↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Few-shot learning (FSL), while boosted by large pre-trained models, struggles with robust generalization to unseen data and adversarial attacks. Current meta-tuning approaches often fail to maintain performance under these conditions. This necessitates more robust techniques that can adapt quickly to novel tasks while defending against distribution shifts and adversarial examples.
The paper introduces AMT, an Adversarial Meta-Tuning method, to tackle this. AMT uses dual perturbations (inputs and weight matrices) during meta-training to create a robust LoRAPool. This pool dynamically merges discriminative LoRAs at test time, allowing the model to adapt effectively to new tasks. Experiments on multiple benchmarks demonstrate substantial improvements in both clean and adversarial generalization over existing state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the crucial challenge of robust generalization in few-shot learning, a key limitation of current meta-tuning methods. By introducing AMT, the authors provide a practical solution for improving the performance of pre-trained models on out-of-distribution tasks. The proposed method’s adaptability and effectiveness across different domains and adversarial attacks make it a significant step forward in the field. This work opens avenues for further research on adversarial meta-learning and parameter-efficient fine-tuning strategies. This research has implications for real-world applications like medical diagnosis, where model robustness is critical.
Visual Insights#
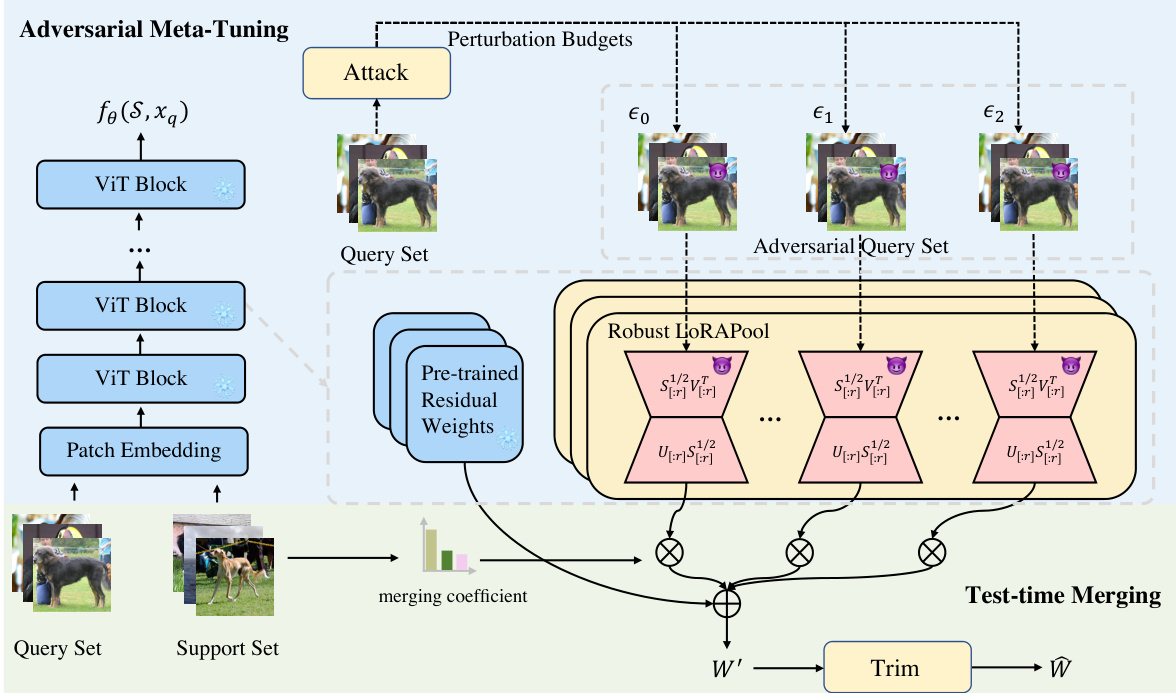
This figure illustrates the AMT method’s architecture. It starts with adversarial meta-tuning, where adversarial perturbations (with varying budgets ’e’) are added to the query set to create an adversarial query set. The model uses a robust LoRAPool (a set of low-rank adapters, LoRAs, meta-tuned with adversarial examples). Each LoRA in the pool is initialized using Singular Value Decomposition (SVD) on the pre-trained weights and incorporates perturbations on singular values and vectors. A test-time merging mechanism dynamically combines the LoRAs based on their effectiveness for a given task, resulting in updated weights (‘W’). The weights are then trimmed (‘W’) before being used for prediction.

