↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many image classification systems use pretrained models to extract features. However, these models can contain harmful biases learned from training data, impacting downstream tasks. This is particularly problematic when the pretrained model is a ‘black box,’ meaning its internal workings are not publicly available or accessible for modification. Existing bias mitigation methods are often not suitable in these black-box scenarios, leaving a critical gap in responsible AI development.
The researchers tackle this problem by proposing a novel method that doesn’t require access to the pretrained model’s internal weights. This method involves using a trainable adapter module to first amplify the existing bias in the downstream task. Then, a clustering-based adaptive margin loss is applied to this biased feature representation to mitigate the bias. The effectiveness of this approach is demonstrated through experiments across various benchmark datasets, showcasing its potential to improve the fairness and reliability of image classification systems using pretrained models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with pretrained models in image classification. It directly addresses the prevalent issue of bias propagation from pretrained, often black-box, encoders into downstream tasks. By proposing a novel method to mitigate these biases, even without full model access, it opens new avenues for creating fairer and more robust AI systems. The study’s findings and proposed techniques are highly relevant to current trends in AI ethics and responsible AI development.
Visual Insights#
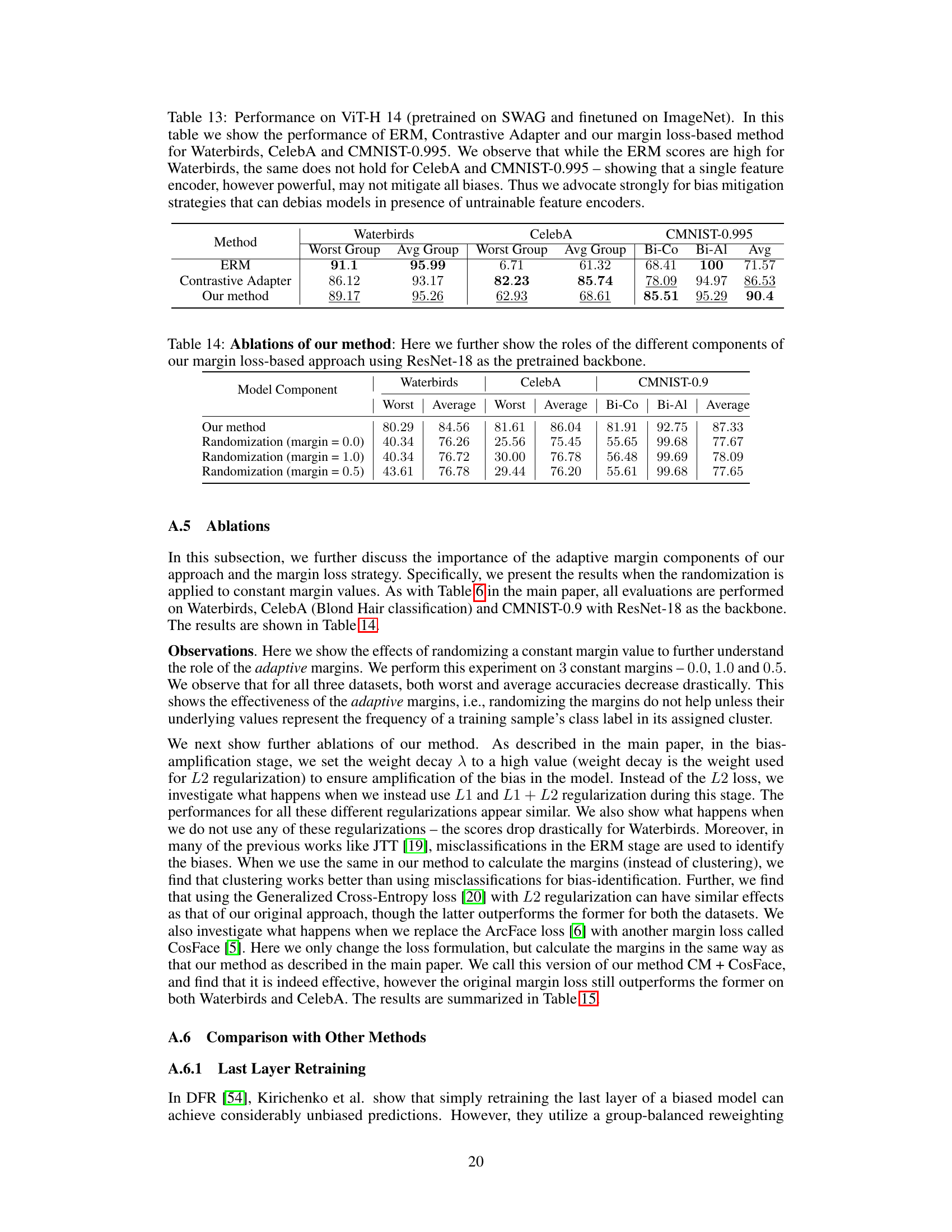
The figure illustrates the proposed method for mitigating bias in a downstream classification task using a frozen pretrained encoder. The process involves three stages: 1) Using a pretrained encoder (frozen weights) to extract features from input images. 2) Adding a trainable adapter module on top of the encoder to learn and amplify the bias present in the downstream dataset. 3) Applying a novel adaptive margin loss technique to mitigate the learned bias, resulting in unbiased predictions for the downstream task. Crucially, the method does not require prior knowledge of the bias attribute.
