↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Referring 3D Segmentation, identifying objects in 3D point clouds using textual descriptions, is typically done in two stages: initial instance segmentation, followed by matching with the text query. This approach is time-consuming and requires extensive annotation. Existing methods struggle with noisy point clouds and the complexities of linguistic understanding in 3D scenes.
This paper proposes a novel single-stage method called LESS that directly performs referring 3D segmentation using only binary masks for supervision. LESS uses a Point-Word Cross-Modal Alignment module, a Query Mask Predictor module, and a Query-Sentence Alignment module to align visual and linguistic information. Area regularization and point-to-point contrastive losses are used to improve accuracy and reduce background noise. The method outperforms existing two-stage approaches on the ScanRefer dataset, demonstrating improved accuracy and significant efficiency gains.
Key Takeaways#
Why does it matter?#
This paper is crucial because it significantly reduces the labeling burden in 3D referring segmentation, a computationally expensive and time-consuming task. Its single-stage approach and use of binary masks make it highly efficient, paving the way for more scalable and practical applications. This approach presents a novel solution that will be relevant to many researchers working in computer vision, particularly those using point cloud data. The superior performance achieved also opens up new avenues for efficient 3D scene understanding.
Visual Insights#
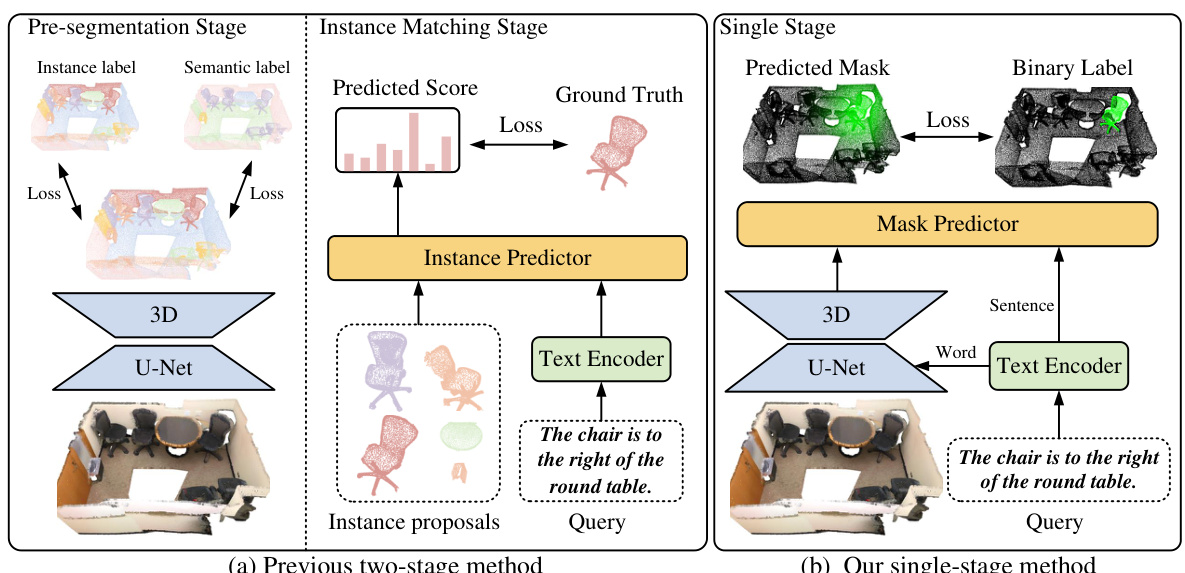
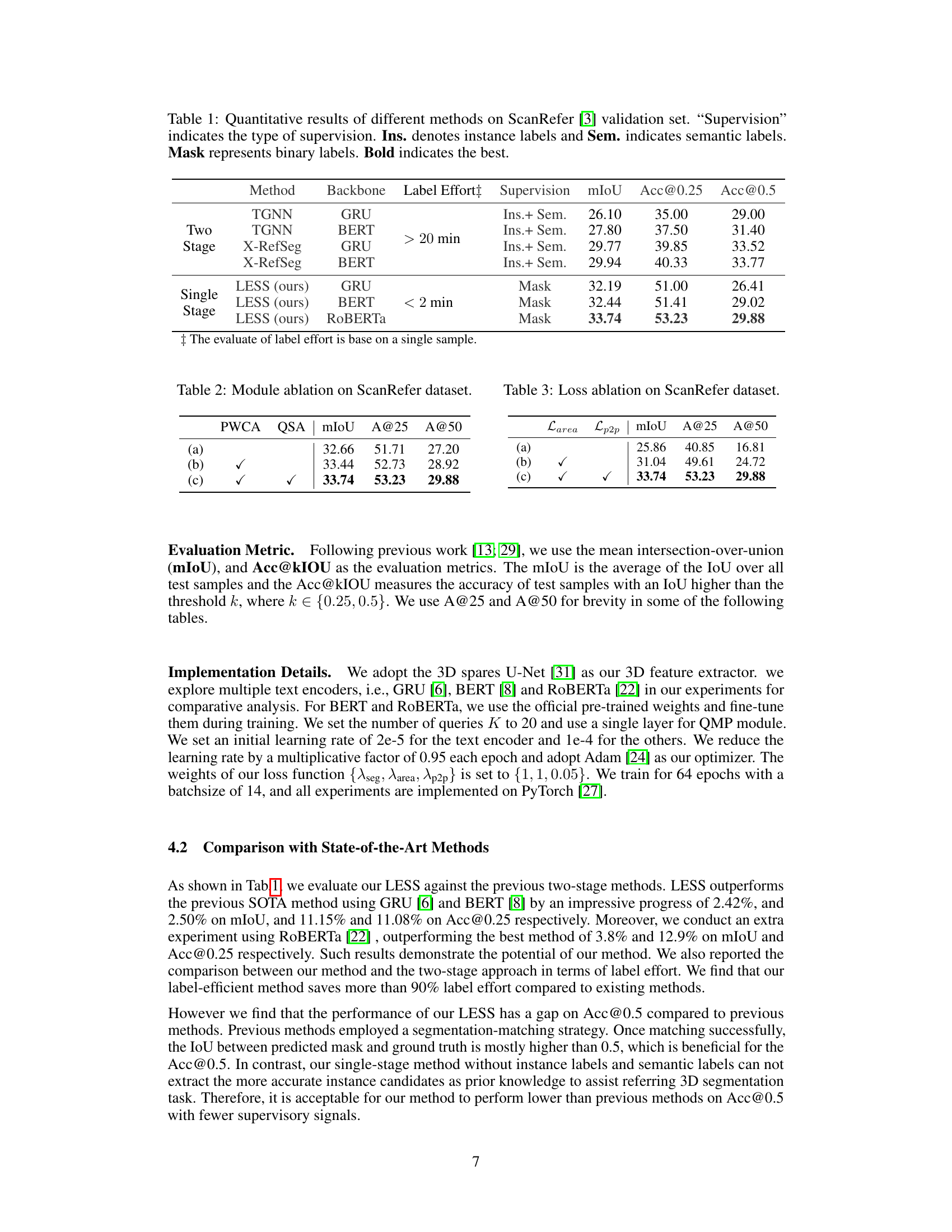
This figure compares the two-stage and single-stage approaches for referring 3D segmentation. The two-stage method first performs instance segmentation using instance and semantic labels, then matches the results with the text query. The single-stage method, in contrast, uses only binary masks for training and integrates language and vision features directly for segmentation, making it more efficient.

