↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Human-AI collaboration is difficult because humans behave unpredictably, changing strategies and levels of engagement. Current approaches often try to model this unpredictable behavior directly, which is difficult and prone to errors. This makes it hard to build AI systems that collaborate effectively with people.
This paper proposes a new approach called Collaborative Bayesian Policy Reuse (CBPR). Instead of modeling human behavior, CBPR focuses on identifying the underlying “meta-tasks” humans perform within a specific task. For example, in a cooking game, meta-tasks could be chopping vegetables, stirring a pot, or serving food. CBPR then trains separate AI agents, each specialized for a different meta-task. This allows the system to adapt more easily to changes in how humans collaborate, resulting in significantly improved collaboration performance in experiments using a cooking game simulator and with real human partners.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in human-AI collaboration: the non-stationary nature of human behavior. By introducing a novel framework that focuses on identifying meta-tasks instead of directly modeling human behavior, it offers a more robust and adaptable approach to building effective collaborative AI agents. This work opens new avenues for research in human-AI interaction, particularly in scenarios involving complex tasks and diverse human collaborators. The theoretical guarantees and empirical results presented strongly support the effectiveness of the proposed method.
Visual Insights#
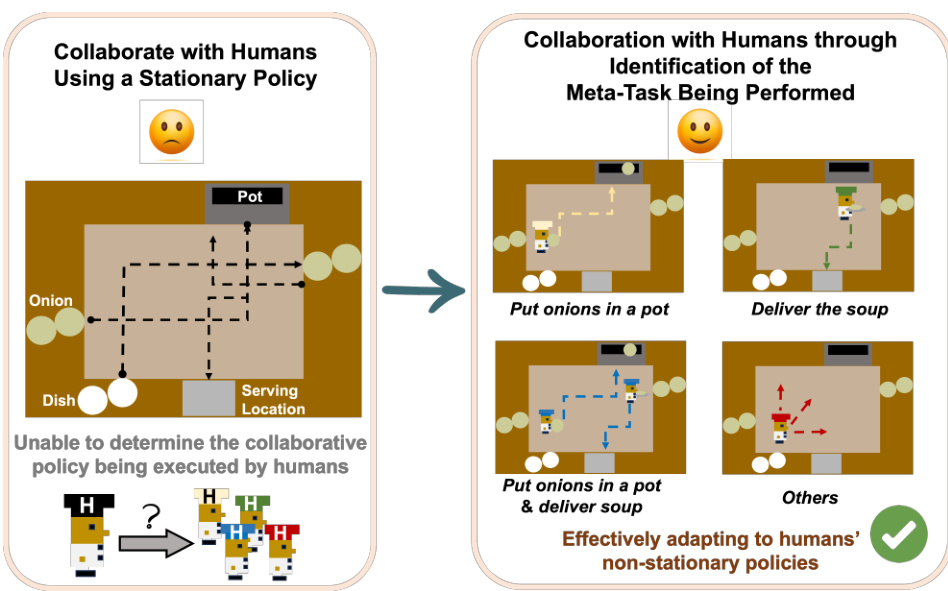
This figure illustrates the core idea of the paper by contrasting two approaches to human-AI collaboration. The left side shows the limitations of traditional methods using a single stationary policy, highlighting the difficulty in adapting to non-stationary human behavior. The right side showcases the proposed method, which focuses on identifying meta-tasks to achieve more effective and adaptable collaboration. The figure uses a visual metaphor of a cooking game to illustrate the concept.
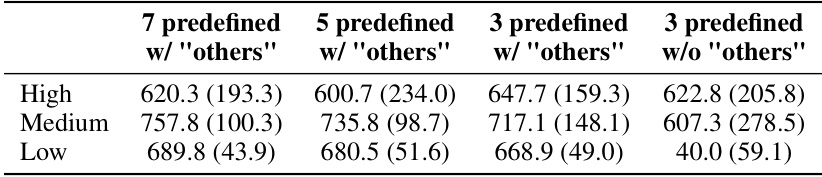
This table presents the results of an ablation study on the number of predefined meta-tasks used in the CBPR framework. It shows the mean reward achieved over 10 episodes by agents with high, medium, and low skill levels when using different numbers of meta-tasks, including a set with and without the ‘others’ category which represents tasks not explicitly modeled.