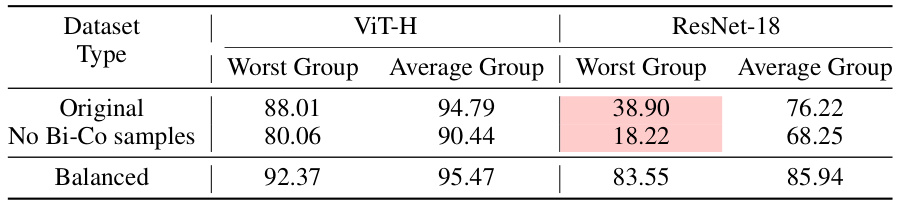
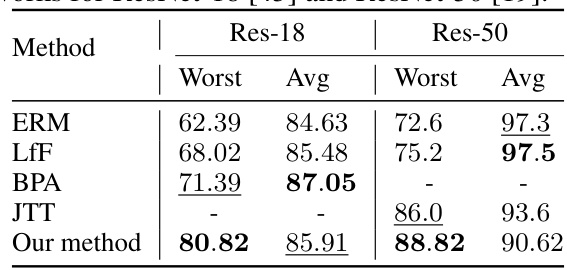
This table presents the performance of the Waterbirds dataset using two different pretrained encoders (ViT-H and ResNet-18) under three different training data scenarios: the original dataset, the dataset with bias-conflicting samples removed, and the group-balanced dataset. The results show the worst-group and average-group accuracy for each encoder and dataset variation, highlighting how pretrained models and data manipulation influence downstream performance.
In-depth insights#
Blackbox Bias#
The concept of “Blackbox Bias” highlights the challenges in addressing biases within complex machine learning models whose inner workings are opaque. The inability to inspect the model’s internal features and decision-making processes makes bias detection and mitigation significantly harder. This is particularly problematic with large-scale pre-trained models where full retraining is often computationally infeasible. Effective strategies must be developed to identify and mitigate bias without directly accessing the model’s internal parameters, requiring innovative techniques like analyzing model outputs or utilizing proxy data to infer biases. Focusing research on methods that effectively address blackbox bias is crucial for deploying fair and reliable AI systems in real-world applications. This requires developing techniques robust to various bias forms and dataset characteristics and scalable to handle the size and complexity of today’s deep learning models.
Adapter Modules#
Adapter modules are valuable tools in deep learning, particularly useful when dealing with pre-trained models. Their primary advantage lies in their ability to insert a trainable component into an otherwise frozen model, allowing for adjustments to the model’s output without retraining the entire architecture. This is especially beneficial when working with large, computationally expensive pre-trained models where full retraining is impractical or impossible. Adapters reduce the risk of catastrophic forgetting while still enabling the model to adapt to downstream tasks and specific datasets. However, the effectiveness of adapter modules is context-dependent and heavily relies on the characteristics of the pre-trained model and the downstream task. Careful consideration must be given to the adapter’s architecture, size, and placement within the overall model to optimize performance. Furthermore, research into adapter module design and usage is ongoing, and future work may reveal new insights and even more powerful applications.
Margin Loss#
The concept of ‘margin loss’ in machine learning, particularly within the context of addressing bias in image classification, involves modifying the loss function to increase the separation between different classes. Standard cross-entropy loss focuses on accurate prediction, but margin loss adds a penalty if a sample’s feature vector is not sufficiently far from the decision boundary of its true class. In bias mitigation, this is particularly useful because harmful biases often manifest as spurious correlations where the model relies on easily learned but misleading features. A margin loss can help the model focus on more robust features, thereby reducing the influence of biases and leading to more generalized and fair predictions. Adaptive margin loss, as explored in the research, takes this a step further by adjusting the margin dynamically based on factors like class frequency within clusters or other bias-relevant attributes, thus making the model more resilient to skewed data distributions.