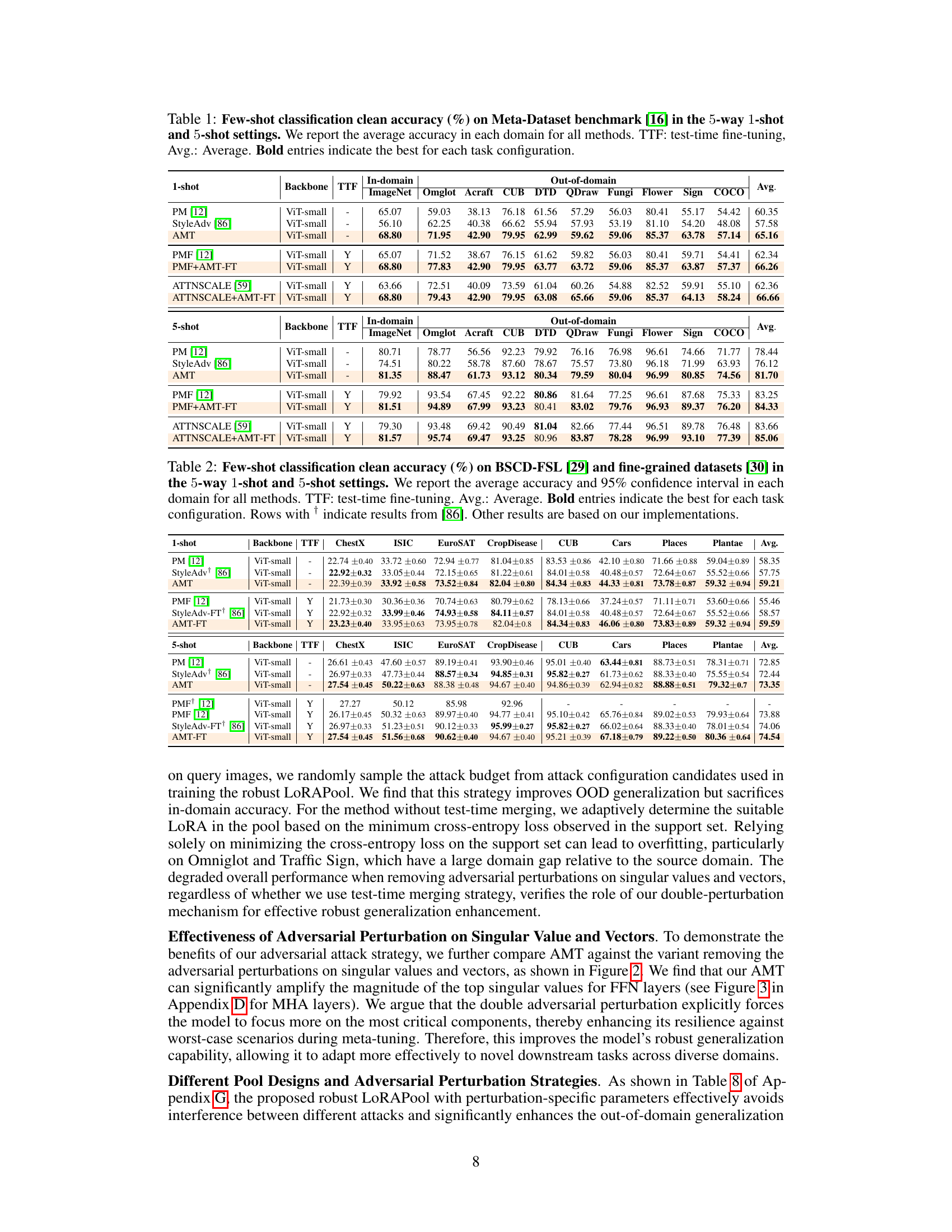
This table presents the clean accuracy results of different few-shot learning methods on the Meta-Dataset benchmark. The results are broken down by the number of shots (1-shot and 5-shot) and the specific dataset within the benchmark. It compares the performance of the proposed AMT method against several baselines, including PMF and ATTNSCALE, both with and without the AMT-FT enhancement. The table highlights the average accuracy across multiple domains for each method and setting.
In-depth insights#
Adversarial Meta-Tuning#
Adversarial meta-tuning, as a robust generalization technique, enhances the adaptability of models in challenging, out-of-distribution scenarios by incorporating adversarial training within a meta-learning framework. Dual perturbations, applied to both inputs and the singular values/vectors of weight matrices, aim to strengthen the model’s principal components, making it more resilient to worst-case attacks. This approach creates a robust pool of Low-Rank Adapters (LoRAs), each meta-tuned with varying adversarial perturbation strengths. A test-time merging mechanism dynamically combines these LoRAs to adapt to unseen tasks during inference. The method is particularly suitable for vision transformers and excels in few-shot image classification scenarios, significantly boosting both clean and adversarial generalization. By explicitly considering adversarial scenarios during meta-training, this technique addresses the inherent challenge of transferring knowledge from source domains to unseen target domains. The resulting robustness offers benefits in applications like autonomous driving and medical diagnosis.
Robust LoRAPool#
The proposed “Robust LoRAPool” is a central component of the AMT (Adversarial Meta-Tuning) methodology, designed to enhance the robustness of vision transformers in few-shot learning scenarios. It addresses the challenge of adapting pre-trained models to unseen, out-of-distribution (OOD) tasks by meta-tuning multiple LoRA (Low-Rank Adaptation) modules in parallel. Each LoRA is trained under varying levels of adversarial perturbations, thus creating a pool of robust adapters. This parallel training approach aims to capture a diverse range of adversarial examples, simulating various distributional shifts encountered in the real world. A key feature is the test-time merging mechanism, allowing the model to dynamically combine these specialized LoRAs based on the characteristics of a new task. This dynamic combination ensures that the model can effectively adapt to unseen tasks while maintaining the advantages of pre-trained knowledge. By explicitly addressing worst-case scenarios through adversarial training and leveraging the efficiency of LoRA, the Robust LoRAPool offers a significant advance over previous methods in tackling OOD generalization and adversarial robustness in few-shot learning settings.
Test-Time Merging#
The concept of ‘Test-Time Merging’ presents a novel approach to enhance the adaptability of machine learning models, particularly within few-shot learning scenarios. It suggests a dynamic, data-driven mechanism to combine pre-trained components or modules during the inference phase. Instead of relying on fixed configurations established during training, this method introduces a merging process at test time, adapting to the specific characteristics of each test task. This adaptability is critical for addressing the challenges of out-of-distribution (OOD) generalization, where the training and test data differ significantly. By selecting and integrating the most relevant components at inference time, this technique aims to improve performance and robustness in OOD settings. The selection process might be guided by evaluating factors such as intra-class compactness and inter-class divergence from the support set, dynamically weighting different components. The test-time merging methodology offers potential advantages for applications where model customization during inference is desirable, however, it also faces challenges such as efficient computation and the requirement of a well-designed merging strategy that avoids interference between components.
Generalization Gains#
The concept of “Generalization Gains” in a machine learning context refers to the improvement in a model’s ability to perform well on unseen data after undergoing a specific training process or modification. A key aspect is the extent to which this improvement surpasses what would be expected from simply increasing model size or training data. Significant generalization gains often result from techniques that enhance model robustness, such as adversarial training or methods that explicitly encourage the learning of more generalizable features. Meta-learning, in particular, often demonstrates substantial generalization gains by allowing a model to learn how to learn quickly from few examples. These gains are usually evaluated on benchmark datasets that cover diverse scenarios and data distributions, providing a robust measure of a model’s ability to generalize. Quantifying generalization gains typically involves comparing performance metrics (e.g., accuracy, F1-score) across different test sets and model variants. Therefore, the analysis of generalization gains forms a crucial part of assessing the overall effectiveness and value of any novel machine learning methodology.
Future Work#
Future research directions stemming from this work could explore several avenues. Extending the AMT framework to encompass diverse adversarial attacks, beyond the l∞ and l2 norms investigated here, would enhance its robustness and applicability across a broader range of real-world scenarios. Another key area is developing a more sophisticated mechanism for adaptively merging the LoRAPool; exploring alternative approaches such as attention-based weighting or reinforcement learning could potentially lead to more effective and efficient test-time task adaptation. Furthermore, investigating the impact of different pre-training strategies on the robustness of AMT, and exploring the potential synergy between various pre-training methods and adversarial meta-tuning, would help optimize AMT’s performance and applicability. Finally, applying AMT to other modalities and tasks, such as audio and natural language processing, would demonstrate its generalizability and uncover further valuable insights.
More visual insights#
More on figures