In-depth insights#
Meta-Task Collab#
The concept of “Meta-Task Collab” suggests a paradigm shift in human-AI collaboration. Instead of focusing on directly modeling unpredictable human behavior, the approach leverages the identification of underlying meta-tasks. These are higher-level goals or patterns in human actions within a specific collaborative context. By identifying these meta-tasks, the AI can select pre-trained policies optimized for each, adapting more effectively to the diverse strategies employed by human collaborators. This method bypasses the complexity of continuously modeling shifting human behavior and instead focuses on matching the AI’s actions to the overall intent, resulting in more robust and efficient collaboration. This framework of meta-task identification and policy reuse has significant potential to enhance human-AI teamwork in various domains, showcasing a more adaptable and flexible approach to AI collaboration than traditional methods reliant on single stationary policies.
Bayesian Policy Reuse#
Bayesian Policy Reuse (BPR) is a transfer learning technique that leverages prior knowledge from previously learned policies to accelerate learning in new tasks. It’s particularly useful when dealing with non-stationary environments or tasks with similar underlying structures. In such cases, the algorithm maintains a posterior distribution over possible policies and adapts its selection based on observed outcomes. The Bayesian approach allows for robust decision-making under uncertainty and efficiently incorporates new information. Key strengths include adaptability to changing dynamics and the reduction in training time and data required. A major application of BPR lies in multi-agent systems, particularly where interaction with human partners necessitates handling unpredictable behavior. However, challenges exist in effectively modelling complex human behavior and efficiently scaling to high-dimensional spaces. Future improvements may focus on improving human behavioral models and developing more efficient algorithms for high-dimensional spaces.
Overcooked Results#
The Overcooked experimental results section would likely detail the performance of the proposed CBPR (Collaborative Bayesian Policy Reuse) framework against various baselines in the Overcooked cooking game. Key aspects to look for would include comparisons against standard approaches like Behavioral Cloning, Fictitious Co-play, and Self-Play. The results should demonstrate CBPR’s superior ability to adapt to non-stationary human behavior, showing better performance with varied human strategies or skill levels, potentially measured by average score or success rate. There would likely be breakdowns of results across different Overcooked game layouts (maps), examining how CBPR handles diverse collaborative challenges. Statistical significance of the results, possibly using t-tests or other statistical measures, would be critical to support the claims of improved performance. Furthermore, analysis of specific agent behaviors or game dynamics, potentially visualized with graphs or videos, could provide further insights into the efficacy and mechanics of CBPR. Finally, the results might incorporate human subject studies showing how real humans perceive and collaborate with the CBPR agent compared to others. Ablation studies, varying parameters like the size of the human behavior queue or the belief update method, could illuminate the framework’s sensitivity to different design choices.
Non-Stationary Agents#
The concept of “Non-Stationary Agents” in the context of AI collaboration highlights a crucial challenge: human unpredictability. Unlike AI agents which follow fixed strategies, humans exhibit diverse behaviors and adapt their approaches, leading to non-stationary dynamics in human-AI team performance. This non-stationarity renders traditional AI training methods insufficient. To effectively collaborate, AI agents must move beyond fixed policies and embrace adaptive strategies which can dynamically adjust to human partner behavior. This necessitates new training paradigms which prioritize not just high average performance, but also robustness and flexibility to handle unexpected shifts in human actions and strategies. Successfully addressing non-stationary agents demands developing algorithms capable of learning and reacting efficiently within constantly changing environments.