Bias Amplification#
Bias amplification, in the context of mitigating bias in machine learning models, is a crucial preprocessing step. It involves techniques designed to exaggerate the existing biases present in a dataset or within a pretrained model’s feature representations. By intentionally increasing the strength of these biases, it becomes easier to identify and subsequently target them for effective mitigation. This approach is particularly useful when dealing with black-box models where direct weight manipulation isn’t feasible. Several methods achieve bias amplification, including techniques that manipulate the training data (such as oversampling biased samples) or by introducing loss functions that reward biased predictions, thereby creating a more easily identifiable bias signal for downstream debiasing methods. The effectiveness of bias amplification relies on the downstream model’s sensitivity to the amplified signal and the suitability of the chosen debiasing method to effectively counteract the amplified bias without introducing new biases or harming overall accuracy. The key is to carefully select methods that amplify only the relevant bias, avoiding the spread of unwanted biases, ultimately leading to improved fairness and model generalizability.
Future Research#
Future research directions stemming from this work on mitigating bias in black-box feature extractors could explore several promising avenues. Developing more sophisticated clustering techniques to better capture subtle biases is crucial, potentially incorporating techniques from semi-supervised or unsupervised learning. Investigating the interplay between different types of biases (e.g., gender, race, and spurious correlations) and how they interact with pretrained models is also important. Furthermore, research is needed on adaptive margin loss functions that are more robust to noisy data and better generalize across diverse datasets. Finally, extending these methods to other modalities such as video and audio, and exploring the potential for cross-modal bias mitigation would broaden the impact and applicability of this work. Addressing these research questions would significantly advance the field and contribute to more fair and equitable AI systems.
More visual insights#
More on figures
This figure shows the three stages of the proposed bias mitigation method. Stage 1 involves bias amplification by training the model with a cross-entropy loss and high weight decay. In stage 2, the resulting biased features are clustered to identify groups based on bias. Finally, in stage 3, an adaptive margin loss uses cluster information to mitigate bias, leading to improved performance on the bias-conflicting data samples.

This figure illustrates the three-stage process of the proposed bias mitigation method. Stage 1 involves bias amplification training using cross-entropy loss with high weight decay. In Stage 2, the biased features are clustered. Finally, Stage 3 uses the clusters to calculate adaptive margins for a margin loss, mitigating biases and improving performance on bias-conflicting data.

This figure illustrates the three-stage process of the proposed bias mitigation method. Stage 1 involves bias amplification training using cross-entropy loss with a high weight decay, resulting in a model that overemphasizes the biases in the data. Stage 2 uses clustering to group similar biased features. Finally, Stage 3 applies an adaptive margin loss that leverages the cluster information to mitigate the bias and improve performance, especially for bias-conflicting data points. The diagram shows the flow of data through the pretrained encoder, adapter, and classifier layers, highlighting which components are frozen and which are trainable.

This figure shows the three stages of the proposed bias mitigation method. First, bias is amplified in the model using cross-entropy loss with a high weight decay. Then, the learned features are clustered to identify groups of samples with similar characteristics. Finally, a margin loss is used to mitigate biases, with the margin values determined by the cluster assignments to obtain unbiased predictions, especially for samples that were not well learned in the first stage of training.
More on tables

This table compares the performance of three different bias mitigation techniques: loss-weighted cross-entropy (LW), cluster-weighted cross-entropy (CW), and the proposed cluster-based adaptive margin loss (CM). The results are shown for three benchmark datasets: Waterbirds, CelebA, and ColorMNIST-0.995. The table highlights that CM significantly outperforms LW and CW, demonstrating the effectiveness of the proposed method in mitigating bias in a black-box setting.

This table presents the performance of the Waterbirds dataset using two different pre-trained encoders (ViT-H and ResNet-18) under three different training scenarios. The first uses the original dataset, the second removes bias-conflicting samples, and the third uses a group-balanced dataset. The results are presented in terms of worst-group and average-group accuracy for each scenario and encoder. This helps in evaluating the impact of pre-trained encoders on downstream task performance and the effectiveness of bias mitigation strategies.