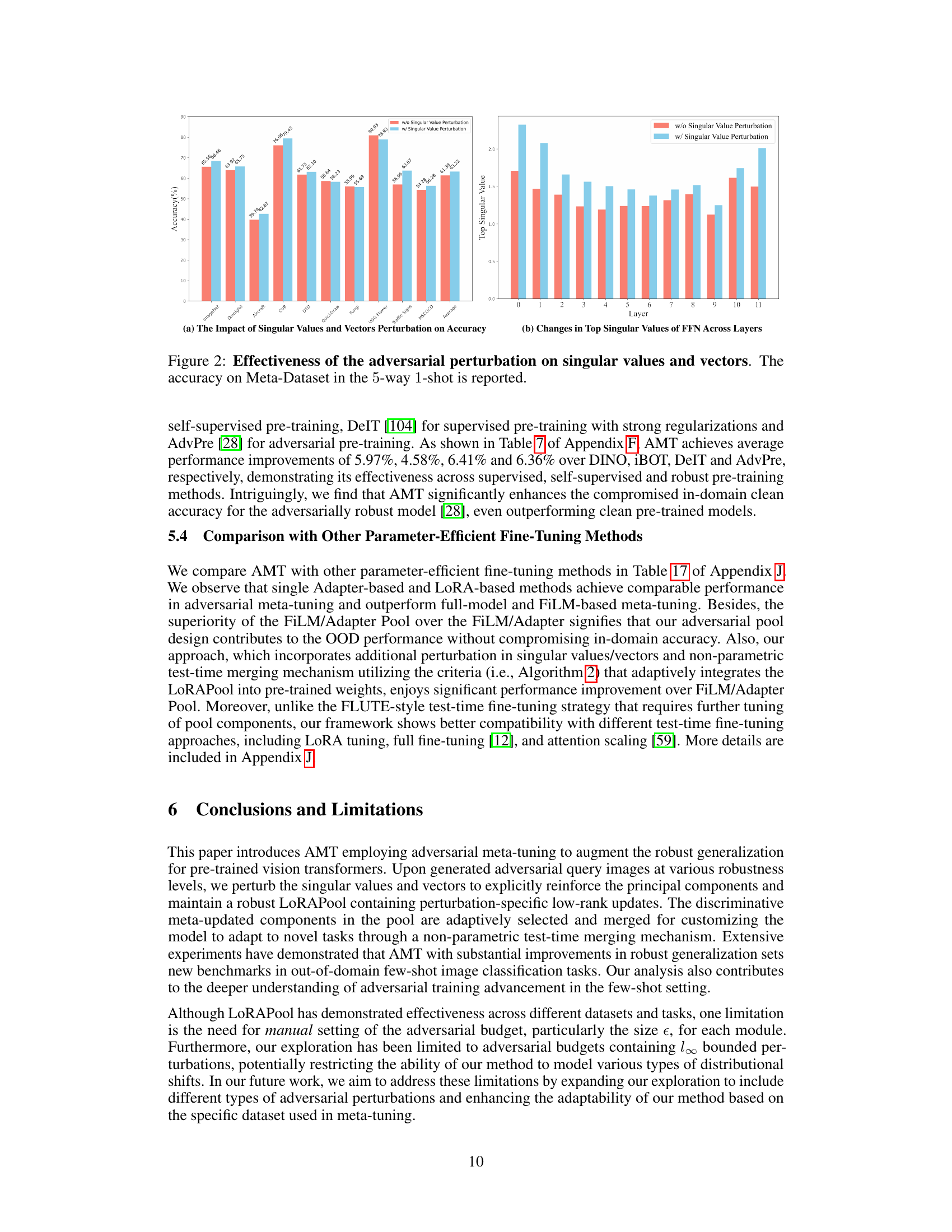
This figure shows the impact of applying adversarial perturbations to singular values and vectors on the model’s accuracy. The left subplot shows the accuracy improvement achieved by including singular value and vector perturbations compared to not including them. The right subplot shows the changes in top singular values of FFN across layers. The results demonstrate that the adversarial perturbations enhance the model’s robustness, particularly in the later layers of the network.

