms. Finally, applying OLS-OFU to high-dimensional data and real-world applications is essential for validating its practical impact and identifying potential limitations.
More visual insights#
More on figures
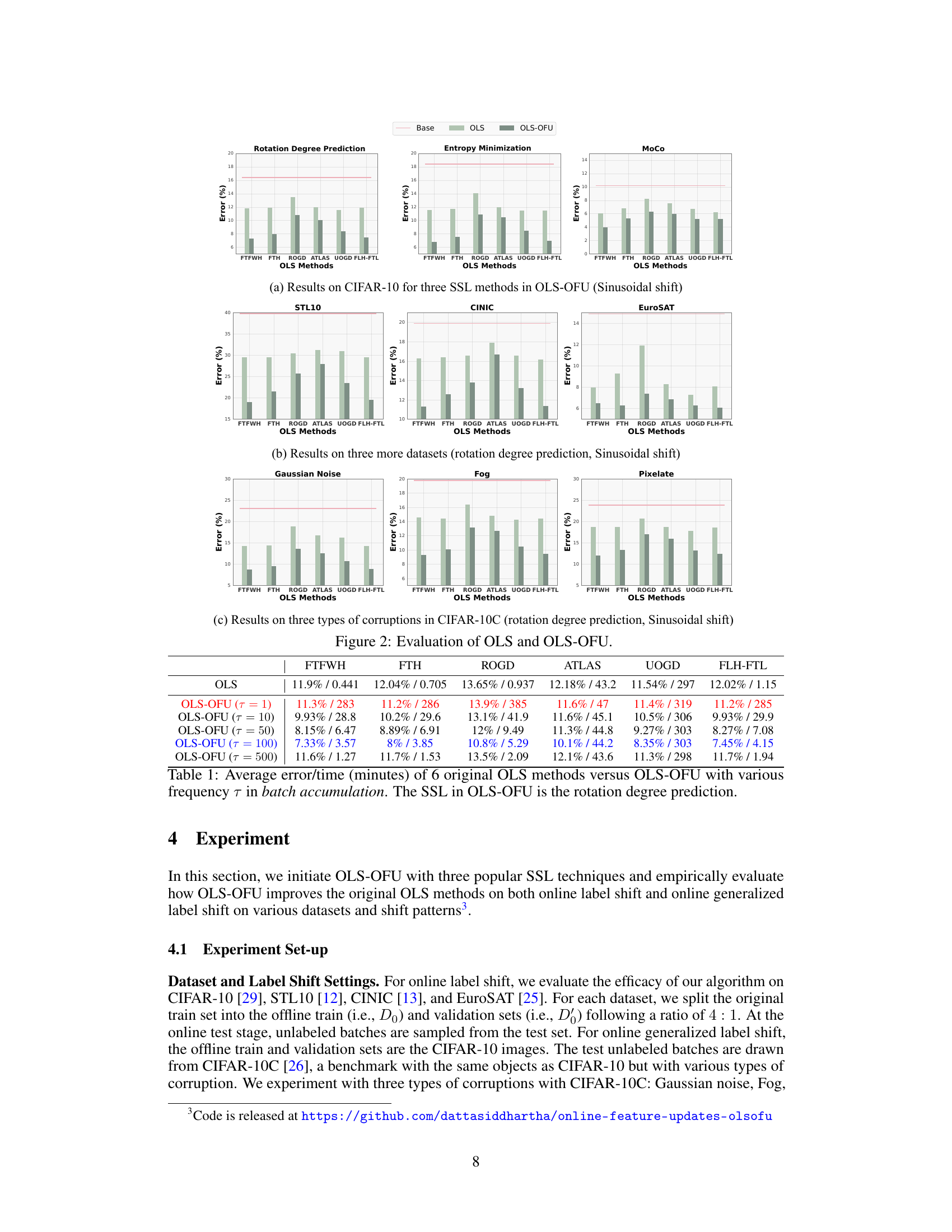
The figure shows the performance comparison between OLS-OFU and OLS methods on CIFAR-10, STL-10, CINIC-10, EuroSAT, and CIFAR-10-C datasets under different label shift scenarios. OLS-OFU is tested with three self-supervised learning (SSL) methods: rotation degree prediction, entropy minimization, and MoCo. The results demonstrate that OLS-OFU achieves substantial improvements over existing OLS methods in various settings, particularly with the sinusoidal shift pattern. The improvements are consistent across different datasets and SSL techniques. The plots compare the error rates of OLS-OFU with various τ (the frequency parameter) against the error rates of baseline and OLS methods. Each subfigure shows results for a specific dataset or corruption type.