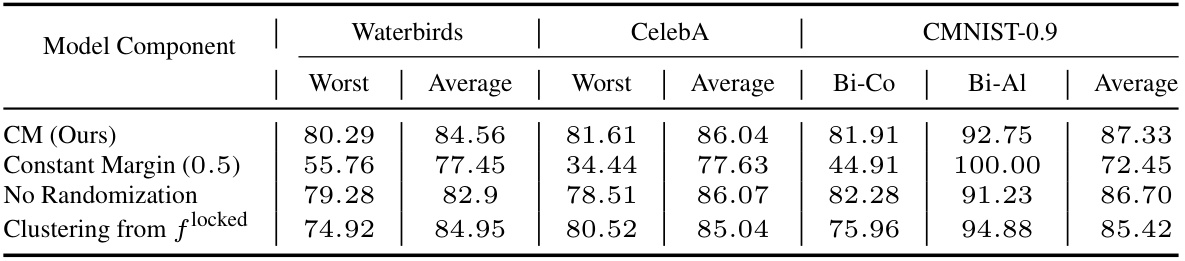
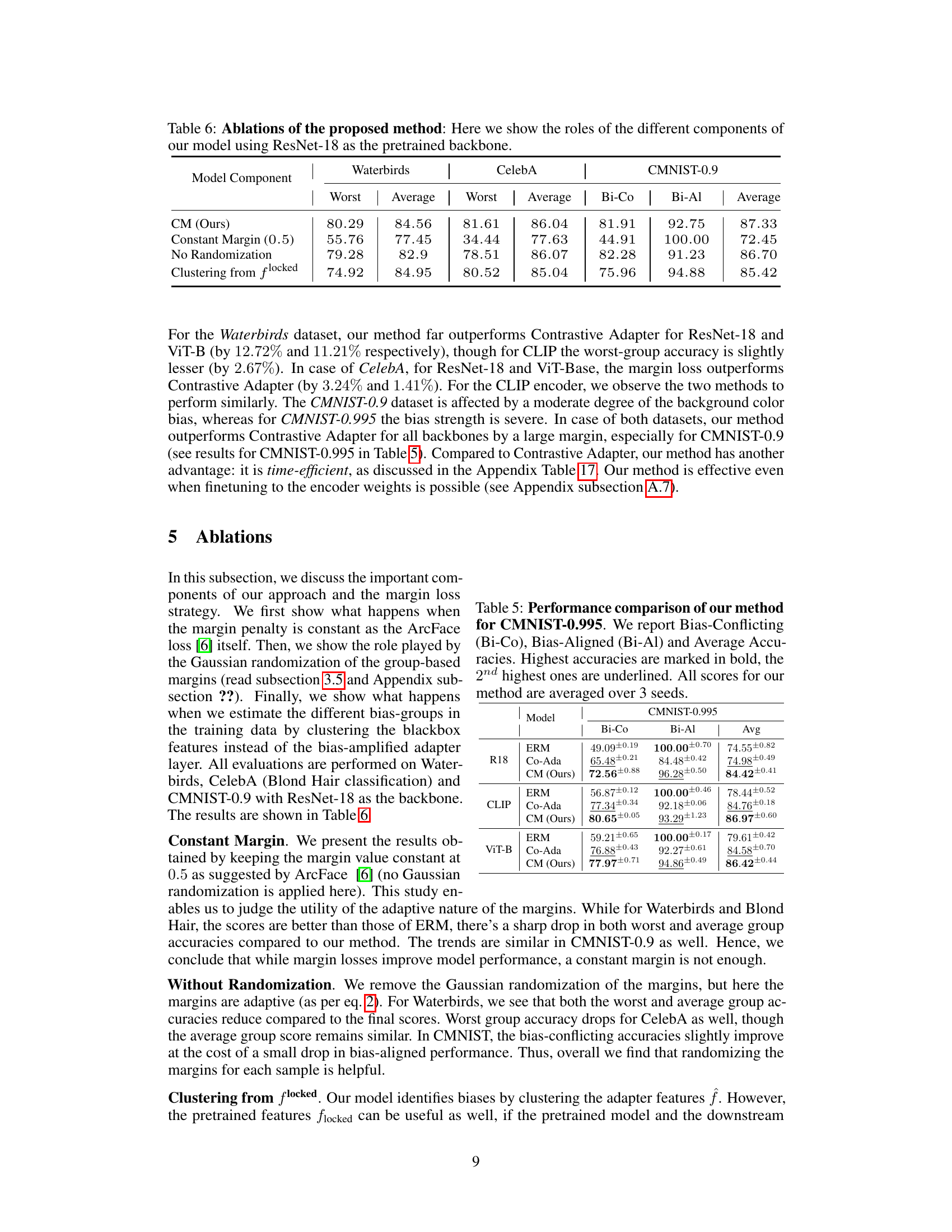
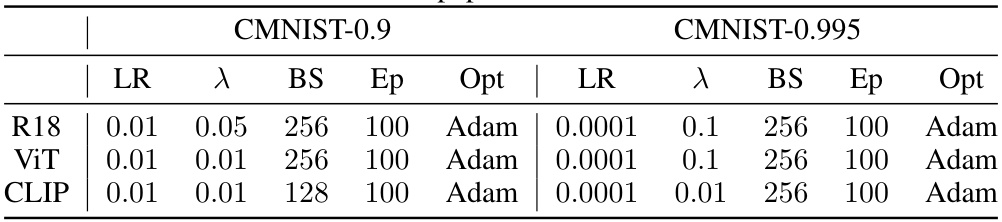
This table presents an ablation study on the proposed bias mitigation method, using a ResNet-18 pretrained backbone. It systematically removes components of the method to assess their individual contributions to performance. The components evaluated include: the adaptive margin loss, Gaussian randomization of margins, and the use of clustered features from the original pretrained model versus features from a bias-amplified adapter. The table shows the worst-group and average-group accuracies on the Waterbirds, CelebA, and CMNIST-0.9 datasets for each ablation.