Future of CBPR#
The future of Collaborative Bayesian Policy Reuse (CBPR) looks promising, particularly in addressing the challenges of non-stationary human-AI collaboration. Extending CBPR to more complex scenarios beyond the Overcooked simulation, such as autonomous driving or healthcare, is a key area for future research. This requires developing robust methods for identifying and modeling relevant meta-tasks in these domains. Incorporating more sophisticated human behavior modeling techniques, possibly using hybrid approaches that combine rule-based reasoning with machine learning, could significantly enhance CBPR’s adaptability. Furthermore, exploring different policy reuse strategies beyond Bayesian methods could lead to more efficient and effective collaboration. Investigating the theoretical properties of CBPR in more general settings than the current NS-MDP framework, might yield valuable insights and improvements. Finally, addressing the computational cost associated with managing a large library of policies is essential for the practical deployment of CBPR in real-world applications. This might involve advanced techniques such as policy compression or meta-learning.
More visual insights#
More on figures

The figure illustrates the CBPR (Collaborative Bayesian Policy Reuse) framework, divided into offline and online phases. The offline phase involves building a meta-task library, training AI policies for each meta-task, and creating a performance model. The online phase shows the real-time collaboration process: (a) human action data is collected, (b) the current meta-task is inferred, (c) the optimal AI policy is selected based on the performance model and inferred meta-task, and (d) the AI takes action accordingly.

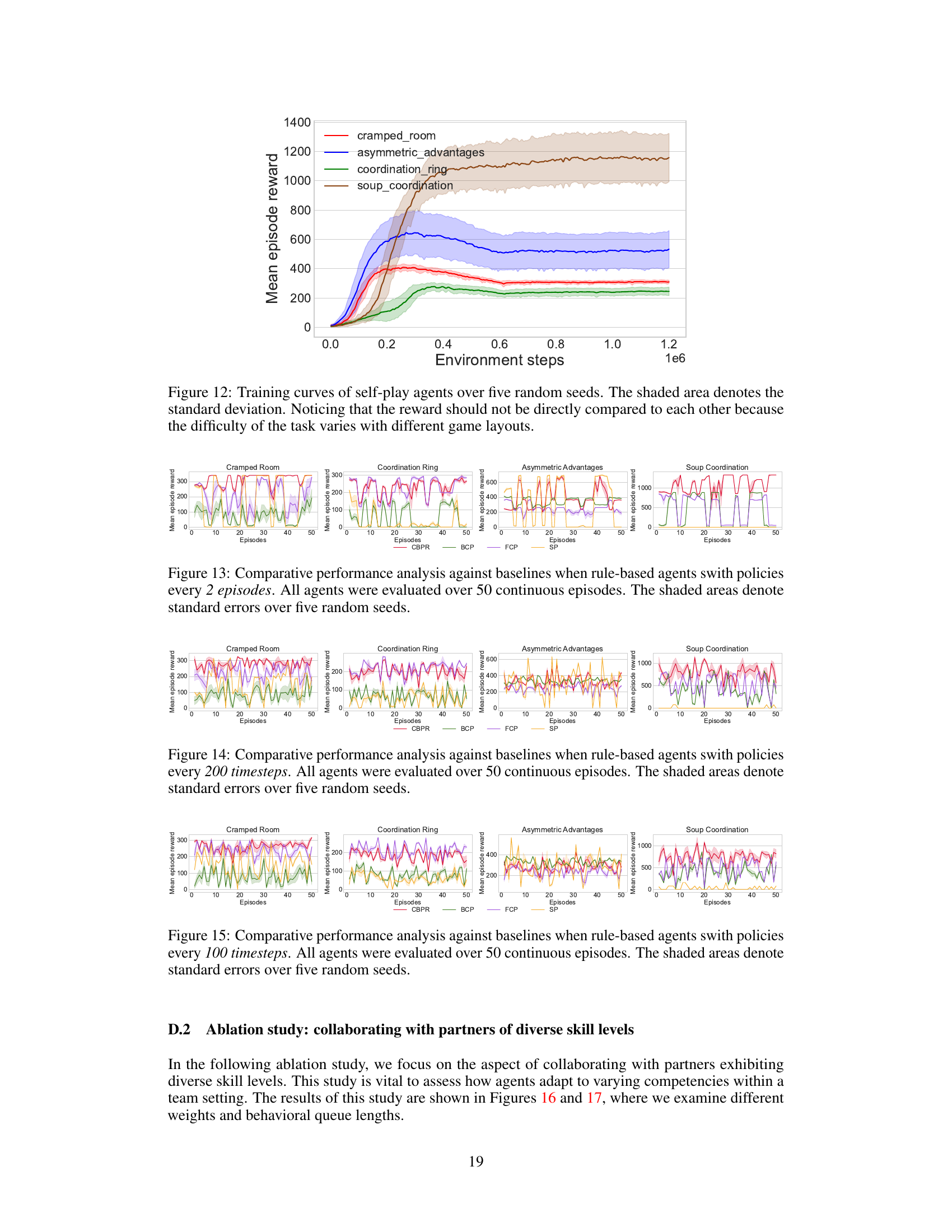
This figure compares the performance of CBPR against three baselines (BCP, FCP, and SP) across four different Overcooked game layouts. The agents’ rule-based policies are switched every episode to simulate non-stationary human behavior. CBPR consistently outperforms the baselines, demonstrating its ability to adapt to dynamic changes in partner strategies. The shaded areas represent the standard deviation across five different random seeds, indicating the consistency of the results.