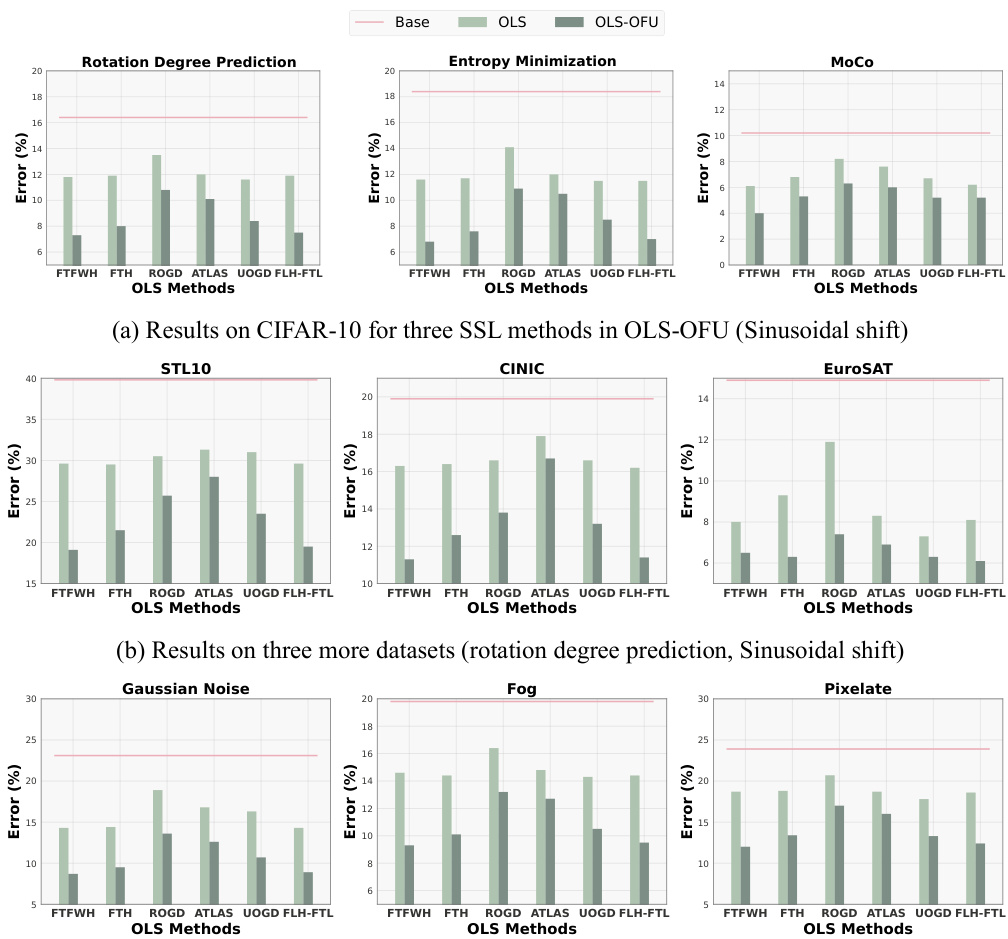
This figure shows the comparison of the performance of OLS and OLS-OFU methods on several datasets under different online label shift settings. Subfigure (a) presents results on CIFAR-10 using three different self-supervised learning (SSL) methods within OLS-OFU under a sinusoidal shift. Subfigures (b) and (c) extend the evaluation to other datasets and corruption types of CIFAR-10C, respectively, again under a sinusoidal shift. The results demonstrate that OLS-OFU consistently outperforms OLS across various datasets, SSL methods, and shift patterns.