This table presents the performance of the Waterbirds dataset using two different pretrained encoders (ViT-H and ResNet-18) under three different training data scenarios: the original data, data with bias-conflicting samples removed, and group-balanced data. The results show the worst-group and average-group accuracy for each encoder and data scenario, highlighting the impact of pretrained encoders and data bias on model performance.
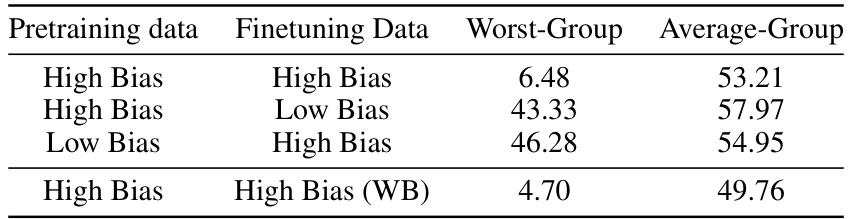
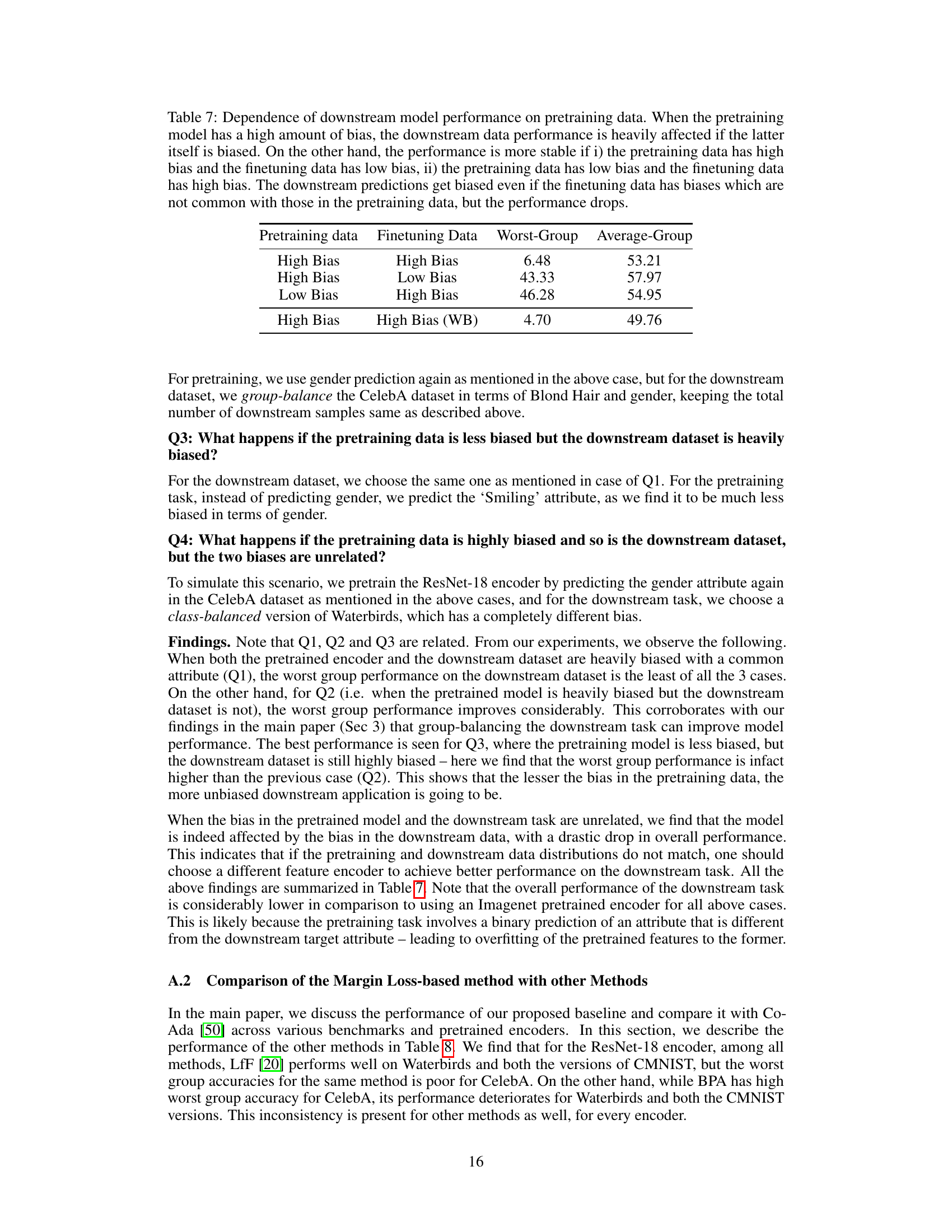
This table shows how the performance of a downstream model is affected by the bias in both the pretraining and finetuning