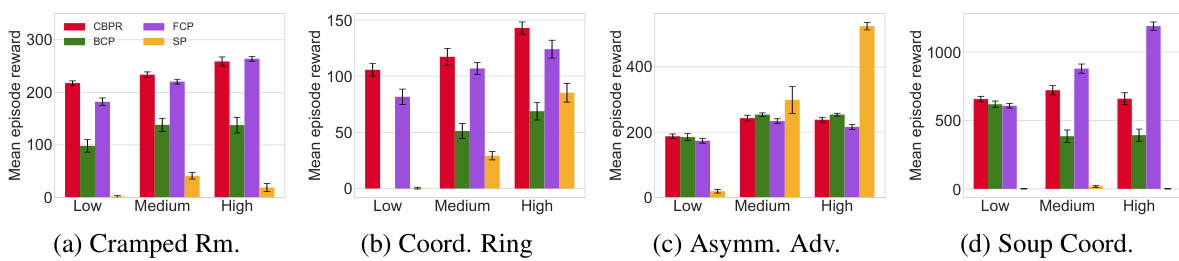
This figure shows the mean episodic rewards achieved by CBPR and three baseline methods (BCP, FCP, and SP) when collaborating with partners of varying skill levels (low, medium, and high) across four different Overcooked game layouts. Error bars represent the 95% confidence intervals. The results demonstrate CBPR’s superior performance, particularly when working with lower-skilled partners. The performance difference is less pronounced in layouts where agents’ movements are not hindered by each other (Asymmetric Advantage and Soup Coordination).
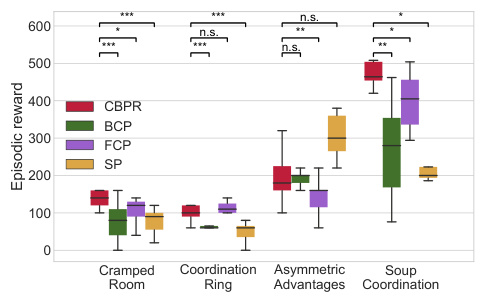
This figure compares the performance of CBPR against three baselines (BCP, FCP, and SP) when collaborating with partners of varying skill levels (low, medium, and high). The box plots show the distribution of episodic rewards across four different game layouts (Cramped Room, Coordination Ring, Asymmetric Advantages, and Soup Coordination). Error bars represent 95% confidence intervals. The results demonstrate CBPR’s superior performance in most cases, especially when collaborating with lower-skilled partners.

This figure shows a case study comparing the performance of CBPR, FCP, and BCP agents in a collaborative cooking scenario. The figure highlights the adaptive behavior of the CBPR agent, its ability to adjust its actions based on the human partner’s actions, and the contrasting rigid and less effective approaches of the FCP and BCP agents.

This figure shows the ablation study on the length of the human behavior queue (l) in the CBPR algorithm. It compares the performance across three different layouts (Coordination Ring, Asymmetric Advantage, and Soup Coordination) with varying queue lengths (l=5, l=10, l=20, l=50) and skill levels (Low, Medium, High). The error bars represent the 95% confidence intervals. The results illustrate the effect of the length of the queue on the algorithm’s ability to learn and adapt to the varying behaviors of human partners.