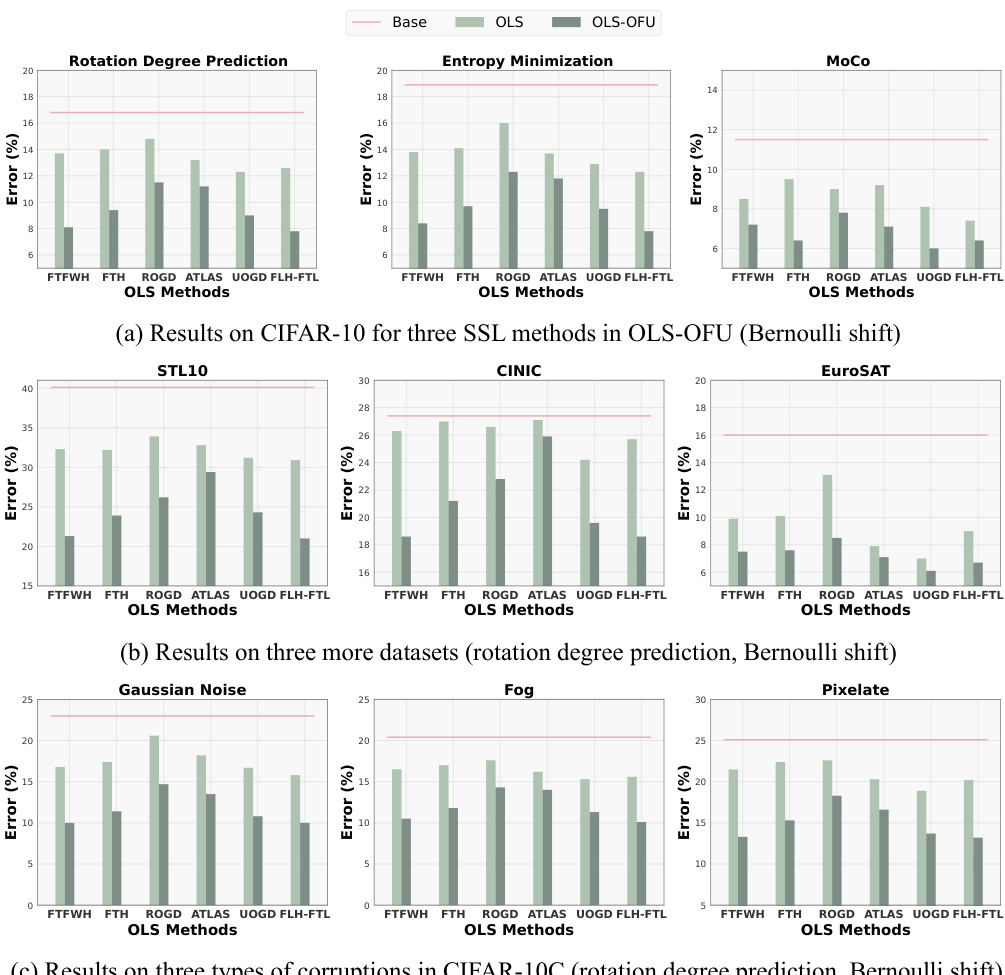
The figure shows the performance comparison between OLS-OFU and OLS methods on CIFAR-10 and other datasets under sinusoidal shift. Subfigure (a) presents results on CIFAR-10 for three SSL methods in OLS-OFU. Subfigure (b) shows results on three more datasets using rotation degree prediction as SSL. Subfigure (c) displays the results on three types of corruptions in CIFAR-10C. The results demonstrate that OLS-OFU achieves substantial improvements over existing OLS methods.