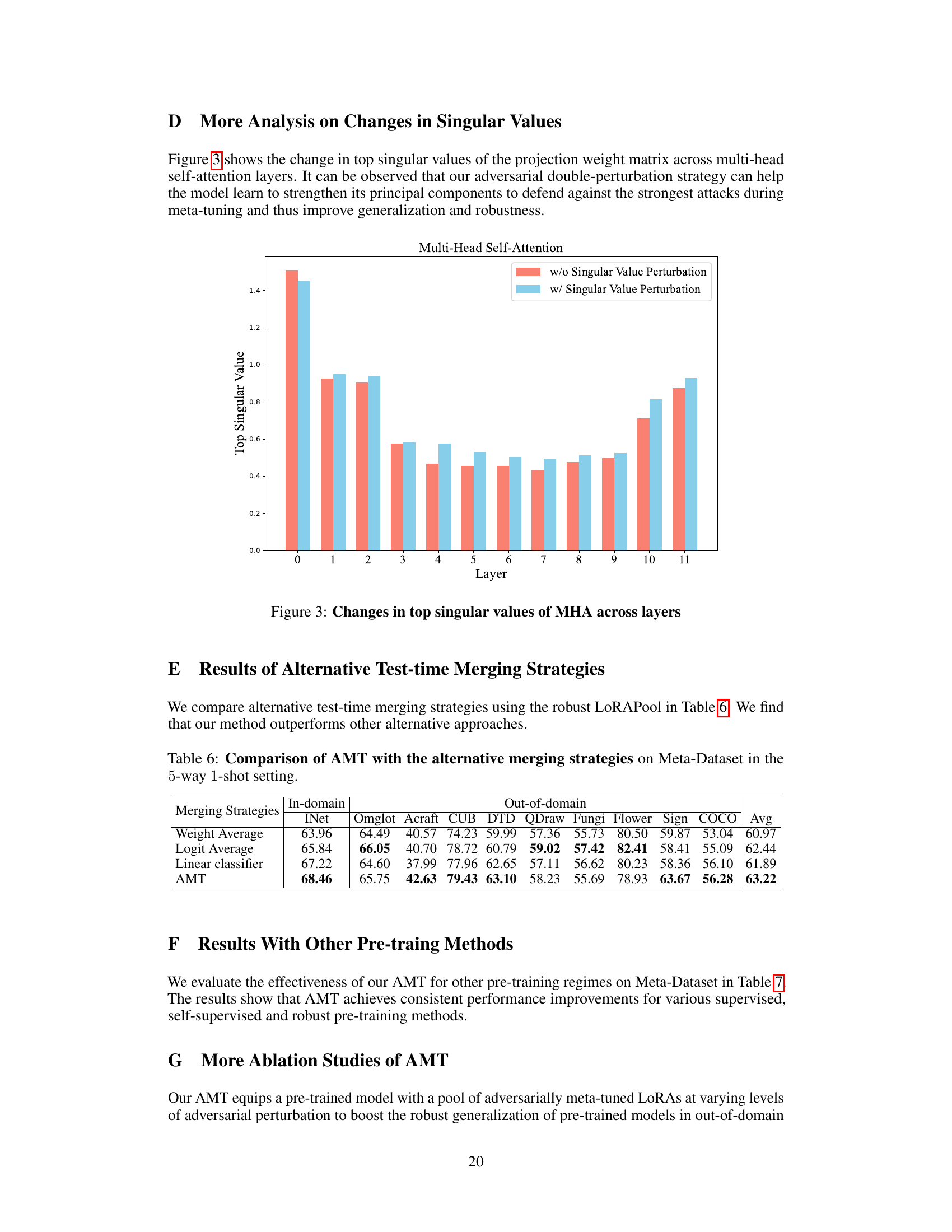
The figure shows the changes in top singular values of the projection weight matrix across multi-head self-attention layers. It illustrates how the adversarial double-perturbation strategy enhances the model’s principal components, improving its robustness against strong attacks during meta-tuning and leading to better generalization.
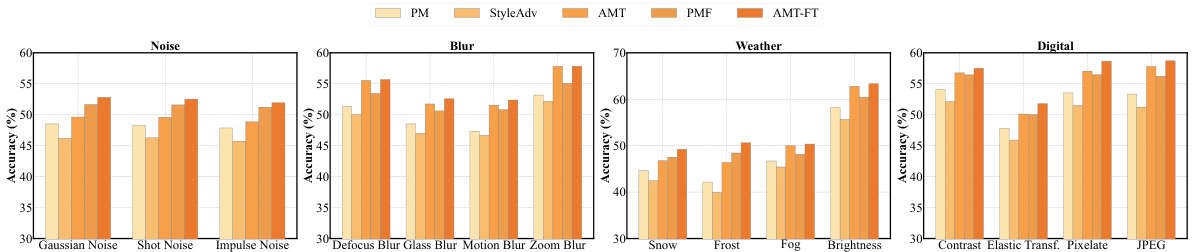
This figure visualizes the robustness of different few-shot learning methods against various image corruptions. The x-axis represents different corruption types (Gaussian Noise, Shot Noise, etc.) and the y-axis represents the accuracy. Each bar represents a specific method (PM, StyleAdv, AMT, PMF, AMT-FT), showing their performance under each type of corruption. The results indicate the relative robustness of each method in handling these common image distortions, highlighting the superior performance of AMT and AMT-FT in maintaining accuracy.
More on tables