This figure shows the four different game layouts used in the Overcooked experiments. Each layout presents a unique set of challenges in terms of kitchen layout and ingredient placement, requiring varying levels of teamwork and coordination between players. The image highlights the differences in starting positions, ingredient locations, and the overall flow of the kitchen in each environment. It also shows the reward structure and cooking time differences among the layouts.
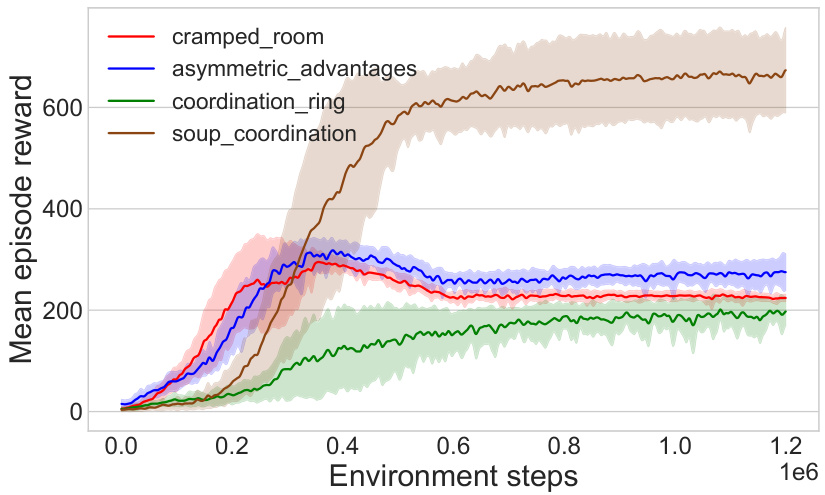