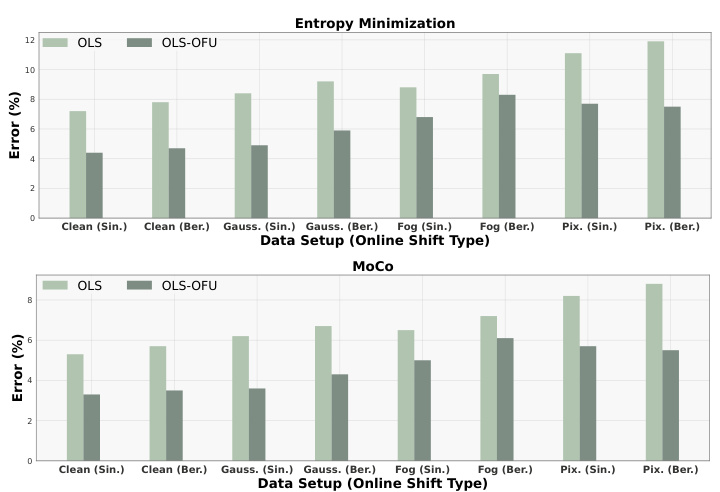
The figure evaluates the performance of OLS and OLS-OFU methods on various datasets and shift patterns. Subfigure (a) shows results on CIFAR-10 using three self-supervised learning (SSL) techniques (Rotation Degree Prediction, Entropy Minimization, MoCo) within OLS-OFU under a sinusoidal shift. Subfigures (b) and (c) extend the evaluation to three additional datasets (STL10, CINIC, EuroSAT) and three types of corruptions in CIFAR-10C (Gaussian Noise, Fog, Pixelate), respectively, all under sinusoidal shifts. The results demonstrate that OLS-OFU consistently outperforms OLS across datasets, SSL techniques and shift types.
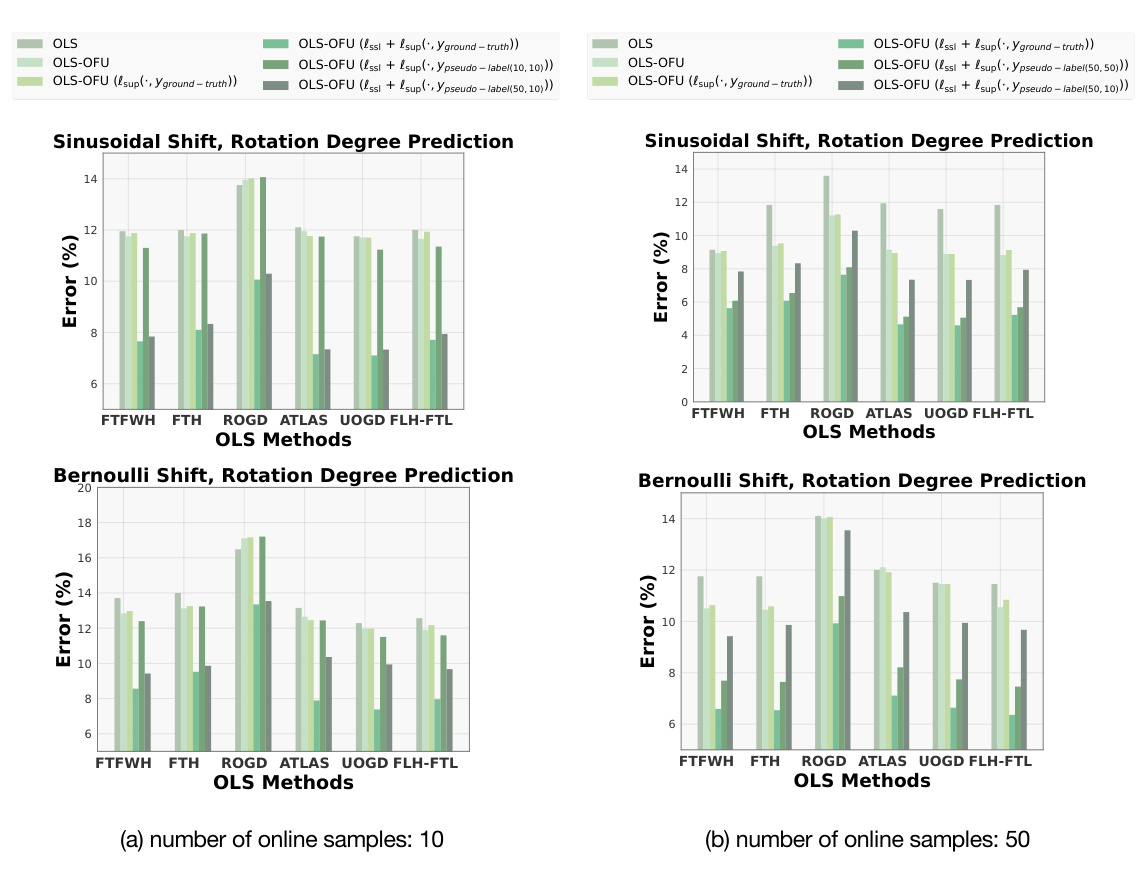
This figure compares the performance of six different online label shift (OLS) methods against the proposed OLS-OFU method. Subfigure (a) shows the results on CIFAR-10 for three self-supervised learning (SSL) methods used in OLS-OFU under a sinusoidal shift. Subfigure (b) extends the comparison to three additional datasets (STL-10, CINIC-10, EuroSAT) using rotation degree prediction as the SSL method under a sinusoidal shift. Subfigure (c) presents the performance when the datasets are corrupted (CIFAR-10C) with three different types of corruption. In each subfigure, OLS-OFU consistently demonstrates significant improvements compared to the baseline and other OLS methods.
