↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many interactive machine learning systems deploy multiple models/services to cater to diverse users. These systems learn iteratively through user interactions, but initial service configuration significantly impacts performance and fairness. Existing methods struggle due to bandit feedback (limited data) and non-convex loss landscapes. This leads to suboptimal local solutions.
This research addresses these issues by proposing a novel randomized algorithm (AcQUIre) that adaptively selects a minimal set of users for data collection to initialize services. Under mild assumptions, the algorithm provably achieves a total loss within a logarithmic factor of the global optimum. This factor is generalized from k-means++, and is complemented by experiments on real and synthetic datasets, showing better performance and fairness compared to existing baselines.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in interactive machine learning and related fields because it provides a novel, efficient, and theoretically sound algorithm for initializing services in systems designed for diverse users. This addresses a critical challenge in deploying effective and fair multi-service ML systems, particularly in settings with limited upfront data on user preferences and the need for adaptation to evolving user behavior. It opens new avenues for research in algorithm design, fairness guarantees, and adaptive data collection strategies for multi-agent systems.
Visual Insights#
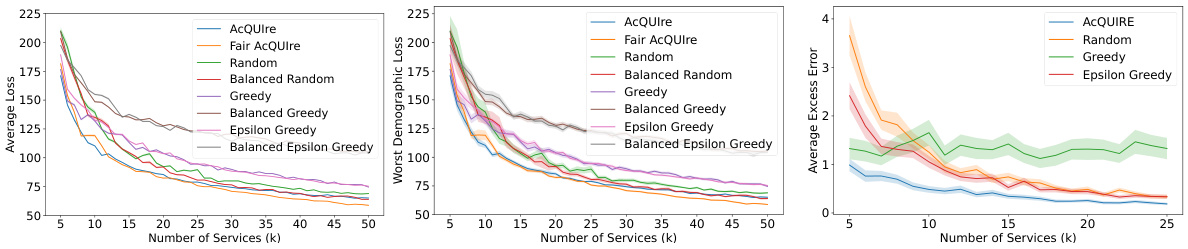
The figure compares the performance of different user selection strategies (AcQUIre, Fair AcQUIre, Random, Greedy, Epsilon Greedy, and their balanced versions) across three scenarios: average loss for all census groups, average loss for the worst demographic group, and average excess error for a movie recommendation task. The results show that AcQUIre and Fair AcQUIre consistently outperform other methods, especially when the number of services (k) is large.
In-depth insights#
Adaptive Service Init#
An adaptive service initialization method for interactive machine learning systems aims to address the challenges of bandit feedback and suboptimal local solutions in environments with diverse users and multiple services. The core idea revolves around efficiently selecting a minimal set of users to collect data from, enabling the system to initialize services effectively. This approach leverages a randomized algorithm to iteratively select users based on their current loss. Theoretical analysis demonstrates that this adaptive strategy leads to a total loss within a logarithmic factor of the optimal solution. This is achieved under mild assumptions of the loss function, representing a generalization of k-means++ to a broader class of problems. The method’s efficiency and effectiveness are further supported through empirical evaluations on real and semi-synthetic datasets, showcasing its ability to outperform other initialization strategies and converge rapidly to high-quality solutions.
Bandit Feedback#
The concept of ‘Bandit Feedback’ in the context of interactive machine learning systems for diverse users presents a crucial challenge and opportunity. It highlights the inherent uncertainty in understanding user preferences before deploying services. Unlike traditional supervised learning settings with readily available labeled data, bandit feedback implies that the system learns incrementally through user interactions and choices, receiving only partial or indirect information about the success or failure of a given service. This sequential learning process, where feedback is sparse and noisy, presents unique difficulties in optimizing service configurations. The exploration-exploitation dilemma is central; the system needs to balance exploring the performance of different services across various user segments while exploiting the knowledge gained to improve service assignment and user experience. Addressing bandit feedback requires sophisticated algorithms, often incorporating techniques from multi-armed bandit problems or reinforcement learning to guide efficient exploration and effective resource allocation in the face of limited information. Ultimately, effective management of bandit feedback is key to building robust and adaptive interactive machine learning systems that serve diverse user needs effectively.
Loss Landscape#
The concept of a loss landscape is crucial for understanding the optimization challenges in training machine learning models, especially in the context of the paper’s focus on initializing services for diverse users. The loss landscape visualizes the relationship between the model’s parameters and its associated loss. Non-convexity is a key characteristic mentioned, indicating the presence of multiple local minima and saddle points. This non-convexity significantly complicates the optimization process, as gradient-based methods can easily get trapped in suboptimal local minima instead of converging to the global minimum. The paper highlights the impact of initial conditions on the learning dynamics, emphasizing how the choice of initial services critically affects the final outcome. Finding good initial conditions, therefore, becomes a significant challenge, particularly in bandit settings where user feedback is only available after deployment. The randomized initialization algorithm proposed addresses this challenge, aiming to guide the optimization process toward regions of the loss landscape with lower loss values and potentially avoiding poor local minima.
Fairness Metrics#
In evaluating fairness within machine learning models, particularly in the context of service allocation to diverse user populations, a nuanced approach to fairness metrics is crucial. Simple metrics may not capture the complexities of real-world scenarios. For example, focusing solely on group-level disparities may overlook individual-level unfairness. A robust framework should incorporate multiple metrics, each addressing different facets of fairness. This might include measuring the difference in average outcomes between groups, evaluating the distribution of outcomes within each group, and analyzing the intersectional impact of multiple sensitive attributes. Moreover, it’s important to consider the tradeoffs between various fairness definitions and the potential for unintended consequences when optimizing for one metric while neglecting others. The choice of metrics should be guided by the specific context, the nature of the services, and the needs of the user groups, with careful consideration given to both the positive and negative impacts of the model. Ultimately, a comprehensive fairness assessment requires transparent reporting of multiple fairness metrics, along with a detailed discussion of their implications and limitations.