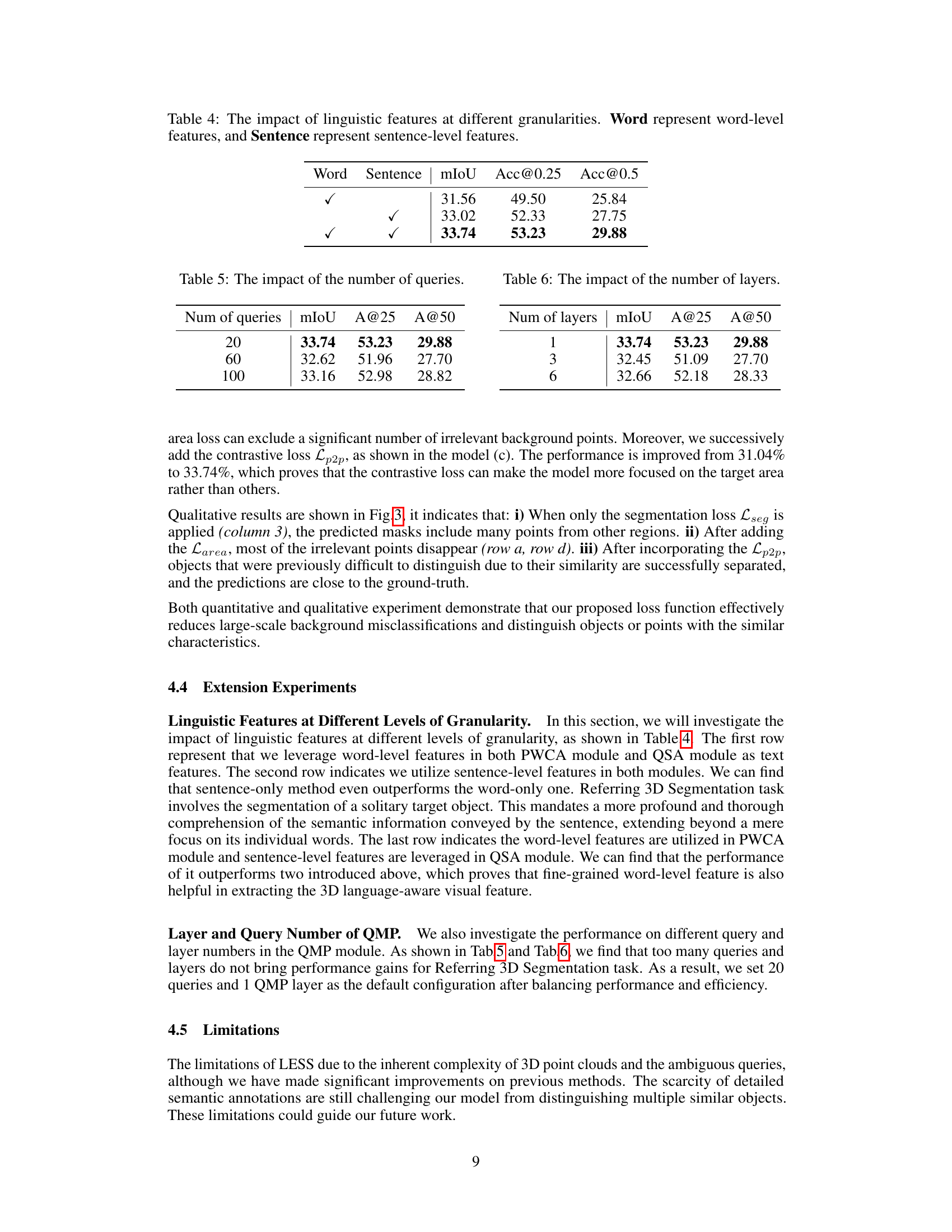
This table presents a comparison of different methods for referring 3D segmentation on the ScanRefer validation set. It shows the method, backbone network used, label effort (time taken for labeling), type of supervision used (instance and semantic labels or binary mask), and the performance metrics (mIoU, Acc@0.25, Acc@0.5). The results highlight the superior performance and efficiency of the proposed LESS method, especially when using only binary masks.