data. The results indicate that when both datasets have high bias, the performance is poor, especially for the worst-performing group. However, if either the pretraining or finetuning data has low bias, the performance is more stable, suggesting that mitigating bias in either the pretraining or finetuning data can improve the overall performance of the downstream model. The table also shows that even when the finetuning data has a different type of bias than the pretraining data, the performance is still affected, suggesting that the model may not be able to fully correct for any biases introduced in the pretraining phase.

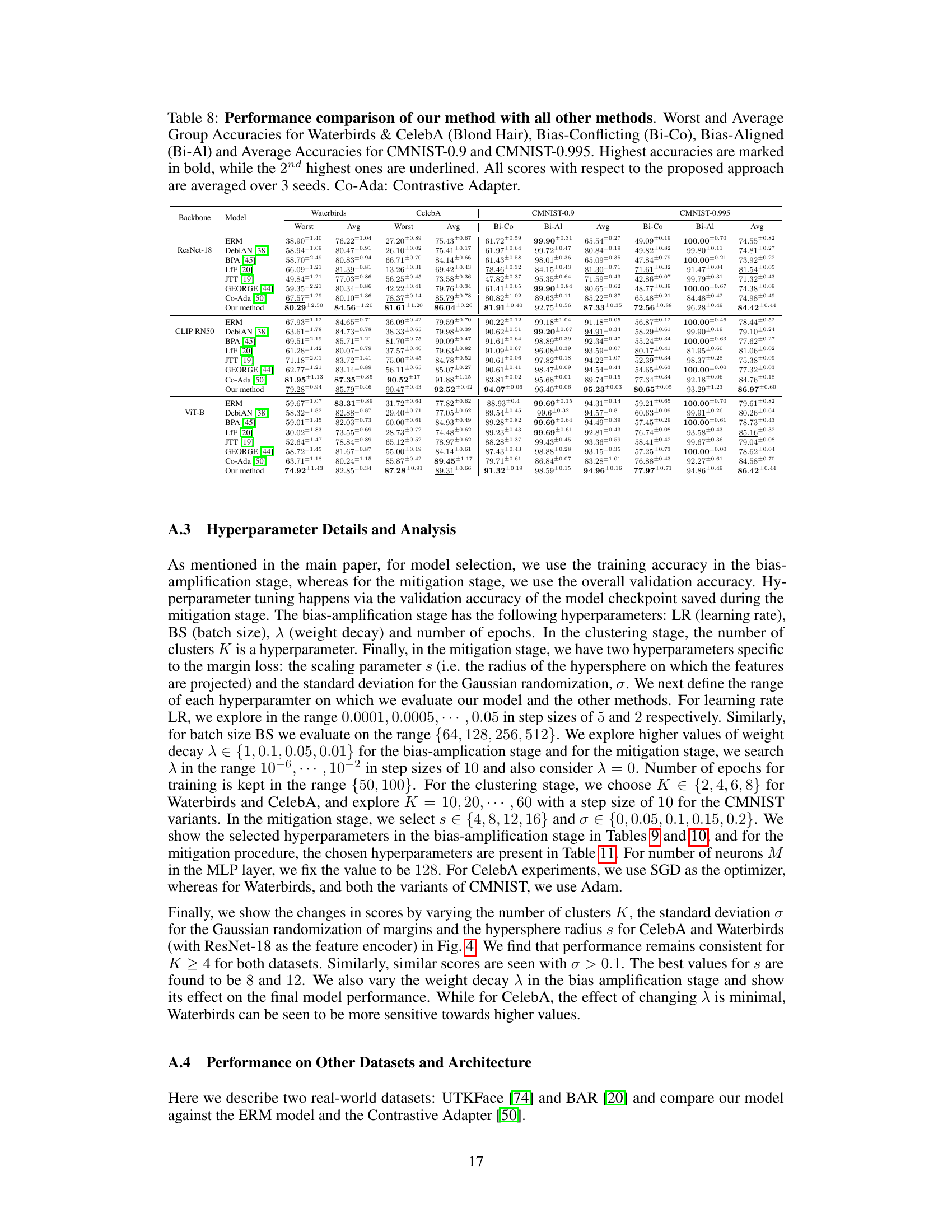
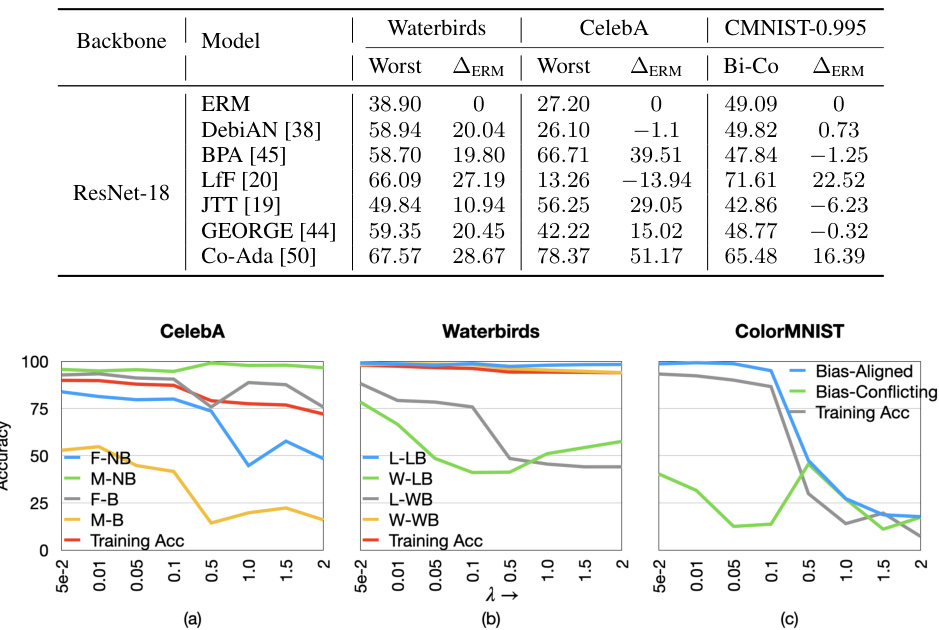
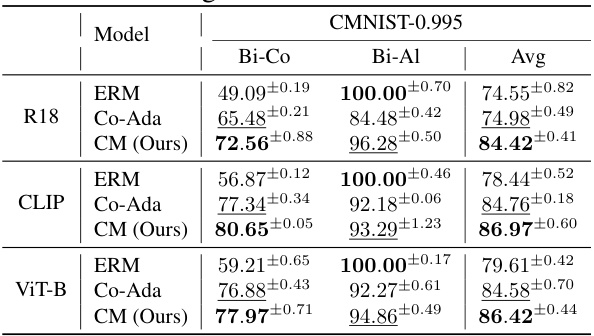
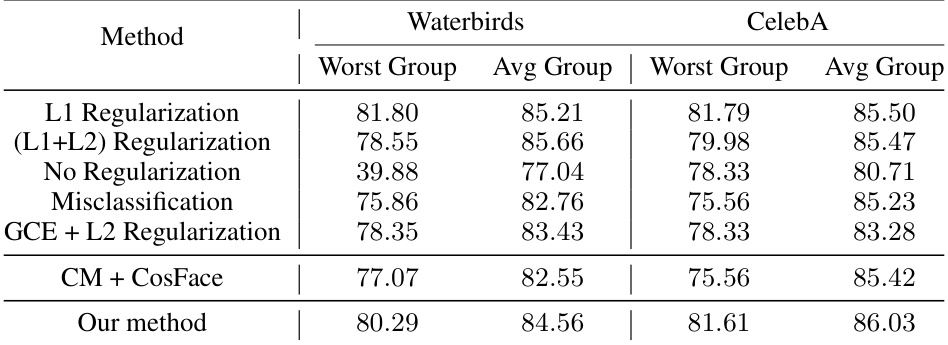
This table compares the performance of several existing bias mitigation methods against the Empirical Risk Minimization (ERM) model and the Contrastive Adapter (Co-Ada) method on three benchmark datasets (Waterbirds, CelebA, and ColorMNIST-0.995). The results show that most of the existing methods either achieve performance similar to ERM or lack consistent high performance across the datasets. The Contrastive Adapter method, however, stands out with consistently high worst-group accuracies.