This table presents the clean accuracy results of several few-shot learning methods on the Meta-Dataset benchmark. The results are broken down by dataset (ImageNet, Omniglot, etc.), setting (1-shot or 5-shot), and whether test-time fine-tuning (TTF) was used. The table compares the performance of several methods (PM [12], StyleAdv [86], AMT, and others) and highlights the best performance for each task configuration.
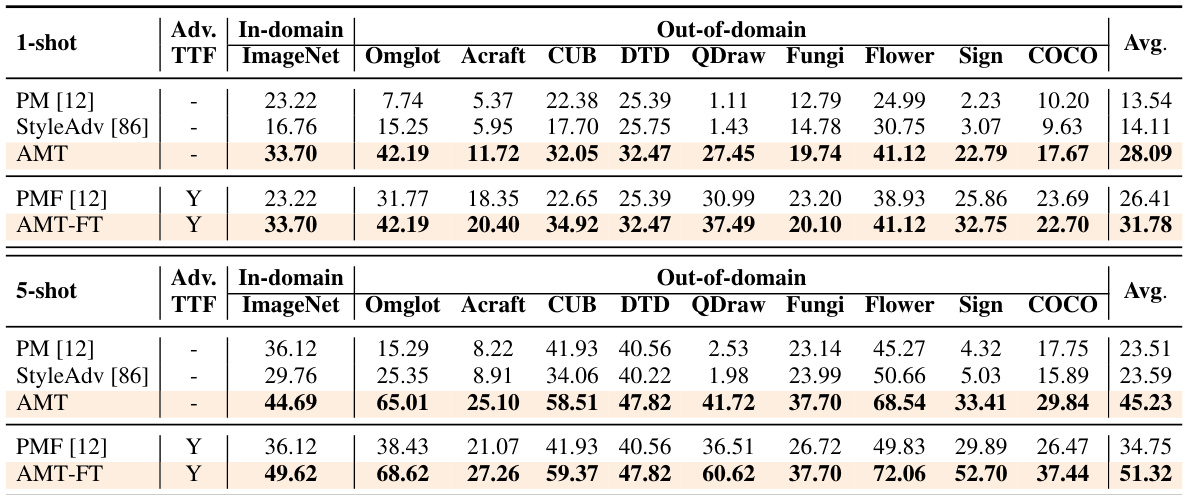
This table presents the clean accuracy results of various few-shot learning methods on the Meta-Dataset benchmark. It shows the performance of different methods (including the proposed AMT) in both 1-shot and 5-shot scenarios across multiple datasets. The results are broken down by dataset and whether test-time fine-tuning was used, providing a comprehensive comparison of the methods’ generalization capabilities.
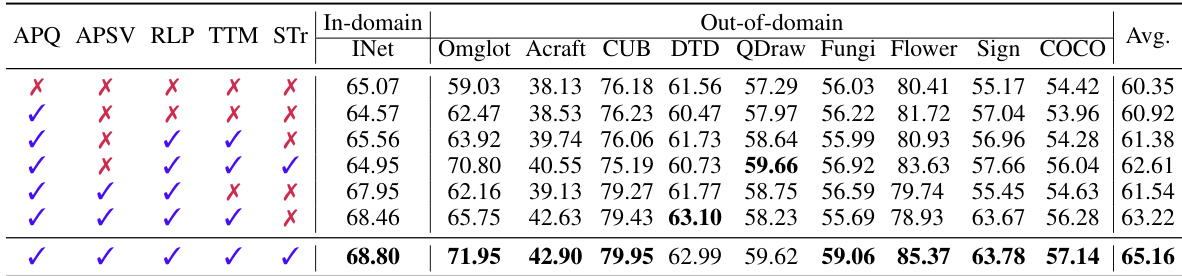
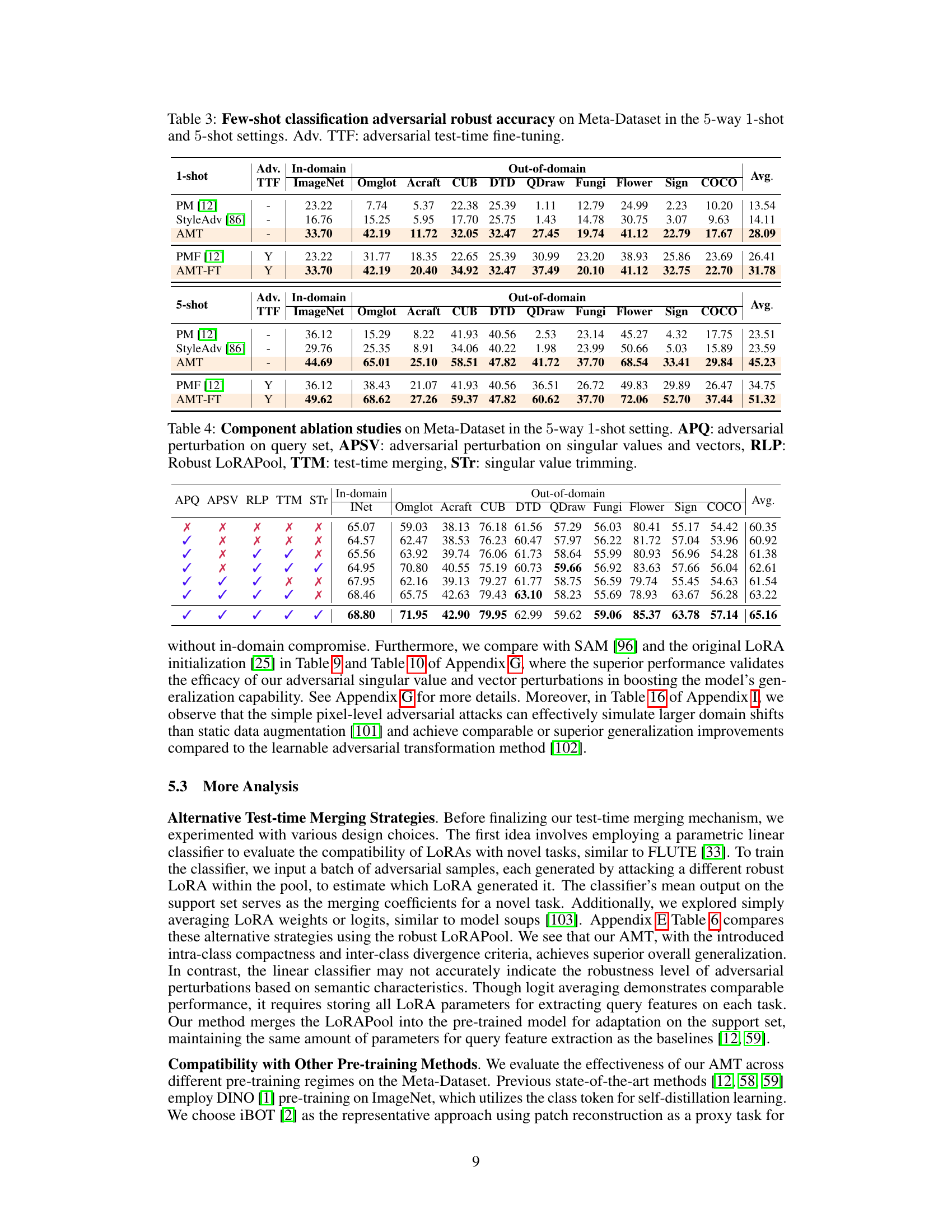
This table presents an ablation study on the Meta-Dataset benchmark for a 5-way 1-shot setting. It evaluates the impact of different components of the proposed AMT method on the performance. The components include adversarial perturbation on the query set (APQ), adversarial perturbation on singular values and vectors (APSV), Robust LoRAPool (RLP), test-time merging (TTM), and singular value trimming (STr). The table shows the average accuracy across various tasks on ImageNet and OOD datasets for different combinations of these components.