In-depth insights#
LESS: Single-Stage 3D#
LESS: Single-Stage 3D represents a significant advancement in referring 3D segmentation by directly tackling the limitations of two-stage methods. The single-stage architecture streamlines the process, eliminating the need for intermediate steps and improving efficiency. The label-efficient aspect, using only binary masks for supervision, is another key innovation, reducing annotation costs and human effort. The method leverages a point-word cross-modal alignment module to effectively bridge the semantic gap between textual queries and point cloud data. This, combined with coarse-grained alignment techniques, results in a more precise and robust segmentation. While the paper’s ablation studies showcase the importance of its different components and loss functions, the method’s performance on the ScanRefer dataset highlights its potential. Despite the improved efficiency and reduced annotation requirements, the single-stage approach might still face challenges with complex scenes or ambiguous queries. This approach opens up new avenues for efficient and effective 3D object segmentation from natural language descriptions.
Cross-Modal Alignment#
Cross-modal alignment, in the context of a visual-language task like referring 3D segmentation, is crucial for bridging the semantic gap between visual features (from a 3D point cloud) and textual features (from a natural language query). Effective alignment is key to accurately identifying the target object. Methods typically involve attention mechanisms or other neural network modules to learn relationships between modalities. Point-word cross-modal alignment is a particularly important area, focusing on aligning fine-grained visual features (points) with their corresponding word embeddings. This often uses attention to weigh the contribution of different points to understanding each word, and vice versa. Coarse-grained alignment between larger visual regions (masks) and the query sentence is also necessary, ensuring that the model focuses on the relevant area in the 3D scene. This could involve matching high-level features from the point cloud to sentence embeddings. Challenges in cross-modal alignment arise from the inherent differences in the nature of visual and textual information, as well as from the complexity of 3D scenes containing multiple objects and background noise. Effective alignment strategies must address these challenges to achieve accurate referring 3D segmentation.
Contrastive Loss#
Contrastive loss functions, in the context of referring 3D segmentation, aim to improve the model’s ability to distinguish between similar-looking objects or points within a 3D point cloud. They operate by pulling together feature vectors representing points belonging to the target object while pushing apart those from the background or other objects. This is particularly useful when dealing with objects that share subtle visual characteristics or when binary masks (simple object/non-object labels) are used for supervision, as is the case in the LESS model. The effectiveness of contrastive loss is often enhanced when combined with other losses, such as an area regularization loss to reduce background noise, leading to a more precise and accurate segmentation. In the LESS model, this combination of loss functions helps the network learn more discriminative features to accurately identify the target object, demonstrating a crucial role in overcoming the challenges presented by less informative labels and highly complex 3D data. The careful design and integration of contrastive loss is key to achieving state-of-the-art performance in label-efficient scenarios.
Label Efficiency#
Label efficiency is a crucial aspect of machine learning, especially when dealing with large or complex datasets. The core idea is to achieve high performance with minimal labeled data. This is particularly important in domains where obtaining labeled data is expensive, time-consuming, or requires specialized expertise. The paper’s approach to label efficiency centers on using binary masks instead of more elaborate instance or semantic labels. This significantly reduces annotation effort. However, relying solely on binary masks introduces challenges. The model needs to learn richer semantic information to distinguish between subtle visual features, and address the issues associated with coarse labels. The authors cleverly overcome this limitation by incorporating additional loss functions. These loss functions guide the model toward better localization and segmentation, even with limited supervisory signals. Their innovative use of point-to-point contrastive loss and area regularization loss highlights a thoughtful approach to the problem of efficient supervision. Ultimately, their method demonstrates a compelling trade-off: less annotation effort for potentially comparable, or even superior, performance to methods reliant on more comprehensive labeling.
Future Directions#
Future research directions stemming from this label-efficient, single-stage approach to 3D referring segmentation could explore several avenues. Improving robustness to complex scenes with more occlusions and a greater variety of objects is crucial. Developing more sophisticated multi-modal alignment mechanisms that effectively capture fine-grained relationships between language and 3D point cloud features remains a key challenge. Furthermore, investigating alternative loss functions beyond those presented, especially for handling class imbalance and noisy data, presents significant opportunities. Finally, extending the method to handle more diverse point cloud modalities such as incorporating color, intensity, or normals, and exploring applications beyond ScanRefer, including robotics and augmented reality, are exciting areas warranting further research.
