↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many existing methods for learning in extensive-form games suffer from high variance due to importance sampling. This paper addresses this issue by proposing a fixed sampling approach where the sampling policy is fixed and not updated over time. This reduces variance in gain estimates, but traditional methods for regret minimization still suffer from large variance, even with a fixed sampling policy.
The proposed algorithm, LocalOMD, uses an adaptive Online Mirror Descent (OMD) algorithm that applies OMD locally to each information set with individually decreasing learning rates. It leverages a regularized loss function to ensure stability. Importantly, LocalOMD avoids the use of importance sampling, addressing the high-variance problem and offering a convergence rate of Õ(T-1/2) with high probability. The algorithm shows near-optimal dependence on the game parameters when using optimal learning rates and sampling policies.
Key Takeaways#
Why does it matter?#
This paper is important because it presents LocalOMD, a novel algorithm for learning optimal strategies in extensive-form games. It addresses the high variance issue in existing methods by employing a fixed sampling approach and adaptive online mirror descent. This offers near-optimal sample complexity and opens up new avenues for research in game theory and reinforcement learning.
Visual Insights#
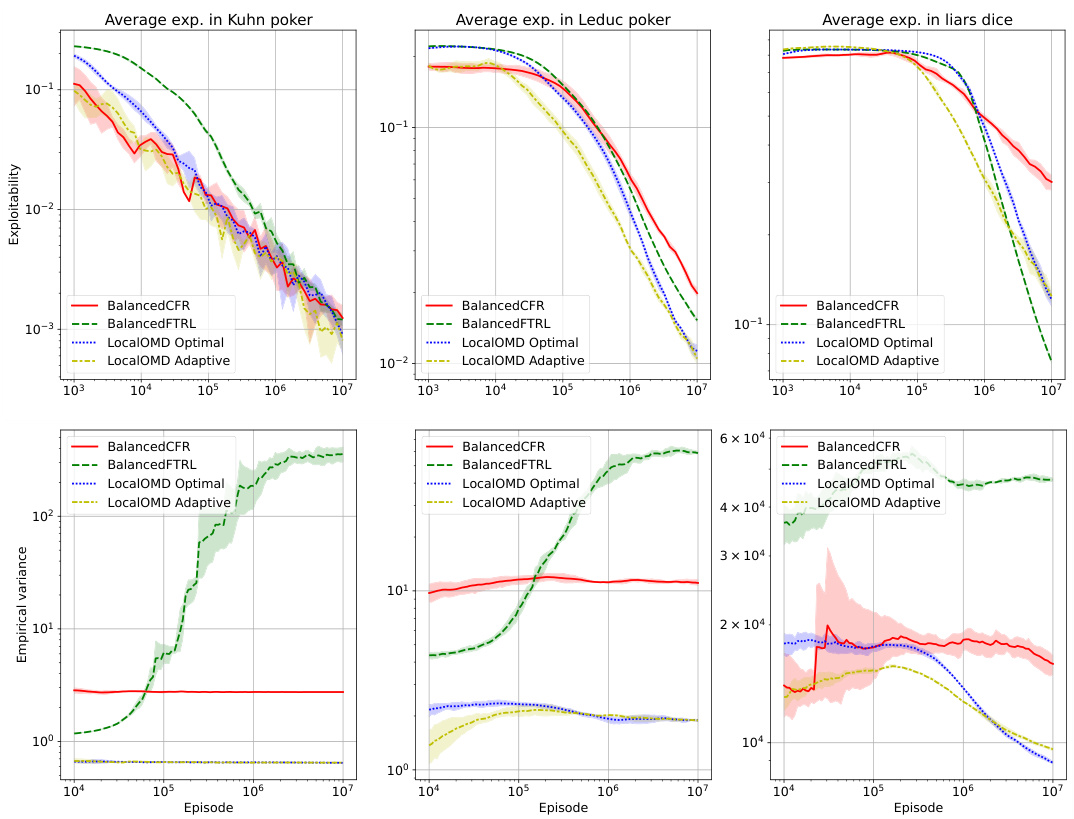
This figure compares the performance of several algorithms (BalancedCFR, BalancedFTRL, LocalOMD Optimal, LocalOMD Adaptive) across three different poker games (Kuhn Poker, Leduc Poker, Liars Dice). The top row shows the exploitability gap (a measure of how far from optimal the learned strategies are) as a function of the number of episodes of training. The bottom row illustrates the empirical variance of the loss estimations during training. The figure demonstrates that LocalOMD achieves lower exploitability and variance compared to other algorithms.
Full paper#