This table presents the results of a comparison of different methods for few-shot image classification on the Meta-Dataset benchmark. It shows the average accuracy achieved by each method across various image datasets for both 1-shot and 5-shot scenarios. The results are categorized by whether or not test-time fine-tuning was used. The best performing method for each task and configuration is highlighted in bold.

This table compares the performance of AMT with three alternative test-time merging strategies: Weight Average, Logit Average, and a Linear Classifier. The comparison is made on the Meta-Dataset benchmark using a 5-way 1-shot setting. The table shows the average accuracy across various datasets (INet, Omglot, Acraft, CUB, DTD, QDraw, Fungi, Flower, Sign, COCO) for both in-domain and out-of-domain performance. This allows for a direct comparison of how effectively each merging strategy integrates the robust LoRAPool into the pre-trained model for improved task adaptation and generalization.
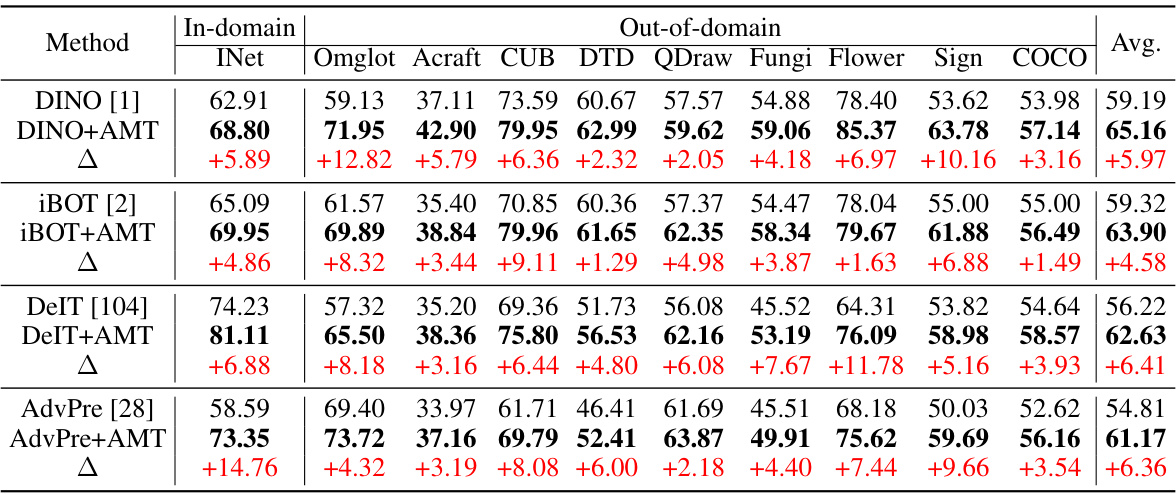
This table presents the results of clean few-shot image classification on the Meta-Dataset benchmark using various methods in both 1-shot and 5-shot settings. The average accuracy across multiple domains (ImageNet, Omniglot, etc.) is shown for each method, indicating their performance in out-of-distribution few-shot learning scenarios. The table highlights the performance of the proposed AMT method compared to baselines and other state-of-the-art methods, emphasizing the improvements achieved by incorporating test-time fine-tuning.