More visual insights#
More on figures
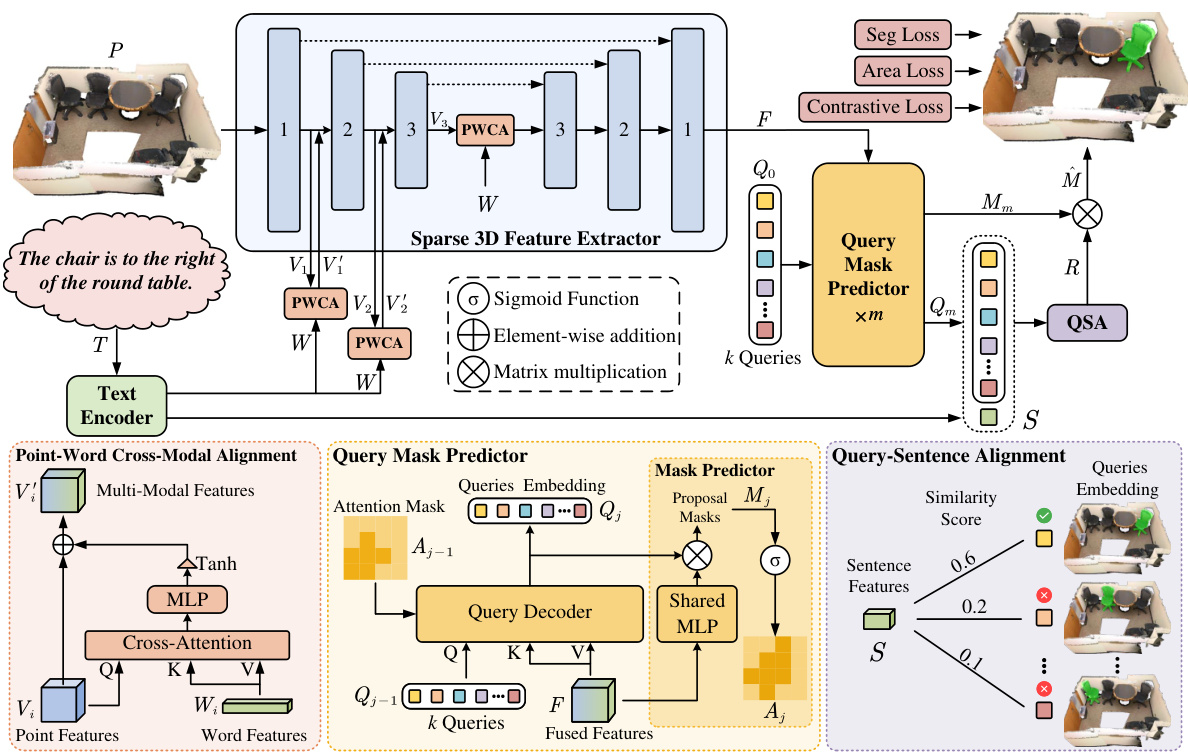
This figure shows the architecture of the LESS framework for referring 3D segmentation. It starts with a sparse 3D feature extractor processing the point cloud, and a text encoder processing the textual query. A Point-Word Cross-Modal Alignment (PWCA) module aligns word and point features. A Query Mask Predictor (QMP) module generates proposal masks, which are then refined by a Query-Sentence Alignment (QSA) module using sentence features to produce the final segmentation mask.