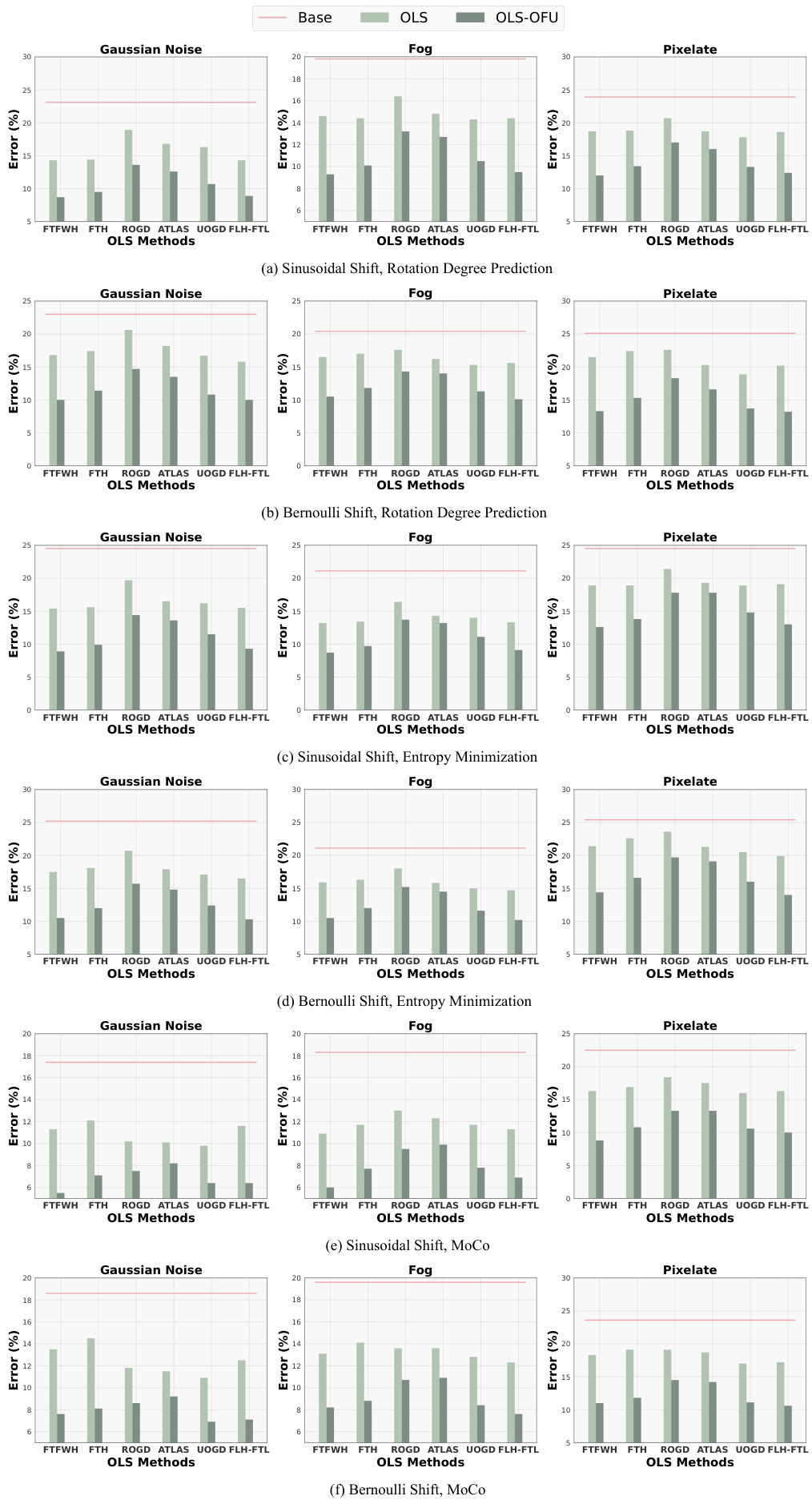
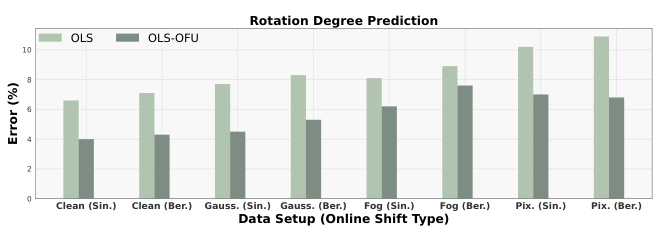
This figure shows the comparison of the performance of different online label shift (OLS) methods and the proposed OLS-OFU method. The results are presented across various datasets and corruption types under two different online shift patterns (sinusoidal and Bernoulli). Subfigures (a), (b), and (c) illustrate results for CIFAR-10, while additional datasets are included in (b) and (c). Each subfigure shows error rates for various OLS algorithms with and without the proposed online feature updates (OFU) across multiple datasets and SSL methods.
More on tables

This table presents the results of an ablation study conducted to evaluate the impact of the order in which the online label shift (OLS) algorithm and the feature update step are performed within the OLS-OFU framework. The study compares the performance of OLS-OFU when the feature extractor is updated before or after the OLS step, using two different frequencies of feature updates (τ = 1 and τ = 100). The results show that updating the feature extractor after the OLS step consistently yields better performance.