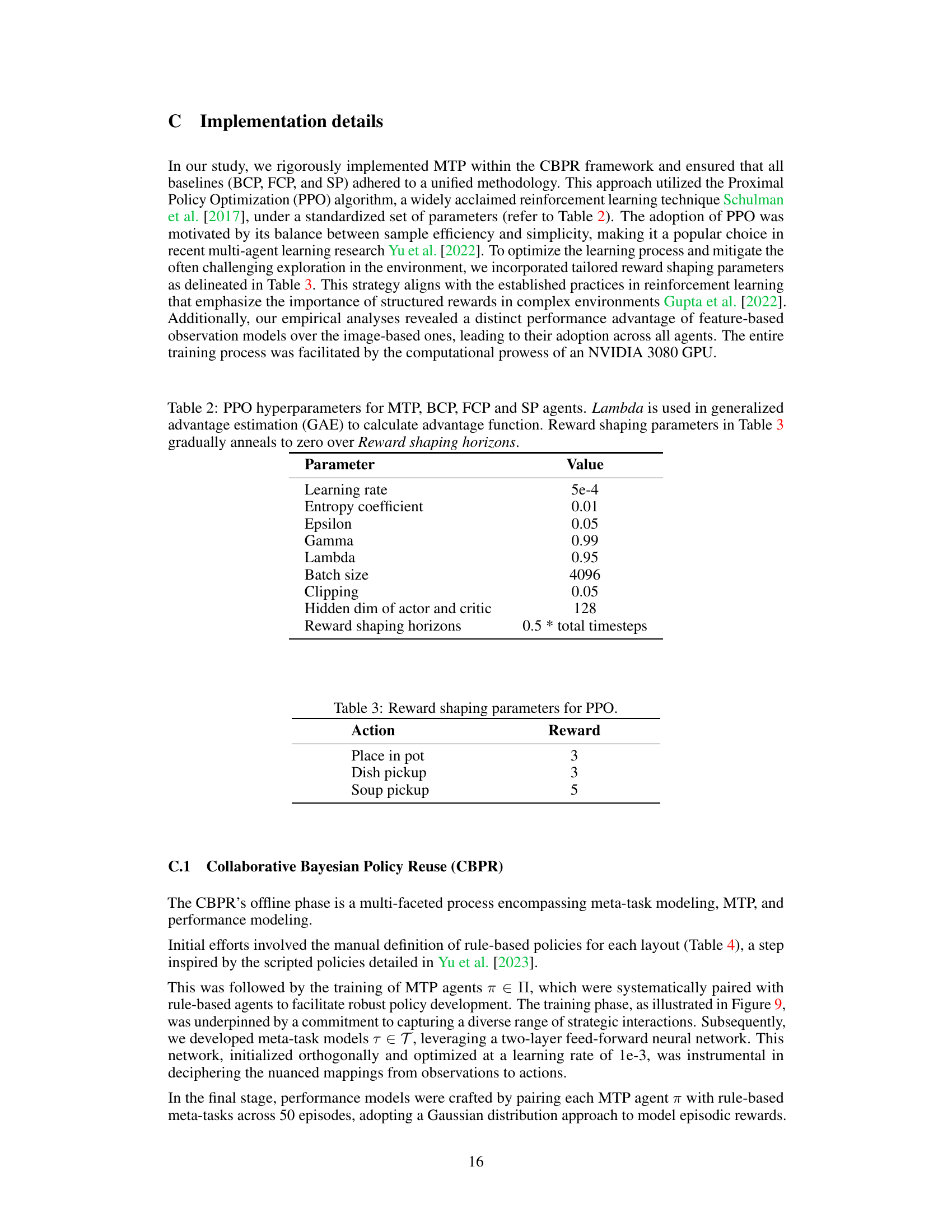
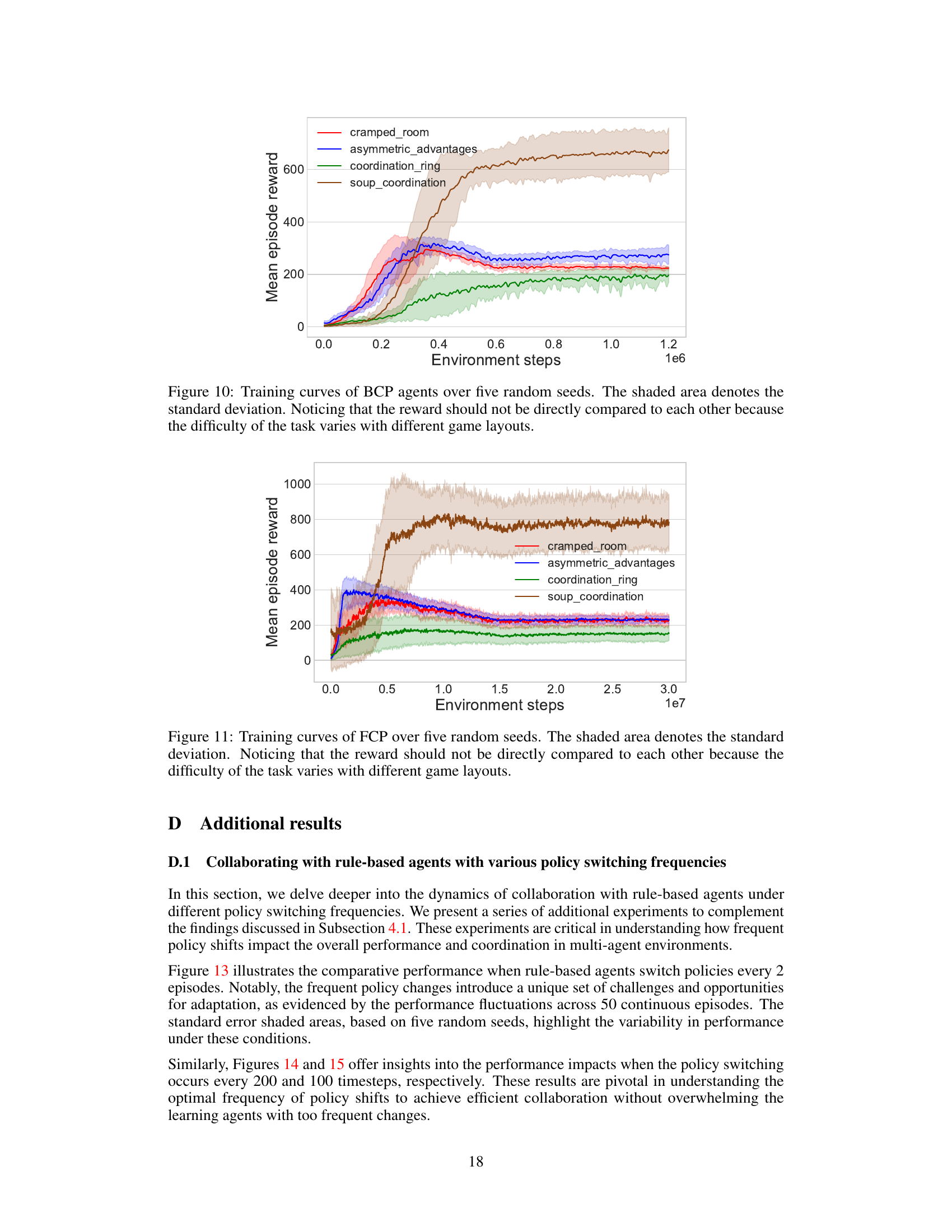
This figure shows the training curves for Behavior Cloning Play (BCP) agents across different Overcooked game layouts. The x-axis represents the number of environment steps during training, and the y-axis represents the mean episodic reward. Each line represents a different game layout, and the shaded region shows the standard deviation across five random seeds. The caption notes that direct reward comparison across layouts is inappropriate due to varying difficulty levels.