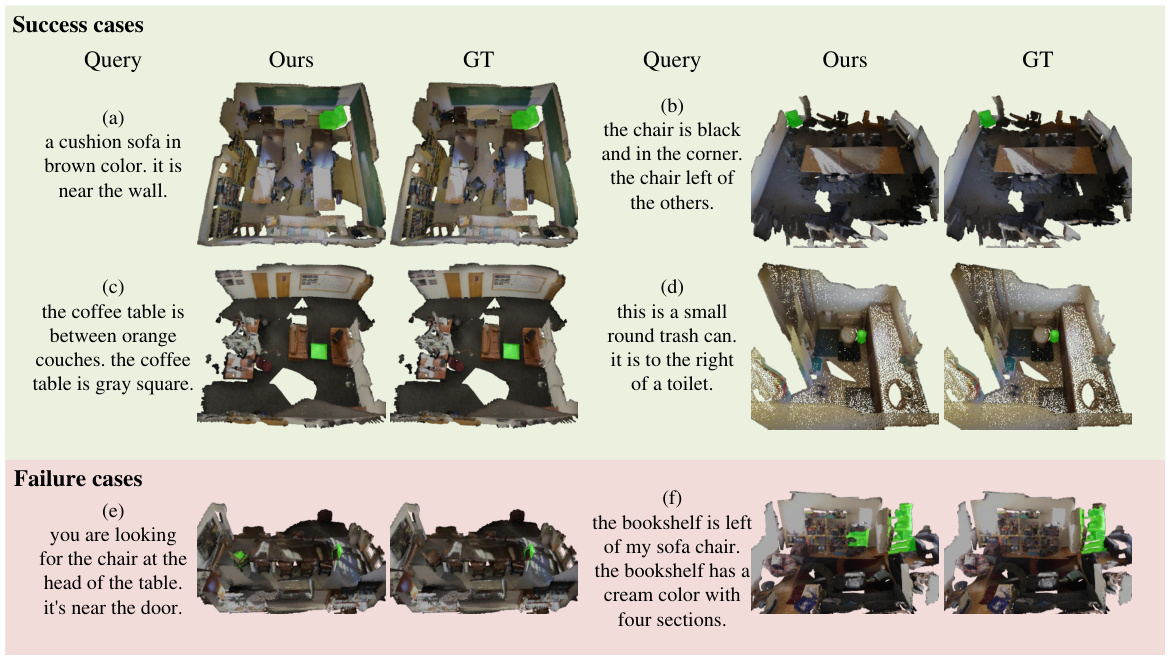
This figure shows the results of applying different combinations of loss functions to the model. The first two columns show the query and the input scene. The subsequent columns show the results of adding each loss function sequentially: segmentation loss (Lseg), area regularization loss (Larea), and point-to-point contrastive loss (Lp2p). The final column shows the ground truth. The figure demonstrates the impact of each loss function on the model’s ability to accurately segment the target objects in the scene, highlighting how each loss function contributes to the final prediction.

This figure illustrates the differences between three types of labels used in 3D point cloud segmentation: semantic labels, instance labels, and binary labels. Semantic labels assign a category ID to each point (e.g., chair, table), while instance labels assign unique IDs to each instance of an object (e.g., chair 1, chair 2). Binary labels, used in this paper’s proposed LESS method, simplify this by assigning a value of 1 to points belonging to the target object and 0 otherwise. This highlights the label efficiency of the LESS method.
This figure compares the architecture of previous two-stage referring 3D segmentation methods with the proposed single-stage LESS method. The two-stage method first performs instance segmentation using both instance and semantic labels, then matches the resulting proposals with the textual query. In contrast, LESS uses only binary mask supervision and integrates language and vision features directly in a single stage for increased efficiency and reduced annotation burden.
More on tables

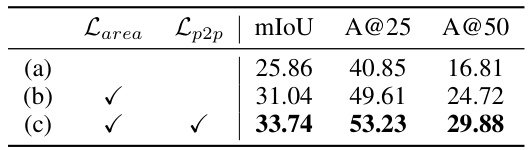
This table presents the ablation study on the LESS model, showing the impact of different modules on the performance. The model is evaluated without PWCA (a), with PWCA (b), and with both PWCA and QSA (c), measuring mIoU, Acc@25, and Acc@50. The results demonstrate the significant contribution of both the PWCA and QSA modules to improving the overall performance.