This table presents the average error and computation time (in minutes) for six existing online label shift (OLS) methods and the proposed OLS-OFU method. The OLS methods are compared against OLS-OFU using various accumulation frequencies (τ). The self-supervised learning (SSL) technique used within OLS-OFU is rotation degree prediction. The table shows how OLS-OFU performs compared to existing methods under different accumulation frequencies, illustrating its efficiency and accuracy improvements.

This table presents the average error and computation time (in minutes) for six different online label shift adaptation (OLS) methods and the proposed OLS-OFU method. The OLS methods are compared against OLS-OFU under different update frequencies (τ) of the feature extractor. The self-supervised learning (SSL) technique used within OLS-OFU is rotation degree prediction.

This table presents a comparison of the average error and computation time (in minutes) for six different online label shift adaptation (OLS) methods and the proposed OLS-OFU method. The OLS methods are FTFWH, FTH, ROGD, ATLAS, UOGD, and FLH-FTL. OLS-OFU is tested with different values for the batch accumulation frequency parameter (τ = 1, 10, 50, 100, 500). The self-supervised learning (SSL) technique used in OLS-OFU is rotation degree prediction. The table shows that OLS-OFU generally outperforms the baseline OLS methods in terms of accuracy, and the optimal value for τ balances accuracy and computational cost.
Full paper#