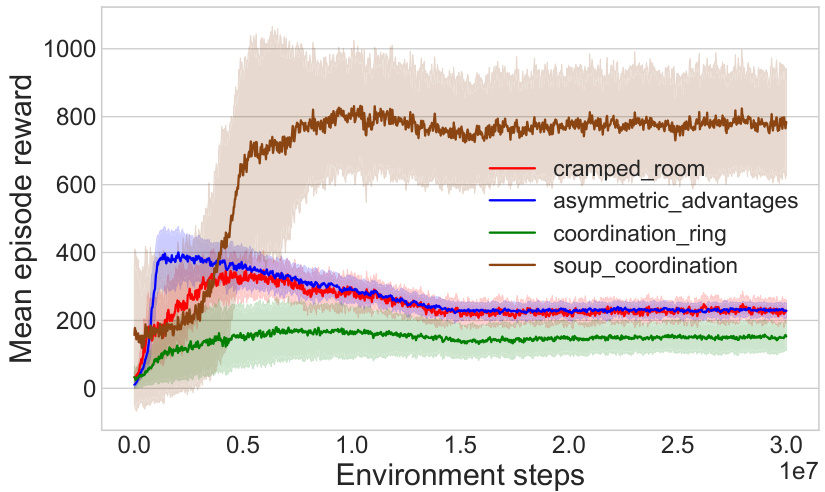
This figure shows the training curves for Behavior Cloning Play (BCP) agents across four different Overcooked game layouts. The curves represent the average episodic reward over training time, and the shaded area represents the standard deviation across five different random seeds. The caption notes that direct comparison of reward values between layouts isn’t appropriate due to varying difficulty levels in each layout.