This table compares three different strategies for constructing the robust LoRAPool in the AMT model: uniform, random, and separate. The uniform strategy uses the average attack strength across all training tasks. The random strategy randomly samples an attack budget for each training task. The separate strategy meta-tunes separate LoRA modules for each attack strength. The table presents the in-domain and out-of-domain average accuracy for each strategy across ten image datasets from Meta-Dataset. The results show that the proposed robust LoRAPool with perturbation-specific parameters effectively avoids interference between different attacks and significantly enhances out-of-domain generalization without compromising in-domain performance.

This table presents an ablation study to evaluate the impact of different components of the proposed AMT method on the Meta-Dataset benchmark using a 5-way 1-shot setting. Each row represents a variation of the AMT method, removing one or more components. The results show the effectiveness of each component in improving the overall performance.

This table shows the impact of using either weight space or spectral space perturbation in adversarial meta-tuning. It compares the performance of the proposed AMT method against a baseline using standard LoRA initialization, both in terms of in-domain and out-of-domain accuracy. The results highlight the effectiveness of adversarial perturbations on singular values and vectors, as proposed in the AMT method. The bold entries indicate the best performance for each specific dataset within each domain (in-domain and out-of-domain).

This table shows the influence of the loss trade-off coefficient (\lambda_{adv}) on the performance of the AMT model. The experiment is conducted on the Meta-Dataset benchmark using a 5-way 1-shot setting. The table displays the in-domain and out-of-domain accuracy for different values of \lambda_{adv}, with the best results for each task bolded and the chosen \lambda_{adv} marked with an asterisk.

This table presents the results of adversarial robust accuracy on the Meta-Dataset benchmark for both 5-way 1-shot and 5-shot settings. It compares different methods, including a baseline (PM [12]), StyleAdv [86], and the proposed AMT method, both with and without adversarial test-time fine-tuning (Adv. TTF). The table shows the accuracy for each of the ten domains in the Meta-Dataset, as well as the average accuracy across all domains. It highlights the effectiveness of AMT in improving adversarial robustness in few-shot learning.

This table presents the results of clean few-shot image classification accuracy on the Meta-Dataset benchmark. It compares the performance of different methods (PM[12], StyleAdv[86], AMT, PMF[12], PMF+AMT-FT, ATTNSCALE[59], ATTNSCALE+AMT-FT) in both 5-way 1-shot and 5-way 5-shot settings across various image domains (ImageNet, Omniglot, Acraft, CUB, DTD, QDraw, Fungi, Flower, Sign, COCO). The results are presented as average accuracy and include the effect of test-time fine-tuning (TTF). Bold values highlight the best performing method for each task configuration.

This table presents the results of clean few-shot image classification accuracy on the Meta-Dataset benchmark. It compares several methods in both 1-shot and 5-shot settings across multiple out-of-domain datasets. The table shows the average accuracy for each method on each dataset, highlighting the best-performing method for each task configuration.

This table presents the results of clean few-shot classification accuracy on the Meta-Dataset benchmark. It compares several methods (including the proposed AMT and baselines) in both 1-shot and 5-shot scenarios across multiple domains. The table shows average accuracy for each domain and overall average, highlighting the best-performing method for each task configuration. The results demonstrate the effectiveness of the AMT method on a challenging few-shot learning benchmark.

This table presents the results of clean few-shot image classification accuracy on the Meta-Dataset benchmark. It compares the performance of various methods (including the proposed AMT and baselines like PMF and ATTNSCALE) across different domains in both 1-shot and 5-shot settings. The table shows average accuracy and highlights the best-performing method for each task configuration.

This table compares the performance of AMT with other data augmentation methods (RandConv, ALT, and ALT with attack pool) on the Meta-Dataset benchmark for 5-way 1-shot image classification. The table shows the in-domain and out-of-domain accuracy for each method. The goal is to assess the effectiveness of different data augmentation strategies in improving the model’s robustness to distribution shifts and out-of-domain generalization.

This table presents the results of few-shot image classification experiments conducted on the Meta-Dataset benchmark. It compares different methods’ performance across various datasets in both 1-shot and 5-shot settings. The table shows the average accuracy achieved by each method in each dataset, along with whether test-time fine-tuning was used. Bold entries indicate the best-performing method for each task configuration.
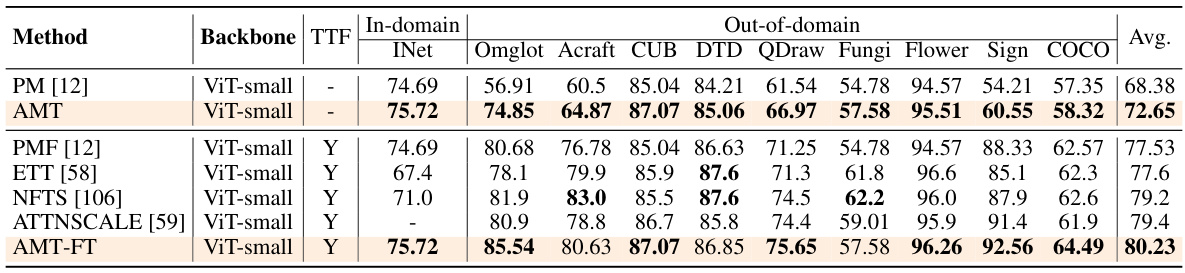
This table presents the results of clean few-shot image classification accuracy on the Meta-Dataset benchmark. It compares several methods (PM[12], StyleAdv[86], AMT, PMF[12], PMF+AMT-FT, ATTNSCALE[59], ATTNSCALE+AMT-FT) in both 1-shot and 5-shot settings across various domains (ImageNet, Omniglot, Acraft, CUB, DTD, QDraw, Fungi, Flower, Sign, COCO). The table shows average accuracy, highlighting the best performing methods for each task.