This table shows the performance of the Waterbirds dataset using two different pretrained encoders (ViT-H and ResNet-18). It compares performance on three versions of the training data: the original data, the data with bias-conflicting samples removed, and group-balanced data. The test set remains consistent across all comparisons. The results illustrate how different pretrained encoders and data preprocessing techniques affect the model’s ability to avoid biases.
This table compares the performance of different pretrained encoders (ViT-H and ResNet-18) on the Waterbirds dataset under various training data conditions. It shows the impact of removing bias-conflicting samples and group-balancing on the model’s ability to generalize and avoid bias amplification.

This table presents the performance of a waterbird image classification model using two different pretrained encoders (ViT-H and ResNet-18) and three variations of the training dataset. The first uses the original dataset; the second removes bias-conflicting samples; and the third is group-balanced. The table compares the worst group accuracy, average group accuracy, and overall accuracy for each scenario, demonstrating the effect of pretrained encoders and dataset bias on model performance.

This table compares the performance of a model trained on the Waterbirds dataset using two different pretrained encoders (ViT-H and ResNet-18). It shows the results for three different training data variations: the original data, the data with bias-conflicting samples removed, and the group-balanced data. The table highlights how the choice of pretrained encoder and the preprocessing of the training data affect the model’s performance, particularly focusing on the performance for the worst-performing group.

This table compares the performance of a model trained on the Waterbirds dataset using two different pre-trained encoders (ViT-H and ResNet-18). The performance is evaluated across three different versions of the training dataset: the original, a version with all bias-conflicting samples removed, and a group-balanced version. The goal is to demonstrate how pretrained encoders and data manipulation affect downstream task performance.

This table presents ablation studies on the proposed method, specifically investigating the impact of different components on performance. It analyzes the effects of using a constant margin instead of an adaptive margin, removing the Gaussian randomization of margins, and using pretrained features for clustering instead of the bias-amplified adapter features. The results are presented for three benchmark datasets: Waterbirds, CelebA, and ColorMNIST-0.9, comparing the worst-group and average-group accuracies, along with bias-conflicting and bias-aligned accuracies for ColorMNIST-0.9.
This table compares three different bias mitigation techniques: loss-weighted cross-entropy loss, cluster-weighted cross-entropy loss, and the proposed cluster-based adaptive margin loss. The results show the worst-group and average-group accuracies on three benchmark datasets (Waterbirds, CelebA, and ColorMNIST-0.995), demonstrating the effectiveness of the proposed method.

This table presents the performance of a model trained on the Waterbirds dataset using two different pretrained encoders (ViT-H and ResNet-18). The performance is evaluated under three different training data scenarios: the original data, the data with bias-conflicting samples removed, and the group-balanced data. The table shows the worst-group accuracy, average-group accuracy for each encoder and data scenario.

This table compares the performance of several existing bias mitigation methods against the proposed method on three benchmark datasets (Waterbirds, CelebA, and ColorMNIST). The results show that most existing methods perform similarly to or worse than a standard ERM (Empirical Risk Minimization) model, except for the Contrastive Adapter method, which achieves significantly higher worst-group accuracies. This highlights the challenges of bias mitigation in the specific setting of using a frozen pretrained feature extractor.
This table presents the performance comparison of several existing bias mitigation methods on three benchmark datasets (Waterbirds, CelebA, and ColorMNIST-0.995) under a specific setting where a pretrained black-box feature extractor is used. The results show that the existing methods do not provide significant improvements over the standard Empirical Risk Minimization (ERM) method, except for the Contrastive Adapter (Co-Ada). This highlights the challenge of bias mitigation when the feature extractor is not finetunable.
Full paper#