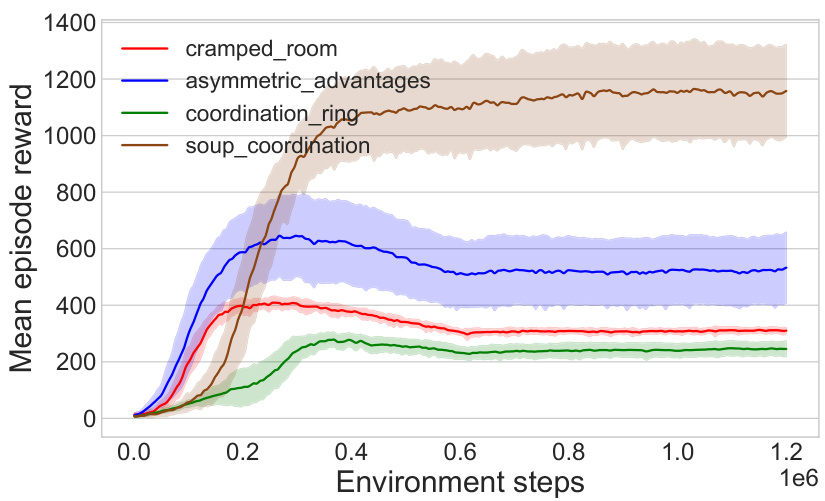
This figure shows the training curves for Behavior Cloning Play (BCP) agents across five different random seeds for four different Overcooked game layouts. The shaded area represents the standard deviation of the performance. The caption notes that direct reward comparison across different layouts is not appropriate because task difficulty varies.

This figure compares the performance of CBPR against three baselines (BCP, FCP, and SP) across four different game layouts in Overcooked. The agents’ performance is evaluated over 50 episodes, where the rule-based policies of the partners switch every episode. The shaded areas represent the standard deviation calculated across five different random seeds. CBPR consistently outperforms the baselines, demonstrating its adaptability to non-stationary human partners.

This figure compares the performance of CBPR against three baselines (BCP, FCP, and SP) across four different Overcooked game layouts. The agents’ policies switch every episode. CBPR consistently outperforms the baselines, showcasing its superior adaptability to non-stationary human dynamics. The shaded areas represent standard deviations, calculated from five random seeds, indicating the variability in performance.

This figure compares the performance of CBPR against three baselines (BCP, FCP, and SP) across four different game layouts in Overcooked when collaborators switch their rule-based policies every episode. The y-axis represents the mean episode reward, and the x-axis represents the number of episodes. The shaded areas represent the standard deviation calculated from five random seeds. The results show that CBPR consistently outperforms the baselines, highlighting its ability to adapt to non-stationary human dynamics.

This figure shows the impact of varying the weight (rho) of the inter-episodic belief on the performance of different agents (CBPR, BCP, FCP, and SP) across three Overcooked game layouts (Coordination Ring, Asymmetric Advantage, and Soup Coordination). The results are presented for agents with low, medium, and high skill levels. Each bar represents the mean episodic reward, and the error bars indicate the 95% confidence interval. The results help in understanding how the balance between inter-episodic and intra-episodic belief affects collaboration.

This figure compares the performance of CBPR against three baselines (BCP, FCP, and SP) when collaborating with partners of varying skill levels (low, medium, and high) across four different Overcooked game layouts. The bar chart shows the mean episode reward for each agent and skill level, with error bars representing 95% confidence intervals. The results demonstrate CBPR’s superior performance, particularly when collaborating with lower-skilled partners. The layouts tested are Cramped Room, Coordination Ring, Asymmetric Advantage, and Soup Coordination.
More on tables

This table lists the hyperparameters used for the Proximal Policy Optimization (PPO) algorithm in the paper’s experiments. It includes learning rate, entropy coefficient, epsilon, gamma, lambda, batch size, clipping, hidden dimension of the actor and critic neural networks, and the reward shaping horizon. The parameters were consistent across the different agents (MTP, BCP, FCP, and SP) for fair comparison.

This table presents the reward shaping parameters used in the Proximal Policy Optimization (PPO) algorithm. It shows that placing ingredients in the pot, picking up a dish, and picking up soup are all rewarded. Picking up soup receives the highest reward, reflecting the importance of successfully completing orders.

This table shows the predefined rule-based meta-tasks used in the Overcooked game for four different layouts: Cramped Room, Coordination Ring, Asymmetric Advantage, and Soup Coordination. Each layout has four meta-tasks defined: placing an onion in a pot, delivering soup, placing an onion and delivering soup, and others (for tasks not covered by the first three meta-tasks). The table serves as a basis for training the meta-task playing (MTP) agents in the Collaborative Bayesian Policy Reuse (CBPR) framework.
Full paper#