This table presents the adversarial robust accuracy results of the proposed AMT method and several baseline methods on the Meta-Dataset benchmark. The results are shown for both 1-shot and 5-shot settings. It shows the in-domain and out-of-domain performance under adversarial attacks, highlighting the effectiveness of AMT in improving adversarial robustness.
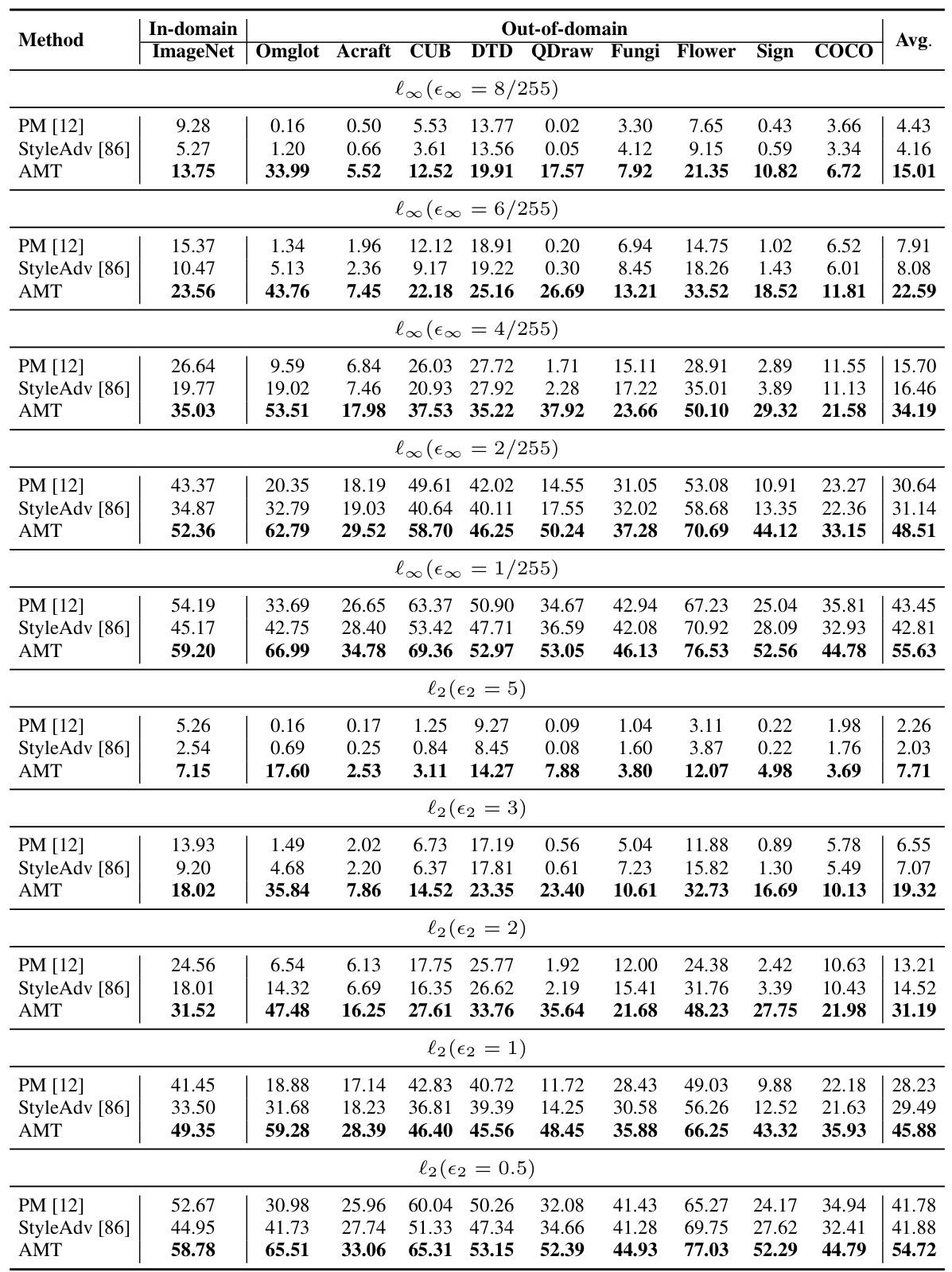
This table shows the results of adversarial robust accuracy on the Meta-Dataset benchmark for both 1-shot and 5-shot settings. It compares the performance of the proposed AMT method against baseline methods (PM [12] and StyleAdv [86]) with and without adversarial test-time fine-tuning (Adv. TTF). The results are presented as the average accuracy across various domains (ImageNet, Omniglot, Acraft, CUB, DTD, QDraw, Fungi, Flower, Sign, COCO). The table highlights the improvements in adversarial robustness achieved by AMT compared to the baseline methods, showing the impact of the adversarial meta-tuning approach.
Full paper#