Future Directions#
Future research could explore generalizing the theoretical framework to accommodate more complex loss functions and user preference models, moving beyond the assumptions of the current study. Investigating the impact of noisy or incomplete feedback on the algorithm’s performance and exploring strategies for handling such scenarios would be valuable. A key area for advancement is developing more sophisticated user selection mechanisms, potentially incorporating bandit algorithms for adaptive learning and dynamic balancing of exploration and exploitation. Robustness analyses under adversarial scenarios and evaluations in diverse real-world applications are crucial to demonstrate practical applicability. Finally, investigating fairness-aware service initialization for complex user demographics and investigating the trade-offs between global efficiency and fairness is essential for building equitable and inclusive ML systems.
More visual insights#
More on figures
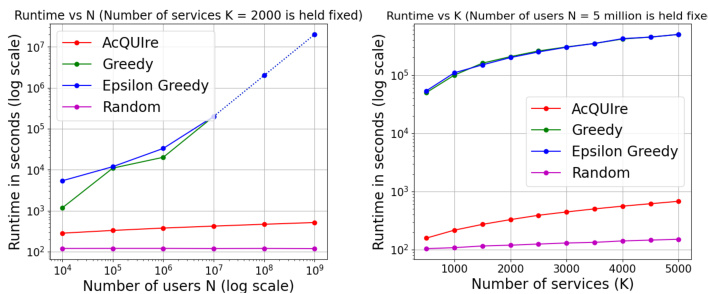
This figure shows the runtimes of the AcQUIre algorithm and its baselines (Greedy, Epsilon Greedy, and Random) for varying numbers of users (N) and services (K). The left panel shows the runtime scaling with the number of users while keeping the number of services fixed at K=2000. The right panel shows the runtime scaling with the number of services while fixing the number of users at N=5 million. The figure demonstrates that AcQUIre’s runtime scales more favorably compared to the other baselines, especially as the number of users or services increases.

This figure shows the impact of initialization on the convergence speed and final loss of two optimization algorithms: k-means and multiplicative weights. The results are presented for two different datasets: Census data and MovieLens10M data. The key takeaway is that the proposed AcQUIre algorithm leads to faster convergence and lower final loss compared to baseline initialization methods (Random, Greedy, Epsilon Greedy). This highlights the significance of a robust initialization strategy for improved optimization performance.
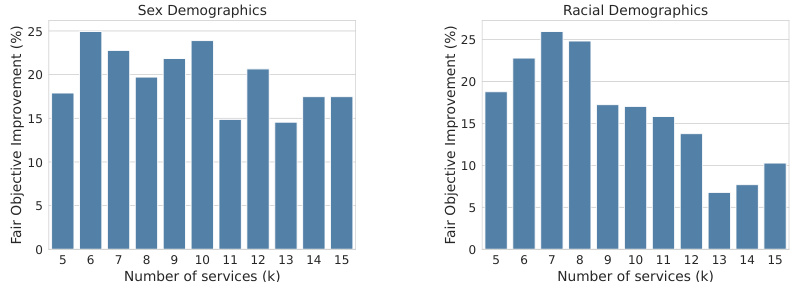
This figure presents bar charts showing the percentage improvement of the Fair AcQUIre algorithm over a baseline algorithm for two demographic categories: sex and race. The x-axis represents the number of services (k), and the y-axis represents the percentage improvement in the fair objective. The results indicate that the Fair AcQUIre algorithm consistently outperforms the baseline across various numbers of services, achieving at least 15% improvement for sex demographics and between 7% and 26% for racial demographics.

This figure shows the effectiveness of the Fair AcQUIre algorithm in reducing disparities in average losses across different demographic groups. The left and middle panels display the average losses for various demographic groups using both weighted baselines and Fair AcQUIre, demonstrating the reduction in disparity achieved by Fair AcQUIre. The right panel shows the percentage improvement of Fair AcQUIre over the weighted baseline for each demographic group, highlighting the significant gains achieved by Fair AcQUIre across all groups.
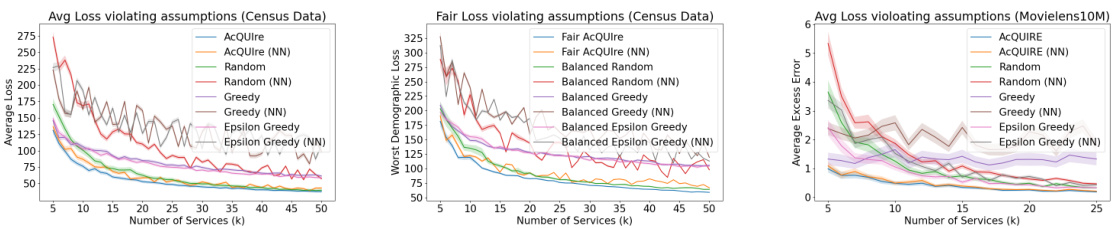
This figure compares the performance of different user selection strategies for initializing services in two tasks: commute time prediction using US Census data and movie recommendations using MovieLens data. Across both tasks, AcQUIre and Fair AcQUIre consistently outperform other methods, especially as the number of services (k) increases. The results highlight the myopic nature of greedy and epsilon-greedy approaches and showcase the effectiveness of AcQUIre’s adaptive data collection strategy.
Full paper#



