This table shows the ablation study of different loss functions used in the LESS model. Specifically, it demonstrates the impact of adding the area regularization loss (Larea) and the point-to-point contrastive loss (Lp2p) to the basic segmentation loss (Lseg). The results are presented in terms of mIoU, Acc@0.25, and Acc@0.5.
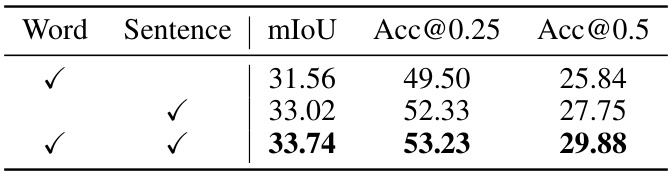
This table presents the results of an ablation study on the impact of using word-level versus sentence-level linguistic features in the LESS model. It shows the mIoU, Acc@0.25, and Acc@0.5 scores for three different conditions: using only word-level features, using only sentence-level features, and using both word-level and sentence-level features. The results demonstrate the relative contributions of these different feature types to the model’s performance.
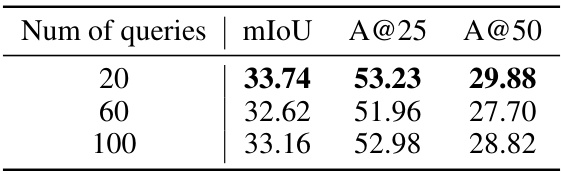
This table shows the effect of varying the number of queries used in the LESS model on the ScanRefer dataset. The results demonstrate how different query numbers impact model performance metrics like mIoU, Acc@25, and Acc@50. It helps understand the optimal query number for balancing performance and efficiency.
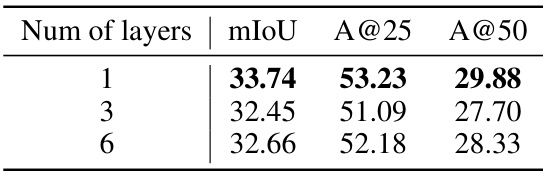
This table shows the results of an ablation study on the number of layers in the Query Mask Predictor (QMP) module. The results are measured in terms of mean Intersection over Union (mIoU), and accuracy at Intersection over Union (IoU) thresholds of 0.25 and 0.5 (Acc@0.25, Acc@0.5). The table demonstrates that increasing the number of layers beyond a certain point does not significantly improve performance.

This table compares the inference and training times of the proposed LESS method with two state-of-the-art methods, TGNN and X-RefSeg, on the ScanRefer dataset. It shows the total inference time for the entire dataset, the inference time per scan, and the training time broken down into stages (where applicable) and total training time. The results demonstrate the efficiency gains of the LESS model compared to the previous methods.

This table compares the performance of the proposed LESS method to the 3D-STMN method on the ScanRefer dataset. The comparison is based on three metrics: mIoU, Acc@0.25, and Acc@0.5. The results show that LESS significantly outperforms 3D-STMN across all three metrics.
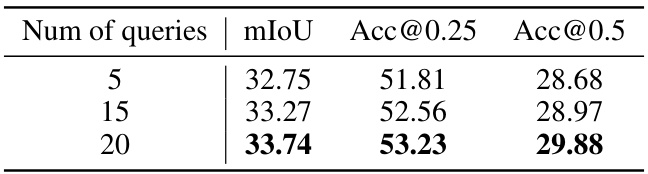
This table shows the performance of the LESS model on the ScanRefer dataset with varying numbers of queries (5, 15, and 20). The results (mIoU, Acc@0.25, and Acc@0.5) demonstrate how the number of queries affects the model’s ability to accurately segment objects in a 3D point cloud scene based on textual descriptions. The optimal number of queries for the model is identified.

This table presents the ablation study results on the impact of mask selection strategy in the LESS model. It compares the performance of selecting only the single highest-ranked mask versus aggregating multiple masks, showing the improvement achieved by the latter approach. The metrics used are mIoU, Acc@0.25, and Acc@0.5.
Full paper#